Keywords
Heart attack, Angiogram, Stent, Machine Learning, Chatbot, CNN, Treatment, Doctor, Patient.
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Computational Modelling and Numerical Aspects in Engineering collection.
This article is included in the AI in Medicine and Healthcare collection.
Heart attack, Angiogram, Stent, Machine Learning, Chatbot, CNN, Treatment, Doctor, Patient.
Cardiovascular illnesses are the principal cause of fatality worldwide, with 17.9 million people dying each year. Low- and middle-income nations account for over 75% of all deaths related to cardiovascular disease. Every year, roughly 80,000 people suffer a heart attack at least once, with India having the highest rate in the world. Patients with obstructive arteries who have chest pain, tightness, or shortness of breath are at a higher risk of having a heart attack. One way the causality rate is handled is by administering stents. Stents of various sizes are advised to be positioned based on the size of the blockage inside the artery to treat them. The foremost important thing is to decide whether a stent is required or not. This decision is done by the cardiologist medical practitioner based entirely on observation and experience, which also includes the use of Human Intelligence. As a result, research into the possibilities of developing machine learning model-based fully agent to support human intelligence is considered in this work.
A Chatbot is a computer program that can converse with humans in natural language. Chatbots can provide accurate and efficient info depending entirely on the user’s requirements. Chatbots are used in a variety of domains, including Customer Support, Virtual Assistance, Online Trainings, and Online Reservations, as well as for routine chats. The authors here proposed a Chatbot that interacts with users and provide them with a realistic experience of conversing with a medical expert. There are already a few Medical Chatbots; however, they don’t provide users with services such as determining heart stent requirement; instead, they link them to a medical question and answer forum and present them with similar solutions to their symptoms that medical doctors may have previously answered.
A study of different research works was done to elevate the methodologies earlier researchers followed and the success they obtained. The study was done in a progressive was on different aspects of usage of chatbot as general applications, applications specific to health care domain, works that could process only text in chatbot followed by the ones which can process text and images as well. The important observations made in the literature survey are given below with respect to each work considered.
In work,1 the real time data of 16,733 patients have been provided by the C.M.O. Centre. Different techniques like Deep learning algorithms, machine learning algorithms using Spark which provides fault tolerance features, implicit data parallelism and data storage have been used. The Spark.ML library also provides all the data-preparation functionalities and the machine learning algorithms to train the collected training data. The chat-bot has been designed to help patients in choosing the most proper disease prevention pathway by asking for different information. The data flows, from and to the patient, through the chat-bot interactions. The result shows that it has 86.78% accuracy. The shortcoming is that it is a text-based application and excludes spoken or visual input. Even in the present work author’s have not included voice based input and left it as a scope of extension to present work.
In work,2 the Reddit dataset has been used by the researchers to make a database for the chatbot. NLP techniques and deep learning methods like Convolution Neural Networks, deep learning library TensorFlow, Neural machine translation (NMT), Bidirectional Recurrent neural network (BRNN) and attention mechanisms have been used for the implementation. The Chatbot takes in the source sentence, understands and analyses it, and produces an output statement mapped to the particular problem or query of the user. With the inclusion of BRNN with Attention model it not only helps in short but also in longer tokens. The weakness of this research is that the chatbot knowledge is based on open domain and it requires further improvement for it to become domain specific (like healthcare, education, etc.).
The researchers of work3 used Radar profile images were used by the researchers as the dataset. The researchers used techniques like CNN-Based Image Recognition Using Deep Convolutional Generative Adversarial Networks, GAN framework, and models of ImageNet Champion, Image recognition, Radar profile recognition. Researchers designed a fresh model structure to generate examples which are tough to collect based on DCGAN’s high scalability and outstanding sample making competence. The research built a recognition framework based on CNN and matched enough sample generation to strengthen the training recognition model. Finally this could improve the accuracy of classification.
In research,4 real time data records of patients have been used by the researchers. Artificial intelligence, Machine learning algorithms like the NLTK library has been used for implementation. The research was used for thematic analysis on the qualitative data to identify the common trends and patterns. A mixed-method approach was used that helped in generating a multi-layered issue. The drawback of this research was that the entire sentences of the query inputs from the user are converted into lowercase which resulted in decline in accuracy of the result search process.
