Keywords
Visual Surveillance, Density Estimation, Crowd Counting, CNN.
This article is included in the Research Synergy Foundation gateway.
Visual Surveillance, Density Estimation, Crowd Counting, CNN.
Hajj has been used as an opportunity for certain rituals. The Hajj is linked to the life of the Islamic prophet Muhammad, who lived in the seventh century AD, although Muslims believe that the tradition of pilgrimage to Mecca dates all the way back to Abraham’s time.1 For four to five days a year, over two million pilgrims from several parts of the world come to Mecca, where they tour the many places in Mecca and perform rituals.2 Each ritual has a short but challenging path to take. The Hajj authorities have confirmed that they are having difficulties in monitoring crowd density, which can be seen from the tragedies that occurred in September 2015.3 Regression-based approaches are normally used to estimate crowd density, to infer a mapping between lower-level capabilities and crowd evaluation.1,2
In this paper, we propose a method for crowd analysis and density estimation using deep learning.2 Our aim is to analyze the map of crowd videos and then use visualization for cross-scene crowd analysis in unseen target scenes. To do this, we must overcome the following obstacles: The challenge of prevailing multitude analysis is insufficient to help in the comparison of research into scene analysis.4–6
The main contributions of this research include:
1. A methodology to accurately perform the multitude analysis from an arbitrary multitude density and arbitrary perspectives in a separate video.
2. An evaluation of interventions and a comparison of these established methods specifically for activity with recent deep CNN networks.
3. A new dataset based on Hajj pilgrimage specifically for the crowds around the Kaaba area. Crowd datasets such as Shanghai Tech, UCSD, and UCF CC 50 are available for crowd analysis research, however our dataset contains large numbers of crowds.
Early works on the usage of detection methods in crowd counting are presented.7–11 Typically, these approaches refer to an individual or head detector through a sliding picture window. Recently, many exceptional object detectors have been presented, including Region Based Convolutional Neural Networks (R-CNN),12–14 YOLO15 and SSD,16 which can have a low precision of detection in scattered scenes. Some works such as Idrees et al.17 and Chan et al.18 implement regression-based approaches that learn directly from the crowd images in order to minimize these issues. They normally extract global19 (texture, gradient, edge) or local characteristics20 for the first step (SIFT,21 LBP,22 HOG,23 and GLCM21). Then several regression techniques such as linear regression24 and Gaussian mixture regression25 are employed to map the crowd counting function. These approaches manage the problems of occlusion and context disorder successfully, but spatial detail is still ignored. Thus, Lemptisky et al.26 have developed a framework that focuses on density assessment, learning to linearly plot local features and charts. A non-linear mapping, random forest regression, which is achieved the same forest to train two separate forests, is proposed in order to reduce the challenge of studying linear mapping.27 Previous heuristic models that traditionally used CNNs to estimate crowd density28–31 have improved significantly compared to conventional handcrafted methods.
We proposed a model that employs the state-of-the-art crowd counting algorithms used for the Hajj pilgrimage. The algorithms predicted specific regions on people’s heads for Hajj crowd images. The head size for each individual is identified using multi-stage procedures. Figure 1 shows the suggested architecture of CNNs, which is made up of three key components. The first component is the extraction of frames. To do this, we first gathered video clips of Hajj pilgrims. For this experiment we have collected video clips from YouTube using video recording software. To develop this model, we have used programming language python 3.6.15 with others libaries such as/opencv-python 3.4.11.43, NumPy 1.21.2, SciPy 1.21.2 and matplotlib 3.4.3.32 We executed 30 frame extractions per second to assemble all of the footage into one clip. Feature extraction at different resolutions is the method used in spatial feature extraction. The CNN prediction map has been utilized in our proposed method. A set of multi-scale feedback reasoning networks (MSFRN) was used to route the results of mapping to the MSFRN. Results from mapping were sent to the MSFRN where information fused across the scales and predictions were formed using boxes.32 Finally, crowd density results were obtained by utilizing the Non-Maximum Suppression (NMS) which uses several resolutions in combination to arrive at the accurate result. After completing the whole process we got the crowd density result. To compare with our proposed method the following existing algorithms were used. Adversarial Cross-Scale Consistency Pursuit was suggested by Zan Shen et al. as a new paradigm for crowd counting (density estimation) (ACSCP). A three-part Perspective Crowd Counting Network (PCC Net) has been suggested by Junyu Gao et al. Yuhong Li et al. suggested CSRNet made up of two main parts: CNN as the front-end for 2D feature extraction and a dilated CNN as the back-end. The CP-CNN developed by Vishwanath A et al. has four modules: the GCE, the LCE, the DME, and a Fusion-CNN (F-CNN). An image’s change in crowd density may be used to enhance the accuracy and localisation of the projected crowd count, as suggested by Deepak Babu Sam et al.
