Keywords
Breast cancer, protein subcellular localization, machine learning, software package, HER2 receptor status, classification.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Breast cancer, protein subcellular localization, machine learning, software package, HER2 receptor status, classification.
Machine learning tools are required to solve binary classification problems for optimal decision making in medicine and other fields of study. In recent times, they have been used to predict subcellular localization of proteins to assist in the functional annotation of gene products and protein secondary structure1,2. As the identification of the subcellular location of any given protein provides insights into its function, this prediction task is highly valuable. This is more so as the specific functions of many proteins remain to be fully characterized. In other contexts, for instance medicine, classifications of patients in breast cancer and other diseases are important for administering therapies. There are five molecular sub-types of breast cancer identified: basal-like, Luminal A, Luminal B, human epidermal growth factor receptor 2- (HER2-) enriched, and normal-like3. The prognosis and administration of therapies in breast cancer is aided by the determination of molecular subtype phenotypes4.
However, for various reasons, occasionally immunohistochemistry and other methods for establishing the presence or absence of these receptors do not necessarily cover all available samples. For example, results can be equivocal for some samples. Machine learning techniques can be trained with data from those samples that have been definitively characterized to correctly classify other uncharacterized samples’ phenotypes based on gene expression profiles. Machine learning methods rely on availability of large datasets to infer accurate outcomes for appropriate decisions concerning problems. With the advent of DNA microarray and next generation sequencing technologies, huge amounts of data are increasingly becoming available for use by these machine learning methods. These have permitted machine learning methods to be applied to characterize prognostic breast cancer samples for constructing patient-specific networks and disease groupings in precision medicine5–7.
Machine learning methods based on Random Forest have been used to identify a gene regulatory program of human breast tumour progression8. Other methods such as Support Vector Machine and Naive Bayes, have all been applied to studies in breast cancer9. Other methods applicable to such problems are Logistic Regression, Bayesian Networks, K-nearest neighbours and tree-based methods10–12. In general, binary classification problems, such as breast cancer classification, commonly occur in nature and they rely on these machine learning methods for effective grouping, and the classification of multiple outcomes.
These methods are implemented in software packages/applications. For instance, several of these methods are implemented in the Weka package13. In R, implementations are provided as fitting functions as well as packages such as randomForest14, ISLR15 and e107116 among others. Unlike linear regression models, which predict quantitative response variables, these methods infer models to predict qualitative response variables.
Recently, median-supplement approaches were introduced and found to outperform the traditional machine learning methods in binary classification models involving classification of receptor status phenotypes in breast cancer17. More importantly, these approaches achieve accuracies that compare favourably with other protein/mRNA-based procedures to decipher hormone and HER2-receptor status phenotypes in as much as they outperform traditional machine learning methods17. This implies that irrespective of the performance of the traditional methods, enhanced approaches provide better results in binary classification problems. However, none of the existing packages (implementations) supports the new median-supplement approaches to the binary classification problems.
Here, we aim to provide a median-supplement based tool, MSclassifier, for automated knowledge discovery from data and illustrate its applicability to both breast cancer and other binary classification problems in broader contexts of study. This provides an effective binary classification tool, preventing biases that may originate from requirements of traditional tools which generally influence the classification decisions. It enhances the capacities of both Naive Bayes and Random Forests to infer models that provide more accurate predictions of classes of observations. This package is implemented in R under free software (GNU General Public Licence).
In performing an effective binary classification, MSclassifier introduces a predetermined number of supplementary instances based on the median of each attribute (feature) of the training sets for binary classification problems involving unequal members of classes. The supplementary instances along with the training instances form a new set from which a Naive Bayes or a Random Forest model is inferred to predict new instances. The provision of additional instances introduced by the new methods increases their prediction accuracies. This is because the effectiveness of the learning methods is improved whenever the training instances are more18. This has necessitated the design of the software package presented in this report. There are existing tools in R, namely randomForest14 and e107116, which implement both Random Forest and Naive Bayes algorithms, respectively. The Random Forest algorithm is based on the method described in 19. These packages are compared with the MSclassifier as the median-supplement approaches represent enhancements in these methods implemented in R. In addition, these provide an objective evaluation of the tool.
The package implements median-supplement approaches to machine learning, robust machine learning techniques that have the advantage of supporting complete compliance efforts by not missing sensitive sub-datasets or allowing certain sub-datasets to escape the classification process when balancing overall datasets. They are applicable to datasets with unequal numbers of instances associated with each class (group).
