Keywords
machine learning, science mapping, bibliometrics, topic analysis, citeSpace
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research on Research, Policy & Culture gateway.
machine learning, science mapping, bibliometrics, topic analysis, citeSpace
Machine learning is a computer science field that studies the learning processes of humans and replicates themusing machines. Different algorithms allow a machine to learn and use the acquired knowledge to resolve several problems that society faces. This field is widely studied and there exists a huge number of articles that present machine learning applications. Consequently, in the present study, we seek to create a generic map about machine learning applications, which allows newcomers to know the fields that are being explored and use machine learning techniques. In this study, we carried out a science mapping analysis of the existing research on machine learning. As a starting point, we find that bibliometrics is a relevant tool to analyze academic research developed on different topics. Bibliometric analyses contribute to the progress of science in many different ways1, for example, by allowing evaluation of progress to be made, identifying trustworthy sources of scientific publications, laying the academic foundation for assessing new developments, or identifying major scientific actors. Performance analysis and science mapping are two bibliometric approaches used to explore a research field2. While performance analysis is an interesting way to evaluate the impact of published papers, based on their citations, science mapping aims at exhibiting the structure of scientific research, showing its evolution and dynamical aspects3.
The present study performs a science mapping analysis; however, this is not the only approach to discover tendencies or to give an overview of a topic. We can find existing literature reviews on specific machine learning topics such as algorithms4, applications into visual analytics5, and recommendation systems6. There are other reviews on applications for different fields, such as medical diagnosis7, radiation oncology8, semantic web9, models for quality prediction10 and methods for text categorization11. Also, it was possible to find a general review on machine learning12, but without a science mapping analysis, as this study performs. In 3 we find a bibliometric analysis related to machine learning, but this work only focuses on reviewing the state of the research carried out by the journal Knowledge-Based Systems (KnoSys) from 1991 to 2014. 13 and 14 use this method in the medical field, while 15 carries out an analysis in the social work area and 16 in the intelligent transportation systems research. Furthermore, there are other approaches and important analyses for providing an overview of a topic or finding its trends, using text mining or Latent Dirichlet allocation, such as in 17 and 18, among others.
This article has the following structure: In the Methods section, we describe the methodology, the dataset extracted, the tool configuration, and how the analysis was performed. The Results section presents the results of the science mapping analysis. The conclusions are given at the end of the article.
We used Web of Science (WOS) Core Collection. This is one of the primary databases for scientific literature in the scientific world. We looked, in the third quarter of 2017, for papers and conferences about machine learning, using that concept as a keyword (‘machine AND learning’), with results ranging from 2007 to 2017 Q2 (published papers up the second quarter of the year). We used the 'All databases' option to have a complete results list. Finally, the results were sorted by date. All the articles, between 2007 and 2017, were taken into account for performing the analysis with the aim of obtaining a general vision of the field.
We obtained 41,962 records from WOS Core Collection that were downloaded as plain text including the full record and cited references. The files were named as 'download' with .txt as the file extension. Figure 1 shows a summary of the records.

In CiteSpace version 5.1.R8 SE19–21, we used the records from WOS database and set a time slicing from 2007–2017, using one year per slice and the default Citespace configuration in term type, links and selection criteria options. We also used the title, abstract, author keywords and keyword plus as term sources. We changed the size of the generated network to fit the graphs, so we reduced the number of documents that were part of the top cited ones on each slice. The Top N configured for the networks are presented below each figure.
CiteSpace allows us to detect and visualize emerging trends and transient patterns in the scientific literature20; for this purpose, we applied three types of bibliometric techniques as in 22. First, co-author analysis, which investigates leading authors that are cited together23. It uses the authors’ names, affiliation countries and institutions as units of analysis and then it shows the author, institution and country co-occurrences. Second, co-word analysis to establish links between documents24, through keyword and category co-occurrences. Third, co-citation analysis that provides, as a result, the cited author, cited-reference and cited journal co-occurrences.
