Keywords
Bayesian spatial and space-time models, Tuberculosis relative risk, baseline predictors and TB hot-spots.
Bayesian spatial and space-time models, Tuberculosis relative risk, baseline predictors and TB hot-spots.
Globally, Tuberculosis (TB) is in the top ten causes of death in low-income countries (ranking above HIV/AIDS).1 This infectious disease is transmitted by bacillus Mycobacterium tuberculosis.2 TB occurs essentially in individuals with weakened immune systems than those with healthy immune systems. As HIV weakens the immune system, TB is often seen in individuals with HIV.3 Nevertheless, in 2019, approximately 10 million people tested positive for TB with an estimated 1.2 million HIV-negative deaths.2 Although this disease can affect both sexes, reports have shown that males (aged 15 years and above) accounted for 56% of the global infections compared to 32% for females in the same age group. Infections among children (aged 15 years and below) accounted for 12% of the total cases and about 8.2% of the reported cases were HIV-patients.2 Geographically, the 2020 reports have shown that the highest number of new TB cases occurred in the WHO South-East Asia (43%), followed by Africa Region (25%), and the WHO Western Pacific (18%), compared to Eastern Mediterranean (8.2%), America (2.9%) and Europe (2.5%).2,4 It has been estimated that 86% of new TB cases occurred in the 30 high TB burden countries,4 where eight countries including India, China, Indonesia, Philippines, Pakistan, Nigeria, Bangladesh and South Africa accounted for 2/3 of the new TB cases.
As such, in order to have faster reduction in TB incidents and deaths worldwide and especially in low-income countries, the World Health Organization (WHO) has called for the development of TB vaccines.2 Reports have shown that TB is preventable and can also be cured as well. Studies have reported that approximately 85% of those who develop TB disease can be treated successfully with a 6-month drug regimen.2 Available reports indicate that this treatment has prevented more than 60 millions deaths from 2000 to 2020.2 Despite this treatment, the global and in specific WHO regions and many high TB burden countries did not have a fast enough progression towards the 2020 milestone of The End TB Strategy. The global cumulative reduction was reported at 9% between 2015 and 2019, and about 2.3% between 2018 and 2019.2 However, more optimistically, Europe had achieved 19% reduction in cases and 31% reduction in deaths between 2015 and 2019. Africa had achieved a 16% reduction in cases and a 19% reduction in deaths between 2015 and 2020.2 As the WHO’s target for global decline of TB cases and deaths (2015-2020) were not achieved, there is still a need for further studies to be conducted on the dynamics of the disease and on mitigation measures for TB in Africa. Ghana as a developing country in Africa, has been affected by the respiratory disease and currently has challenges in eradicating TB. The country implemented policies called Directly Observe Therapy (DOT) and National Tuberculosis Programmes (NTPs) in 1994, to detect and treat TB.2,5–7 The implementation of the NTP led to 100% DOTs coverage in 2005 with more TB cases detected for treatment every year since. For instance, TB cases detected increased from 7,425 in 1996 to 15,286 in 2009.8,9
Although TB cases and deaths have declined due to the implementation of mitigation/treatment strategies, TB still remains a life-threatening disease and poses a burden on health infrastructure in Ghana. Hence, TB has gained considerable attention as a topic of research among researchers from diverse backgrounds. Studies have investigated the dynamics of TB indicators as well as risk factors of this disease in Ghana6,7,10 Osei et al.6,7 studied trends of TB detection and treatment outcomes using the logistic regression to assess the relationship between patients and disease characteristics. Further, Osei et al.6,7 have studied TB detection, mortality and co-infection with HIV, using patients data collected in the Volta Region from 2012–2016. The authors used simple and multiple logistic regression to investigate determinants of TB mortality in 10 districts of the Volta Region of Ghana. Aryee et al.10 have studied the dynamics of TB using Autoregressive Moving Average (ARIMA) methods and TB data recorded by the Korle Bu Teaching Hospital from 2008–2017. Iddrisu et al.11 have studied the temporal and geographical pattern of TB prevalence in Ghana between 2015 and 2018.
In this paper, Bayesian hierarchical spatial and space-time models is used to study the relative risk (RR) of TB and associated risk factors across the 10 Regions of Ghana. Hence, the purpose of this study was to model the spatio-temporal risk pattern of TB in Ghana, using Bayesian hierarchical and space-time models discussed in previous literature.12–16
In this study TB detection data obtained from Ghana Health Service and National Tuberculosis Programme was used.8 The data contained information on TB detection from 2009 to 2017, for the 10 old administrative regions of Ghana. These regions include, Ashanti, Brong Ahafo, Central, Eastern, Greater Accra, Northern, Upper East, Upper West, Volta, and Western.
Figure 1 shows the TB trends in the 10 regions from 2008 to 2017. Generally, there is a decrease in TB cases observed in all regions (except Brong Ahafo Region where TB cases increase) of Ghana from 2008 to 2016. It can also be observed that TB cases in Northern and Upper East increased remarkably between 2016 and 2017, whereas cases in Ashanti Region decreased from 50 per 100, 000 population in 2016 to 45 per 100,000 population in 2017. In the Northern Region, TB cases increased from 24 per 100,000 population in 2016 to 52 per 100,000 population in 2017. Further, cases in Upper East Region increased from 53 per 100,000 population in 2016 to 63 per 100,000 population in 2017. However, the changes in TB cases in the other regions are almost horizontal.
