Keywords
TITAN, permutations, thresholds, community composition
This article is included in the RPackage gateway.
This article is included in the Bioinformatics gateway.
TITAN, permutations, thresholds, community composition
Community ecologists are interested in understanding the structure and interactions of multiple species in a given area or habitat type and many are interested in understanding how communities respond to changing environmental or anthropogenic gradients. One method a community ecologist can use for understanding or detecting changes in ecological thresholds across environmental gradients is Taxa Indicator Threshold ANalysis (TITAN) (Baker and King 2010). TITAN is useful for determining the impacts of environmental or anthropogenic gradients in community ecology studies because it both analyzes each individual taxa response and the community as a whole in the same analysis. Additionally, unlike other community ecology methods (Gauch and Gauch 1982), TITAN separates the taxa that increase from those that decrease across an environmental gradient to provide a more complete picture of the community response to that gradient.
As an overview, TITAN methods use change point (King and Richardson 2003; Qian, King, and Richardson 2003) and indicator species analysis (Dufrêne and Legendre 1997) to determine the point along an environmental gradient, such as percent impervious cover (IC) in the upstream watershed area, where individual taxa have the largest change in occurrence frequency and abundance, and then uses the individual taxa results to determine synchronous areas of taxa change at the community level (Baker and King 2010, 2013). In TITAN, individual taxa change points are determined by calculating the taxa’s indicator score (IndVal) along the environmental gradient and assigning the taxa as either increasing (z+) or declining (z-) in response to an increase in the environmental gradient variable. Permutations of data in TITAN runs are used to calculate the likelihood of random data generating a larger IndVal score than the observed data and to standardize the taxa response to the environmental gradient by calculating the taxa z-scores using permuted distributions. Taxa z-scores are added together for increasing (z+) and declining (z-) taxa along the environmental gradient and the point with the highest sum (z-) and sum (z+) score is defined as the community change point. Next, bootstrapping of observed data is used to calculate percentiles around the community and individual taxa z-scores, and to determine if individual taxon responses are pure and reliable. Purity is a measure of the proportion of bootstrap results that match the taxa’s observed response group as either increasing or declining. Reliability is the proportion of bootstraps with a low probability (p < 0.05) of random data having a higher IndVal score than the bootstrapped observed data. Community change points are also calculated after selecting (filtering) only the taxa that exceeded purity and reliability requirements for the increasing (fsum(z+)) and declining (fsum(z-)) change points, where f refers to filtered results. Narrow peaks around the maximum sum(z) or fsum(z) (filtered) scores indicate areas with synchronous change in individual taxa frequency and abundance and may indicate an ecological threshold along the environmental gradient being evaluated. More information on TITAN methods can be found in Baker and King (2013) or in the TITAN R package, TITAN2.
While TITAN is a powerful tool for community ecologists it requires additional analysis for comparing results from different regions, groups or treatments. Previously, researchers have used non-overlapping confidence intervals for change-points from TITAN output to indicate significant differences between groups (King et al. 2011). However, although non-overlapping confidence intervals can indicate significant differences, overlapping confidence intervals do not necessarily mean the null hypothesis should be accepted (Greenland et al. 2016; Schenker and Gentleman 2001).
We developed a new R package, pTITAN2, as an extension of the existing TITAN2 R package. The goal of pTITAN2 is to enable comparisons of TITAN output between treatments by permuting the observed data between treatments and rerunning TITAN on the permuted data. There are some limitations on the permutations, including (1) a sampling site cannot occur in a category more than once, the same limitation as in the original TITAN runs and (2) the original sample size distribution is maintained. This addresses potential sample size effects and enables comparisons between treatments with different sample sizes more accurately than using non-overlapping confidence intervals. A vignette is provided based on a dataset of macroinvertebrate data from California streams that fall along a gradient of watershed percent impervious cover. We compare change-points among different climate conditions (wet, average, and dry) based on the Palmer Drought Severity Index, which serve as the treatments in this example.
Like TITAN2, pTITAN2 was developed using the R programming language (RRID:SCR_001905). pTITAN2 has been tested on Windows, Mac OS, and Ubuntu on the latest R version (4.1.0 at time of writing) along with select old release (4.0 and 3.6) and development versions via github actions. It is recommended that users are familiar with the TITAN2 package operations before using pTITAN2.
The basic workflow for pTITAN2 is
1. Prepare and import the environmental gradient dataset into R
2. Prepare and import the taxonomic dataset into R
3. Preprocess raw taxonomic data to determine appropriate taxonomic level of resolution (occurrence function)
4. Select columns for the taxon level returned by occurrence function
5. Permute the data across treatment labels to generate list of lists
6. Set up cluster for parallel processing (optional)
7. Run TITAN2 series on original and permuted data sets
8. Analyze probability of exceeding observed difference in changepoint between treatments based on distribution of paired changepoint differences
The first step of pTITAN2 is to provide the data about the environmental gradient in exactly the format as for TITAN, step 1). This can be either a single file or included in the taxonomic data file. Like TITAN2, taxonomic information should be provided as counts or density. Unlike TITAN2, pTITAN2 taxonomic data need to be provided as a code that is eight characters in length and captures four levels of hierarchical taxonomic classification information.
The pTITAN2 package provides four example data sets, two taxonomic and two environmental gradient (Table 1). These data sets are provided as raw csv files and as prepared R datasets.
You can gain access to the csv files via system.file

