Keywords
Customer churn prediction, Data sampling techniques, Algorithmic fairness, Class imbalance problem
This article is included in the Research Synergy Foundation gateway.
Customer churn prediction, Data sampling techniques, Algorithmic fairness, Class imbalance problem
In the revised version of the paper, we updated the introduction section with the applications of algorithmic fairness in two significant areas, recommender systems, and customer churn predictions. In addition, we also define the scope of the work. Three versions of data are prepared as extremely imbalanced (i.e., 5% non-churn and 95% churn rate), very imbalanced (i.e., 15% non-churn and 85% churn rate) and normal imbalanced (i.e., 30% non-churn and 70% churn rate). The classification results are demonstrated with the learning curves with the Random Forest classifier to provide a clear vision of the model’s performance in these datasets and discussed briefly in the discussion section. We added a compact discussion on the major limitations of the study in the conclusion section. We believe this revised version of the paper would yield the readers with the insightful knowledge about the requirement to consider algorithmic fairness in machine-based decision tasks, especially in rapidly growing ecommerce businesses.
See the authors' detailed response to the review by Chu Kiong Loo
See the authors' detailed response to the review by Prabu P
Customer churn, the phenomenon in which customers are shifting to rival companies due to dissatisfaction with the existing services or for other inevitable reasons,1 is one of the common issues usually encountered in every customer-oriented sector, including telecommunication. Customer churn prediction (CCP) is a supervised binary classification procedure that detects the potential churners before they are churned. Since there are no standardized principles for collecting data for CCP tasks, data distribution between classes will be varied from one data set to another. Therefore, one class might have extremely underrepresented compared to another class. In CCP, the target class is those being churned or not. To be exact, churn is always a minority class when the non-churn class usually comes in large numbers. Therefore, churn is used to consider a rare object2 in service-based domains including telecom. Thus, telecom datasets always suffer from a class imbalance problem (CIP) and lead to a situation in which minority instances remain unlearned.
Advanced machine learning techniques can be applied to predict potential churners. Let us consider a dataset with 10,000 data instances with 10% of churn samples i.e., 1000 churners and 9,000 non-churners. Even if a carefully built model could predict 90% correctly on the minority class, it means 100 customers are misclassified to the wrong class. Suppose 60 churners are misclassified as non-churners, i.e., false negatives, the company will lose a huge amount of revenue since recruiting new customers is more expensive than keeping the existing ones.3 Thus, the ultimate goal in the telecom sector is to increase profit by decreasing customer churn. Hence, CIP is a block when trying to achieve the major goal of CCP, since it degrades classification accuracy. Algorithmic fairness has become a very active research topic since ProPublica observed that the algorithms could yield discriminative outcomes, which impacted a minority group in real life.4
Algorithmic fairness is monitored in line with the protected features or sensitive variables in the dataset. Sensitive data could be, but is not limited to gender, race, age group, or religion. Algorithmic fairness is achieved if the decisions generated by a model do not favor more or less any individual or a group.5 The lesser the bias in the training data, the bigger the chance of achieving algorithmic fairness. However, it is almost not possible to train a zero-bias model since the historical data could have contained bias for many reasons.6 The common reasons for bias in the training data involve the compounding of initial bias over time, using proxy variables, and unbalancing of sample size between minority and majority groups.7
In the CCP process, customers’ behavior is analyzed within specific time windows, for example within one month.8 Once the prediction is done, the outcomes are reused as training data for the next prediction. Therefore, there are high chance to have repeated bias in the historical data without even noticing. This fact suggests why the algorithmic fairness issue should be considered in building of CCP models. Since CIP is a major concern in CCP process, one solution for CIP is to apply data sampling techniques (DSTs) to the training data. Since the major function of DSTs is to increase or decrease the sample instances to balance between majority and minority classes, there are changes in the number of samples in the different groups in the dataset. Even though there are high chances of having bad impacts of using DSTs on algorithmic fairness, the research works on that specific topic are minimally found. This motivates us to start our research work on an evaluation of DSTs’ impacts on algorithmic fairness in the CCP process.