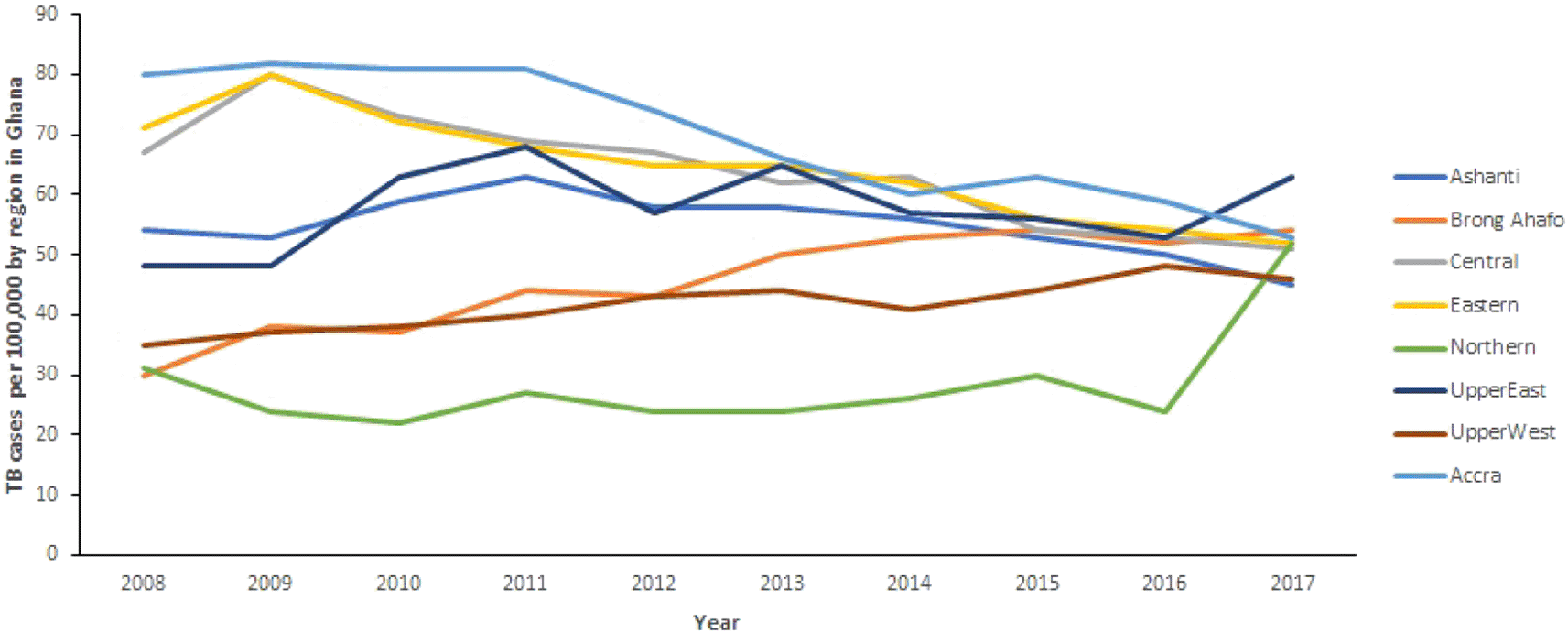
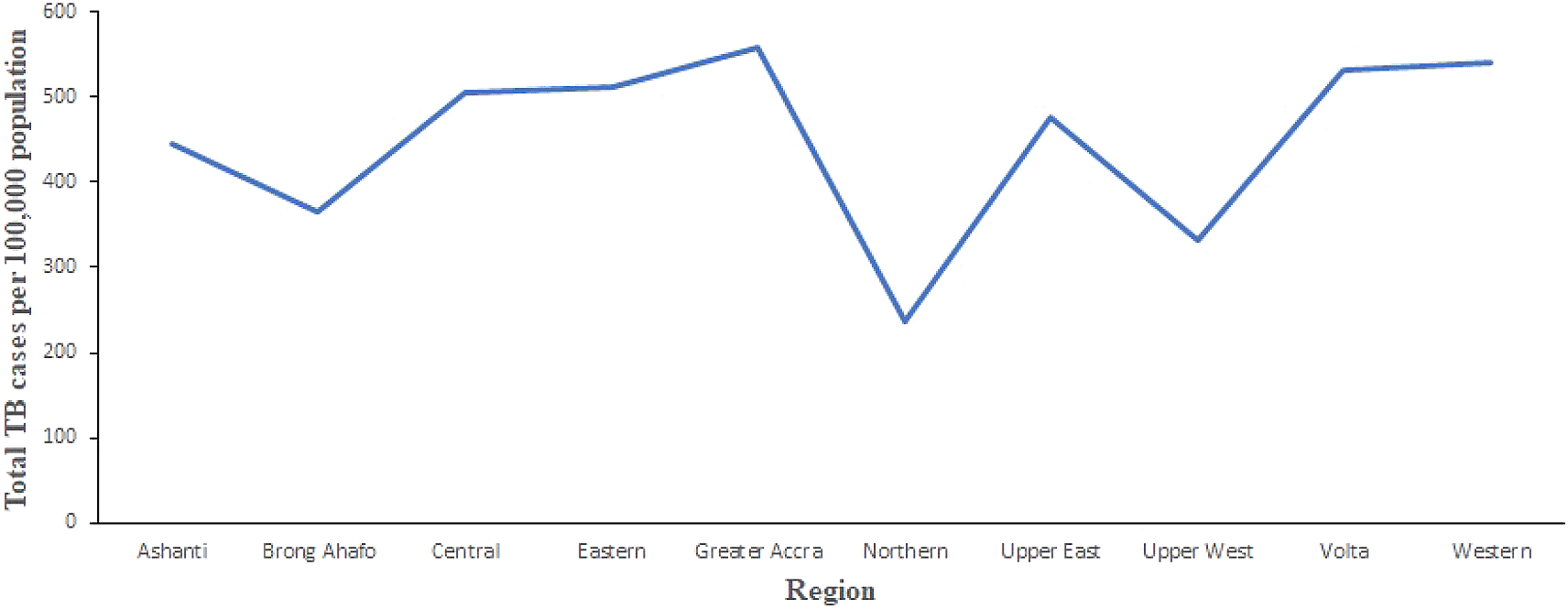
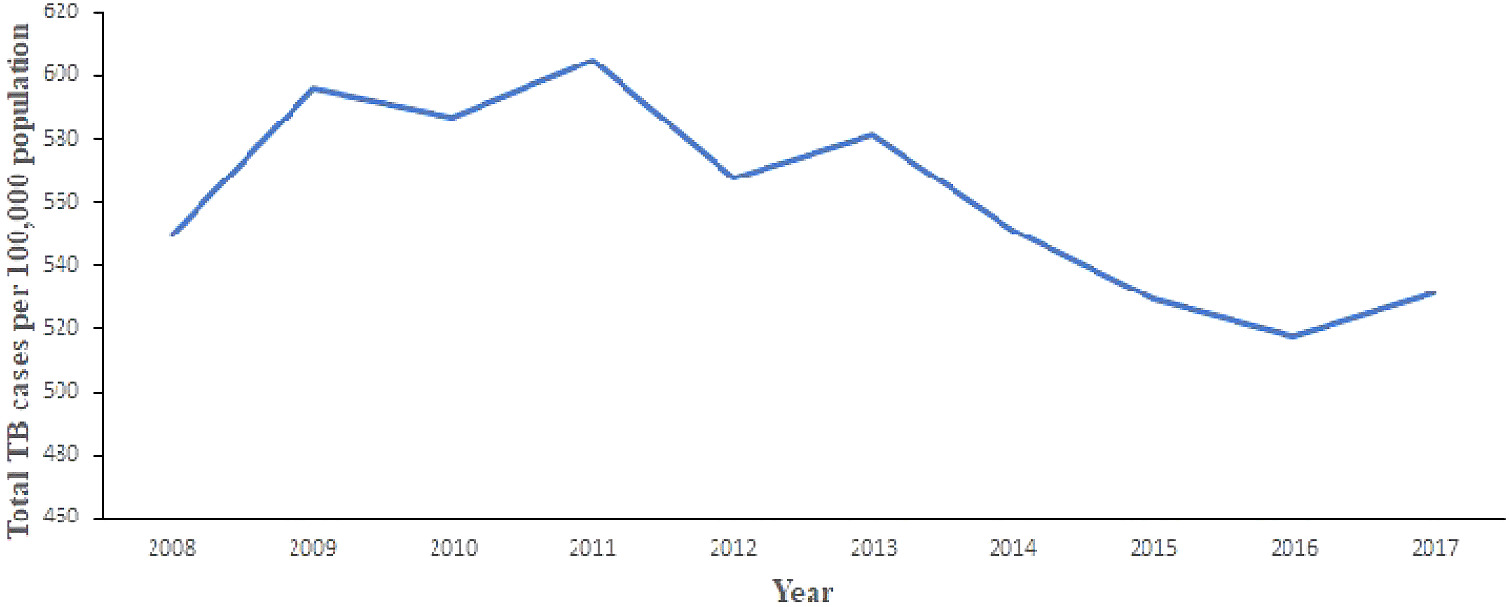
Figure 2 shows the trend of total number of TB cases for each region from 2008 to 2017. It shows that the highest cases recorded was in the Greater Accra Region from 2008 to 2017. It also shows that the lowest was recorded in the Northern Region. Volta and Western Regions are second and third, respectively, with records slightly lower than Greater Accra Region. In addition, Figure 3 shows the trend of total TB cases in each year/period. The figure shows that the highest number of total TB cases was recorded in 2011 while the lowest was in 2016. It can be observed that TB cases decreased slowly from 2011 to 2017 with increments in 2012 and 2017.
