Keywords
smartphone, one-dimensional motion signal, activity recognition, stacking deep network, discriminant learning
smartphone, one-dimensional motion signal, activity recognition, stacking deep network, discriminant learning
Human activity recognition (HAR) can be categorized into vision-based and sensor-based. In vision-based HAR, an image sequence, in the form of video, recording the human activity is captured by a camera.1 This sequence will be analysed to recognize the nature of an action. This system is applied for surveillance, human-computer interaction and healthcare monitoring. For sensor-based HAR, human activities are captured by inertial sensors, such as accelerometers, gyroscopes or magnetometers. Among these approaches, sensors are more favourable due to their lightweight nature, portability and low energy usage.2 With the advancement of mobile technology, smartphones are equipped with high-end components. Accelerometer and gyroscope sensors embedded in the smartphone make it feasible as an acquisition device for HAR. Smartphone-based HAR has been an area of contemporary research in recent years.3–9 In this work, we categorize the smartphone-based HAR as part of the sensor-based HAR. Activity inertial signals are collected through smartphone sensors.
Hand-crafted approaches using manually computed statistical features have been proposed.10–12 These authors applied various machine learning techniques such as decision tree, logistic regression, multilayer perceptron, naïve Bayes, Support Vector Machine etc. to classify the detected activities. The performance of the handcrafted approaches might be affected when dealing with complex scenarios due to their feature representation incapability. The algorithms could easily plummet into the local minimum despite the global optimal.
Hence, various deep neural networks (DNNs) were explored in HAR owing to the capability of extracting informative features. DNN is a machine learner that can automatically unearth the data characteristics hierarchically from lower to higher levels.13 The work of Ronao and Cho (2016),14 Lee et al. (2017)15 and Ignatov (2018)16 explored the deep convolutional neural networks by exploiting the activity characteristics in the one-dimensional time-series signals captured by the smartphone inertial sensors. The empirical results substantiated that the extracted deep features were crucial for data representation with promising recognition performance.
Zeng et al. (2014) proposed a modified convolutional neural network to extract scale-invariant characteristics and local dependency of the acceleration time-series signal.17 The weight sharing mechanism in the convolutional layer was modified. Unlike in the vanilla model where the local filter weights were shared by all positions within the input space, the authors incorporated a more relax weight sharing strategy (partial weight sharing) to enhance the performance.
Recurrent Neural Network (RNN) was proposed to process sequential data by analysing previously inputted data and processing it linearly. Due to the vanishing gradient problem, RNN was enhanced and Long Short-Term Memory – LSTM was introduced. Chen et al. (2016) explored the feasibility of LSTM in predicting human activities.18 Empirical results demonstrated an encouraging performance of LSTM in HAR. Further, an enhanced version of LSTM, known as bidirectional LSTM, was proposed.19 Unlike LSTM, bidirectional LSTM tackles both past and future information during the feature analysis. With this, a richer description of features could be extracted for classification.
A cascade ensemble learning (CELearning) model was proposed for smartphone-based HAR.20 There are multiple layers in this aggregation network and the model goes deeper layer by layer. Each layer contains Extremely Gradient Boosting Trees, Random Forest, Extremely Randomized Trees and Softmax Regression. The CELearning model gains higher performance, and the training process is rather simple and efficient. Besides, Hierarchical Multi-View Aggregation Network (HMVAN) is also one of the aggregation models.21 This model integrates features from various feature spaces in a hierarchical context. In this network, three aggregation modules from the aspect of feature, position and modality levels are designed.
In DNNs, there are learning modular components in multiple processing layers for multiple-level feature abstraction. These layers are trained based on a versatile learning principle, which does not require any manual design by experts.22 These DNNs accomplish excellent performances in pattern recognition. However, these networks are not well trained if they have limited training samples, leading to performance degradation. Furthermore, there is a lack of theoretical ground on how to fine-tune the gigantic hyper-parameter series.21 The outstanding accomplishment of DNNs can only be achieved if and only if sufficient training data is accessible for fine-tuning the large parameter set. A high specification of GPU is needed to train the network from gargantuan datasets.