Median-supplement machine learning algorithms. They involve the following steps:
1. Find the median of each attribute among all the samples (instances).
2. Find the scalar multiplication of the median of each attribute and a corresponding column vector of an m by n matrix of uniformly distributed random numbers between 0 and 1. m is the difference between the numbers of groups of samples, and n is the number of attributes. These form a supplementary set.
3. The supplementary set is added to the expression profiles to form the new balanced, median-supplement data set.
4. Finally, classification models are inferred from the median-supplement data.
There are two kinds of median-supplement approaches, namely, median-supplement Random Forest and median-supplement Naive Bayes methods. Each approach is distinguished by the kind of model constructed from the median-supplement data. For a ’median-supplement Random Forest’, a Random Forest classifier is inferred from the median-supplement data to assign classes to instances. To obtain a ’median-supplement Naive Bayes classifier’, a Naive Bayes model is developed from the median-supplement data to classify instances. The overview of the underlying principles of median-supplement approaches as implemented in MSclassifier is shown in Figure 1.
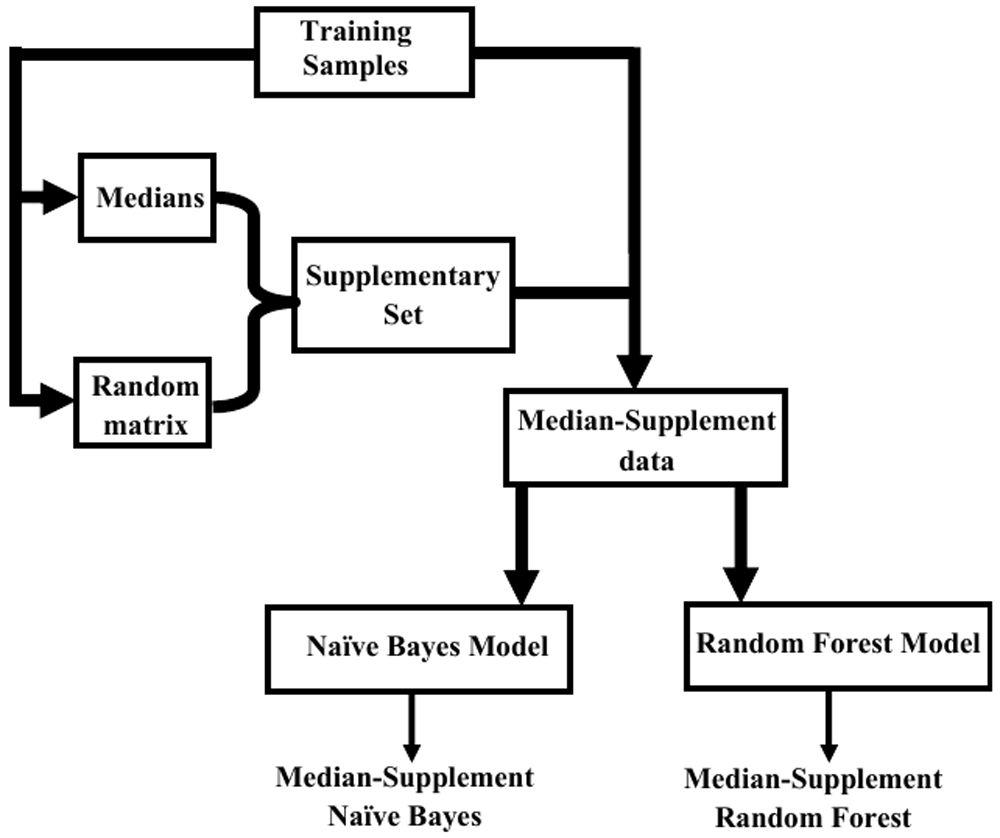
A set of medians of attributes and a randomly generated matrix with uniformly distributed values are initially derived from the training sample. The result of a scalar multiplication of medians and corresponding column vectors of the random matrix is obtained and aggregated to the initial training sample to form a median-supplemented dataset. Finally, median-supplemented models are inferred from the median-supplemented data to predict new instances.
Naive Bayes model. This model applies the Bayesian framework to predict classes of new instances. Any classes having the highest posterior probability becomes the class of a new test instance. Let G be a set of attributes. Then, the probability that any instance belongs to any class/category, Cj, is given by:
where P(G|Cj) is the probability of G given class Cj, P(Cj) is the probability of Cj and P(G) is the probability of G occurring. In this model, the attributes of each class are presumed to be independent distributions if the class is known. Thus, for each i-th attribute of n attributes, gi, the probability is given by:
Random Forest model. Random Forest is advancement in multistage decision making. It is a collection of Decision Trees. This typically involves constructing a collection of trees from bootstrap samples each of which consists of a subset of variables of the training sets. This approach of inferring trees from bootstrap samples involves recursively repeating the following20:
Selecting m variables from the full set of attributes, n, at random.
