Keywords
Student performance, data mining, support vector machine, naïve bayes, multilayer perceptron
This article is included in the Research Synergy Foundation gateway.
Student performance, data mining, support vector machine, naïve bayes, multilayer perceptron
Referring to comments from the reviewers, we have made the following changes: 1) We have added papers into the Literature Review. 2) We have also amended the Introduction to better show the contributions, significant findings as well as the structure of the paper. 3) We have also added statements that better present the research problem in the Introduction. 4) To improve the flow of the paper, we have also changed the title of the Section 'Methodology' to 'Methodology and Results'. 5) We have also emphasized the significant findings in the discussions and the Conclusions. 6) Updates have been made to Fig 2 to show missing values. 7) The Conclusions have been revised to include the significant results, contribution and the weakness, which will be addressed in future work.
See the authors' detailed response to the review by Huiling Chen
See the authors' detailed response to the review by Sadiq Hussain
The definition of a student is a person who attends school or any education institution level to achieve a certain level of knowledge or skill set in a course under the supervision of an educator. Almost everyone was once a student with responsibilities to acquire proper education. Acquiring knowledge by means of getting the right education is of utmost importance and each person should have basic equality in receiving education.
When discussing education at the secondary level, a vital aspect to consider is student performance. Student performance can be assessed in a variety of dimensions, either through exam-based assessment or participation-based assessment. Exam-based assessment includes quizzes, midterms, and final exams, while participation-based assessment is a two-way communication during learning and group activities.
Apart from the obvious, there are so many factors that can affect student performance, such as individual habits, absenteeism, social activities after school and others. This gives way to having machines to learn patterns from data so that they can predict how well a student performs; by acknowledging these factors and subsequently detecting and improve their performance as early as possible.
The contributions of this paper are the identification of significant features that influence student assessment, which in turn can be used to develop various predictive models to ascertain student performance. This will assist educators to form corrective or remedial actions can help to improve student performance. In addition, this may also assist in formulating curriculums that may direct students to career pathways that are most suitable for them.
The paper is structured as follows: Related Works, Methodology and Results, followed by Conclusions.
Student performance is an essential part in a secondary-level education as it will show where the student stands when continuing to higher education. Daud et al.1 noted that the ability to predict the success of a student is essential and seems to be a fascinating area to dig into.
Sokkhey et al.2 found out that mathematics is one of the subjects that has scientific progression on students. All aspects of human life at various levels are influenced by mathematics and there are no instances in life where mathematics is not used.
Akhtar et al.3 discovered that social status is correlated with family’s social and monetary wealth. They managed to find the effect of monetary wealth on students’ grade in Pakistan.
Amazona et al.4 as well as Hussain et al.5 have adopted educational data mining (EDM) methods to perform gathering, achieving, and studying of information concerning student’s assessment and learning.
On another note, researchers have also looked at student dropout,6 interpersonal influences7 as well as career decisions after graduation albeit at the tertiary level.8–10
Exploratory data analysis (EDA)11 is a method of analyzing dataset to summarize the important features via visualization. EDA helps:
• to find errors.
• to check assumptions.
• to determine the tentative choice of suitable models and tools.
• to determine the relationship between the dependent and independent variables.
• to detect the directions and size of the relationship between variables.
Feature selection is a component of dimensionality reduction where it reduces the number of features to maximize the performance of a machine learning model. Too many features in a dataset can overwhelm a machine learning classifier and potentially reduce the efficacy.12
The Boruta feature algorithm is a wrapper algorithm that underpins the random forest model. From the results yielded by Tang et al.,12 feature selection is able to effectively recognize and improve overall evaluation metrics on their medical dataset research.
Support Vector Machine (SVM) is able to build the best possible boundary of a line called hyperplanes, which can segregate dimensional spaces into classes. In the work of Sekeroglu et al.,13 they achieved good results with SVM on Mathematics and Portuguese subjects from two secondary schools.
