Keywords
repository, business process management, clinical trials, data sharing, raw data, individual patient data
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the Health Services gateway.
repository, business process management, clinical trials, data sharing, raw data, individual patient data
Revisions were made based on the feedback from Reviewers. We further clarified our previous findings and our proposed ideas, as well as added further information about the Vivli and CSDR.
See the authors' detailed response to the review by Paul Grefen
See the authors' detailed response to the review by Ida Sim and Rebecca Li
Considerable interest has been shown recently in increasing transparency of clinical trials. National Institutes of Health (NIH) defined clinical trials as research studies that explore whether a medical strategy, treatment or device is safe and effective for humans, and, if conducted well, they produce the highest level of evidence available for healthcare decision making among primary studies1. However, very often raw data from clinical trials are hidden from scientific community2,3. Sharing individual patient data (IPD) from clinical trials in a central openly available repository was suggested as a solution4.
Although ideas about open data sharing come mostly from researchers, it has recently been shown that clinical trial participants support this idea too. A recent survey of individuals who participated in a diverse group of clinical trials showed that the overwhelming majority would support sharing of their data and that their willingness to share data would not be much different depending on the purpose of the data use5.
In computer sciences, a repository is defined as a central location in which data are stored and managed6. Currently, there are no repositories that host open-access data from clinical trials exclusively. In our earlier study (Gabelica et al.; unpublished data) we found 14 open-access repositories on the Internet, which host clinical trial data together with data from other types of studies. This study was an environmental scan, with the last search date in December 2016. The 14 repositories hosting clinical trial data at that time were: B2Share, Data Repository for the University of Minnesota (DRUM), Dryad, Easy/ DANS, Edinburgh Datashare, Figshare, Interuniversity Consortium for Political and Social Research (ICPSR), Open Science Framework (OSF), Research Data Australia, Swedish National Data Service (SND), Zenodo, University of Bath, London School of Hygiene and Tropical Medicine (LSHTM) Data Compass, Harvard Dataverse.
However, those repositories were highly heterogeneous, i.e. they were not uniform. Furthermore, they were not devoted to clinical trials exclusively and most allow data providers to restrict data access for the “shared” data. For this reason, there is a need for a universally adopted open-access repository devoted specifically and exclusively to data from clinical trials. Instead of having a variety of different repositories, it would be ideal to have one with the desired characteristics.
The US National Academy of Medicine (NAM), formerly called the Institute of Medicine (IoM), has indicated that it would be beneficial to have one single centralized data store, “to collect all clinical trial data worldwide into one central database”. Such a model would benefit from economies of scale, and individuals or groups interested in data would need to search in one database only7.
It is acknowledged that there are opinions that valid reasons may exist for sharing clinical trial data under managed access. The IOM recommendation states [quote]: “The committee believes that open access (to the public with no controls) is appropriate and desirable for clinical trial results, and, in some cases, no or few controls on sharing other types of clinical trial data may be the preferred approach when all stakeholders involved in a trial (i.e., sponsors, investigators, and participants) are comfortable with this approach and believe the benefits outweigh the risks. In many cases, however, sponsors, investigators, and/or participants may have concerns about an open access model for certain clinical trial data.”
We firmly support the idea of uncontrolled access to all raw data from clinical trials, but, of course, in a way that will protect the participants’ privacy. While acknowledging that there might be different opinions, we do not think that managed access or controlled access system is the best solution because it contains a discretional right to withhold data from the requestor. It is recognized that there are challenges associated with such an approach, but if we start addressing the challenges, and considering how such a repository would look like, we could make it a reality one day.
This manuscript aimed to propose how an ideal open-access repository for clinical trial data should look like and to develop a model of such repository using business process analysis approach.
Firstly, we suggested which features an ideal repository should have. Some of the features were informed by the earlier study that searched for repositories hosting raw data from clinical trials and analyzing their characteristics. Insufficiencies of existing repositories were taken into account and several additional characteristics were suggested, as we continued envisioning an ideal repository8.
Secondly, we used business process management BPA software, ARIS Express (Software AG, Darmstadt, Germany) to describe the flow of the entire process from decision to deposit data to either data being published or discarded. ARIS was selected as an adequate tool for this task, as it contains a visual representation of vital elements needed for the task. Documents, software, people at hand, etc. are placed in a 2D setting, connections are plain and unambiguous, the expected outcome is clear and perspective is not tainted with complex models. Business process management software allows precise problem identification, and reference model towards solving weak points, continuous quality control and monitoring9.
