Keywords
Joker Tao, NoSQL, Cloud, Database, Life science, Physical data table, Virtual data table, RDBMS
Joker Tao, NoSQL, Cloud, Database, Life science, Physical data table, Virtual data table, RDBMS
Taking the referees’ advice:
We extended the Introduction chapter to clarify the problems our proposed method tries to solve.
Database designing rules applied by us and more examples were added to the method chapter in order to describe the method more clearly.
In the Introduction and Discussion we highlighted the importance of the developed method and how it improves the state of the art.
Dataset 1 has been added to show the data storage structure in JT logic based databases.
To read any peer review reports and author responses for this article, follow the "read" links in the Open Peer Review table.
Databases which store and manage long-term scientific information related to life science are used to store huge amount of quantitative attributes. This is specially true for medical databases1,2. One major downside of these data is that information on multiple occurrences of an illness in the same individual cannot be connected1,3,4. Modern database management systems fall into two broad classes: Relational Database Management System (RDBMS) and Not Only Structured Query Language (NoSQL)5,6. The objects in the relational database are grouped based on their type, format and number of identical attributes. The data tables in the relational databases are normalized. Join operations are used in the relational databases when combining information based on a matching value for a primary key and foreign key across multiple data tables. In several cases the query became slower in the relational database because of the larger schema and increased number of data tables that need to be joined7. A significant amount time is spent by database experts developing a common structure for the data coming from different sources and not on the analysing processes themselves. The introduction of a new entity attribute requires the introduction of additional data tables or modification