Researchers in work5 dealt with image dataset of respective and CT perfusion techniques, Radlex playbook (tool) and various machine learning and image recognition techniques have been adopted for the implementation. Description of high-level features of reusable medical image datasets suitable to train and regulate ML products was done. Communication among medical imaging domain experts, medical imaging informaticists, academic clinical and basic science researchers, government and industry data scientists, and interested commercial entities were improved. The result of this research was that it helped in understanding the medical image datasets. The challenges found were that, it required highly centralized data security and different regulatory and legal environments.
In research of6 a medical knowledge database and user information database, conversation scripts are used by the researchers. For text understanding module pattern matching, ML Algorithms, XML, AIML, Decision Trees, Web services (Dialog Flow by google) are used. For Dialogue Management Pattern Matching, ML Algorithms have been used and for Text Generation ML and Deep Learning methods have been used by the researchers. This work was intended to support researchers of chatbot development for medical field by investigating different development strategies and connected technical characteristics. As a result the 4 technical aspects of the chatbot have been recorded. The problem is that, it only paid attention on text-based chatbot usage, where the input or output modality is only written.
In research7 the dataset of chest X-ray images, chest CT images was used by the researchers. “Automated Classification of COVID-19 from Chest X-Ray Images using Transform Learning with Deep Convolution Neural Network” to assist diagnosis is done. The network consists of risk factors of patients being considered in first layer followed by a convolution layer and risk prediction is done using softmax classifiers in the fully connected last layer. Risk prediction is done with output label as, P = P0,P1, where, P0 and P1 indicates the subject is at high risk and low-risk of COVID- 19, respectively. As a result, the 3 open research directions, classification of CXR images using ML techniques, and risk prediction are presented. The disadvantage observed is the generalizability of the ML model.
In work,8 Images from Pascal, ImageNet, SUN, and COCO were used as the dataset. The researchers have used object detection, image recognition techniques like Mask R-CNN. The chatbot was capable to identify objects in the image, tell about and make out the image, and was also able to answer the questions about the image. The underlying recognition framework for this work was an encoder-decoder network which is used for fusion of images and Resnet architecture for object detection and localization. The scope of improvement of this research was that still many necessary tests have to be carried out to prove whether the sample really has the characteristics of real data or not.
The researchers of work9 used the dataset includes the real time patient records. The research used the Food and Drug Administration (FDA) online database for premarket approval applications to identify the major regulatory approvals. It Used the World Intellectual Property Organization’s natural language search engine (TACSY version 2.1.1) to locate the appropriate International Patent Classification designation used by patent reviewers for classification of applications related to stents. Using a comprehensive database of patents, it identified all individuals and institutions that developed intellectual property related to stent technology early in its development process. The result of this research was that 245 granted patents were recorded. The drawback is that this study of patents and patent citations focused only on the years preceding the clinical introduction of artificial stents.
In work,10 brain MRI images containing tumors of different patients have been used as the dataset. The researchers used techniques like Threshold-based segmentation algorithm, Machine Learning algorithms such as clustering, fuzzy c-means clustering (FCM), K-means clustering, and expectation maximization (EM) and CNN. In order to segment brain images, the researches proposed a combination of morphological operations to develop a hybrid clustering algorithm. Outer membrane is removed in first step using morphological operations in algorithm thus reducing need of large number of clustering iterations and complexity of computation. In the clustering stage, the K-means++ clustering algorithm is exploited to initialize the clusters’ centroids which helps in solving the problem of unstable clustering. The drawback was that the noise present in the images greatly affected the segmentation of lesions and diagnosis of patient’s conditions.
The block diagram of the overall idea can be seen in the Figure 1.
