Keywords
Semantic annotation, Semantic meta-modelling, Semantic mediation, Interoperability, Linked open data, Semantic web, Artificial intelligence, Scientific workflows
This article is included in the Agriculture, Food and Nutrition gateway.
Semantic annotation, Semantic meta-modelling, Semantic mediation, Interoperability, Linked open data, Semantic web, Artificial intelligence, Scientific workflows
In an increasingly connected world, the value of information depends not only on the ability to use it for the purposes for which it was collected, but also of reusing and linking it within an expanding information landscape. The term interoperability refers to the ability of information to be reused and linked across and beyond the institutional and disciplinary contexts where it originates. In recent years, much attention has been paid to interoperability, not only in empirical science, but also in sectors such as government, industry, the military, policy making and information management.
Disciplines emphasizing the study of information in a variety of sciences (e.g. bioinformatics, ecoinformatics, geoinformatics) have emerged to focus on reusability and integration of data artifacts and models. Reusability, versatility, reproducibility, extensibility, availability, and interpretability of information were identified as key requirements for sustainability1. Wilkinson et al.2 outlined the FAIR principles for data stewardship and management, calling for Findable, Accessible, Interoperable, and Reusable scholarly data publication. In practice, these goals can be enabled in different ways, with an exact interpretation that depends on the application. The most demanding interpretation of the FAIR principles can be seen as the one sought in support of the Linked Open Data paradigm3, in which information can be found, retrieved, linked and operated upon in the ultimate “machine actionable” way: unsupervised and automated, so that distributed computational workflows and models can be not only built and run, but also discovered on distributed repositories with negligible risk of misalignments. We refer to this interpretation as FAIR+, where the “I” in FAIR is rigorous enough to be trusted for automated, unsupervised linking in model and data workflows. A corollary requirement of FAIR+ is the need for information products to carry enough metadata to allow ranking of multiple candidates for linking, in order to choose the one most appropriate for the context of use.
The work presented here is part of a wider investigation on a methodology we call semantic meta-modeling (SMM), which enables the definition and execution of potentially complex, distributed scientific computations (scientific workflows4), based on automated semantic inference and powered by FAIR+ interoperability. In SMM, data and models can be (1) discovered on linked repositories based on semantics alone; (2) ranked for appropriateness to the intended context of use; and (3) assembled automatically into coherent, working scientific workflows. The authors, in collaboration with others, have been working on SMM for about a decade and produced a proof-of-concept software stack, named k.LAB, which operationalizes the approach. The first large-scale project building on the SMM paradigm, ARIES (ARtificial Intelligence for Ecosystem Services:5), has provided the primary rationale and testing ground for the development of SMM. The ARIES project implements a distributed semantic web platform for ecosystem services6 modelling, where users are presented with the result of computing scientific workflows built automatically as a response to conceptually stated queries (e.g. “observe carbon sequestration in year 2010 in the Danube watershed”). In this article, first in a series of planned contributions illustrating the different aspects of SMM, we describe the semantic principles and methods that underlie and enable interoperability in the approach, incorporating the feedback of ~15 researchers and ~150 ARIES modelers since 2007. Further contributions will expand on aspects of SMM not described here, in particular (1) assembling and running model workflows, (2) the details of the software implementation, and (3) the community process that has allowed us to build a distributed base of semantically annotated informational resources.
The vision of a Semantic Web7,8 brought semantics to the foreground as an instrument to integrate diverse, independently developed information. The use of digitally stored ontologies (formal vocabularies paired with logical axioms describing their relationships and intended meaning9) has since become commonplace for annotating informational assets, i.e. adding concepts from ontologies to the associated metadata to enable their integration and reuse (e.g. 10,11). Research and progress in ontology-mediated interoperability have been significant, and interest in it remains high. Yet, the promise of semantic annotation has often been disappointing in practice, as describing the conceptual underpinnings of information in a way that is complete, consistent and understandable across disciplines and communities has proven difficult and elusive. Attributing stable, reliable and shared meaning to information is difficult because of a lack of accepted best practices, confusion about the phenomenological nature of observed entities and attributes, lack of accepted rules on how to choose, specialize and connect concepts, among other inevitable logical challenges. The result has been a confused landscape of mixed, incompatible attempts, which Goguen12 described as “… the creation of a constantly shifting foreground and background, with the latter being called ‘context’”.
Ontologies for science come in many varieties. Foundational (also upper or reference) ontologies aim to provide philosophical foundations upon which to build lower level, domain-specific ones. They describe abstract, high-level concepts with the aim of establishing foundational logic for the definition of domain-specific concepts in derived ontologies13. For example, they may define the difference between abstract and concrete or establish the logical underpinnings of spatial, temporal, or part-whole relationships. Well-known foundational ontologies include DOLCE14, BFO (15, also see 16), and more comprehensive efforts like SUMO17, endorsed by the IEEE. Foundational ontologies have been successfully used and some have seen relatively broad adoption, but due to their high abstraction they cannot alone solve the issue of “what is what”, aside from providing a base for more specific domain ontologies (see below).
A second class of conceptualizations, observation ontologies (e.g. OBOE18, Ο&Μ19), also includes high-level concepts, but uses the notion of observation as the main device to introduce semantics, focusing on the “how” of observation rather than the “what” of phenomena. Emphasis is given to aspects such as the type of observation (e.g. measurements vs. rankings vs. classifications) and their use context. Observation ontologies thus try to occupy a foundational niche without committing to a specific phenomenology. Observation ontologies have been relatively successful in terms of adoption, but due in part to the lack of a phenomenological underpinning they cannot guide investigators in choosing appropriate observables, nor, by themselves, guarantee any of the FAIR principles for interoperability.
Domain ontologies, in contrast, describe specific areas of interest. Although in principle they should be used in conjunction with foundational ontologies, they are typically produced to serve the needs of a specific community, and are seldom committed to interoperability with ontologies from other domains13. The interoperability enabled in such a situation is primarily syntactic (“we use the same vocabulary, even if the semantics are not well thought out”) and therefore limited to users of the same ontology. Commonly these are formed as taxonomies, using a hierarchy of specialization (is-a relationships, for example: Precipitation is-a AtmosphericPhenomenon) to organize and systematize the terms used within the communities endorsing their development. Examples abound in various domains, including earth and environment: for example, SWEET20, ENVO21, SPAN/SNAP22, Gene Ontology23, and PlantOntology for plant anatomy and morphology24. Some of them, such as the Gene Ontology23, have been highly successful; yet the terminology is easily drained of meaning when confronted with other disciplinary contexts that use the same terms differently. For example, a crop is, to an agricultural economist, the agricultural product that reaches the market, possibly further processed after harvest, while to an agronomist the same term refers to the producing plant species. In general, domain ontologies commonly strive to endorse the term usage that is most popular in a community; this is both the reason for their success within those communities and their primary limitation.