of the existing data tables. In the NoSQL databases, the development such as creating simple query is more complex because there is no standard query language and there are limits to the operations (for example, there is no join operation in MongoDB)7. The primary goal of our developed method was to store and manage each data in a single data table while the data handling processes can be completed by SQL commands. Our method may be useful in an environment where the schema is constantly changing as a result of adding new devices or tools that generates new types of attributes. This solution contributes to the interoperability between the relational and NoSQL systems where converting application usage is unnecessary. JT can be defined as a NoSQL engine on an SQL platform.
The technical environment is Oracle Application Express (Apex) 5.0 cloud-based technology. Workstation: OS (which is indifferent) + internet browser (Chrome). Firstly, we demonstrate an example for a simplified relational database (Figure 1). Following this, the presented data tables have been modified step by step. At the end of these steps, each data from the presented database will be stored in a single data table using JT logic.
The database designing rules we applied can be summed up as follows: .
Rule 1: Creating a data table with four columns
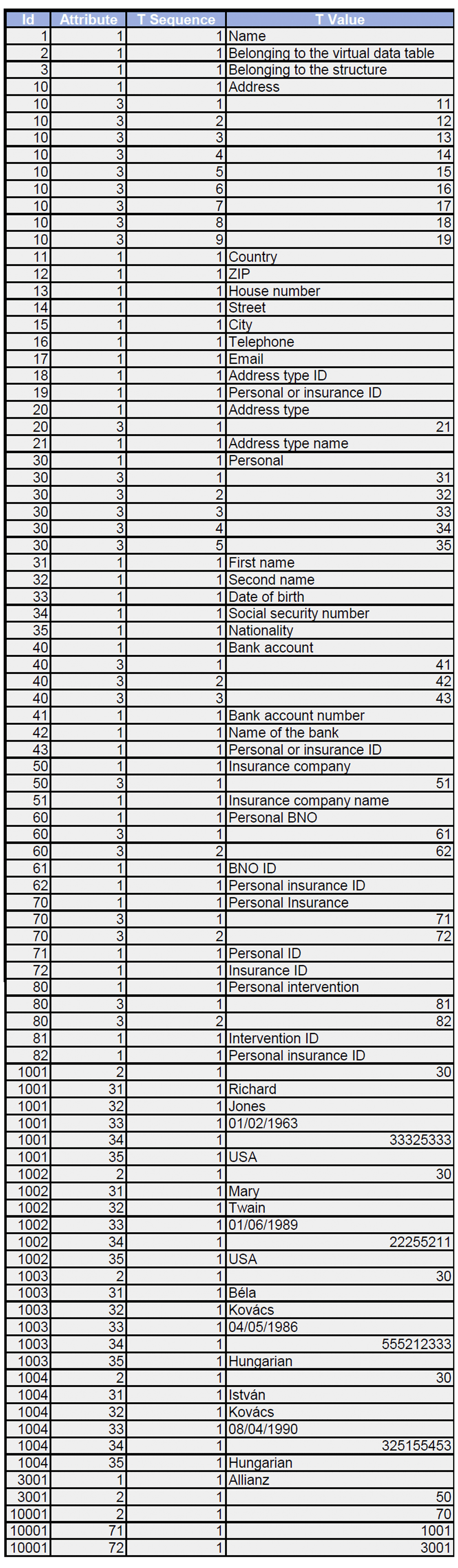
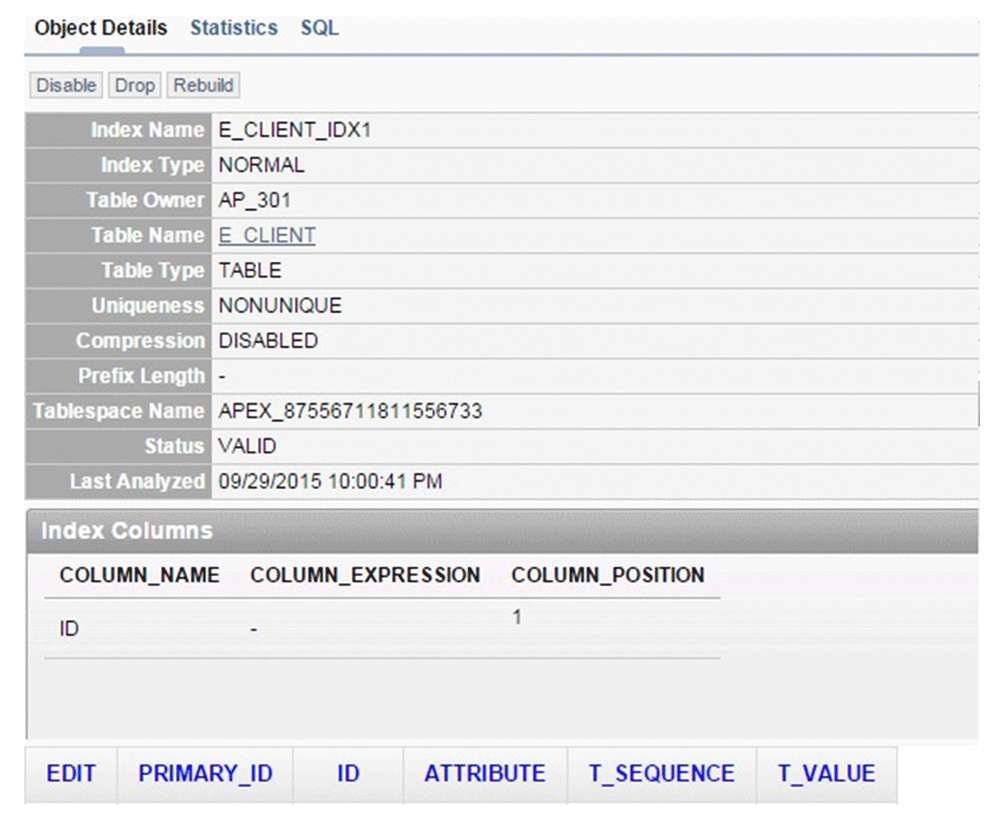
Specification of the physical data table structure was determined with -ID (num) as the identifier of the entity, which identifies the entity between the data tables (not only in the given data table); -ATTRIBUTE (num) is the identifier of the attribute; -SEQUENCE (num) which is used in the case of a vector attribute; and -VALUE (VARCHAR2) which is used for storing values of the attributes.
Note: The codes which are stored in the Attribute column are also defined, sooner or later, in the ID column. At that time the attribute becomes an entity. In every case, the subjectivity determines the depth of entity-attribute definition in the physical data table.
