Keywords
precision medicine implementation, omics technologies, implementation measurement, differential item functioning, item response theory
precision medicine implementation, omics technologies, implementation measurement, differential item functioning, item response theory
Recent advances in omics technologies offer greater understandings of how gene-environment interactions affect health and pathological processes. Omics-based biomarkers (OBMs) resulting from advances in biomedical technologies form the basis of precision medicine (PM), an approach to medicine that emphasizes predictive, preventive and personalized medical care1. Deep insights gained in systems biology, molecular evolution and microbial environments is increasingly being applied in clinical settings through OBMs, with huge biomedical, clinical and public health implications. For instance, due to broadening understanding of the complex genotype-lifestyle-environment interactions, how biomedical research evidence is collected and applied is changing to reflect a shift from “average many” to “unique few” approach to health interventions. Evidence-based medicine (EBM)2, the widely applied and accepted approach to medicine, is mostly informed by systematic reviews, meta-analyses or group-level studies from which average recommendations for the “average person” are derived. However, this “one-size-fits-all” approach has severe limitations in that it does not adequately cater for uniqueness in individuals, neither does it consider disease heterogeneity in larger populations. Although most people may be accounted for within some average categories, yet many others are ‘outliers’, falling outside recommended mean estimates. Although understanding individual-level underpinnings of health and disease at finer resolution may be overwhelming in practice, PM provides a shift away from the generalized average protocols to personalized strategies in medical care. Moreover, PM, through OBMs and other biotechnologies, enables better disease delineation and patient stratification. In emphasizing individual uniqueness at the molecular level and tailored care based on uniqueness of genotype, PM also enables advanced detection of pre-symptomatic conditions in the population and individuals, while improving surveillance and management of infectious diseases. This results in better-adapted and personalized therapies, significantly delayed disease onset, as well as disease prevention.
However, while interventions associated with PM, including cell-, gene-, and tissue-engineered therapies3 are highly personalized in nature, their clinical validity and utility is generally limited. This lack of adequate clinical utility implies that in PM, the boundary between research and practice is blurred as opposed to the traditionally more pronounced research-practice boundary in EBM. Despite mounting evidence supporting the value of OBMs in improving health outcomes (e.g., Berg AO4), the moving-target nature of most genomic-based interventions implies that the evidence base for PM must constantly be updated as more knowledge is gained over time. Implementation of PM therefore inevitably juxtaposes biomedical research and clinical practice elements, implying co-existence of both research and practice settings. Although such co-occurrence settings create novel opportunities to advance medicine through PM, little is currently known about the nature and implications of such research-practice partnerships, especially for PM implementation at health systems level.
We assessed a PM implementation (PMI) measurement model using a latent variable approach informed by item response theory (IRT). The study constructed four variables (factors) that were hypothesized to have varying influences on PM implementation at health systems level. These were: 1) Characteristics of omics biomarkers; 2) Organizational support in terms of resources required for implementation; 3) Public genomic awareness; and 4) precision medicine implementation outcomes. OBMs are biological disease- or health- status indicators gleaned from genomics (gene structure and sequencing), epigenomics (gene expression via transcriptomics)5, proteomics (RNA products)6,7, metabolomics ( metabolites) and DNA-based tools that detect bacteria, parasites and viruses that coexist in the human body through metagenomics8. Despite apparent advantages associated with omics biomarkers, varying perceptions about their effectiveness persist, largely due to less-conclusive clinical validity. Concerns around OBMs include questions around the biomarkers’ reliability, interpretation of test results and quality standards9. Based on existing literature, six items were selected as indicators for the ‘Omics Biomarkers’(OBM) construct as illustrated in Table 1. Organizational support relates to resource investments required to move OBMs from point of discovery to point of clinical application. For instance, material and non-material investments are needed to continuously update existing biomedical knowledge including new algorithms and bioinformatics methodologies, as well as high-velocity and high-capacity computation facilities. Resources are also required in compliance with good practice in genomic data governance through optimized data capturing, storage, transfer and processing. Organizational support, therefore, is a factor that can influence PM implementation outcomes. Six items were selected as its indicators (Table 1). On the other hand, although use of biomarkers is beneficial in circumstances such as identifying susceptibility for inherited conditions, this often implies genetic profiling, which can lead to anticipation, skepticism and concern at the personal level10,11. Individuals, empowered through publicly available information prevalent in social media and other connected technologies, may advocate for adoption of certain biomedical technologies. They may also manifest willingness to participate in genomic studies, as they appreciate relative importance of doing so not only for themselves but for public good in general. Therefore, the level and quality of public genomic awareness give rise to differing genomic attitudes, perceptions and values among members of the public, both as individuals and as health providers. Six items were selected to be indicative of ‘Public Genomic Awareness’, as seen in Table 1. Finally, the PM implementation outcomes factor captures the long-term goal of PM implementation efforts: improved uptake and routine use of OBMs in healthcare. Four items were selected as measures of the construct ‘Implementation Outcomes’ (Table 1).