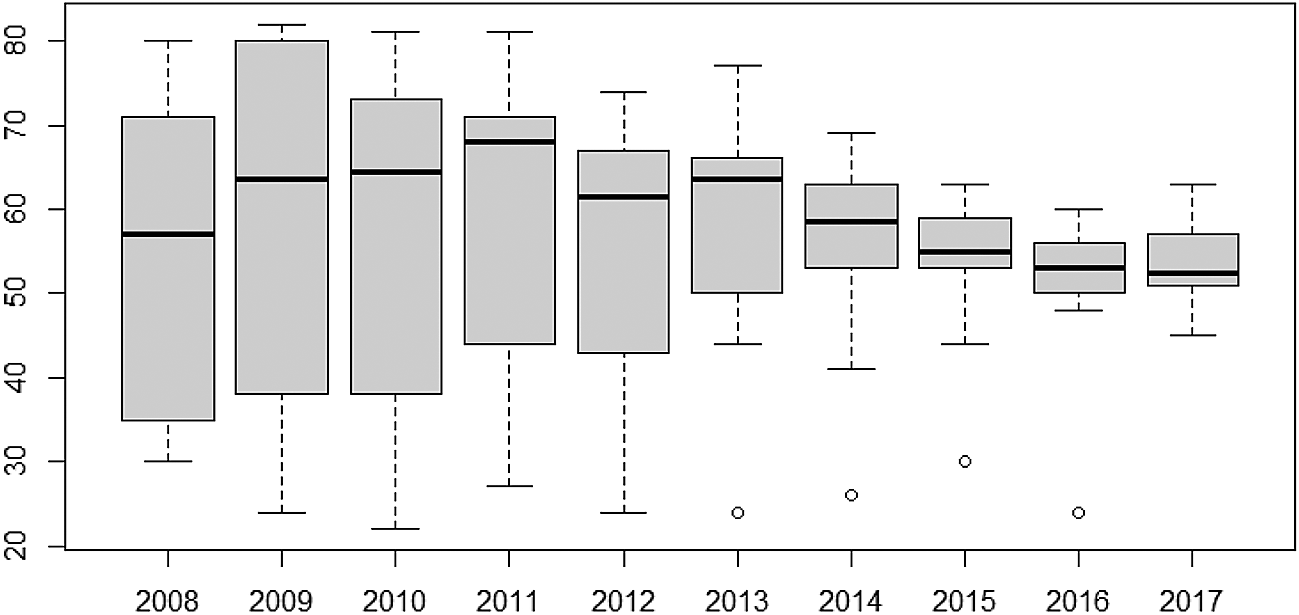
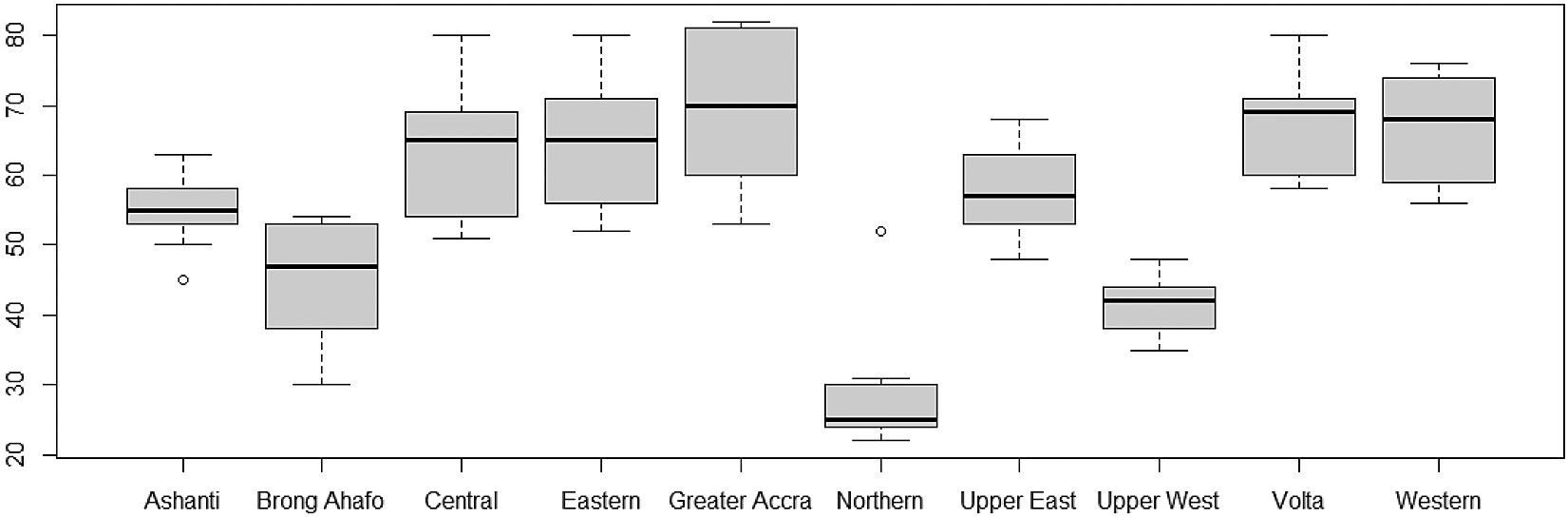
Furthermore, the variability of TB cases from 2008 to 2017 have also been presented using box-and-whisker plots in Figure 4. The overlapping box-and-whisker plots imply that there is no variability in cases among the years. The plots show that TB cases were skewed towards larger numbers from the year 2008 to 2014, and skewed towards smaller numbers from 2015 to 2016. Extremely small numbers were observed in 2013, 2014, 2015, and 2017. Variability across the regions have been presented in Figure 5. None-overlap of box-and-whisker plots imply variability between regions. Thus, there is variability in TB cases among the regions since some of the box-and-whisker plots do not overlap. It can also be observed that TB cases in most of the regions are skewed towards larger numbers except Northern and Upper East Regions (especially, the Northern Region with one extremely large value).
Some baseline regional characteristics on the risk of TB infection have been explored in this study. The set of baseline predictors include doctor to population ratio, nurse to population ratio, HIV prevalence, TB cure rate, TB success rate, wealth quantiles and the proportions of men/women employed, unemployed, educated, and uneducated. Variables also considered in the study include proportions of people who have heard about the TB disease, have knowledge that TB is airborne, knowledge that TB can be cured, and those who believe that TB status should be kept secret. In the data analyses, all the baseline variables were explored to obtain significant predictors of the TB cases.