Rule 2: Defining basic relationships
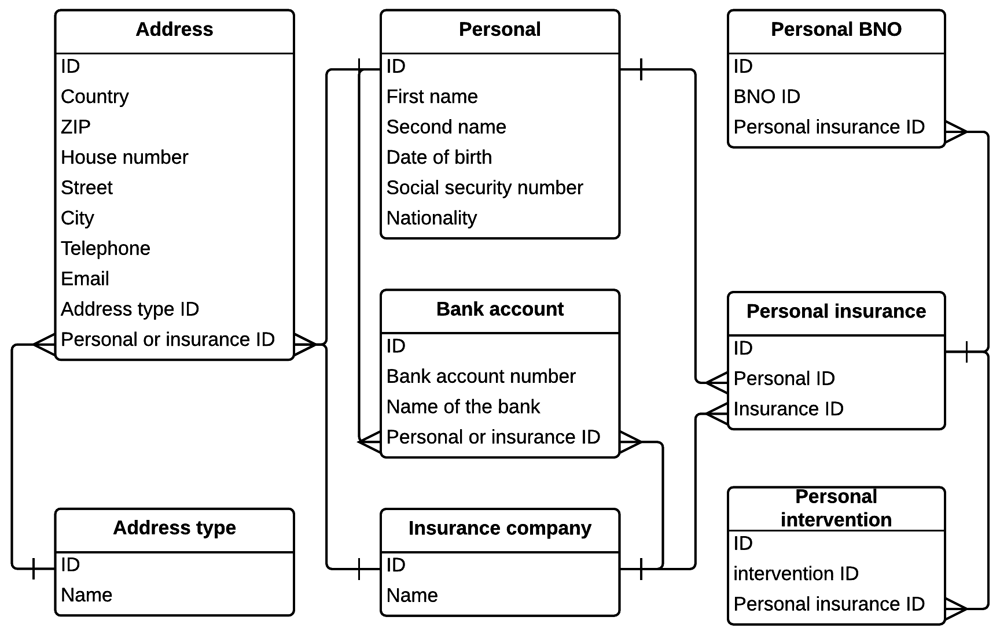
The first step is the technical data storage. In Figure 2, basic relationships will be defined which describe the names of the attributes (can be interpreted as columns in the usual relational databases), type of relationships (belonging to the structure) and virtual data tables (can be interpreted as "belonging to the data table" in the usual relational databases). The Name is defined as an entity and an attribute at the same time as the code 1 appears in both columns in the ID and in the Attribute as well. Following this two entities are defined: the "Belonging to the virtual data table" with ID=2, and "Belonging to the structure" with ID=3. In these records the same code 1 appears in the Attribute column which means we named the entities (Name was identified with code 1). With this technique we can name the new entities in the database. Once the code appearing in the ID column is stored in the Attribute column, the data will be interpreted as an attribute (like in the case of Name).
Rule 3: Entity storage
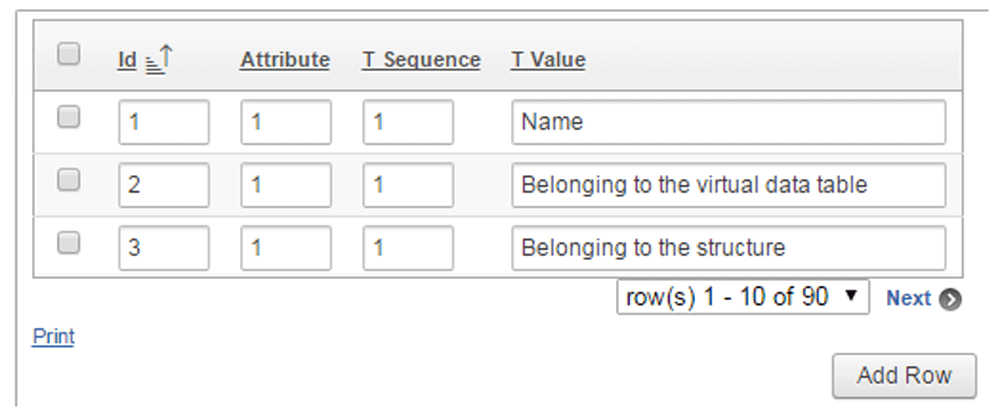
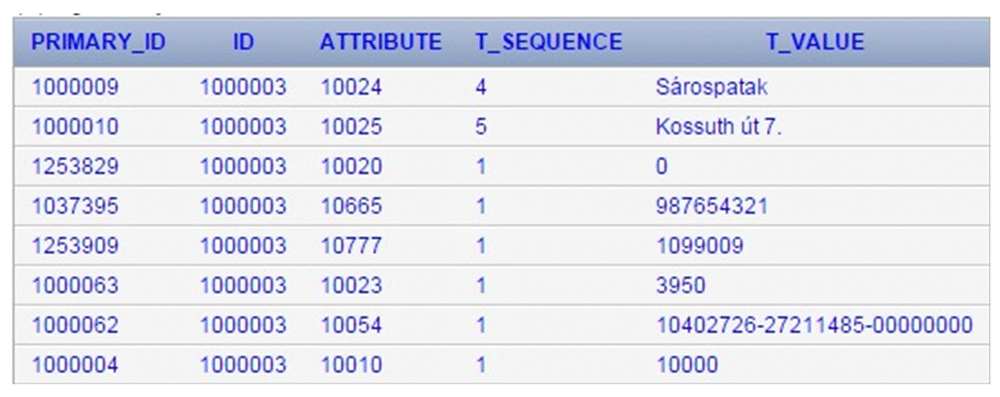
An entity is defined with the records having the same ID values (Figure 3). These identifiers can be any natural number that has not already been used in the ID column. In this example we introduced the Address. The records with the ID=10 identify the Address as an entity. The Address was determined by the previously defined attributes: Firstly we named this entity with the Attribute=1 that means Name. Secondly the "Belonging to the structure" was clarified (with Attribute=3). We introduced some values of the Address in a list. Every record of the Address entity belongs to different structures in this example. The TSequence column is used to make a list in this concept.