or get the data sets loaded into your environment via

The CN_06_Mall.csv (Chaparral Region, Treatment = Normal) file contains raw macroinvertebrate density data for 500 possible macroinvertebrate codes for each taxonomic level (class, order, family, genus). The occurrences function selects the codes that should be used for the TITAN2::titan run. The goal is to select the macroinvertebrate code with the most taxonomic detail having at least n occurrences. Only one macroinvertebrate code will be associated with the macroinvertebrate counts. For example, if there are at least five occurrences at the genus level, the family, order, and class codes would not be used in the TITAN2::titan run.
The names within the data set are expected to have the following structure:
• 8 characters in length
• characters 1 and 2 denote the class
• characters 3 and 4 denote the order
• characters 5 and 6 denote the family
• characters 7 and 8 denote the genus.
If no information at a level exists, use “00” to hold the place. For example: A code that is ‘Bi000000’ is the Bivalvia class, while BiVe0000 is the Bivalvia class, Veneroida order. BiVeSh00 is the Bivalvia class, Veneroida order, Sphaeriidae family. BiVeSh01 is a genus within that family.
The first new function provided by pTITAN2 is occurrences. Taking the taxonomic data as an input, the return of occurrences is a data.frame with the taxon, the class, order, family, and genus split out into individual columns, and the count of occurrences within the provided taxonomic data set. TITAN2::titan recommends all taxonomic groups have at least five observations (Baker and King 2010). Thus, occurrences returns only taxa with at least n observations (where n defaults to five). The taxonomic code chosen for analysis should be at the finest possible resolution. For example, if a macroinvertebrate count has at least five occurrences in a genus code, the family, order, and class codes associated with these counts should be removed. Further, if there are too few counts at the genus level, but at least five counts at the family level- the family code would be retained, and the order and class codes would be removed.
The second new function provided by pTITAN2 is the permute function which provides a list of permuted sets of taxa and environmental gradients. This function is used with categorical environmental variables (treatments), such as Wet/Dry or Urban/Rural. The function permutes the treatment labels across the data such that each station has a non-zero probability of being assigned to each treatment, and the stations are unique within each treatment and replication. There are some limitations on the permutations generated by permute. First, a site cannot occur in a category more than once within a permutation. Second, the original sample size distribution is maintained. These limitations address potential sample size effects in TITAN, where treatments with low sample sizes have wide confidence intervals and variable change points compared to treatments with high sample sizes, and enable comparisons between treatments with different sample sizes.
For example, assume we have sites A, B, C, D, and E with treatments 1 and 2 (Table 2). Let Trt0 denote the initial treatment labels for the sites and Trt1, …, Trt4 denote permuted treatment labels. For sites A and C, each permuted set of treatment labels consist of one row for label 1 and one row for label 2. For sites B, D, and E, the initial observations were for treatments 1, 2, and 2 respectively. The balance of these labels is maintained across the permutations.
Trt = treatment.
| site | trt0 | trt1 | trt2 | trt3 | trt4 |
|---|---|---|---|---|---|
| A | 1 | 1 | 2 | 1 | 1 |
| A | 2 | 2 | 1 | 2 | 2 |
| B | 1 | 2 | 2 | 2 | 1 |
| C | 1 | 1 | 2 | 2 | 1 |
| C | 2 | 2 | 1 | 1 | 2 |
| D | 2 | 2 | 2 | 1 | 2 |
| E | 2 | 1 | 1 | 2 | 2 |
After permutations, clusters can be used for parallel processing of TITAN::titan() calls. This can be advantageous as TITAN::titan() calls can be time and computationally expensive. Following the needed TITAN::titan() calls the differences between treatment change points in the observed data can be compared to the differences between treatment change points in the permuted stat to determine if the observed treatment differences are statistically significant.
Here we present an example showing implementation of pTITAN2. We will describe the provided example data sets and how to use the occurrences() and permute() functions.
To reproduce the examples in this vignette you will need to load and attach the pTITAN2 and magrittr namespaces. Other namespaces are used explicitly, loaded (not attached) here.