For spatial TB data, let denote a Poisson random variable with probability mass function defined as , where is a vector of relative risk parameters for each region. The variable represent total number of TB cases for region It follows that the likelihood function for the Poisson variable is defined as:
with assumption that the sample values of given the parameter estimates are independent.17 Bayesian modeling framework requires prior distribution of the unknown parameters in the likelihood function for the data. The prior distribution represents the current knowledge of the parameters before the data are observed.17 Under the Bayesian framework, all parameters are stochastic and assigned appropriate distributions called prior distributions.17 Bayesian modeling framework combines the likelihood function for the data and the prior distributions for the parameters resulting in a distribution known as the posterior distribution.15,17–19 The posterior distribution is defined as (i.e. probability distribution of the parameters given that the data which is proportional to the product of the likelihood function) while the prior distribution is defined as:Moreover, after covariate adjustments, statistical inferences remained unchanged and the classical parametric formulation (in Equation 7) remains the most accurate model for the TB data. The posterior summary statistics in Table 6 showed negligible risk of TB across the 10 regions. Precisions of both the unstructured and structured components indicate clustering of risk. The models are implemented in R-software via the Integrated Nested Laplace Approach (INLA) packagon. Instructions on downloading and how to use this package can be found in Håvard et al.20 Also, this package can directly be installed in R software by using the command install.packages("INLA",repos=c (getOption("repos"),INLA="https://inla.r-inla-download.org/R/stable"), dep=TRUE).
The clustering and variability of risk were studied using correlated and uncorrelated structures, respectively. The use of uncorrelated heterogeneity models with gamma or beta prior distributions for estimating the relative risk of a given disease are useful, however, such models have limitations. Andrew [17, P. 82-84] stated that a gamma distributions restrict the incorporation of covariates into the modeling process. Another limitation is that such models do not allow the formulation of a simple and adaptable general form of the gamma distribution with spatially correlated parameters [17, P. 82-84]. Wolpert and Ickstadt21 have also given an example of correlated gamma field models that yield poor results.22 However, Gaussian models permit incorporation of correlated structure (CH) into the modeling process. Further, variability in the data can be modeled as uncorrelated heterogeneity (UH) using a Gaussian prior distribution with a mean zero and risk variance of the disease across the regions. Both correlated and uncorrelated heterogeneity can be incorporated into the model to account for clustering and heterogeneity of risk. These structures are introduced into the modeling through a log-linear term with additive random effects.18,23 Besag et al.24 have provided the form of the model with CH and UH structures parameterized as follows:
where is the fixed effect component, and are the correlated and uncorrelated heterogeneity components, respectively with separate prior distributions. Often, the CH component is assumed to have either an intrinsic Gaussian conditional auto-regressive (CAR) prior distribution or a fully specified Multivariate Normal prior distribution.18,19,22,24CAR models provide a tool for detecting and identifying regions where disease risks are clustered. The specification of CAR models provide a framework for borrowing strength between neighboring regions in such a way that, regions that share boundaries are likely to have similar risks and regions that are distant apart are likely to show variability with regard to risk. Waldo Tobler’s25 noted that “everything is related to everything else but near-by things are more related than distant things”. CAR models were rarely used to detect and cluster risk until the 1990s.13,26 The models enable the influence of disease risk in neighboring regions to be modeled and estimated.18,19,27 Distances or boundaries between the regions are used to determine neighborhood properties in the CAR models.14,17,28
Let denote the study area and classifies regions that share boundaries with region Let be a stochastic variable, then the CH structure of follows a normal distribution defined as:
Assume that region has neighbors and for each region that is a neighbor but zero elsewhere. The conditional expectation of is given by:
and the conditional variance is:The Gaussian processes are defined by mean and covariance functions.30 Thus, the mean and variance-covariance functions are required to specify the CAR model. It follows the conditional probability distribution of the CAR structure is defined as22,24,25:
The symmetry of implies that the covariance matrix is symmetric such that The probability distribution Function (3) can alternatively be defined as:
It has been proved that the CAR structure follows the Gaussian distribution by showing that is symmetric, see18,31 for details.
0.0.1. Parameter estimation: CAR model
Parameters in the CAR model are estimated using Bayesian hierarchical methods. The TB detection data used in the study are counts (whole numbers), therefore, Poisson distribution is assumed for such data. The unknown risk of TB in any region represented by The number of cases and population risk in any region are denoted by and respectively. The expected number of cases in region can then be written as:
wheregescrepresents the overall risk in the study population. The corresponding likelihood function is defined as:
Taking natural logarithm of the likelihood function, differentiating with respect to the disease risk and equating to zero, it can be shown that the maximum likelihood estimator of is
which defines the standardized mortality ratio (SMR) in region However, using the Bayesian framework, Poisson , where the Poisson mean Gamma with shape parameter and scale parameters respectively. However, these formulations do not incorporate covariates in the modeling process. Covariates through a linear predictor was introduced, as seen in previous work [18, 19, 17, P. 84]. The distribution of the response variable is specified by the exponent of the linear predictor as Poisson , where is the mean of Poisson distribution. Thus, the relative risk of the disease in region is defined as:
where and has a CAR structure.Using the generalized linear model with a log-link function, we have:
Bayesian models are defined by the posterior distribution of the parameter estimates, where the posterior is the product of the data likelihood function and the prior distribution(s) of the parameter estimates. Hence, we define the likelihood function as:
The parameter estimates are assumed to follow the Gaussian distribution defined:
and the prior distribution for the CAR random effect is defined by:where is the number of areas which share boundaries with the area32 with:with quantifying the proximity between regions and . That is, if , then and share a common boundary. The posterior distribution can be expressed as follows:The hyperprior distribution for the precision parameters and are respectively, Gamma and Gamma The linear regression coefficient distribution is defined by:
0.0.2 The Besag, York and Molli’e (BYM) Model
Clayton and Kaldor33 were first to propose the BYM framework, and later, Besag et al. developed it further.24 The BYM (also known as the convolution model) unifies the CH and UH structures into the same model that is capable of explaining clustering and variability of the disease risk. Although various models have been proposed for smooth risks estimation, the model proposed by Besag et al. (BYM)24 have been used extensively in literature. The BYM model is expressed as follows:
As indicated in the previous section, the TB cases follow the Poisson distribution, thus, Poisson where The linear link function is The relative risk is . Therefore, the relative risk for area is defined by:
The log log-link function is defined as:
Parameters in the BYM are estimated using the same formulations discussed in the previous section, however, is required to be a Gaussian prior distribution given by:
The resulting posterior distribution can be written as follows:
The distributions for the hyper-prior precision parameters are as follows:
respectively. The regression coefficients follow Gaussian distributions stated as follows;The estimates, and are precision-variance estimates for and respectively, and are used to measure the level of variability of risk among the regions and to cluster risk between neighboring regions.18,27
The TB data used in study are collected over time and hence spatial models alone will not be enough to model the space-time pattern of the relative risk of the disease. The spatial models are constrained for identifying heterogeneity and clustering of risk at a single time point. Several methods have been proposed to account for spatial and temporal patterns of disease risks.23,24,34–36
In this section, space-time models are presented based on three modeling frameworks developed by Knorr-Held et al.,16,37 Bernardineli et al.23 and Waller et al.37 These models differ with regards to their space-time interactive structures and inclusion of covariates. Consider region in year that recorded TB cases. The cases follow the Poisson distribution, i.e.:
where the unknown relative risk at region in time is:and is the expected number of TB cases in region in time . The expected number of TB cases represents the number of cases expected if the population of region has statistical behavior comparable to the standard population We express the crude rate of TB cases for region in time as:and the number of TB cases expected in region in time as:where denotes the observed population, is the TB cases in the standard population. Thus, the overall crude rate of TB cases is given by:and the overall number of expected TB cases is defined by:Our first space-time model formulations is based on the framework developed by Bernardineli et al.,23 where the linear predictor is:
It follows that the Poisson mean is
and logarithm of the mean is given by:These formulations suggest that each spatial unit has its own time trend with a spatial intercept and a slope . This model assumes a linear time trend in each spatial unit. The parameters to be estimated are and the hyper-parameters .
