Keywords
open access, publication profiles, R shiny
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the RPackage gateway.
open access, publication profiles, R shiny
Several points in the introduction were made more specific and the description of rationale of this work has been extended. A clearer description of the use case and the target user has been added. Furthermore, a small evaluation on the accuracy of matching publications was conducted.
See the authors' detailed response to the review by Paul Albert and Curtis L. Cole
See the authors' detailed response to the review by Griffin M Weber
See the authors' detailed response to the review by Daniel W Hook
Given the increasing number of both researchers and publications as well as publishing modes,1,2 it becomes a challenge to identify and consolidate all publications from a single author. A few of the main issues are transliteration of names into roman alphabetic system, the non-uniqueness of names, differently written names (e.g., with or without middle initial) and changing affiliation over time. There are broadly speaking two approaches to solve this ambiguity: “unattended” and “attended”. The “unattended” approach tries to automatically resolve ambiguity using additional existing metadata. The “attended” approach relies on human intervention in the form of unique identifiers that enable robust linkage of publications to authors, assuming researchers and their collaborators use them consistently. The most important, widely used and de facto standard identifier in many fields is the Open Researcher and Contributor ID (ORCID).3 Other identifiers such as Google Scholar ID4 or ResearcherID (Publons)5 are also used, although they are not as broadly used as ORCID and persistence of identifiers is not always guaranteed. Having multiple identifiers on multiple platforms is not unusual and automatic publication detection and syncing between accounts is possible to some degree. However, automatic synchronization of accounts for different identifiers can be hindered by the fact that not all systems use the standardized DOI (Digital Object Identifier) as document identifier to match publications.
Although the two main standardized identifiers for authors (ORCID) and documents (DOI) are widely adopted, other identifiers are still used, making it often necessary to synchronize publication records on different platforms manually to obtain complete records. For instance, there is no simple one-click solution to synchronize publications between ORCID and Google Scholar. In Google Scholar, publications need to be searched and added manually (if they are not detected automatically) while in ORCID it is possible to input a citation file. A typical workflow to update ORCID based on Google Scholar would therefore be to first search (one by one) in Google Scholar all publications that are listed in ORCID and then add the missing ones. But since it is possible that publications listed in Google Scholar are not in ORCID, the reverse needs to be done to be sure the accounts are up to date. If more accounts need to be synced (e.g., Publons), the complexity and time needed increases accordingly. Although it is possible, and probably advisable, to link accounts for automatic updates (e.g., linking Publons with ORCID), this cannot be done under all circumstances and missing publications are still possible. Updating data in ORCID is possible using a variety of methods, such as through CRIS (current research information) systems, as auto updates between Crossref and ORCID, linking to Dimensions, among others.
While some (commercial) services (such as Dimensions6 or Web of Science7) provide extensive data mining to retrieve publication data, they often also rely on unique identifiers (such as ORCID in the case of Dimensions) for correct assignment. Furthermore, on many platforms that combine different sources, it is not easy to determine where the data originated (e.g., is a publication listed in ORCID or in Publons? or both?). In addition, data exploration and visualization is often restricted to citations over time (except costly commercial services). With the growing awareness, interest and mandates towards Open Science, open access (OA) status of articles can also be of interest. The same is true for preprints, which are not always taken into account despite becoming increasingly important in many research fields.8,9
Another inconvenience can be the existence of duplicated publications, which can stem either from the association of preprint and peer-reviewed publication or from revisions or different versions. In many cases, it is sensible to treat those closely linked publication as just one publication instead of multiple. If the required information to link publications is missing, automatic detection is not always possible and manual intervention is needed.
Many tools, both commercial and free, exist that combine bibliographies and bibliometrics for a wide variety of use cases such as evaluation, compliance (e.g. OA), grant writing, literature review and keeping professional web profiles updated. Furthermore, many of the available tools are not made for individual authors but rather operate on the department, institutions or even country level. Although those tools allow research institutions to curate research profiles to meet some of the aforementioned use cases, they are usually not designed for individuals to curate their own individual profiles outside an institutional context. Some of the existing commercial tools include Elements (from the company Symplectic10) and Dimensions, both of which are mainly intended for institutional use; but, especially Dimensions also offers functionalities for authors to explore their bibliographies.
