Keywords
graph theory; biological networks; network analysis; cytoscape plugin
graph theory; biological networks; network analysis; cytoscape plugin
In this section we briefly introduce the fundamental concepts that are needed to understand the principles of the software described in this article. We introduce the main theoretical concepts used to describe and analyze networks, most of which come from graph theory that is a large field containing many results and we describe only a small fraction of those here, focusing on the ones that are relevant to the study of real-world networks.
To represent a graph there are many different ways in literature. A graph is usually represented as an adjacency matrix. The adjacency matrix A of a simple graph is the matrix with elements aij, where aij = 1 if an edge between vertices i and j is present, and 0 otherwise. We note that a) for a graph with no self-edges the elements in the matrix diagonal are all zero, b) the adjacency matrix is symmetric (if there is an edge between i and j then there is an edge between j and i). In some situations it is useful to associate a weight to the edges; such weighted (or valued) graphs can be represented by giving the elements values of the adjacency matrix equal to the weights of the corresponding connections.
Network centrality measures allow categorizing nodes for their relevance in the network structure. The literature on biological networks are typically interested in the global properties of the network; in the case of centrality it is often considered from a global point of view, as for example analyzing degree or centralities distribution2–6. In BiNAT were implemented the most used network centrality measures i.e. Degree, Betweenness, Eccentricity, Closeness and Stress centrality.
The increasing availability of large network datasets, along with the progress in experimental high-throughput technologies, have promoted the need for tools that allow an easy integration of experimental data with data derived from network computational analysis. In order to enrich experimental data with network topological parameters, it has been developed the Cytoscape plugin BiNAT (Biological Network Analysis Tool).
The plugin computes several network centrality parameters, and allows the user to analyze these computational results in textual and graphical format. BiNAT identifies the nodes that are relevant from the experimental and the topological viewpoint. BiNAT is one of the few Cytoscape plugins that computes several centrality indices at once. In BiNAT the centrality measures can be easily correlated with each other, in order to identify the most significant nodes according to topological properties. Functional to this capability is the scatter plot options, which allows an easy correlation of node centralities.
Equally to other Cytoscape plugins, BiNAT (and its dependencies) must reside in the plugin directory in the Cytoscape root folder. BiNAT needs to be executed with administrative privileges to working proper. After first running, BiNAT creates three folders (binatData, binatLog and binatTemp) in the Cytoscape root directory:
in binatLog folder application log files reside in two formats (.html and .txt), both useful to monitor the proper running of all software operations.
in binatData folder generated application data reside such as: a) stats.xlsx file that contains network information (centrality measures for every nodes, network diameter, network density, node average degree, network maximal clique degree, etc). b) complexesIntersectionMatrix.xlsx file that represents the complexes adjacency matrix computed according to the number of shared nodes between complexes. c) complexesShortestPathsMatrix.xlsx file that represents the complexes adjacency matrix computed according to the shortest path among all shortest paths between two nodes that are members of the same complex. d) shortestPaths.txt file that contains all pairs shortest paths in the network, useful to accelerate many other plugin features.
in binatTemp some plugin temporary files reside such as: a) sp_*.txt files that contain all pairs shortest paths in the network. The maximal size of every sp_*.txt file is 50MB and their creation may take a long time depending on the network size. b) toResume.txt file that contains two indexes necessary to resume the process of calculating shortest paths if it has been stopped.
The idea behind the developed interface consists of a clear separation from the visualization of results and the Java classes that contain the processing logic. The structure is comparable to the MVC (Model - View - Controller) design pattern that is based on the separation of roles between the software components that interpret three major roles:
Model: application data and rules.
View: it can be any output representation of data, such as a chart or a diagram.
Controller: it mediates input, converting it to commands for the model or view.
The Controller is the key class that guides the input information flow (commands and parameters) towards the right actions to be performed.
In this section the algorithms implemented in BiNAT are introduced through a pseudocode and a comprehensive description for each algorithms. The following algorithms have been implemented: Dijkstra algorithm, Betweenness centrality, Closeness centrality, Degree centrality, Eccentricity centrality, Stress centrality and Clique Finder (Bron-Kerbosch) algorithm.
Dijkstra’s algorithm7 solves the single-source shortest path problem when all edges have non-negative weights. It is a greedy algorithm, similar to Prim’s algorithm, but the two solve different types of problems and the properties are computed in different ways. Algorithm starts at the source vertex s and grows a tree T that ultimately spans all vertices reachable from s. Vertices are added to T in order of distance i.e., first s, then the vertex closest to s, then the next closest, and so on. The following implementation (see Listing 1) assumes that the graph G is represented by adjacency lists. As already mentioned, all centrality measures available in BiNAT, excluded the Degree centrality, depend on the Dijkstra’s shortest path algorithm.
