Keywords
Sentiment analysis, subjectivity, objectivity, attention mechanism, neural nets.
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research Synergy Foundation gateway.
Sentiment analysis, subjectivity, objectivity, attention mechanism, neural nets.
See the authors' detailed response to the review by Hien D. Nguyen
See the authors' detailed response to the review by Ashima Yadav
The proliferation of digital commerce, especially in Malaysia, has allowed many local merchants to reach out to a wider customer base. In order to attract customer’s attention, merchants always compete to offer better price and higher quality of services. Besides that, they also seriously consider the customer feedback or reviews in order to gauge service and product quality.1
By exploring the sentiment tendency of customer reviews, it can provide a good reference for other customer before the purchasing decision is made. Besides, it helps merchants to improve service quality and customer satisfaction.
Sentiment analysis is aimed to determine the sentiment as well as polarity on part of a text. Normally, language terms are under two form of statements, namely fact statement and a non-fact statement, which are known as objective and subjective in categorical terms.2 Facts are objective terms likes events entities and their properties. On the other hand, a non-fact statement is subjective and usually related to an individual’s sentiments, personal beliefs, opinion, perspective, feelings or thoughts.
This paper adopted attention segment3 to a neural network, LSTM, by creating attention-weighted features, namely Long Short Term Memory with Attention (LSTM-ATT)4 to create attention-weighted features. It aims to introduce these features at the input level to the neural network, so that the performance of sentiment can be increased. This paper explores non-contextual embedding on subjective and objective statements, mainly Word2Vec that is proven to be fast and accurate.5–7 LR and L-SVC are employed as benchmark to evaluate the effect of our adopted attention mechanisms (LSTM-ATT) on sentiment analysis based on subjectivity and objectivity. In order to increase the size of the dataset for better classification performance, this paper proposes to adopt data augmentation technique using Bidirectional Encoder Representations from Transformers (AUG-BERT) to two sentiment classifiers, namely, Linear SVC (L-SVC) together with AUG-BERT and LSTM-ATT with AUG-BERT.
Word embeddings are a scheme to convert human language to a word representation that is understandable by computers. The word representation is in the form of a real-valued vector that encodes the meaning of the word, so that the words that are closer in the vector space are expected to be similar in meaning.
Collobert8 declared that a distinction word vector and proper training can increase the performance of NLP works especially the sentiment analysis. Word embedding can be classified into two types; contextual and non-contextual embeddings. Non-contextual embedding does not consider the effects of arrangement of words in a particular sentence, while contextual embedding does the opposite.
For non-contextual embedding, Mikolov et al. initiated Word2Vec.9 The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. Bengio et al.10 and Collobert et al.11 enhanced it by implementing Neutral Net Language Model (NNLM). Bojanowski et al.12 made enhancement on Word2Vec by applying n-grams and cables to obtain higher performance in Word Similarity assignments that involved various types of languages and was able to show big enhancements on morphology rich languages, in particular, German datasets such as GUR350 and GUR6513 and ZG222.14 Bhagat et al.15 applied unigrams to extra individual words from Twitter messages and multiple machine learning techniques to perform sentiment analysis. Ebner et al.16 employed three simple bag-of-words representations, where a text is represented as the bag (multiset) of its words, namely pooling encoders, pre-trained word embeddings, and unigram generative regularization to regularize incorporating auxiliary discriminative tasks that managed to reduce training time and model size while maintaining high performance. Gayatry17 employed Count Vectorizer to convert each word into its corresponding vectors.
For context embedding, Peters et al.18 modified LSTM neural nets to create Embedding from Language Models (ELMo) that were able to show better results than the Stanford Tree-bank model (SST-5) from the research work by Socher et al.19 Devlin et al.20 constructed BERT along with Transformers and Attention Mechanism.3 The role of BERT is not limited to embedding functions but also become a language model that is capable to exceed ELMo on General Language Understanding Evaluation assignments (GLUE) from the research outcomes by Wang et al.21 Liu et al.22 enhanced BERT by developing A Robustly Optimized BERT Pre-Training Approach (RoBERTa). RoBERTa omits the Next Sentence Prediction task and applies an unfixed masking configuration rather than static Masked Language Modelling (MLM).
