Introduction
The growing popularity of social media sites presents a unique opportunity to study human interactions and experiences. Twitter, one of the most popular social media sites, allows users to ‘microblog’ by sharing 140 character messages with their social network. Although Twitter doesn’t disclose the number of people who use its service, estimates are in the hundreds of millions and perhaps as many as half a billion1. Approximately 340 million tweets are sent every day around the world2. Researchers have begun to use this data to answer questions in a variety of fields3–9. Recent reflections on the data collection practices of the US National Security Administration have spurred similar meditations on the ethics of digital research10. The concern is that Twitter data could conceivably be used in a way that violates the privacy and rights of the tweet authors.
Twitter data have already been used in a number of studies to detect influenza-like illness (ILI)3–6, risky behaviors associated with the transmission of HIV7, sentiments about childhood vaccination programs8, and political sentiments9. These study designs generally feature count data, rather than user-specific data. For example, there are multiple studies that compare the proportion of tweets about flu-related symptoms to public health data on influenza-like incidence (ILI). An increase in syndromic flu tweets might indicate that an outbreak is occurring. These data are usually reported either at the national level or without any geographic parameters. Another common study design aims to determine public sentiments by counting words, phrases, and emoticons that co-occur with keywords like ‘Obama’. These sentiment indicators can be used to infer public opinions about political elections, mental health, or consumer products.
Unlike Facebook, Pinterest and other competitors, Twitter provides several application programming interfaces (APIs) that allow real-time access to vast amounts of content. Data streamed through the APIs include metadata about the authors, including the text location from their profile (e.g. ‘Baltimore’), their time zone, the time they sent the tweet, the number of friends and followers they have, the number of tweets they have ever sent, and more (Figure 1). Approximately 1% of tweets have a geolocation, which uses GPS to append the author’s precise geographic coordinates to the tweet. Geolocations are sufficiently detailed to determine from which wing of a building a tweet was sent. The default privacy settings do not enable geolocation, but do make a user's tweets and metadata available through the API. Users can modify their setting to make their profile private, which shields their account from public view online and from the API11.
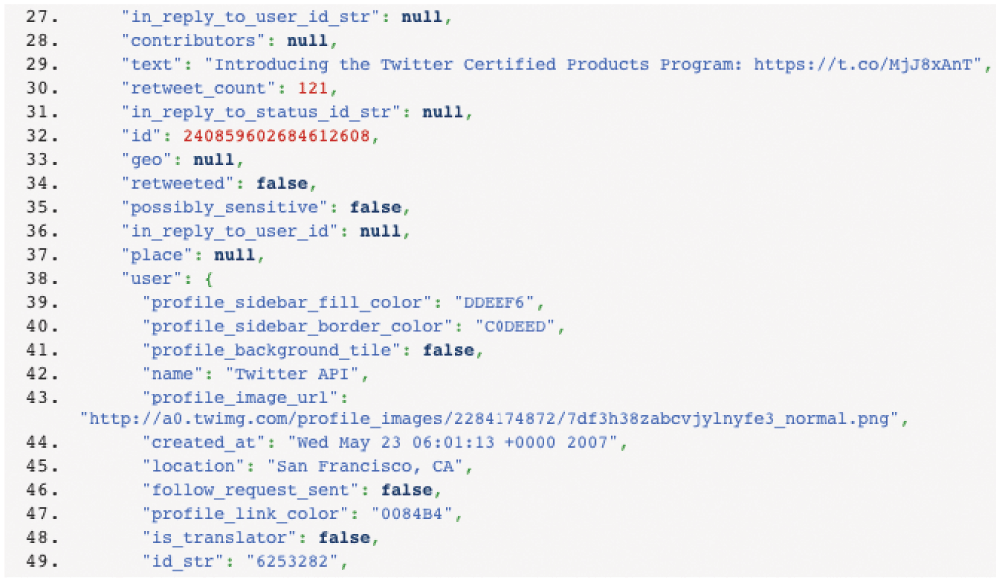
Figure 1. An excerpt of a single tweet returned through the Twitter API11.
There are numerous ways to access the data through these APIs: one method is through the ‘garden hose’, which is a random sample of approximately 1% of all live-streamed tweets. Other access methods include the search API which enables searching for particular users, hashtags, or locations, and author-specific queries which can retrospectively gather up to 3,200 tweets from a single user11. Furthermore, in 2010 Twitter donated its entire historical record of tweets to the US Library of Congress. Detailed plans for these data are not yet available, but the Library of Congress has indicated that it intends to collaborate with academic institutions to make the data available to researchers12.