As omics-based technologies gradually move into clinical settings, a co-occurrence of biomedical research and clinical practice is likely to present as an important variable in the implementation of PM. This co-occurrence, however, is complicated by potential differential interpretation of factors that affect or influence PM implementation. Modern psychometric tools offer reliable means of assessing item-level measurement variability that focus on differential item functioning (DIF)12. DIF has been defined as a measure of different probabilities of success or endorsement across construct while controlling for the underlying trait being measured13. DIF represents unequal response patterns among groups, which can profoundly threaten research findings, as it may constitute bias. To assess this kind of differential item functioning in PM, this paper sought to establish a PM implementation measurement tool’s differential item functioning (DIF) across two study participant sub-groups; one affiliated to academia (representing research) and the other affiliated to industry (representing practice). In as much as measurement variability due to sub-group membership - irrespective of the construct being measured - has often been underscored in other disciplines14, it is important to assess the same in the new field of PM. Item-level invariance assessment entails a valuable exercise as it serves to test what may often be implicit assumptions concerning much measurement processes15. Furthermore, such assessment will help curtail a number of problems including errors in hypothesis testing, flawed population forecasts and policy planning16 in relation to PM implementation. The study also confirmed the tool’s psychometric reliability and construct validity.
Table 1 shows the four PM implementation factors (latent variables) and items that measure them.
This was a cross-sectional study that employed analytical approaches for quantifying factorial relationships. DIF analysis helped to reveal differences in perceptions towards PM implementation between two study participant subgroups: one affiliated to academia and the other affiliated to industry. Item response theory (IRT) is one of the widely used methods for assessing DIF. In this study, IRT allowed for a critical examination of the information that was harvested from the manner study participants endorsed and ranked the various items associated with PM implementation. As noted earlier, DIF examines the probability of endorsing an item conditioned on the latent trait. This method was deemed suitable for examining DIF in this study as IRT examines the monotonic relationship between responses and the latent trait17. Furthermore, as compared to classical test theory, IRT parameter estimates are not only as confounded by sample characteristics, but statistical properties of items can be expressed with greater precision, thereby increasing the interpretation accuracy of DIF between sub-groups18.
Members of “academia” were defined as individuals involved in biomedical research that related to translating newly discovered molecular or omics-based biomarkers (OBMs) for purposes of clinical or population health use. Members of “industry” were defined as individuals involved in the clinical use of the biomarkers or those involved in commercialization activities related to OBMs (e.g., Direct-To-Consumers Genetic Testing, DTC-GT)19. “Precision medicine implementation” was defined as the process of translating newly discovered omics-based biomarkers (OBMs) for clinical or population health use. “OBMs” were defined as candidate genetic biomarkers that are in the process of being clinically validated or those already validated and in clinical use.
The snowball sampling method, a non-probability sampling method, was applied in identifying potential study participants from population of interest. Inclusion was based on a participant’s affiliation to either an academic institutions or a commercial entity (industry); the institution or organization had to be involved in molecular/genetic testing and/or omics-based biomarkers in Africa; a participant had to be involved in the field of precision medicine and/or biomarker-related biomedical research as indicated by contribution to the field through publications in peer-reviewed journals and/or attendance of related academic conferences. It is well known that snowball sampling poses significant recruitment “community bias” risk whereby recruitment of new members does not branch out from the sample subgroup of individuals initially accessed. In the present study, this risk of source bias was addressed by properly selecting the initial individuals to ensure proportional inclusivity of subgroups in the seed (initial) sample. Consequently, the seed sample was identified and selected from a precision medicine-related conference; an event we regarded as representative of our study population as it brought together diverse groups from academia and industry involved in precision medicine and its implementation in resource-constrained settings. Therefore, the probability of selection bias for subsequent in-link recruitment waves of study participants was negligible. Besides, it has been shown that with an appropriate bootstrap resampling, selection bias due to the initial seed sample (if known to be representative of the targeted population) is progressively attenuated as the sample expands wave by wave20,21.