Adjusting for risk factors of TB cases detection, the model 6 can be written as model 7. Now the parameters to be estimated are and the hyper-parameters are .
It is known that if the region-specific trend is less steep than the mean trend. On the other hand, implies that the region-specific trend is steeper than the mean trend. Further,
The second space-time model is based on Waller et al.30 dynamic non-parametric formulation on the linear predictor:
The quantifies temporal-structure effect and it is modeled using a random walk through a neighboring structure16 defined as:
Finally is specified by means of a Gaussian exchangeable prior: . Finally is specified by means of a Gaussian exchangeable prior: .
The third space-time Model 10 is an extension of Model 9 that enables a space-time interaction in order to explain the difference in the time trend of TB cases. It is expressed as follows:
In this model, and were estimated, where is interaction between and The model assumes that there is no interaction between and hence, Incorporating covariates into Model 10, yields Model 11:
Hence, and For the interaction term , it is assumed that there is spatial or temporal structure on the interaction, then .37 In this study, all the precision parameters are assumed to follow the gamma distribution.16
In this section, the TB data has been analysed with the hierarchical space and space-time models.
Moreover, accuracy experiments for the space-time models using the Deviance Information Criterion (DIC) developed by Spiegelhalter was performed, in order to ascertain the most accurate model for predictive studies. In the discussion, only results obtained from significant predictors are reported and discussed. Further, in the analysis, a risk value higher than 1 is classified as high risk while risk lower than 1 is classified as low risk. Risk is classified as normal if it has a value of 1.
Furthermore, the space-time models discussed, involve the classical parametric framework (7) (presented by L. Bernardinelli et al.(1995)23), the dynamic nonparametric framework presented by L. Knorr-Held et al. (2000)37 for the linear predictor Equations (9), and Model (10). Model (10) (is an extension of Model (9)) to incorporate interactions between space and time. This enables us to explain the differences in the time trend of the TB cases across the regions. Equation (7) is refered to as Model I, Equation (9) as Model II and Equation (10) as Model III. Results are reported for experiments that involve adjustment and non-adjustment of covariates.
In this section, BYM without covariate adjustments (defined as ) was implemented. The posterior estimates are presented in Table 1. The maps of the posterior mean for the region-specific relative risks of presented in Figure 6a,b are used to identify regions with high risk. High risk is visualized by computing for details see M. Blangiardo et al.16 Figure 6a shows the five of the ten regions that have high risk of TB cases. The risk profile for TB in Ghana are shown in the figure-legends. In the regional map of Ghana, the darker the region the higher the risk and vice versa. It can be observed that Upper East and Upper West Regions have the highest risk (with values in the range 1.8-3.4), followed by Volta, Western and Central Regions with risk between 1.1-1.8. The rest of the regions have low risk of TB detection, specifically, Northern and Ashanti Regions have the lowest risk (with values in the range 0.3-0.6), followed by Greater Accra and Brong Ahafo Regions with values between 0.6-0.9. The Eastern Region has normal risk (with a value in the range 1-1.1).
| Estimate | sd | 25% | 50% | 95% CI | |
|---|---|---|---|---|---|
| Fixed effects | |||||
| Random effects | |||||
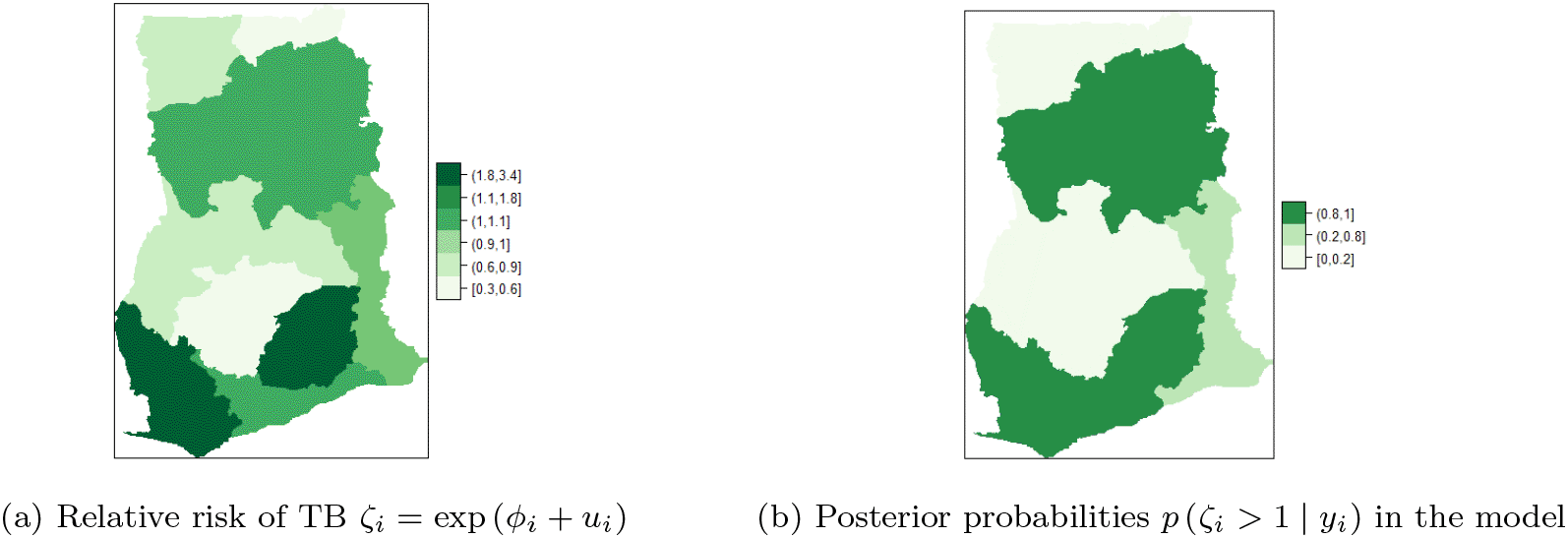
Figure 6b shows that Upper East, Upper West, Volta and Central regions have the highest posterior relative risk (0.8-1) of TB detection. The regions have similar risks, however, none of them has a risk higher than the national risk 1. Moreover, low relative risk (0-0.2) of TB detection is observed in the Northern, Brong Ahafo, Ashanti, and Greater Accra regions, followed by Eastern and Western regions that have relative risk values in the range (0.2-0.8).