The strength of tweets as a data source is in the volume; collection through the garden hose API brings in approximately 60,000–100,000 tweets per day. However because tweets are short and often lack context, it is difficult for computers to determine tweet content automatically. For this reason, researchers primarily use tweet data to conduct population-level research concerned with trends and patterns. Study designs rely on large volumes of data to accommodate false positives and negatives. A typical data set contains millions of tweets and many thousands of tweet authors. However, a user-centric use case involving Twitter is not inconceivable. Researchers interested in social network analysis, qualitative research, and rare-event topics may eventually turn to Twitter as a data source. Potential methodologies include building a social network out of @mentions (the @ is Twitter lexicon for referencing another user); mining qualitative data from specific user’s accounts; or conducting prospective research by following a person or small group of people over time. These user-centric approaches are fundamentally different from population-level studies, and may require different ethical considerations than aggregated study designs. Additional methodologies might also involve interacting with Twitter users, which will not be addressed here.
Under non-digital circumstances, ethics guidelines suggest that collecting information from a public space where people could ‘reasonably expect to be observed by strangers’ is considered appropriate even without informed consent13. According to these guidelines, tweets are text that users publish for the purpose of sharing with others. The weakness of this argument is that it fails to distinguish between population-level research and research focused on selected individuals. It would be clearly unethical for a researcher to follow one specific shopper around the mall and gather data exclusively about him without his consent. However, simply counting or observing behavior in aggregate at a mall is an acceptable research practice. The difference is that the latter example adheres to a level of privacy that the observed individual might expect from being in public, whereas the former violates those natural privacy boundaries. A similar distinction is needed in digital research.
As an example of the potential privacy pitfalls of digital research, suppose investigators were interested in the social networks of adolescents suffering from depression. A research plan might look like this: the investigators gather geocoded tweets that contain words relevant to the topic of interest, as shown in Figure 2. They filter for geocodes that correspond to school locations in order to identify adolescent users. From there, a simple query to the Twitter API returns a list of followers for each of those presumably depressed adolescents. They now have a social network. For each member of the network, they mine the user's tweet histories to find identifying details such as their real names. The researchers then use the gathered information to 'snowball' data collection by curating from a variety of different sources like Facebook, tumblr and the White Pages. They can collect birth dates, cell phone numbers, home addresses, favorite hangout spots, “likes” and “dislikes”, etc. The final result would be detailed demographic information for potentially thousands of people who exhibit symptoms of depression or are connected to a depressed adolescent. Current guidelines do not prohibit this kind of research activity. However, if the same information were collected through surveys or other traditional means, Institutional Review Board (IRB) approval would be needed.