Large investments have been made in developing controlled vocabularies to describe and discover artifacts of interest for specific disciplinary sectors, meant to facilitate annotation and sharing of information objects. Controlled vocabularies are typically domain-centered, with little or no pretension of phenomenological adequacy, but have strong links to the culture, language and applications in their community of origin, usually endorsing terms and assumptions that are best recognized in a community of reference. When formally expressed, their structure is often inspired by organizational, rather than logical, reasons. Many high-adoption examples exist, including e.g. AGROVOC25 and CABT26 for agriculture, CUAHSI for hydrology27, and MESh for medicine28. Generally, vocabularies contain a large number of terms (e.g., for taxonomic or chemical species of interest), are often multilingual, and can grow rapidly with use, while, by contrast, ontologies strive for minimality and robust logics. The differences between ontologies and controlled vocabularies are often misinterpreted, and in common practice the terms are sometimes used interchangeably.
Exploring ontology repositories, such as the OBO Foundry29, immediately shows that notable inroads have been made in both fundamental and domain ontologies, and that efforts to produce multi-domain conceptualizations based on common semantics are made regularly. Despite these attempts, duplications, ambiguities and inconsistencies continue to hamper the development and adoption of semantic annotation standards in practitioner communities. With the current state of the art, and with the semantic web community seemingly more interested in enabling technologies than in the conceptual aspects of interoperability, FAIR+ interoperability remains all but impossible, perhaps aside from within very restricted communities. In our view, a major need for progress towards this goal is a solid, uncontroversial phenomenological base, i.e. the basic semantics for the types of phenomena and entities that can be understood by human observers. This phenomenology needs to be general enough to work across domains and worldviews. Formalisms and toolsets must be built to support it, to ease the specification of domains and allow for extension, while enforcing a consistent design discipline. We need clear best practices for specialization and connection of terms, and guidelines on how to integrate always growing, and potentially infinite, domain content from vocabularies without breaking the logical integrity of the resulting annotations. We start our discussion by focusing on the definition and preconditions of interoperability itself, before illustrating the details of the approach we have found useful as a possible starting point towards FAIR+ interoperability.
In this article, we are concerned with the process of creating informational artifacts describing an observable concept in a chosen context, to provide evidence for a scientific deduction or computation. By observation we refer any artifact that is resolved from the perspective of a scientific process, i.e. can be used without requiring any further observation. Observations in this sense are commonly called “data”; yet, this term can be ambiguous with respect to the semantics of the observables involved, as we will explore later.
Definitions for interoperability vary by purpose, and while emphasis is sometimes given to formats and protocols for encoding and transmission (syntactic), legal compatibility (i.e., copyright and licenses) or organizational aspects (e.g., openness and purposes of the data), most definitions involve semantics - the meaning of what the information represents. The most rigorously structured information, such as scientific data and models, present the most stringent challenges in establishing semantic equality. Interoperability in such situations concerns links between two informational endpoints: for example, finding data to link to model inputs, or linking the outputs of one model to the inputs of another, so that a single computational chain can be established without fear that its results will be invalid. We term observations compatible to refer to this definition of interoperability between two informational endpoints (we will provide a more formal definition in Section 2.6).
We maintain that this kind of information alignment has three nearly independent semantic dimensions: semantics of the observable, the observation and the context.
Observable semantics describes what observations are about: physical objects, events, processes, agents, or characteristics that may be “observed” or measured. The human observer recognizes relevant observables, e.g. elevation (a quality pertaining to a location on Earth), households (subjects, part of villages or cities), or surface water flow (a process observable in watersheds). Much of what we call “data” consists of observations of qualities; their inherent subjects (e.g., the location on Earth whose elevation we observe) are often specified indirectly or implicitly. In order for observations to be made, and for their interoperability to be possible, it is crucial that such identities are fully specified and unchanging. For two observations to be compatible, their observables must be described by the same concept.
If a physical object, event, process or relationship can be simply acknowledged to exist in a context of interest, qualities, such as the elevation of a mountain or the temperature of a body, can only be observed indirectly, i.e. by comparison with reference observations. Units of measurement, currencies, rankings and classification systems define the ways human observers quantitatively or qualitatively describe such observations. Observation semantics describe how the observation activity is carried out, detailing the choice of reference metrics to ensure that a state can be understood and mediated. Mediation between different observation semantics is often possible, sometimes exactly (units of measurement, typically converted with negligible loss of precision), sometimes approximately (prices in different currencies can be more roughly compared by adjusting for inflation and purchasing power) and sometimes hardly (e.g. different land cover classifications systems are often extremely difficult to mediate). To be assessed for compatibility, qualities need the full statement of how they are observed; mediation operations may be necessary to harmonize two observations before computation involving both can take place.
Observation always happens in a context, providing observables with a when and a where. The context is usually chosen a priori by the actor who created the original artifacts, and may differ, subtly or greatly, between two compatible observations. Just like the scale of a geographical map determines what entities are visible in it (urban streets disappear in a 1:2,000,000 map), certain observables only come into focus at a given geographical scale, and certain phenomena emerge only at a given temporal scale. Context semantics describes these aspects for an observation. While differently scaled observation can be mediated to some extent through aggregation or propagation (with loss of information), scale also reflects deeply on semantics; large scale shifts will determine incompatible semantic misalignments, with (e.g.) uncountable processes becoming countable events when their time scale is changed beyond a threshold. For example, lightning is seen as an event by a meteorologist and as a process by a high-energy physicist; subjects, e.g. the microorganisms in a lake, become visible only through qualities (the color of the lake) over a spatial extent that makes the observer lose sight of them. For this reason, scale is key to establishing meaning in more ways than usually recognized; scale depends entirely on the chosen observation context, therefore on the human decision of what to observe. The semantics of scale largely deal with space/time, and as such, can be formalized independently from the observables’.
The ability to accurately characterize semantics along observable, observation and context dimensions addresses the interoperable and reusable FAIR criteria. Semantic specifications can be rewritten into queries that select interoperable counterparts for an observation, addressing the findable and accessible requirements. If queries embodying all three dimensions can be executed and the resulting observations can be ranked for appropriateness, unsupervised linking becomes possible. While observation and context semantics are relatively well-understood, the characterization of what things are - observable semantics - remains difficult and uncertain, even with increasing investments in ontologies and vocabularies and an engaged community behind the current state of the art.
The rest of this article details our approach to building foundations for FAIR+ interoperability through semantics, using examples. We describe a conceptual framework and examples of reasoning and specifications to support the characterization of observable semantics, resulting from field-testing in years of initial application, followed by a discussion of goals already achieved and those that remain. Here, and in all applications of these principles and methods, we argue for SMM as a driver for a semantics-first workflow, where the lifecycle of information begins, before data collection or model development, with the understanding of semantics, which in turn guides data collection, organization and processing up to eventual documentation, storage and curation. This contrasts with the more commonly adopted annotation approach10 where data represent the first-class artifacts, collected and stored with a logic dictated primarily by practical constraints, and semantics may complement the artifacts “after the fact” to suit the data to specific applications.