Guided by general principles of the Nuremberg Code, the Declaration of Helsinki and institutional review board permit obtained from the University of KwaZulu-Natal (BREC Permit Ref No BE513/18), a study package was distributed via email to potential participants between June and July 2019. Since this study contained negligible risk of potential embarrassment or other ethical dilemmas that are usually associated with snowball sampling in many other studies, initial participants were encouraged to forward the email containing the study package to their colleagues. The study package (available as Extended data)22 included an invitation letter with study description, consent form and a link to the online card-sort platform. A total of 31 study participants were recruited for the study. Although there is no definitive number for a pilot study sample size according to Hunt, Sparkman and Wilcox23, to increase statistical power and degrees of freedom for our study, we applied a Monte Carlo simulation (MCS) approach as described by Mooney24. MCS studies are computer-driven experimental investigations in which certain parameters, such as population means and standard deviations that are known a priori, are used to generate random (but plausible) sample data24. This method of generating and analyzing data treats the collected research sample as a “population reservoir” from which a large number of random samples are drawn with continuous replacement such that the probability of selection for any given case remains equal over every random draw25. We requested 2,000 iterations, drawn with replacement from the original data set of 31 cases (our empirical sample).
A card-sort task approach26 was used to obtain comparative item-rating data. Respondents were presented with a set of cards that contained constructs clearly defined using everyday language and a set of categories onto which the concepts on the cards were to be mapped, as explained by Angleitner, John, & Lohr27. The respondents were asked to read each item and assign it to the construct or concept it best indicated, in their judgment. Participants were required to rank the cards according to their own understanding and preference, indicating their perception on concepts presented on each card. If participants deemed it necessary to make any changes as to where a card previously assigned should be reassigned to, they could do so. Although simple in practice, this exercise generated enough data that was used to assess the desired group perception levels, construct validity and scale reliability. The actual sorting of the items was, however, performed using an online platform hosted and supported by Optimal Workshop28. The items are presented in Table 1. Besides offering convenience to study participants, the online platform enhanced data security and confidentiality. A total of 22 items were to be assigned into four categories initially provided for, with participants allowed to create own separate construct categories if they so desired. The results about number of items per category and the items’ ranking order (positioning) within their respective categories were then extracted and analyzed. Participants’ demographic data were also extracted, including sex, highest educational qualifications and age. Data was subsequently subjected to item response theory (IRT) analysis29,30 with logistic regression modelling.
In summary, the data are an output of an exercise where respondents were required to place items arranged as cards into specific categories and ranked in order of perceived importance. The cards related to specific attributes indicative of wider factors thought to influence precision medicine implementation at health systems level. This meant that if an item on the card was regarded as the most important in each category, it was ranked 1st, and the next ranked 2nd and so on. If a card was not placed in a category, it was scored zero in that same category. For compactness and statistical purposes, the data was formatted to have one observation per row (for 31 participants, there were 31*4 = 124 observations).
One of the assumptions in item response theory (IRT) model analysis is that factors are generally unidimensional31. Therefore, to examine differences in perception between the two sub-groups (academic and industry) related to each item in the PM implementation scale, DIF was tested within each subscale. Each of the four factors that were identified as influencing PM implementation correspond to a subscale. Thus, four sets of tests were conducted with each of the four factors (sub-scales) examined separately for both item response functions (IRFs) and unidimensionality. To determine and confirm sub-scale unidimensionality, we used R package “mokken” version 2.8.1132. In this study, scale reliability referred to the consistency of measurement, while construct validity refers to the extent to which a set of indicators that were devised to gauge the four constructs (OBM, OrG, PGA and ImO) really measured that construct. Differential item functioning (DIF) was defined as a property of an item that shows the extent to which the item might be measuring different dimensions of the variable it was supposed to measure for members of separate subgroups. We applied the ordinal logistic regression modelling function in the package “lordif” (logistic ordinal regression differential item function) using IRT, version 0.3-3)33 in R version 3.6.134. The package “lordif” provides a logistic regression and IRT framework for detecting various types of differential item functioning33. We preferred it because it could adequately handle the item-sort-and-rank data that we used. To analyze DIF in the scale, we devised three models. The first of the three models distinguish DIF and non-DIF items. The second model identifies uniform-DIF items that occur due to an item tapping a dimension of the attribute measured in the scale that manifests differently between the groups. That is, for uniform DIF, whereas the probability of endorsing an item at a certain ranking is greater for one group than the other, this is uniform over all levels of knowledge of the factors under consideration. Finally, the third model identifies non-uniform DIF; that is the probability of endorsing an item at a certain ranking is greater for one group than the other, but this is not uniform over all levels of knowledge of the factors under consideration. This may be because of distracting elements (not necessarily related to the scale) in the measurement process, such as different understandings of a word or phrase used on the item35.