In terms of sentiment analysis, Sangeetha23 proposed multi-head attention fusion model of word and context embedding for student feedback. In addition, Yadav et al. have also provided discussions of sentiment analysis,24 with applications in medical reviews25 and disease impacts.26 For models with attention mechanisms, Nguyen et al. have implemented language-oriented sentiment analysis based on the grammar structure.27
Ethical Approval Number: EA1602021 (From Technology Transfer Office (TTO), Multimedia University).
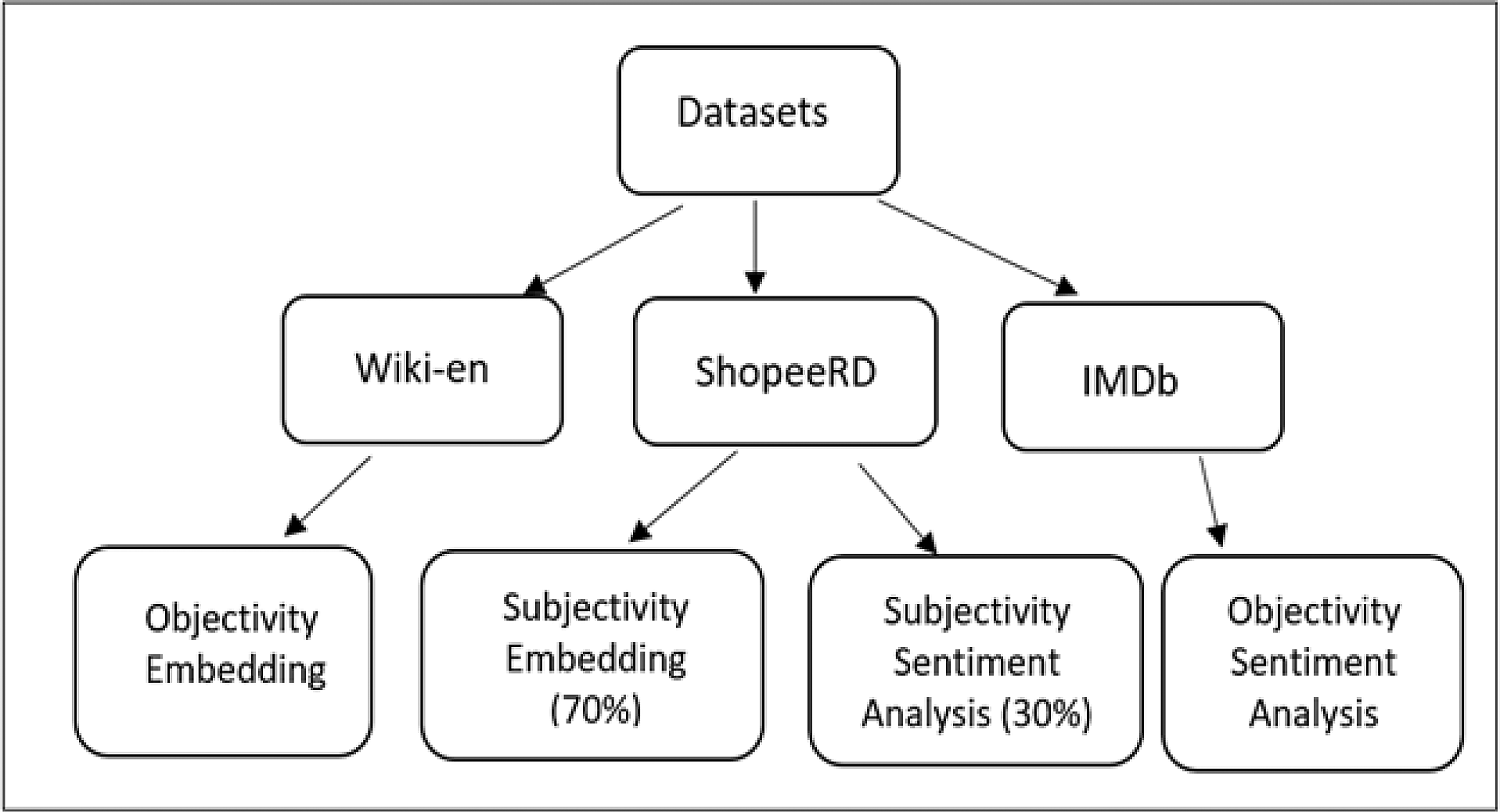
Three large corpora datasets were chosen to denote objectivity and subjectivity datasets correspondingly. IMDb28 and Wiki-en29 were chosen as the objectivity datasets while ShopeeRD30 was chosen as the subjectivity dataset.