The results in Table 1 confirm the similarity or clustering of risk in the neighboring regions. This is indicated by the low variability captured by the precision of the spatial structure . The estimate of the posterior marginal variance to capture the amount of variability explained by the spatial structure was evaluated. The spatial structure effect empirically using this formula was estimated:
The estimated proportion of spatial structure variance is approximately implying that only of the variability is explained by the spatial structure. It further explains the remaining higher variability captured by the unstructured random effect component of the BYM. The precision of the unstructured component of the BYM model indicates that the risk is heterogeneous among regions. The exponent of the posterior mean (overall mean effect) shows that there is approximately a 3-fold increase in TB infections rate across the 10 regions of Ghana. The corresponding 95% credible interval ranges from to .
This section represents the results obtained from experiments conducted with seven (7) covariates adjustments of the BYM:
Among the baseline predictors stated in Section b, the significant predictors for TB cases in Ghana that yield accurate models include: HIV prevalence, TB cure rate, TB success rate, proportion of people with knowledge about TB, proportion of those who know that TB is airborne, proportion in high income group and literacy. Table 2 presents posterior estimates of the overall mean, fixed effects (i.e. ) as well as random effects (i.e. and ) for the unstructured and structured components of the BYM. The maps of the posterior mean for each region’s relative risk (i.e. ) are presented in Figure 7a and b. The risk can be visualized by computing .16
| Estimate | Sd | 25% | 50% | 95% | |
|---|---|---|---|---|---|
| Fixed effects | |||||
| 2653723 | |||||
| Random effects | |||||

It can be observed in Figure 7a that Upper East, Brong Ahafo and Western Regions have high and similar detection risks ranging from 1.1-1.8. The adjusted risk (i.e. risk with the covariates in Figure 7a) is less than the unadjusted risk (risk without covariates in Figure 6a). Upper East Region is still among the regions with high risk of TB detection after covariates adjustment. Upper West Region does not belong to the high risk class while Brong Ahafo and Western Regions have moved to the normal risk class after the covariate adjustments. Greater Accra and Central Regions are the second highest in the high risk class, with risk ranging from 1-1.1. Upper West, Northern, Volta, and Eastern Regions are in the normal risk class, with risk ranging from 0.9-1. Further, Ashanti Region is in the low risk class (with values in the range 0.6-0.9) after covariate adjustments. In Figure 7b, it can be observed that Brong Ahafo and Western Regions have the highest and similar relative risk (0.8-1), while Ashanti Regions has the lowest relative risk (0.0-0.2). The rest of the regions have similar relative risks ranging from 0.2-0.8.
Table 2 presents the posterior estimates of fixed and random effects of the BYM with covariate adjustments. It can be observed that TB cure rate increases the risk of TB cases by approximately 8% This observation implies that as more cases are detected, more cases are cured and hence TB cases should in general decrease over time. This explains why TB success rate leads to 14% reduction in detection rates. The results also revealed that knowledge about TB significantly increases TB detection by approximately 5% This behaviour is expected because, as people become aware of TB, preventive measures are taken. High income is associated with 5% reduction in TB cases while literacy is associated with 12% increase in cases. High income increases the use of health facilities and testing for TB, thus, leading to a reduction of TB cases. HIV prevalence lead to 55% reduction in cases.
After adjusting the covariates, similarity/clustering of risk between neighboring regions, (see Figure 7) with low variability of risk among the regions was observed. This observation is captured by the precision of the spatial structure in Table 2. Heterogeneity of risk across the regions has reduced after the covariates adjustment.
Furthermore, the posterior marginal variance to determine the amount of variability explained by the spatial structure using the formulations in Equation (12) was evaluated. The results showed that the estimated proportion of spatial structure variance is approximately 5%. This implies that only 5% of the variability is explained by the spatial structure. Much of the variability remaining is captured by the unstructured random effect component of the BYM. The precision of the unstructured component of the BYM indicates that risk is heterogeneous across regions.
The posterior mean of the exponent (overall mean effect) gives an indication that there is approximately 9-fold increase in TB infections rate across the 10 regions in Ghana.
Table 3 presents the DIC, mean deviance and effective number of parameters components for the three space-time models. The performance indicators show that the classical parametric formulation (see Equation (7) introduced by Bernardinelli et al.23 is the most accurate among the three space-time models. Hence, further discussion will include only the results from that model.
The results in Table 4 show that there is about increase in risk of TB detection across the 10 regions of Ghana. However, this increase is statistically not significant at 5% significance level. As observed in the BYM, TB cases do not significantly increase with time. The precision parameter shows some level of variability in the risk of TB among the regions, while there is clustering of risk between neighboring regions exhibited by the high precision parameter for the spatial structure. High precision characterized by indicates low variability associated with This further indicates that there is less interaction between space and time, as well as global trend and areas-specific trend Hence, the area-specific trend is less remarked than the mean trend.
| Estimate | sd | 25% | 50% | 95% CI | |
|---|---|---|---|---|---|
| Fixed effects | |||||
| Random effects | |||||
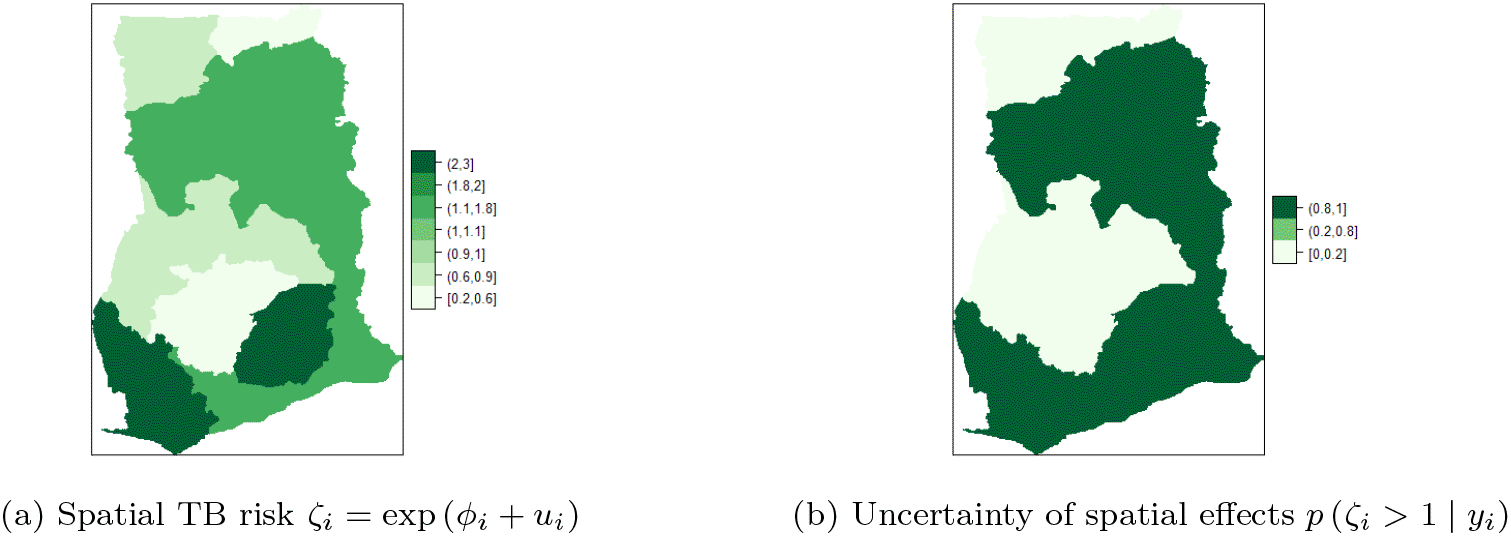
Figure 8a shows the map of spatial trend for the 10 regions and Figure 8b is the map of the posterior probabilities defined as Figure 8a shows that there is high risk of TB in the Eastern and Western regions. There is high risk (i.e. in the range 1.1-1.8) and clustering among the neighboring regions; Volta, Northern, Central, and Greater Accra regions. Upper East and Ashanti regions have the lowest risk (0.2,0.6) followed by Upper West and Brong Ahafo (0.6-0.9). The results account for the high variability captured by the unstructured component and the low variability captured by the structured component of the area-specific trend. The posterior probabilities in Figure 8b indicate low risk (below 1) and relatively low level of associated uncertainty.16 The time effect is not significant and there is no significant interaction between space and time. This observation accounts for the inaccuracy of Model II (i.e. Equation (10)) and Model III (i.e. Equation (9)) for the TB data.
