Keywords
human activity recognition, smartphone, temporal convolutional network, dilated convolution, one-dimensional inertial sensor
This article is included in the Research Synergy Foundation gateway.
human activity recognition, smartphone, temporal convolutional network, dilated convolution, one-dimensional inertial sensor
Human activity recognition (HAR) is extensively applied in various applications such as personal health monitoring,1,2 geriatric patient monitoring,3 ambient assisted living,4 etc. The widespread use of smartphone-based HAR is due to the ubiquity of smartphones and low-cost sensors. Additionally, sensor-based HAR provides a non-intrusive solution.
Numerous HAR algorithms have been proposed, including handcrafted feature (HCF) methods5-7 and deep learning (DL) methods.8-10 HCF methods require complex data pre-processing and manual feature engineering. The manually extracted features are highly dependent on prior knowledge, leading to high bias and loss of essential implicit patterns. Hence, DL methods, such as convolutional neural network (CNN),8,9 recurrent neural network (RNN), and long-short term memory network (LSTM),10,11 are devised to overcome the downfalls of HCF methods. DL methods involve no complex data pre-processing, and features are automatically tuned for the desired outcome. Besides, the architecture is adaptable to different applications.
Although CNN is good in extracting spatial features, it hardly learns temporal features, which are significant in motion analysis. RNN and LSTM are feasible for time-series data, but they suffer from several shortcomings. For example, RNN is prone to short-term memory problems, leaving out important information at the beginning if the input sequence is too long. LSTM prevails over RNN as the former has a longer-term dependency and is less susceptible to vanishing gradient. However, LSTM requires higher computation due to multiple gate operations and more memory to store partial results throughout the training phase.
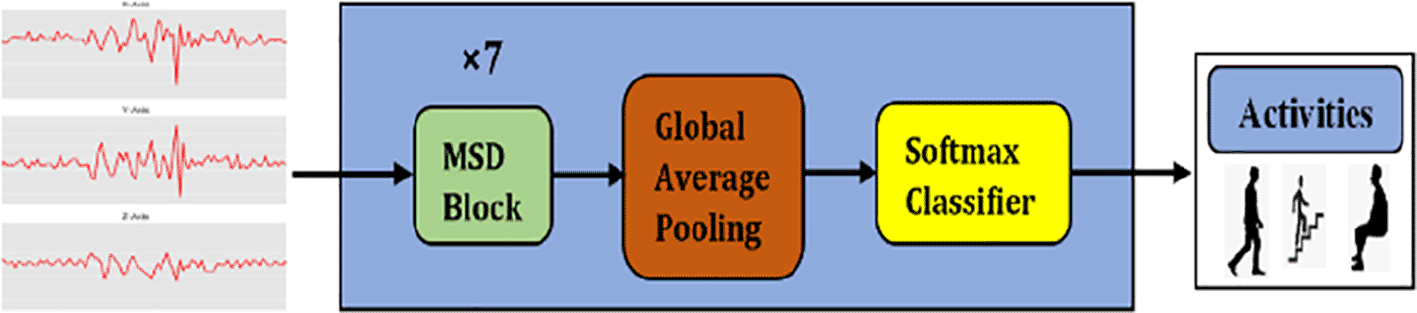
This work proposes a multiscale temporal convolutional network, termed MSTCN. As illustrated in Figure 1, MSTCN is constituted by multiscale dilation (MSD) blocks, global average pooling and softmax. The contributions of this work are:
- A deep analytic model, amalgamating the Inception model and Temporal Convolutional Network (TCN), is developed to extract spatial-temporal features from inertial data. MSTCN requires minimal data pre-processing and no manual feature engineering.
- Multiple different-sized convolutions are incorporated in MSTCN to perform multiscale feature extraction. The scaled features encompass low-to-high level features of the data. The concatenation of multiscale features enables MSTCN for better data generalisation.
- Dilated convolution is implemented to improve the convolution kernel's receptive fields. The dilation captures the global characteristics of the inertial data and retains a longer effective history.
- A comprehensive experimental analysis is conducted using two popular public databases, UCI12 and WISDM.13 Subject independent protocol is implemented where the training and testing sets do not share the data from the same users.
