Keywords
digital pathology, pancreatic cancer, cancer grading, deep learning, image classification
This article is included in the Research Synergy Foundation gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
digital pathology, pancreatic cancer, cancer grading, deep learning, image classification
This version addresses the comments from the reviewers as below:
1) Revised "Introduction" and "Deep learning and related works" sections
2) Added "Contributions" after the "Introduction",
3) Revised "Effect of data augmentation" section and "Comparison between the best and the worst performing model" sections.
See the authors' detailed response to the review by Francisco Maria Calisto
Pancreatic cancer is one of the most lethal malignant neoplasms in the world,1 developed when cells multiply and grow out of control in the pancreas,2 forming cancer cells caused by cells mutation in their genes.3 Doctors commonly perform a biopsy to diagnose cancer when physical examination or imaging tests like magnetic resonance imaging (MRI) and computerized tomography (CT) scans are insufficient. In pancreatic cancer, grading is essential for planning treatment but is currently done using a meticulous microscopic examination.4 Limited work found on analysis of pathological images for pancreatic cancer. Niazi et al.5 presented a deep learning method to differentiate between pancreatic neuroendocrine tumor and non-tumor regions based on Ki67 stained biopsies. The purpose is for the quantification of positive tumor cells in a hotspot. Up to now, there has been no successful implementation of artificial intelligence (AI) for classifying pancreatic cancer grade. The absence of such AI work motivates this paper to use transfer-learning to grade pathological pancreatic cancer images using 14 deep learning (DL) models. This work can facilitate an automated cancer grading system to address the exhaustive work of manual grading.
This work presents an automated grading system focusing on pancreatic cancer from pathology images, which has not been done before to the best of our knowledge. The work also contributes a comparison of performance for 14 DL models on two different pathological stains, namely the May-Grünwald-Giemsa and haematoxylin and eosin.
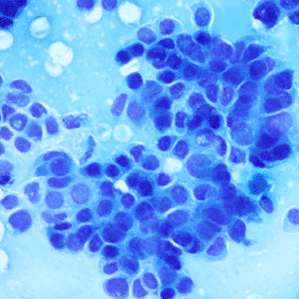
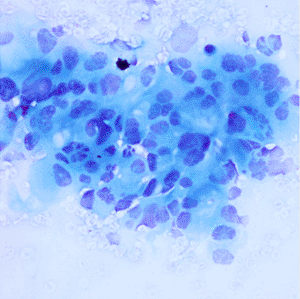
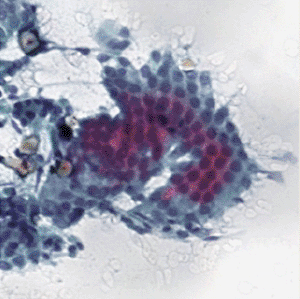
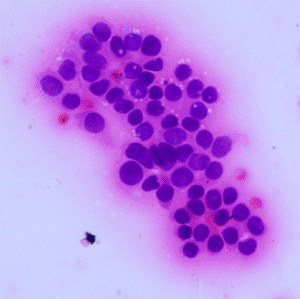
Pancreatic cancer is considered to be under-studied, and improvements in the diagnosis and prognosis of pancreatic cancer have therefore been minor.6 Digital pathology is an image-based environment obtained by scanning tissue samples from glass slides. Staining, usually using May-Grünwald-Giemsa (MGG) and haematoxylin and eosin (H&E) stains, is carried out on the tissue samples before digitization into whole-slide images. The cancer grade is identified by the degree of differentiation of the tumour cells7 ranging from well to poorly differentiated as described in Table 1.
MGG = May-Grünwald-Giemsa; H&E = haematoxylin and eosin.
Convolutional neural network (CNN) is a widely used deep learning (DL) algorithm in medical image-based classification and prediction.8 Several methods use CNN in cancer detection and diagnosis9 such as the Gleason grading of prostate cancer,10–12 colon cancer grading,13 breast cancer detection,14,15 and pancreatic cancer detection16–19 and classification.20 AI has been proven to assist clinicians with better prediction and faster diagnosis for breast cancer screening.21 However, grading of pancreatic cancer with DL still needs comprehensive study.
