Beckett SJ, Boulton CA and Williams HTP. FALCON: a software package for analysis of nestedness in bipartite networks [version 1; peer review: 2 approved]. F1000Research 2014, 3:185 (https://doi.org/10.12688/f1000research.4831.1)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
Nestedness is a statistical measure used to interpret bipartite interaction data in several ecological and evolutionary contexts, e.g. biogeography (species-site relationships) and species interactions (plant-pollinator and host-parasite networks). Multiple methods have been used to evaluate nestedness, which differ in how the metrics for nestedness are determined. Furthermore, several different null models have been used to calculate statistical significance of nestedness scores. The profusion of measures and null models, many of which give conflicting results, is problematic for comparison of nestedness across different studies.
We developed the FALCON software package to allow easy and efficient comparison of nestedness scores and statistical significances for a given input network, using a selection of the more popular measures and null models from the current literature. FALCON currently includes six measures and five null models for nestedness in binary networks, and two measures and four null models for nestedness in weighted networks. The FALCON software is designed to be efficient and easy to use. FALCON code is offered in three languages (R, MATLAB, Octave) and is designed to be modular and extensible, enabling users to easily expand its functionality by adding further measures and null models. FALCON provides a robust methodology for comparing the strength and significance of nestedness in a given bipartite network using multiple measures and null models. It includes an “adaptive ensemble” method to reduce undersampling of the null distribution when calculating statistical significance. It can work with binary or weighted input networks. FALCON is a response to the proliferation of different nestedness measures and associated null models in the literature. It allows easy and efficient calculation of nestedness scores and statistical significances using different methods, enabling comparison of results from different studies and thereby supporting theoretical study of the causes and implications of nestedness in different biological contexts.
Nestedness is a statistical property of systems where two kinds of entity interact, which can be represented as bipartite networks. Originally used as a metric for species-site distributions1,2, nestedness has recently gathered much attention as a metric for bipartite species interaction networks, e.g. plant-pollinator mutualisms3,4 and host-virus interactions5–7. Various discussions have considered the sources of nestedness in such systems and its potential implications for ecological dynamics4,8–13. However, it is unclear how to systematically compare results for different ecological datasets. Furthermore, nestedness is not restricted to ecological datasets, but is a generic property of any bipartite network. Thus, there is a need for measures of nestedness that are context-independent and do not depend on any particular (ecological) interpretation. Multiple methods for measuring nestedness have been used in different studies, along with multiple approaches to calculating statistical significance of the measured values. This provides a large number of ways in which nestedness could be evaluated14–16. Before theoretical investigations of the mechanisms of nestedness can be properly undertaken, robust measures and statistical tests for nestedness are required to allow comparison of results from different studies.
Here we present FALCON – a free software package that allows the user to easily compute several measures of nestedness and associated statistical significances based on a selection of null models. FALCON stands for “Framework for Adaptive ensembLes for the Comparison Of Nestedness”. FALCON operates on any form of bipartite interaction data represented as a matrix of associations and is set up to be deliberately ‘blind’ to the source and interpretation of input data. FALCON is based on the assumption that nestedness is a general statistical property of matrices and therefore its measurement should be independent of context or interpretation. FALCON calculates nestedness as a statistical property of a matrix, by returning the nestedness score for the most-nested configuration of the input matrix. Since calculating statistical significance of nestedness scores can be computationally demanding, involving generation of a large ensemble of matrices from a null distribution, FALCON uses a novel “adaptive ensemble” method to improve efficiency by using the minimal ensemble size sufficient to give robust statistics.
Several software packages for calculating nestedness already exist – including1,11,17–21, but these are subject to various factors which make the direct comparison of different nestedness measures and the statistical interpretation of returned values difficult to achieve. Several nestedness measures are handled by packages which deliver a single measure, making the comparison difficult. Some are specific to a particular operating system. Some do not make the source codes available for re-implementation, reducing confidence in their outputs and prevent future extensions. Two packages for the R statistical programming language, bipartite19 and vegan21, together contain functions for several nestedness measures and associated null models, as well as many other tools for analysis of bipartite ecological networks. However, these packages offer no obvious implementation of significance testing (the principal method for reporting results of nestedness analyses) and they also lack several nestedness measures which have been recently developed. FALCON is designed to address these deficiencies, enabling the calculation of nestedness and statistical significance by using a variety of measures and null models, with open source code provided for several platforms.
The FALCON package is available for three commonly used numerical analysis platforms: MATLAB, Octave and R. MATLAB (http://www.mathworks.co.uk/products/matlab/) is a commercial software platform, while Octave (https://www.gnu.org/software/octave/) and R (http://www.r-project.org/) are both freely available open source platforms. FALCON can be freely downloaded on Github (http://github.com/sjbeckett/FALCON) or figshare22 and all code is open and accessible. A guide to downloading, installing and running FALCON accompanies the code. This document describes the assumptions on which FALCON is based, how it calculates nestedness and statistical significance, gives details of the adaptive ensemble method used to improve computational efficiency and provides a case study to demonstrate its usage and outputs.
1 What is nestedness?
Nestedness is a statistical property of bipartite interaction data presented in matrix form. In a perfectly nested matrix, the entries in each successive row are a strict subset of those in the previous row, while the entries in each successive column are a strict subset of those in the previous column (Figure 1). Interpretation of nestedness depends on context.
Figure 1. Perfectly nested, weakly nested, and randomly connected matrices.
White squares indicate connections between two kinds of entity arranged in rows and columns.
The concept of nestedness was first described in studies on how species distributions varied between sites23–25, and later defined quantitatively as measuring the ‘amount of order/disorder’ in matrices representing the presence/absence of species in island communities1. Used in this way, nestedness is calculated from a matrix of presence-absence data where rows are species and columns are sampling sites along some environmental or spatial gradient. A perfectly “nested” matrix (see Figure 1) would be achieved when the set of species present at each site along the gradient is a subset of the species present at the previous site. Since then, the concept of nestedness has been extended in various directions; see26 for an historical overview of the nestedness concept. Nestedness has continued to be applied to spatial patterning (e.g.27) and has been linked with β-diversity28, but has also been applied to study mutualistic or antagonistic species-species interactions29,30, species-time relationships for a single site31, and several other types of bipartite networks9,10,32–35. For pairwise interactions (e.g. plant-pollinator or host-parasite systems), nestedness has been interpreted as placing species along a gradient of generalism-specialism in the number of partners they interact with; in this context, perfect nestedness is achieved when species within each class are ordered such that the interaction set (set of partners) for each species is a strict subset of that of the next species, and the most generalised species of one class interact with the most specialised species of the other class.