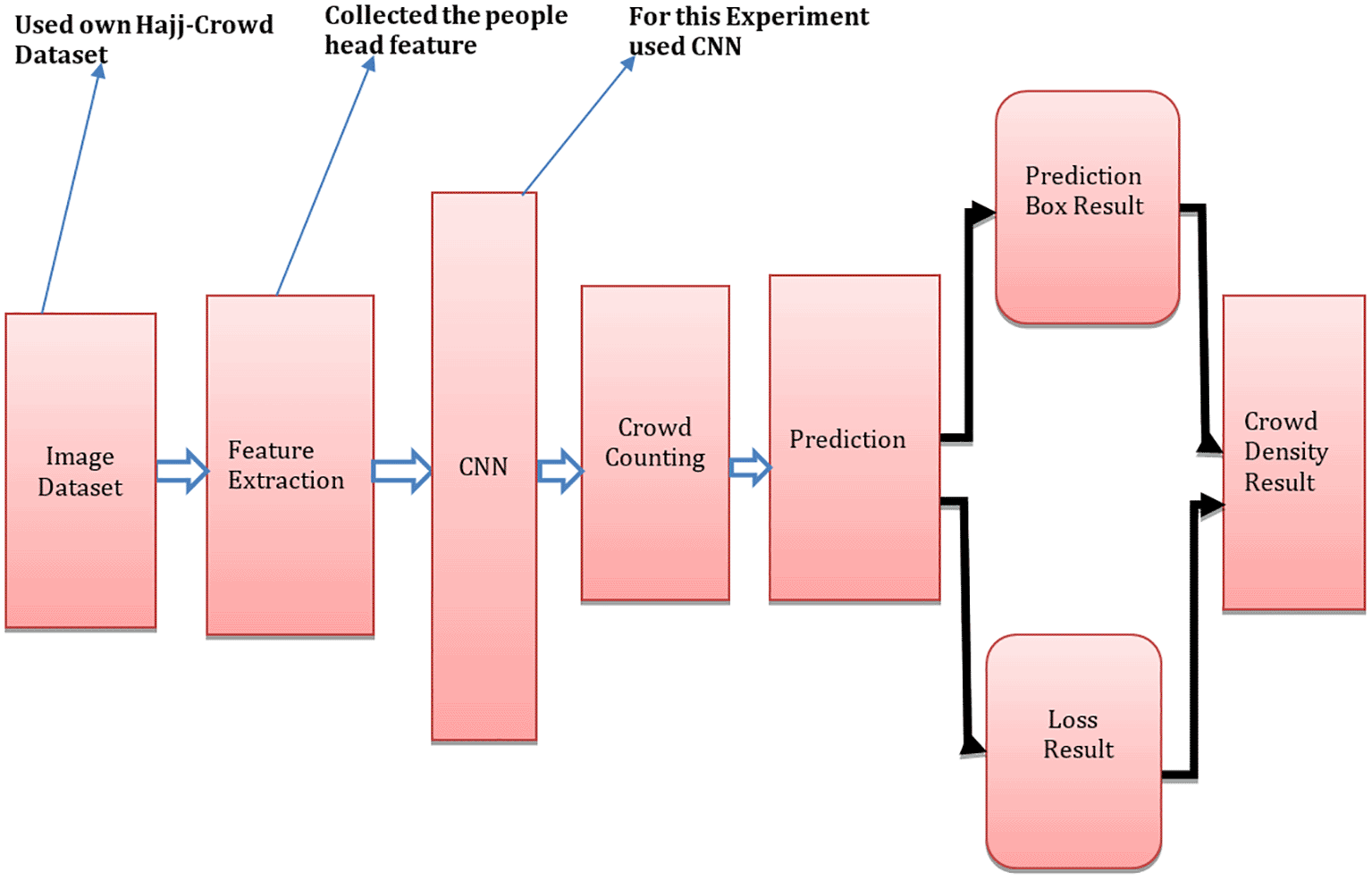
In addition to CNN detectors, all existing CNN-related detectors are built on a deep-backbone feature extractor network. Furthermore, it is possible that detection accuracy is linked to functionality consistency. CNN-enabled networks are often used in counting crowds, and give an approximate real time performance.31 The first five CNN convolution blocks initialized using ImageNet training are the backbone network’s starting point.33
Instead of making everything the same size, we used a per pixel categorization approach for scaling. The model classifies each head as part of or inside the context of one of the bounding boxes. Model scale branches generate map set , showing the confidence level for each pixel for classes of the box. The final requirement for training the model is to know the model’s users’ head sizes, which is not easily accessible and cannot be reliably inputted from typical crowd sourced databases. We created a method to help estimate head sizes in this research. We used the crowd dataset accessible point annotations to get the ground truth. People’s heads are located at certain coordinates with these annotations. Note that only quadratic boxes are regarded as box-like. However, on the whole, they are deemed experimentally effective,
In choosing the Box U+03B2 (s)/b s for each scale, a popular approach is used. At the maximum resolution scale (s = ns U+2212 1), the initial box size (b = 1) is often set at one, which increases the ability to handle the extremely congested density. The standard size of increase values on different scales are the y = 4, 2, 1, 1 definition. Please note that at high-level (0.5 and 0.25), in which coarse resolution is appropriate (as shown by Figure 1), boxes of better sizes include those of low resolution (0.16 and 0.25).33