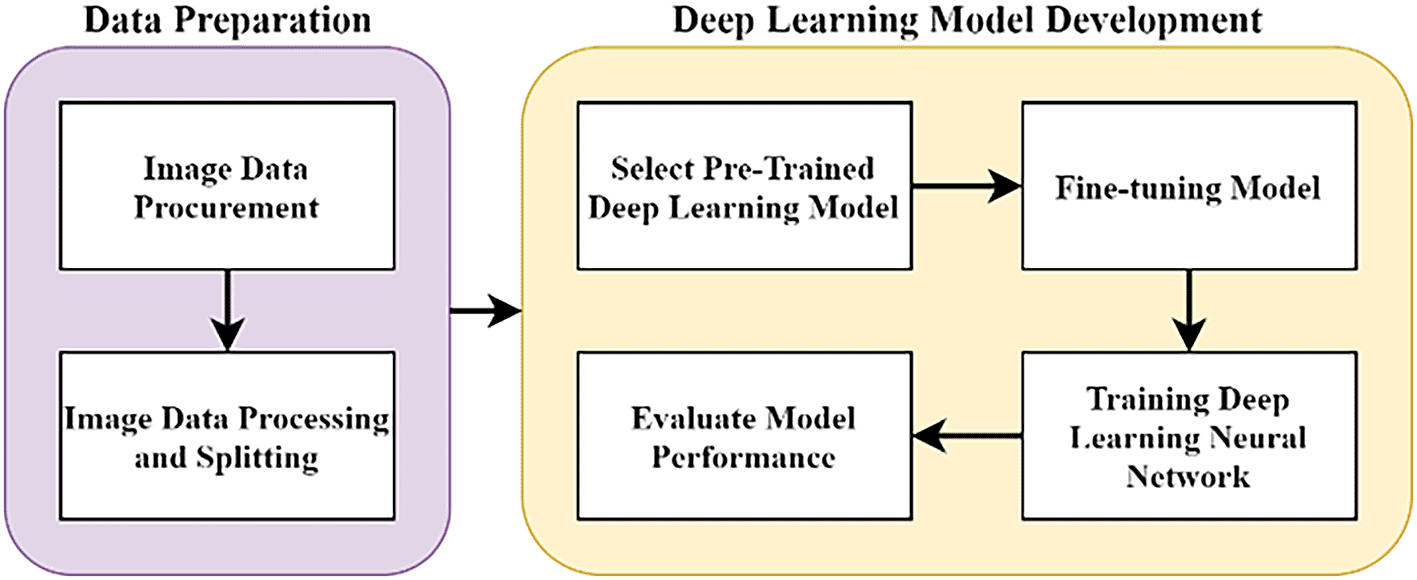
The methodology of this work was done at Multimedia University, Cyberjaya, from June 2020 to May 2021. The overall methodology of this research is as illustrated in Figure 1, with two major stages. In the data preparation stage, pathology images of pancreas tissue samples were obtained from our collaborator and the images were pre-classified by a pathologist into four classes. In the DL model development stage, the images were trained on the DL model and evaluated accordingly. All stages were carried out using Jupyter notebook in Google Colab. The source code is available from GitHub and archived with Zenodo.26
This work was approved by the Research Ethics Committee of Multimedia University with approval number EA2102021. This article does not contain any studies with human participants or animals performed by any of the authors. Only pathology images were used, and the patients’ personal data were anonymized.
Pathology image procurement
A total of 138 high-resolution images with varying dimensions (1600 × 1200, 1807 × 835 and 1807 × 896) were obtained and pre-classified by the collaborators (see Acknowledgements). Four classes were identified (as shown in Table 2): Normal, Grade-I, Grade-II and Grade-III. Each image consisted of a tissue-sample stained with MGG and H&E. The image distribution in each class was unequal with Grade-II having 58 images and Normal with only 20 images. To better capture the cells characteristics which is paramount in determining their grade and to match the lower-resolution setting of the network’s input, the images were pre-processed into small non-overlapping patches.
MGG = May-Grünwald-Giemsa; H&E = haematoxylin and eosin.
| Stain\Class | Normal | Grade I | Grade II | Grade III | Total |
|---|---|---|---|---|---|
| MGG stained | 13 | 4 | 43 | 19 | 79 |
| H&E stained | 7 | 27 | 15 | 10 | 59 |
| Total | 20 | 31 | 58 | 29 | 138 |
Image pre-processing
The pre-trained models require a low dimension and square image for training and making predictions. The squared slicing method is used where smaller patches with approximately 200 × 200 pixels of non-overlapping regions are sampled from the original images. Further processing was done to remove unwanted patches, as shown in Figure 2.