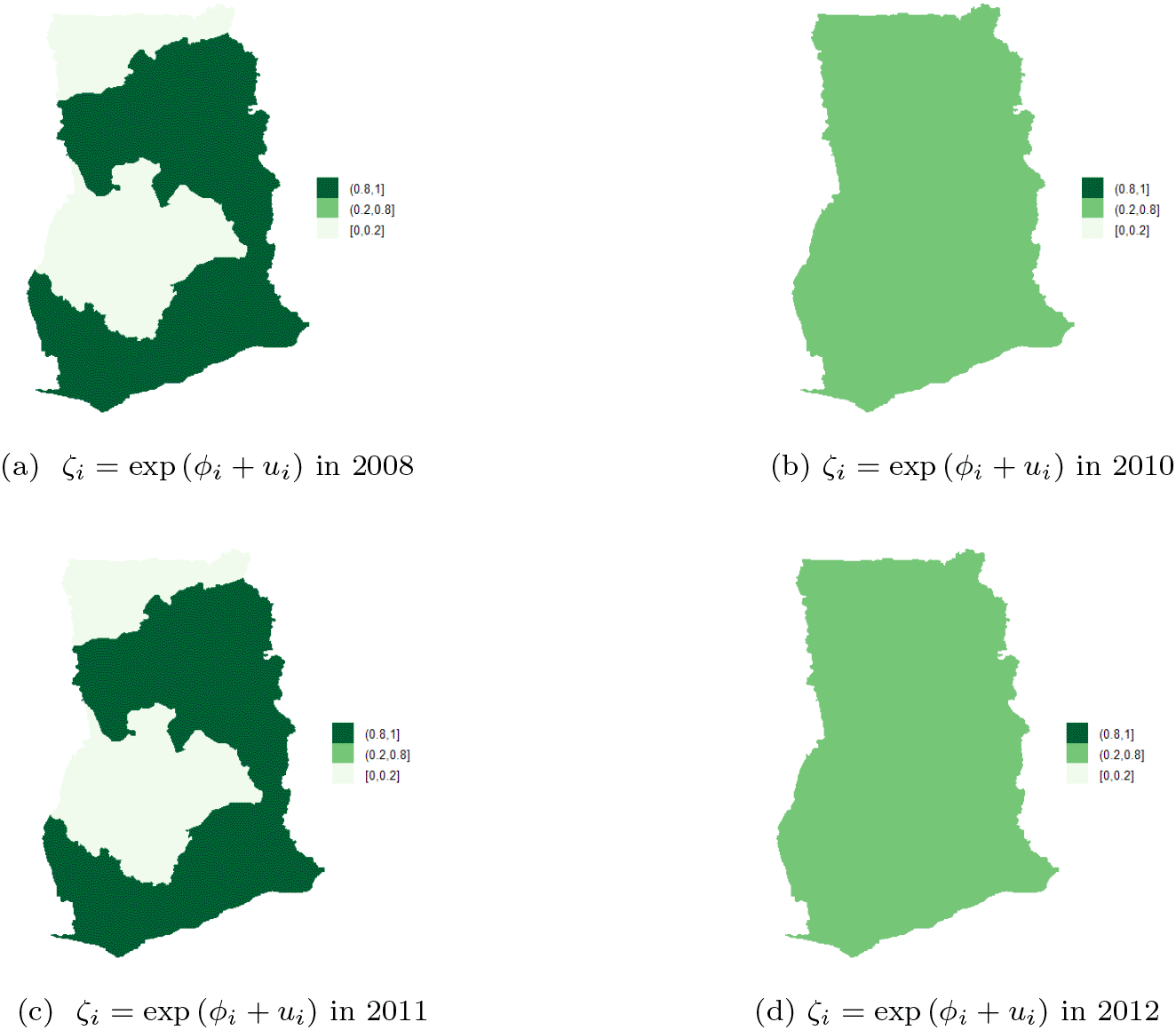
Next, the posterior probabilities of each region by year was evaluated. The results indicate that time has no significant effect on the space-time pattern of TB cases as shown in Figure 9a-d. The risk of TB infection is almost the same across the 10 regions. Figure 9a shows that there is relatively high risks (in the range 0.8-1) in the Northern, Volta, Eastern, Western, Central, and Greater Accra regions, while Upper East, Upper West, Brong Ahafo, and Ashanti regions have low relative risk (i.e. between 0-0.2). The results exhibit clear clustering of risk among neighboring regions associated with low variability or uncertainty. In the year 2010, all the regions had risks in the range 0.2-0.8, see Figure 9b. Similar observations can be made in year 2011 and the rest of the years shown in the figure. The results imply that it is sufficient to use only spatial models to estimate the risk of TB across the 10 regions of Ghana.
It can be observed in Table 5, that Model I of the space-time models has the lowest DIC, mean deviance and a high number of effective parameters . The indicators show that the classical parametric formulation of Ref. 23 (see Equation 7) is still the most accurate model among the three space-time models, for the TB data.
| Model | DIC | ||
|---|---|---|---|
| Model I | |||
| Model II | |||
| Model III |
Table 6 shows negligible risk of TB across the 10 regions of Ghana. Similarly, the TB cases over time is statistically insignificant as observed previously. The precision parameter indicates very low variability in the risk of TB detection among the regions and much clustering of risk between neighboring regions exhibited by high precision parameter values for the spatial structure. High precision characterized by indicates lower variability associated with This further indicates that there is no significant interaction between space and time as well as global trend and areas-specific trend Hence, the area-specific trend is less remarked than the mean trend.
| Estimate | sd | 25% | 50% | 95% CI | |
|---|---|---|---|---|---|
| Fixed effects | |||||
| Random effects | |||||
The results in Table 6 also revealed that TB success rate significantly increases TB cases by 11%. Also, knowledge about TB significantly reduces TB cases by approximately 2%, while increasing TB cure rate, significantly reduces detection by 8%. Awareness that TB is airborne increases TB detection by approximately 25%. That is, more people are willing to participate in TB testing to know their status leading to more case detections. It was also observed that HIV prevalence and high income significantly increases TB detection by 27% and approximately 4%, respectively. Literacy significantly reduces the risk of TB detection by approximately 14%.