In e-commerce businesses, the role of artificial intelligence has become very important, and it plays a major part to run the businesses more smoothly. On the other hand, along with the challenges of Covid-19, the trends of the customer-oriented businesses have rapidly transformed into the online platforms which need to heavily rely on the machine learning models to provide the precise personalized experiences to the customers. Thus, the works on preventing customer churns and enhancing recommendation systems are hot topics in the e-commerce research. Despite the research demand, there are very minimum works that are closely related to our study. Some of the prominent studies are organized in Table 1.
| Research works | Description | Reference |
|---|---|---|
| Gui, Chun (2017) | In the article, the authors experimented with three kinds of feature selection techniques, Random Forest (RF), Relative Weight, Standardized regression coefficients, three types of DSTs, and RF classification algorithm on the real-world dataset with 45000 records to analyze the imbalanced dataset problem in CCP. | 3 |
| Mehrotra et al. (2018) | This research work proposed a conceptual and computational framework and several policies for optimizing the relevance of the recommendation systems. | 9 |
| Valentim et al. (2019) | The authors evaluated the impact of different data preparation techniques mainly for sensitive data removal, encoding of categorical data, and data selection techniques by testing on two well-known public datasets. But their work was not focused on the DSTs’ impact on algorithmic and they tested only on very small public datasets. | 10 |
| Beutel et al. (2019) | The study introduced a new set of fairness evaluation metrics for the recommender systems by using pairwise regularization. | 11 |
| Patro et al. (2020) | The authors investigated the fair recommendation in the context of two-sided online platforms and proposed a novel mapping called FairRec which provides the effectiveness in incurring a marginal loss in the recommendation process. | 12 |
In this paper, we evaluate how the DSTs applied in the data preparation stage of the CCP process impact the algorithmic fairness by testing on three versions of real-world Telecom customer churn datasets. Therefore, the main goal of this study is to explore and identify the impact of using DSTs on training data on algorithmic fairness in the CCP process. To the best of our knowledge, there is very little research concerning algorithmic fairness in the CCP process. We believe the findings of this study would provide valuable insights into future CCP research.
In the following, we elaborate on the methodologies applied in the experimental procedure. We list all of the classification results and learning curve results, performance measures for fairness in the next section. The significant results are specifically discussed in the discussion section. After that, we discuss the challenges and opportunities gained from this study. We conclude the article by discussing the limitations and future works of the study.
Ethical Approval Number: EA1742021
Ethical Approval Body: Research Ethics Committee 2021, Multimedia University
In this study, the original data set is prepared to make three versions of unbalanced datasets, with rates of 5% (i.e., 95% of non-churn data and 5% churn data), 15%, and 30%. Each version is applied with four DSTs and compared the results with the unsampled original dataset to evaluate the classification performance and impacts on algorithmic fairness. The step-by-step methods to conduct the study are presented in Figure 1.
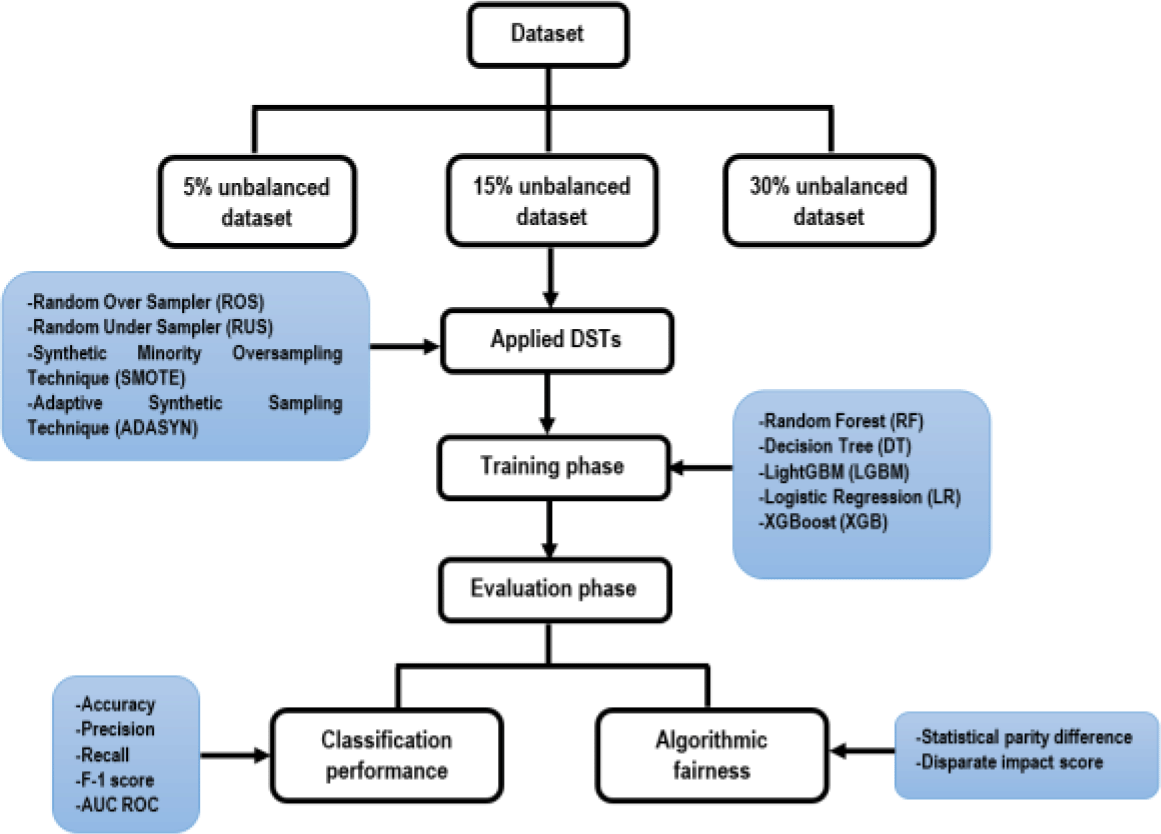