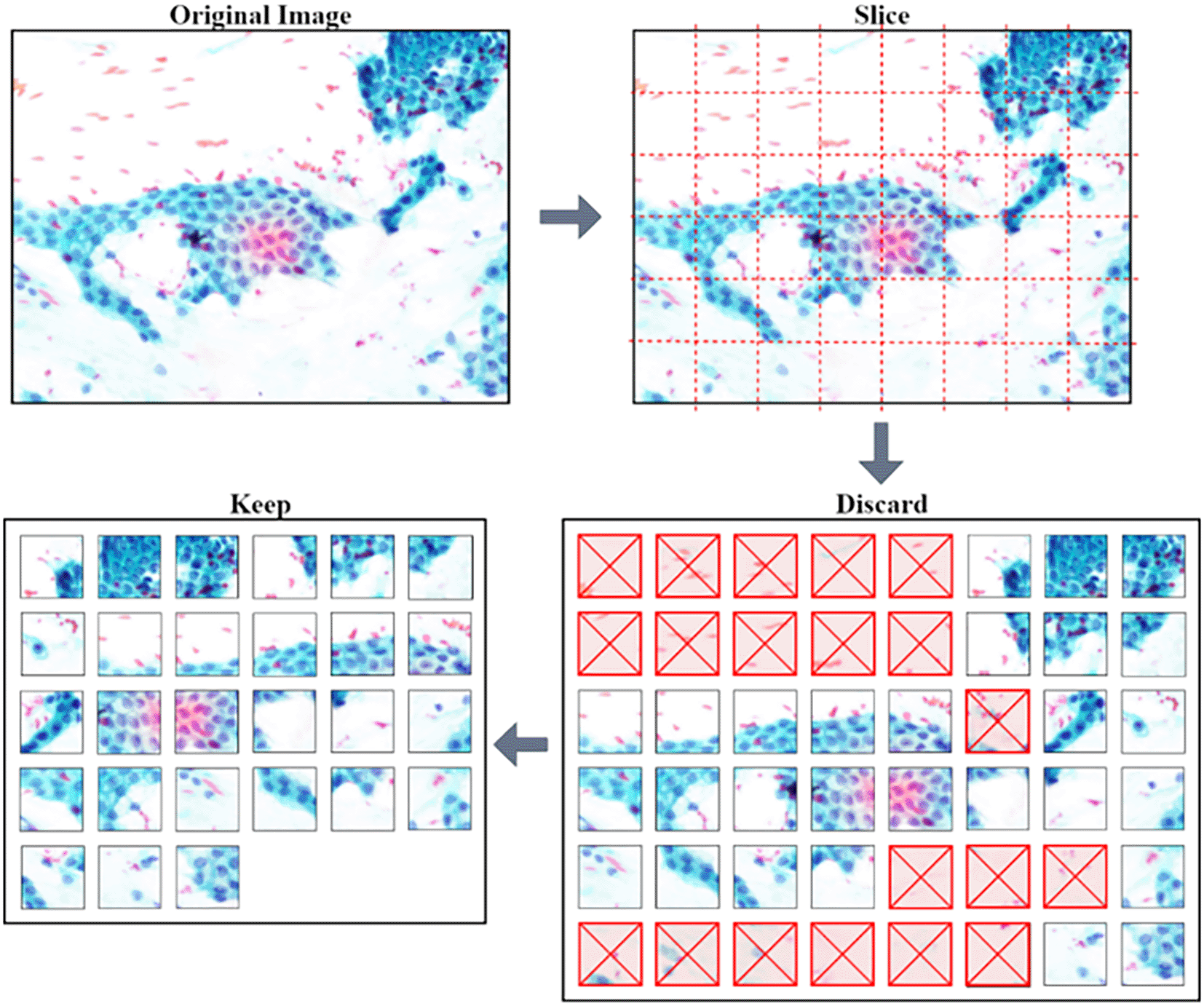
Image dataset
A total of 6468 patches were generated from the slicing process of the 138 original images which is an increase of 468% in number of images. Overall, 50.5% (3267) of the patches with background and non-tissue information were discarded, and the remaining are listed in Table 3. Examples of MGG stain and H&E stain pathology images are shown in Table 1, with the mixed dataset combining all images from MGG and H&E stains. From the numbers in Table 3, these datasets still had an imbalanced number of patch images in each class but this can be mitigated by employing a weighted average to evaluate the model.
MGG = May-Grünwald-Giemsa; H&E = haematoxylin and eosin.
| Stain\Class | Normal | Grade I | Grade II | Grade III | Total |
|---|---|---|---|---|---|
| MGG stained | 401 | 108 | 983 | 366 | 1858 |
| H&E stained | 139 | 606 | 309 | 289 | 1343 |
| Total | 540 | 714 | 1292 | 655 | 3201 |
Training-validation splitting and K-fold cross-validation
To evaluate the DL model, images in each dataset were split into training and validation set with 80-20 ratio. K-fold cross-validation with K = 5 was used by splitting all MGG, H&E and the mixed dataset into five parts, producing cross-validation sets with five new copies of MGG, H&E and mixed datasets and labelled (e.g. MGG Set 1 to MGG Set 5 for MGG). Each set had a different set of images used for training (80%) and validation (20%). The average value was calculated from the five-training iterations to evaluate the performance.