Nestedness is calculated from a biadjacency matrix representing pairwise interactions between two kinds of entity (one represented by rows, the other by columns). The order of rows and columns for a biadjacency matrix is arbitrary with respect to connectivity; rows and columns can be permuted without affecting the underlying topology of the interaction network. Any non-arbitrary ordering of rows and columns in the matrix representation necessitates the use of additional contextual information to specify which order rows and columns should take. While some datasets may suggest a “natural” ordering to rows and columns in the matrix representation of data (e.g. when one of the dimensions represents an environmental/spatial/temporal gradient), for many applications of nestedness there is no natural ordering (e.g. species interactions).
As stated above, we consider that nestedness should be a context-free metric, so that it can be applied to data without requiring any supplemental information on row/column ordering. This assumption implies that the ordering of rows and columns should not affect the measurement of nestedness. While some nestedness measures are insensitive to row/column ordering, several of the most commonly used measures are highly sensitive to ordering, introducing indeterminacy to the quantification of nestedness when rows/columns are ordered arbitrarily. To avoid this indeterminacy and return a single robust nestedness score for a given input matrix, FALCON can sort the rows and columns such that nestedness (however calculated) is maximised. Since re-ordering rows/columns in a matrix representation does not alter the structural information (node adjacency) of the underlying data, this re-ordering is a reasonable approach and makes the measurement of nestedness more consistent.
2 Measures of nestedness in FALCON
Nestedness is most commonly calculated for binary data representing presence/absence of an interaction between two entities, but can also be calculated for weighted data that indicate the strength of the interaction. The methods used to calculate nestedness vary depending on whether binary or weighted interaction data are provided. The nestedness measures available in FALCON are shown and briefly described below and in Table 1; further details are given in Appendix A.
The nestedness measures considered here are not trivial variations upon each other, but differ significantly in their derivations. However, some similarities can be drawn. Spectral radius (SR)11 and the measure of Johnson, Domínguez-García, & Muñoz38 (JDM) are invariant to the ordering of rows and columns in the network and are calculated using the adjacency matrix of the network. On the other hand, discrepancy (BR)2, Manhattan distance (MD)37 and nestedness based on overlap and decreasing fill (NODF)36 are all sensitive to row/column ordering and are maximised when rows/columns are ranked by degree. The nestedness temperature calculator (NTC)1,21 involves sorting of rows and columns against the ‘isocline of perfect order’ (see Figure 5) such that it maximises connections above the isocline and minimises connections below the isocline. BR is similarly calculated relative to an idealised ‘maximally packed’ matrix. NODF is found through pairwise comparisons of overlap between subsequent rows and columns, whilst MD is found by assigning a weight to each connection as a sum of it’s row and column indexes. The measures also differ in how nestedness is scored; the degree of nestedness in a network increases with increasing measure score for JDM, NODF and SR, but with decreasing measure score for BR, MD and NTC.
3 Comparison of nestedness scores
Nestedness is strongly sensitive to the size (number of rows and columns) and fill (number of non-zero entries) of the input matrix17. This is problematic in practical terms, since we often wish to compare nestedness of matrices that differ in these basic properties; in fact, cases where we compare empirically derived matrices with identical size and fill are an exception. Thus comparison of absolute values of nestedness metrics is not informative and may be misleading. To compare nestedness of matrices with differing size and fill, observed nestedness should always be interpreted in the context of a null distribution of matrices with similar properties. Measuring observed nestedness relative to expected nestedness derived from a null distribution of similar matrices allows determination of both effect size (e.g. as a z-score, which is commonly used to compare different nestedness schemes26,39) and statistical significance (e.g. as a p-value giving the expected frequency of the observed score in the null distribution). This approach necessitates choice of a suitable null model and generation of a distribution of random matrices drawn from it.
In the present context, a null model is a method for creating a distribution of matrices that conserves some properties of the input matrix while varying other properties at random40. We continue the “context-free” approach in our treatment of null models; to allow comparison of nestedness across different scenarios, a good null model should not make assumptions about the mechanisms by which data were generated, but treat the matrix as an independent data structure. However, to be comparable to the input matrix, null matrices must conserve some key matrix properties (such as size and fill) on which nestedness depends. The null models available in FALCON are given in Table 2; further detail is given in Appendix B. FALCON includes some of the more popular null models from the literature, alongside some additional null models that we feel can be useful. Null models vary in whether the original data is binary or quantitative, and in which properties of the original input matrix are preserved.
an input network in the form of a bipartite matrix
whether binary or quantitative nestedness should be investigated (quantitative matrices can be analysed using binary measures)
whether to sort rows and columns to maximise nestedness score
which nestedness measures should be used
which null models nestedness should be tested under
whether the ensemble of null models should be created with a fixed number or adaptively chosen
whether or not to plot the distributions of nestedness scores
Output is returned to the user in the form of:
the most nested configuration of the input matrix
the nestedness measure(s) of the input matrix
the expected value of nestedness under the null model(s) (as the mean measure of matrices created in the ensemble)
the number of ensemble members used to calculate significance in each null model
the statistical significance of the nestedness of the input matrix against each null model as a p-value
the standard deviation and sample z-scores of the measure in the ensemble as well as other properties.