These three models can be summarized as36:
logit(P(U = 1)) = β0 + β1θ + β2g + β3θg (Model 3: Non-uniform DIF)
logit(P(U = 1)) = β0 + β1θ + β2g (Model 2: Uniform DIF)
logit(P(U = 1)) = β0 + β1θ (Model 1: No DIF)
where:
(P(U = 1)) is the probability of endorsing an item at a particular rank in a category,
θ is the participant’s latent perception level on the factor the item is measuring,
g is the group to which the participant belongs (academia or industry).
We used two sets of logistic regression-based criteria for detecting DIF: one set based on statistical significance (likelihood ratio χ2 tests) and the other on Pseudo R2 magnitude (Nagelkerke's and McFadden’s pseudo R2). Uniform DIF was examined by comparing the log likelihood of model 1 with 2 (degree of freedom (df)=1) and non-uniform DIF by comparing model 2 with 3 (df=1).The comparison between model 1 and model 3 (df=2) detected the total DIF effect—both uniform and non-uniform DIF36,37. Items that revealed significance in any of the three likelihood ratio χ2 tests with an alpha of 0.25 (Model 1 versus 2, Model 2 versus 3, and Model 1 versus 3) were flagged as having DIF. To examine the magnitude of DIF, we used various pseudo R238,39 such as Nagelkerke's Pseudo R2 and McFadden’s pseudo R2 statistics for the defined model comparisons, and applied Zumbo et al.’s guideline to evaluate R240: effect size was regarded as negligible DIF (pseudo R2 < 0.035), moderate DIF (0.035 ≥ pseudo R2 < 0.070), and large DIF (pseudo-R2 ≥ 0.070).
For individual participants, the difference between the DIF-adjusted (purified) subscale score and the initial unadjusted score for each subscale. Finally, we obtained item and subscale characteristic curves to show the impact of DIF for each group, i.e. item parameter estimates were computed and graphically examined via item characteristic curves (ICCs) and other graphs. R code used to calculate DIF is available as Extended data41.
Descriptive statistics that were obtained for the data included analysis of outliers, which was defined as any value that is greater than three standard deviations above or below the mean. Multivariate skewness and kurtosis statistics of the data were assessed using R package ‘psych’ version 1.8.1242.
Skew values ranged from 1.21 to 2.41 while kurtosis (k) statistics for 21 items ranged from -0.37 to 2.49, with the 22nd item indicated at k= 5.87. Figure 1 is a quantile-quantile (Q-Q) plot formed by the data and shows the distribution of the data against the expected normal distribution. Since the observations seemed to approximate a straight diagonal line with minimal deviations, we concluded that our data has a general normal distribution. Despite one item being an outlier with k = 5.87, its inclusion in the data set did not alter results, and therefore all items were included for further analyses.

The data did not contain any missing values because all the fields of the online item sort tool for data collection were set as “required” to eliminate non-responses. Underlying data are available at Zenodo22.
