Keywords
phasor measurement unit, missing data, data recovery, smart grid, interpolation, cubic spline, data quality, data pre-processing
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research Synergy Foundation gateway.
phasor measurement unit, missing data, data recovery, smart grid, interpolation, cubic spline, data quality, data pre-processing
The worldwide growing power systems highlight the need for better monitoring and control mechanisms to avoid major blackouts. Smart grids are intelligent systems that facilitate the development of communication, network, and computing technologies, protocols, and standards to integrate power system elements for two-way communication. This time-synchronized high-precision measurement device that is also known as a synchrophasor or Phasor Measurement Unit (PMU), gives clear information on the working of the entire grid. The PMU is used to monitor and control the power grid. It can help in providing real-time measurements by eliminating adverse conditions like blackouts. These combined characteristics of data availability, timeliness, and communication network contribute to the better performance of the PMU system. Although the role, impact,1 architecture, technology,2 applications, functionality, standards, and evolution of PMU (timing, measurement, communication, and data storage) have been released since 1995, the North American Synchro Phasor Initiative (NASPI) has highlighted the importance of data quality.3 Data quality issues, their potential causes, and consequences are elaborated.4–6 Generally, incomplete or missing data might affect the functionality of the entire system.7 Hence, a way to handle missing values in PMU is mandatory for the effective functioning of the entire grid system.
In this paper, a modified recurrent equation-based method termed the Alpha Method (AM) for PMU missing data problem is proposed. The results are compared with the tri-diagonal matrix-based conventional cubic spline interpolation for the spline coefficients which is also termed the Linear Equations Method (LEM).
The need to fill in the missing values in PMU and potential causes have been reviewed.5–7 These works imply the need for missing data recovery techniques for PMU data to enhance the accuracy of the decision-making process and show the data quality and security risks associated with the missing data in PMU. One of the popular approaches is the matrix completion (MC) based on missing data recovery.8–12 The MC is the most exploited technique, however, a few of these were only theoretical approaches and a few approaches were only tested with simulated data.
Interpolation-based missing data recovery techniques13–15 propose a reconstruction of missing values by a spatial interpolation or spatio-temporal interpolation of the values. Yet they require historical data of the same channel’s or time’s data for the interpolation. A few of the advanced/hybrid approaches16,17 like k-nearest-neighbor and recurrent relation-based interpolations are not yet applied over the PMU data.
Missing data is a common problem in all fields of study; hence a variety of solutions are found to be effective based on the data pattern, data processing model, and data quality needs. However, adopting any conventional techniques available for treating missing values can get complex especially when solving the high precision and volume of PMU data.15 Therefore, there is a need for a missing data recovery method for PMU data. NASPI presents a variety of data requirements, attributes, and data quality problems for both static data and real-time data. There is a need for designing an effective data recovery method to work without the need for historical data processing and training.3 So, a data-driven recovery technique capable of recovering missing entries with available or observed data is much needed. Moreover, the technique should not get complex and time-consuming when the size of the data grows.
Cubic spline interpolation is a widely used polynomial interpolation method for functions of one variable. Let be a function from . It is assumed that the value of is known only at Piecewise cubic spline interpolation is the problem of finding the , and coefficients of the cubic polynomials written in the form:
Where can take any value between and . That is,
Let the first-order derivative of equation (1) be:
The first-order derivative at for values of will be
And the second-order derivative be:
The second-order derivative at for values of will be:
For a smooth fit between the adjacent pieces, the cubic spline interpolation requires that the following conditions hold:
If = and if is equal for all values, following Revesz,17 the relation between coefficients and can be resolved:
Equation (6) represents a system of linear equations for the unknowns for . As the values of are known, the value of can be found by solving the tri-diagonal matrix-vector equation. While there are n+1 numbers of constants, equation (6) yields only (n-2) equations. Based on the nature or type of spline assumed two more equations representing the boundary conditions of the spline. In general, two types of splines may be considered: natural cubic spline and clamped cubic spline.