The ideal clinical trial data repository should be the first place on the internet for searching clinical trial data from published and unpublished clinical trials. The ideal open-access repository for hosting raw data from clinical trials would be a public Internet-based resource.
General features:
1. Exclusivity. Repository accepts exclusively data from clinical trials, including raw data, analyzed data and meta-data. The user interface will be exactly tailored to fit the deposition of clinical trial data.
2. Mandatory use. In line with the requirements of the International Committee of Medical Journal Editors (ICMJE) for mandatory trial registration, relevant stakeholders such as employers, funders and journal editors could agree that clinical trial data need to be deposited in a clinical trial repository.
3. International governance. An international board of relevant stakeholders from academia, industry and funders is governing the repository. These stakeholders should be internationally renowned, non-profit organizations with stable funding, such as large universities, research funding agencies, European Medicines Agency (EMA), or similar.
4. The repository is self-sustainable. An ideal repository needs to develop a sustainable collaborative funding model that will ensure the maintenance and continuing development of the repository, providing new tools and storing new datasets, while ensuring that the repository is free to access and reliable10. Such a collaborative model could, for example, include financial support of governments, as part of their investment in research.
Cost of data deposit is free or minimal. Data deposit is free for data depositors, or partially funded from grants, or institutions or government if such funds exist. Lack of funds should not prevent data deposition. Since funders now regularly cover the cost of publications in open-access journals, principal investigators applying for grants can also include the cost of data deposition in an open-access repository. Principal investigators without funds can apply for a fee waiver. The cost of data deposition, if there is any cost at all, should not be prohibitively high, and in line with the cost of manuscript publication.
Features related to user experience:
5. English is the main language of the repository framework, with the option to create sibling web sites in other languages. The uploaded files can be in any language, and language of files is indicated, with the preference for uploading files in the English language to achieve maximum visibility.
6. Simple user interface and searching. The user interface is a friendly and self-explanatory environment, which enables step by step upload. All the content in the repository is searchable.
7. Updates and corrections are archived. The repository enables subsequent updates and corrections to a deposited dataset, where each change is explained and recorded, and each version of the dataset is archived and accessible.
8. Mandatory inclusion of metadata with clinical trial data. Metadata include a comprehensive separate data set that should answer all potential answers about the clinical trial and data from a trial. Such metadata enables managing clinical data portfolio, enable assessment of the conduct and analysis of those trials, and reanalysis11–13
9. Instructions for preparing and depositing data and metadata. Extensive instructions on data preparation for deposition are available on-site, with clear statements on mandatory data and metadata deposition13. da Silva et al. concluded that most researchers store their data in various formats and the main reason for data loss is lack of appropriate annotation14.
10. The maximum upload file size is 2 GB, while the maximum project upload size is unlimited so that researchers can upload all the files that are associated with a clinical trial. Limitations regarding upload size contribute to concise data preparation. Image compression in an ideal repository should be lossless. Currently, there is a problem with deposition and archiving of medical images from MR, CT scans and similar devices that generate large file sizes. Mezrich and Siegel addressed the need for universal and technological appropriate guidelines regarding storing digital medical images, with the help of the information technology community. Image compression has been suggested as an approach but no guidelines have yet been made and adopted15. Although Koff’s study found no difference in diagnosis based on low level compressed and uncompressed images, evaluating the standards for irreversible compression in digital diagnostic imaging has been proposed by the Canadian association of radiologists16.
11. Persistent identifier is assigned to each dataset. A digital object identifier (DOI) is an important international standard for identification of online material. A DOI is therefore provided to each dataset (complete data and metadata for one study). It is vital for digital objects (articles, datasheets, images) to receive a DOI, as it helps to avoid several issues with citations, such as broken links (marked with a warning: error 404), copy-paste errors in citation text and copyright violation. Also, a DOI enhances verifiability, because it always leads to the correct web source17. According to Klump and Huber, a DOI is used in 75% of repositories as the most common persistent identifier, making it most successful persistent identification system currently in use18. Price of DOI is 1$ in the most expensive scenario for an article and 0.06$ for data set; the price varies according to DOI issuing agency19.