Semantics starts with the act of cataloguing observed reality into classes that can be referenced and communicated. Terms describing commonly acknowledged classes of physical entities (such as persons or objects) are complemented through inference, comparison, association and imagination, to encompass objects, events, processes and relationships that may not be directly perceived by the senses, but still appear in human experience, thought and communication. Such observable entities can be arranged along a small number of fundamental phenomenological categories (for example physical objects, processes, characteristics or events) that determine how they can be described, observed, modeled and represented. Our perception of space/time is crucial to the process of organizing reality into communicable observables, as the “resolved” units of space and time determine how we classify. This is particularly important when science’s exacting descriptional needs of come into play: as described previously, spatiotemporal resolution influences an object of study’s perceived structural or functional character, and shifting resolution or extent can fundamentally alter an observable’s perceived category. It follows that interoperability can exist in a conceptualization, as long as the boundaries of stability of meaning for all concepts with respect to their fundamental phenomenology are stable. Scale, commonly defined as the choice of resolutions and extents through which we make observations of the world, binds the observables of informational artifacts to precise phenomenological categories, establishing boundaries of validity for conceptualizations.
In SMM, we call any domain conceptualization where every term has a stable and explicit phenomenological characterization a worldview; we recognize the worldview as the outer possible boundary for interoperability. In practice, a worldview is a set of ontologies that describes meaning under the viewpoints set by a given range of scales, where terminology is unambiguous and its relation with the chosen phenomenology is stable. Relationships between fundamental types in the chosen upper ontology create binding constraints for the entire conceptualization and provide guidance for semantic consistency and validation. The worldview we use in the ARIES project is the primary source for the examples in the rest of this article. This worldview focuses on spatial and temporal scales broadly in tune with human life, dealing with entities, processes, events and relationships that characterize and bound socio-ecological, economic and agricultural systems. We thus anticipate that it can provide semantic building blocks for data management and modeling across a wide range of applications in socioeconomic and environmental simulation. While we found this worldview adequate to represent Earth systems data and models, we would be hard pressed to suggest its use in disciplines whose scales of interest are widely distant, such as cosmology or high-energy physics.
The formalism described in the rest of this article outlines a simple metaphysics dedicated to the practical description of observations. In this view, things exist as long as observations of them can be produced. Our later use of philosophical terms, such as universal, particular, etc.30, exclusively serves this interpretation, and may slightly differ from other definitions used in philosophy and computer science. Ample discussion of these terms and their meaning can be found in the philosophical literature9,15,30. Our work aims to enable FAIR+ interoperability in scientific workflows, outlining a minimal and practical phenomenological basis intended to be simple and intuitive enough to be internalized by large numbers of practitioners. Our choice of terms has evolved along a span of about eight years, reflecting design and planning, plus several years of exposure to and feedback from diverse users in academic, governmental and non-governmental sectors.
We briefly articulate the phenomenological basis for our approach below, starting with the fundamental logical dichotomy of universals vs. particulars and further dividing particulars into continuants and occurrents. In our interpretation, these terms all refer to concepts; we are not concerned here with concrete instances (e.g., the individual tree, as opposed to the idea of a tree) as our only aim is to produce observations - informational artifacts generated through the process of observing concepts in the world.
Based on this reasoning, we use the term particular to refer to concepts that describe observables for which an observation can be made, as described above, although in some literature the term is used to refer to instances. Particulars include (1) physical objects, (2) their qualities, the (3) processes and (4) events that affect them (whose observation is likely to describe the qualities affected, causal pathways and component objects) and (5) the relationships that connect them. In contrast with particulars, we use the term universals to refer to concepts that cannot be observed directly. In much literature (e.g. 15), the term universal simply means a concept (the abstraction of an entity, as opposed to the entity itself), so it includes concepts that we classify as particulars, such as processes or physical objects. We take a stance closer to Platonic realism31, which defines universals as those notions that cannot be directly incarnated unless associated with a particular. This includes classes of concepts such as attributes (e.g. ‘black’ cannot have an instance, but it can qualify a physical object, e.g., a cat), roles and others. In SMM, we translate universals into entities that cannot be observed in their own right. Only observations of particulars can be made, and universals are attributed to them to further specify their semantics.
Within particulars, the continuant vs occurrent distinction reflects how observed entities stand with regard to space and time. This distinction is found in all foundational ontologies with slightly different definitions or terminology16: for example, DOLCE14 uses the terms perdurant and endurant instead. Continuants are entities that maintain their identity through time, including physical objects (named subjects in SMM) and their measurable qualities. For example, color or height, which can be observed only when linked to other entities through mandatory inherency: e.g., the height of a tree. While continuants are, occurrents, such as events and processes, happen: their definition is intimately tied to time. As discussed previously, a spatial shift in the observation point can morph continuants from countable subjects to uncountable qualities as spatial resolution moves upwards and small-scale subjects lose their individual visibility in favor of larger-scale ones. Similarly, countable events can morph into uncountable processes, as temporal resolution shifts to allow appreciating change within what was formerly seen as an individual event. Relationships between two observations also reflect the continuant-occurrent dichotomy; accordingly, they can be seen as structural (unconcerned with time, such as parent-child) and functional (such as flows, whose expression is a time-dependent process).
Figure 1 illustrates how observational scale and the categorization of particulars are intimately linked. A temporal scale gradient (Y axis) separates occurrents - for which fine temporal resolution allows an observer to appreciate change - from continuants, the meaning of which can be appreciated independent of time, due to the temporal scale being coarse enough to make change invisible. On a spatial scale gradient (X axis), “close” observation focuses within individual observations, impeding the appreciation of their individuality (therefore the “counting” of separate individuals), but enabling the observation of their inherent qualities and processes. As spatial scale is made coarser, the point of view moves outside the individual observation, allowing an observer to appreciate first the individual relationships between two of them, then an arbitrary number of them in the context of a larger-scale observation (not shown in the image). The property of countability tracks meaning along a spatial scale gradient in the same way that the dichotomy “happens/is” tracks meaning along time scale gradients. The diagram in Figure 1 has proven intuitive enough for ARIES users to remember and use as guidance in the first steps of semantic annotation.