Naïve Bayes (NB) is based on Bayes rule of conditional probability and has high capabilities in dealing big datasets.4 The method is used to estimate the probability of a property given set of data as proof and Bayes’ theorem. The posterior is calculated from the product of likelihood and prior and divisible by its evidence.
Multilayer perceptron (MLP) underpins the artificial neutral network (ANN).4 It has an interconnection of perceptron in which it flows from the input to the output in a single direction with multiple routes.
In this research work, the approach consists of seven stages, namely data acquisition, data processing, data integration, data discretization, data transformation, feature selection and classification. The flow of the research is shown in Figure 1.

a) Data acquisition
The dataset of student performance is taken from a population of two Portuguese secondary schools namely Gabriel Pereira Secondary School (395 students)14 and Mousinho da Silveira Secondary School (649 students).15 In the survey, the students were taking the subjects, Mathematics and Portuguese. The two datasets were combined and consisted of 1044 students’ personal data and scores for the two subjects. The datasets are visualizations and shown in Figures 2 to 6.
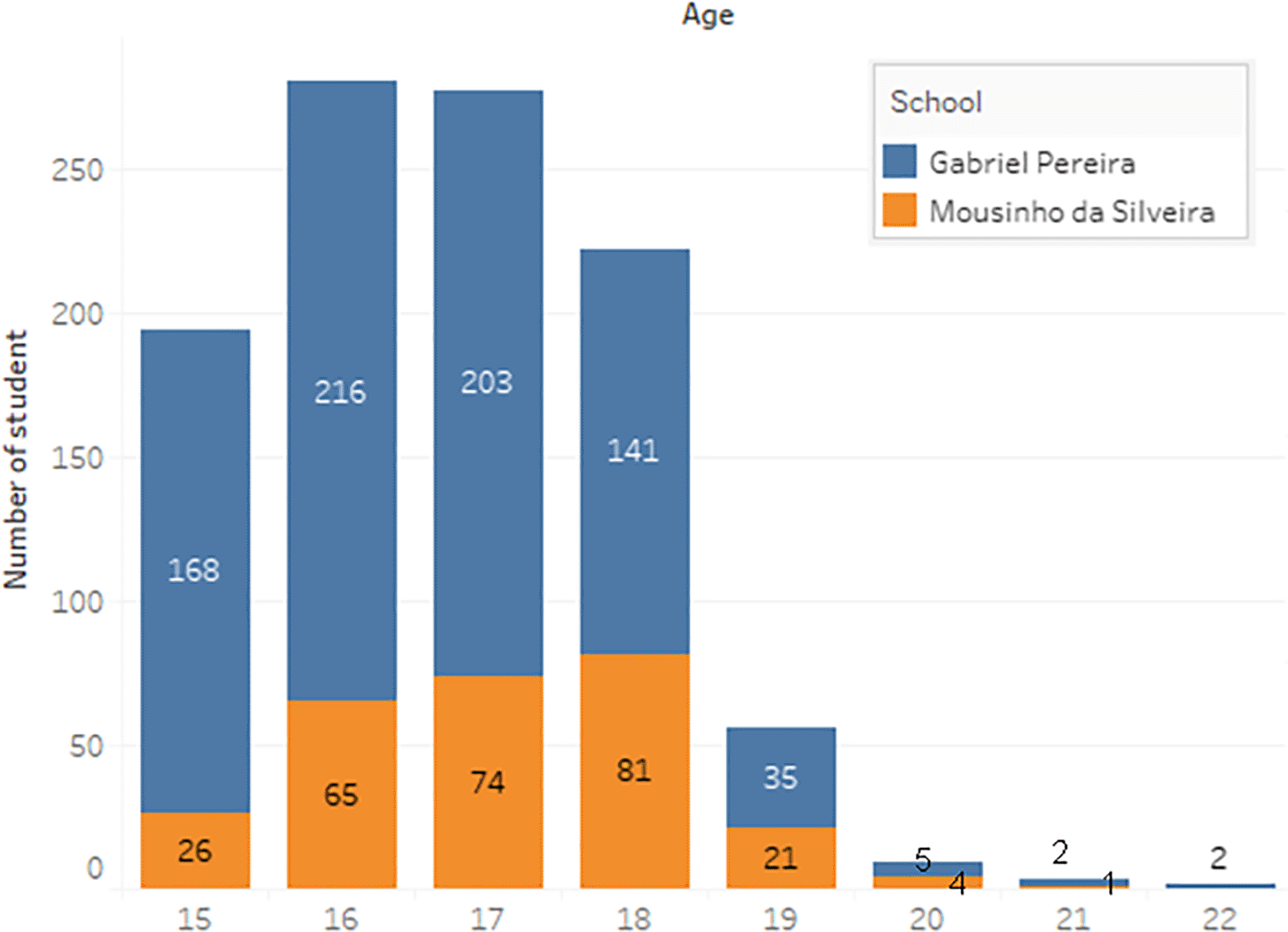
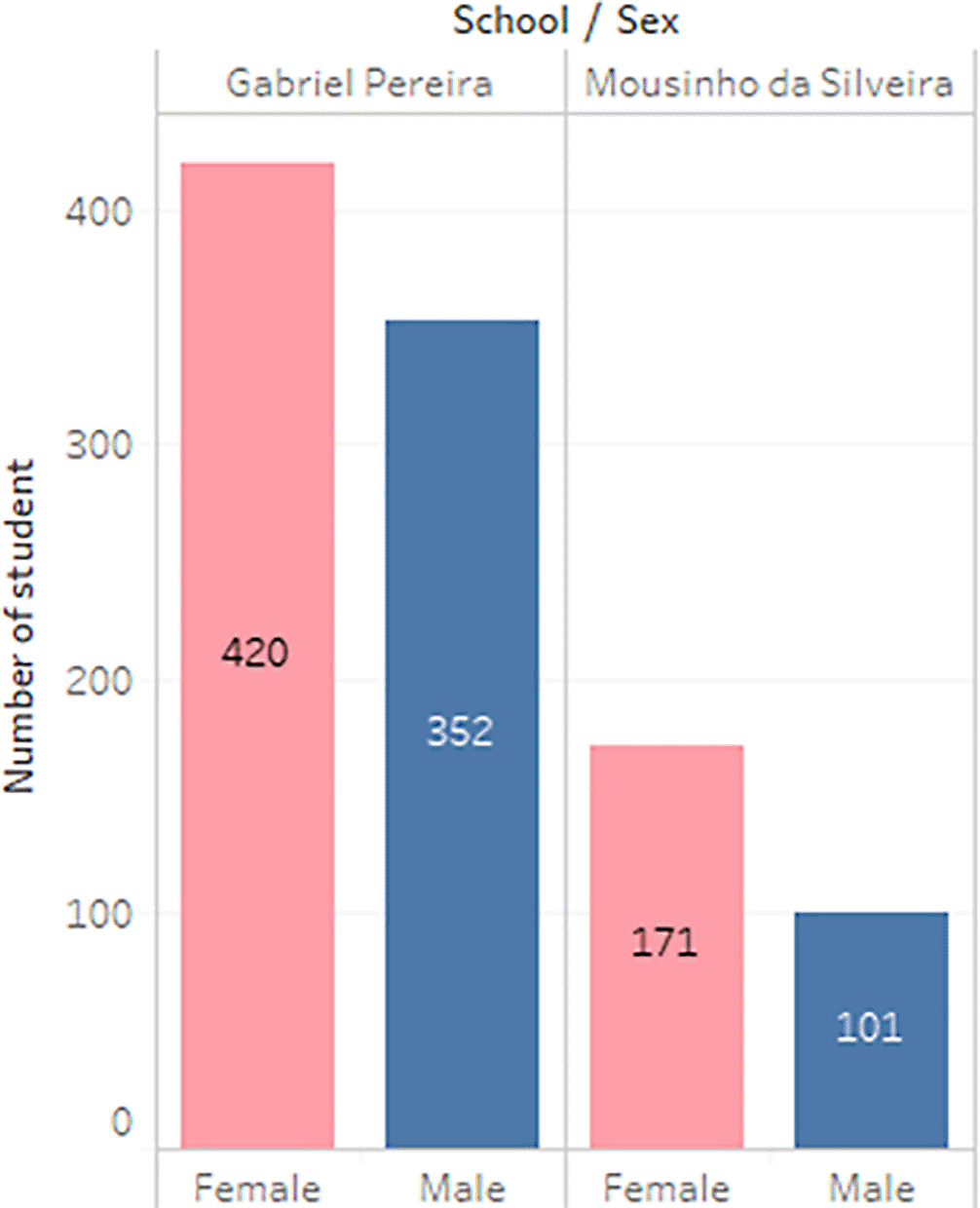

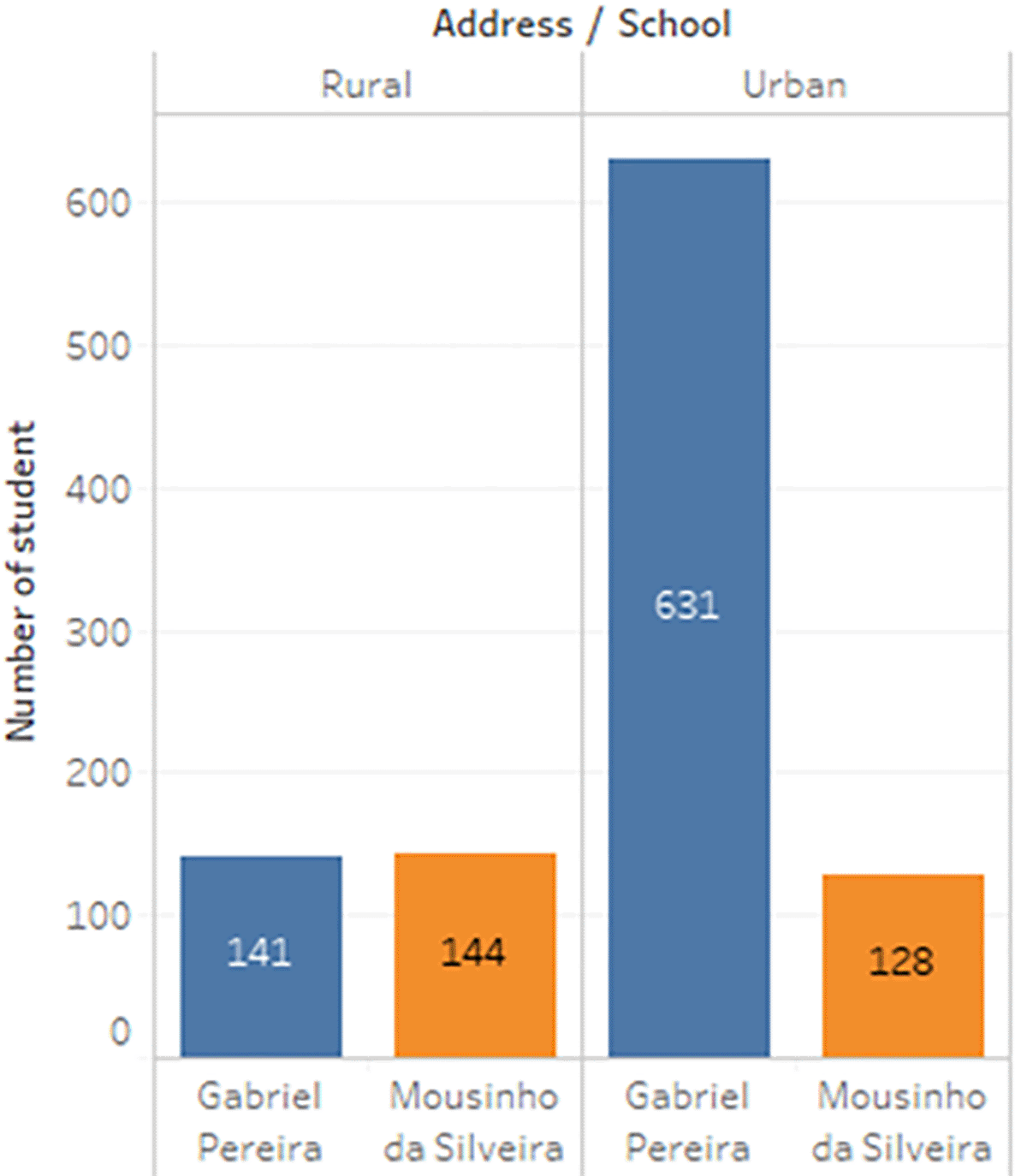
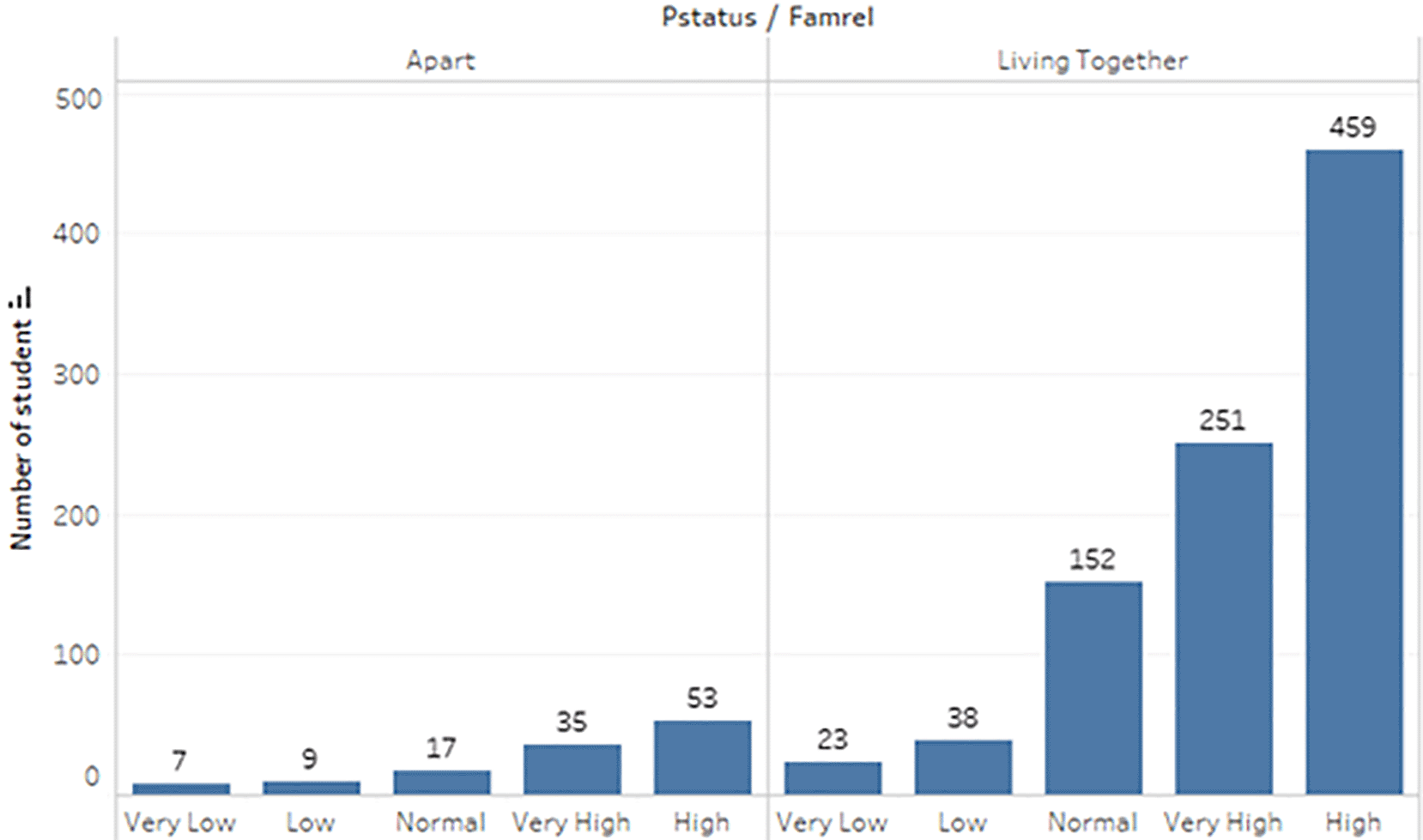
b) Data processing
This process helps to validate the two datasets by making sure there is no missing term in any feature.