4.2 What FALCON does
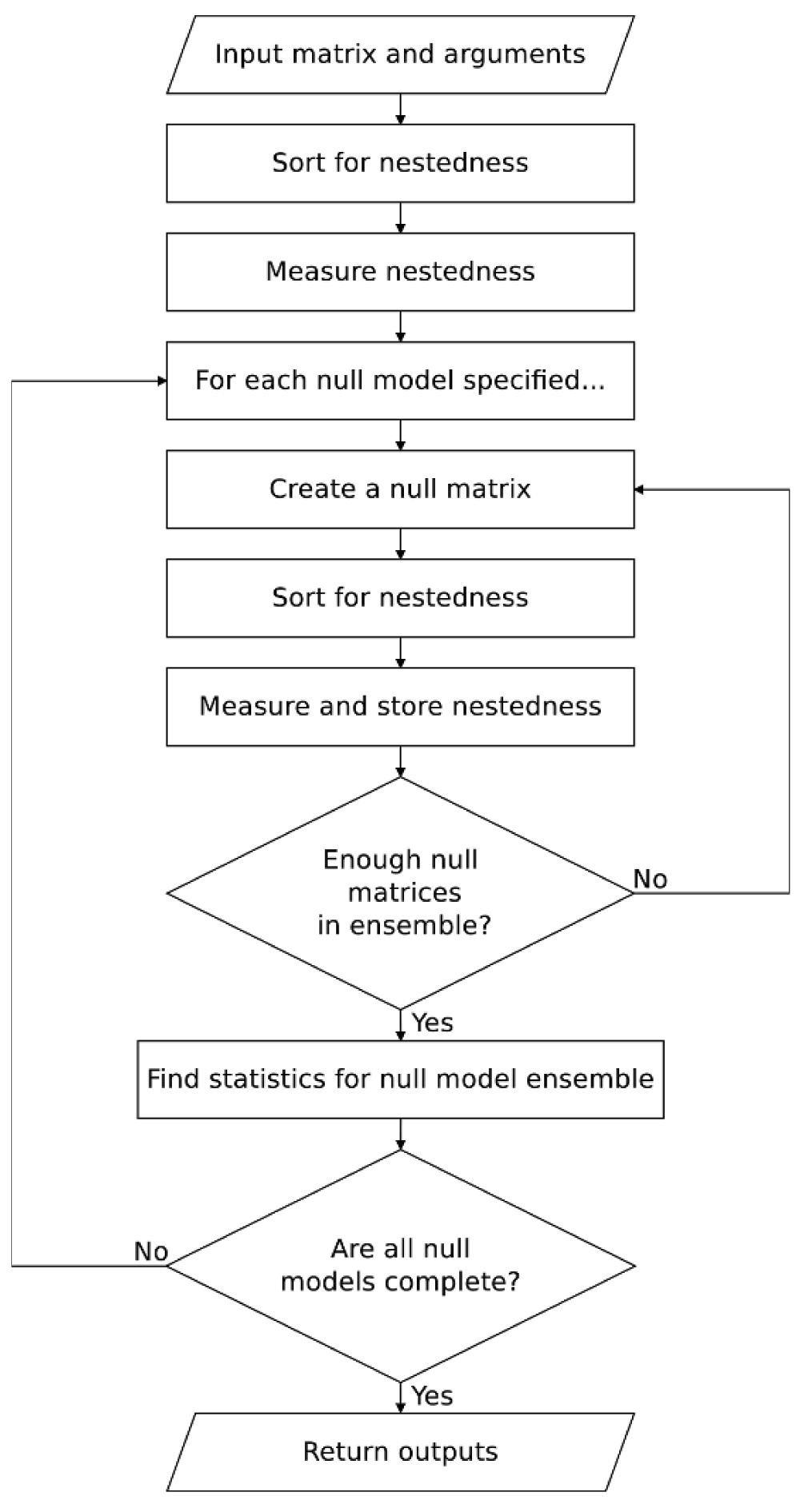
FALCON follows the process shown in Figure 2. First, it sorts the user input matrix into a maximally nested configuration and removes any empty rows/columns before finding the nestedness of this matrix using the users chosen measures. Then, FALCON goes through each of the user specified null models one by one, creating an ensemble of null matrices according to the rules of each null model. Each null matrix is then sorted and measured by each of the chosen nestedness measures. Thus, for each null model, nestedness measures are calculated for each of the null matrices in a single null ensemble, enabling direct comparison of results. The size of the null ensemble is determined by the input choice of using either the fixed or adaptive ensemble size (see Section 4.5). Statistics are computed from the measures found in the null ensemble (and the direction in which that nestedness measure is calculated), before the next null model ensemble is instantiated. Once all null models have been computed, the results are returned to the user.
Figure 2. FALCON algorithmic procedure.
4.3 Direction of increasing nestedness
For different nestedness measures, increasing scores can represent either increasing or decreasing nestedness as discussed in Section 2. FALCON initially determines whether a higher measure score is related to greater nestedness (or vice versa) in the chosen measure by comparing the scores returned for a highly nested network (see Figure 3A) and a highly non-nested network (a weighted checkerboard configuration; Figure 3B), for which the fill (number of non-zero elements) and element sums are equal. The direction of increasing nestedness for a given measure is used during calculation of statistical significance. This method of determining direction each time the algorithm runs is included to allow easy extensibility; if a new measure is added, FALCON will automatically determine which direction indicates increasing nestedness.
Figure 3.
(A) Weighted nested matrix. (B) Weighted non-nested matrix (checkerboard). Both (A) and (B) have 55 non-zero elements that sum to 220.
4.4 Initial sort
For efficiency, FALCON is set up to initially sort the input matrix by row and column degrees for calculation of BR, MD and NODF, retains this sorted configuration for calculation of JDM and SR, and subsequently re-sorts for NTC in order to find the maximal nestedness of a binary matrix. For quantitative data, FALCON uses the same methods as for binary interactions, but also utilises weight data to break symmetry when two rows (columns) have the same degree; in this case, the row (column) which has greater values for most overlapping elements is ranked highest. Where two or more rows (columns) share the same degree and most overlapping elements, the rows (columns) are ranked according to the total sum of row (column) elements. This sorting does not affect the underlying topology or the relationships in the data. FALCON also allows the user to decide if any sorting is performed, enabling the “context free” assumption to be relaxed (e.g. for investigation of gradient-based nestedness39).
4.5 Size of null ensemble
FALCON uses a bootstrap method to calculate the statistical significance of a given nestedness score, since the true null distributions of the test statistics are not known. The ensemble size used for this calculation can either be fixed or calculated adaptively by FALCON to improve computational efficiency and reduce undersampling effects. Note that the strongest significance that can be assigned is where N is the ensemble size.
Fixed. The number of null matrices used to make up the ensemble is fixed by the user. This method is effective providing that the ensemble is large enough to have statistical power; the larger the ensemble, the more power the test has and the closer the answer will be to the p-value for the (unknown) true null distribution. However, it is not obvious how large the ensemble needs to be; in the literature, amongst others30, use 1,000 null models in their ensembles, whilst12 use 10,000, and6 use 100,000. A large number of different null matrix configurations are possible for a given input matrix and we may wish to avoid undersampling42; however, at the same time very large ensembles can make the calculation of significance computationally intractable.
Adaptive. FALCON includes a mechanism for adaptive determination of ensemble size. This is intended to ensure robust statistics are achieved, avoiding concerns about undersampling or oversampling42, while minimising computational load. The adaptive method works by creating two ensembles in parallel using the same null model. Starting with a minimum ensemble size of 500 in each group, the ensembles are expanded until they show similar statistical properties. This condition is met when the null hypothesis (both ensembles come from the same distribution) of a Mann-Whitney U-test cannot be rejected at 10% significance. When this occurs, it suggests each group represents a good sample of the underlying distribution, and the two groups are combined to form a single null ensemble used to calculate final statistics. The expansion of the size of the ensemble has an upper limit of 100,000 members in case the null hypothesis is always rejected. The adaptive ensemble methods balances statistical precision with computational efficiency; we conservatively use 1,000 as a minimum final ensemble size such that a p-value as low as 0.001 can be assigned.
4.6 Output statistics
p-value. The p-value is the probability that a matrix drawn from the null distribution will be more nested than the input matrix. Low values (p → 0) indicate that the input matrix is highly nested relative to the null distribution; commonly a threshold of p ≤ 0.05 or p ≤ 0.01 is used to denote a statistically significant level of nestedness. Here p is calculated by counting the frequency of matrices in the null ensemble that are more nested than the input matrix; for cases where no member of the null ensemble is more nested than the input matrix we conservatively assign where N is the ensemble size.