For natural cubic spline interpolation, the following boundary conditions are assumed: . That is, the second derivatives of the splines at the endpoints are assumed to be zero. Based on equation (4), a system of (N+1) linear equations of (N+1) variables can be formulated as:
For clamped cubic spline interpolation the following boundary conditions are assumed: ) and ), where the derivatives ) and ), are known constants. Thus, based on the boundary conditions assumed both natural and cubic splines result in n+1 system of linear equations. The resulting system of n+1 linear equations can be used to get unique solutions by any of the standard methods for solving a system of linear equations.
Once the values of are obtained, using equations (5) and (6) respectively, the values of coefficients and can also be found. Similarly, under clamped spline interpolation,
Revesz,17 chose boundary conditions that need to solve the tri-diagonal system given in equation (6) where rational variables rational constants, r is a non-zero rational constant and A is:
The first row of the new matrix in (6) is shown to be equivalent to the first row of the clamped b matrix is
The chosen boundary conditions are such that the first row of the new matrix was the same as that of clamped cubic spline and while that of the last row was that of the natural cubic spline fixing the value of as 0.
Based on the above, the closed form of solution for can be given as:
The above equation solves no matter exactly what the initial values for . This leads to a faster evaluation of the cubic spline than solving a tri-diagonal system. The major advantage of the method is when new measurements are added to the system. While conventional tri-diagonal matrix-based algorithm requires a complete redo of the entire computation, equation (14) leads to a faster update for each i ≤ n only with the addition of the term:
The system of linear equations given in equation (7), in general, is solved by the standard solution of linear equations in the matrix form Alternatively, it could be solved for n variables by the recurrence relations given equations (16) and (17). The two methods, the first using the tri-diagonal matrix-based solution for the spline coefficients is termed the Linear Equations Method (LEM) and the second one using recurrence relations is termed the Alpha Method (AM). The algorithmic procedure for LEM and AM are given below.
Step 1: Given the initial vector with missing values, separate them into two sets of vectors, the observed values vector and the missing values vector , having sizes of NO and NM, respectively, such that NO+NM=N.
Step 2: vector at values of the (NO-1) splines shall be the coefficient vector.
Step 3: Using, generate the RHS vector E given in equation (11).
Step 4: Generate a square coefficient matrix A as given in equation (11)
Step 5: Solve for the vector is given in (11), using the relation Ac=E
Step 6: Applying in equations compute the and coefficient vectors for n-2 points of the ,
Step 7: Using the values of,, , missing values can be found by the equation (1) re-written as:
Where x represents the missing positions, between and of spline i.
Step 1: Given the initial vector with missing values, separate them into two sets of vectors, the observed values vector and the missing values vector , having sizes of NO and NM, respectively, such that NO+NM=N.
Step 2: The vector at values of the (NO-1) splines are the coefficient vector.
Step 3: Using, generate the RHS vector E given in equation (11).
Step 4: Set given in equation (11) calculate the alpha vector using the relation.
for values ranging from 1 to NO-1
Step 5: Set and solve for values using the relation.
Step 6: Applying in equations compute the and coefficient vectors for n-2 points of the ,
Step 7: Using the values of,, , missing values can also be found using equation (18), re-written here again for convenience:
Where x represents the missing positions, between and of spline i.
The modifications are as follows: In the AM method rather than computing E, alpha vectors and coefficients for the full range of NO-1 data points only the RHS, E vector, was calculated for the full range of NO-1 data points, while alpha vector and were calculated only for data elements, where is the missing data element. For the imputation of the element, only the vector for all NO-1 data points, vector and vectors for and and coefficients were essential for the calculation missing element and its imputation.