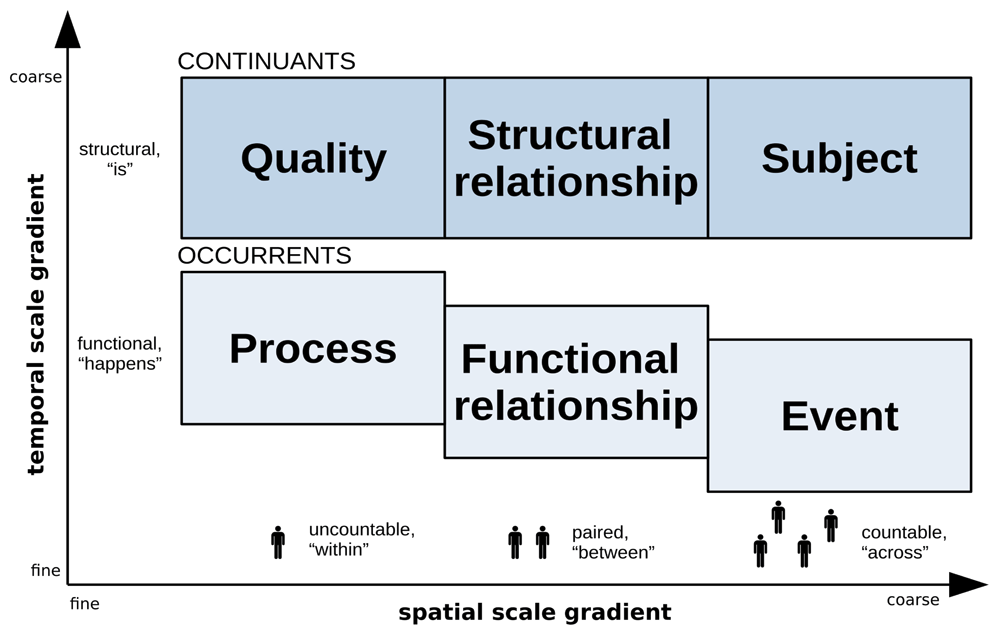
Refer to the text for explanations.
During the development of the ARIES project, it quickly became apparent that the explicit statement of semantics was key to achieving our goals of building and linking community-driven, interoperable repositories of independently developed data and models. At the same time, it became clear that no community of modelers, data scientists or other prospective users would consider an investment in OWL or other semantic web-endorsed formalism as the vehicle to express the semantics in data and models, and that a different approach was necessary. Our solution was the design of a custom semantic specification and annotation language, for which we laid out four main requirements.
1. Full compatibility with accepted semantic web standards. In the current implementation, this translates into the ability of any specification to compile to OWL2.
2. Expressiveness: syntax and keywords should intuitively relate to the phenomenology and experience of scientific observation, so that the terminology and complex logical constraints in the underlying ontology do not need to be learned or exposed.
3. Readability: the language should read as close as possible to English, using familiar terms that are as easy as possible to learn and memorize.
4. Parsimony: the language should support flexible composition of terms to allow the terminology to remain as small as possible, enabling the greatest possible reuse of terms.
The result of many years of design and user feedback is the k.IM language, which currently makes worldviews accessible to ARIES modelers. The k.IM (for “knowledge-Integrated Modeling”) language is complemented by an open source software stack named k.LAB, which provides integrated tools to develop and use conceptualizations and models using k.IM. The software, which in its current alpha stage requires training to be applied, will not be discussed here, but can be freely downloaded and explored in source form.
In k.IM, particulars and universals are combined to specify observables; these can later be used to annotate data and models. Keywords and syntax rules are designed to make k.IM statements readable and understandable by mimicking English syntax, while specifying much more complex, correct and consistent OWL32 axioms. All k.IM statements compile to OWL2, the most widely used and accepted representational standards for ontologies. Conceptualizations written in k.IM can thus be exported and used in OWL-based systems with no loss of information.
Experience with developing and teaching k.IM has highlighted three clearly distinguishable tiers of sophistication in semantic annotation practice, arranged here by decreasing levels of experience required and progressively shorter learning curves. Tier 1 is annotation of data and models, performed by minimally trained users utilizing the terms from domain ontologies, facilitated by context-aware search tools. Tier 2 is domain definition, where domain experience is the essential skill, but an investment in knowledge engineering remains necessary. Tier 3 is worldview definition, limited to knowledge engineers with ample time to invest in work with domain experts. All three tiers are enabled in the k.LAB community and will be discussed and exemplified below. Tier 3 usage is discussed in Section 2.3. Examples from tiers 2 and 1 will be given in Section 2.5.
The following examples, taken from the socio-ecological system worldview used in ARIES, illustrate some of the most important aspects of k.IM and their role in facilitating the conceptualization of domains. For clarity, the examples are highlighted in the same way the k.LAB editor does: keywords (identifiers recognized as part of the language) are in purple; user-generated text (including concept identifiers) is in black; literal text (such as quoted strings) is in blue. Table 1 provides a more systematic list of keywords with their associated meanings. We only discuss the features of the language used to specify concepts; those concerned with data annotation will only be briefly described, while the features concerned with modeling will be discussed in a forthcoming contribution.
Keywords (in bold) are used in the language to state concepts. Other keywords indicated can be used to specify relationships between concepts (e.g. exposes, describes, implies).
Geographical elevation is a quality inherent to regions of Earth, whose full specification involves different notions, some specific to the geographic domain, others of more general relevance. We use namespaces, associated with separate URLs or files, to separate concepts from different knowledge domains; a namespace can import another (through a using clause as shown below), so that the concepts defined in it can be referenced. Concepts from imported namespaces are referred to using the namespace identifier as a prefix to the concept name, separated by a colon (for earth:Region, the concept Region is defined in the earth namespace). The specification in definition (1) comes from the geography namespace, declared at the beginning along with its imports.
namespace geography using im, earth; length Elevation "Geographical elevation above sea level, as described by a digital (1) elevation model." is im:Height of earth:Terrain within earth:Terrestrial earth:Region;
In this specification, the length keyword establishes the fundamental character of geographical elevation, including its physical nature (an extensive property whose value changes with the extent of the inherent subject) and the base unit for its measurement. This is done by tying the concept being defined to the core observation ontology, which lays out the phenomenological categories defined above, along with constraints and relationships for all common scientific observables, unseen by users. The language contains keywords for many fundamental quantities, allowing users easy specification in most situations (Table 1). It also provides semantic operators to easily and systematically modify existing concepts obtaining derived quality concepts:
event Earthquake; (2) model table(“data/earthquakes.csv”) as probability of Earthquake;
Example (2) needs only one concept, Earthquake, as the annotation of its probability can be done through a semantic operator (probability of), which can only be followed by a concept describing an event and produces a concept for its probability. Similar operators allow the expression of presence, occurrence, distance, proportion, ratio and value (Table 2). The use of semantic operators greatly reduces the number of concepts needed in the worldview and enables validation of the modified observable.
Text in square brackets indicates optional specifications in k.IM syntax. These operators only create concepts, with no assumption over their values. Observer statements (Table 4), which also build the correspondent concepts, are the k.IM specifications that are concerned with the actual states resulting from their observation.
As concrete qualities (those of which observations can be made) can only exist inherently to a direct observable, the observable must be made explicit before the concepts can be used (e.g., earth:Region in the previous elevation example). In example (1), the concept statement starts with a description (highlighted in blue) that is indexed in the k.LAB software, so that users can easily locate concepts by textual searching. The is keyword introduces the semantic specification for the term Elevation. In it, im:Height (from the base namespace im, for “integrated modeling”, also the name of the containing worldview) is first established as its fundamental nature; then, inherency is established by means of the keywords of and within. Inherency enables validation of the contexts in which the qualities are used. For example, after the definitions in (1), it will be correct to annotate elevation within a watershed, as long as a previous statement defines the Watershed concept as a type of earth:Region. In many situations, specifying within is enough to establish inherency. The of keyword is used when the quality refers to a second, implicit observable in the context of inherency. For example, the “height of trees” quality in a region is inherent to that region, but implicitly describes tree subjects in it. In keeping with our readability requirement, we only allow two levels of specification and use two different keywords (within and optionally of). We found that legitimate chained specifications, such as “x within y within z within …”, were awkward and difficult to understand in usage tests and decided against allowing such statements. Multiple chains of inherency of this kind can be defined using intermediate concepts.