Thus, a stacking-based deep learning model for smartphone-based HAR is proposed. Inspired by the hierarchical learning in the DNNs, the proposed stacked learning network is aggregated with multiple learning modules, one after another, in a hierarchical framework. Specifically, a discriminant learning function is implemented in each module for discriminant mapping to generate discriminative features, level by level. The lower (generic) to higher level (deeper) features are input to a classifier for activity identification. This proposed approach is termed Stacked Discriminant Feature Learning, coined as SDLF.
The contributions of this work are summarized in three-fold:
1. A deep analytic model is proposed for smartphone based HAR to extract deep features without the need of a gigantic training set and tenuous hyper-parameter tuning.
2. An adaptable modular model is developed with a discriminant learning function in each module to extract discriminant features from lower to higher levels demanding no graphics processing unit (GPU) but only a central processing unit (CPU) with a fast-learning rate.
3. An experimental analysis using various performance evaluation metrics (i.e. recall, precision, the area under the curve, computational time, etc.) with subject-independent protocol implementation in which there is no overlap in subjects between training and testing sets.
Smartphone inertial sensors were used to capture 3-axial linear (total) acceleration and 3-axial angular velocity signals. These signals were pre-processed into time- and frequency-domain features, as listed in Table 1. Next, the pre-processed data was inputted into the Stacked Discriminant Feature Learning (SDFL) for feature learning. The extracted feature template was fed into the nearest-neighbour (NN) classifier for classification. The overview of the system is illustrated in Figure 1.

SDFL is a pile of multiple discriminant learning layers interleaved with a nonlinear activation unit, as illustrated in Figure 2. By cascading multiple discriminant learning modules, each layer of SDFL learns based on the input data and the learned nonlinear features of the preceding module. The depth of the stacking layer is determined using the database subset. If the performance is not improving but showing degradation, the depth of the stacking layer is determined. In this case, the depth of three showed the optimal performance, so we adopted this architecture with three layers. To be detailed, the first discriminant learning module learns based on the input data and the second learning module learns based on an input vector (concatenating the input data and the learned features of the first learning module). This is similar to the third learning process where the third learning module learns based on an input vector (comprising the input data and the learned features of the second learning module).