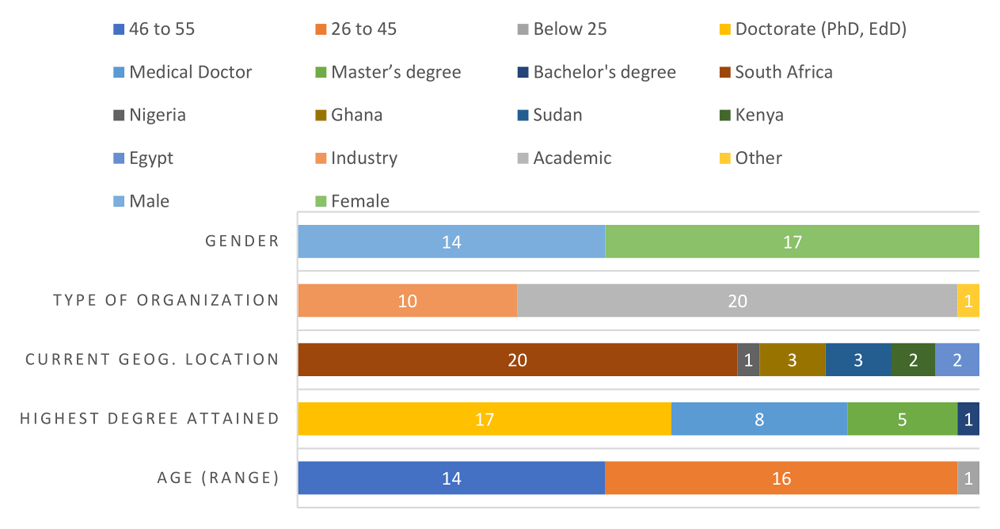
Of the 35 participants invited and who attempted the item-sort exercise, 31 successfully completed it (88% response rate). There were three more female participants than males (10%). Those with research qualifications (PhDs and equivalent) were the majority (55%), while slightly a quarter of the participants were medical doctor. The rest of participants’ qualities varied greatly and are summarized in Figure 2.
The correlogram in Figure 3 is an inter-item correlation plot indicating item and scale structure in the data. In the upper triangle, positive correlations are displayed in blue and negative correlations in red colored circles. Color intensity and the size of the circle are proportional to the correlation coefficients, helping to identify “groups” of variables that share a strong relationship with each other (hierarchical clustering). The lower triangular correlation matrix displays the actual correlation values.

Each item seems to fit into one of the four well defined clusters (Figure 3), implying four factors defined the data as hypothesized. Items x16 (“Using this genetic/omics test has been regarded by practitioners as an appropriate mechanism for patient management (e.g. aid in drug dosage decisions, in carrying fetuses to term or carry out prophylactic surgery)”; and x20 (“Practitioners are more willing to order the genetic/omics test more often whenever deemed necessary”) are the only items not showing a strong correlation within the groups they belong.
To confirm the suggested four factors in the variable correlation matrix, we performed further scale analysis using functions in the “mokken”43 R package. Four unidimensional scales were identified as dimensionality solutions via the package’s automated item selection algorithm (AISP) performed at factor loading ≥0.3 and Type I error level (α)=0.05. Table 2 shows the results of this procedure and various reliability associated with each factor (subscale).
Key: MS=Molenaar Sijtsma statistic (a.k.a. rho); Alpha=Cronbach's alpha; Lambda.2=Guttman's lambda.2; OBM=Characteristics of omics biomarkers construct; OrG=Organizational support construct; PGA= Public genomic awareness construct; ImO = PM implementation outcome construct. ‘Chi12’, ‘Chi13’, and ‘Chi23’ denote the likelihood ratio χ2 statistic between Models 1 and 2, Models 1 and 3, and Models 2 and 3, respectively; R12, R13, R23 indicate Nagelkerke's pseudo R2 from comparing Models 1 and 2, Models 1 and 3, and Models 2 and 3, respectively. Scale dimensionality solution was obtained by the automated item selection algorithm (aisp).