Commercial as well as institutional tools provide valuable improvements to the quality of bibliographies, especially in non-STEM subjects where accurate representations of scholars is often more difficult.
Some of the free and/or open tools include VIVO11 (Institutional level, creates ontologies for representing scholarship), Profiles Research Networking12 (Institutional level, help to discover collaborators), ReCiter13 (Institutional level, find publications of authors in PubMed), ImpactStory14 (author level, impact and open access status of publications from ORCID).
Furthermore, tools mainly intended for monitoring open science include the open science monitoring of the European commission15 (country-level), the German open access monitor (institution-level) and OpenAIRE (Open Access Infrastructure for Research in Europe), which provides dashboards (country- or institution-level).
In our case, we took inspiration from the Swiss National Science Foundation’s Open Access Check,16 which allows Swiss researchers to reflect on their publishing practices and encourages various forms of OA, including green OA; importantly, such resources rely on the source databases being up to date in the first place. It is worth noting that our tool is not meant in any way for evaluation of researchers and that initiatives such as DORA17 and the Leiden Manifesto18 represent important considerations toward responsible research evaluation.
To facilitate overview and synchronization of publication records, we provide a web-based application that allows publications for an author to be retrieved from different sources, combines entries, checks for duplicates and downloads citations to easily update records across platforms. Furthermore, the open access status of each publication is provided, which can help to select publications that could be “greened” (i.e., depositing documents in institutional repositories). Taken together, this allows researchers to organize their public publication profiles and to interactively explore the accuracy of records across the various entry points. In other words, pubassistant.ch is intended for researchers who want to cleanup their publication profiles across multiple platforms and are interested in the open access status of their publications. One specific use case would be to find publications where the ORCID was not included and therefore is not listed in the online ORCID profile, but for example found and listed by Google Scholar.
The workflow is as follows: The user needs to first specify the unique identifiers of the researcher of interest for at least one of ORCID, Google Scholar and Publons. Additionally, a search query for Pubmed can be generated. Furthermore, the option to search for bibliometrics, obtained from the NIH Open Citation Collection using iCite,19 can be selected. After confirmation, publications are retrieved from the specified sources and combined into a table based on the DOI (see Figure 1) or, in case of publications from Google Scholar, based on (fuzzy) matching of titles and/or metadata retrieval from Zotero (Zotero translator, i.e., web scraping)20 or Crossref (i.e., query the available metadata to obtain a DOI).21 Since the set of considered publications stem from the same author, matching of publications is solely based on the title of the publication, by calculating the pairwise relative Levenshtein distances (Levenshtein distance divided by the maximum possible Levenshtein distance, i.e., number of characters) between titles and setting a threshold of 0.1 below which publications are assumed to be the same. The accuracy of detecting duplicates using a small test dataset (n=6929) of reasearch articles with an associated preprint on bioRxiv22 was 0.72. No other formal validation of this approach was done, but manual checking of a large number cases showed good matching in most cases. After joining the publications list, the open access status of each publication with a DOI is retrieved using Unpaywall,23 who provide a publicly accessible database containing open access information for publications. The definitions of the different open access status that Unpaywall uses is provided in Table 1. Additionally, preprints are defined as having OA status “green” in Unpaywall with the attribute “version” equal to “submittedVersion”. A database snapshot of Unpaywall can be downloaded https://unpaywall.org/products/snapshot.