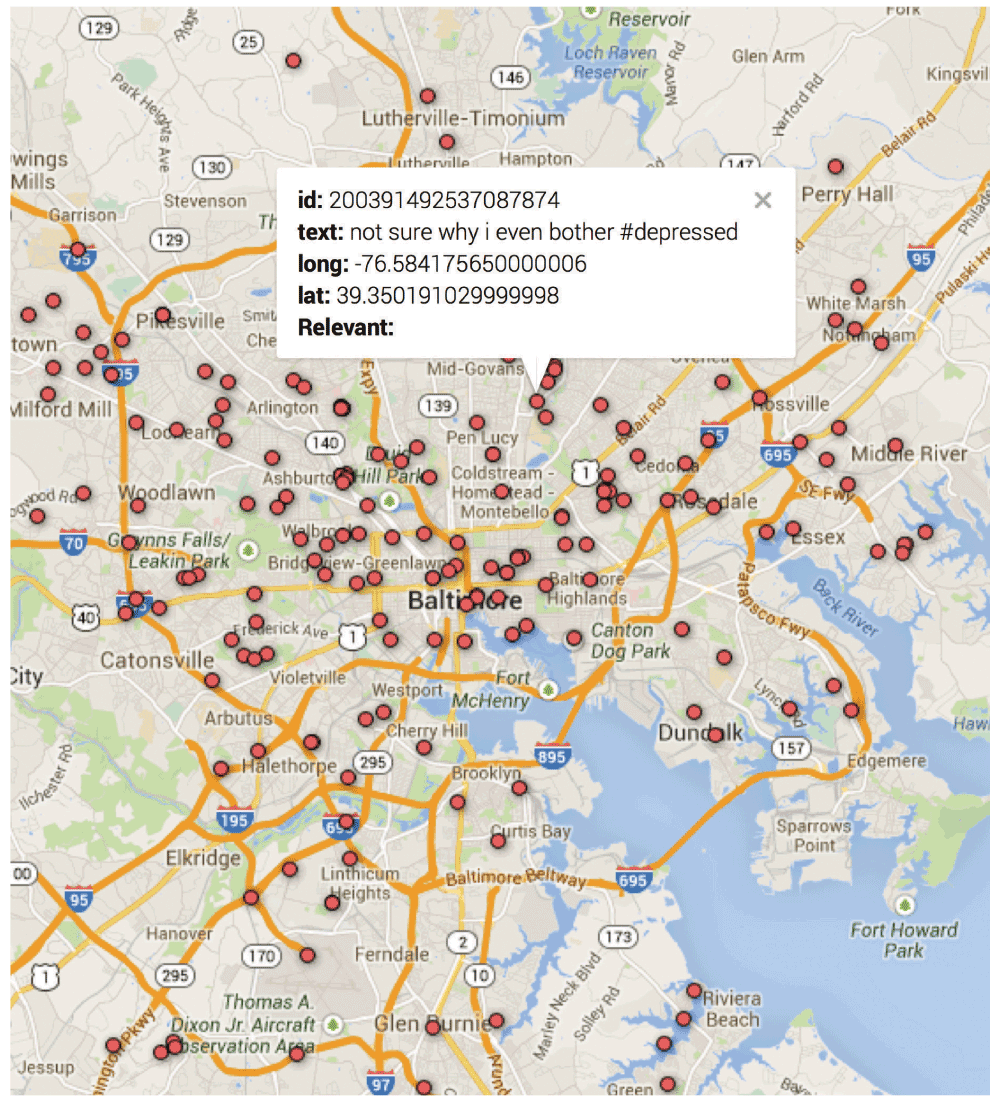
Figure 2. Each dot is a geolocated tweet collected through the Twitter API.
The example tweet displayed is fabricated.
According to the US Department of Health and Human Services Policy for Protection of Human Research Subjects, data that are publicly available are exempt from requiring IRB approval14. Because Twitter data are public, they technically fall under this exemption. Furthermore, Twitter’s privacy policy makes no secret of the fact that user data are indexed by search engines, archived within the US Library of Congress, and are available through an API15. However, it is unlikely that many users follow the link to read the lengthy and complex document. One study found that it would take 244 hours a year for an average internet user to read every privacy policy of the unique sites they visit16.
The US Consumer Privacy Bill of Rights (CPBR)17 may instead serve as a useful framework for guiding researchers conducting research with Twitter. The CPBR was issued by the Obama administration in February 2012 in order to “give consumers clear guidance on what they should expect from those who handle their personal information, and set expectations for companies that use personal data.” There are seven principles enumerated by CPBR in Table 1.
That being said, I think we agree on a lot of points. Twitter is a wonderful datasource for a studies in a variety of fields. We ourselves have used it to study risky behaviors associated with the transmission of HIV. We are simply proposing that researchers take a few simple steps to protect the privacy of the users whose data they curate.
For example, the study designs you mentioned and the guidelines we proposed are not incompatible. Under our suggested framework, large scale network and geo analyses are fine. We just ask that identifying information (user names, high-resolution geolocations) is not published. If you would like to follow specific users or publish identifiable information, then we suggest consulting an Institutional Review Board.
Thanks again for adding your voice, we hope the conversation continues.
-Caitlin Rivers and Bryan Lewis
That being said, I think we agree on a lot of points. Twitter is a wonderful datasource for a studies in a variety of fields. We ourselves have used it to study risky behaviors associated with the transmission of HIV. We are simply proposing that researchers take a few simple steps to protect the privacy of the users whose data they curate.
For example, the study designs you mentioned and the guidelines we proposed are not incompatible. Under our suggested framework, large scale network and geo analyses are fine. We just ask that identifying information (user names, high-resolution geolocations) is not published. If you would like to follow specific users or publish identifiable information, then we suggest consulting an Institutional Review Board.
Thanks again for adding your voice, we hope the conversation continues.
-Caitlin Rivers and Bryan Lewis