Sub-scales were demarcated by means of scalability coefficients44 as indicated by the coefficient H in Table 2. At the lowest scalability threshold of 0.3, four unidimensional subscales were identified through the AISP. AISP is a scaling method of item selection we applied to partition the 22 items into subscales. This implies that there were four latent factors (subscales) measured by the 22 items (i.e., four underlying variables explain the association between latent factors and responses to items). Unidimensionality ranges between H=0 and H=1: strong unidimensional scale has H ≥ 0.5, moderate 0.4 ≤ H < 0.5, and weak 0.3 ≤ H < 0.444. The four subscales’ coefficients H ranged between H ≥ 0.5 and H = 0.8, implying the subscales were strongly unidimensional. This was strongly supported by the reliability indices (Mokken’s rho, alpha and Guttman’s lambda-2 (λ2)) which indicated high internal consistency (internal validity/goodness-of-fit) for the four subscales. Cronbach's α, the expected correlation of two tests that measure the same construct, was separately obtained for the four constructs. All four subscales had coefficient alpha (α) ranging between 0.76 and 0.95 (with an average α =0.88). Besides, given that internal scale consistency (intercorrelations among items) is maximized when all items in a subscale measure the same construct, we concluded that the high Cronbach's alpha values for our subscales are an indirect but confirmatory indicator of the degree to which the items in the subscales measure corresponding unidimensional latent construct. However, Cronbach's alpha has been found to have limitations in measuring reliability in some instances45–47. Due to this concern, we obtained other reliability indices for the same purpose as described below.
Guttman’s λ2 is a reliability estimate that is more robust than Cronbach’s alpha, i.e., more resistant to outliers. The range of λ2 values for the four subscales were: 0.81 ≤ λ2 ≥ 0.96. This implies that more than 80% of variance in each of the subscales is attributable to the true score and less than 20% to error, confirming that the internal construct validity and scale reliability is good. On the other hand, Mokken’s rho, considered to be an improvement in relation to Cronbach’s alpha and whose values should exceed 0.70 to show adequate scale reliability48, was obtained. As shown in Table 2, all the four subscales had their rho (MS) coefficients above 0.78, confirming good scale reliability.
Table 2 also shows DIF detection outcomes using logistic regression approach33. DIF items revealed from the likelihood ratio χ2 tests are indicated with asterisks in Table 2. Of the 22 items making up the PM implementation (PMI) scale, 13 were flagged as DIF items at α=0.25 with MCS set at 2,000. They all showed statistical significance for total DIF effect test when comparing Models 1 and 3. Of the 13 DIF items however, seven were indicated as mixed DIF items. Their likelihood ratio χ2 test comparisons between Model 1 and 2, and models 2 and 3 were statistically significant. Moreover, of the remaining six, five had non-uniform DIF (x1, x4, x9, x16 and x20); the comparisons were statistically significant for Models 2 vs 3 as compared to Models 1 vs 2. Only one item had uniform DIF (x19): it showed non-significant comparisons for models 2 vs 3 but significant comparisons for models 1 vs 2. However, using the same statistical significance test, all items were DIF flagged at α =0.5 and non at α =0.01. This finding indicates the effect of statistical significance levels in DIF detection.
However, in contrast to the likelihood ratio χ2 tests that detected 13 of the 22 items as DIF-positive, Nagelkerke's Pseudo R2 statistics flagged only five items as DIF (x1, x4, x7, x10 and x12). These were all moderate DIF (0.035 ≥ pseudo R2 < 0.070). To verify this result, we inspected other pseudo R2 statistics, such as McFadden’s and Cox and Snell’s R2. The additional pseudo R2 indices also yielded similar values.
From the above analyses, we generated various graphs. However, due to space constraints, we present only those graphs related to characteristics of omics biomarkers (OBM construct). Diagnostic plots are used below to describe the relationship between the perception latent trait and the probability of responding positively to an item as observed from the data (positively here means endorsing an item in any of the four scales). Participant’s perception trait level is signified by theta (θ).
The top left plot in Figure 4a shows item true score functions based on group-specific item parameter estimates. It shows the item characteristic curves (ICCs) for the item for industry vs academia affiliated participants represented with red dashed and black solid lines respectively. The slope of the function for industry group was substantially higher than that for academia group, indicating non-uniform DIF. The upper–right graph shows the absolute difference between the ICCs for the two groups, indicating that the difference is mainly at high levels of perception of omics biomarkers (especially between average (0) ≥ θ ≤ +3). The lower-left graph shows the item response functions for the two groups based on the affiliation–specific item parameter estimates (slope and category threshold values by group, as also printed on the graph). It juxtaposes the item response functions for academia and industry groups. The non-uniform component of DIF revealed by the LR χ2 test can also be observed in the difference of the slope parameter estimates (33.46 vs. 2.75). The lower-right graph shows the absolute difference between the ICCs (the upper-right graph) weighted by the score distribution (size) for the focal group, i.e., industry group, indicating minimal impact.