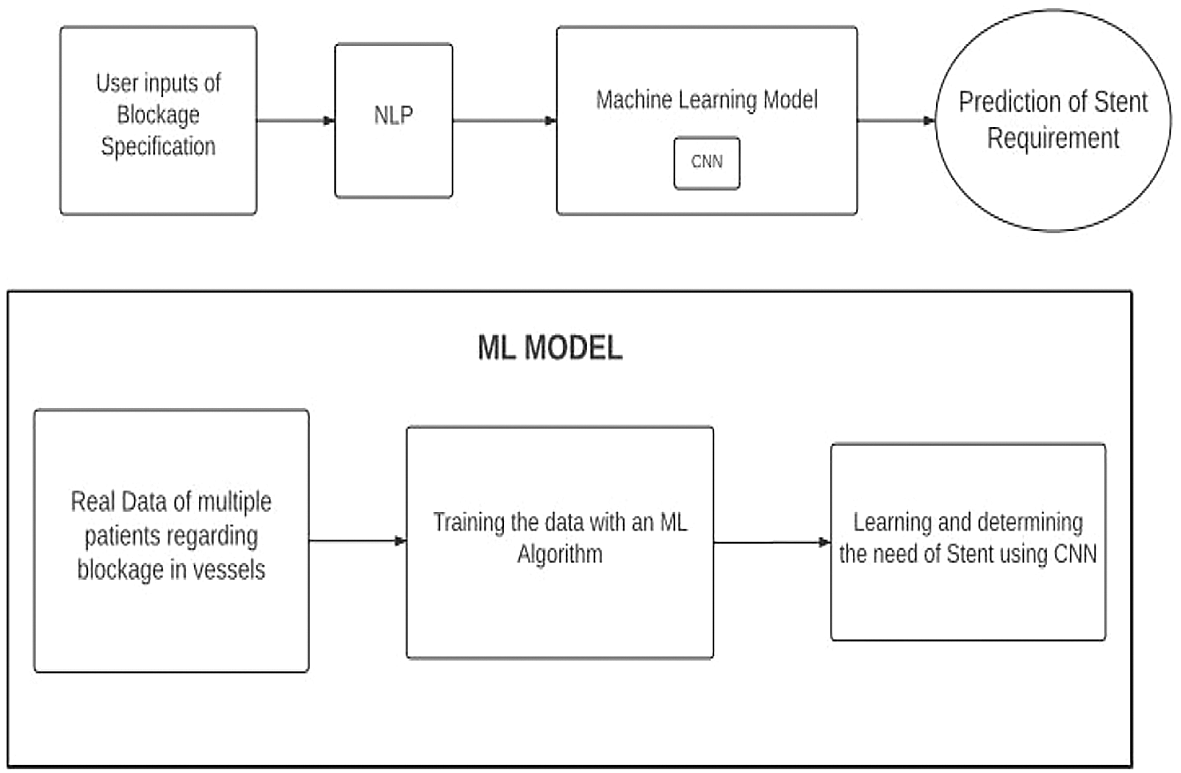
The user accesses the web application and inputs the concern regarding heart in the form of text data and scanned images of the artery. The entered text data is formatted using an AI - Natural Language Processing (NLP) technique.
Figure 2 below shows the level-0 Use case diagram of the work carried out by authors of this paper.
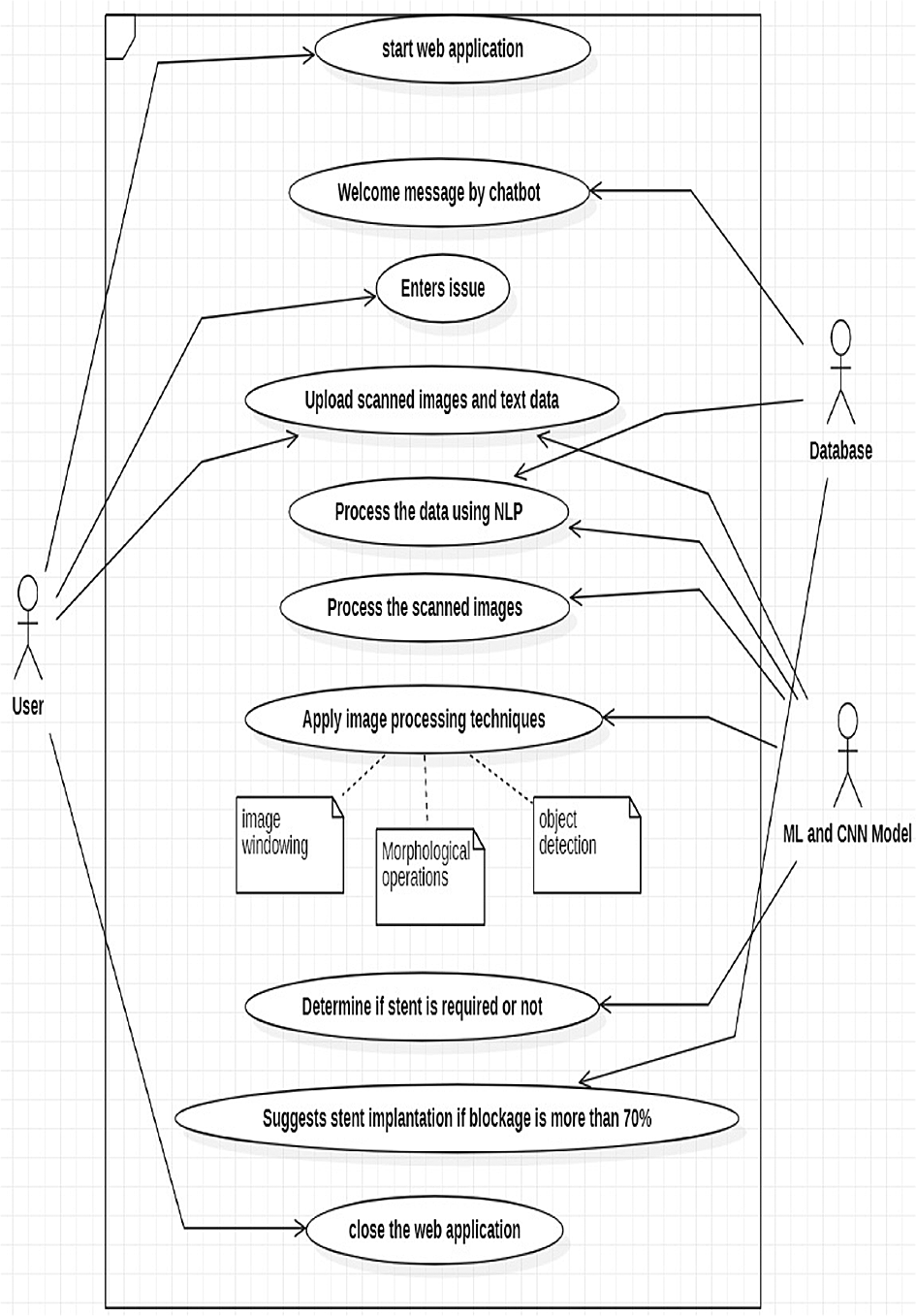
Using the chatbot, the user can upload the scanned images of heart in jpeg format. The scanned images are processed using the Convolution Neural Networks (CNN) model which is an artificial neural network used in image recognition and image processing. CNN is a class of deep neural networks which is a subset and function of Artificial Intelligence. CNN module is composed of convolution layers and pooling layers to process input data. Various image processing techniques like image windowing, morphological operations, and object detection are used in procedure to identify the actual blockage part in a vein of the heart’s image that is uploaded.
The images used for this work are the Coronary Angiogram Reports and Angiogram images of real time data belonging to 20 patients provided by a well reputed Cardiac hospital in Hyderabad. The Angiogram data provided was in the form of DICOM images. DICOM is Digital Imaging & Communications in Medicine and used to supply interchangeability of medical information and images. “Syngo fast View” software enables to view DICOM images, apply image manipulation and convert them to bitmaps, JPEG, AVI. The images were provided along with the standalone viewing tool SYNGO fast View for visualization of DICOM images (series, studies, patients). For experimentation purpose these dicom images are converted to jpg using online available resources. The number of jpg images resulted is the number of frames consisting in the DICOM image. The required and useful images showing blockage in the coronary artery are separated manually and these useful images segregated forms the dataset of our project. The dataset considered consists of a total of 348 images of patients. To train the CNN model, 193 images having blockage and 155 images having no blockage were used.