In knowledge domains (as opposed to physical ones), the implicit inherent subject is often a configuration. This is a perceived, measured or inferred arrangement of observables that can be experienced and recognized by humans without being directly amenable to providing the observable of an informational artifact. For example:
namespace earth using physical; configuration Terrain (3) "The three-dimensional configuration of land surfaces" is physical:PhysicalConfiguration within Terrestrial Region;
In k.IM, configurations can only follow of in inherency specifications. This constraint allows the construction of clear and unambiguous statements that relate well to scientific discourse while remaining logically consistent. Common logical errors stem from confusing legitimate observables (such as qualities, subjects or events) with “objects of study” in science that are part of daily discourse but are not actually amenable to being directly described by informational artifacts. Configurations often allow keeping such concepts (such as Terrain above) in a specification without compromising logical integrity. Other examples of configurations include bathymetry, aesthetics and all types of networks, e.g. a stream network or a social network, whose observables are the actual subjects and relationships that create the perceived configuration.
The inherency requirement for qualities is one of the primary means for semantic inference and validation in SMM. Machine reasoning can be applied to ensure proper usage of each concept in data annotations and models. For example, models of a quality that is inherent to a specific subject or process are validated to ensure that all other qualities used for its computation are inherent to a compatible subject type (see below for a definition of compatibility). Any mismatch makes the model semantically inconsistent and must be solved before it can be computed. At the same time, many inferences are possible through reasoning on inherency. For example, a model’s requirement for “presence of biology:Tree” will automatically be satisfied if data for this specific concept are not available, by an observation of “im:Height of biology:Tree within earth:Region”. Because non-zero values of extensive physical properties imply the existence of their inherent subjects, a model for presence of trees can be automatically built using the height data and height > 0 as the criterion to establish presence. Interestingly, inherency underlies the mechanism through which shifts in a spatial scale affect identity and meaning in continuants. If a finer spatial scale resolves, e.g., the color of individual unicellular algae subjects in a volume of water, expanding the spatial extent and lowering the resolution may cause the algae subjects to go “out of focus”. Their color now becomes a quality inherent to a larger, previously invisible lake subject.
In specification (1), geographic elevation is established as a length by its fundamental keyword, but the definition introduced by is defines it as a Height, from the base im worldview namespace. The definition of Height shows the use of attributes to constrain the length concept to a specific orientation relative to the observer:
namespace im; (4) abstract length Height inherits Vertical, Lineal;
The attributes Vertical and Lineal (whose definitions are not shown here) are attributed to Height using the keyword inherits, establishing characteristics of Height beyond its definition as a length. In this worldview, Lineal (as opposed to Areal or Volumetric) is used to ensure that transformations of qualities involving dimensional reasoning (e.g. dimensional collapse under scale aggregation) carry the information that is needed for the algorithms to properly mediate scales and values. While the concept of “length” belongs to the foundational observation ontology, outside the worldview, dimensionality is specific to worldviews, as it could be interpreted differently in other domains (e.g., in non-classical physics). The Height concept is declared abstract to ensure that observations cannot be made of it; any concrete concepts derived from it - omitting the abstract keyword, such as elevation in (1) - must specify their inherency or the k.IM parser will flag an error.
Attributes are an important feature for k.IM to enable fluent specifications while enforcing our parsimony requirement. Definition (1) exemplifies the English-like syntax used to specify attributes that restrict the context to terrestrial regions without creating a new concept. The context for geography:Elevation is declared to be “earth:Terrestrial earth:Region”, combining two concepts at the time of usage by simply mentioning them in sequence. Instead of merging them into another concept, earth:TerrestrialRegion, the sequential specification follows the grammatical conventions of the English language and yields more parsimonious ontologies. The ubiquitous use of is-a specialization to add attributes to observables (BlackCat is-a Cat) is a major cause for explosion of terminologies in domain ontologies. While this is legitimate from a phenomenological perspective (a black cat certainly is a cat) and from a mathematical logics perspective (black cats certainly are a subset of the set of all cats), we adopt the convention that only clear semantic distinctions should reflect in is-a inheritance. As long as an attribute does not obviously modify identity (a black cat is just a cat) the specialization should be described without explicitly creating a new concept. Attribute composition through is-a relationships can also yield ambiguous inheritance graphs, logical errors and specification dead-ends when many attributes are used but subtypes are intended to inherit only some. As most universals apply to broad classes of observables (color is certainly not just an exclusive attribute of cats), the advantages of the quasi-natural k.IM syntax quickly become apparent in terms of parsimony and readability. This syntax enables the creation of ontologies that are small enough to be learned and used but retain high expressive power. The underlying infrastructure, such as k.LAB, is left in charge of handling, unseen, the axiomatic complexities of concept inheritance and attribute composition.
Attributes are often used to coarsely summarize the value of qualities. In k.IM, we preserve these relationships in order to allow inference of attributes:
namespace ecology using chemistry, earth; abstract attribute Salinity describes chemistry:Salinity within earth:Aquatic earth:Region has children (5) Saline, Brackish, Freshwater;
In definition (5), it is clear how an attribute (ecology:Salinity) with its “child” sub-categories is a synthetic and approximate way to describe the actual concentration of sodium chloride in a natural water body, defined in the chemistry namespace (see Section 2.4 for details on chemical identities, and Table 2 for the proportion of semantic operator):
namespace chemistry using im, physical; quantity Salinity (6) is proportion of (NaCl im:Mass) to (Water im:Mass) within physical:DelimitedBody;
By establishing a semantic relationship between the salinity categories in the ecology namespace and the proper salinity definition in the chemistry domain, we open the way for classification models (not discussed in this article) to define specific ways to observe ecology:Salinity (i.e., establish the concrete sub-trait that applies to a chosen context). This occurs by observing and checking ranges of chemistry:Salinity that determine each category in context-specific ways (e.g. distinguishing brackish from fresh water; see 5 for practical examples of how similar models may be chosen, assembled and used).
To ease specification and enable inferences and functionalities, attribution in k.IM uses four categories of universals, collectively named traits, which correspond to different keywords used at declaration (Table 1). We distinguish general attributes from more specialized orderings (whose subtypes define an ordered sequence), realms (which identify mereologically arranged subdivisions of a context, such as atmospheric strata) and roles, which categorize the ways specific observables are seen when in the context of another. Each of these categories enables specific types of inference in applications; roles, in particular, are crucial for interoperability in modeling applications, and deserve a discussion that is outside the scope of this article. A final category of universals, identities, is instrumental for the use and reuse of external vocabularies and terminologies, and is described in detail in the next section.