Image data augmentation and normalisation
Image data augmentation was implemented to virtually expand the training set, but not on the validation set. The transformation parameter involved was horizontal flip, vertical flip and -90° to 90° rotation range. Image data normalisation was used to rescale image pixels from a range of [0,255] to [0,1] so the input pixels will have similar data distribution.
Deep CNN algorithm was used for developing a model for classifying pancreatic cancer grading from pathology images.
Transfer-learning
A total of 14 CNN pre-trained models from recognizing 1000 classes in ImageNet was selected from Keras API22 to get the best model for classifying the 4-grade classes of pancreatic cancer. The proposed pre-trained models are listed in Table 4 along with their original model’s image input shape, and its respective top-1 accuracy on the ImageNet validation set.
Fine-tuning
All 14 models were fine-tuned with four newly added layers to extract the features from pathology images: a flatten-layer to form a 1D fully connected layer; a dense-layer with 256 nodes and ReLu activation-function; a dropout-layer with a rate of 0.4 to regularise the network; and lastly another dense-layer with 4-nodes and SoftMax activation-function to normalize the probability of prediction.
Setup and evaluation parameters
Batch size of 64 was chosen to allow the computer to train and validate 64-patch-samples at the same time. Adam optimizer with default initial learning rate of α = 0.01 and moment decay rate of β1 = 0.9 and β2 = 0.999 was used. The loss function is calculated using categorical cross-entropy for the 4-class classification task. With this setup, the models are compiled and trained for 100-epochs.
The confusion matrix, precision, recall, f1-score and weighted-average were used to evaluate the model's performance. Weighted-average was used to calculate the performance of individual cross-validation set and suitable for imbalanced dataset. The equation for the weighted-average is:
This experiment was done with the first cross-validation set of the mixed dataset, to observe how data augmentation impacts a model training performance.25 Table 5 and Table 6 display the final accuracy and loss of training and validation set after 100 epochs. Without data augmentation in Table 5, it is evident that overfitting has occurred, because the model is doing very well on the training set but not on the validation set. With data augmentation, the validation accuracy improved, specifically on VGG19 model (54.83% to 77.22%). The training accuracy of other models are slightly reduced with data augmentation (except for VGG19) but it is normal as the model is learning newly transformed images. The validation loss also shows a reduction, as in Table 6, such as on NASNetLarge model from 3.36376 to 0.68587. Overall, these results show that data augmentation may reduce overfitting and improve model performance as reported in.11,14,15 The reason behind this is the model is becoming more robust with data augmentation for getting to learn various transformed images of the limited size dataset. These kind of images are high-likely to exist in real-world applications, especially when it comes to unique human cells.
The overall performance results of all 14 different transfer-learning models proposed for this experiment are presented. Each model was trained with the 3 datasets and 5-fold cross-validation. Figure 3 illustrates the overall performance in terms of mean f1-score.

Comparison between MGG, H&E and the mixed dataset
This comparison shows how a DL model learns from single coloured stain. In Figure 3, all models trained with the H&E obtained the highest f1-score compared to MGG and mixed. Most models scored above 0.9 except for VGG19 (0.87). When trained with the MGG, models other than VGG16 and VGG19 performed the lowest compared to H&E and Mixed. The performance of mixed is as expected because it contains a mixture of both datasets. The VGG16 and VGG19 model, however, performed better on MGG than Mixed, due to the small VGG network architecture and small fully-connected layers making it unable to learn complex features and patterns in pathology image. The trend described in Figure 3 indicates that image patches in the H&E are easier to learn with better prediction than MGG.
Comparison between pre-trained models
From the result, DenseNet network architecture was the best at classifying pathology images where all three variations trained on MGG, H&E and mixed take the top spot among the 14 models. The ResNet on mixed dataset were ranked ascendingly from ResNet101V2, ResNet50V2 and ResNet152V2 before the three DenseNet models. This supports the work of Huang et al. in23 where DenseNet was designed to improve the ResNet architecture. DenseNet201 which is a much deeper layer than the other two DenseNet models managed to achieve the highest f1-score of 0.88, 0.96 and 0.89 for MGG, H&E and mixed, respectively. The DenseNet121 and DenseNet169 performance on the three dataset scores were marginally lower at 0.87, 0.95, 0.89 and 0.87, 0.95, 0.88, respectively. This shows that a deeper DenseNet layer can perform more accurate prediction.