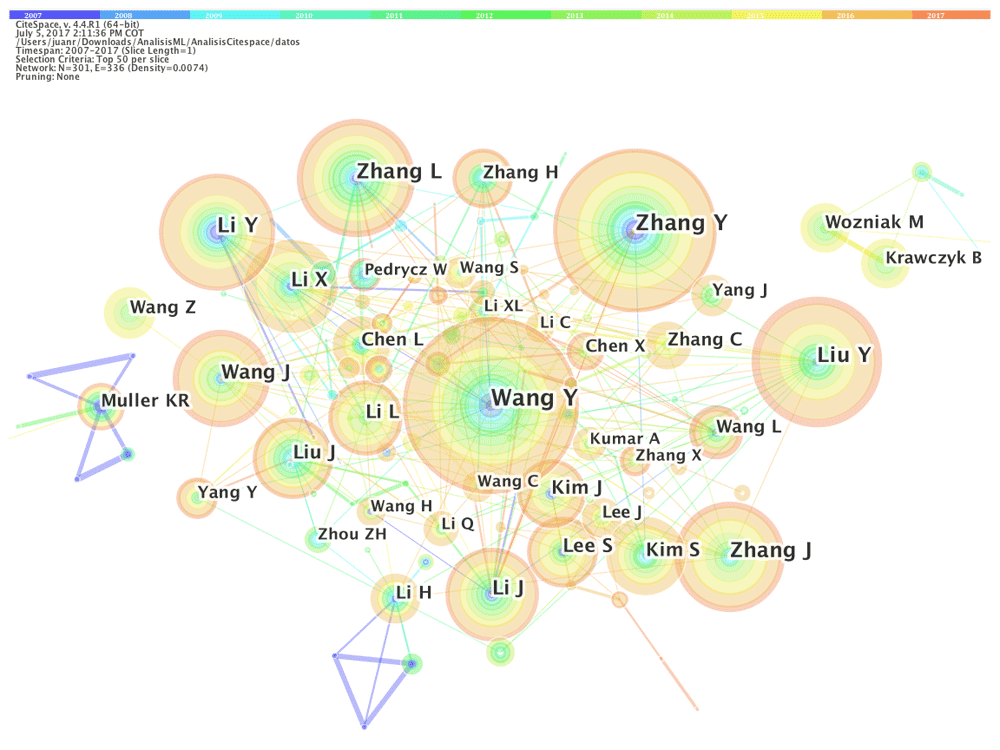
A co-authorship analysis was done to explore the authors who have the greatest bibliographic production in the field of machine learning. Figure 2 shows the resulting network. The network has 301 nodes and 336 links. Each node represents an author, and its width indicates the number of author's publications proportionally. The connections between the nodes represent co-authorship of papers and their width suggests the proportion of the cooperative relationships. Finally, the different colors of the nodes and links represent the years between 2007 and 2017(Q2). From Figure 2, following a precise analysis supported in CiteSpace and without an additional analysis of duplicates, it can be highlighted that Wang Y, Zhang Y, Liu Y and Zhang L are the authors that have published the highest number of papers on machine learning.
After the previous co-authorship analysis, it was relevant to study the authors’ institutions and countries. Figure 3 shows a network with the leading countries in which machine learning is an important subject of study, and the relationships between them. The network has 23 nodes and 85 links. From Figure 3, we can observe that the United States of America (USA) is the most productive country, followed by the People’s Republic of China, Germany, and England. Regarding the distribution, 24,761 papers correspond to the USA, 10,808 to China, 4,479 to Germany, 4,365 to England, 3,866 to India, 3,407 to Spain and 3,045 to Canada. The nodes with the highest centrality, as indicated by purple rings, suggest that the USA plays a major role in machine learning research with authors from other countries, followed by Canada, England, Brazil and Australia. The centrality of these nodes is 0.44 for the USA, 0.42 for Canada, 0.23 for England, 0.18 for Brazil and 0.16 for Australia.