In semantic annotation practice, it is common to encounter situations when an abstract observable (such as an individual animal, plant, or a material object such as a delimited volume of matter) must be identified by a “species”, such as a taxonomic or chemical one. For such situations, k.IM recognizes specific types of universals we name identities, which can be bound to observable concepts so that the use of a given identity type becomes mandatory to further specialize the observable:
namespace biology using physical; agent Individual (7) is physical:SelfAssertedBody requires identity Species;
In this case, the set of possible identities may be very large or even infinite. Since it is of course impractical to expect that ontologies can list all possible identities, this presents a problem when reasoning must compare concepts at two separate endpoints, as the identity used at one may not be known at the other. Having users create concepts for identities whenever a new one is needed would break interoperability, and the alternative - adding them to the shared worldview on an as-needed basis - would make the worldview prohibitively difficult to coordinate and maintain.
In such situations, we use authorities to link authoritative terminologies and ontologies. In k.LAB, authorities are software components that translate terms provided by authoritative terminologies, maintained by standard-defining organizations such as IUPAC for chemical nomenclature, into logical axioms that can be inserted into the namespaces provided in the worldview to create stable concepts that are available at all points of use. Authorities are identified in k.IM by names bound to a specific identity in a worldview:
namespace biology; abstract identity Species (8) is Taxonomy defines authority GBIF.SPECIES;
This statement binds the GBIF.SPECIES authority to the biology:Species identity, requiring that any concrete biology:Individual is identified using it (based on definition 7, each Individual is in turn bound to adopting a biology:Species identity). For example, a spatial coverage (e.g., a raster GIS dataset) describing the counted occurrences of honeybee individuals (Apis mellifera) per square kilometer could be annotated as follows:
model raster(“data/bees.tif”) as count biology:Individual identified as “1341976” by GBIF.SPECIES per km2; (9)
Code 1341976 in the GBIF catalogue33 is the identifier for the Apis mellifera species, tracking its unchanging taxonomic identity through any changes in nomenclature that may have occurred over time. For increased readability, definition (9) can also be written with a concept declaration that makes the identity explicit for a reader:
agent HoneybeeIndividual is biology:Individual identified as “1341976” by GBIF.SPECIES; (10) model raster(“data/bees.tif”) as count HoneybeeIndividual per km2;
In such situations, the user-defined concept (HoneybeeIndividual) functions as an alias for the GBIF honeybee concept, so that independent uses of the concept will not produce ambiguity, even if different specifications like (10) are given and different concept names are used in them. The two specifications (9) and (10) are functionally identical and compile to the same OWL axioms. Within the GBIF.SPECIES authority, producing logical axioms for the GBIF code 1341976 entails verifying that the code is a valid species identifier: a different outcome, such as using a non-existent or, e.g., a family code, would result in a parsing error reported to the user. This mechanism guarantees the ability to reason across namespaces and allows full interoperability of taxonomic names when used at independent and uncoordinated endpoints. Multiple sub-authorities (such as GBIF.FAMILY, GBIF.CLASS, etc.) allow binding different classes of identifiers managed by the same organization. The GBIF web-accessible catalog service33 provides codes that identify species and other taxonomic names in a stable and reliable way. It also provides metadata, such as labels, common names and broader terms, that are automatically linked to each concept created, allowing full specification of the identity and automated documentation of the resulting informational artifacts.
In addition to the identities managed by GBIF, representing the full taxonomic hierarchy from kingdom to variety, k.LAB provides authorities that recognize and interpret: (i) chemical identities (using the InChi naming conventions34); (ii) soil taxa according to the World Reference Database nomenclature35; and (iii) several classes of agricultural terms provided in AGROVOC25 (Table 3). In most cases, authorities provide both validation of identifiers and search facilities, building on services provided by the managing institutions. For example, if a user refers to a chemical compound using a wrongly formatted InChi string, an informative error is reported. In contrast, a correct string can be translated by the IUPAC authority into a molecular diagram for the user to check. Availability of a specific authority within a worldview is equivalent to an endorsement of that authority in it. Authorities, complemented with search tools and validation, such as those provided in k.LAB, provide consistency and a sound annotation discipline in a usage landscape characterized by widespread redundancy and inconsistency. “Bridging” authorities, while not yet attempted, might also be designed to accept terms from one authority and turn them into the same axioms of another covering the same domain. For example, SOIL.USDA may in the future complement the existing SOIL.WRB authority as an alternative source of soil taxonomy identifiers, producing axioms compatible with the latter. This would enable transparent mediation of competing vocabularies and further expand opportunities for interoperability and reuse of existing annotated data.
Each authority uses an external service or vocabulary and can provide one or more views that bridges to a specific type of identity. The concepts produced by authorities carry the URIs of the original concepts as metadata, when those are produced by the corresponding authority.
With a common phenomenology, a structured language and validating supporting infrastructure, knowledge engineers can create worldviews with better prospects of consistency, expressiveness and reusability. Yet, the task of building a worldview remains daunting. We can consider the building of the worldview a Tier 3 activity, requiring significant expertise, long-term research investments and a careful vetting process involving consultation and continuing collaboration with a large number of experts. We will briefly summarize challenges and successes of worldview development for ARIES in the discussion and better discuss the topic in forthcoming contributions.