A real-world telecom dataset was provided by one of Malaysia’s leading telecom companies (see Underlying data for details on access to this dataset). The original dataset contains 1,265,535 customer records, which were collected from January 2011 to December 2011. Since the original data set is huge in volume, we randomly selected 100,000 records and utilized them for this study as we prefer to start with a smaller sample of data due to the limited resource allocation. We included demographics, call information, network usage, billing information, and customer satisfaction data in our dataset since they are considered influential factors in the CCP process.13,14 A total of 22 features were extracted after careful aggregation, i.e., new features were created based on the original data and some unnecessary features were deleted from it, and features are listed in Table 2.
The final dataset was prepared with three different rates of unbalancing: 5%, 15%, and 30%. We created a Python script (see Extended data) which used the Pandas tool of Scikit-learn machine learning library to prepare three versions of datasets. We set up these specific rates because we wanted to experiment with extremely unbalanced cases up to intermediate levels.
In the data preprocessing stage, we excluded any null values. Since we found only a few outliers in the selected dataset, we manually removed them without using any specific procedure. We applied four DSTs to the data: Random Over Sampler (ROS), Random Under Sampler (RUS),15 Synthetic Minority Oversampling Technique (SMOTE),16 and Adaptive Synthetic Oversampling Technique (ADASYN).17 The selection of DSTs was based on their popularity and to know the impact of each of them on the algorithmic fairness in the CCP process.
We applied six popular classifiers: Random Forest (RF), Decision Tree (DT), LightGBM (LGBM), Gradient Boosting (GB), Logistics Regression (LR), and XGBoost.18 We created our own Python script (see Extended data) using Scikit-learn machine learning library to perform this step. After a careful exploratory data analysis, we dropped Customer ID, Avrg local amt, Avrg std amt, Avrg idd amt, Avrg dialup amt from the predictor variable list since they were weakly correlated to the target variable.
We performed two evaluations: performance measures19 and algorithmic fairness metrics.20
Performance measures
In measuring the classifier's performance, we applied standard measures which are commonly used in most machine learning classification tasks, including precision, recall and accuracy. We applied F-1 and AUC-ROC scores since accuracy alone is not enough to evaluate the actual performance of the classifiers. However, the performances of the different classifiers are compared by using AUC-ROC score. We created our own script (see Extended data) using Scikit-learn, a free machine learning software library for Python programming language. The performance of each classification was done as follows:
Algorithmic fairness metrics
We emphasized the assessment of whether the classifier is discriminated against between women, a protected group, and men, a non-protected group. We applied two well-known fairness definitions in measuring algorithmic fairness and utilized the popular AI-fairness 360 tool to calculate algorithmic fairness.20
Statistical parity (SP): Also known as an equal acceptance rate. SP is achieved if women have an equal probability to be predicted in the positive, i.e., churn class, as the men.21
SP difference measures the difference of a specific outcome between the protected (female group) and non-protected (male group). The smaller the SP difference between the two groups, we can say that the model treats the unprotected group statistically similar to the protected group.