Selecting the best split among the variables.
Split the nodes into two nodes.
Once all desired trees have been achieved in those steps (which repeats after reaching a putative node size), a classification is determined by a majority vote. Assume Cb(x) is the class prediction of the b-th random forest tree. Then the classifier is given by:
Typically, Using random forest spans from the fact that it improves predictive accuracies of tree-based methods19,20.
MSclassifier, implemented in R, can be installed and run on most operating systems. The sole requirement is the availability of a recent version of R (https://cran.r-project.org/). The package is organized as a programme with the flexibility of selecting a median-supplement Random Forest or a median-supplement Naive Bayes method. The overview of the package follows the structure presented in Figure 1. The Documentation of the package has detailed instructions for installation and usage as well as other descriptions of the package.
MSclassifier does not require any special programming skills of the user. It accepts a tabular dataset in which the attributes and instances are in columns and rows respectively. In this way, the class of each instance is stored in the last column. At any time, two different datasets, training and test sets, may be supplied and the programme returns the predicted classes of instances of the test set. The training set comprises of characterized (labelled) samples whereas the test set is not characterized. In the absence of a test set, the user can specify only the training set to obtain a model for further analysis. Furthermore, the user specifies the desired median-supplement method. If no method is specified, a median-supplement Random Forest is automatically applied. Summary descriptions of arguments of MSclassifier function is described in Table 1. Samples of training and test sets are provided with the package. They are used in the illustration of the MSclassifier in the next section.
In order to illustrate the use of the package, we use HER2 datasets included in the package. These datasets were obtained from an earlier study that explored the use of machine learning techniques to determine hormone and receptor status phenotypes in breast cancer17. The training data consists of 86 HER2 receptor-negative and 14 HER2 receptor-positive samples while the independent test set consists of 51 HER2 receptor-negative samples and 11 HER2 receptor-positive samples. The illustration shows how to use the MSclassifier after installation.
Comprehensive description of function and application can be found in the help file after loading the installed package and getting the full description of the package:
> library(MSclassifier) # load package
> ?MSclassifier
To load package datasets:
> data(her2)
> data(testset)
To view a subset of the package’s her2 training set:
> her2[1:3,1:3]
NPTXR_23467 DOCK3_1795 LOC400927_400927
1 266.0075 38.1356 12.7119
2 461.8575 34.9231 6.5481
3 199.3335 11.8146 6.9676
To view a subset of the package’s her2 test set:
> testset[1:3,1:3]
NPTXR_23467 DOCK3_1795 LOC400927_400927
1 304.5058 21.0756 0.7267
2 453.4778 10.1620 7.5072
3 510.8080 3.5776 4.9292
To classify instances/determine her2 status of the test samples using median-supplement Random Forest, the following apply:
> Predictions <- MSclassifier(her2,testset = testset, method ="MSRandomForest")
> head(Predictions)
Sample1 Sample2 Sample3 Sample4 Sample5 Sample6
Negative Negative Positive Negative Negative Negative
Levels: Negative Positive
To analyse median-supplement Random Forest for error matrix, here is a sample:
> Model <- MSclassifier(her2, testset = NULL, method = "MSRandomForest")
> predictions <- predict(Model, newdata = testset)
> head(predictions)
1 2 3 4 5 6
Negative Negative Positive Negative Negative Negative
Levels: Negative Positive
> table(predictions, testset$her2_status)
predictions Negative Positive
Negative 47 10
Positive 4 1
To classify instances/determine her2 status of the test samples using median-supplement Naive Bayes, here is a sample:
> Predictions <- MSclassifier(her2,testset = testset, method = "MSNaiveBayes")
> head(Predictions)
Sample1 Sample2 Sample3 Sample4 Sample5 Sample6
Negative Negative Positive Negative Negative Negative
Levels: Negative Positive
To analyse median-supplement Naive Bayes for error (confusion) matrix, the following is an example:
> Model <- MSclassifier(her2, testset = NULL, method = "MSNaiveBayes")
> predictions <- predict(Model, newdata = testset[,-ncol(testset)])
> head(predictions)
[1] Negative Negative Positive Negative Negative Negative
Levels: Negative Positive
> table(predictions, testset$her2_status)
predictions Negative Positive
Negative 51 8
Positive 0 3Data sets. In order to illustrate the performance of the package, we use two real datasets. Particularly, the first data, obtained from previous study17 describes gene expression measurements in breast cancer. In this illustration, median-supplement models are inferred with the MSclassifier package to assign classes to new instances of the test set. In the case of the HER2 data, the class of each instance is the expressed receptor status phenotype while attributes are the relevant gene expression profiles. The data consists of 86 HER2 receptor-negative and 14 HER2 receptor-positive samples. These are samples included in the MSclassifier package.
