Keywords
Machine learning, Binary classification, Classifier performance evaluation, Classifier selection optimization, Classifier comparative uniqueness
This article is included in the Artificial Intelligence and Machine Learning gateway.
Machine learning, Binary classification, Classifier performance evaluation, Classifier selection optimization, Classifier comparative uniqueness
We incorporated a new figure, MARS ShineThrough bar chart (MARS charts section), which allows for the prompt visualization of the classifiers’ individual ETP but provides no information about combined classifier target-class discovery efforts. The discussion section was extended to explain the circumstances under which MARS metric usage is ideal and to further emphasize that for applications with different tradeoffs, an inverted MARS evaluation method, aimed at maximizing true negatives, may be preferable.
See the authors' detailed response to the review by Timothy A. Warner
See the authors' detailed response to the review by Samir Chatterjee
Traditionally, binary classification performance has been assessed using a combination of statistical measures derived from the classifier’s confusion matrix (accuracy, precision, recall/sensitivity, specificity, F score), or the classifier’s various confusion matrices, in the case of classifications at different cut-off thresholds (ROC curve, AUC metric). Accuracy is defined as the percentage of correct predictions out of all predictions. Precision is the percentage of predicted positives that are true. Recall (sensitivity) is the percentage of actual positives that are correctly predicted. Specificity is the percentage of actual negatives that are correctly predicted. F scores (various variants like F1, F2) combine precision and recall, weighting each equally, or unequally, to account for different misclassification costs. Finally, for binary classifiers that assign a probability or score to predictions, ROC curves and AUC metrics account for these ranked predictions, allowing for sensitivity and specificity to be observed at different cut-off thresholds. To plot the ROC curve and assess AUC, sensitivity and specificity are measured @k, where k is the number of top-ranked predictions and increases from 1 to the total number of observations in the dataset. Effective classifiers demonstrate a “bulge” in the ROC curves, and concomitant AUC close to 1, indicating that they discover far more true positives in the top-ranked k items, than would be expected in a random selection of k items. Notably, none of these conventional metrics assess the distinctiveness (uniqueness) of the classifier’s predictions, relative to other classifiers. In other words, conventional metrics are unable to assess what percentage of true positives (‘hits’) are found only by the current algorithm but not by alternatives, nor what percentage of false negatives (‘misses’) were missed by the current algorithm but not by alternatives.
Prior to modern-day computational capabilities, the inability to quantify classifier uniqueness had not been seen as a significant limitation, as available computing power did not allow for the use of big-data or complex classifiers, resulting in a low-diversity classifier prediction sample space for most applications. However, within the context of modern-day computational power, which allows for the use of high-volume data to train complex ML classifiers for tasks beyond traditional classification/regression, e.g., discovery-driven tasks, such as flagging potentially hazardous products via online reviews (discussed below); the inability to quantify how many, and what proportion, of a classifier’s correct (and incorrect) predictions are exclusive to that classifier is a significant limitation. Especially considering that complex models may often report equal accuracy (or precision, or recall, or AUC), but have fundamentally different decision boundaries, resulting in a high-diversity prediction sample space – hence, the classifiers may each have the unique ability to identify distinct observations from the target class, and this classifier uniqueness ought to be assessable.
Such assessments about classifier uniqueness have been made possible through the use of novel MARS (Method for Assessing Relative Sensitivity) ShineThrough and MARS Occlusions scores, whose software-level implementation was recently described in Ref. 19. However, since19 focuses solely on the usage and interpretation of the software artifact’s outputs, it does not outline the methodological framework used to generate ShineThrough and Occlusion scores. Thus, in this paper, we present the mathematical foundations behind MARS metrics and their corresponding software artifact. Furthermore, we also provide step-by-step sample calculations that illustrate the inner workings of Shinethrough and Occlusion scores for a simple dataset. Being able to quantitatively assess classifier uniqueness has multiple benefits: better decisions could be made about combining complementary classifiers (vs duplicative classifiers), and improved characterizations could be run of where particular classifiers ‘shine through’ (spot true positives that no other classifiers spot) or ‘occlude’ (hide or miss observations in the target class, by mistakenly classifying those observations as false negatives, when all other classifiers were able to spot those observations as true positives).