c) Data integration
The two datasets were combined and consisted of 1044 students’ records with 33 features. By adopting EDA,11 the selected features are then assigned into four groups comprising of student background (12 features), lifestyle (18 features), history of grades (three features) and all features. Tables 1 to 3 shown the features in student background, lifestyle, history of grades respectively. The category ‘all’ consists of the entire 33 features.
| Feature | Description | Value |
|---|---|---|
| G1 | First period grade | 0–20 |
| G2 | Second period grade | |
| G3 | Final grade |
d) Data discretization
Tables 4 and 5 show the binary levels and 5 levels5 after discretization, representing the grades of the students.
e) Data transformation
The features are normalized with linear scaling to avoid bias on heavy weighted attributes.
f) Feature selection
Next, Boruta feature selection was performed to remove irrelevant features.
g) Classification
Three supervised machine learning techniques were implemented which are support vector machine, naïve Bayes, and multilayer perceptron 60–40 and 50–50 train-test splits and 10-fold cross validation. Four categories that comprise of student background, student lifestyle, student history of grades (history) and all features. Experiments are carried out on binary levels and five level classification. Binary levels classification will indicate fail or pass, meanwhile for the five levels classification is for student scores F, D, C, B and A.
GridSearchCV is applied to perform hyperparameter tuning. The performance metrics are accuracy, precision, recall and F1-Score. The experiments results are shown from Tables 6 to 11.
SVM obtained the highest accuracy, with scores of 77%, 80%, 91% and 90% on background, lifestyle, history of grades and all features respectively in 50–50 train–test splits for binary classification (pass or fail). SVM also obtained highest accuracy for the five-class classification (grade A, B, C, D and F) with 39%, 38%, 73% and 71% for the four categories respectively. Based on the results, history of student grades shows significant contribution to a good student performance, where the classification rates obtained are the highest among the four respective categories in each respective classifier. This finding is consistent with the observations from Hwang et al.,16 Mega et al.17 and Waheed et al.,18 that the students’ performance is highly related to the history of grades.
Table 12 shows the comparison of our models with other research work in 50–50 train–test splits for binary classification (pass or fail) on the dataset with population of two Portuguese secondary schools.
| Model and features | Data | ||
|---|---|---|---|
| Mathematics (395 students) | Portuguese (649 students) | Mathematics and Portuguese (1044 students) | |
| SVM on all features [our model] | - | - | 0.90 |
| SVM on history of grades [our model] | - | - | 0.91 |
| SVM on all features4 | 0.89 | - | - |
| Naive predictor on all features17 | 0.92 | 0.90 | - |
| SVM on all features17 | 0.86 | 0.91 | - |
The paper presented predictive modelling of student performance based on four categories. Based on the results, history of student grades shows significant contribution to a good student performance. SVM obtained the highest accuracy with scores of 77%, 80%, 91% and 90% on background, lifestyle, history of grades and all features respectively in 50-50 train-test splits for binary classification (pass or fail). SVM also obtained highest accuracy for five class classification (grade A, B, C, D and F) with 39%, 38%, 73% and 71% for the four categories respectively. The results show that the history of grades form significant influence on the student performance. The study looks at data only from Portugal and may not reflect a general view of the case. Future work will include more datasets from different countries. Also, other classifiers will be explored and investigated.
Kaggle: A machine learning approach to predictive modelling of student performance
https://www.kaggle.com/larsen0966/student-performance-data-set
and
https://archive.ics.uci.edu/ml/datasets/Student+Performance
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)