Normalised Temperature. The normalised temperature is inspired by the τ-Temperature37. It describes the relationship between the nestedness measure found for the input matrix and the expected nestedness measure derived from the null model ensemble. It is described as:
where < Measure > denotes the expected value. In simple terms, the normalised temperature indicates whether the input matrix is more or less nested than the expectation for a null distribution of similar matrices. Where the measure gives increasing scores with increasing nestedness, T > 1 indicates greater-than-expected nestedness. Where the measure gives decreasing scores with increasing nestedness, T < 1 indicates greater-than-expected nestedness.
Mean. The mean average of the set of nestedness measures found for each of the ensemble members is returned.
Standard Deviation. The standard deviation (σ) of the set of nestedness measures found for each of the ensemble members is returned.
Sample z-score. The z-score, or standard score, is calculated as the difference between the nestedness measure and its expected value divided by the standard deviation of the sample:
It is a measure of the number of standard deviations the nestedness measure of the input matrix is above the expected value. Hence, the way it should be interpreted, as with the normalised temperature, depends on whether nestedness increases with increasing measure score.
5 FALCON usage - case study
To demonstrate FALCON we analyse nestedness analysis in a bipartite network representing the hashtags used by a sample of Twitter users. Data were collected using the Twitter API (https://dev.twitter.com/docs/api) by searching for tweets including the hashtag “#IPCC” in the time period 21st September 2013 – 5th October 2013. A list of all hashtags used by all users found in the search dataset was then used to create a binary bipartite adjacency matrix for users and hashtags. This was then sampled to create a smaller matrix used for this case study by including each row/column with probability of 1.1 and removing any empty rows/columns. The resulting matrix was stored in a comma-separated file called ’IPCC_HTuse_10_10_1_53x27.csv’.
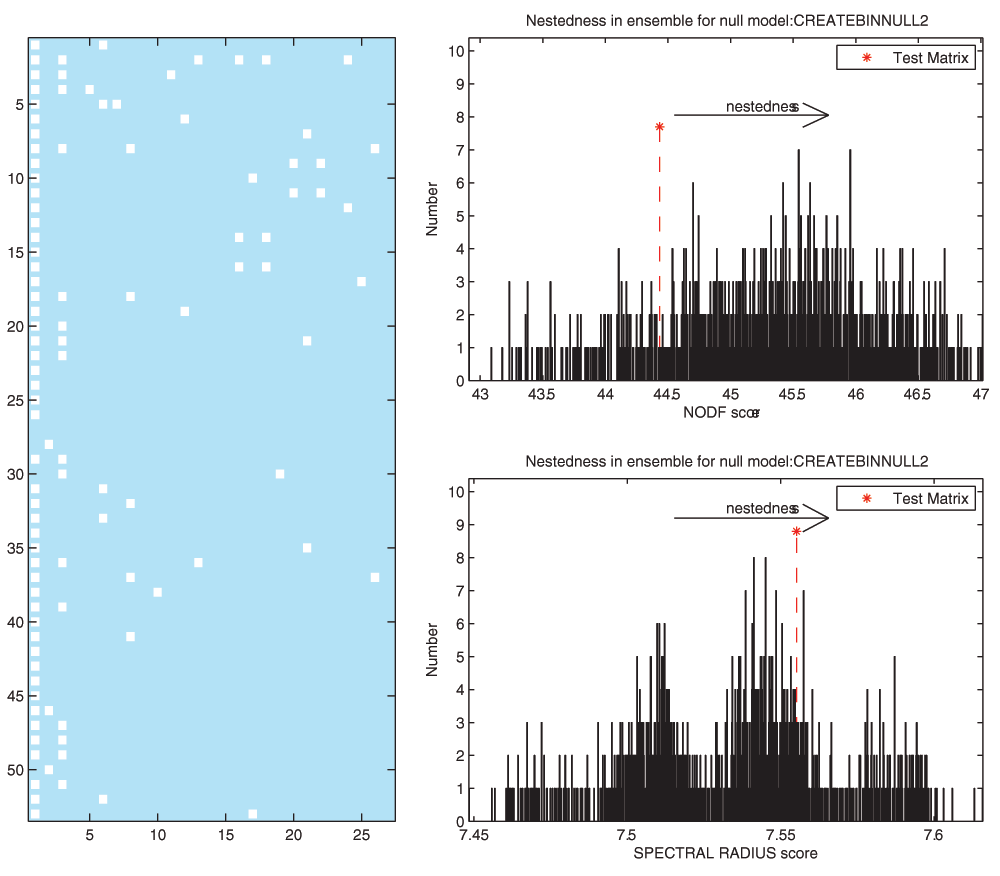
The box below shows the command sequence used to perform a binary nestedness analysis using FALCON in MATLAB. The first line reads in the “.csv” datafile, which includes row and column headers. The second line extracts the adjacency matrix from the imported data. The third line runs FALCON, using two binary nestedness measures (NODF and SR) and two null models (CC and FF, i.e. nulls 2 and 3) using the adaptive solver and displaying histogram plots. The fourth line plots the input matrix in its most nested configuration, as determined by FALCON. The nested configuration of the matrix and output histograms from significance testing are shown in Figure 4, whilst Table 3 shows an example output from the significance testing. Further examples for use of FALCON in R are given in supporting information accompanying the software.
Figure 4. Example output from FALCON.
(A) the nested arrangement of the UserHashtag data. (B) Distribution of NODF scores found for an ensemble of FF null models generated for the UserHashtag network (C) distribution of spectral radius scores found from the same null matrix ensemble. The asterix marks the nestedness score of the input network.
Table 3. Example output from FALCON showing sample statistics for the UserHashtag network using the operations
in the box above.
Nestedness statistics were computed for the FF and CC null models using the NODF and spectral radius measures.
In this paper we have presented FALCON, a software tool for reliable and efficient calculation of nestedness (and associated effect size and statistical significance) based on a selection of popular nestedness measures and null models used in the literature. FALCON treats nestedness purely as a statistical property of a bipartite matrix and removes any form of interpretation or contextual information from the analysis. This enables FALCON to be used to compare nestedness across a wide variety of application areas, noting that the concept of nestedness has already spread from its origin in island biogeography to include species-species interactions and other scenarios, and is likely to find further applications in other domains. The contribution of FALCON is to enable easy cross-comparison of observed nestedness using different nestedness measures and null models. We hope that this functionality will allow greater methodological uniformity and comparability of studies of nestedness. We are in the process of performing a large comparison study of nestedness metrics using FALCON (Beckett and Williams., in preparation). Uniformity of measurement and comparability of empirical results is an important preliminary step that must be achieved to enable understanding of the mechanistic basis and ecological (and otherwise) implications of nestedness. We hope that FALCON will be of use to other researchers and help illuminate this intriguing property of bipartite networks in many natural systems.
SJB developed the initial project in MATLAB. SJB, CAB and HTPW enhanced the original package. SJB and CAB ported FALCON into R. SJB and HTPW wrote the manuscript with input from CAB.