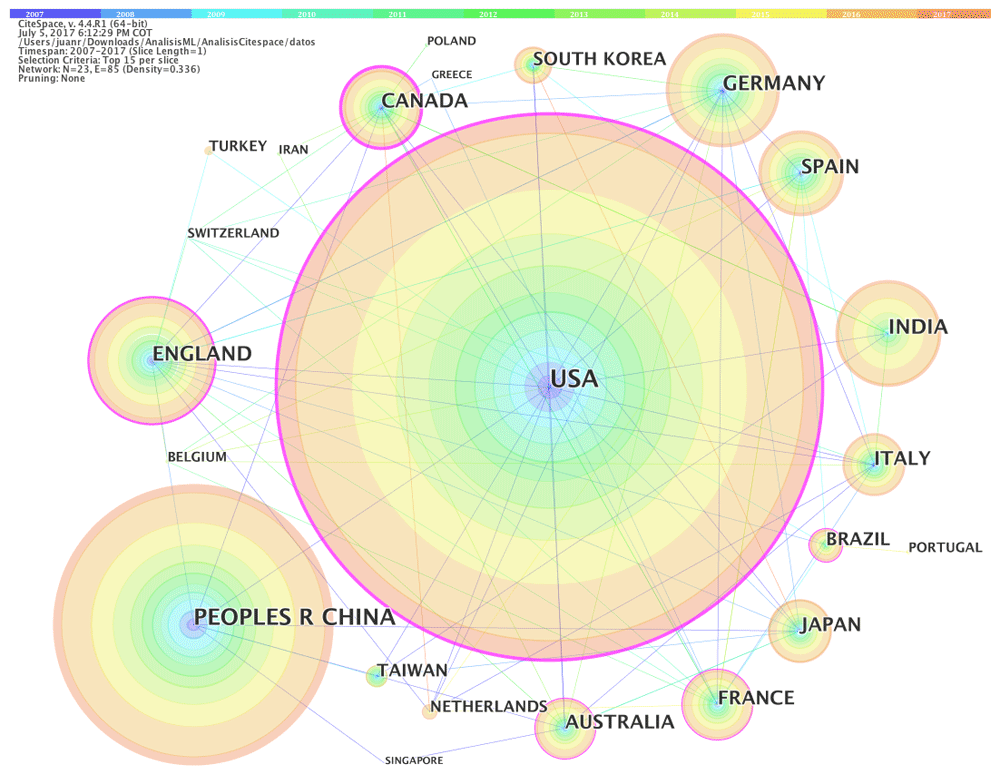
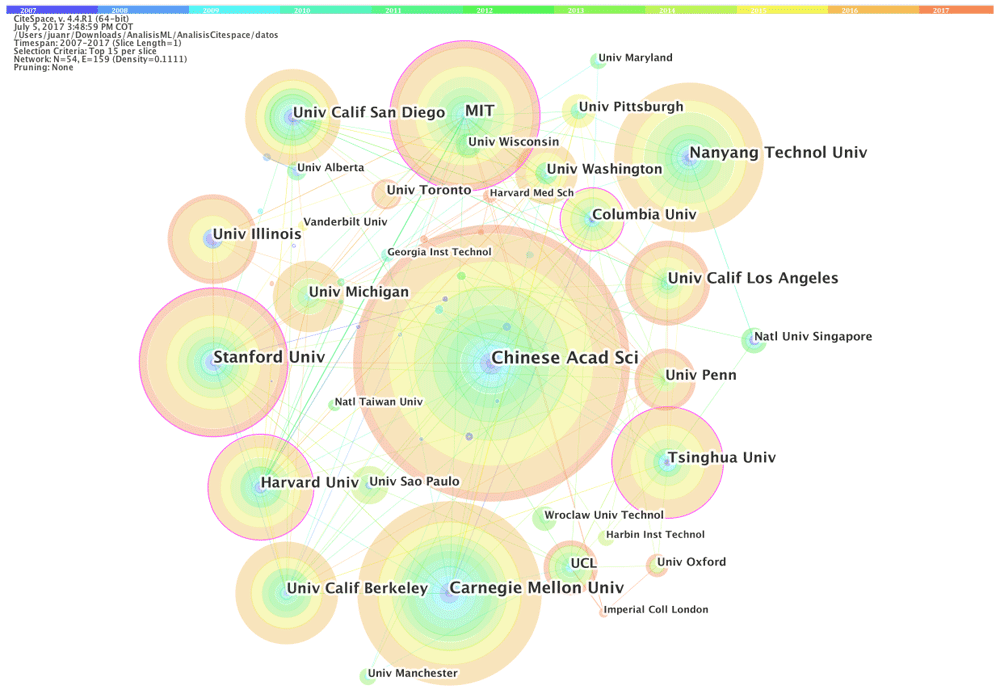
Figure 4 shows the institutions' network, which presents the organizations with the highest production of articles on machine learning. The network has 54 nodes and 159 links. The Chinese Academy of Sciences, Carnegie Mellon University, Stanford University, Massachusetts Institute of Technology, Nanyang Technological University, University of California and Harvard University are part of the institutions that have published the largest number of articles. Additionally, Harvard University (0.17), Stanford University (0.12), Massachusetts Institute of Technology (0.12) and Columbia University (0.11) have the highest centrality, which means that they occupy key positions on the relevant paths in machine learning research.