One-dimensional inertial data undergoes a complicated pre-processing in HCF methods to extract salient statistical feature vectors in time and/or frequency domains. The manually extracted features are then fed into standard machine learning classifiers, such as support vector machine (SVM),7,12 ADA Boost,14 Random Forest,6 C4.5 decision tree,15 etc., for activity classification. He and Jin5 proposed a discrete cosine transform method to extract features and classify the features using multiclass SVM. Lara et al.,16 developed an additive logistic regression, boosting with an ensemble of 10 decision stump classifiers. In the works of Ronao and Cho,17,18 the authors explored the Continuous Hidden Markov Model (HMM) to perform activity recognition in two stages, where the first stage is for static and dynamic classification and the second stage is for course classification. Although these methods produce an adequate performance, they are highly dependent on the effectiveness of the manual feature engineering techniques.
Recently, researchers leaned towards DL methods since DL requires minimal to zero pre-processing and feature engineering. Ronao et al.,8 Yazdanbakhsh et al.,9 and Huang et al.,18 proposed a CNN-based deep learning system to perform HAR. The reported empirical results show the feasibility of the CNN-based method in analysing motion data. Besides, three-layer LSTM was proposed to classify human activities.11 LSTM variant, known as Bidirectional LSTM, was employed in HAR.10 This model uses richer information, i.e. previous and subsequent information, to perform activity recognition. Nair et al. proposed two variations of TCN, namely Dilated-TCN and Encoder-Decoder TCN in HAR.19 In addition, another two TCN-based models are proposed in Ref. 20, namely TCN-FullyConnectedNetwork and deepConvTCN. Both works of Nair et al.,19 and Garcia et al.,20 concluded that the TCN-based models achieved better performance than existing recurrent models due to their longer-term dependencies.
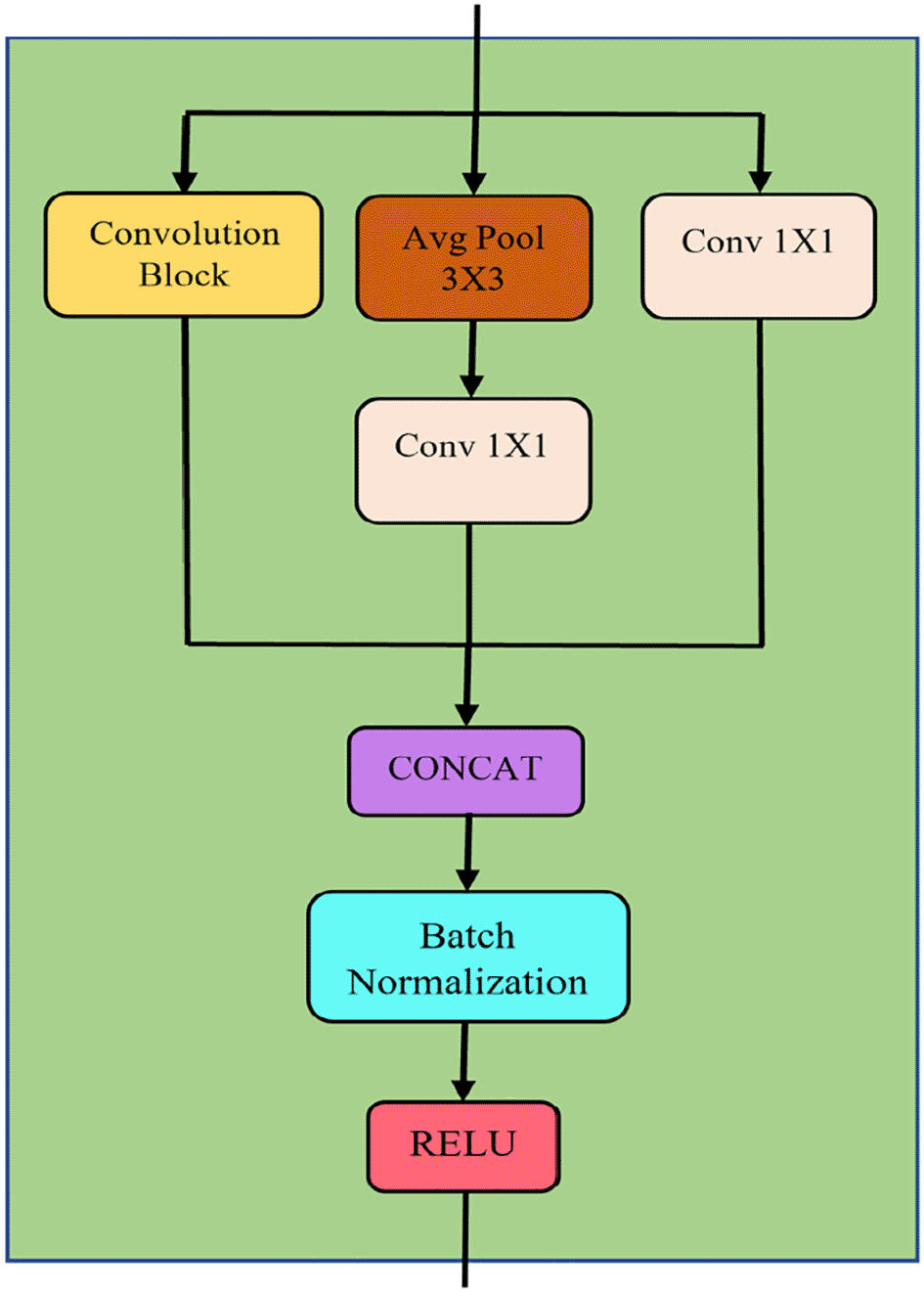
The raw inertial signals were first pre-processed to remove any null values. Next, the pre-processed signals were segmented using sliding window technique. In specific, the signals were partitioned into fixed-sized time windows and each window did not intersect with another window. Then, the segmented data was fed into seven MSD blocks in MSTCN (green box in Figure 1) for feature extraction. Figure 2 illustrates the structure of an MSD block. MSD block was designed based on the inception module structure for multiple scale feature extraction.21
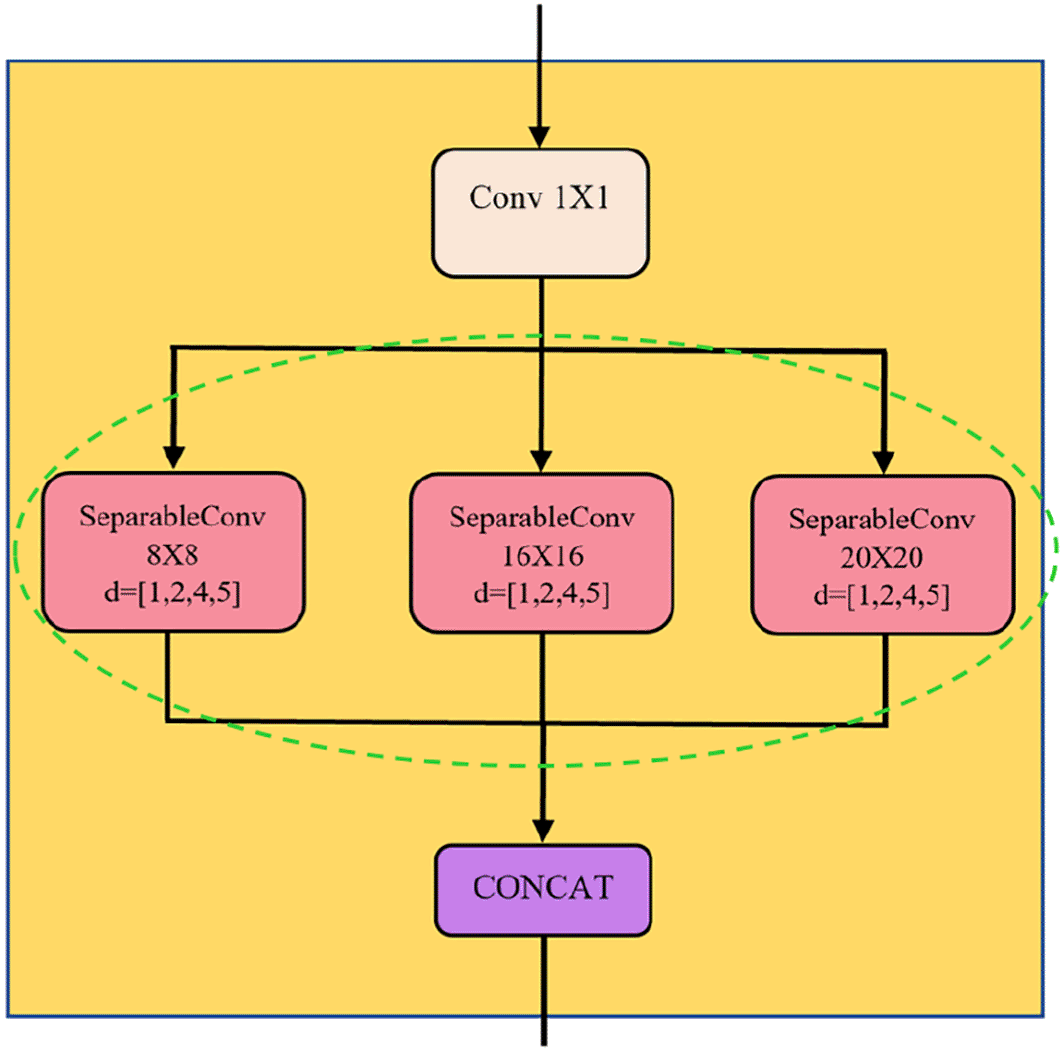
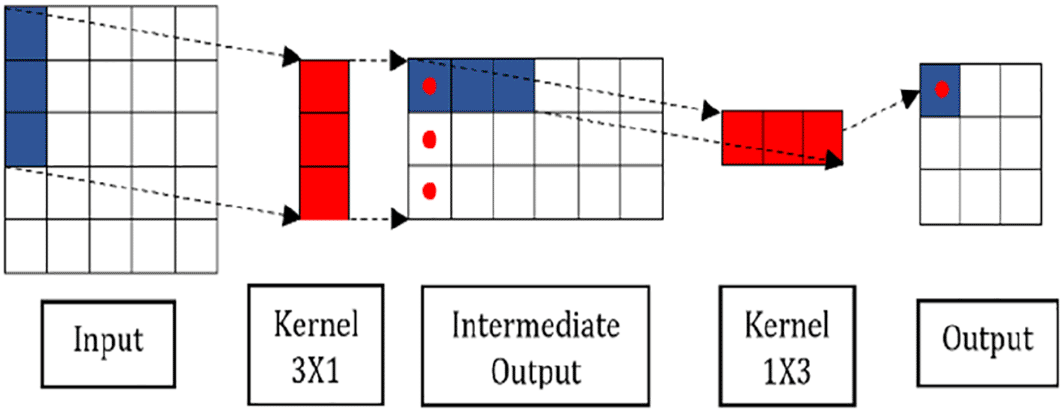