For testing the model in Figure 1, the predictive fusion procedure is utilized in place. The multi-resolution prediction is made across all branches of the picture pipeline. Using these prediction charts, we can anticipate that the locations of the boxes are linearly scaled from the resolution of the input. When the present NMS is in place, then it is used to prevent multi-threshold mixing.
The HAJJ-crowd dataset was collected from live television broadcasts via YouTube of the Mecca Hajj 2019. All of the images depict pilgrims performing tawaf around the magnificent kaaba. Tawaf involves walking around the Kabba seven times. The moving process begins in the opposite direction of the clock. The video frames have been extracted and saved as.jpg files for future examination. The dataset contains a total of 1500 crowd images. As a result, 1500 images and ten film sequences are captured in several populous areas surrounding Kaaba (Tawaf region), with some typical crowd scenarios, such as touching a black stone in the Kaaba region and tossing a stone into the Mina region. All images have a resolution 1280 × 720 HD and videos have a resolution 1080p.
We used python 3.6.15 and opencv-python 3.4.11.43 as an annotation tool to easily annotate head positions in the crowds. The process involved two types of labelling: point and bounding box. During the annotation process, the head is freely zoomed in/out, split into a maximum of 3 × 3 tiny patches, allowing annotators to mark a head in 5 sizes: 2x (x = 0,1,2,3,4) times the original image size.