(a) Graphical display of the item “X1:The omics test has been used among people similar to the present target population” which shows non–uniform DIF with respect to affiliation to either academia or industry. (b) Box-and-whisker plot and a scatter plot showing (individual-level) differences between initial and purified scale scores for each respondent. (c) Impact of DIF items on test characteristic curves (TCC) for all items and DIF items. (y-axis = sum of the item scores of the OBM domain; x axis (theta) = knowledge of OBMs). (d) Smoothed histogram showing perception differences towards omics biomarkers between those affiliated to academia and industry.
Figure 4b displays the boxplot and a scatter plot that show DIF items as unique to each group, accounting for DIF in trait estimates. It shows the difference in latent trait level between the initial IRT-based trait estimate with ignored DIF items and the purified trait estimate with DIF items accounted for. Each (black) circle and (red) triangle stand for the latent trait estimate of the OBM domain for a single participant. It also shows the expected amount of change in latent trait estimates when DIF is accounted for. Accounting for DIF items in a multi-item scale is commonly referred to as “scale purification”. In both graphs, the y-axis is the difference (initial – purified) and the x-axis on the right graph is the initial latent trait level. The Box-and-Whisker plot on the left shows that median difference was around -0.04, and the middle 50% of respondents, depicted as the box (i.e., the interquartile range)ranged from approximately -0.04 to 0.07, indicating a fairly normal but slight right-skewed distribution with possible outliers at high ends (θ above average). The scatter plot on the right shows the initial (no DIF) vs purified (DIF accounted for) difference against the initial latent trait level that ignored DIF, implying that across the entire latent trait continuum, those participants who were affiliated to industry (red triangles) show more positive difference, further suggesting that accounting for DIF leads to lower scores for them compared to initial (non DIF) scores; for those affiliated to academia, (dark circles), the pattern is in the opposite. Guidelines are placed at 0.0 (solid line), i.e. no difference, and the dotted horizontal reference line is drawn at the mean difference between the initial and purified estimates.
What is suggested in Figure 4b corresponds well with Figure 4c, the test characteristic curves (TCC). The y-axis of Figure 4c indicates all possible scores for domain “OBM”. Figure 4c indicates a clear difference in TCC curves, albeit in small margins, of DIF item responses between academia and industry groups. On the other hand, the left graph for all items displayed a much smaller difference than the right graph of Figure 4c. This can be explained as the DIF impact being diluted by the non-DIF items, resulting in the overall score difference between the two groups becoming minimal. It is evident that at average knowledge levels (θ = 0), the scale performs better among those affiliated to industry than academia. But at higher trait levels (θ ≤ +2), industry lags behind academia.
Finally, Figure 4d shows smoothed histograms of the omics biomarkers perception (knowledge) levels for those study participants affiliated to industry (dashed red line) and academia (solid black line) as measured by the OBM subscale (theta). Industry affiliated participants on average had lower mean scores than their academia-affiliated counterparts, although there is a broad overlap in the distributions.
Items related to public genomic awareness (PGA) appear to have the least DIF. In contrast, all the factors (characteristics of omics biomarkers (OBM), organizational support (OrG) and precision medicine implementation outcomes (ImO)) had a substantial number of items flagged for DIF. There were two types of DIF items that identified in this study: uniform and non-uniform. The only item shown to have uniform DIF on the scale was item x19 (“The genetic/omics test is yet to be used as a routine practice within its intended service setting”); implying that one subgroup was consistently more likely than another to endorse this item at each level of the measured trait. Five items that showed explicit non-uniform DIF implied that there was inconsistent pattern of response; i.e., one group crossing-over, so that at certain levels of the trait, one group was more likely to endorse the item, while at another level, the other group was more likely to endorse the same item. Public genomic awareness is closely related to social and ethical nuances of research in precision medicine49,50. PGA focuses on ethical questions ranging widely: from social justice issues regarding healthcare equity and access to specific questions regarding consent, safety and public acceptability of genomic technologies. The level of omics technology acceptability among practitioners (physicians) is another aspect of PGA51. Our study findings agree with other findings in literature that focus on genomic engagement with public and practitioners49,50,52,53. The PGA non-DIF items indicate deep-cutting agreement across study participants on the likelihood of inadequate genomic knowledge and genetics personnel to deal with issues surrounding ethical, legal and social implications of advancements in precision medicine. The fact that both subgroups (academia and industry) mostly agreed on most PGA aspects suggests that in a research-practice partnership designed to advance PM, both groups are likely to have similar outlooks towards ethics and genomics such as the balance between health gains and possible loss of privacy which may warrant sensitive, ongoing attention. The non-DIF items about PGA among study participants also suggests overwhelming support for community consultation and involvement where clinical implementation of omics technologies is concerned.