12. Mandatory manual curatorship of datasets. After deposition, data are verified by at least two experts independently, such as a biocurator and a statistician20,21. The UK’s Digital Curation Centre suggests outlines of their approach to digital curation procedure, with several steps, of which the following are relevant for ideal repository: i) conceptualization: considering which digital material will be stored, which data capture methods will be used and available storage options; ii) creation: production of relevant metadata because it enhances accessibility; iii) access and use: determining whether data are publicly accessible, whereas for ideal clinical trial open data repository limited accessibility is an option to consider, as well as embargo options before the publication of results; iv) appraisal and selection: determining what digital data is relevant, in respect to legal guidelines if they exist; v) disposal: discarding irrelevant data; vi) ingesting: placing digital objects to predetermined storage locations; vii) preservation: taking actions that will ensure long-term data protection and retention of the nature of digital material; viii) reappraisal: reevaluate material to ensure that is still relevant and is true to its original form; ix) storage: keeping the data secured; and x) access and reuse: routinely check that material is still accessible22,23.
13. A limited embargo period is allowed. Investigators can deposit the data after obtaining results, before the manuscript is submitted, but with an embargo that will be in effect until manuscript publication. The maximum embargo period that investigators can request is 1 year24.
14. Data and metadata are reusable. Curators need to confirm that data is reusable and analyzable by performing minimal reanalysis according to the internally-agreed uniformed data reanalysis protocol, to confirm at least one result from the published manuscript.
15. Access to data is open after the registration. Users have open access to data after registration on the site, accredited via affiliation.
16. Data can be reused. Datasets are published under a Creative Commons Attribution 4.0 International License, which allows maximum dissemination and data reuse. Users will be free to share and remix the dataset, under the condition that they attribute the source of the dataset to the original author25,26.
17. Enabled interconnectivity. Clinical trial data repository should be connected with protocol registries, such as ClinicalTrials.gov, ISRCTN and EudraCT, and with published journal article by using a DOI. Links to protocol registrations and journal articles are to be found on the repository website.
18. Researcher identification should be managed with an ORCID ID, a nonproprietary alphanumeric code whose purpose is to provide a unique persistent identifier to academic authors. An ORCID ID is thus similar to DOI. Even though the ORCID organization warns that they are not an identity verification system, many universities and publishers, along with commercial companies, promote and use ORCID27.
19. Management of IPD is crucial and the most demanding process related to the design of the ideal repository. It has to be defined according to the EU General Protection Regulation (GDPR) which is designed to harmonize data privacy laws across Europe and to protect all EU citizen data privacy and redefine the way organizations across the EU approach data privacy. The enforcement date for GDPR was May 25, 2018, and since that date organizations in non-compliance will face heavy fines. Deposited data should be prepared and deposited in such a way that the data subject is no longer identifiable. For example, IPD should contain a code instead of participant real name, address, email, photo, phone number or social security number should not be in the table. It is not likely that someone could be identified via sex, age and arterial pressure, blood glucose and TNM stage. All other questions regarding GDPR compliance should be managed by the clinical trial principal investigator or dedicated officer28.
20. The repository should qualify for CoreTrustSeal, which guarantees that the repository has been created according to 16 guidelines for a sustainable and trustworthy repository29.
21. Organization of metadata should be following the Dublin Core Metadata Initiative, specifically DCMI metadata terms30. DCMI maintains authoritative specification of metadata terms, and those terms are published as IETF RFC 5013 [RFC5013], ANSI/NISO Standard Z39.85-2007 [NISOZ3985], and ISO Standard 15836:2009 [ISO15836]. Description of every single metadata repository element is beyond the scope of this article
For the uploader: The repository would be safe archival space where one can store an unlimited amount of data. These data may serve to others, but also as a backup for the uploader, in terms of data protection and preservation.
For other researchers: It would be a user-friendly interface and smart search engine that would provide easy access to clinical trial results, and dataset acquisition in just a few seconds. These data can then be reused and reanalyzed.
For stakeholders concerned with research integrity: It would help stakeholders check whether clinical research data have been fabricated or falsified. Preventing statistical analysis results unfavourable to the researcher (including the funding agency) from being concealed, and preventing fraud in a clinical trial results publishing2,31.
For legislators: The repository would combine ethical science and reporting of results with good clinical practice. If problems emerge, all data from the beginning to the end of the study is available on site.