Disparate Impact (DI): Also known as indirect discrimination where no protected variables are directly applied, but biased outcomes are still produced relying on the variables correlated with protected variables.22 The standardized threshold for the calculation of DI is 0.8, which means the group whose DI values are under 0.8 are discriminated by the classifier.
The threshold value 80% is advised by the US Equal Employment Opportunity Commission.23 The model could be DI-free when the value is larger than 80% but it should be lower than 125%.24
where Y = predicted decision
The preliminary classification results for the datasets with different data unbalanced rates using four DSTs are shown in Tables 3–5. Table 3 shows the specific results of classification performance gotten when testing on 5% of unbalanced rate concerning the chosen classifiers and four DSTs.
Table 4 shows the details results of classification performance obtained when testing on 15% of unbalanced dataset with respect to the chosen classifiers and four DSTs.
Table 5 shows the details results of classification performance obtained when testing on 30% of unbalanced dataset with respect to the chosen classifiers and four DSTs.
The classification results are shown in terms of learning curves in this section from Figures 2 to 4. In this article, we display the results of the classifications with RF since RF yields the best performance results among the other six classifiers. Figure 2 indicates the learning curves of the classification performance with 95%-5% (i.e, non-churn-churn) unbalanced rate of data compared with the original data and after four DSTs are applied.
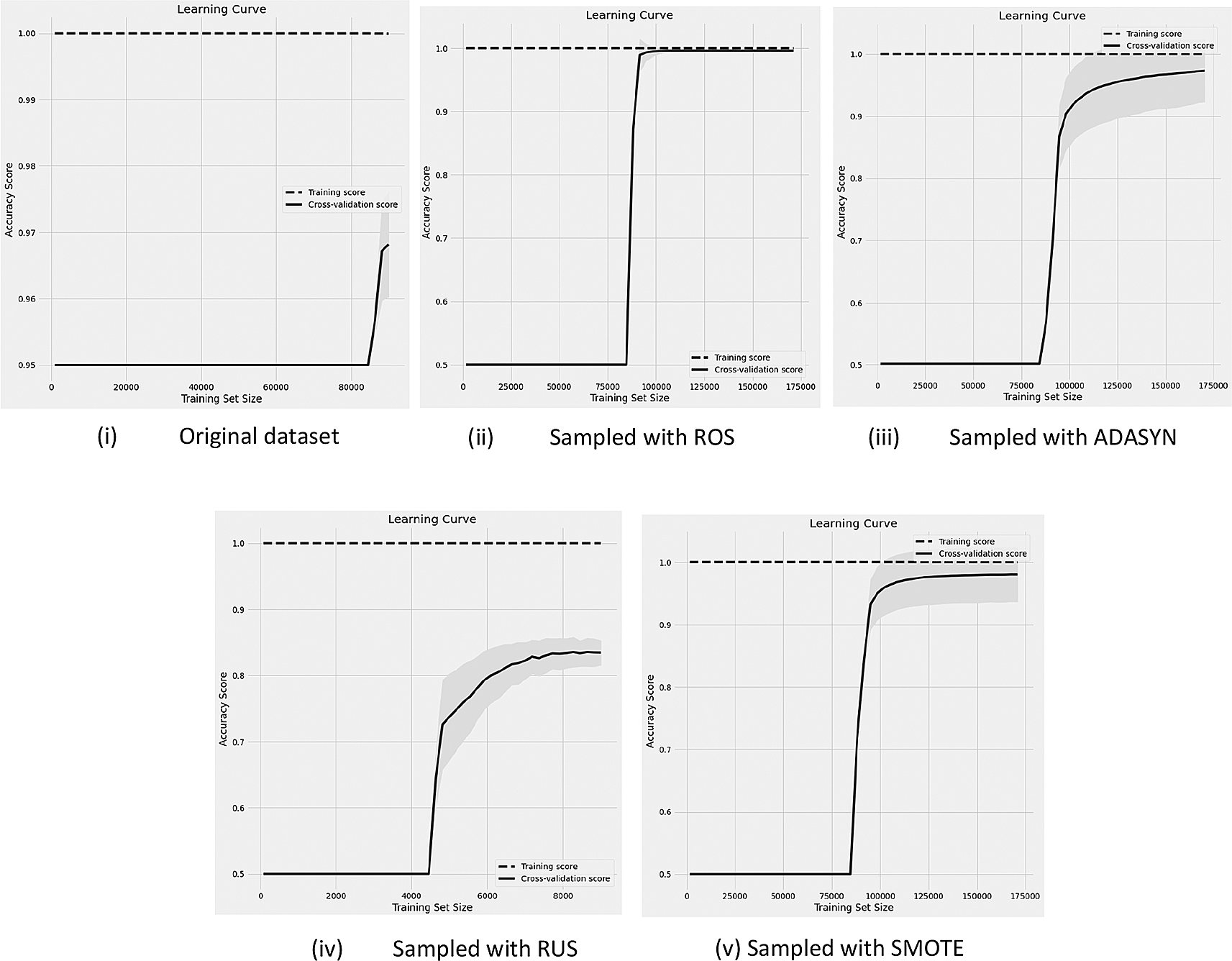
Before and after sampling results of learning curves with the data (95%-5% of non-churn and churn rate) with RF classifier.

Before and after sampling results of learning curves with the data (85%-15% of non-churn and churn rate) with RF classifier.
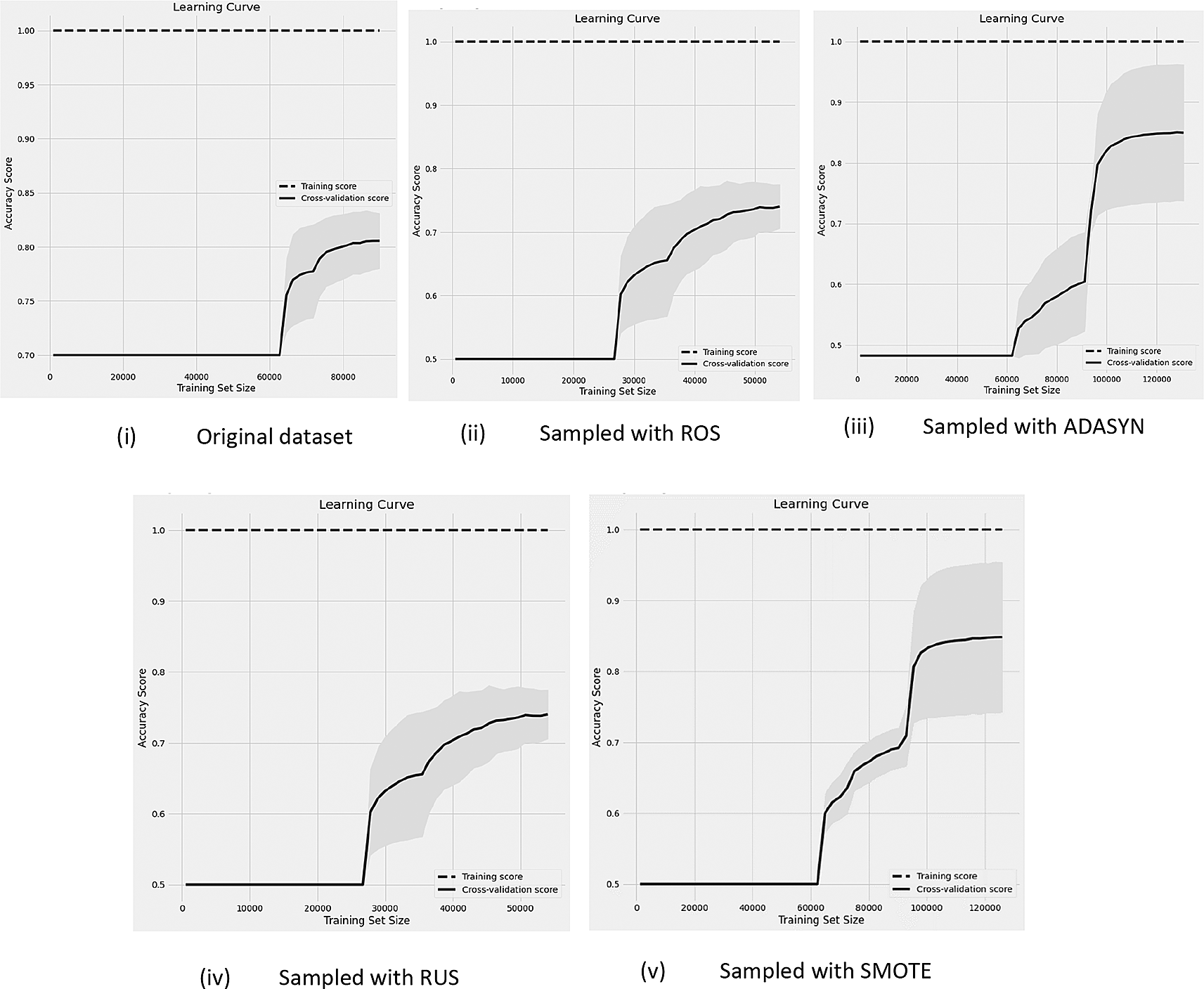
Before and after sampling results of learning curves with the data (70%-15% of non-churn and churn rate) with RF classifier.