As an example of the problematic omission of exclusivity metrics in the evaluation and comparison of classifiers, consider the following cases. Recently,1 evaluated the generalized, binary predictive ability of eight classifiers across ten datasets. ROC curve values for the top-ranked classifiers revealed that Support Vector Machine (SVM), Artificial Neural Network (ANN), and Partial Least Squares Regression (PLS) classifier performances were nearly identical across all datasets.2 compared the performance of several classifiers, namely, Random Forest (RF), Decision Tree (DT), and k-nearest neighbors (kNN), using binary classification schemes for variable stars. Similar to Refs. 1,2’s precision, recall, and F1 scores indicated that all three classifiers performed nearly identically.3–5 reported similar outcomes, with virtually equal performance metric values across the top n-ranked classifiers. In all these cases, while the performance of the classifiers is nearly identical according to conventional classifier evaluation metrics, the classifiers clearly made different false positive and false negative errors, and thus triumphed, or failed, relative to other classifiers on particular observations. Clearly, the scope of traditional statistical performance measures is too narrow to provide the insight required to distinguish between the top n-ranked classifiers based on their respective exclusive hits or misses. Novel classifier exclusivity metrics are needed to illustrate the success or failure of classifiers on particular observations, relative to their competing classifiers. These exclusivity metrics should reflect the extent to which a classifier exclusively finds (“shines through”) observations in the target class (that are not spotted by competing classifiers), or exclusively misses (“occludes”) observations in the target class that are spotted by competing classifiers.
Consider a classification task where the data scientist is attempting to identify safety concerns expressed by consumers in millions of online product reviews (e.g., see Refs. 6–9), using alternative candidate classifiers C1 and C2. The classification task is critical: missed safety concerns are unaddressed product hazards that could injure current or future product users. Assume the two competing classifiers, C1 and C2, both have precision of 80%, and recall of 80%, superficially (i.e., prima facie) indicating the classifiers have similar performance. However, if we are able to take into consideration the exclusivity of the classifier’s predictions (“shine through” and “occlusion”), we may find that C1 finds a significant proportion of the target class (safety concerns, in this observation) that C2 misses (“occludes”). Assessing classifier exclusivity is thus essential to revealing that two classifiers with 80% precision are by no means identical in their target- observation discovery ability, and may be complementary, rather than simply competing. This realization allows the data scientist to discover more safety concerns, through intelligent classifier combination (e.g., taking true positives from both classifiers), rather than the data scientist simply deciding to eliminate a superficially comparable classifier (when regarding conventional classifier performance metrics only prima facie).
Hence, while traditional performance metrics are highly efficient at identifying elite models, they tend to fall short when the task at hand requires that these (elite) models be differentiated, particularly so if the source data is of high volume.
In this paper, we present the methodology for MARS (“Method for Assessing Relative Sensitivity”), a novel approach that evaluates the comparative uniqueness of a classifier’s predictions, relative to other classifiers.19 By mathematically defining MARS ‘ShineThrough’ and ‘Occlusion’ scores, we demonstrate how these metrics assess model performance as a function of the model’s ability to exclusively capture unique true positives not found by the other classifiers (‘ShineThrough’) and the model’s inability to capture true positives found by the other classifiers (‘Occlusion’). These metrics, designed to complement widely used traditional and alternative measures, add another layer to classifier assessment, provide crucial insight that helps better distinguish and explain the behavior of the top n-ranked classifiers, and can be further extended to find optimal complementary classifier combinations for target-class discovery.