IMDb consists of 50K of movie reviews with contents based on the true plot and written with a neutral point of view (NPOV). Wiki-en consists of 4677K of records based on Wikipedia that forced the articles to be factual and follow the NPOV policy. ShopeeRD consists of 208K customer reviews taken from the Shopee Code League 2020 Data Science and Data Analytics competition. ShopeeRD’s entries are based on customer experiences, which are potentially judgemental and opinionated.
Wiki-en was used as the objectivity corpus for word embedding, while IMDb was used for objectivity sentiment analysis. 70% of the ShopeeRD was used as the subjectivity corpus for word embedding and the remaining 30% for subjectivity sentiment analysis. Figure 1 displays the mapping of datasets.
The reviews and records from the datasets underwent a set of data cleaning steps which included emoji cleaning, text cleaning such as repeated character elimination, punctuation (e.g., ?, ! or,) elimination, stop word (e.g., becomes, against, or at) elimination, lemmatization, case lowering and normalization (normalizing non-English writing into English writing).
Word embedding is carried out to transform the reviews into floating-point numbers that are stored in a high dimension array, which forms a dictionary that the computer is able to obtain word vectors from. The word embedding must be large enough to represent millions of words and for each word is denoted as a high dimension vector. In this paper, one word is represented as a 300-dimension vector.
Word2Vec by Mikolov et al.31 is a word embedding method that consist of two structural design, namely Skip-gram and Continuous Bag-of-Words (CBOW). In the CBOW model, the distributed representations of context (or surrounding words) are combined to predict the word in the middle, while in the Skip-gram model, the distributed representation of the input word is used to predict the context. It has been proven that the Skip-gram structure has been shown better results in comparison to Continuous Bag-of-Words.32–34 Hence, this paper utilizes Word2Vec Skip-Gramm structure to perform word embedding.
ShopeeRD and Wiki-en were trained into embeddings of 300d (300-dimension), with a factor of five negative examples, window dimension of five tokens, and elimination of small sentences. The two embeddings (subjectivity and objectivity) were trained for ten repetitions.
To prevent over-fitting or one model favouring towards a particular embedding, two models (LR and L-SVC) were applied for this paper. In general, a sentence vector is produced from the formation of word vectors.35 Nevertheless, this paper assumes that certain letterings might not apply any weight or produce any consequence, therefore an attention layer, which is adopted from Vaswani et al.3 was produced as a substitute. Self-attention is capable of allocating ‘attention’ to an important vector (keyword). This permits the structural design in a way to highlight attention-ed vectors.36
For that reason, a model integrating attention segments was recommended, and the structural design is presented in Figure 2. The word vectors worked through the attention layer, creating attention-weighted features. By adapting LSTM neural nets, both the original embedding and the attention-weighted embedding are concatenated to create sentiment features. We are of the opinion that attention mechanisms will improve accuracy of the sentiment analysis because of the weighted features. This allows the model to utilize the most relevant parts of the input sequence in a flexible manner, by a weighted combination of all the encoded input vectors, with the most relevant vectors being attributed the highest weights.