Convolution in mathematics is an operation of two functions that creates a third function, which shows how the form of one is changed by the other. The model built was sequential, 5 Convolution 2D layers and 5 Max Pooling layers are added to the model alternatively. The input shape is given 150 × 150 × 3 as the images are in the rgb format. The actual size of each image is 512 × 512. One flatten layer, dense layers and dropout layer is added to the model. The activation function used in these layers is ReLU. First, in relation to the dimensions of the input, the convolved function is reduced and the second type is used to minimize the padding. The rectified linear unit function “ReLU” activation is a piece-by-part linear function which reproduces the input directly if positive; otherwise it produces zero. The Pooling-Layer reduces the Convolved feature’s spatial dimension. It reduces the computational power necessary to process the data by reducing dimensionality. It is also used to extract dominant features that are invariant in rotation and position, thereby maintaining the model’s effective formation process. Max pooling returns “the maximum value in the kernel” area of the image. Max Pooling is called as a “Noise suppressant” because it discards the noisy activations and also performs de-noising along with dimensionality reduction. The flatten layer “converts the data into a 1-D array” for inputting it to the next layer. Flattening the output of the convolutional layers to create a long feature vector and then it is linked to the final classification model like ANN (Artificial Neural Networks) which is called a fully connected layer. The dropout rate is particular to the layer because the chances of placing every input to the layer to zero. The dropout rate is set to 0.2 in the experiments carried out. The dense layer’s neurons get input from output of each neuron of its previous layer, in which neurons of the dense layer carry out matrix-vector multiplication. The activation feature of this dense layer used was sigmoid. The CNN architecture used in experiments carried can be shown as in Figure 3.