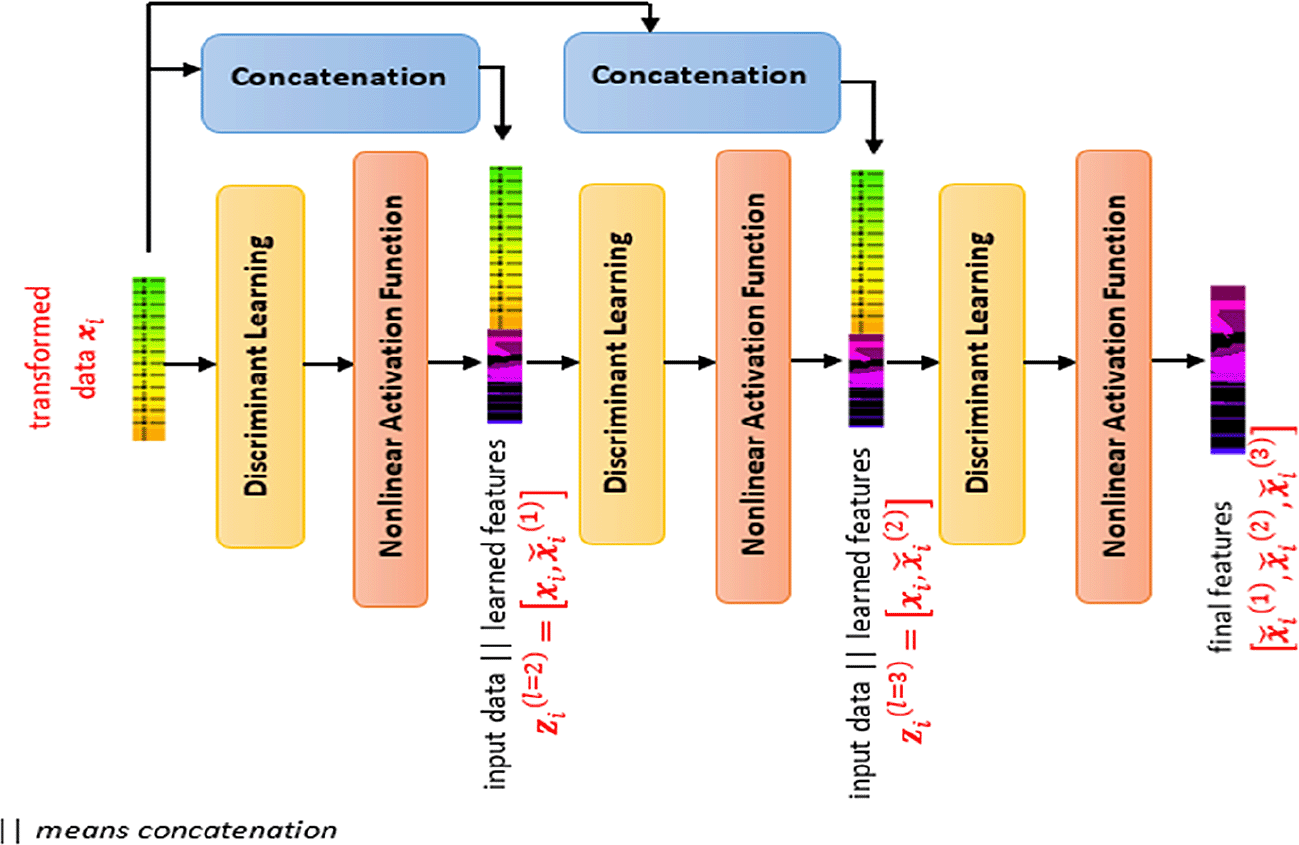
Let be a set of transformed data, is the class label of , is the number of training classes, each of classes has a mean and total mean vector with denotes the number of training samples for jth class. In the first learning layer, the input vector is the transformed data . The computation of the intrapersonal scatter matrix and interpersonal scatter matrix are defined as:
where T denotes a transpose operation. Next, a linear transformation is computed by maximizing the Rayleigh coefficient. With this optimization, the data from the same person could be projected close to each other, while data from different people is projected as far apart as possible. This optimization function is termed as Fisher’s criterion,23
The mapping is constructed through solving the generalized eigenvalue problem,
The learned features are produced through the projection of the input data onto the mapping subspace,
is transformed to dimensions. We denote l for the index of modular layer in SDFL. The learned feature vector of the first modular unit is notated as . A nonlinear input-output mapping is applied to via a nonlinear activation function. In this study, we adopt a sigmoid function, for the nonlinear projection. To be specific, is the nonlinear learned features of the first modular unit.
For deeper modules, the input vector of the respective module is a stacking vector containing the input data and the learned features, i.e. where and . The intrapersonal scatter matrix and interpersonal scatter matrix are formulated,
In this case, is the jth class mean computed from the input vectors of jth class, and the total mean vector at lth modular unit. The final feature vector is the nonlinear learned features of each modular layer,
We scrutinized how well SDFL could analyse the inertial data and correctly classify those activities. The experimental hardware platform was constructed on a desktop with an Intel® Core™ i7-7700 processor with 4.20 GHz and 48.0 GB main memory; whereas the experimental software platform was a 64-bit operating system of Windows 10 with Matlab R2018a (MATLAB, RRID:SCR_001622) software (An open-access alternative that provides an equivalent function is GNU Octave (GNU Octave, RRID:SCR_014398)).
We used the UCI HAR dataset12: There were 30 subjects with 7352 training samples and 2947 testing samples. Each subject was required to carry a smartphone (Samsung Galaxy SII) on the waist and perform six different activities. The activities were “walking”, “walking_upstairs”, “walking_downstairs”, “sitting”, “standing” and “laying”.