Competing interests
No competing interests declared.
Grant information
The author(s) declared that no grants were involved in supporting this work.
Acknowledgements
We thank Virginia Domínguez-García with the implementation of the JDM nestedness measure.
8 Appendix A: Detailed description of nestedness measures in FALCON
8.1 Binary
NODF. The nestedness measure based on overlap and decreasing fill (NODF) was first described by36 and has since become one of the most popular methods for describing the nestedness of a matrix. NODF can be found as:
Here Ncol and Nrow are scores found by pairwise comparison of rows and columns, c is the number of columns, and r is the number of rows. Ncol is found as the sum of scores from pairwise comparisons of each column against all columns to its right. If both columns have the same degree, then the score is zero. If they have different degrees, the score is the percentage of elements in the second column which also appear in the first column. Nrows is found similarly for pairwise comparisons of each row against all rows below it. The sum of Ncol and Nrow is then normalised by the total number of pairwise comparisons. Values for NODF are between 0 (zero nestedness) and 100 (perfect nestedness). If the input matrix is first sorted to maximise nestedness by rank ordering rows and columns by degree, the form of NODF known as NODFMAX is found43.
τ-Temperature and Manhattan distance. The τ-Temperature37 is a nestedness measure based on relative distances between matrix elements. Unlike other distance-based measures (such as NTC1 and its better described successors BINMATNEST17 and AININHADO18), the τ-Temperature does not use genetic algorithms to sort the data. The τ-Temperature is found by measuring the Manhattan distance D of the network matrix. This is the sum of the row and column indexes of all of the matrix elements Aij that are filled:
Manhattan distance is lower in more highly nested networks, since rows and columns can be shuffled so that many of the elements appear in upper-left positions where row and column indices are low. Once D is found, a null model is chosen (cf. Section 3) and an ensemble of null matrices are created. By finding the mean average Manhattan distance from the ensemble, denoted < Drand >, τ-Temperature can be calculated as:
Values τ > 1 imply that D is greater than < Drand > and
the network is less nested than expected for a network with the properties defined in the null model. τ is better described as a test statistic of the Manhattan distance, than as a measurement of nestedness itself.
JDM Nestedness. The nestedness measure described in38, here termed JDM after author initials, treats nestedness as a measure of dissassortativity between the nodes, i.e., negative correlation between row and column degrees for non-zero elements of the input matrix. Their measure calculates the overlap (as the sum of the elements in the squared adjacency matrix which shows the minimum number of length two paths needed to connect any two nodes) of the input matrix and normalises it by the expected nestedness of the configuration model (a random graph with the same empirical degree distribution as the input network) and thus discounts the effect of degree heterogeneity. This nestedness score is unbounded, but when close to 1 it indicates that the matrix represents an uncorrelated random network. Unadjusted nestedness is calculated using the adjacency matrix a formed from the input bipartite matrix with r rows and c columns, where D is the node degrees in the adjacency matrix:
Nestedness of the configuration model ηconf can be calculated as:
which can also be written as:
where k are the row degrees and d are column degrees in the bipartite matrix. This leads to the normalised measure of nestedness for bipartite networks defined by38 as:
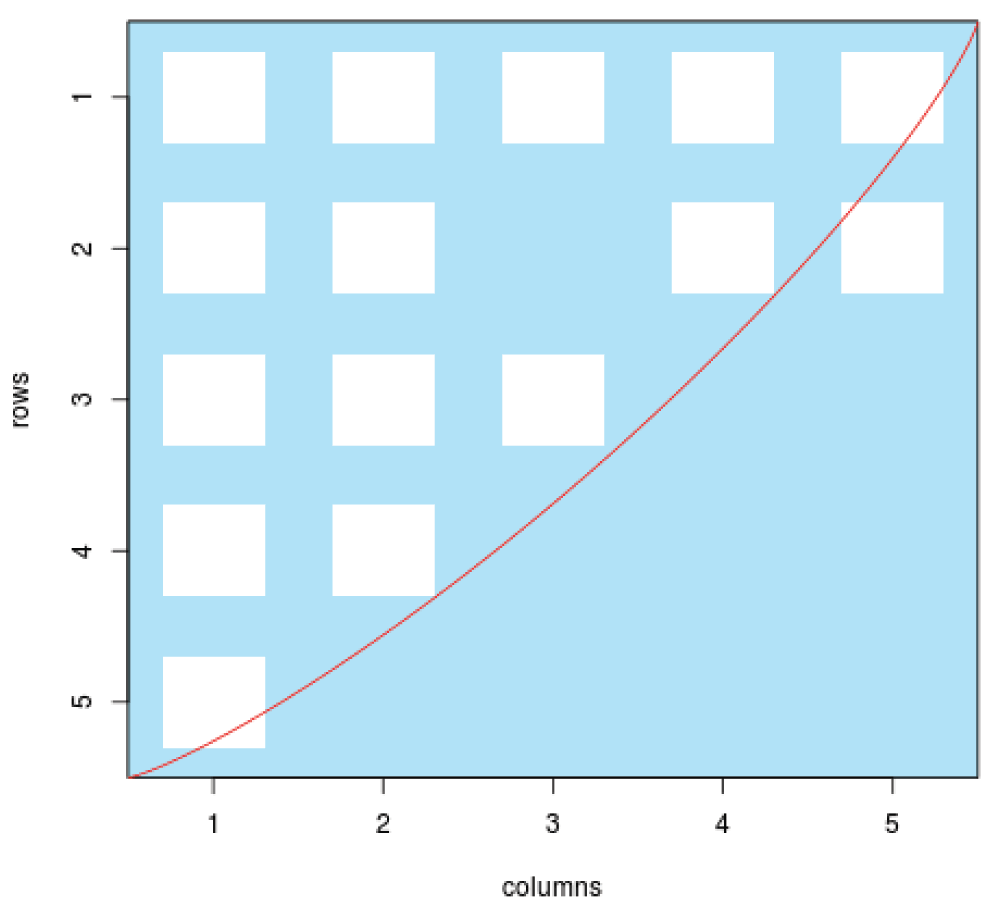
Nestedness Temperature. The original nestedness temperature calculator (NTC)1 was vaguely described and therefore difficult to reimplement, leading to several subsequent variations utilising similar underlying principles15,17,18,21. Here we have recoded the nestedtemp function from the R package vegan21. The nestedness temperature for an input matrix is based on the ‘isocline of perfect order’, a curve drawn from the lower-left corner of the matrix to the upper-right, with curvature defined by matrix fill (see Figure 5). Row and column orderings are then permuted using a genetic algorithm to maximise the number of connections above the isocline and minimise connections below the isocline. The number of connections which violate these rules, termed ‘surprises’, is then calculated and normalised to give a score between 0 (highly ordered) and 100 (highly disordered).