Binary classification Machine Learning (ML) performance metrics provide quantitative insight pertaining to different facets of a classifier’s true behavior, i.e., its performance on unseen data. For example, while precision is defined as the proportion of predicted positives that are actually positives, recall (sensitivity) is the overall proportion of actual positives that were correctly labelled as such.10 These metrics, derived from the classifier’s confusion matrix (Figure 1), offer complementary assessments concerning the classifier’s ability to detect and correctly label true positives, as evidenced by their mathematical definitions:

Abbreviations used: TP = True Positives, FP = False Positives.
Abbreviations used: FN = False Negatives.
Similar to sensitivity, which calculates the model’s true positive rate, specificity evaluates the overall proportion of negatives that were correctly labelled by the classifier (true negative rate).11 Consequently, it follows a similar formulation:
Abbreviations used: TN = True Negatives.
These metrics (precision, recall, specificity) provide crucial insight relating to classifier-class interactions. Other measures, such as accuracy and F score,12 provide a more generalized interpretation of model behavior. F score, defined as the harmonic mean of precision and recall, evaluates the classifier’s performance across three confusion matrix components: TP, FP, FN, and can be defined as follows:
Where β is arbitrarily chosen such that recall is β times as important as precision. The two most commonly used implementations are F1 and F2 scores.13–15
Overall accuracy, unlike the aforementioned metrics, incorporates all four confusion matrix components into its calculations:
As for visual metrics and evaluation of a classifier over multiple classification cut-off thresholds (ranked predictions), Receiver Operating Characteristics (ROC) curves16,17 and Precision-Recall (PR) curves are generally considered to be the standard. ROC curves display what proportion of the total target class items were found by the classifier (sensitivity) in the x top- ranked target class predictions (x-axis).
Precision-Recall [PR] curves are sometimes used as an alternative to ROC curves,18 to illustrate fluctuations in hit- and miss-rates, as increasing numbers of top-ranked observations are considered by a classifier. Notably, neither ROC curve nor PR curves indicate how many of the true positives in the top-ranked predictions are exclusive to the current classifier (i.e., were target-class items not found by any other classifier), nor how many of the false negatives are exclusive to the current classifier (i.e., were target-class items correctly found by all the other classifiers). Regarding this, the use of the MARS software artifact, proposed in Ref. 19, has been suggested as a way to overcome this limitation, which we further validate in this paper by presenting the mathematical foundations behind the software-level implementation of the MARS metrics.
We assess overall classifier uniqueness across two separate dimensions: MARS ShineThrough and MARS Occlusion scores. These performance measures are briefly defined in Ref. 19 as:
1. MARS ShineThrough Score: The proportion of exclusive true positives discovered only by the classifier under consideration, relative to the total number of unique true positives (i.e., counting each target-class observation once only, if it is found by any classifier) discovered across all classifiers.
2. MARS Occlusion Score: The classifier’s proportion of exclusive false negatives (missed only by the current classifier) that were correctly labelled by all the other classifiers relative to the total number of unique true positives discovered across all classifiers (i.e., counting each target-class observation once only, if it is found by any classifier).
These performance measures are rigorously analyzed and mathematically anatomized in the subsections MARS Shinethrough scores and MARS Occlusion scores below. Note that the approach described in the following sections can be easily adapted to true negatives and false positives, instead of true positives and false negatives, but is omitted for brevity (as the calculations are identical).
Table 1 provides a quick-reference glossary of the symbols used in our definitions.
| Symbol | Definition |
|---|---|
| i | Observation number |
| j | Classifier number |
| n | Total number of observations |
| yi,Cj | Predicted class label for observation i, predicted by classifier j |
| ti | True class label for observation i |
| J | Set of classifiers |
| Cw | Classifier of interest |
| Cj | Classifier j |
| Zi | Constant defined in (2.1) for observation i |
| Ri | Constant defined in (4.1) for observation i |
| TTPall | Total number of unique true positives across all classifiers |
| ETPCj | Exclusive true positives found by classifier j |
| EFNCj | Exclusive false negatives for classifier j |
Let n be the number of observations in a given dataset and J the set of classifiers, under consideration. Similarly, let yi be classifier’s predicted class label and ti the true class label (0 or 1) at observation i.