Convolutional unit in MSD block extracts spatial-temporal features of the motion data. The components of the convolutional unit are illustrated in Figure 3. First, the input channels are processed via one-by-one causal convolution for dimensionality reduction. This layer, known as bottleneck layer, adopts fewer filters to reduce the number of features maps while the salient features are retained. The causal padding preserves the input sequence's length and order, preventing information leakage from the future into the past. Next, the reduced feature maps are further processed parallelly by separable convolutions (SepConv) with three different-sized filters to extract features at multiple scales. Figure 4 shows the operation of SepConv. The reason for implementing SepConv in MSTCN is that it can produce fewer parameters and reduce computational complexity.
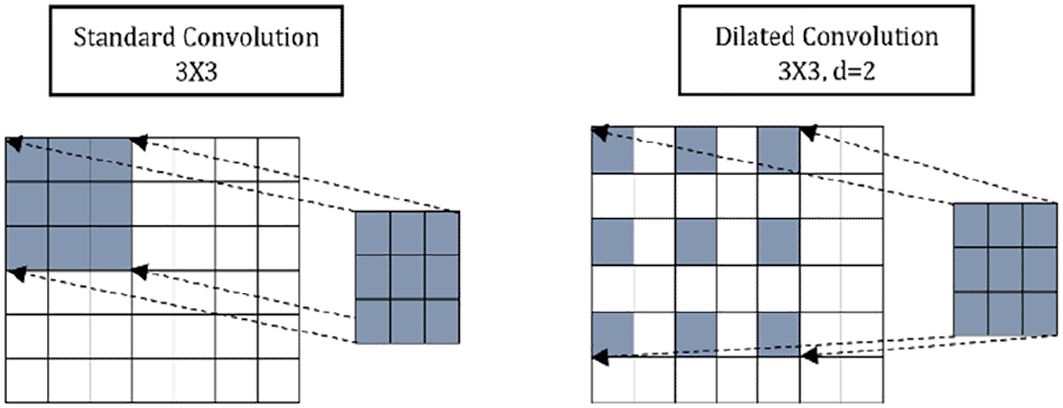
Dilated convolution prevails over classical convolution because it allows the model to have a larger receptive field, controlled by the dilation rate. This helps capture long-time sequences' global features without increasing the model's parameters and memory. Figure 5 shows the difference between the dilated convolution and the classical/standard convolution. Dilations are implemented in SepConv to increase the receptive fields of the convolution kernels.