Figure 5. The NTC measure is based on an isocline of perfect order.
Here there are two ‘surprises’.
Discrepancy. Discrepancy2, here denoted BR, quantifies nestedness as the difference between the input matrix and a perfectly nested matrix of the same dimensions and fill. The duplicate matrix P has the same row degrees as the input matrix, but the 1s in each row are pushed as far to the left as possible (ignoring the effect this has on underlying network topology). The discrepancy is then found by subtracting the input matrix from this perfectly nested matrix and counting the number of 1s that remain – the number of differences between P and the input matrix. By treating columns instead of rows an alternative perfectly nested comparator matrix P′ can be formed by pushing the 1s in each column of the input matrix as far to the top as possible – from which a different discrepancy score can be found. Here we modify the original method of2, which looks at discrepancy only in respect to P, and instead define discrepancy as the minimum of the individual discrepancy scores found from P and P′, to remove any bias towards row or column nodes.
8.2 Quantitative
WNODF. The weighted NODF measure, WNODF20, uses a similar algorithm to NODF, but is designed for use on quantitative rather than binary networks. In addition to asking which pairs of rows/columns are subsets of one another, WNODF utilises weight information by also requiring that the preceding row/column has greater values in the overlapping elements. In effect, WNODF is a stricter version of NODF; the maximum WNODF score that can be achieved for a quantitative matrix is equal to the NODF score for the binary matrix.
8.3 Both
Spectral Radius. The spectral radius (SR) is defined as the absolute value of the maximum real eigenvalue from the adjacency matrix of a given input bipartite matrix. SR was proposed as a nestedness measure by11 and can be applied to both binary and quantitative matrices.
9 Appendix B: Null models available in FALCON
9.1 Binary
Swappable-Swappable (SS). The “swappable rows, swappable columns” (SS) null model conserves matrix dimensions (numbers of rows and columns) and fill. It is similar to ‘test one’ in11, which works by shuffling elements at random within the matrix; however, it differs in that degenerate matrices (those containing rows/columns with no connections) are not permitted.
Fixed-Fixed (FF). The “fixed rows, fixed columns” (FF) null model conserves dimensions, fill and degree distribution of the original matrix. It is the most strict null model we consider here and is known to suffer from Type II errors (i.e. a failure to detect nestedness)30. We use the curveball algorithm41 to generate null matrices of this type. It does this by iteratively choosing pairs of rows at random, compiling a list of column indices which contain filled elements in one but not both of the two rows. This list of column indices is then randomly permuted and reassigned to the two rows corresponding to the number of unique positions belonging to each of the original rows. It should be noted that the Manhattan distance is invariant to these permutations.
Cored-Cored (CC). The “cored rows, cored columns” (CC) null model conserves dimensions and fill as in the SS null model, but also conserves some of the core structure found in the observed input matrix. It is found by performing a total of M × N trial-swaps on the M × N input matrix, where two matrix elements are randomly chosen and their values can be swapped only when this does not reduce the corresponding row or column degrees to zero. This ensures that the size structure is conserved and preferentially preserves specialist interactions within the network. The removed elements are then randomly reassigned to the remaining empty spaces to preserve matrix fill.
Degreeprobable-Degreeprobable (DD). The “degreeprobable rows, degreeprobable columns” (DD) null model first described by3 has subsequently been a popular choice for application to species-species nested comparisons. Matrix elements are probabilistically determined depending on the degree distribution of the rows and columns of the initial matrix as:
where pij is the probability of assigning a 1 to the ith row and jth column of the null matrix, dj is the column degree of the jth column, ki is the row degree of the ith row and r and c are the respective number of rows and columns. Due to the stochastic nature of this null model its output matrices will vary in size and fill.
Equiprobable-Equiprobable (EE). The “equiprobable rows, equiprobable columns” (EE) null model is probabilistic and assumes that the probability of a connection occurring between two nodes is related to the number of total connections in the input matrix. Hence for an input matrix with fill M, r rows and c columns, the probability of a connection being present between two nodes is . Due to the stochastic nature of this null model its output matrices will vary in size and fill. It is the least strictly defined null model we consider here and is known to suffer from Type I errors (a tendency to falsely detect nestedness)30.
9.2 Quantitative
Binary Shuffle. This null model was employed by11 and conserves the entire binary structure of the input matrix and the values of the elements in the matrix, but shuffles the order of these values randomly across the binary structure.
Conserve Row Totals (CRT). This null model conserves binary structure and the row sum totals, but the values of the elements on each row are changed such that each connection in the row is assigned a random proportion of the row sum total.
Conserve Column Totals (CCT). This null model conserves binary structure and the column sum totals, but the values of the elements in each column are changed such that each connection in the column is assigned a random proportion of the column sum total.
Row Column Totals Average (RCTA). Both of the two above null models conserve information related to either the rows or the columns, giving this property precendent over that of the other entity. We also introduce the Row Column Totals Average (RCTA) null model which uses the average of a single null model made from each of the CCT and CRT null models. As information from both rows and columns is utilised in the creation of this null model it may better fit with the context free ethos of nestedness we pursue than either of CRT or CCT alone.
Faculty Opinions recommended
References
1.
Atmar W, Patterson BD:
The measure of order and disorder in the distribution of species in fragmented habitat.
Oecologia.
1993; 96(3): 373–382. Publisher Full Text
2.
Brualdi RA, Sanderson JG:
Nested species subsets, gaps, and discrepancy.
Oecologia.
1999; 119(2): 256–264. Publisher Full Text
3.
Bascompte J, Jordano P, Melián CJ, et al.:
The nested assembly of plant-animal mutualistic networks.
Proc Natl Acad Sci U S A.
2003; 100(16): 9383–9387. PubMed Abstract
| Publisher Full Text
| Free Full Text
4.
James A, Pitchford JW, Plank MJ:
Disentangling nestedness from models of ecological complexity.
Nature.
2012; 487(7406): 227–230. PubMed Abstract
| Publisher Full Text
6.
Flores CO, Valverde S, Weitz JS:
Multi-scale structure and geographic drivers of cross-infection within marine bacteria and phages.
ISME J.
2013; 7(3): 520–532. PubMed Abstract
| Publisher Full Text
| Free Full Text
7.
Beckett SJ, Williams HT:
Coevolutionary diversification creates nested-modular structure in phage-bacteria interaction networks.
Interface Focus.
2013; 3(6): 20130033. PubMed Abstract
| Publisher Full Text
| Free Full Text
8.
Thébault E, Fontaine C:
Stability of ecological communities and the architecture of mutualistic and trophic networks.
Science.
2010; 329(5993): 853–856. PubMed Abstract
| Publisher Full Text
9.
Saavedra S, Stouffer DB, Uzzi B, et al.:
Strong contributors to network persistence are the most vulnerable to extinction.
Nature.
2011; 478(7368): 233–235. PubMed Abstract
| Publisher Full Text
10.