Then, we can define the total number of true positives (TTPall) as the sum, over n observations, of the maximum value of the product between predicted and true class labels across all j classifiers:
To determine the total number of exclusive true positives (ETPCw) discovered by the classifier of interest, Cw,j, i.e., target class observations found only by the current classifier and not found by the other classifiers, we use:
Where we sum (over n observations) the difference between the product of predicted and actual class labels and the maximum value of the same product across the remaining j -1 classifiers. Additionally, we multiply the latter by constant , defined as:
Consequently, the sum at observation i will have a non-zero value if and only if the classifier’s predicted and actual labels belong to the target class.
Then, using (1) and (2), we calculate the ShineThrough Score for classifier j as follows:
Hence, MARS ShineThrough provides a much-needed numerical interpretation of the classifier’s comparative uniqueness, i.e., what proportion of the total number of true positives were exclusively identified by the classifier under consideration, relative to the competing classifiers. Occlusion scores, on the other hand, provide insight relating to the classifier’s comparative weaknesses.
We define the total number of expected false negatives (EFNCw) labelled by the classifier of interest, Cw, and correctly labelled by all of the remaining
Where we find the minimum value of across the remaining j − 1 classifiers and multiply the output by binary constant Ri, defined as:
Thus, the summation will have a non-zero value at observation i if and only if the classifier under consideration incorrectly labelled the target class. Using (1) and (4), we then define the MARS Occlusion score for Cw as:
Where we divide by to determine what proportion of the classifier’s false negatives are true positives for the remaining j – 1 classifiers, therefore, quantitatively assessing the classifier’s comparative weaknesses.
For the purposes of illustration, in the following subsections, we provide a stylized dataset and step-by-step, worked examples showing the computation of the MARS ShineThrough and MARS Occlusion scores, as well as the plotting of multiple MARS scores visually, in MARS charts.20
While we provide an arbitrary, stylized dataset in this paper (to facilitate the understanding of the step-by-step examples), MARS metric performance on a real dataset can be found in Ref. 19. However, the latter does not provide any worked-out examples or rigorous mathematical explanations beyond the software-artifact’s outputs.
We created a simple, binary classification dataset with ten observations, each assigned an artificially generated “true” class label, for illustrative purposes. We also generated (predicted) labels for arbitrary classifiers: J = {C1, C2, C3, C4}. Actual (true) and classifier (predicted) labels can be seen in Table 2.
In order to calculate MARS scores, we first determine the total number of true positives discovered across all four classifiers using Eq. (1), that is:
We illustrate the sum’s inner calculations for the first two observations below:
Thus, the sum at i = 10 would be:
Summing over all ten observations yields the value of 6, indicating that every target-class observation was correctly labelled by at least one classifier. This can be double-checked by looking at the classifiers’ target class predictions in Table 2 (i = 2,4,6,7,8,10).
To calculate individual ShineThrough scores for the classifier under consideration, we divide the total number of exclusive true positives found by Cw by the total number of unique true positives (i.e., correctly classified observations in the target-class) across all classifiers (Eq. (3)). We demonstrate the ETP calculation procedure for C1 in Table 3.