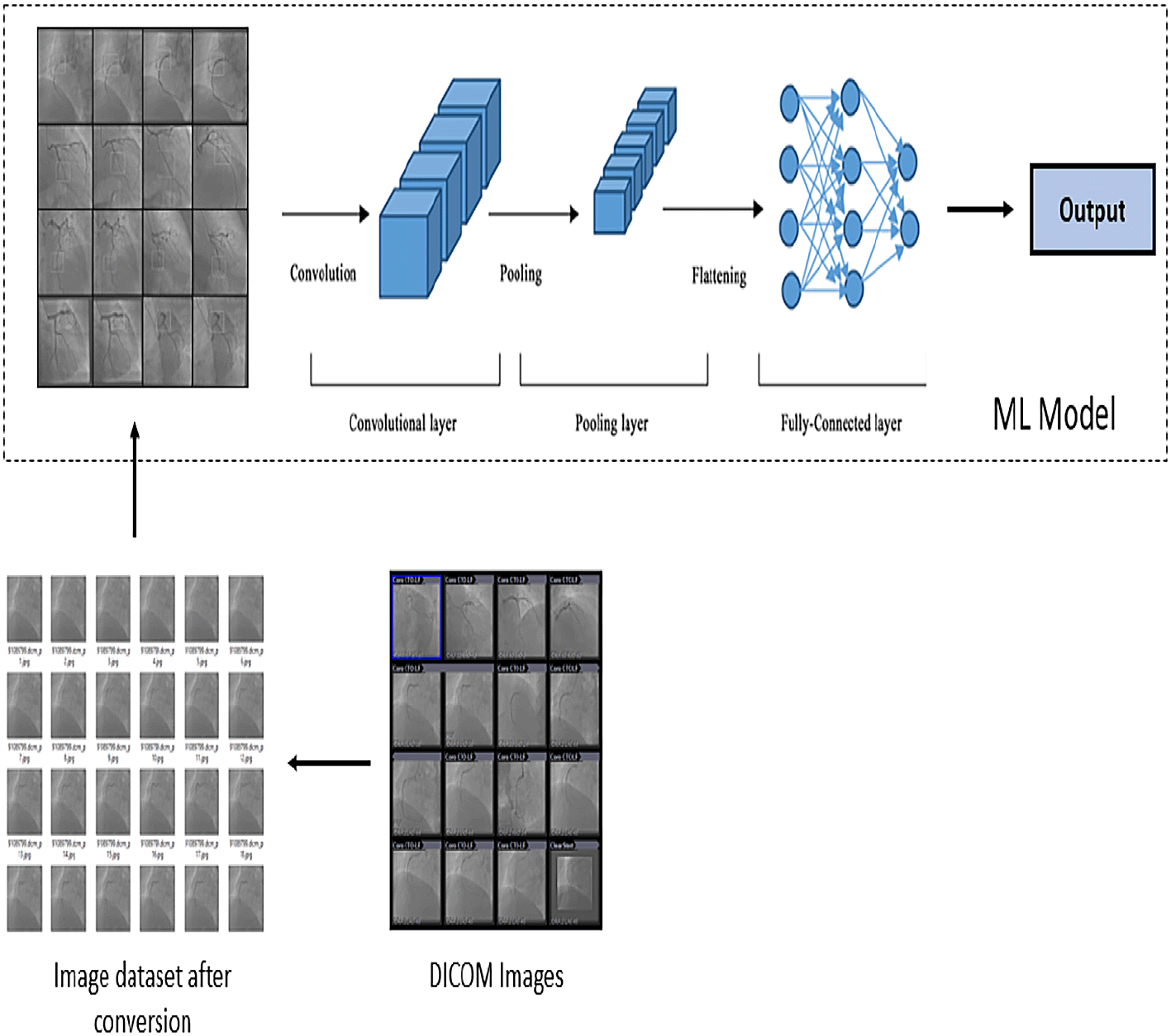
The summary of model generated can be seen as given below in Figure 4.