The second (larger) dataset was derived from a study that characterized amino acid sequences of human proteins localized in nine cellular compartments21. Code written in LISP was used to determine values of physicochemical properties of proteins known to be primarily localized in the designated subcellular locations were used. Protein properties used are based on the amino acid composition (including hydrophobicity, normalized van der Waals volume, polarity, polarizability, and charge), transitions and distribution as detailed21. For instance, "PERCENT-R" is a reference to the percentage of arginine residues in the primary sequence of amino acids of a protein; "HYDROPHOBICITY-PERCENT-GROUP1" is a reference to the percentage of polar amino acids in the primary sequence of amino acids (i.e. group 1 amino acids are polar, group 2 amino acids are neutral, and group 3 amino acids are hydrophobic); "POLARITY-GP1-GP3-TRANSITIONS" is a reference to the frequency of transitions between low polarity residues (L, I, F, W, C, M, V, and Y) and high polarity residues in a given protein’s primary sequence of amino acids (H, Q, R, K, N, E, D). The data comprised of 2635 instances and 126 attributes. Among the instances, 1589 were associated with (localized in) the plasma-membrane and 1046 were associated with the nucleus22. In its usage to illustrate the package, instances of the dataset were classified as "nucleus" and "plasma-membrane".
Performance measures of packages. The performance of each method is determined by its classification rate: proportion of correctly classifying instance given by the ratio of correctly classified test instances to the total number of test instances23. In general, the classification rates agree with measures of accuracies of such classification methods. Higher classification rate of a method indicates that the package has higher chances of making accurate assignments of samples to their respective classes. Therefore, it is desirable to have higher classification rate. For instance, a higher classification rate for classifying receptor status phenotypes in breast cancer indicates the method has high sensitivity for deciphering the particular receptor status. This is because the sensitivity is also a proportion of correctly classified instances among characterized instances as exemplified in unsupervised learning systems24. Furthermore, Mann-Whitney tests are performed to evaluate differences among classification rates of the methods. Both independent and cross-validation testing methods are used to evaluate the packages22. While a 10-fold cross-validation is applied to the HER2 data, a 5-fold cross-validation is applied to the subcellular localization of proteins data22.
In this experiment, HER2 training and test sets made available in the package were used. It was found that the median-supplement Naive Bayes (MNB) implemented in MSclassifier outperformed all the other methods considered in this case (Figure 2). This was to be expected since the MSclassifier implements median-supplement methods, which have been shown to outperform the traditional machine learning methods17. Higher performance of this package on this test example is the result of the enhanced median-supplement training set from which MSclassifier infers models. Thus the enhancement makes more instances available to train models.
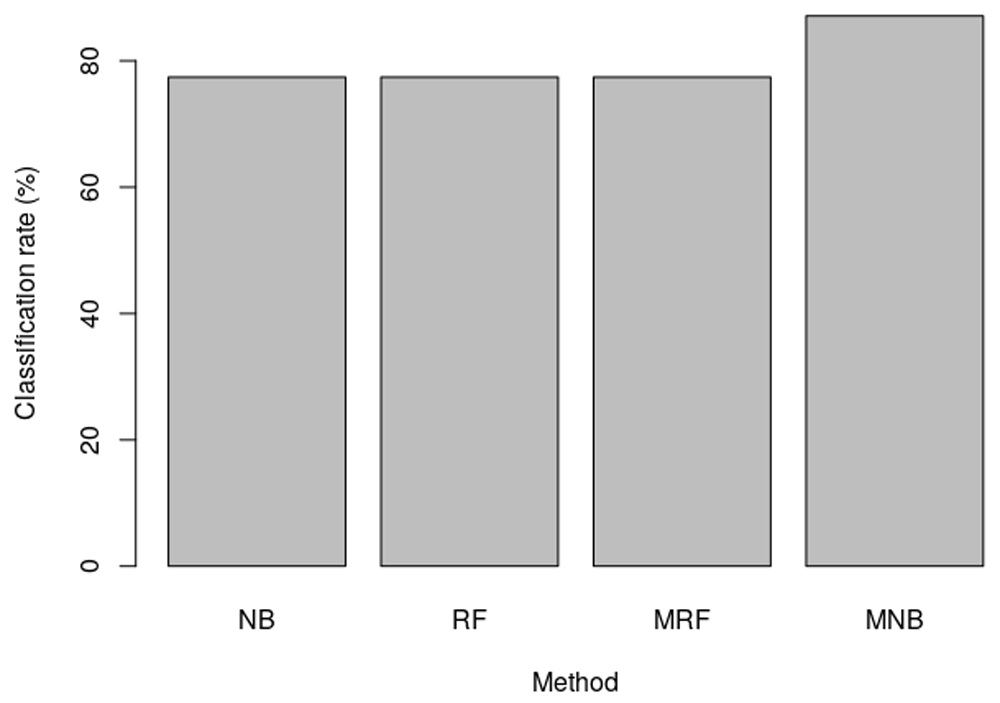
NB is Naive Bayes, RF is Random Forest, MRF is median-supplement Random Forest and MNB median-supplement Naive Bayes. While both MRF and MNB are implemented in MSclassifier, NB is implemented in e1071 and RF is implemented in randomForest packages.