Listing 1. Pseudocode of the Dijkstra’s shortest path algorithm.
dijkstra (G, w, s) 1. initialize_single_source (G, s) 2. S <- { } // S will ultimately contains vertices of final shortest-path weights from s 3. initialize_property_queue Q 4. Q <-V[G] 5. while Q is not empty do 6. u <- extract_min(Q) // pull out new vertex 7. s <- S E’ {u} // perform relaxation for each vertex v adjacent to u 8. foreach v in Adj[u] do 9. relax(u, v, w)
The Clique Finder algorithm that we use was developed by Bron & Kerbosch (1973)8. This algorithm combines a recursive backtracking procedure with a branch and bound technique to eliminate searches that cannot lead to a clique. The recursive procedure is self-referential: finding a clique of length n is accomplished by finding a clique of length n-1 and another node that is connected to all the nodes in that clique. The branch and bound technique makes use of rules that allow us to determine in advance certain cases for which possible combinations of nodes and edges will never lead to a clique. There are three sets that are essential for this algorithm:
“potential-clique”: this is a set of nodes where every node is connected to every other node. Each recursive call will either extend this set by one node or reduce it by one node.
“candidates”: this is the set of nodes that are eligible for addition to the “potential-clique” set.
“already-found”: this is the set of nodes that have already served as an extension to the present configuration of “potential-clique” and are now explicitly excluded. That is, all possible extensions of “potential-clique” containing any point in this set have already been generated.
The algorithm operates recursively on each of the sets by generating all extensions of a given configuration of “potential-clique” that use given set of “candidates” and that do not contain any of the nodes in “already-found”, as described in the simplified pseudocode represented in Listing 2. Initially, the set “candidates” contains all the nodes in the graph and the set of “potential-clique” and “already-found” are empty. Bron & Kerbosch adopt a clever strategy to select the nodes: to choose nodes with the largest number of edges, in order to reach the branch and bound condition as soon as possible. This leads to the larger cliques being found first and sequentially generates cliques having a large common intersection. More details of this algorithm, including a more detailed pseudocode, implementation are given by8.
Listing 2. Pseudocode of the Bron-Kerbosch algorithm.
bron_kerbosch_clique_finder (potential-clique, candidate, already-found) 1. if a node in already-found is connected to all nodes in candidates then 2. no clique can ever be found (branch and bound step) 3. else 4. foreach candidate-node in candidates do 5. move candidate-node to potential-clique 6. create new-candidates by removing nodes in candidates not connected to candidate-node 7. create new-already-found by removing nodes in already-found not connected to candidate-node 8. if new-candidate and new-already-found are empty 9. potential-clique is a maximal-clique 10. else 11. bron_kerbosch_clique_finder (potential-clique, new-candidates, new-already-found) 12. endif 13. move candidate-node from potential-clique to already-found 14. endfor 15. endif
One of the most important commands in BiNAT is the one for the creation of the principal output file (in MS Excel or CSV format), in which all network nodes with all their own centrality measures defined before are listed: the ranking measure has been introduced to find a correlation between centrality measures that are in conflict with each other; it is a value ranging from 0 to 10, where highest value are received by nodes that are candidates to be considered hubs. This file creation step passes through almost all stages of operational calculus which constitute the heart of the software. The first step consists is the input of a network. The network must be in TXT format according to the TAB2 standard. The format supported until now is that adopted by BioGRID. To compute all nodes and network centrality measures, it is needed to type the “makestatistics” command in the plugin text field (please see the software manual on the official site for more information about available commands). BiNAT will then performs the following steps:
First of all BiNAT computes all pairs shortest paths in the network using Dijkstra algorithm7 (it is needed to compute almost all centrality measures);
Once obtained all shortest paths, BiNAT computes all supported centrality measures for each node in the network.
Then BiNAT assigns a ranking value to each node; such ranking is obtained calculated as the arithmetic average value of all centrality measure for each node. Once completed, all centrality measures for all nodes in the network, BiNAT computes other global measures such as the network density, the network diamenter, the maximal clique degree and much more.
Data is ready to be returned in output now. BiNAT creates the output file in the folder specified at the beginning of the operation. To create XLSX files, BiNAT uses the Apache POI libraries: Java API for Microsoft Documents. The aim of the Java POI is to manipulate various file format based upon the Office Open XML standards (OOXML) and Microsoft’s OLE 2 Compound Document format (OLE2). In short, the programmer is able to read and write MS Excel, MS Word and MS PowerPoint files using Java.