Bustos S, Gomez C, Hausmann R, et al.:
The dynamics of nestedness predicts the evolution of industrial ecosystems.
PLoS One.
2012; 7(11): e49393. PubMed Abstract
| Publisher Full Text
| Free Full Text
11.
Staniczenko PP, Kopp JC, Allesina S:
The ghost of nestedness in ecological networks.
Nat Commun.
2013; 4: 1391. PubMed Abstract
| Publisher Full Text
12.
McQuaid CF, Britton NF:
Host-parasite nestedness: A result of co-evolving trait-values.
Ecol Complexity.
2013; 13: 53–59. Publisher Full Text
13.
Lever JJ, van Nes EH, Scheffer M, et al.:
The sudden collapse of pollinator communities.
Ecol Lett.
2014; 17(3): 350–359. PubMed Abstract
| Publisher Full Text
14.
Gotelli NJ:
Null model analysis of species co-occurrence patterns.
Ecology.
2000; 81(9): 2606–2621. Publisher Full Text
15.
Ulrich W, Gotelli NJ:
Null model analysis of species nestedness patterns.
Ecology.
2007; 88(7): 1824–1831. PubMed Abstract
| Publisher Full Text
16.
Csermely P, London A, Wu L, et al.:
Structure and dynamics of core/periphery networks.
J Complex Networks.
2013; 1(2): 93–123. Publisher Full Text
17.
Rodríguez-Gironés MA, Santamaría L:
A new algorithm to calculate the nestedness temperature of presence–absence matrices.
J Biogeogr.
2006; 33(5): 924–935. Publisher Full Text
18.
Guimarães PR, Guimarães P:
Improving the analyses of nestedness for large sets of matrices.
Environ Model Softw.
2006; 21(10): 1512–1513. Publisher Full Text
20.
Almeida-Neto M, Ulrich W:
A straightforward computational approach for measuring nestedness using quantitative matrices.
Environ Model Softw.
2011; 26(2): 173–178. Publisher Full Text
21.
Oksanen J, Guillaume Blanchet F, Kindt R, et al.:
vegan: Community Ecology Package. R package version 2.0–10. 2013. Reference Source
22.
Beckett SJ, Boulton CA, Williams HT:
FALCON: nestedness statistics for bipartite networks. 2014. Data Source
23.
Hultén E:
Outline of the history of arctic and boreal biota during the Quaternary period: their evolution during and after the glacial period as indicated by the equiformal progressive areas of present plant species. Bokförlags Aktiebolaget Thule. 1937; 1: 168. Reference Source
24.
Darlington PJ:
Zoogeography: the geographical distribution of animals. Wiley, New York, 1957; 676. Reference Source
25.
Daubenmire R:
Floristic plant geography of eastern Washington and northern idaho.
J Biogeogr.
1975; 2(1): 1–18. Publisher Full Text
26.
Ulrich W, Almeida-Neto M, Gotelli NJ:
A consumer’s guide to nestedness analysis.
Oikos.
2009; 118(1): 3–17. Publisher Full Text
27.
Fraser CI, Terauds A, Smellie J, et al.:
Geothermal activity helps life survive glacial cycles.
Proc Natl Acad Sci U S A.
2014; 111(15): 5634–5639. PubMed Abstract
| Publisher Full Text
| Free Full Text
28.
Baselga A:
The relationship between species replacement, dissimilarity derived from nestedness, and nestedness.
Glob Ecol Biogeogr.
2012; 21(12): 1223–1232. Publisher Full Text
29.
Fortuna MA, Stouffer DB, Olesen JM, et al.:
Nestedness versus modularity in ecological networks: two sides of the same coin?
J Anim Ecol.
2010; 79(4): 811–817. PubMed Abstract
| Publisher Full Text
30.
Joppa LN, Montoya JM, Solé R, et al.:
On nestedness in ecological networks.
Evol Ecol Res.
2010; 12: 35–46. Reference Source
31.
Chávez VA, Doncaster CP, Dearing JA, et al.:
Detecting regime shifts in artificial ecosystems. In Advances in Artificial Life.
ECAL.
2013; 12: 625–632. Publisher Full Text
32.
Tim Tinker M, Guimarães PR Jr, Novak M, et al.:
Structure and mechanism of diet specialisation: testing models of individual variation in resource use with sea otters.
Ecol Lett.
2012; 15(5): 475–483. PubMed Abstract
| Publisher Full Text
33.
Dalsgaard B, Trøjelsgaard K, González AMM, et al.:
Historical climate-change influences modularity and nestedness of pollination networks.
Ecography.
2013; 36(12): 1331–1340. Publisher Full Text
34.
Piepenbrink A, Gaur AS:
Methodological advances in the analysis of bipartite networks: an illustration using board interlocks in Indian firms.
Organ Res Meth.
2013; 16(3): 474–496. Reference Source
35.
Melo AS, Cianciaruso MV, Almeida-Neto M:
treenodf: nestedness to phylogenetic, functional and other tree-based diversity metrics.
Methods Ecol Evol.
2014; 5(6): 563–572. Publisher Full Text
36.
Almeida-Neto M, Guimaraes P, Guimarães PR, et al.:
A consistent metric for nestedness analysis in ecological systems: reconciling concept and measurement.
Oikos.
2008; 117(8): 1227–1239. Publisher Full Text
37.
Corso G, Britton NF:
Nestedness and τ-temperature in ecological networks.
Ecol Compl.
2012; 11: 137–143. Publisher Full Text
39.
Ulrich W, Almeida-Neto M:
On the meanings of nestedness: back to the basics.
Ecography.
2012; 35(10): 865–871. Publisher Full Text
40.
Gotelli NJ:
Research frontiers in null model analysis.
Glob Ecol Biogeogr.
2001; 10(4): 337–343. Publisher Full Text
41.
Strona G, Nappo D, Boccacci F, et al.:
A fast and unbiased procedure to randomize ecological binary matrices with fixed row and column totals.
Nat Commun.
2014; 5: 4114. PubMed Abstract
| Publisher Full Text
42.
Poisot T, Gravel D:
When is an ecological network complex? Connectance drives degree distribution and emerging network properties.
PeerJ.
2014; 2: e251. PubMed Abstract
| Publisher Full Text
| Free Full Text
43.
Podani J, Schmera D:
A comparative evaluation of pairwise nestedness measures.
Ecography.
2012; 35(10): 889–900. Publisher Full Text
Beckett SJ, Boulton CA and Williams HTP. FALCON: a software package for analysis of nestedness in bipartite networks [version 1; peer review: 2 approved]. F1000Research 2014, 3:185 (https://doi.org/10.12688/f1000research.4831.1)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
track
receive updates on this article
Track an article to receive email alerts on any updates to this article.
Share
Open Peer Review
Current Reviewer Status:
?