Example data provided within the pTITAN2 package were based on publicly available stream macroinvertebrate data from California. The data include existing macroinvertebrate abundances from the California Environmental Data Exchange Network (CEDEN, last accessed 30 June 2017), and the Southern California Coastal Water Research Project (SCCWRP) (Fetscher et al. 2014). Samples in the CEDEN dataset were collected between 2000 and 2016, and samples from the SCCWRP dataset were collected between 1997 and 2011. Both data sets were generated using probabilistic sampling designs and are expected to be representative of streams in the region (Figary et al. 2021).
For this example, data were extracted for California’s Chapparal Region (Ode et al. 2011). Sample observations were divided into one of three classes based on the precipitation regime for the sampling year using the Palmer Drought Severity Index (PDSI). The PDSI was determined for each sampling event using monthly PDSI data from the National Oceanic and Atmospheric Administration (NOAA, last accessed 21 December 2016) (RRID:SCR_009427) and climate divisions from the National Climatic Data Center (USGS 2004, last accessed 21 December 2016). We classified all sampling events as dry if PDSI was less than -2 , normal for PDSI between -2 and 2, or wet if PDSI was greater than 2 and these classifications were used as treatments for the permutations. These cutoffs correspond to NOAA categories of moderate drought and unusually wet soil, respectively. The environmental gradient of interest was percent impervious cover in the upstream watershed, in this case defined by the National Land Cover Datasets (NLCD, Homer et al. (2007, 2015), with values interpolated between NLCD years of record (2001, 2006, 2011). Impervious area additions beyond 2011 were estimated as 50% of disturbed area for construction sites as documented in the California Stormwater Multiple Application and Report Tracking System (SMARTS dataset, CalEPA).
For running pTITAN2, the example data sets have a separate csv or pre-built R data sets (Table 1), for the environmental variable, in this case percent impervious cover, and macroinvertebrate density data. The data structure that is shown here is not required for pTITAN2 and instead the environmental variables and treatments could be in a single data file and subdivided as desired. Separate data files are provided for each ‘treatment’ that is explored including data from either drought (dry) or normal precipitation years in the Chaparral region of California.
The taxonomic sets, CD_06_Mall_wID and CN_06_Mall_wID, contains raw macroinvertebrate density data for 500 possible macroinvertebrate codes for each taxonomic level (class, order, family, genus).