For science, at large: Implementation of the repository would lead to a reduction of waste in research. Currently, many RCTs do not report all data collected within the study. Other researchers or healthcare workers may benefit from knowing that certain data were collected and analyzed, and accessible in a repository32. Such a mandatory repository would mark an era of truly open science and data sharing in clinical trials.
The focus of this project was a development of IPD and clinical trial data deposition and curation scheme, or to put it simply, what happens to data when a researcher deposits them to the repository. BPM was used to identify all necessary steps required for successful data management from deposition, checking whether data were adequately prepared via human curation and DOI assignment, and finally data publishing on the repository website. Figure 1 shows the entire process that we are proposing. The main goal was to ensure that there are no loose ends in the data management lifecycle; once the data is deposited in the repository, the project must end as published or discarded data.
The process in the middle of the model has left arm which describes the necessary documents and tools. The right arm defines the person responsible for performing a task that leads to another process until the process is finished as discarded data or published data. Every process begins with a decision whether or not one will enter the process. When researchers decide to share their data, clinical trial data manager puts an effort to generate RCT data sheet (block) they want to share. The next step is preparing data according to repository policy so data could be successfully ingested and manipulated until publication, e.g. images, sheets, videos, written data, should be submitted in acceptable formats. After preparation, data is submitted via an online form and the clinical trial data manager’s job is now finished (Figure 1).
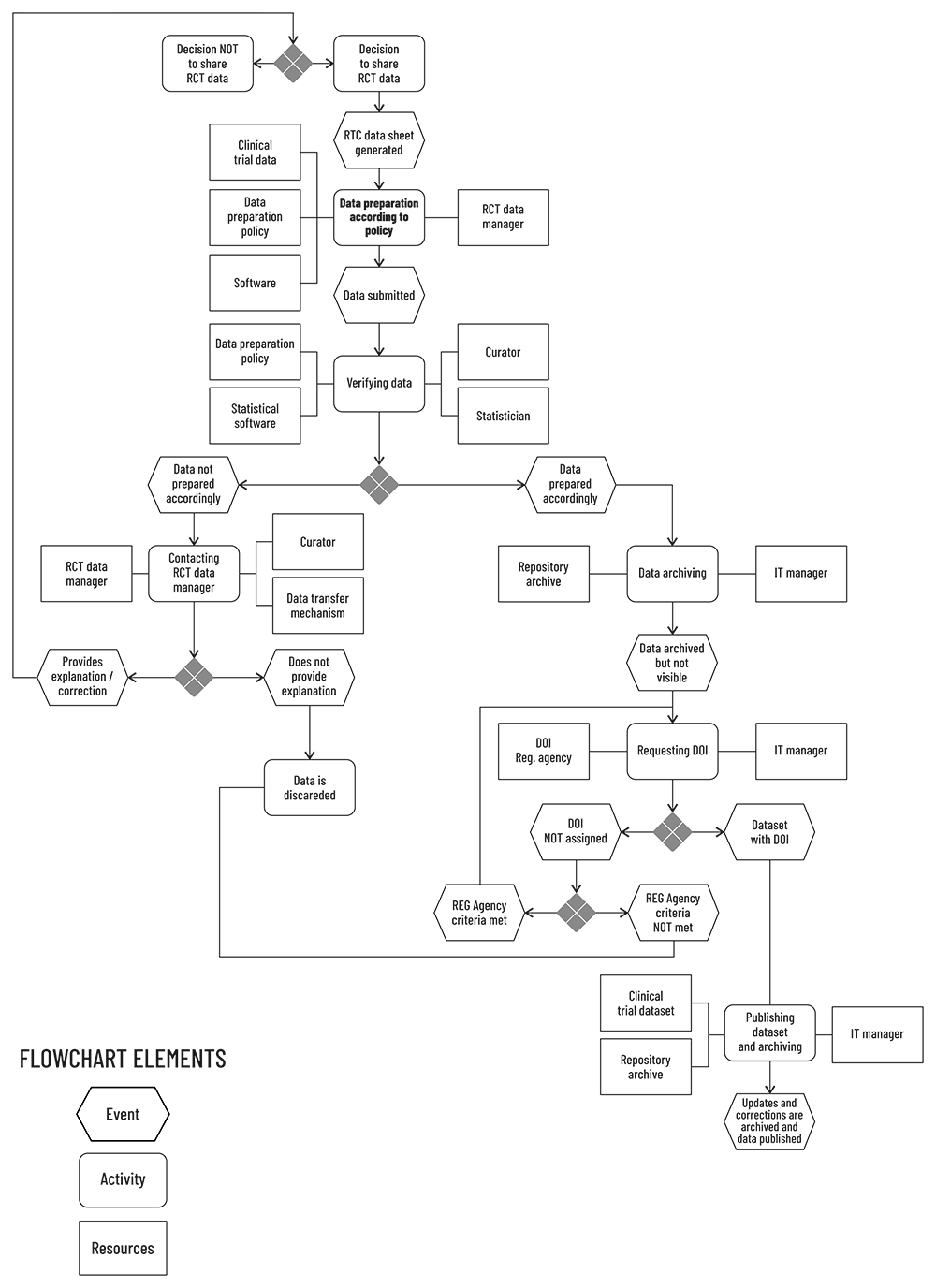
The repository should have curator(s) and statistician(s) proficient in the area of clinical trials. After data submission, curators will now verify whether deposited data has been prepared according to relevant policy; therefore, we see a branching process if data is not prepared accordingly (Figure 1). In that case, clinical trial data manager will be contacted to explain provide an explanation for not following policy instructions. If an explanation is provided, the process begins again from the top; if an explanation is not provided, the process will terminate, and the data will be discarded (Figure 1).
If data are prepared properly, they are placed in repository archive but are not visible to others. Requesting a DOI for an archived dataset is the next process, which also branches in two arms, depending on registration agency criteria for DOI assignment. This means that the registration agency can decline DOI assignment. If that happens, the process is to be repeated until criteria are met to acquire DOI. Next step is publishing dataset with DOI on the repository website, making it fully visible online (Figure 1).