Figure 3 reveals the learning curves of the classification performance with 85%-15% (i.e, non-churn-churn) unbalanced rate of data compared with the original data and after four DSTs are applied.
Figure 4 shows the learning curves of the classification performance with 70%-30% (i.e, non-churn-churn) unbalanced rate of data compared with the original data and after four DSTs are applied.
In our study, we have observed that a variable, is-senior remained unbalanced even after applying the DSTs. The algorithmic fairness scores for each group with different unbalanced rates are described in Tables 6–8. Table 6 shows the comparative results of SP difference and DI scores calculated on 5% unbalanced dataset and the original dataset.
Table 7 displays the comparative results of SP difference and DI scores calculated on 15% unbalanced dataset and original dataset.
Table 8 describes the comparative results of SP difference and DI scores calculated on 30% unbalanced dataset and original dataset.
Recent works of algorithmic fairness research in machine learning applications is broadly organized into three main trends. Some studies emphasize enhancing or proposing better fairness notions and evaluation metrics in line with the domains concerned,21,25 some focus on the ways to mitigate the bias in the classification process (which can further be divided into three main groups: pre-, in-, and post-processing techniques),26–29 while the last trend proposes how to maintain the ethical AI standards and policies in practicing machine learning applications in different sectors.30,31
Despite some previous empirical studies on the impact of using preprocessing techniques on algorithmic fairness, the findings of previous works could not pinpoint the direct impact of using DSTs on algorithmic fairness. Lourenc and Antunes,10 which is the closest work to our research, distinguish the effect of data preparation on algorithmic fairness. However, their work has been tested with two small datasets and provides general results using random under- and over- DSTs. Importantly, their work fails to be tested on the widely-applied DSTs, SMOTE and ADASYN. In contrast, we apply real-world business data and show how different DSTs influence dissimilar levels of imbalance rate.
In the classification task, RF seems to be the best classifier since it yielded the best results over the other five models based on their AUC-ROC scores, while LR provided the worst scores for almost all metrics. It was observed that RUS worked better for the extremely unbalanced situation compared with 15% and 30% imbalanced rates. The best outcomes were found via ROS, SMOTE, and ADASYN in all different unbalanced rates, thus, could be concluded that oversampling techniques seem to provide more promising prediction results than undersampling techniques. This might be because the undersampling technique modifies the data by decreasing the majority of instances, which makes the dataset lack useful information for learning. By observing the learning curves, the performance of the classifier is highly increased after applying DSTs in all versions of the data. But in the 5% unbalanced version, the performance results are better than two other versions of data. The classifier might ignore 5% of churns since the churn rate is too less. The data size used in the experiment is less, it would be better to use more training examples to see whether the models are well fit or not.