In addition, using the AM, an effective procedure was demonstrated for the computation of the following cases: (i) missing first and the last element of the data vector, (ii) missing multiple data points at the beginning and the end, and (iii) missing multiple elements anywhere in the data vector. That is in equation (18), when the current values of A [i] are replaced either with A [N-1] or A [i-1] based on the position of missing edge values or continuous values the ToC and RMSE values have improved significantly.
A comparison between LEM and AM methods is shown here for the imputation of one-min real PMU system data having a size of 1490 data points for each of the 25 heterogeneous variables obtained from five different PMUs. Since our data does not have any missing values we artificially introduced the missing values of 10%, 20%, 30% in random.
A sample of one minute PMU data for five PMUs’ was used in the study.18 One minute of PMU data with 10%, 20%, 30% missing data respectively for five PMUs were evaluated.
When the AM method was employed, the average root mean squared error (RMSE) values were 0.5968, 0.9448, and 1.2445 for 10%, 20%, and 30% of missing PMU data respectively. This can be seen in Figure 1. Moreover, for the same performance, the AM method showed significant improvements in its time of calculation (ToC) as shown in Figure 2. The average ToCs for the proposed AM method were 2.132, 1.9634, and 1.738s when recovering 10%, 20%, and 30% of its missing data. By comparison, LEM had ToC values of 32.7679, 33.4482, and 36.7988s for 10%, 20%, and 30% of its missing data, respectively. The proposed method reduced the ToC by a factor of approximately 10 times.
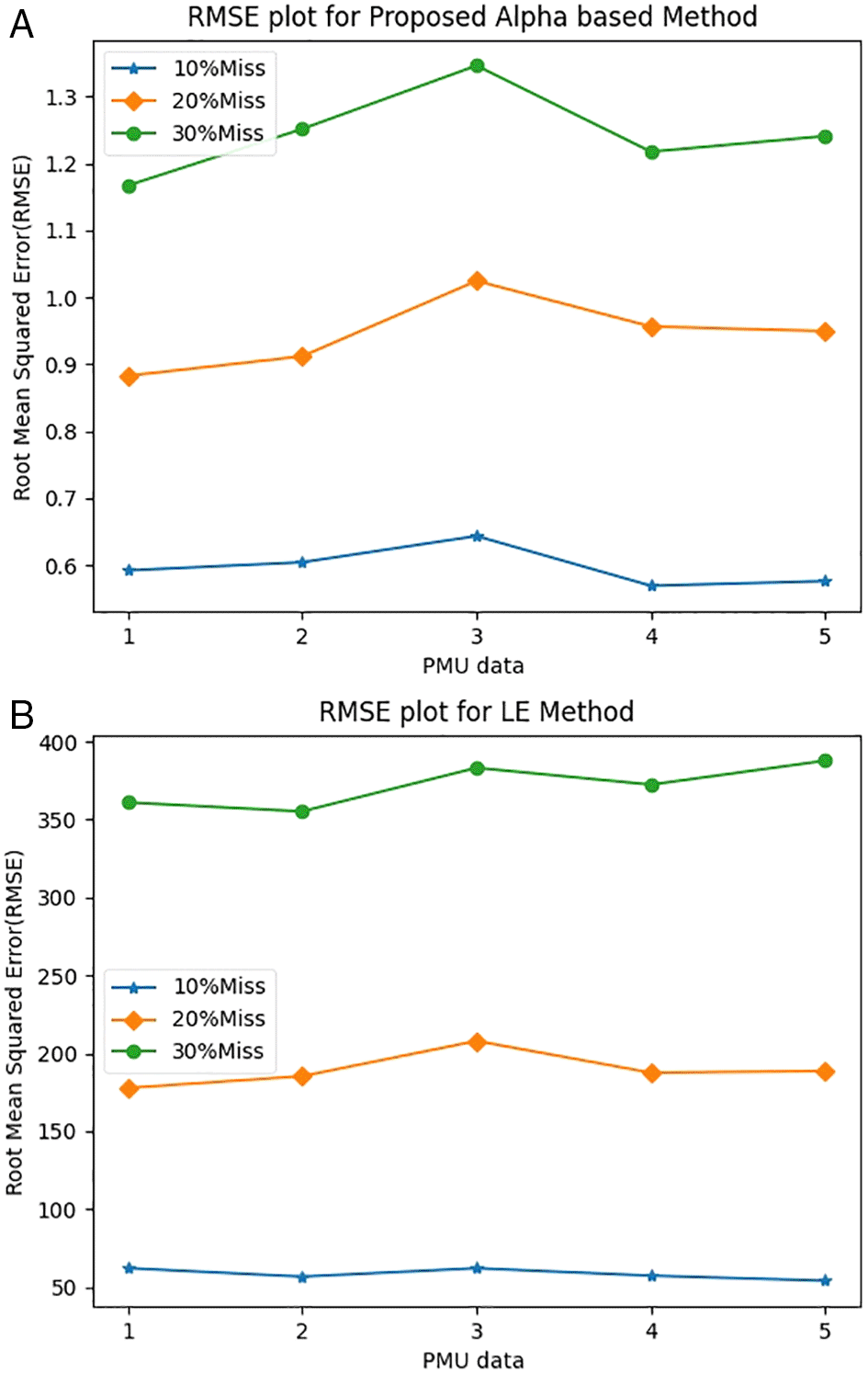
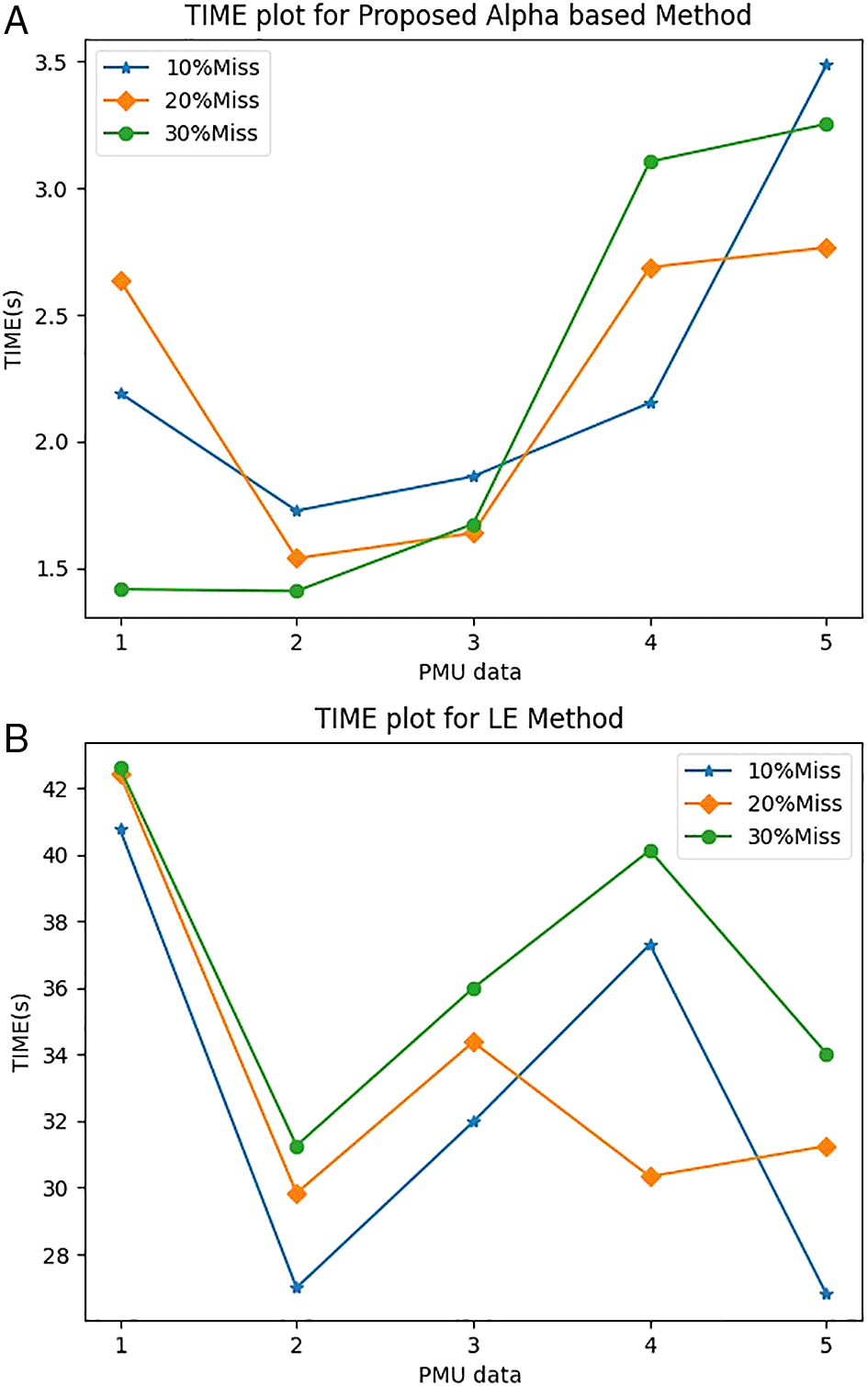
In this study, the proposed AM method was compared with the LEM technique. However, because of the proliferation of the data, there is a need for customization of this technique to handle a high volume of data to reduce computational time and power. In the proposed method, the approaches demonstrated a reduced computational effort and time of calculation for solving the coefficient vectors. This study has made the following contributions: (i) the recurrent relation-based alpha method has been effectively employed in the imputation of PMU data and its advantages are demonstrated as an effective and efficient alternative to the conventional technique, and (ii) an effective procedure for handling special cases (edge, continuous values) is shown, which has not been addressed clearly in other methods. The proposed method has proven effective, and it only requires 10% effort in comparison to the LEM. Future research will focus on the application of the modified recurrent method in the analysis of real-time or stream PMU data.