When a suitable worldview is available, it should become possible to compose domain semantic annotations by combining existing concepts from the worldview and its endorsed authorities. We can consider this Tier 2 of difficulty in semantic annotation; it is the scope of many initiatives of which a representative example is the Agrisemantics initiative36. The Agrisemantics vision statement mentions height of corn as an archetypical example of a common observable whose interoperability for existing data resources is desirable. A fitting ontology available in the OBO foundry29 that provides concepts adequate for this task is the Plant Trait Ontology (PTO,37), which draws on the work of many experts and enjoys good community acceptance. The PTO provides a hierarchy of concepts starting at quality (imported from the BFO ontology, also a base ontology for k.LAB) specialized to morphology, then further into size height and plant height. One can assume that identifying height of corn would require a further specialization of plant height, and the corn identity would simply be implied syntactically by using a Corn… prefix in the term assigned to the concept. Further exploration of the PTO reveals that giant embryo (a gene type) is a sibling of plant height, both specialized from whole plant size through is-a inheritance. Further is-a specialization of plant height defines, among others, concept plant height uniformity (a quality not physically commensurable with height) and relative plant height (seemingly adding an observation-related attribute, relativity, out of many possible). The PTO is one of the most advanced domain ontologies in use with respect to phenomenological characterization, and its terms have proved useful to large communities. Yet it is clear from this example that no ontology can force users to adopt cogent annotation practices, ensuring that physical and biological identities are preserved along inheritance chains and attributes retain traceable and stable meaning. These are key requirements to help prevent inconsistencies and better assist annotation in service of the FAIR goals. If the same exercise were replicated in k.IM, for example to annotate a raster map file describing corn height in cm in a given region, the language itself would have driven the specification of the semantics:
model raster(“data/cornheight.tif”) as measure im:Height of agriculture:PlantIndividual identified as “c_12332” by AGROVOC.CROPS (11) within agriculture:CropField in cm;
Or for increased readability:
agent CornPlant is agriculture:PlantIndividual identified as “c_12332” by AGROVOC.CROPS; model raster(“data/cornheight.tif”) as measure im:Height of CornPlant within agriculture:CropField in cm; (12)
The measure (observable) in (unit) syntax (see below and Table 4), one of k.IM’s observer statements (Table 4), embodies the semantics for the how of observation discussed above, and requires that the primary observable, in this case im:Height, be a physical property, simultaneously enforcing the use of units of measurement appropriate for its physical nature. Definitions (11) and (12) intentionally use agriculture:PlantIndividual instead of biology:Individual, as the latter requires a precise species identity (definition 7), while the former references the commonsense taxonomy used in AGROVOC for crop types, reflecting the intended semantics for the data. Most importantly, the adoption of rigorous phenomenological inheritance and specification syntax requires the realization (and the explicit statement) that height is first of all a quality of a plant subject, and that the data refer to plants within a cropfield subject. These logical axioms are a necessary base for any reasoning that can assess their compatibility within applications. While such details still need to be learned by a user, the syntax itself serves as a guide for the annotation workflow: the use of inconsistent observables or the lack of proper inherency would yield ungrammatical statements that are reported as errors. For example, leaving out the of specification would cause height to become abstract, therefore not usable for data annotation; leaving out within would leave the context of inherency for the quality blank, reported as an error for any non-abstract quality. The result is readable by a non-expert and compiles to axioms specifying a single OWL concept, which can be transferred to a remote endpoint in axiomatic form and reconstructed for reasoning or database querying; the shared worldview is the only requirement for its interpretation. The concept as constructed carries information about physical nature, dimensionality, domain of application, agricultural identity, biological identity and context of inherency (plants within a cropfield). These are assembled through consistent logical restrictions and are robust to validation and machine reasoning. On this basis, inferences can be performed that use the annotated dataset to satisfy queries beyond the asserted quality, e.g. for presence of CornPlant as discussed previously. Simply through reasoning on the concept, a query for an observation of the height of generic agriculture:PlantIndividual in any earth:Region (of which agriculture:CropField is a subtype) could be satisfied, in absence of a more specific match, by the same corn height data.
These statements are used in data and model annotation (as opposed to ontology definition) to express either data semantic or model dependencies; when necessary, they automatically apply the semantic operators of Table 2 to build the correspondent concepts. In addition, they specify observation semantics (such as units, currencies or categories) so that the concepts can be associated to specific data values and mediated when necessary.
| Prototype | Description |
|---|---|
| measure <O> in <unit> | Specifies the unit for a concrete physical property and ensures that it is compatible with the physical nature and the spatiotemporal context of use. Ensures that units are converted when dependencies are matched to data. |
| rank <O> [min to max] | Used with priorities, can specify a scale for bounded ranks and ensure that scales are properly converted when dependencies are matched to data. |
|
classify <O> [into <O1 [if <condition>], O2, …>] [according to <metadata field>] [as identified by <authority>] | Used with class concepts, enables many useful ways of specifying the semantic content of categorical classifications; in addition to the direct specification of the concepts that each possible value or range of values should map to, it allows specifying metadata for conversion (e.g. the standard encodings of categories in common land cover datasets) and to match values to concepts by converting identifiers through a specified authority. |
|
value <O> [over <O2>] [in <currency>] min to max] | Values can be direct or relative (an example of the latter is the pairwise comparisons used in multiple criteria analysis) and refer to a currency (monetary or conceptual) or have a scale like in the case of rankings. When the currency is monetary, a year must also be specified; k.LAB contains functionalities that bridge to conversion services so that values can be adjusted for inflation and converted to different currencies in many cases. |
| distance to <O> in <length unit> | A distance observer will observe all the objects of the type mentioned in the context of observation and compute the distance to them. In k.IM, this observer can also be used with reference to the URI of a specific observation, which can be located anywhere. |
| count <O> [per <extent unit>] | Count observers observe all the objects of the type mentioned and produce their numerosity, if necessary distributed over space and/or time. A count concept is produces unless O is already a count. |
| ratio [of] <O1> [to <O2>] | Ratio observers describe ratios between qualities. A ratio concept is produces unless O is already a ratio. |
|
proportion [of] <O1> [in <O2>] percentage [of] <O1> [in <O2>] | Proportion and percentage are differently scaled ways to observe a proportion concept, which is created according to rules in Table 2 unless O1 is already a proportion. |
| uncertainty [of] <O> | The numeric scaling and computation of uncertainty is not mandated in k.IM. In k.LAB, currently, numeric uncertainties are computed as standard deviations of probability distributions, and the Shannon index of diversity is used for categorical information. |
| probability [of] <O> | Probability observers validate their data in the [0-1] interval. A probability concept is produces unless O is already a probability. |
| occurrence [of] <O> | This observer is a “fluent” shorthand to specify the probability of a presence. |
| presence [of] <O> | Validates data as boolean (true/false). A presence concept is produced unless O is already a presence. |
The simplest examples of usage (Tier 1) exploit pre-defined concepts from the worldview to annotate resources. In such cases, knowledge of the syntax and simple search tools allow a user to produce annotations that can accompany informational assets for automated discovery and indexing:
worldview im; model raster(“elevation.tif”) as measure geography:Elevation in m; (13)
Specifications such as (13) are simple enough to be added to metadata or “sidecar files” – files with a “.kim” extension that accompany data files with the same name - which may be automatically detected and indexed by specifically designed web crawlers, so that indexes of web-accessible, annotated datasets can be built and maintained. Specification (13) is complete and correct, as geography:Elevation is fully characterized in terms of inherency within the worldview, as seen in statement (1). The statement of the worldview name is enough to load the web-accessible worldview and use it to interpret the specification that follows. To annotate qualities, which encompass a majority of data artifacts, the syntax for observer statements (such as measure in the example above) is enough to represent all observation semantics known to k.IM. The set of available observer statements (Table 4) is small and has proven easy to learn and use in ARIES coursework and test user communities.
While this article does not fully describe modeling and annotation features of k.IM and k.LAB, we note that data annotation is not restricted to qualities. Subjects can also be annotated with ease using a slightly different syntax:
model each vector(“data/roads.shp”) as infrastructure:Road; (14)
As subjects are observed directly (without needing units or other known observations for comparison), the simple acknowledgement of the semantics is enough to annotate a source of objects, such as roads in a vector file. The keyword each, only applicable to countable observables, reflects the fact that such sources can produce one or more subjects with the specified semantics; the model statement also allows annotation of semantics for any attributes of the observed subjects (not shown). The k.IM language and k.LAB infrastructure build on these semantic foundations to enable a distributed modeling infrastructure, in which the resulting observations can be complemented, through further extension to the model syntax, with procedural information to create “live” observations interacting on a networked infrastructure, in compliance with their semantics. Such features, briefly described for the ARIES application in 5, will be more thoroughly illustrated in forthcoming contributions and documentation.