Other processes that precede data deposition, and processes after data publication are not addressed in this article. Ohman et al. advised 10 principles and 50 recommendations that should be taken into consideration for successful clinical trial data sharing in general. They described steps to be taken from data preparation to data sharing monitoring33. Ohman et al. focused on ideal data sharing prerequisites, while we focus on technical aspects regarding ideal repository features, data validation and publication of such data.
This manuscript describes features of an ideal repository for hosting open-access data from clinical trials, and ideal schema for its creation, using a business management approach. Such a central, mandatory repository for clinical trials is necessary because we are witnessing numerous calls for action, statements, articles, open letters, organizations, projects, and initiatives regarding “open data” movement34,35.
However, an ideal repository needs to be backed up by a legislative framework to be usable and sustainable. Without it, all efforts for creating sustainable clinical trials repository will be futile and dispersed36. The legislation behind ClinicalTrials.gov is a relevant example. The first milestone towards open clinical trial science was achieved in 2008, with legislation that backed up mandatory basic results reporting at ClinicalTrials.gov through Section 801 of the Food and Drug Administration Amendments Act (FDAAA 801), and again in January 2017 with the Final Rule for Clinical Trials Registration and Results Information Submission (42 CFR Part 11), the law generally includes interventional studies (with one or more arms) of FDA regulated drugs, biological products, or devices that meet one of the following conditions: the trial has one or more sites in the United States, or it is conducted under an FDA investigation and finally if the trial involves a drug, biologic, or device that is manufactured in the United States or its territories and is exported for research37,38.
Now is the time for the next milestone in open clinical trial science, which will include the creation of one exclusive, domain-specific repository that will host raw data from clinical trials, with the strong support of the legislation, and publishing community.
Currently, the two most promising existing initiatives considering data sharing are ClinicalStudyDataRequest (CSDR)39 and Vivli40. Both initiatives provide data on request, the request is processed, and a decision is made whether or not one is eligible to view the data. If the access to data is granted, one must sign a Data Use Agreement, which differs depending on the company holding the data; the agreement in some way restricts the use of data and publication of finding. Both initiatives are funded by pharmaceutical companies. The good thing regarding these initiatives is relative access to some individual participant data.
Vivli40 has numerous features of a centralised repository; it follows a vision as a mediator between data providers and users, charging a fee to data requestor to remain sustainable, and with a privilege to decline the request. We do not consider that charging a fee to a data requestor and having an option to decline the request is a feature of an ideal repository that aims to foster data sharing and re-use.