To find the main subjects of the publications and, due to the fact that during the last decade the topics in machine learning research may have changed, a co-category analysis was performed. We did a preliminary analysis, using the categories generated by WOS, as shown in Table 1.
COMPUTER SCIENCE ARTIFICIAL INTELLIGENCE (12,594, 30.013%) and ENGINEERING ELECTRICAL-ELECTRONIC (10,715, 25.535%) are the two categories that have the highest number of publications, followed by COMPUTER SCIENCE THEORY METHODS, COMPUTER SCIENCE INFORMATION SYSTEMS and COMPUTER SCIENCE INTERDISCIPLINARY APPLICATIONS. Out of all these categories, we conclude that COMPUTER SCIENCE (and its sub-categories) is the leading one. Apart from this category, other relevant fields for research in machine learning may be biology, telecommunications and automation control systems.
To perform a deeper analysis, we built a network of co-occurring subject categories, as shown in Figure 5. The resulting network has 27 nodes and 80 links. COMPUTER SCIENCE - INTERDISCIPLINARY APPLICATIONS (0.47), COMPUTER SCIENCE (0.37), ENGINEERING (0.20) and MATHEMATICAL & COMPUTATIONAL BIOLOGY (0.18) are the nodes with the highest centrality, suggesting that they are the main topics that link machine learning studies carried out on different periods. We could find that COMPUTER SCIENCE - INTERDISCIPLINARY APPLICATIONS, due to its centrality value, is a relevant category between the other concepts. This means it can be the basis of future works.

A keyword analysis allows us to observe emerging trends, since it provides information on the content of articles published on the subject. For this purpose, we constructed several networks of co-occurring keywords. First, we built a network with N=15, where N is the size of the top cited or occurred items from each slice (one year in this case). Figure 6 presents the resulting network, and has 23 nodes and 88 links. It is important to remember that each node in the network has several rings around it, and their colors refer to the years in which that keyword appears.