For a list of all supported command line options, please take a look at the User Manual on the plugin official site. BiNAT also provides a server mode that allows the user to fully remotely control the plugin. When the server mode is enabled, user can send commands remotely using BiNAT client available as desktop and mobile application (for Android devices only).
We tested BiNAT on Saccharomyces Cerevisiae (Figure 1) protein-protein interaction network. PPI network was extracted from BioGRID database and consist of 6,096 nodes and 214,235 interactions.

It was analyzed with information about yeast complexes provided by the Wodak Lab (Molecular Structure & Function program, Hospital for Sick Children, Toronto, ON, Canada). We first used BiNAT to compute all the centrality measures. A first overview of the global topological properties comes from the values of all centralities along with the diameter and the nodes average degree (Figure 2).
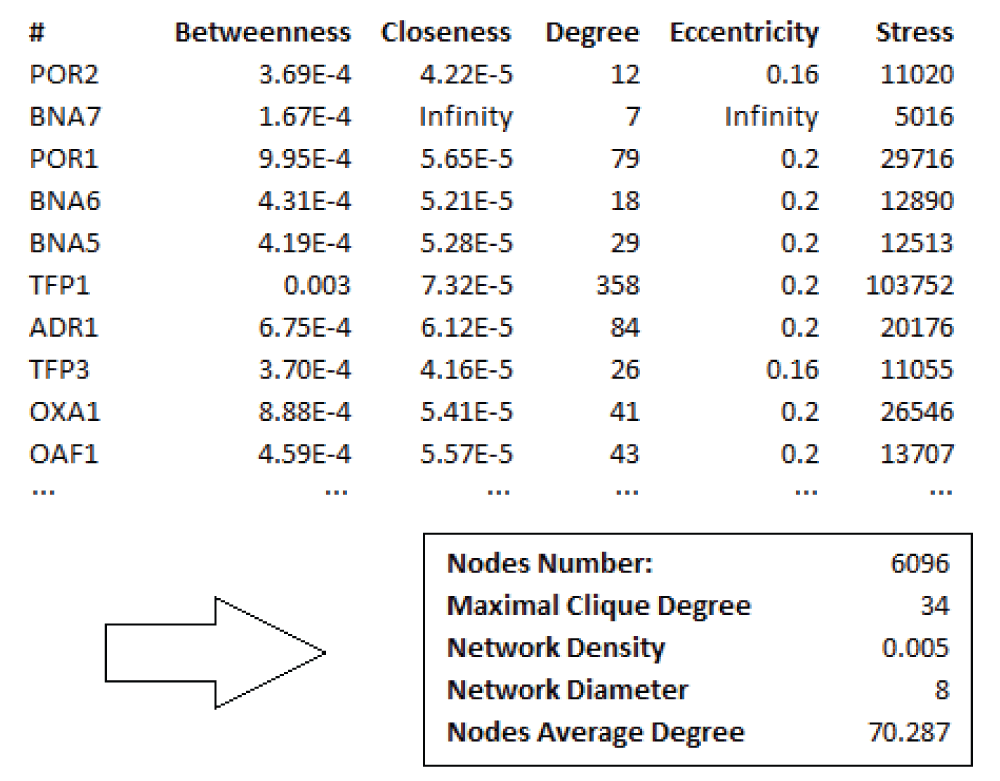
With this data and with the help of a graphical layout, we can deduce a highly connected network. The computation of network centrality measures allow us a first ranking of this network. Further analysis bases on a Gene Ontology database search, or by adding functional annotation data, may allow a deeper functional exploration of the network. The combination of BiNAT with other bioinformatics tools, such as CentiScaPe or Network Analyzer or MCODE, may help to analyze high-throughput genomic and or proteomic experimental data and facilitate the analysis process. It’s recommended to see the plugin User Manual for a step-by-step guide on how to use BiNAT and all its features.
The Cytoscape plugin BiNAT was designed to provide the user a powerful tool for an accurate analysis of networks centrality. The plugin interface is simple as a shell; a practical user manual can be downloaded from the official web site http://dmb.iasi.cnr.it/binat.php.
BiNAT plugin has been accepted by the Cytoscape community and is actually available for the download on the official plugins repository for the 2.8.3 version of Cytoscape.
Software available from Cytoscape Plugins repository: http://chianti.ucsd.edu/cyto_web/plugins/ and search for binat
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)