For all three unbalanced rates, the original dataset always gave less statistical parity differences (SPD) compared to sampled datasets created using four DSTs, while datasets with RUS and ROS yield a slightly larger SPD but the statistics showed there is no disparate impact. However, we can hypothetically consider there might still be a bias as both RUS and ROS have their limitations. With RUS, the important information could have been removed and the classifier could provide a biased result since there was less information to learn from. On the other hand, with ROS, the prediction performance could also be biased due to the overfitting problem. In this sense, it is suggestible to apply different fairness measures and to compare the fairness scores. For the DI scores, if there is DI less than 0.8, there is indirect discrimination towards the unprotected group. The mathematical equivalence of DI suggests equalizing the outcomes between protected and unprotected groups. However, in reality, the conditions in the context of interest drive us to allow DI to a specific group up to some percentage. For example, in telecom CCP, the number of female customers could be very less than the dataset, since most males usually apply for a network plan representing the whole household. Therefore, we assume considering DI with the 80% rule is reasonable.
In the 5% unbalanced original dataset, LGBM, LR and XG-Boost imposed with DI values of 0.79, 0.64, and 0.78 respectively. But there is no DI in the other two original datasets for 10% and 30%. This reveals that more discrimination could occur on a more unbalanced dataset. The analysis of all datasets with SMOTE and ADASYN provides alarming information on the classifier’s discrimination against the unprotected group. The 30% unbalanced dataset yields the worst unfair results since this is the highest SPD between female and males groups with LR of 0.38 and 0.43, respectively. Overall, among all DSTs, ADASYN, and SMOTE tend to provide more unfair outcomes compared to other DSTs. In contradiction, they both provide a better classification performance in comparison to RUS and ROS. There is not a huge difference among the three different data unbalanced levels. However, in this study, we experimented with the gender attribute as a sensitive variable.
Due to the nature of the CCP process and the rarity issue, training datasets have high chances to have compounded bias and suffer from unbalanced problems not only for the target class but also in the other attributes including sensitive variables. We have noticed that one variable remained unbalanced even after applying the DSTs; in such a case, a careful selection of data attributes should be done to avoid selection bias.
As the quality of training data is important, we would suggest enhanced mechanisms of data repairing techniques to prevent bias in the training data. Furthermore, the algorithmic fairness problem mostly concerns societal discrimination. For example, in the scholarship selection process, if classifiers give more favors to males than females who have the same qualifications as males but are not selected, this will decrease their chances of a scholarship. In a profit-centered industry like telecom, one could think there will be no loss for the customers though any group is less or more favored. It is important to consider the impact of biased decisions for the sake of the company’s reputation, the importance of equal treatment to customers, and to practice ethical AI policies.
In this paper, we experimented on three versions of unbalanced real-world telecom datasets to assess the impact of using four types of DSTs on the algorithmic fairness in the CCP process and compared the results with the unsampled original dataset. Classification performance and algorithmic fairness were evaluated with well-known metrics. The outcomes imply that RF provides the best classification results. Using SMOTE and ADASYN yields larger SPD between male and female groups as well as a disparate impact on the female over the male group. Previous work emphasizes the use of this method in choosing a scholarship candidate, releasing prisoners on parole, and choosing a credible candidate. Since machine learning applications would be applied to almost every sector so on shortly, the practice of using fairer or unbiased systems is essential. Our study highlights the importance of paying attention to algorithmic fairness in the machine-driven decision-making process of the profit-centered and customer-oriented sectors on which very little research work has been done. Particularly, our finding highlights the fact that a careful choice of DSTs must be done to achieve unbiased prediction results. Despite the experiment being done on the real-world telecom dataset with 100,000 records, the data size is still considered to be very less and the experimental results on a much larger amount of data could be varied. Since the data size is small, the results on the learning curves are not remarkable. Another limitation is we use only one sensitive attribute, gender, in our study. In future work, we would like to test the same procedure on a much larger dataset and would like to measure more algorithmic fairness metrics to investigate the best suitable algorithmic measures for the CCP task. Moreover, we would like to test with more sensitive variables rather than just gender.
The real-world telecom dataset was obtained from the Business Intelligence and Analytics department of Telekom Malaysia Bhd. The authors were required to go through a strict approval process following established data governance framework. Interested readers/reviewers may contact the Business Intelligence and Analytics department to request the data ([email protected]). The decision as to whether or not to grant access to the data is at the discretion of Telekom Malaysia Bhd.
As most telco companies own similar customer data, other customer churn datasets that are representative of the data being used in this research can be found as follows:
Analysis code available from: https://github.com/mawmaw/fairness_churn.
Archived analysis code as at time of publication: https://doi.org/10.5281/zenodo.5516218.32
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)