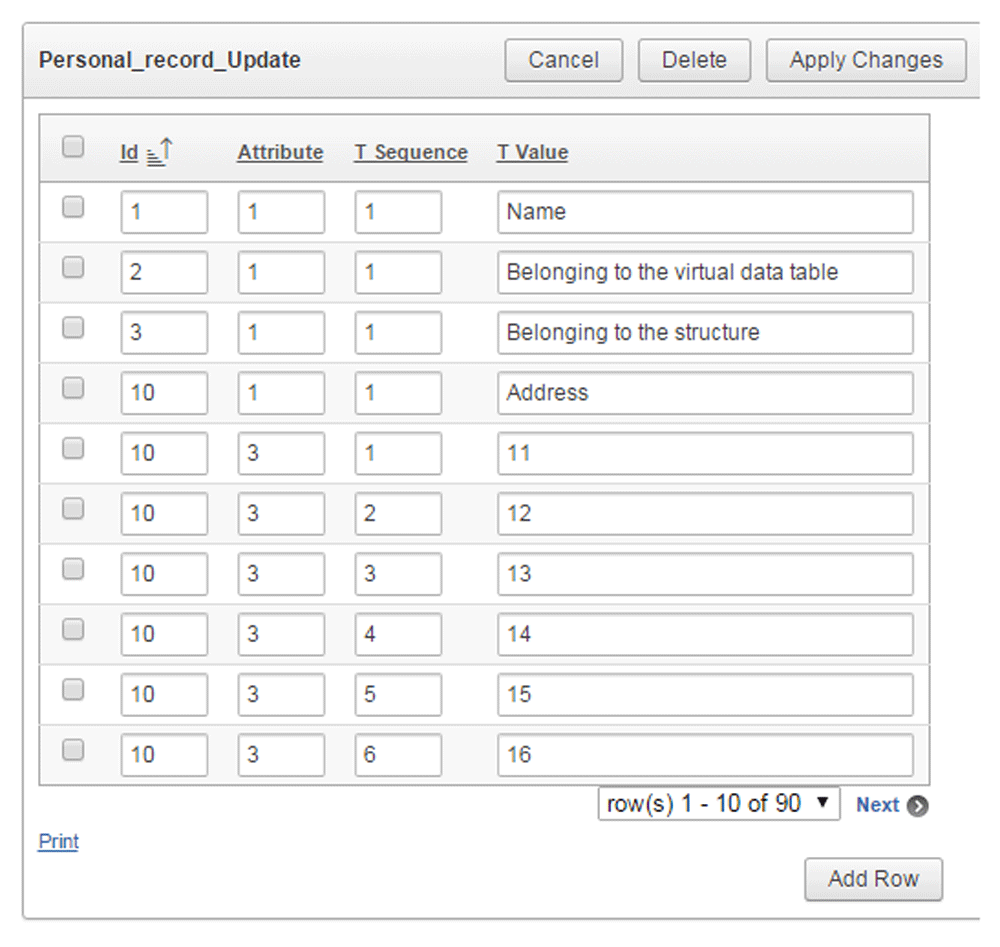
Rule 4: Attribute storage
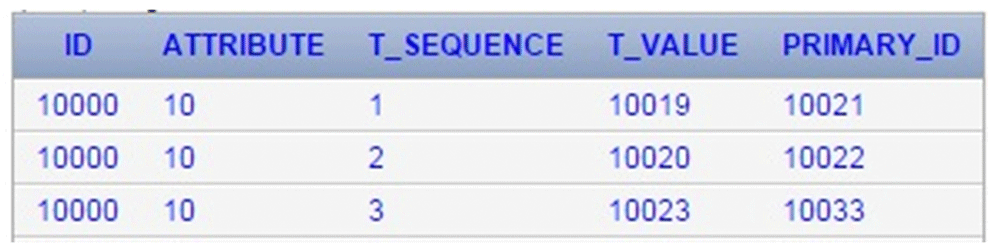
The codes witch were previously introduced into the ID column, now are transferred to Attribute column (Figure 4). The values of these identifiers can be any natural number that has not already been used in the Attribute column.