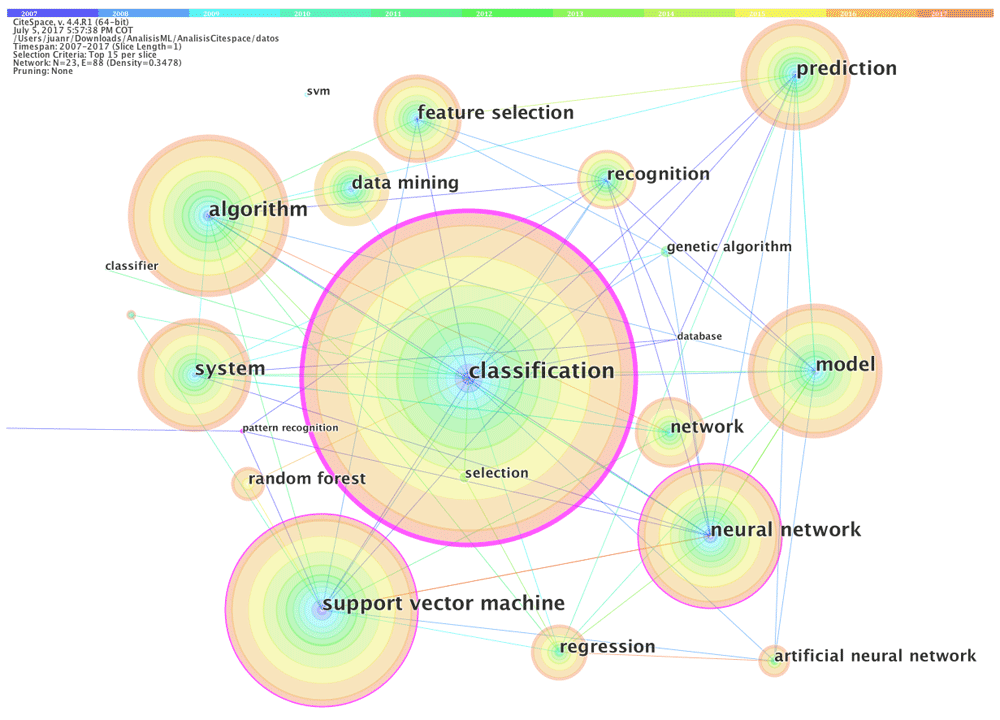
The most important keywords appearing in Figure 6, as ordered by their citation counts, are classification (5,546), support vector machine (3,347), algorithm (2,681) and neural network (2,450), followed by model (2,253), system (1,898), prediction (1,893), feature selection (1,559), data mining (1,282) and network (1,196). By their centrality, the main keywords are classification (0.56), support vector machine (0.18), pattern recognition (0.17) and neural network (0.10). From these keywords, we can observe that the classification algorithms, such as support vector machine, have been widely studied and represent an important intellectual turning point, acting as bridges that link concepts over different periods. We can find all the concepts connected to this main node. Other relevant algorithms are the ones used for regression purposes, such as neural networks, and the ones used for grouping purposes, such as k-nearest neighbors.
Second, a network of co-occurring keywords with N=50 was constructed, the resulting net being shown in Figure 7, with 95 nodes and 420 links. The keyword with the highest citation count appearing in the network is classification, with 5,546 citations, followed by support vector machine (3,347), algorithm (2,681), neural network (2,450), model (2,253), system (1,898), prediction (1,893), feature selection (1,559), data mining (1,335), network (1,304), recognition (1,283), regression (1,110), artificial neural network (1,048), random forest (971), identification (966), selection (935), optimization (853), classifier (818), genetic algorithm (743) and decision tree (675). This network highlights once again classification (centrality = 0.42) as a widely studied subject, being an important turning point between the other concepts and having a great potential for future works. The prediction keyword, with a centrality equal to 0.13, is another turning point in this network.

Lastly, using the net of co-occurring keywords presented in Figure 7, we applied a filter, eliminating subjects that are transversal (such as data or information) and elements that belong to the proper development of any work with machine learning (such as classification or random forest). Figure 8 shows the resulting network. The most important keyword appearing on the net, by its citation counts, is data mining (1,335), followed by pattern recognition (652), database (624), diagnosis (599), cancer (449) and big data (420). Other relevant keywords are Image (414), sentiment analysis (325), disease (240), bioinformatics (209), Alzheimer's disease (188), protein (170) and computer vision (131). In the network, we can observe that data mining is an important concept in the published works, and that machine learning is becoming relevant in the health field, for the diagnosis of diseases such as cancer or Alzheimer's, by using databases collected from different sources, such as EEG signals or multiple sensors.