Firstly, we gathered all images of size 1280 × 720 pixels. Then we applied a profound learning method to improve the CNN and obtain the best outcomes. Training and analysis was done using the pytorch 1.9.1 framework and operating system Ubuntu 18.04.6 LTS deep learning packages on NVIDIA GEFORCE GTX 1660Ti GPU. For profound learning, we utilized packages such as opencv-python 3.4.11.43, NumPy 1.21.2, SciPy 1.21.2, matplotlib 3.4.3.
The HAJJ-crowd data collection consisted of three sections, the examination, validation and training. The count accuracy which is the Mean Absolute Error (MAE) and Mean Squared Error (MSE) should be measured in two measurements. The equations are shown below:
In this scenario, N is assumed to be the test sample, yi is regarded as the count mark, whereas y′i is the approximation count sample. For each set of persons, the preceding group consists of (0), (0, 1000) (1000, 2000), (2000, 3000). In accordance with the annotated number and quality of the image, each image is allocated an attributing label. In the test set, MAE and MSE are applied for the matching samples in a particular viewpoint for each class. For example, the luminescence attribute calculates average MSE and MAE figures based on two categories that demonstrate the counting models’ sensitivity to luminescence variation.
Figure 2(a) and Figure 2(c) indicate clearly that there is no significant change in the loss of pixels from zero to ten epochs, whereas there is a ten pixel loss from ten to 20 epochs. However, the pixel loss between 20 and 30 epochs keeps increasing, up to 40–52 epochs. At the end, the pixel loss is 15.0 at 52 epochs. We may get genuine training loss from this experiment. More than anything, the legitimate pixel loss in tests is 17 at 40 epochs and 14 at 52 epochs. At the same time, based on the preceding equation, we computed the MAE test. We have computed the valid MAE test loss and the valid MAE test that is shown in Figure 2(b) and Figure 2(d). For the MAE test, we found that the error is over 600 when the epoch is zero. We saw the error coming down to 200.0 after 52 epochs. In the Test MSE, we saw the error is over 425 if the epoch is zero. After that, we saw that the error came down to 240.0, after 52 epochs. Figure 2 shows the graphical representations of the results.
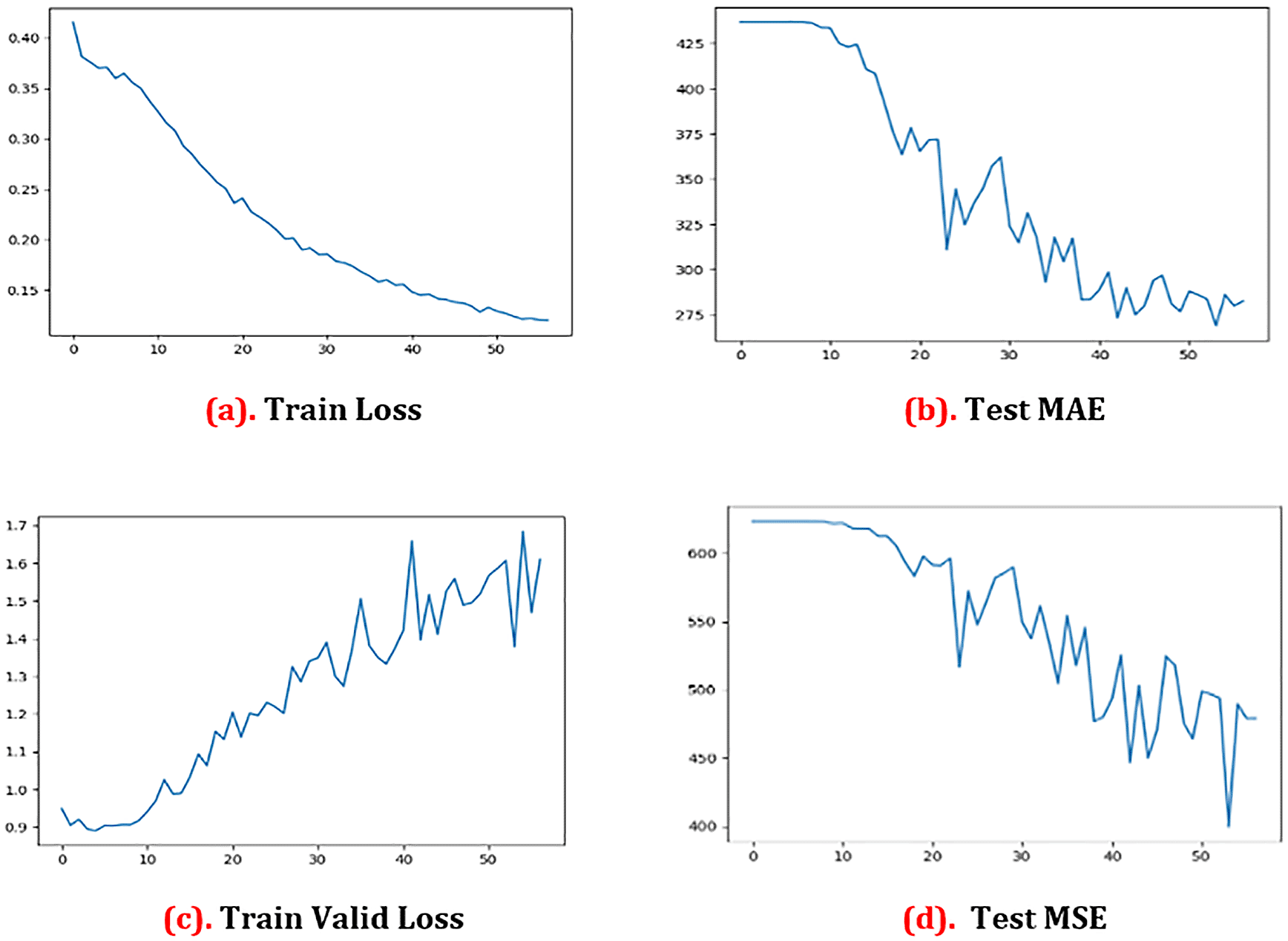