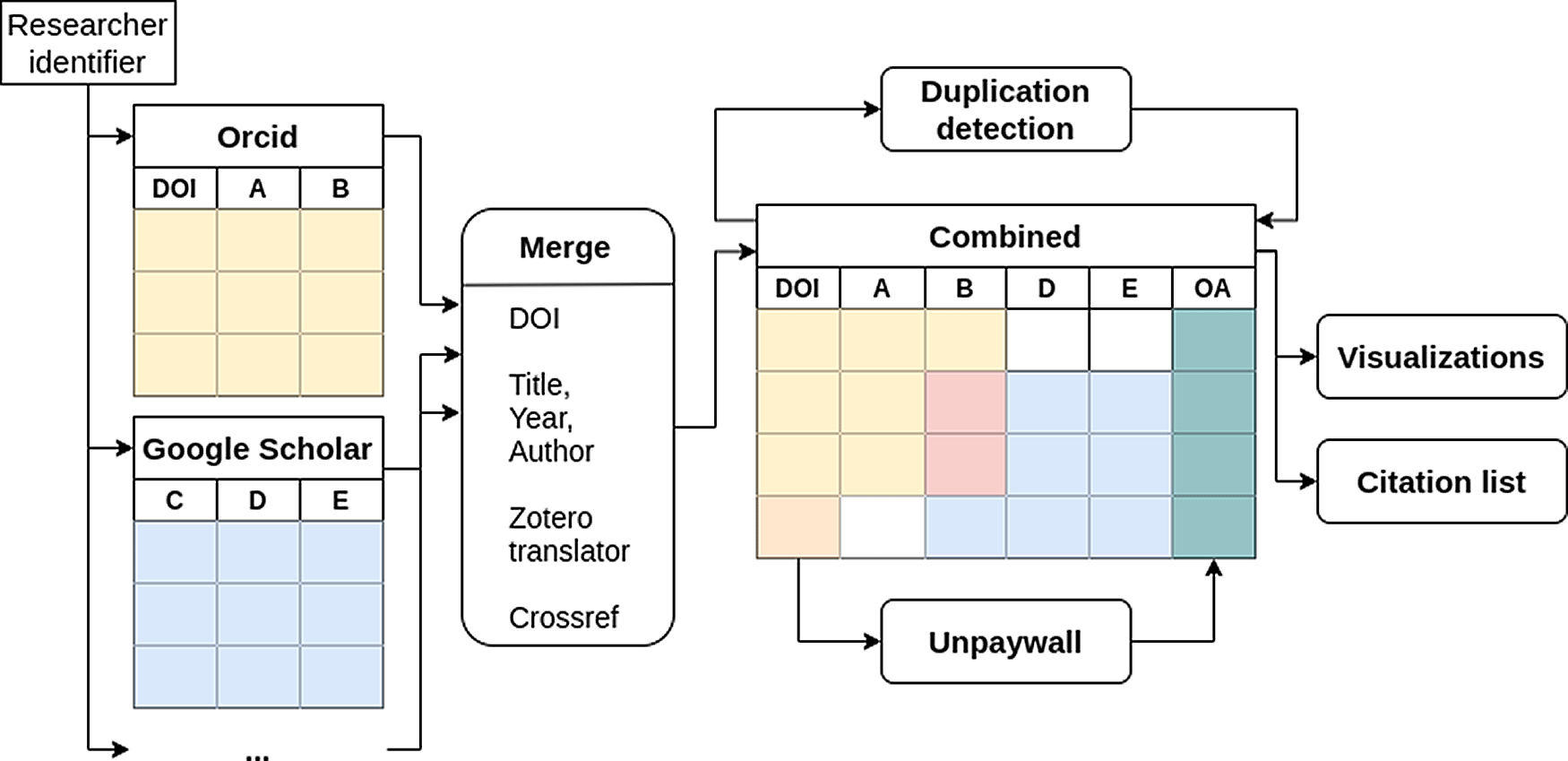
The identifiers given by the user are used to obtain the data from each platform independently. The data is then merged and the open access status (column OA) is obtained using the Digital Object Identifier (DOI). Furthermore duplicates are detected by comparing the titles of the publications.
| OA status | Open accessible | Description |
|---|---|---|
| Gold | Yes | Published in open-access journal |
| Green | Yes | Publication in free repository |
| Hybrid | Yes | Open licence |
| Bronze | Yes | No open licence |
| Closed | No |
After this step, interactive exploration of the publications is possible. Various options to filter the data according to OA status, year and source (ORCID, Google Scholar, etc.) are available with the possibility to remove or show duplicates (detected using fuzzy matching of titles, similar to matching of publications). Several metrics, tables and plots are available for exploration of the data. Examples include a upset plot that shows how many publications are associated with each identifier, a histogram of the number of publications per year colored by open access status, and a table listing the individual publications. After exploration, specific subsets can be generated using the filtering options, which are then imposed on the visualizations and tables presented. In all cases, relevant snapshots of the citation information can be obtained in the form of a downloadable file.