A co-citation analysis is an interesting way to measure the relationship between documents. It allows us to represent the proximity between the publications of the data set and the relevant cited articles in external sources. In this case, we did a journal co-citation analysis, which addresses the journals of the items analyzed. It is important to observe that, in this study, when we mention journals, we also include conference proceedings. Table 2 presents the top 10 source journals for machine learning research, based on the statistics from the WOS. LECTURE NOTES IN COMPUTER SCIENCE is the journal with the highest number of publications, having published 2,107 articles on machine learning research and being published by Springer, followed by LECTURE NOTES IN ARTIFICIAL INTELLIGENCE (1,132) and PROCEEDINGS OF SPIE (646). From Table 2, we can notice that no journal widely collects the publications made on the subject of machine learning. This dispersion in the journals confirms the multiple applications of machine learning.
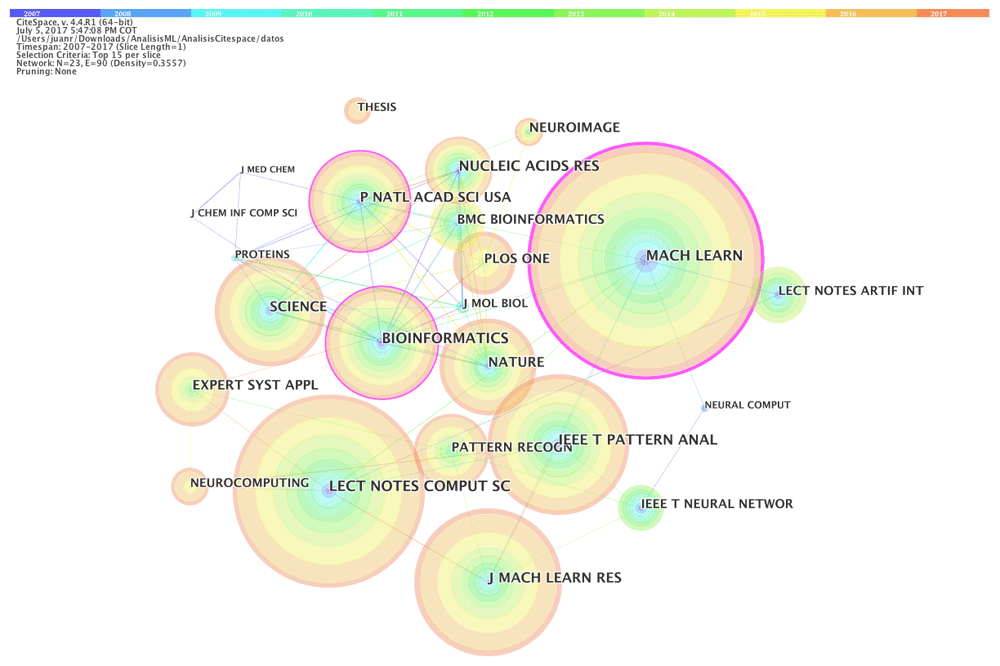
In order to find the most important cited journals and to evaluate the influences and co-citation patterns of the studies in machine learning, we did a journal co-citation analysis, which resulted in the network shown in Figure 9. The network has 23 nodes and 90 links. Concerning co-citation frequency, the most influential journals are MACHINE LEARNING (15,767) and LECTURE NOTES IN COMPUTER SCIENCE (14,684), followed by BIOINFORMATICS (14,067), IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (11,586) and NUCLEIC ACIDS RESEARCH (10,949).
To identify and to analyze the relationships between authors who have works cited in other publications and the evolution of research communities, we performed an author co-citation analysis. Figure 10 shows the resulting author co-citation network, which has 29 nodes and 131 links. Leo Breiman, a statistician at the University of California, is the author with the highest number of citations (5,270), followed by John Ross Quinlan (2,442), Bernhard Scholkopf (2,125), Vladimir N. Vapnik (2,043), Corinna Cortes (1,948) and Mark Hall (1,897).