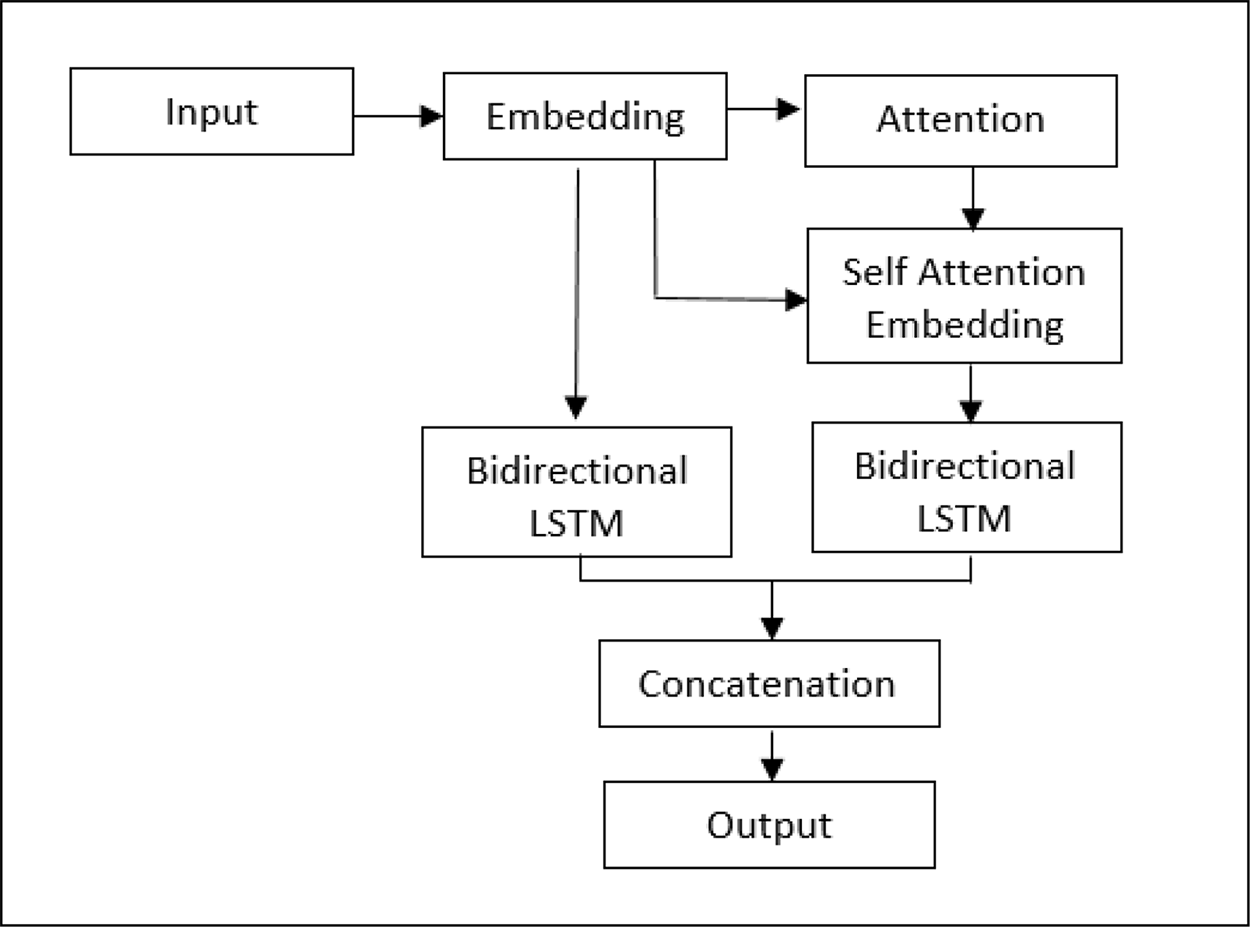
This paper adopted attention-weighted features model is called Long Short Term Memory with Attention (LSTM-ATT)4 with intention to improve the sentiment performance. These features at the input level to the neural network and go through a few dense layers to flatten the output. Finally, Rectified Linear Unit (RELu), a non-linear activation function is applied to produce the sentiment results. The model, LSTM-ATT, is then evaluated against LR and L-SVC. The workflow of the sentiment analysis on IMDb and ShopeeRD with multiple models is illustrated in Figure 3.

The experiments were performed in Python, utilizing the scikit-learn library for machine learning as well as the BERT model architecture. Three models (LR, L-SVC and LSTM-ATT) were trained with the objectivity (Wiki-en) and subjectivity (70% of ShopeeRD) embeddings. Ten-fold cross-validation was applied during the training. After that, the models were tested against the objectivity (IMDb) test set and the subjectivity (20% of ShopeeRD) test set to eliminate bias.