The classification rates of conventional methods, implemented in existing packages, ranged between 83% and 91%, methods implemented in the MSclassifier had values with minimum of 87% and maximum of 91%. Particularly, it was found that conventional random forest was significantly higher than the Naive Bayes (mean classification rate of 89.83% versus 85.43%, p = 1.48e-11). However, the median-supplement Naive Bayes implemented in MSclassifier achieved the highest classification rates among all the methods22. More importantly, it had significantly higher classifications rates than the random forest method (mean is 90.30% versus 89.83%, p = 8.62e-3). These results are consistent with performance of median-supplement methods on HER2 classifications studied earlier17.
With regards to the prediction of subcellular localization of proteins, although both MSclassifier and the other packages could attain equally high classification rates (94%) in this test, the minimum classification rate achieved by the median-supplement Naive Bayes was lower compared to the conventional Naive Bayes method (mean of 69% versus 86%, p = 4.55e-14). However, this observation was different in other studies17. The difference is attributable to the differences in data and prediction tasks. Nevertheless, these performances are suboptimal when compared to the random forest-based methods which achieved mean classification rates of 93%22. Specifically, the performances of both the random forest and the median-supplement random forest were statistically indistinguishable (mean of 93.42% versus 93.19%, p = 0.06). These results are indicative that tree-based random forest methods have better performances on larger datasets. However, the superiority of median-supplement methods over several other machine learning methods when applied to predict hormone and HER2 receptor phenotypes underpinned in the literature17. These results demonstrate the potential of MSclassifier to better predict instances of binary classifications problems.
We have presented the MSclassifier package to implement median-supplement approaches for machine learning to support medical decisions. The package was shown to decipher HER2 receptor status phenotypes in breast cancer and also predict subcellular localizations of proteins. MSclassifier compares favourably well with existing packages because it implements enhanced methods which offer effective approach to machine learning. Finally, MSclassifier can be installed and run on most operating systems. The sole requirement is the availability of a recent version of R. MSclassifier, steps for installation and other supplementary information are freely available at https://nweb.gimpa.edu.gh/schools/school-of-technology/software/MSclassifier/. Furthermore, the MSclassifier package and every other supporting data for this work have also been made publicly available at https://doi.org/10.5281/zenodo.394667522.
Software available from: https://nweb.gimpa.edu.gh/schools/school-of-technology/software/MSclassifier/
Source code available from: https://github.com/esadabor/MSclassifier.git
Archived source code as at time of publication: https://doi.org/10.5281/zenodo.394667522
License: GPL-3
Datasets used in Use Case:
- Gene expression measurements in breast cancer, obtained from previous study17. Dataset available here: http://doi.org/10.5281/zenodo.396451425 (permission to reuse this dataset and to republish on Zenodo has been granted by Oxford University Press).
- Characterized amino acid sequences of human proteins localized in nine cellular compartments, obtained from previous study21. Dataset available here: http://doi.org/10.5281/zenodo.396450326. Protein subcellular localisation dataset available here: https://doi.org/10.5281/zenodo.394667522.
Zenodo: Supporting information and data for MSclassifier: Median-Supplement model-based Classification tool for automated knowledge discovery, https://doi.org/10.5281/zenodo.394667522.
This project contains the following extended data:
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)