The Xception23 and InceptionResNetV224 are improvements of InceptionV3, which performs better than their ancestor. The f1-scores for Xception trained by MGG, H&E and Mixed are 0.85, 0.94 and 0.86, as compared to InceptionV3, 0.80, 0.92 and 0.83, respectively. However, InceptionResNetV2 are just slightly higher than InceptionV3 (0.93 and 0.83 for H&E and mixed) but lower for MGG (0.80). VGG models did not perform quite well when compared to its earlier models. VGG19, which is supposed to be an improvement to VGG16, failed to achieve a greater f1-score, with 0.74, 0.87 and 0.65 for the MGG, H&E and mixed, respectively, while VGG16 was higher at 0.80, 0.93 and 0.78. The results concluded that VGG19 was the worst performing model for our datasets.
This experiment applied transfer-learning on 14 ImageNet pre-trained models to classify pancreatic cancer grades. From the comparisons, DenseNet201 model is suggested for practical application of pancreatic grading system of MGG or H&E stains.
Comparison between the best and the worst performing model
Table 7 and Table 8 shows the precision and recall of VGG19 (the worst) and DenseNet201 (the best) for the three datasets. VGG19 struggles to make prediction for Grade-I patches in MGG where the precision and recall are 0.00 for CV sets 3, 4, and 5. A similar pattern is noticed in Grade-III patches, and from our observation, this is because most of the Grade-I and Grade-III patches were wrongly predicted as Grade-II. This is due to the imbalance classes in MGG where Grade-II patches account for 52.9% of the total images whereas Grade-I consist of only 5% and Grade-III 19.7%. This class imbalance has caused the VGG19 model to struggle a lot at recalling class with fewer data.
For H&E images, the effect of class imbalance however did not affect the performance of VGG19. The recall and precision for Normal class are ranked among the highest despite its smallest number (10%) of patches. Looking back at Table 1, the H&E Normal images have a quite different stain colour compared to other classes, which explains the good prediction for both models. This could be seen as a problem where limited image variation can cause biasness. The precision of Normal class would score poorly if it were tested to predict different variation of H&E stain image even with the same set of ground truth, but can be assuaged if the class have many different variations of stain colour.
For the mixed dataset, VGG19 also struggled to predict Grade-III class, especially on CV 4 and 5 where it scored 0.00 for both metrics. The reason could be that the Grade-III patches are difficult for the VGG19 model to learn. This is the reason why cross-validation should be performed to rigorously evaluate a DL model. DenseNet201 managed to get good recall for Grade-III patches for both CV sets, confirming its ability to learn complex features on the pathology image.
From the study, we can see that integrating AI into the diagnosis system can assist the pathologist in getting the suggestive grading based on the prediction. It is however meant to assist and not on decision-making. The future aim of this study is to have a platform for screening of pancreatic cancer biopsies.
This paper presents development of several deep learning models through transfer-learning for classifying pancreatic cancer grade from pathology images. The datasets were trained on a total of 14 ImageNet pre-trained models. Image data augmentation was performed to counter the low number of images and has proven to improve the validation accuracies of all pre-trained models up to 40%. The evaluation on 14 pre-trained models shows that the DenseNet models performed best compared to the other models. Most of the models trained by H&E managed to achieve f1-score above 0.9. The MGG dataset scores lower f1-score compared to the mixed dataset. The highest f1-scores were achieved by DenseNet201, with 0.8786, 0.9561 and 0.8915 for MGG, H&E and Mixed, respectively. To the best of our knowledge, no similar work on pancreatic cancer grading has been reported in the literature. With these promising early results, this work can aid pathologists in facilitating an automated pancreatic cancer grading system for better cancer diagnosis and prognosis. This study has not been tested with whole slide images (WSI), but similar approaches can be applied. Further improvements to the system can potentially be achieved by using future state-of-the-art DL models.
Open Science Framework: Dataset for Pancreatic Cancer Grading in Pathological Images using Deep Learning Convolutional Neural Networks. https://doi.org/10.17605/OSF.IO/WC4U9.25
This project contains the following underlying data:
- Dataset PCGIPI-Original.zip (pancreatic pathological image patches used for our analysis. The stain types are May-Grünwald-Giemsa (MGG) and Haematoxylin and Eosin (H&E)).
- Dataset PCGIPI-sliced.zip
- PCGIPI Results.xlsx
- Slicing Process for Table 3.docx
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
Analysis code available from: https://github.com/mnmahir/FYProject-PCGIPI
Archived analysis code as at time of publication: https://doi.org/10.5281/zenodo.5532663.26
License: MIT
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)