The experiments were based on benchmark comparison, embedding comparison and model comparison with 70-10-20 train-validation-test splits. The validation was carried out to perform parameter tuning, so that the best results among the models could be obtained.
Figures 4 and 5 demonstrate the t-distributed Stochastic Neighbor Embedding (t-SNE) plots for Wiki-en and ShopeeRD embeddings on the top 15 nearest words to the word ‘happy’. The t-SNE for both datasets revealed that word similarities are discovered in the embeddings, for instance, ‘glad’, ‘pleased’, ‘excited’ are grouped together with ‘happy’.
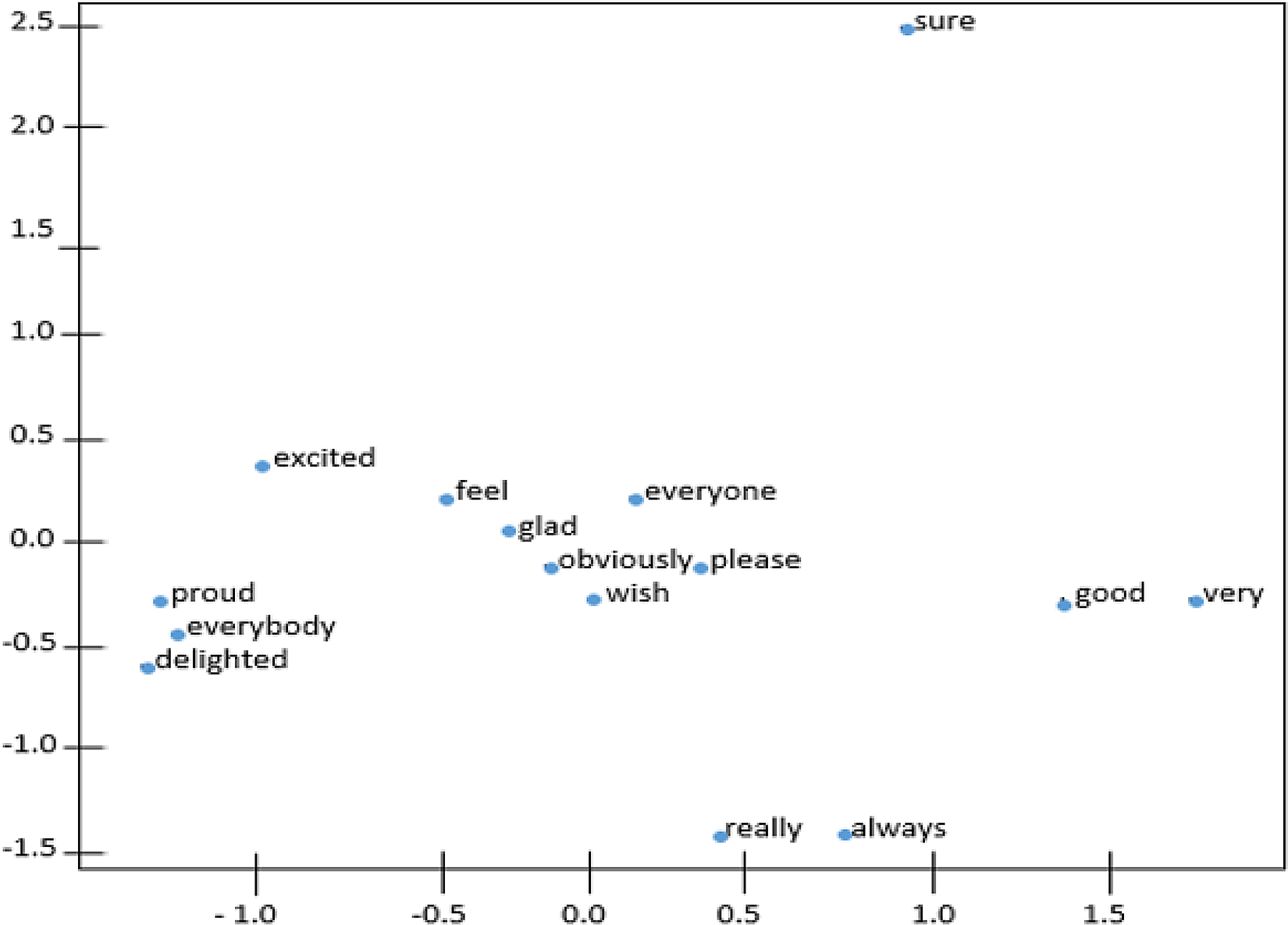
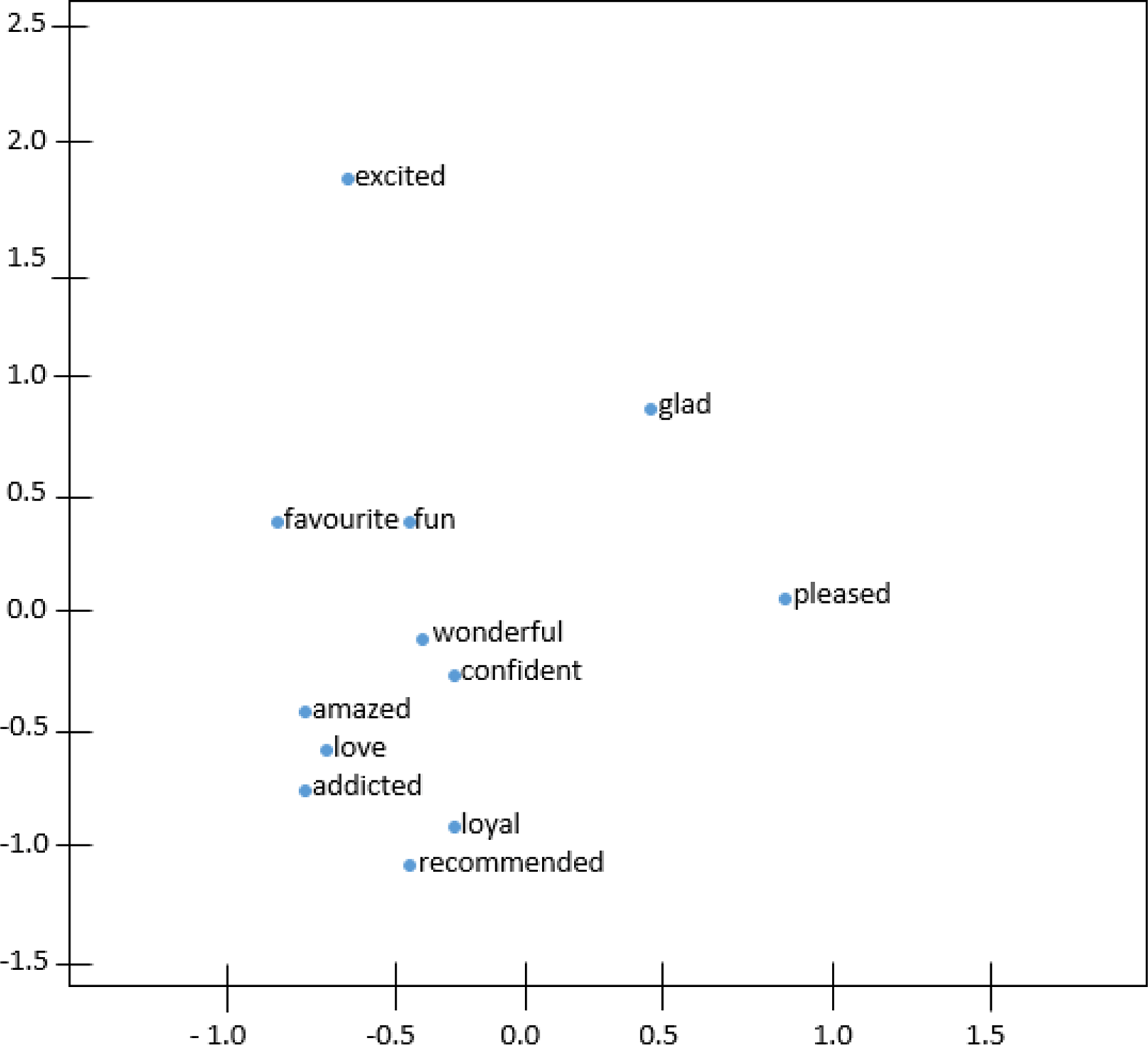
The words ‘very’ and ‘good’ having closeness to ‘happy’ were only found in t-SNE for Wiki-en only. Meanwhile the words ‘satisfied’ and ‘wonderful’ having closeness to ‘happy’ were found in t-SNE for ShopeeRD. Furthermore, outliers like ‘everyone’ and ‘everybody’ were found to appear in the t-SNE for Wiki-en. This shows that the two embeddings are different in nature.