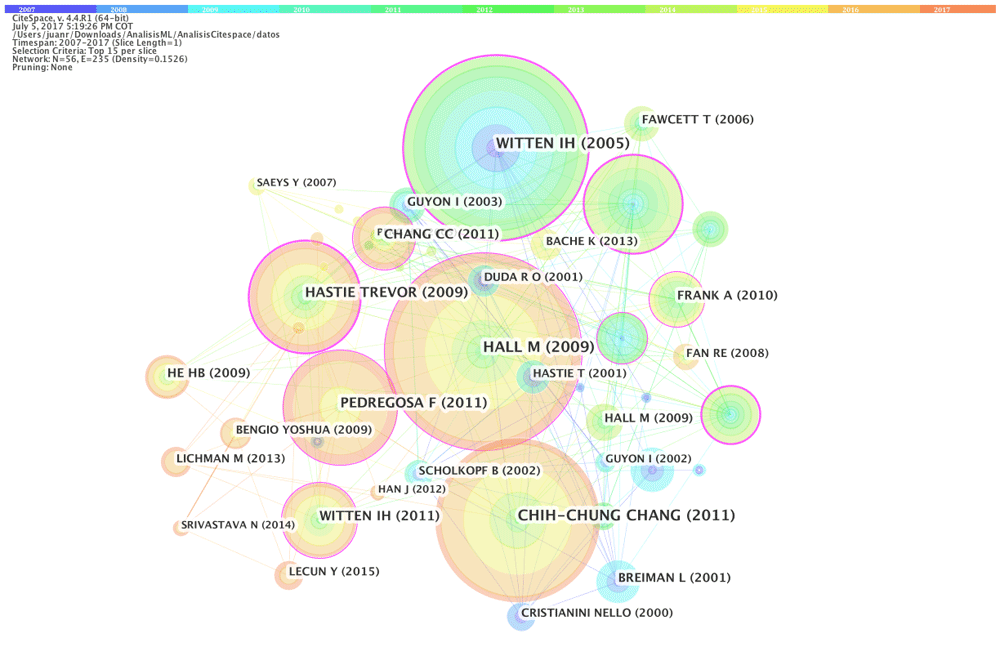
A reference co-citation analysis allows us to observe which one is the most cited reference in the articles that belong to the dataset used. Figure 11 shows the resulting network of the reference co-citation analysis. The network has 56 nodes and 235 links. Of these references, HALL M (2009), WITTEN IH (2005) and CHIH-CHUNG CHANG (2011) occupy the top three positions (with citations counts equal to 1089, 1039 and 928, respectively) followed by PEDREGOSA F (2011) and HASTIE TREVOR (2009). The nodes with the highest centrality are BISHOP CM (2006, 0.27), DEMSAR J (2016, 0.26), HASTIE TREVOR (2009, 0.24) and WITTEN IH (2005, 0.22), showing their publication year and centrality. This suggests they are important turning points between the other nodes and interesting references for future publications.
Understanding the dynamics of the machine learning field has practical and significant implications for researchers from different disciplines. In this study, we developed a science mapping analysis of machine learning. From this integrative approach, we identified the trends, state, and evolution in the field. From the results obtained, we can conclude that the USA is the most productive country in the field of machine learning, with double the publications of the People's Republic of China. The Chinese Academy of Sciences, Carnegie Mellon University, Stanford University, Massachusetts Institute of Technology, Nanyang Technological University, University of California, and Harvard University are part of the institutions that have published the largest number of articles. It is useful to mention that Machine Learning, Lecture Notes in Computer Science and Bioinformatics are the journals with most frequently cited documents. However, no journal widely collects publications written on the subject. There are a wide number of topics that have attracted the interest of scientists and could continue to be important in the future: diseases, such as cancer or Alzheimer’s disease, studies in biology, such as the protein molecule, virtual reality, commerce, smartphones and ubiquitous computing, are all important themes related to the applications of machine learning as shown by this study. This shows that machine learning can improve a large number of applications in society.
Dataset 1: Data obtained from Web of Science and Citespace project file, to be opened in Citespace. DOI, 10.5256/f1000research.15619.d21242625
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Click here to access the data.
Spreadsheet data files may not format correctly if your computer is using different default delimiters (symbols used to separate values into separate cells) - a spreadsheet created in one region is sometimes misinterpreted by computers in other regions. You can change the regional settings on your computer so that the spreadsheet can be interpreted correctly.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
{kind=link}
Comments on this article Comments (0)