The generalization level of SDFL was evaluated in a user-independent scenario. SDFL was trained using training samples from a group of users. Then, the model was applied to new users without the necessity of collecting additional samples of these new users to retrain the model. In this experiment, the UCI HAR dataset was partitioned into two sets: 70% of the volunteers were selected to generate the training data and the remaining 30% of the volunteers’ data was used as the testing data. There was no subject overlapping between the training and test data sets. Table 2 records the performance of SDFL and Table 3 records the performance comparison with other approaches.
| Metric | Performance |
|---|---|
| True Positive (TP) rate | 0.963 |
| False Positive (FP) rate | 0.008 |
| Precision | 0.964 |
| Recall | 0.963 |
| F-score | 0.963 |
| Area Under the Curve | 0.977 |
| Accuracy (%) | 96.2674 |
| Method | Accuracy (%) |
|---|---|
| Dynamic Time Warping24 | 89.00 |
| Hierarchical Continuous Hidden Markov Model25 | 93.18 |
| Deep Belief Network (as reported in4) | 95.80 |
| Group-based Context-aware method for human activity recognition (GCHAR)3 | 94.16 |
| Handcrafted Cascade Ensemble Learning model (CELearning)20 | 96.88 |
| Automated Cascade Ensemble Learning model (CELearning)20 | 95.93 |
| Convolutional Neural Network (CNN)14 | 95.75 |
| Artificial Neural Network (ANN) (as reported in14) | 91.08 |
| Stacked Discriminant Feature Learning (SDFL) | 96.27 |
Table 4 tabulates the computational time. The computational time of SDFL is benchmarked with that of the ordinary methodology, which is directly performing classification on the pre-processed data. Instead of using a multiclass support vector machine as in,12 we adopt Nearest Neighbour (NN) classifier for classification because the focus of this work is the feature extraction capability and the classification is standardized with the simplest classifier, i.e. NN.
Classifier = Nearest Neighbour (NN) classifier.
From the empirical results, we observed that the proposed SDFL was able to demonstrate superior classification performance compared to most of the existing techniques, even though a simple classifier was adopted in the system. The exceptional performance of SDFL explains the capability of SDFL in capturing the essence of the inertial data without heavily depending on the classifier. Furthermore, SDFL also exhibited its superiority to most of the existing approaches, including deep learning models. To be specific, SDFL obtained an accuracy of 96.3%, whilst Deep Belief Network’s accuracy was 95.8%,4 CNN achieved 95.75% accuracy14 and ANN’s accuracy was 91.08%.
Last but not least, it was discerned that the performance of SDFL is on a par with the Cascade Ensemble Learning model (CELearning).20 Both approaches are ensemble learning methods with multiple layers for data learning. The key difference between these approaches is the analysis algorithms in each layer. CELearning is comprised of four different classifiers, i.e. Random Forest, Extremely Gradient Boosting Trees, Softmax Regression and Extremely Randomized Trees and the final classification result is obtained through the last layer via the score-level fusion of the four complex classifiers. On the other hand, in SDFL, merely Rayleigh coefficient optimization is implemented to extract the low-to-higher level of discriminant features. Further, a simple classifier, i.e. NN classifier, is adopted in SDFL. This deduces that the discrimination capability of SDFL primarily depends on the SDFL modular model to extract discriminant features demanding no complex classifier.
From Table 4, we can notice that the overall training and testing time of SDFL are much lesser than those of the benchmark method. On average, SDFL just needs ~seconds per sample (sps) for the training phase and ~ sps for the testing phase. The fast feature learning of SDFL and the dimensionality reduction in SDFL to project the data onto a lower-dimensional subspace are the main reasons for having such an efficient computation.
A cascading learning network for human activity recognition using smartphones is proposed. In this network, a chain of independent discriminant learning modules is aggregated, layer by layer in a stackable framework. Each layer is constituted by a discriminant analysis function and a nonlinear activation function to effectively extract the rich features from the inertial data. This proposed SDFL network possesses characteristics of good performance even on small-scale training sample sets, as well as less hyper-parameter fine-tuning, and fast computation compared with the other deep learning networks. Despite showing computational efficiency, the proposed network also demonstrated its classification superiority to most of the state-of-the-art approaches with an accuracy score of ~97% in differentiating human activity classes.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)