The occurrences function selects the codes that should be used for the TITAN2::titan run. The goal is to select the macroinvertebrate code with the most taxonomic detail having at least n occurrences. Only one macroinvertebrate code will be associated with the macroinvertebrate counts. For example, if there are at least five occurrences at the genus level, the family, order, and class codes would not be used in the TITAN2::titan run.
The data are parsed within the occurrences call and return a data.frame with each taxon code split into its components and the frequency of the taxon within the data set. This is an extension for deciding the taxonomic detail to be included in a TITAN run based on minSplt in TITAN. minSplt is minimum number of occurrences that TITAN is looking for taxa to have across the provided sites. The minSplt default in TITAN is five and, as noted by Baker and King (2010), should never drop below three. The default for occurrences is minSplt = n = 5.

Compare these results to working with the raw data. For example purposes we present the summary of the raw data twice, once using tidyverse syntax and once using data.table syntax.

Note that for the Ar class there is only one row with no order, family, or genus level information. Compare to the Bi class where the Un order has no presence counts and is thus not reported in object returned from occurrences. BiVeCa01 has counts and will be reported but BiVeCa00 should not be reported. BiVe0000 and Bi000000 should not be reported as occurrences as preference for the codes with family and genus level information.
The function permute is used to generate a list of permuted sets of taxa and environmental gradients. Function parameters include a list of data frames containing taxa for each treatment group, a list of data frames containing the associated environmental gradient variables, and the site ids. Before we can run permute, we need to import the environmental gradients data.

The return of permute is a list of lists. The first level denotes the treatment; in this example Treatment1 is “dry” and Treatment2 is “normal” – the order of the input data sets. The second level contains the data.frames with environmental and taxonomic data.
The most computationally expensive part of this work is calling TITAN2::titan many, many times. A good option is to use the parallel package to send the task of permuting the data and running TITAN2::titan() to individual processing cores. That is system dependent and left to the end user to implement. For an example of generating the permutations with TITAN2::titan() see the example script provided at:

That file will generate the provided data set permutation_example with ten rows from ten permutations of the example data set.
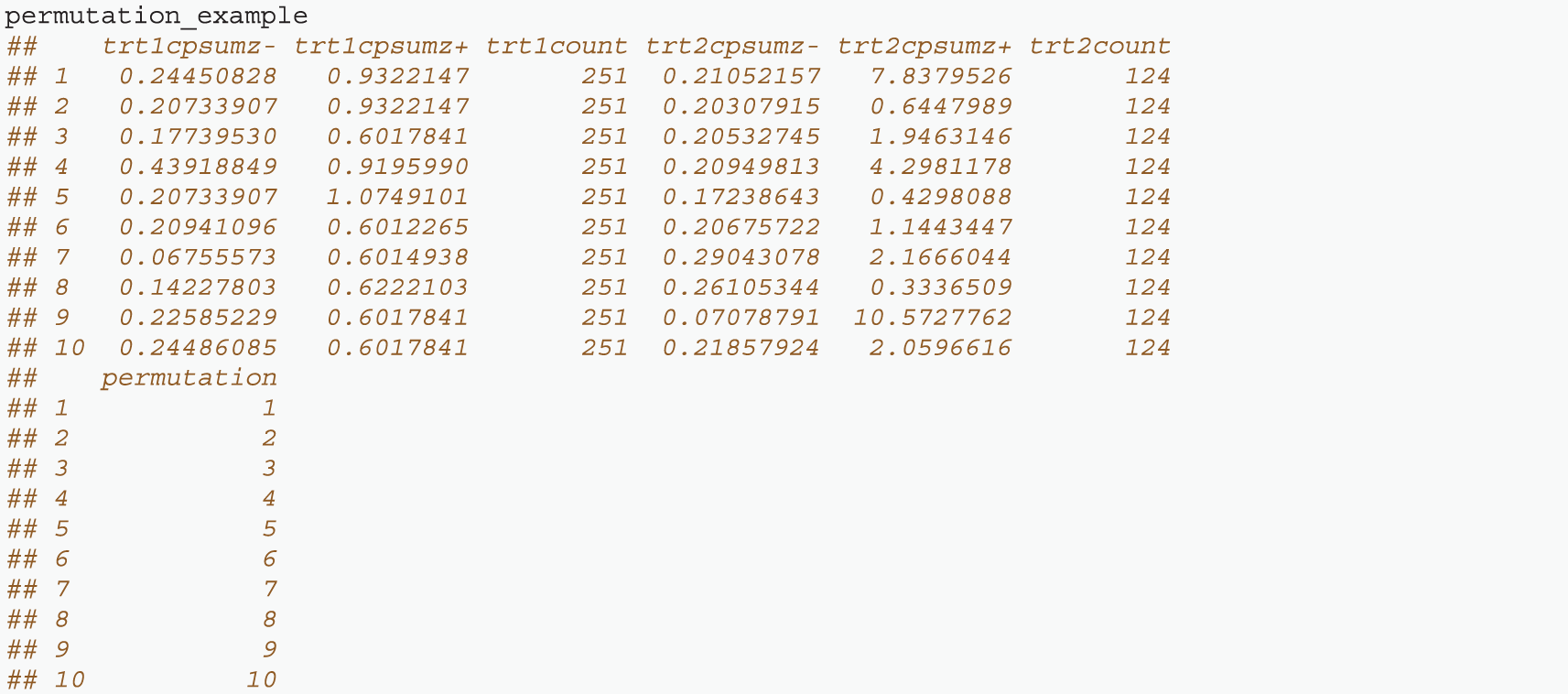
The results are the increasing and decreasing taxa sumz values. In this example only ten permutations are used, and TITAN bootstrapping is limited to five iterations. In an actual analysis these values should be much higher. This process is very computationally intensive and can take hours or days to run depending on the available computing power and the number of bootstraps and permutations used.
If you have three or more treatments and need to permute over them with the condition that no station will be in the same treatment more than once on any particular permutation and that all treatment labels are viable for each station then you can still use the permute function.
The output from the code in section 3.4 can then be used to compare the differences in change-point values for treatments from the observed samples versus the permuted samples. A p-value test can be run on these data to test for statistically significant differences between the treatment effects.


TITAN is used in ecological studies to determine individual taxa and community level change points across an environmental gradient for both taxa that increase with the increasing environmental gradient and taxa that decrease with the increasing environmental gradient (Baker and King 2010). pTITAN2 was developed as an extension of TITAN to enable comparing TITAN results between different treatments, including those with variable sample sizes, by permuting the observed data between the treatments and then rerunning TITAN on the permuted dataset. This allows for statistically determining difference between the treatments without using overlapping confidence intervals, which can be problematic and can lead to accepting the null hypothesis more frequently than statistically necessary.
Zenodo: pTITAN2. https://doi.org/10.5281/zenodo.5894746 (Figary et al. 2021)
This project contains the following underlying data:
- CD_06_Mall_wID.csv (stream macroinvertebrate data from the Chapparal region of California collected during dry years)
- CN_06_Mall_wID.csv (stream macroinvertebrate data from the Chapparal region of California collected during normal precipitation years)
- C_IC_D_06_wID.csv (environmental gradient data (watershed percent imperviousness) for sites in CD_06_Mall_wID.csv)
- C_IC_N_06_wID.csv (environmental gradient data (watershed percent imperviousness) for sites in CN_06_Mall_wID.csv)
Zenodo: pTITAN2. https://doi.org/10.5281/zenodo.5894746 (Figary et al. 2021)
This project contains the following extended data:
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
Source code available from: https://github.com/USEPA/pTITAN2
Archived source code at time of publication: https://doi.org/10.5281/zenodo.5894746
License: Creative Commons Attribution 4.0 International
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)