The core difference between MSTCN and TCN is that the dilated convolutions are organised parallelly in MSTCN (green dotted circle in Figure 3) but in a serial form in TCN. With the proposed layout, each extracted multiscale feature from the SepConvs with differently sized filters is concatenated for a better model generalisation, see Figure 3.
In a MSD block, average pooling (brown box in Figure 2) down-samples the feature map to reduce noise and dimensionality. Additionally, it also preserves localisation. The pooling's output is fed into a one-by-one convolution. A residual connection is formed by passing the input into a one-by-one convolution, followed by a batch normalisation. This residual connection ensures longer-term dependencies and prevents information loss. Further, it also reduces the vanishing gradient effects. On the other hand, batch normalisations in MSD block are to reduce the internal covariance shift in the model during training. Furthermore, ReLU activation is chosen for its non-linearity, and the gradient vanishing is minimised.
The features extracted from the series of MSD blocks are further fed into the global average pooling (GAP). In MSTCN, GAP replaces the traditional fully connected layers because GAP is more suitable.22 This operation generates one feature map according to each activity from multi-dimensional feature inputs. Besides, GAP is also considered as a structural regulariser since it imposes the generated map as the confidence map for each class.22 With this, it better prevents overfitting by reducing the number of model parameters. Additionally, GAP does not require parameter optimisation.
In the classification stage, a simple softmax classifier is used. The softmax activation formula is defined:
where is the input vector, is the exponential function of the input, is the number of classes and is the exponential function of the output. This function outputs probabilities of each class, ranging from zero to one, and the target class will have the highest probability.
The experiments were conducted on a desktop with Intel® Core™ i7-8750H CPU with 2.20 GHz, 16GB RAM and NVIDIA GeForce GTX 1050 Ti with Max-Q Design and 4GB memory. Two public databases, UCI12 and WISDM,13 were used to assess the reliability of the proposed model. In addition, subject independent protocol was implemented where there were no overlapping users between training and testing sets. Details of the databases are recorded in Table 1. The evaluation metrics used in this work include precision, recall, F1 score and classification accuracy.
Three experiments were conducted on UCI dataset to study the effects of (1) convolution, (2) pooling and (3) regularisation on MSTCN's performance. Table 2 shows the proposed model's performances using dilated one-dimensional (1D) causal convolution (CC) and dilated 1D separable convolution (SC). From the empirical results, it was observed that the parameters of SC are approximately half of the parameters of CC. Usually, models with more parameters perform better since maximal data patterns are captured from the training samples. However, when the training sample size is limited, these models might tend to overfit and not generalise properly to the unseen data, leading to poor performance. In this study, SC obtains ~0.04 higher F1 score than CC.
| Dilated 1D causal convolution | Dilated 1D separable convolution | |
|---|---|---|
| Number of parameters | 6 062 086 | 3 750 406 |
| Precision | 0.9357 | 0.9761 |
| Recall | 0.9375 | 0.9750 |
| F1 score | 0.9356 | 0.9752 |
| Accuracy | 93.62 | 97.46 |
Next, the performances of max-pooling and average pooling were studied. From Table 3, average pooling dominates max-pooling by attaining F1 score of 0.9752. Average pooling performs better in this domain because it takes every value into account. With this, the information leakage is prevented, and feature localisation is preserved.
| Max pooling | Average pooling | |
|---|---|---|
| Precision | 0.9478 | 0.9761 |
| Recall | 0.9468 | 0.9750 |
| F1 score | 0.9463 | 0.9752 |
| Accuracy | 94.67 | 97.46 |
Table 4 shows the performance of MSTCN with different regularisation settings. The regularisation is performed at the bottleneck layer in MSTCN. L1 is good at dealing with outliers and sparse feature spaces. Moreover, it also reduces the coefficient of the insignificant features to zero and removes them. It is a good feature selector. L2 learns complex patterns from the dataset and prevents overfitting. By combining the usage of L1 and L2, we can leverage the benefits from both. Hence, the best result of 97.5% accuracy is obtained with L1 and L2 regularisation.