Another possible application is the integration of local databases, such as university repositories. For example, the Zurich Open Research Archive (ZORA),24 developed and maintained by the Main Library at the University of Zurich, has been integrated in an alternative version of the app that allows local entries to be compared with public profiles, allowing synchronization of publication profiles with local repositories.
The application is written in R (Version 4.1.0)25 and shiny (Version 1.6.0),26 see Software availability. As a back-end database, PostgreSQL is used to store a local copy of Unpaywall (and ZORA). Such a local database for Unpaywall is not strictly needed, but a large speedup of the retrieval of the open access status is achieved compared to access over the Unpaywall API. Furthermore, since only a fraction of the data from Unpaywall is used (only the DOI, the open access status and two additional columns for preprint identification) the actual table, containing open access status, is comparably small with a size of about 6 GB (compared to more than 165 GB of the complete version). Unpaywall does daily updates that can be downloaded and are used to update the local database to keep it in sync with the online version. The DOIs for publications listed in Google Scholar are obtained by either matches to publications from other sources, metadata retrieval using the Zotero translator service or a Crossref query.
Various R packages that facilitate retrieval of publications from a specific resource such as https://docs.ropensci.org/rorcid (ORCID),27 https://github.com/jkeirstead/scholar (Google Scholar)28 or https://docs.ropensci.org/rentrez (Pubmed)29 have been included.
The app is containerized using Docker (Version 19.03.13, dockerfiles and docker-compose file are provided in Software availability). Multiple, interacting containers are deployed using docker-compose, the two most important are a container running the R shiny application and another running PostgreSQL. Furthermore, the Zotero translator service is run in a separate container. As already stated, the PostgreSQL service is not strictly needed, but substantially increases retrieval speed of the OA status.
As mentioned above, a key use case is the comparison of publications listed in different public profiles and the detection of possible duplicated entries that allows the respective profiles to be updated. Figure 2 shows a use case for an author where the ORCID (0000-0002-3048-5518) and Google Scholar ID (XPfrRQEAAAAJ) were given as an input (collapsed panel in Figure 2A). Panel B provides a summary of the publication list and options to filter by dataset, by year and by OA status. Additionally, the possibility to remove duplicates or only show duplicates is available. The other panels contain visualizations including an upsetplot30 (C), a histogram (D) and a table (E). The table can be further filtered by selecting rows allowing to create specific citation lists that can be created based on the rows in the table. The contents of the table can be copied to the clipboard or downloaded in CSV format.

After entering identifiers in panel A, successful retrieval and merging, panels B-E appear. Panel B is the main panel for filtering. Visualizations are in panel C (upsetplot), D (histogram) and E (table).
Our method relies on the DOI to retrieve the OA status, which is a limitation in domains where DOIs are not used. The DOI is also used to unambiguously match publications. If no DOI is present, the titles of the publications are used for matching, which can lead to ambiguity. Even if a publication has an assigned DOI, but it is missing in the data, it becomes difficult or time-consuming to retrieve the missing information with services such as the Zotero translator or Crossref.
Because of the non commercial nature of this application, some additional limits present themselves. Most notably, our application requires freely-available APIs, or in the case of Google Scholar web-scraping (contravening the terms of use of Google Scholar), for retrieving the open publication data from their respective sources. For the two main sources considered so far (ORCID and Google Scholar), no restrictions have been noticed, while for others rate limits in the number of requests are quite restrictive (e.g., for Publons). Other APIs not currently included in our application (e.g., from Dimensions or Mendeley) could be added in the future. An useful addition could be the integration of the API from OpenAlex for citation information and publication metadata.31
Software available from: https://pubassistant.ch/
Source code available from: https://github.com/markrobinsonuzh/os_monitor
Archived source code at time of publication: https://doi.org/10.5281/zenodo.5509626
License: MIT
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)