The loss function “categorical crossentropy” is used. For the model developed, there are two classes NoStent and Stent to classify. Adam optimization is a stochastic gradient descent technique based on adaptive first and second order moment prediction. Adam has been specifically designed for the formation of deep-neural networks as an adaptive learning rate optimization algorithm. Adam optimizer was used during experimentation. The accuracy metrics have been used.
A chatbot was created using flask techniques on deep learning algorithms. The chatbot was made to learn on the data which contains intents, pattern and responses. The chatbot was built using Flask, NLTK, Keras, Python, Punkt, wordnet package etc.
After having training data ready, the model training was initialized. A 3-layer output model was used. There are hundred and twenty eight followed by a second layer having sixty four neurons having softmax, Relu activation function applied and the ultimate layer holds neurons matching with to be predicted number of intents. It was observed in work carried out that stochastic gradient descent with Nesterov accelerated gave acceptable results for this model.
The results of application developed and experimentation done are shown in the Figures 5, 6, 7, 8 given. The series of screenshots shows the chat bot conversation and the decision given by the underlying trained model, whether stent is required or not for a patient based on image uploaded.
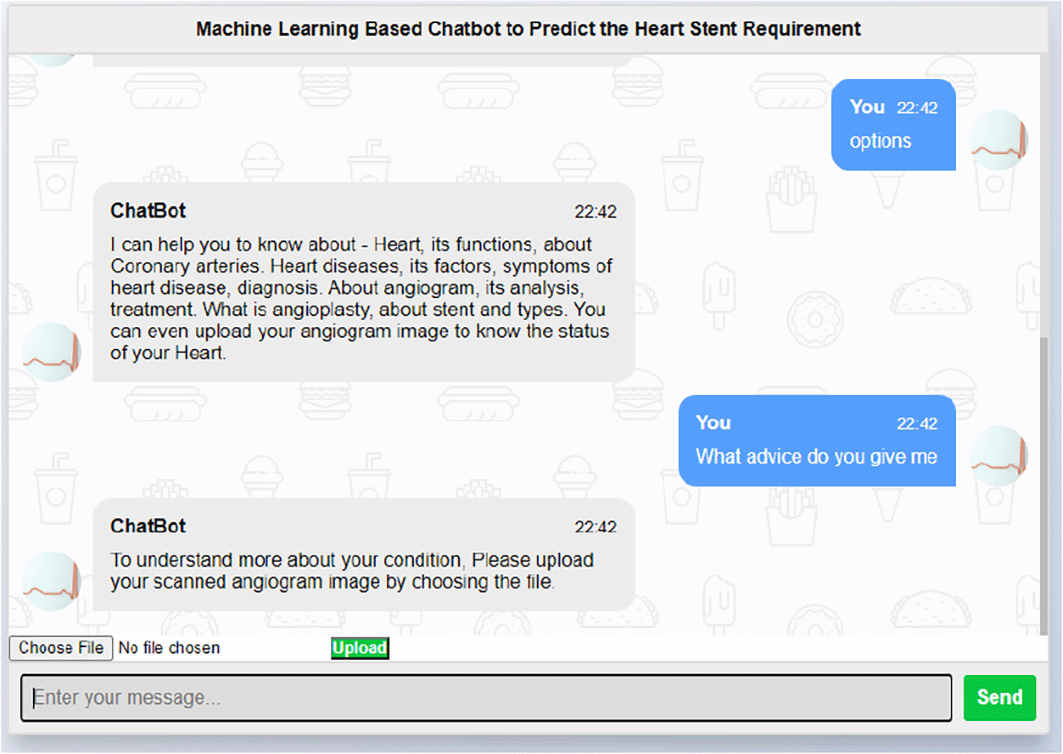
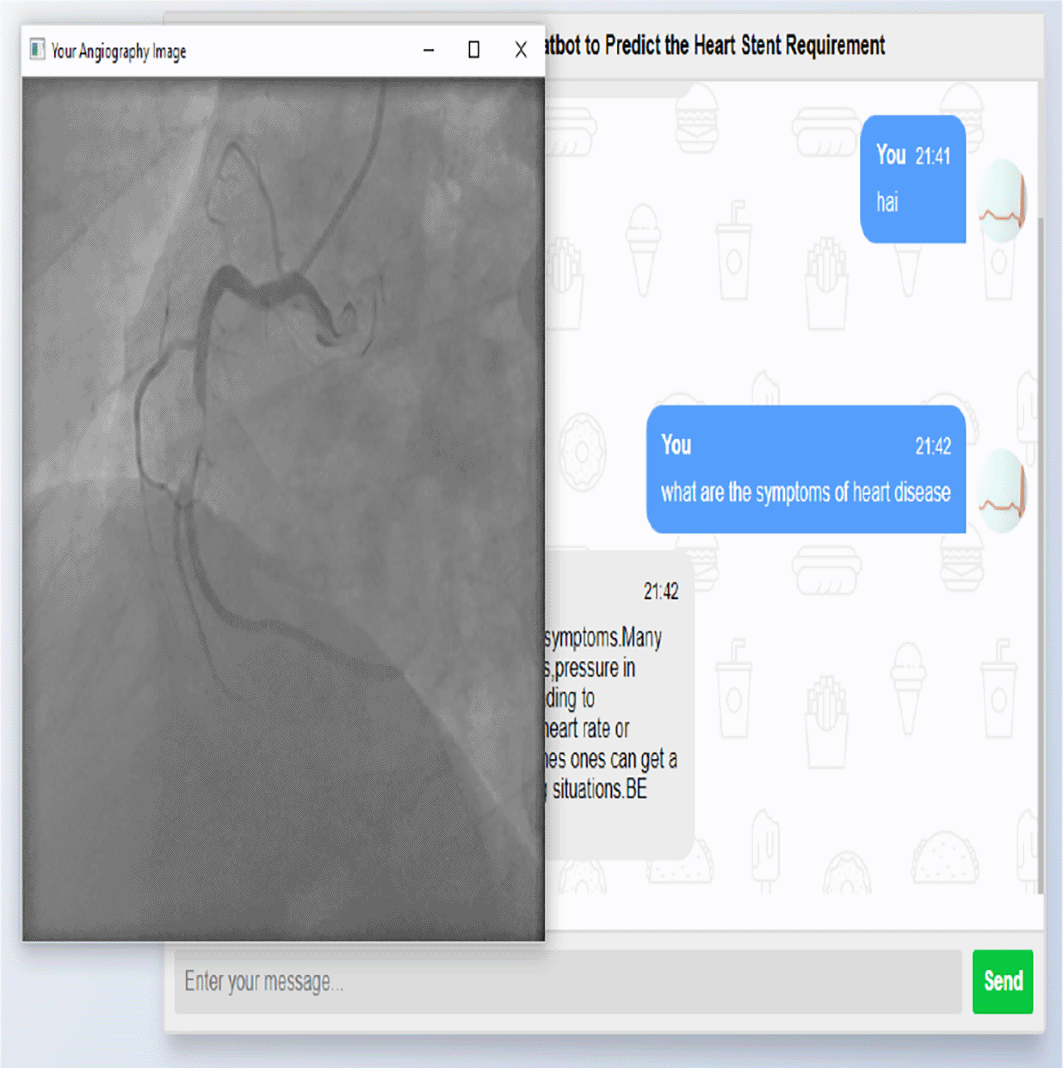

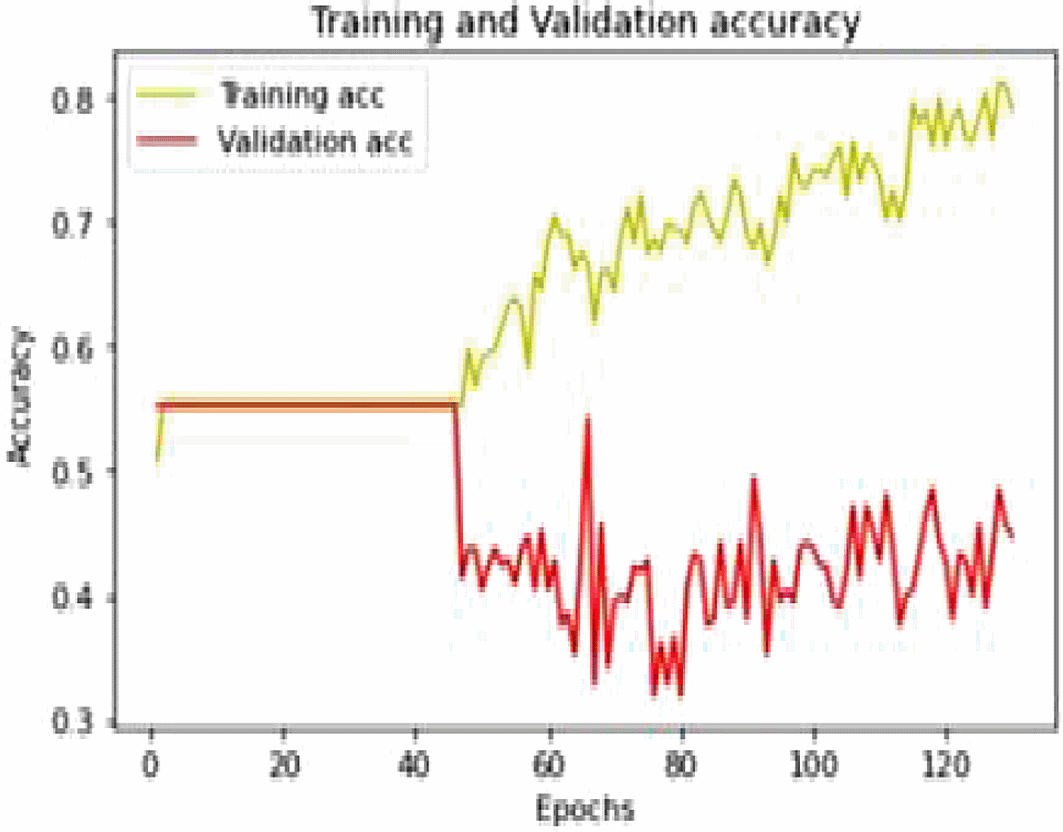
Figure 8 below depicts the CNN training and Validation Accuracy for the model developed in order to predict whether stent is required or not.