A performance comparison between MSTCN and other state-of-the-art methods was conducted. Tables 5 and 6 show the performance on UCI and WISDM datasets using subject independent protocol. The proposed MSTCN showed extraordinary performances against the existing methods by achieving 97.46% accuracy on UCI and 95.20% on WISDM. The experimental results will be discussed further in the following section.
| Type | Accuracy (%) | |
|---|---|---|
| Statistical features + SVM12 | HCF | 96.00 |
| Statistical features + Continuous HMM17 | HCF | 91.76 |
| Statistical features + HMM Ensemble23 | HCF | 83.51 |
| Statistical features + RF24 | HCF | 78.00 |
| Statistical features + Linear SVM7 | HCF | 86.00 |
| Statistical features + Hierarchical Continuous HMM25 | HCF | 93.18 |
| Statistical features + Dropout Classifiers24 | DL | ~76.00 |
| Statistical features + Data Centering + CNN26 | DL | 97.63 |
| CNN8 | DL | 94.79 |
| Frequency features + CNN8 | DL | 95.75 |
| Bidirectional LSTM10 | DL | 93.79 |
| Dilated TCN19 | DL | 93.80 |
| Encoder-Decoder TCN19 | DL | 94.60 |
| Statistical features + MLP27 | DL | 95.00 |
| Frequency and Power features + Multichannel CNN28 | DL | 95.25 |
| Statistical features + InnoHAR29 | DL | 94.50 |
| MSTCN (Proposed Method) | DL | 97.46 |
| Methods | Type | Accuracy (%) |
|---|---|---|
| Statistical features + RF24 | HCF | 83.46 |
| Statistical features + RF6 | HCF | 83.35 |
| Statistical features + Dropout Classifiers24 | DL | 85.36 |
| Statistical features + CNN26 | DL | 93.32 |
| Dilated and Strided CNN9 | DL | 88.27 |
| Data Augmentation + Two Stage End-to-End CNN18 | DL | 84.60 |
| Statistical features + CNN30 | DL | 94.18 |
| MSTCN (Proposed Method) | DL | 95.20 |
From the empirical results, we observe that:
1) MSTCN prevails over HCF methods on both datasets because the proposed model can better capture discriminating features from the motion data. Unlike handcrafted features, these deep features are less biased as they are not dependent on prior knowledge. This is crucial, especially for a subject independent solution.
2) Generally, MSTCN outperforms most CNN-based approaches, with accuracy scores of ~97.5% in UCI and ~95.2% in WISDM. This performance exhibits that MSTCN can capture the global and local features that discriminate each activity. Besides, the implementation of GAP in MSTCN is less prone to overfitting.22 Hence, it is suitable for subject independent HAR.
3) MSTCN dominates the recurrent model10 due to its ability in modelling longer-term dependencies via dilated convolution. Residual connection and ReLU activation in MSTCN allow the model to be less susceptible to gradient vanishing and exploding.
4) MSTCN is a TCN-variant model. The obtained empirical results demonstrate that MSTCN outperforms the ordinary TCNs (Dilated TCN and Encoder-Decoder TCN).19 MSTCN learns features at multiple scales via different convolutions with differently sized filters. The concatenation of these multi-scaled features produces global feature maps encompassing each activity class low-to-high level features, leading to better recognition.
A new deep analytic model, known as MSTCN, is proposed for subject independent HAR. MSTCN is based on the architectures of the Inception network and temporal convolutional network. In MSTCN, different-sized filters are adopted in dilated separable convolutions to extract multiscale features with the enlarged receptive field of each kernel for longer-term dependencies modelling. Besides, average pooling is performed for dimensionality reduction and locality preservation. The inclusion of residual connections in MSTCN prevents information leakage throughout the network. The efficiency of MSTCN is evaluated using UCI and WISDM datasets. The empirical results demonstrate the superiority of MSTCN over other state-of-the-art solutions by achieving 0.9752 and 0.9470 F1 scores, respectively, in UCI and WISDM.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)