FAIR+ interoperability requires the unsupervised assessment of compatibility between semantically annotated resources. We use the term compatibility to refer to concepts and interoperability to refer to observations of compatible observables. In k.LAB, compatibility enables interoperability in two fundamental ways:
1. Validation of connections, for example in ensuring that a model’s dependent observables are compatible with the computed output in terms of inherency;
2. Discovery and retrieval of compatible observables for queries stated only through their semantics, so that the best source of information (data or model) for a required observable can be located on the network when requested by users or models being computed.
Using the notion of interoperability illustrated in Section 1.2 and the semantic foundations illustrated so far, the assessment of compatibility for interoperability can be defined as follows.
Two observables (O1, O2) are compatible if and only if:
The main observable concept in O1 (without considering traits and inherency) equals, or is a more specialized version of, the main observable in O2;
O1 adopts all the same traits and roles as O2 (which may have additional traits); e.g. the main observable in O1 and O2 may be a generic length, but if O1 is vertical, O2 must also be;
If O1 has an inherent type (of), O2 must have a compatible one;
If O1 has a context type (within), O2 must have a compatible one.
If observables are compatible, their observations are interoperable. They are FAIR+ interoperable if and only if:
Their observables are compatible;
Their observation semantics can be mediated (e.g. both are measurements in compatible, but possibly different units);
Their context can be mediated: the intersection of the extents (e.g. space, time) of the scale for both observables is non-empty and the resolution of each extent is the same as, or can be resampled to fit, the other’s.
This definition is amenable to being incorporated in an unsupervised algorithm. Mediation may engender information loss (e.g. aggregation error) and other uncertainties (e.g. when bridging different classification systems), which should be recorded as provenance38 in separate records kept with the dataflow. In queries, when more than one interoperable observation may be returned, any potential information loss can become part of the criteria used to rank the appropriateness of each candidate observation that matches the observable. On a semantic level, the match may also be incomplete. For example, some traits of the matching observation may not be stated in the query, e.g. a vertical length could match an unspecified one. This offers a base to develop ranking strategies considering, among other criteria, metrics of semantic accuracy or distance; the latter is an important criterion in k.LAB and will be discussed in detail in further contributions.
Distributed databases with their contents annotated according to a common worldview can allow the kind of large-scale, yet precise, semantically-driven interoperability that has so far remained a high-ranking wish in the semantic web community. SMM, a modeling approach where FAIR+ interoperability is an integral requirement, sees data and models as definitions for possible observations: while datasets can produce, possibly through mediation of observation or context semantics, the requested observations in a self-contained way, models do so through computation that may involve the observation of other concepts they depend on, to be resolved through other data or models. Distributed databases of k.IM-annotated data and models can be built using k.LAB and accessed through modern web services39 with distributed, certificate-based authentication. These services form an operational semantic web whose nodes contain FAIR-compliant scientific observations and models. In forthcoming contributions, we will describe the ways that k.LAB enables the assemblage, validation and computation of scientific workflows that observe an arbitrary user-requested concept in a user-defined context. These functionalities have been informally described in the context of the ARIES project5.
While the coverage and scale of our applications so far remains too small to warrant claims of large-scale success, our experience with ARIES indicates that building such distributed knowledge bases is possible and practical. Large-scale initiatives, such as NEON40, CSDMS41, directives such as INSPIRE42 and many others, are seeking interoperability of data, increasing requirements and initiatives for data openness and publication of data43, and implementing new data release standards that emphasize accessibility of information. Approaches that can facilitate the development of consistent semantics beyond textual metadata and controlled vocabularies become essential. FAIR criteria outline a way to gather all those observations in a way that will greatly advance science synthesis44. Faced with a state of the art in which semantic interoperability is still often understood as “matching of terms”41, we argue that the semantic research and infrastructure available to date are still not ready for a FAIR+ interpretation of interoperability, and propose the work presented here as a contribution towards it.
At the time of this writing, the k.LAB infrastructure and the im worldview are used to annotate datasets and models numbering just below one thousand, and have been exposed to about 150 users, of which only about 20 use it for their daily work. These are very small numbers compared to the ambition of open data and the importance of interoperability in scientific discourse. Our experience in ARIES has highlighted both strong and weak points in the attempt of creating a systematic and accessible path to rigorous semantic annotation for practitioners. Advantages recognized by the user community are:
Clarifying the components of interoperability, so that conceptualization efforts are focused and a suitable workflow can be identified. The most important aspect in this sense is the clear focus on observable semantics: no time is wasted seeking semantics to express model-related concepts (“model”, “variable”), observation-related ones (“measurement”) or context-related ones (“spatial resolution”), all of which figure prominently in commonly used ontologies.
Formalizing a simple phenomenology for observables and universals. The base observables in Figure 1 have proven intuitive enough to be understood and remembered by diverse users, helping them “home in” quickly on observable semantics as described in the previous point. Also, the use of independently defined and flexibly attributed universals to express attributes, identities and roles has effectively and intuitively solved, in our applications, the plaguing issue of excessive and improper specialization.
The k.IM language and k.LAB platform make ontologies and annotations immediately actionable, enforcing the logical consistency of each definition both by enforcing syntactical correctness through intelligent editing tools and by employing a machine reasoner45 to identify and report logical errors to the user. The language guides, simplifies and validates the definition of knowledge; the support software provides feedback and allows users to immediately perform user queries and compute workflows whose results enable at-a-glance validation of the semantic correctness of the concepts employed.
At the same time, clear difficulties remain in instrumenting a path to large-numbers adoption of an approach like the one we propose. For example, the use of a custom language to specify ontologies has disadvantages: the choice was inevitable for us due to the need to reach large bases of users other than knowledge engineers, but connecting to semantic web research and communities with a custom approach is of course much more difficult despite our commitment to OWL2. Another important difficulty is the need for complex, custom software to make the approach actionable, with obvious costs and difficulties related to its development, distribution and maintenance.
Finally, building and sharing worldviews that reflect large and complex domains remains a daunting task, despite the guidance of a systematic conceptual framework and methodology. In particular, developing a collaborative process to ensure that the worldview reflect the uncontroversial thinking of large communities requires both large collaboration investments and sophisticated tooling for harmonization and refactoring. Despite the success of mid-size initiatives like ARIES, we are at the very beginning of an ambitious effort whose challenges may well prove too large for large-scale adoption.
In our mind, these difficulties are offset by the potential for the collaborative, wider use of scientific products that would be enabled by such a rigorous, semantically-driven interoperability. The ability to automatically discover and compute dataflows based only on conceptual queries opens pathways that may lead to much larger use of scientific products, with a potentially much larger involvement of decision-makers and citizen scientists. Our efforts are sustained and motivated by the realization of the potential of effective, actionable interoperability to promote and enable a more efficient economy of knowledge, creating clear incentives to the sharing of data and models, so that they may become part of large and yet undiscovered computational chains.
The k.LAB software is available in source form from Bitbucket and in binary form from the Integrated Modelling collaboration site.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (2)