Assessment of invariance of chosen measurement models across subgroups is likely to emerge central to policy efforts that assess optimal ways of implementing PM at national health system level. This study has helped show the critical importance of a measurement tools’ psychometric evaluation and how DIF analysis can play a vital role in implementation decisions. For instance, depending on the statistical procedure used for DIF detection, differing results may be yielded. Thus, one procedure may indicate DIF for certain items while others do not. The present study’s findings, however, have another policy implication: in as much as evidence of DIF may play a vital role, it should by no means be the sole basis for policy decisions and conclusions. Presence of DIF may be an indication of problematic items that need to be revised or omitted and not necessarily an indication of sub-group irrationality. Therefore, DIF analysis can be considered a useful tool for item analysis but is more effective when combined with robust reasoning. Another consideration in the face of DIF in a measurement model is that a sub-group’s domain score should be interpreted in a way that corrects for the measurement bias. This can lead to two policy implications: either to develop subgroup norms or to understand why DIF items occur in the first place and then to later revise and improve DIF items of the measurement model.
More generally, precision medicine combines both practice and research components. The relationship between academic research and clinical practice in precision medicine is, however, not easy and straightforward. In as much as public health and clinical practice through PM may benefit from advances in omics technologies and deeper gene-environment insights that flow from rigorous biomedical research, research also benefits from being informed by practice problems and practical knowledge, leading to co-creation of solutions to broader PM issues in both spheres.
This study assessed latent traits (factors) that relate to precision medicine implementation using a newly formulated implementation measurement scale in order to validate the scale’s general reliability and construct accuracy. The findings demonstrate general conceptual and psychometric measurement equivalence of the scale across two subgroups involved in PM implementation: academia (research) and industry (practice). Differential item functioning (DIF) analysis was used to study the performance of the 22 items of the PMI measurement scale, examining whether the likelihood of item (categorical) endorsement is equal across the two subgroups as matched on the measured trait. Even though there were no DIF flagging at statistical significance of α=0.5, DIF analysis at α=0.25 revealed the presence of some DIF items in the scale. There were two types of DIF items that were pointed out in this study: uniform and non-uniform.
Moreover, the study delved into the assessment of statistical basis of the measurement model as well as providing various indices such as scalability, reliability and unidimensionality. All four subscales showed strong scalability. The a priori subscales were strongly supported by the automated item selection algorithm, AISP, further validating the theory behind the generation of the measurement items.
Apart from highlighting DIF items on a newly developed precision medicine implementation (PMI) measurement tool, this paper also pointed out potential and benign differences between perception on PM implementation held by those affiliated to industry (those in clinical and public health practice) and those in biomedical research. This has both implicit and explicit implications in the field of PM implementation, especially at health systems level. First, it highlighted the kind of information separately held by these two subgroups in the field of PM. Secondly, it also highlighted the kind of information held together in common by these important subgroups in the pursuit of ideals of PM. Thirdly, the findings contained in this paper may inform the kind of information that should be availed to them. With this paper, we hope to have contributed to draw attention to those in PM to the fact that biomedical research and PM practice need deliberative attention from both researchers and practitioners to succeed.
Zenodo: Extended data for Manuscript: Precision medicine implementation and research-practice partnerships: implications of measurement scale differential item functioning (DIF). http://doi.org/10.5281/zenodo.392527622.
File ‘DIF Analysis Raw.Extended Data’ (XLSX) contains the redacted survey responses from the card sort exercise and the results of the card sort exercise itself.
Zenodo: Extended data for Manuscript: Precision medicine implementation and research-practice partnerships: implications of measurement scale differential item functioning (DIF). http://doi.org/10.5281/zenodo.392527622.
File ‘DIF Study Package.Extended data’ (DOCX) contains the study package provided to participants.
Zenodo: R code for DIF. http://doi.org/10.5281/zenodo.392533641.
This project contains the R code for this study in R and PDF formats.
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)