Figure 10a shows the spatial trend for the 10 regions and Figure 10b shows the posterior probabilities defined by Figure 10a shows that TB cases risk is higher and clustered in the Volta, Brong Ahafo, Ashanti, Eastern, Western and Greater Accra regions (ranging from 1-1.1) while there is low risk in the Upper East, Upper West, Northern, and Central regions. Thus, there is high and similarity/clustering of risks among neighboring regions. After covariate adjustments, there is low risk in the Upper East, Upper West, Northern and Central regions. These observations account for the low variability captured by both the unstructured and structured components of the area-specific trend.
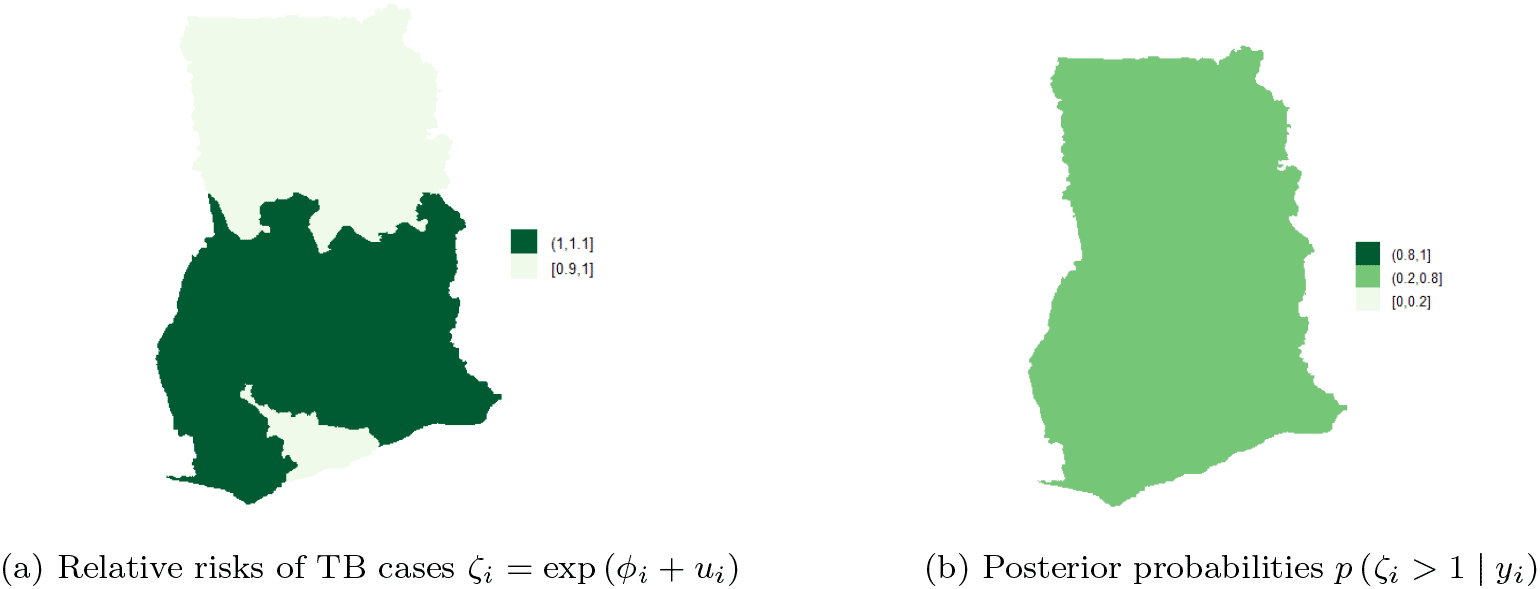
Figure 10b shows the posterior probabilities, it can be observed that all the regions have low relative risks (i.e. in the interval 0.2-0.8) after adjusting the covariates. Since the time effect is negligible, there is no interaction between space and time. This observation accounts for the inaccuracy of Model II (10) and Model III (9) for the TB data. The posterior probabilities of the region after covariate adjustments (in the period 2008-2017), showed that the risks of TB across the 10 regions are the same/clustered in the range 0.2-0.8 (this observation is the same as the one made in Figure 10b).
The spatial model used is based on the BYM24 formulation. The results from this model (without covariate adjustments) showed that hot-spots of TB cases are located in five regions, i.e.; Upper East, Upper West, Volta, Western, and Central regions. Northern, Ashanti, Greater Accra, Brong Ahafo, Eastern and Western regions have low risk of TB detections. Another notable finding is the clustering of risk between neighbouring regions (i.e. nearby regions have similar risk). The results also revealed that the unstructured component of BYM (that explains variability of risk among the regions) is significant because the spatial structure only explains a small proportion of risk variability among regions. Additionally, after covariate adjustments, the number of high risk regions reduced from five to three (i.e. Upper East, Brong Ahafo and Western regions). The posterior probabilities in the BYM (with and without covariate adjustments) showed that there is clustering of risk between regions.
Further, this study also revealed that TB cure rate, TB success rate, knowledge about TB, awareness that TB is airborne, HIV prevalence, percentage of literacy, high income are important predictors of TB detection across the 10 regions of Ghana. Heterogeneity/variability of the risk reduced across the regions after covariate adjustments. The reduction in heterogeneity is due to low variance of the unstructured component and clustering due to low variability of the spatial or structured component of the BYM. Clustering of risk is evident from Figure 7, where almost all the regions have similar risk.
Furthermore, the study showed that the classical parametric formulation (i.e. Equation (7) called Model I) is the most accurate space-time model for the TB data. This model yields the lowest DIC, lowest mean deviation and highest effective number of parameters with or without covariate adjustments. Hence, it was selected for further experiments. Results from this model show that the risk of TB does not significantly increase over time. There is some level of heterogeneity in risk over time indicated by the precision of the unstructured component. There is relatively high level of clustering among neighboring regions as well. The results shows that there is less interaction of risk between space and time, as well as global trend and area-specific trend. Hence, the area-specific trend is less remarked than the mean trend.
Clustering of risk is evident per the relative risk profile in Figure 8. The space-time model classifies Eastern, Western, Volta, Northern, Central and Greater Accra regions as the hot-spots of the disease over time. Three of the regions (i.e. Volta, Western and Central regions) are classified as high risk regions, by the BYM without covariate adjustments and the Model I without covariate adjustments. The posterior probability in Figure 8b clearly shows clustering of risk and low level of associated uncertainty. The posterior probabilities over the study period are shown in Figure 9a-d. The figures show that the risk of TB does not change over time.
Moreover, after covariate adjustments, statistical inferences remained unchanged and the classical parametric formulation (in Equation 7) remains the most accurate model for the TB data. The posterior summary statistics in Table 6 showed negligible risk of TB across the 10 regions. Precisions of both the unstructured and structured components indicate clustering of risk among the regions. Therefore, all the regions exhibit similar risk. There is no significant space-time interaction due to low variability captured by The results identify the risk factors under the BYM as significant predictors of TB detection.
Therefore, our study has characterized the spatio-temporal pattern of TB in Ghana, using hierarchical space-time models. The key findings include the identification of hot-spots, significant baseline predictors, heterogeneity/clustering of risk across regions and insignificant dependence of TB risk on time.
Source data The data used in this study can be found in the following links: https://open.africa/dataset/4176f749-cfa8-4e32-9418-86cef78f9db6/resource/0bcf9b54-3e35-4543-95cd-fd4de953edff/download/factsfigures_2018.pdf, https://www.who.int/teams/global-tuberculosis-programme/data https://www.stoptb.org/static_pages/GHA_Dashboard.html.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)