CSDR39 defines itself as consortium of clinical study sponsors. It is acknowledged that CSDR defines a „Sponsor“ as follows: „The Sponsor may be an individual or pharmaceutical company, governmental agency, academic institution, private organisation, or other organization“. However, it appears that the uptake of the CSDR among industrial and academic sponsors is limited. There is not much information on the CDSR web site about all the sponsors that have deposited data in the CSDR – on the page titled „Data sponsors“, only 13 logos were present on July 29, 2022. On the page titled „News“, sub-page „Academic-Led Clinical Trials Data Shared on CSDR“, there is a news item from November 2019 indicating that the CSDR includes data from 18 academic-led trials. Thus, according to the publicly available information, it appears that the global uptake of CSDR by industrial and non-industrial sponsors is extremely limited. CSDR acknowledges that the part of the approval process for obtaining data is sponsor’s check of a predefined list of criteria. However, we feel that such procedure greatly limits the scientific process. Furthermore, CSDR indicates that the time from data access proposal to approval could be 90 days if no further information is needed. We consider that this process is unnecessarily lengthy, and potentially prone to failure, which could discourage researchers from further attempts to obtain and re-examine data.
Strom et al. have described their experience with CSDR. As members of independent review panel deciding about requests for use of those data, Strom et al. reported on the first 2 years of applications for access to data from 3049 trials that were available through the website. Of the 177 research proposals that were submitted, the majority was granted, and of those only four reports were published by October 2016. Strom et al. suggest that this could indicate inefficiency of the approval process behind CSDR39.
In our previous research (Gabelica et al.; unpublished data), we screened 1700 (re3data) repositories and found that individual participant data can be found in public repositories such as Dryad, Zenodo, OSF, B2share, Edinburgh data share, Easy/DANS, ICPSR, LSHTM Data Compass, SND, DRUM and University of Bath Research Data Archive. The only repository that was specifically created for hosting raw data from clinical trials was University Hospital Medical Information (UMIN)31 Center’s Individual Case Data Repository (ICDR) within the University of Tokyo Hospital; however, the UMIN repository was not open access; it is open only to researchers from Japan who previously registered their trials in it.
In 2016., Goldacre and Gray published a manuscript in which they described the creation of an open database for hosting all data and documents threaded together by an individual trial41. Their OpenTrials database has been created online and is available at the URL https://opentrials.net/. However, the way they envisaged their database has multiple serious issues that will not make it sustainable.
Firstly, there is an issue of funding. According to the information on the database web site, they secured funding for the first phase of the project, which allowed them to create a “practical data schema”42. Secondly, OpenTrials proposes web scraping as a method for populating the database. Web scraping, by definition, is the extraction of large amounts of data from websites. For the Open Trials database, web scraping will be done automatically with the help of software. However, certain web sites have barriers that will disable such work. Alternatively, manual web scraping is an option, but that is a very tedious work, which requires additional knowledge on what to scrape41,43.
The third issue of the OpenTrials database is an expectation about crowdsourced curation. This sourcing model relies on a large network of internet users to participate in data curation, specifically clinical trial data. It is hard to believe that a significant number of people will be available for curating data from such a broad and complicated area of science44.
It is also unclear how OpenTrials would match the data about the same trial from various sources. Goldacre and Grey wrote in their manuscript that they will “record linkage”41, and on the OpenTrials web site, they write that this is “area of ongoing work and research”45. Thus, it is unclear how they planned to record linkage. Presumably, the idea is to connect deposited data with registered protocols and published manuscripts with results, but this is not clearly indicated, nor are methods to achieve so. Simple linking of records would have to be done manually, and it could not be automated, which would be a major disadvantage of such an approach.
Most importantly Goldacre and Grey propose against hosting IPD to protect patient privacy. However, the anonymity of data is a technical issue that is simple to solve. Planning of the ideal repository must consider full anonymization of the IPD’s data under EU GDPR act28. Without the availability of IPD, there is no open science, and there will be a limited possibility for reuse and reanalysis of clinical trial data. Strom et al. state that meta-analysis of firewalled patient-level data from multiple sources is a grievous endeavour. Open access to data on a dedicated repository is obvious solution46.