Key to Reviewer Statuses
VIEWHIDE
ApprovedThe paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approvedFundamental flaws in the paper seriously undermine the findings and conclusions
This is a great, easy-to-use, and comprehensive piece of software. I am eager to begin to use it myself and to send it to colleagues who are reluctant to run the other nestedness software. The paper is also very well-written
... Continue reading
This is a great, easy-to-use, and comprehensive piece of software. I am eager to begin to use it myself and to send it to colleagues who are reluctant to run the other nestedness software. The paper is also very well-written making this field more accessible. As the authors state, many forms of biological data are organized in bipartite networks and show nested pattern. With such a software platform and clear manuscript, I hope more similarities across biological systems will be recognized and appreciated, perhaps even promoting collaborations and new theory. My one suggestion is for the authors to provide a more thorough description of what null models should be used with which data structures, sampling procedures, biological processes, ecs. This would aid the cross-system comparisons and users from finding spurious patterns.
Competing Interests: No competing interests were disclosed.
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard.
The paper introduces a new freeware package designed to collate existing measures of nestedness in biological samples. This is a useful capability because several different methods exist for quantifying parameters and testing significance. The paper describes a novel and efficient
... Continue reading
The paper introduces a new freeware package designed to collate existing measures of nestedness in biological samples. This is a useful capability because several different methods exist for quantifying parameters and testing significance. The paper describes a novel and efficient method for sampling the null distributions that calibrate the significance of nestedness scores. The package should interest anyone working with biological networks of bipartite data, and is conveniently available for open-source platforms R and Octave as well as MATLAB.
I have no major concerns about the conception, execution or description of the paper. It appears to me well motivated, technically sound and written with considerable clarity. The case study provides a useful illustration, though is under-developed as I will detail below and perhaps represents a missed opportunity. I found the program itself easy to use and really useful for exploring alternative measures of nestedness
The manuscript title answers to the content of the paper. The Abstract provides a clear summary, though its impact would benefit from removal of repetition. An abstract of 150-words in a single paragraph could state concisely what the need is, and how the package addresses it.
The Introduction could usefully explain the meaning of nestedness (currently in the following section) before briefly reviewing alternative methods of quantification. That review should attempt some categorisation of existing methods in one paragraph, and examples of their applications, before describing their various limitations in a following paragraph. Then say how FALCON addresses these issues.
The paper provides a clear description of the concept of nestedness and its interpretation, which is not an easy task. It would help to define ‘bipartite’ in the context of the Fig.-1 matrices, as the two dimensions that make up the matrix columns and rows. Table 1 gives shorthand codes for the various nestedness measures, though only some of these correspond to the codes for calling the measures in the program (Table 2 of the instruction guide). It would help to have a closer correspondence of shorthand with code of measures, and with the subtitles in Appendix A. Likewise for null models and Appendix B.
The Section-5 case study should take the opportunity to show readers how they can find interesting patterns in datasets by calculating nestedness, using sensible measures and calibrations. For this particular example, it would help to clarify the context by indicating that ‘IPCC’ stands for either ‘Intergovernmental Panel on Climate Change’ or ‘Independent Police Complaints Commission’. It’s not clear to me whether this hashtag was chosen purposefully to sample such different populations of Twitter users, and if so how one might interpret nestedness in the aggregate population. Any case study serves its purpose only if it is followed through all the way from motivation through to extraction of qualitative meaning from the quantitative analysis. Thus the text needs to interpret Figure 4 qualitatively, explaining the choice of measure and null model for these data, and resulting nestedness score such that the reader can see how nestedness might reveal interesting pattern in the data. It would be good to have the case-study dataset made available for users to try out for themselves.
In the case study, the textual explanation of the command box says that the program uses three null models, but as far as I can see it calls only two: FF and CC. Then, confusingly the output graphs of null distributions show only the first one: CREATEBINNULL2. Actually, the second one looks more interesting according to Table 3. These steps from input to output need more explanation. Particularly for Fig. 4 and Table 3, interpretation is not helped by the lack of correspondence between names used for shorthand (e.g., ‘SR’, ‘FF’) and code (e.g., ‘SPECTRAL_RADIUS’, ‘CREATEBINNULL2’). If correspondence is not possible in the program itself, it would help at least to have clearer titles for graphs and tables.
When using the package, I thought that the instruction guide would benefit from some tidying up. For example, it would help to tabulate all possible alternative values for each of the seven options. Null models should be presented after measures, since a null only has meaning as the baseline against which to calibrate a measure. For the R version of the program, an example script is provided to illustrate capability (examplescript.R). Its ‘TEST 2’ loads a .csv file containing a matrix suitable for nestedness analysis, but omits the specification ‘header = FALSE’. As a result, it reads the first line of the file as a header, which was surely not the intention.
Specific points that merit attention:
Last paragraph of Section 1, say: “FALCON can sort rows and columns so as to maximise nestedness regardless of the method used for its calculation.”
When referring to specific published texts, remove the superscript, to say for example (Section 4.5): “in the literature, ref 30 amongst others use 1000 null models in their ensembles, whilst ref 12 use…” etc.
Figure 4 component parts need labels (A), (B), (C). Label the axes of the matrix, at least in the legend if not in the figure itself: presumably columns for users and rows for hashtags.
Table 3, avoid vertical lines in tables. The table would be easier to read if columns and rows were switched around. Left-justify text, and use a decimal tab to align numbers in a column.
Avoid the phrase ‘As stated above’ – reorganise to state only once.
Avoid ending a sentence in a verb. The verb imparts meaning to the sentence by describing the action, so giving it early facilitates the reader’s comprehension.
Competing Interests: No competing interests were disclosed.
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard.
Alongside their report, reviewers assign a status to the article:
Approved - the paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations -
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approved - fundamental flaws in the paper seriously undermine the findings and conclusions
Adjust parameters to alter display
View on desktop for interactive features
Includes Interactive Elements
View on desktop for interactive features
Competing Interests Policy
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Examples of 'Non-Financial Competing Interests'
Within the past 4 years, you have held joint grants, published or collaborated with any of the authors of the selected paper.
You have a close personal relationship (e.g. parent, spouse, sibling, or domestic partner) with any of the authors.
You are a close professional associate of any of the authors (e.g. scientific mentor, recent student).
You work at the same institute as any of the authors.
You hope/expect to benefit (e.g. favour or employment) as a result of your submission.
You are an Editor for the journal in which the article is published.
Examples of 'Financial Competing Interests'
You expect to receive, or in the past 4 years have received, any of the following from any commercial organisation that may gain financially from your submission: a salary, fees, funding, reimbursements.
You expect to receive, or in the past 4 years have received, shared grant support or other funding with any of the authors.
You hold, or are currently applying for, any patents or significant stocks/shares relating to the subject matter of the paper you are commenting on.
Stay Updated
Sign up for content alerts and receive a weekly or monthly email with all newly published articles


Comments on this article Comments (0)