The experiment was carried out under a set of constraints and authors of this paper opine by modifying the parameters further and enhancing the dataset can result in high accuracy and most robust system. The research was carried out as a project work during final semester of engineering study of students resulting in time constraint for doing more iteration of experiments. The future scope of this project includes: application did not make use of voice based input, in next level audio based chat can be implemented. It was observed that the dataset used was not sufficient for model to learn the complete variations of blockages in images of heart. As researchers worked with only possible real time patient data of 459 images yet there is a good scope of improvement when using thousands of images the model may learn more accurately to classify stent required and not required heart images of patients. Data augmentation is one way we can try to overcome this problem. The low variance in the image set considered could be one reason of less model generalization achieved. If researchers can have as large as 10,000 data images with high variance we hope networks such as Variational-Auto Encoder combined with U-Net may give more better performance when run on GPUs.
Coronary artery stenting is the remedy of preference for patients requiring coronary angioplasty. The quest for a perfect stent continues, however the decision of whether to go for stent or not is crucial. Using this work authors explored an easy to access chatbot based application that predicts the requirement of stent for the user based on scanned image of angiogram uploaded by user. The authors proposed a simple mechanism using chat bot to mitigate dilemma of young practicing doctors as well as patients in deciding whether stent is required or not. Authors made use of CNN model to classify the images having blockages in arteries. The sequential CNN model consists of 5 convolutional 2D layers and 5 Max Pooling Layers. It was observed that the model was giving an accuracy of 81%.
Mr. Krishna Chythanya N was the brain behind this work and proposed as well guided the research with time to time code verification and suggesting team members. Dr. Jandyala N Murthy was instrumental in presenting the thoughts on paper in right way and also time to time evaluated the on going work suggesting where ever required. Ms. Harika Konda was instrumental in developing the required code to implement the work. Ms. Fazilath Maheen was playing the role of supporting Harika in code development. Ms. Rapolu Reetica was contributing in developing the chatbot module. Ms. Mudunuri Alekya played a pivotal role in contacting near by hospitals to get real time heart scan images of patients and also supported in coding as well as writing the technical paper. Ms. Chaitanya Priya played the role of tester and thoroughly tested the project besides helping in coding.
Figshare: Heart Image Data Set for chatbot to predict need of stent in cardiac treatment, https://doi.org/10.6084/m9.figshare.20252016.v1. This project contains the following underlying data:
Zenodo: CHATBOT TO PREDICT NEED OF STENT IN CARDIAC TREATMENT, https://doi.org/10.5281/zenodo.6834504.
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)