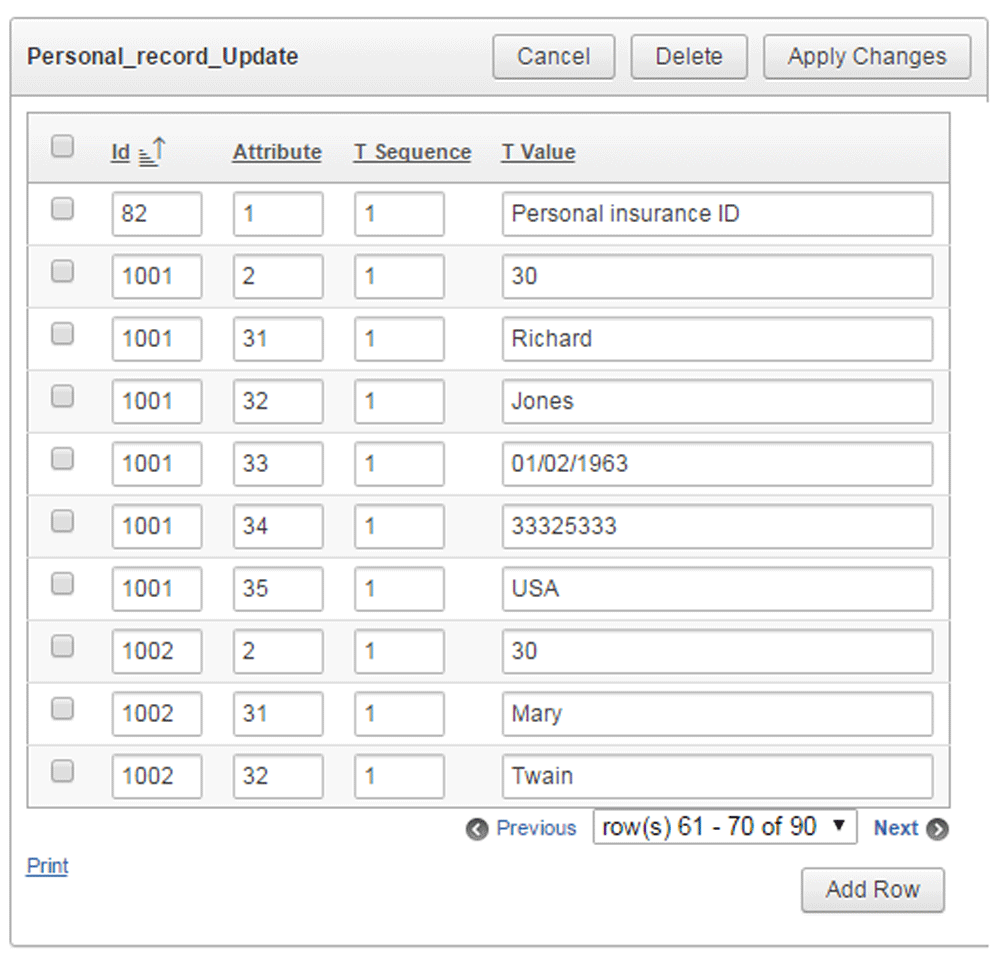
Each attribute is identified in the Attribute column. In this example the following contexts can be read out related to the entity identified with ID=1001: -The value of the "belonging to the virtual data table" attribute (code 2) is Personal data table (code 31); -First name (code 32) is Richard; -Second name (code 33) is Jones; -Date of birth (code 33) is 01/02/1963; -Social security number (code 34) is 33325333; -Nationality (code 25) is American. The codes (namely 2,31,32,33,34,35) have to be stored sooner or later in ID column. At that time these attributes become entities and are defined by other attributes (eg. the "name" of the entity identified with 82 ID value is Personal insurance ID; the attribute called "name" was defined earlier in ID column see Figure 3 and now it is applied in the attribute column as an entity attribute).
Rule 5: Defining data tables
The attributes are assigned to each virtual data table using a previously introduced attribute called “belonging to the virtual data table”. In the usual relational databases, the entities are grouped by different data tables. For the same purpose, we introduced "virtual data tables" in our single big data table. The code 2 in the Attribute column identifies the belonging to the table. The different entities that belong to the same data table have to own the same value in the Tvalue column (Figure 5).