Harvard Dataverse: Underlying data for ‘Modified recurrent equation-based cubic spline interpolation for missing data recovery in phasor measurement unit (PMU)’, ‘PMU data’, https://doi.org/10.7910/DVN/Y2LLJJ.18
This project contains the following underlying data:
- Data file: pmu1-1m-10.tab – One minute of data from PMU1 with 10% missing data
- Data file: pmu1-1m-20.tab – One minute of data from PMU1 with 20% missing data
- Data file: pmu1-1m-30.tab – One minute of data from PMU1 with 30% missing data
- Data file: pmu2-1m-10.tab – One minute of data from PMU2 with 10% missing data
- Data file: pmu2-1m-20.tab – One minute of data from PMU2 with 20% missing data
- Data file: pmu2-1m-30.tab – One minute of data from PMU2 with 30% missing data
- Data file: pmu3-1m-10.tab – One minute of data from PMU3 with 10% missing data
- Data file: pmu3-1m-20.tab – One minute of data from PMU3 with 20% missing data
- Data file: pmu3-1m-30.tab – One minute of data from PMU3 with 30% missing data
- Data file: pmu4-1m-10.tab – One minute of data from PMU4 with 10% missing data
- Data file: pmu4-1m-20.tab – One minute of data from PMU4 with 20% missing data
- Data file: pmu4-1m-30.tab – One minute of data from PMU4 with 30% missing data
- Data file: pmu5-1m-10.tab – One minute of data from PMU5 with 10% missing data
- Data file: pmu5-1m-20.tab – One minute of data from PMU5 with 20% missing data
- Data file: pmu5-1m-30.tab – One minute of data from PMU5 with 30% missing data
- README.txt
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)