MAE = mean absolute error; MSE = mean squared error.
The HAJJ-crowd dataset contains a large number of crowds as well as a density collection. It contains 1050 training images and 450 testing images with the same resolution of 1280 × 720 pixels. The mainstream UCF CC 50 dataset are compared with the most advanced non-defined approaches34–38 in terms of the MAE and MSE. Our method and dataset outperforms the state-of-the-art methods, and attains a remarkable MAE result of: 200.0 (Average of 82.0 points improvement) and MSE of 240.0 (Average of 135.54 points improvement). Table 1 shows the comparison with state-of-the-art methods.
This paper provides a new approach for crowd density estimation using a convolutional neural network. A multi-column structure of high-level feedback processing that addresses the problems in large crowds is the proposed model of the convolutional neural network. The proposed model can recognize moving crowds, which leads to improved performance. We found that crowd analysis prior to crowd counting has significantly boosted the efficiency of counting for extremely dense crowd scenarios.
Due to the ethical and copyright limitations around social media data, the underlying data for this study cannot be disclosed. The original dataset contains a total of 1500 images, all of which were collected from the Mecca Hajj 2019. The dataset contains three classes of crowd density around tawaf area. The Methods section offers extensive information that will enable the research to be replicated. If you have any questions concerning the approach, please contact the corresponding author.
Software available from: https://github.com/romanbhuiyan/CrowdCounting.
Archived source code at time of publication: https://doi.org/10.5281/zenodo.5635486.32
R.B. developed the experimental model, structure of the manuscript, performance evaluation and wrote the preliminary draft. J.A. helped to fix the error code, checked the labelled data and results as well as reviewed the full paper. N.H. gave some important feedback on this paper. F.F. helped with the structured full paper revision. J.U. helped format the full paper. N.A. checked the revised version and added a few paragraphs to the full article. M.A.S. helped with the paper organization. All authors discussed the results and contributed to the final manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)