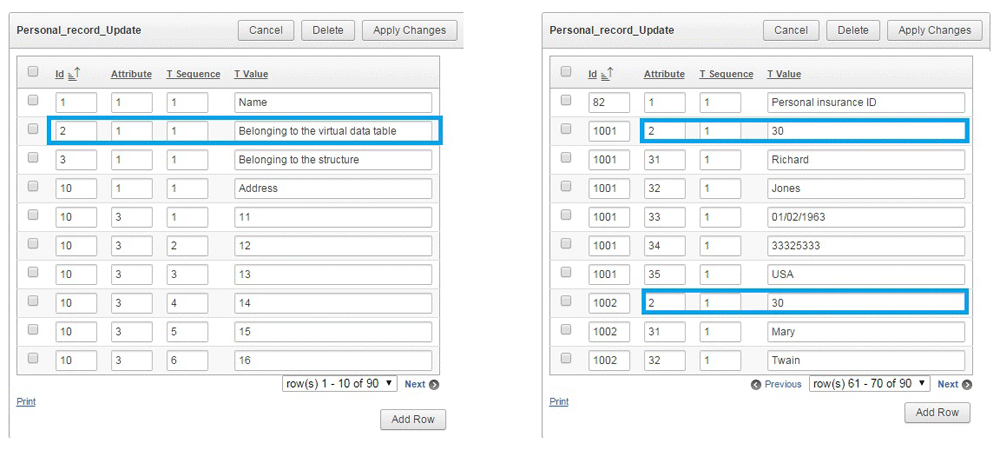
From this example, the following context can be read out: The entities identified with 1001 and 1002 ID values belong to the same virtual data table.
With these steps the developer can design one data table to store each entity, attribute and value in a relational database. Obviously, the user doesn’t see these virtual tables. These appear for the user in a form as usual data tables in the Oracle Apex platform. Only the names of the attributes appear for the user instead of their codes. A query can be created in the same way like in any relational database. In the background: the attribute of the given virtual data table is queried. This attribute is array-type and means increasing number of TSequence. The user can see only the names of the TSequence and TValue (Name of the attributes) like in the following example (Figure 6).
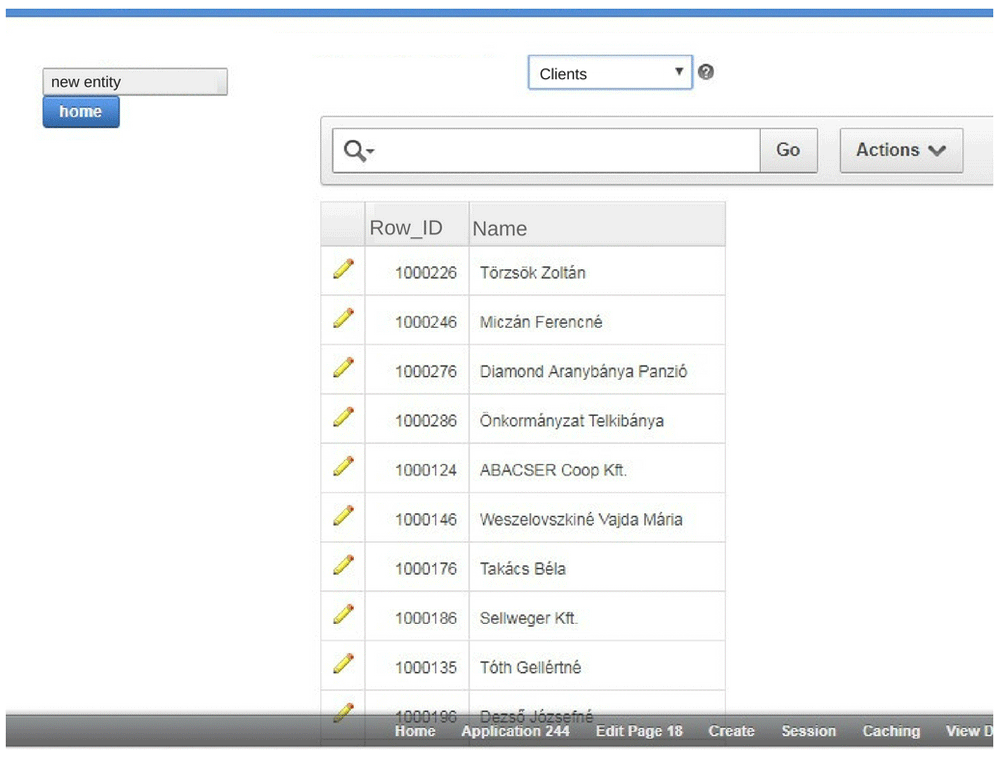
Oracle Apex automatically supply each record with row IDs. The above described method can be applied manually. For the automatic conversion (for primarily non cloud-based applications) we created a Java code below 7:
public static String getEntityName ( )
throws Exception
{
Connection conn = broker.getConnection ( );
PreparedStatementpstmt =
conn.prepareStatement ("select *from joker");
ResultSetrs = pstmt.executeQuery ( );
inti = 0;
while (rs.next ( )) {
i++;
}
System.out.println ("number of records:" + i);
broker.freeConnection (conn);
return " ";
}
public static void insert JokerRow
(Integer GROUP_ID, Integer UNIQ_ID,
Integer FIELD_ID, Integer ARRAY_INDEX,
String SEEK_VALUE, String FIELD_VALUE)
throws Exception {
if (GROUP_ID == null) pstmt.setNull (1, 2);
else pstmt.setInt (1, GROUP_ID.intValue ( ));
if (UNIQ_ID == null) pstmt.setNull (2, 2);
else pstmt.setInt (2, UNIQ_ID.intValue ( ));
if (FIELD_ID == null) pstmt.setNull (3, 2);
else pstmt.setInt (3, FIELD_ID.intValue ( ));
if (ARRAY_INDEX == null) pstmt.setNull (4, 2);
else pstmt.setInt
(4, ARRAY_INDEX.intValue ( ));
if (SEEK_VALUE == null)
pstmt.setNull (5, 12);
else pstmt.setString (5, SEEK_VALUE);
if (FIELD_VALUE == null) pstmt.setNull
(6, 12); else pstmt.setString
(6, FIELD_VALUE); pstmt.execute ( );
}
public static void readFile ( )