Without proper legislation, manual curation, automation of selected processes, regulation and sustainable funding, it is possible that OpenTrials may not fulfil expectations. Multiple such attempts were made before. One example is OneRepo, which aimed to solve the problem of institutional repositories fragmentation, and open access to scholarly articles47. OneRepo was described as a project whose aim is to “unify the world’s green and gold open-access works” by providing a single access point for searching all of the world’s institutional repositories48. However, it does not look like the research community is taking any notice. As of November 2017, there is no single scholarly article available in major indexing databases about OneRepo. In November 2017, personal communication with the OpenRepo’s founder Mike Taylor indicated that development of OneRepo has been halted due to funding issues.
An ideal central repository for hosting data from clinical trials should be modelled as a governmental database, such as DNA banks for convicted criminal offenders, fingerprint databases, bank account information, civil registration systems, land and property records, judicial records or vehicle information records49. In the case of an ideal repository, this would be a transgovernmental organization, such as INTERPOL50. The reason for this is that raw information from clinical trial data is too important to be insecurely funded or improperly curated.
In this manuscript we are advocating for a “centralized repository”, which is unlike any currently existing laboratory. We would like to refer to GISAID initiative (https://www.gisaid.org/) as an example of a centralised repository for rapid sharing of data from all influenza viruses and the coronavirus causing COVID-19. The GISAID Initiative fosters the rapid sharing of data from all influenza viruses and the coronavirus causing COVID-19. This includes genetic sequence and related clinical and epidemiological data associated with human viruses, and geographical as well as species-specific data associated with avian and other animal viruses. The Initiative ensures that open access to data in GISAID is provided free-of-charge to all individuals that agreed to identify themselves and agreed to uphold the GISAID sharing mechanism. Their approach is encouraging, and should inspire similar initiatives in the future related to sharing of clinical trial data.
We hope that relevant stakeholders will strive to create a repository which we idealistically propose. While such repository may not be perfect initially, it can be perfected over time, for the reasons that Strom et al. elaborated: “Making trial data broadly available is ethically imperative and scientifically justified and has the potential to increase public understanding of and support for clinical research. But it seems critical to find ways to improve the use and output of data-sharing projects before the clinical research community invests the substantial effort and resources required to broaden the effort to include academic and other non-commercial investigators”46.
With this manuscript, we hope to foster further activities to reach a consensus of a wider research community about the suggested features of an ideal repository. We have suggested features that we consider important, but the wider community could likely suggest other features that would be important, and that some of the features we suggested could be trimmed. We are not suggesting a crude approach where everyone will simply have to deposit their full data, but a creation of an ideal repository, which will also address concerns regarding the possible re-identification of patients.
The novel part of our ideal repository is strictly defined technical aspect of deposited data validation, and data curation, while implementing all aspects of FAIR data principles, which include findability, accessibility, interoperability and reusability51.
We would like to emphasize that the aim of this article was not to conduct a landscape scan of current repositories. We have mentioned some characteristics of existing repositories to provide context for our ideas. The business analysis approach is utilized to present our way or the ideal way of clinical data processing, curation, storage and publication. Business process management gives unambiguous insight into the process, and we believe it is clear and informative, as the diagram shows.
We acknowledge there are legal and cultural contexts that may be used as a reason, or an excuse, for the lack of data sharing. However, the aim of this article was not to address or solve legal or cultural issues that may prevent data sharing.
Regarding funding, we agree that sustainability may be threatened if there is no sustainable funding. However, there are many jointly-funded initiatives in the world, supported by governments that see merit in those initiatives. We consider that clinical trial data are one such initiative that deserves consideration of stable governmental funding.
For clinical trial data we strongly advocate the idea of minimal reproducibility. Our idea involves skilled statistical staff, because without them data validity proof is not plausible. This would be expensive, its acknowledged. However, we are proposing an ideal repository, and not a budget-friendly repository.
We certainly do not think that we are proposing the ultimate ideal that nobody will contest– we are providing our point of view to foster a discussion on this subject. Hopefully, other researchers will build on our idea and a consensus about the characteristics of the ideal clinical trial repository will be reached in the future.
Of note, we used the ARIS platform for this manuscript because some of the authors are certified for the work with it. We are aware that there are numerous other tools that can be used for this specific purpose.
In conclusion, we described our idea of an ideal open-access repository for clinical trial data and developed a model of such a repository using a business process analysis approach. We hope this work can inspire relevant stakeholders to engage in discussion about the necessity of creating such repository, and that we will witness the creation of such repository in near future.
No data are associated with this article.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)