The three models namely LR, L-SVC and LSTM-ATT were evaluated in terms of their performance in sentiment analysis. The accuracy of the three models is presented in Table 1. L-SVC obtained the highest accuracy (56.9%) for objectivity embedding, whereas LSTM-ATT obtained the highest accuracy (69.0%) for subjectivity embedding. L-SVC performed better than LR properly due to L-SVC attempting to exploit the margin between the closest support vectors whereas LR exploits the posterior class probability.37
| Data | Model | ||
|---|---|---|---|
| LR | L-SVC | LSTM-ATT | |
| Objective embedding | 0.5338 | 0.5685 | 0.5604 |
| Subjective embedding | 0.6418 | 0.6892 | 0.6902 |
From Table 1, there is possible limitation factor cause by the capacity of the training data, therefore the size of the dataset is increased through the data augmentation technique.38 As LR has a simpler architecture, data augmentation is not considered, and the focus is made on L-SVC and LSTM-ATT. Table 2 presents the outcome of data augmentation.
| Data | Model | |
|---|---|---|
| L-SVC+AUG-BERT | LSTM-ATT+ AUG-BERT | |
| Objective embedding | 0.5746 | 0.5991 |
| Subjective embedding | 0.6907 | 0.7004 |
From Table 2, it is found that the accuracy of models with the augmented data are found to be better than the models, although not by much. The LSTM-ATT+AUG-BERT was able to beat L-SVC+AUG-BERT on both objective and subjective embeddings.
To the best of our knowledge, there is only one sentiment analysis result from Gayatry’s work17 that accepted by Shopee Code League 2020 Data Science.30 Table 3 shows the comparison of our models with Gayatry’s work on ShopeeRD.
| Data | Model | ||
|---|---|---|---|
| ShopeeRD | L-SVC+AUG-BERT [our method] | LSTM-ATT+AUG-BERT [our method] | Multinomial Naïve Bayes14 |
| Training (110K), Testing (36K) | - | - | 0.58 |
| Training (145K), Testing (41K) | 0.69 | 0.70 | - |
To the best of our knowledge, there is no research work on objectivity sentiment analysis on IMDB without any involvement of pre-train data from taken IMDB, as all of them used 50% of total dataset for training and another 50% for testing. In this paper, we trained the models by Wiki-en and test on IMDB.
This paper has presented word embeddings for both objectivity and subjectivity contexts by applying Word2Vec. Analyzing the embedding using the t-distributed stochastic neighbour embedding plot shows that there are some similarities between the two embeddings, but most of them are dissimilar. Three models namely, LR, L-SVC and LSTM-ATT were employed to evaluate the performance of the adopted embedding technique. The attention model adopted was able to perform sentiment analysis well with the requirement of more data was fed into the model utilizing AUG-BERT data augmentation. Models with differing architectures will be explored in future work.
- Compiled Movie reviews from the Internet Movie Database (IMDb) : https://datasets.imdbws.com/,28 cited on 6 August 2021.
The data are available for personal and non-commercial use, as stipulated by the owner (IMDb).
- A complete copy of all Wikimedia wikis, in the form of wikitext source and metadata embedded in XML: https://dumps.wikimedia.org/backup-index.html,29 cited on 6 August 2021.
The data are available under the terms of the Creative Commons Attribution-Share-Alike 3.0 License.
- Product reviews from the Shopee e-commerce platform, created for the Shopee Code League 2020 Data Science and Data Analytics competitions: https://www.kaggle.com/davydev/shopee-code-league-20,30 cited on 6 August 2021.
The data are available for personal and non-commercial use, as stipulated by the owner (Shopee).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)