throws Exception
{
File f = new File ("data.txt");
BufferedReaderbr = new BufferedReader
(new FileReader (f));
while (br.ready ( )) {
String line = br.readLine ( );
int GROUP_ID = Integer.parseInt
(line.substring (0, 10));
int UNIQ_ID = Integer.parseInt
(line.substring (11, 21));
int ARRAY_INDEX = Integer.parseInt
(line.substring (22, 32));
String FIELD_VALUE = line.length ( ) > 32 ?
line.substring (33, line.length ( )): " ";
insertJokerRow (Integer.valueOf (GROUP_ID),
Integer.valueOf (UNIQ_ID), null,
Integer.valueOf (ARRAY_INDEX),
null, FIELD_VALUE);
}
br.close ( );
}
The resulting table structure is called JT structure (Figure 7). The result from automatic conversion is a physical data table which uses 6 columns. In cloud, Oracle Apex automatically add row IDs and we introduced "belonging to the virtual data table" attribute instead of Group IDs. In cloud we prefer to use only 4 columns to store each data in a database.
The JT logic-based databases can be defined using primitive relation scheme known as a three-tuple according to Paredaens (1989)9 concept:
PRS = (ω,δ, dom)
where
ω is a finite set of attributes, in our case, it is the set of entities from the ATTRIBUTES virtual data table.
δ is a finite set of entities, in our case, it is a set of virtual records.
dom : ω → δ
is a function that associates each attribute to an entity; it can be interpreted as a predefined set of attributes called "1:N registry hive". This function is used to maintain the entities in the virtual data tables.
A relation scheme (or briefly a relation) is a three-tuple RS=(PRS,M,SC)
where
PRS is a primitive relation scheme; M is the meaning of the relation. This is an informal component of the definition, since it refers to the real world and since we will describe it using a natural language. SC is a set of relation constraints. From the JT physical data table, the following definitions can be read out:
• Virtual record is set of the physical records which have the same ID value.
• Virtual data table is set of the virtual records which have the same value of the "belonging to the virtual data table" attribute6.
Thesis: In the JT structure, each attribute needs only one index for indexing in the database.
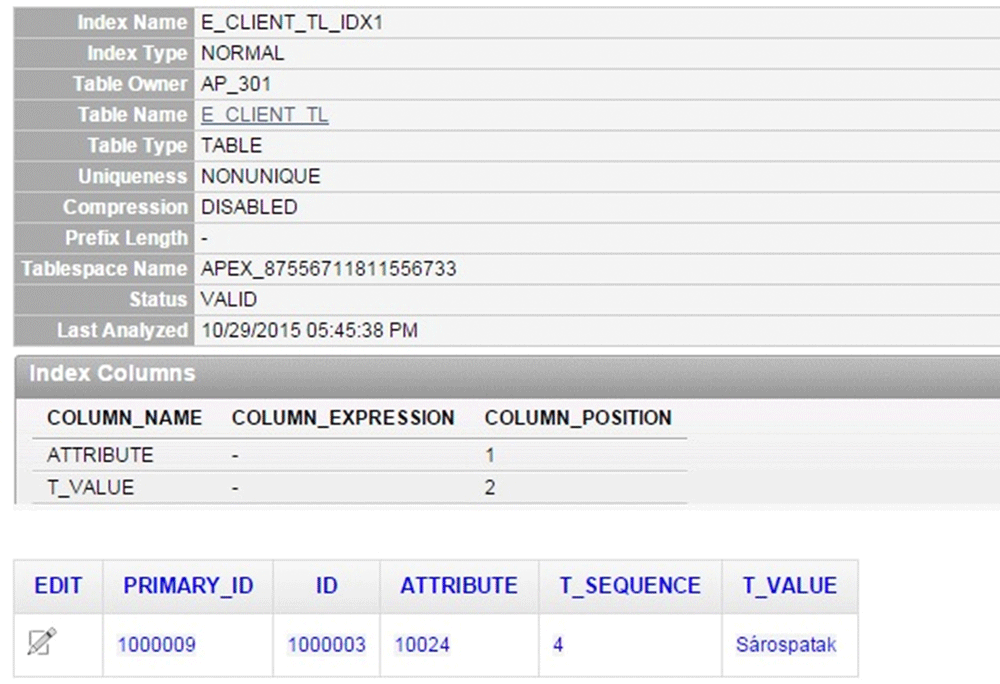
>Proof using mathematical induction: It is obvious the statement is true for the case of one record stored in a data table (according to the RDBMS structure where the developers use more indexes to indexing more attributes). In this case the data table appears as shown in Figure 8. Index= attribute (num) + value (varchar 2) In view of entity, an ID (numerical) index is also used in JT logic-based systems. This ID does not depend (no transitive dependency) on any attribute. Thus, the entities of the virtual data tables meet the criteria of the third normal form (Figure 9).
The modes of the expansion of a data table are: -input new entity (Figure 10); -input new attribute (Figure 11); -input new virtual data table (Figure 12).

The indexing is correct in case of n+1 record expansion also. With JT logic the user is able to use only one physical data table to define each virtual data table in a database. Therefore, since only one index is required to index each attribute, the statement of the thesis is true in every case of the JT logic-based data table according to the principle of mathematical induction below. Thesis: For n=1 ergo;
1 + 2 + .. + n = n ∗ (n + 1)/2
substituting one into the equation we get :
1 = 1 ∗ (1 + 1)/2
result of the operation is 1=1, that is, the induction base is true.
Using proof by induction we can now show that this is true for the following equation:
n = k where k is a optional but fixed natural number. Therefore, we know that the following operation is true:
1 + 2 + .. + k = k ∗ (k + 1)/2
Finally using n=k+1 we can prove our assumption to be true:
1 + 2 + .. + k + (k + 1) = (k + 1) ∗ (k + 2)/2
The above induction proof shows:
1 + 2 + .. + k + (k + 1) = k ∗ (k + 1)/2 + (k + 1)
Conducting the mathematical operations we obtain the following:
1 + 2 + ..k + (k + 1) = (k ∗ ((k + 1)/2) + 2 ∗ (k + 1))/2 =
(k ∗ k + k + 2k + 2)/2 = (k ∗ k + 3k + 3)/2
Conducting the mathematical operations on the other side we obtain the same:
(k+1)∗(k+2)/2 = (k∗k+2k+k+2)/2 = (k+k+3k+2)/2
Thus, the induction step is true. Given that both the induction base and the induction step are true, the original statement is therefore true. In the present study, we explained the JT data storage logic. In our other study we focused on the query tests. Our previous results8 show that from 18000 records the relational model generates slow (more than 1 second) queries in Oracle Apex cloud-based environment while JT logic based databases can remain with the one second time frame.
Using the developed database management logic, each attribute needs only one index for indexing in the database. JT allows any data whether entity, attribute, data connection or formula, to be stored and managed even under one physical data table. In the JT logic based databases, the entity and the attribute are used interchangeably, so users can expand the database with new attributes after or during the development process. Our solution provides three time saving benefits. Firstly it improves the query time over large amounts of data. Secondly it reduces development time for integrating data from various sources. Finally it removes the need for adding or modifying data tables with the addition of new attributes.
With JT logic, one physical data storage is ensured in SQL database systems for the storage and management of long term scientific information (Dataset 1).
Figshare: Data storage structure in JT logic based databases. doi: 10.6084/m9.figshare.3119086.v110
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)