| Observation (i) | Pred. class (yi) | True class (ti) | Zi | Inner sum - Eq. (2) |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | (1 × 0) − max (1 × 0, 0 × 0, 0 × 0) × 0 = 0 |
| 2 | 0 | 1 | 0 | (0 × 1) − max (1 × 1, 1 × 1, 1 × 1) × 0 = 0 |
| 3 | 0 | 0 | 0 | (0 × 0) − max (1 × 0, 0 × 0, 1 × 0) × 0 = 0 |
| 4 | 0 | 1 | 0 | (0 × 1) − max (1 × 1, 0 × 1, 1 × 1) × 0 = 0 |
| 5 | 1 | 0 | 0 | (1 × 0) − max (0 × 0, 1 × 0, 0 × 0) × 0 = 0 |
| 6 | 1 | 1 | 1 | (1 × 1) − max (0 × 1, 0 × 1, 0 × 1) × 1 = 1 |
| 7 | 1 | 1 | 1 | (1 × 1) − max (0 × 1, 0 × 1, 1 × 1) × 1 = 0 |
| 8 | 1 | 1 | 1 | (1 × 1) − max (0 × 1, 0 × 1, 0 × 1) × 1 = 1 |
| 9 | 0 | 0 | 0 | (0 × 0) − max (1 × 0, 1 × 0, 0 × 1) × 0 = 0 |
| 10 | 0 | 1 | 0 | (0 × 1) − max (0 × 1, 0 × 1, 1 × 1) × 0 = 0 |
Finally, we use Eq. (3) to obtain C1 ShineThrough scores:
This reveals that C1 alone accounts for one third of the discovered target class observations, suggesting its behavior is fairly unique amongst its peers. The calculations can be easily verified by looking at observations i = 6 and i = 8 in Table 2. Additionally, we can also calculate combined ShineThrough scores for two or more classifiers by summing the number of unique TPs discovered by the models, i.e., their combined ETP.
For example, using Table 2, we can obtain the combined ShineThrough score for C1 and C4 using Eq. (1), (2), and (3), as follows:
This combined-ShineThrough indicates that two-thirds of the total target class observations Eq. (6), were exclusively discovered by classifiers C1 and C4, revealing that when combined, the classifiers are highly capable of target-class discovery, relative to the remaining classifiers. Note that originally (prior to combining classifiers), the observation at i = 7 was not considered to be exclusive for any of the classifiers, however, once C1 and C4 had their predictions combined, it became exclusive for C1,4.
As for occlusions scores, we can calculate the total number of exclusive false negatives (missed only by the current classifier) that were correctly classified by the other classifiers following Eq. (4):
In the case of C1, the first two iterations of the sum are as follows:
Following the same procedure, the final sum at i = 10 would be:
Then, we calculate the Occlusion score for classifier C1 using Eq. (5):
Unlike ShineThrough scores (where higher scores suggest better performance), with Occlusion scores it is the case that lower scores suggest better performance. In the case of C1, its Occlusion score reveals that 16% of the target class observations discovered by all other competing classifiers are being misclassified by C1. Similar to ShineThrough scores, we can also sum classifier exclusive FN predictions to calculate combined Occlusion scores. For example, for C1 and C3, whose combined predictions only have false negatives correctly labelled by the other classifiers (C2 or C4) at observation i = 4 (Table 1), we can calculate combined Occlusion1,3 as follows:
Occlusion scores for the combined classifier, C3,4, indicate that one third of the target class labels were misclassified by the combination of classifier C3 and classifier C4, but correctly labelled by at least one of the remaining j − 1 classifiers.
MARS ShineThrough and Occlusion scores can also be visualized, allowing for the rapid depiction of the classifiers’ relative uniqueness. For our example dataset and classifiers above, the MARS metrics can be transformed from proportions (of total true positives) to counts (of unique hits or misses), and visualized, across individual and combined classifiers, as seen in Figures 2-4, using a bubble-chart style format. Figure 2 is the MARS ShineThrough chart for classifiers C1-4; the radius of the yellow circle represents the number (count) of exclusive true positives found by the classifier on the y-axis. The radius of the orange circle represents the number of exclusive true positives found by both the classifier on the y-axis and x-axis, i.e., combined ShineThrough. Figure 3 is the MARS Occlusion chart: the radius of the red circle represents the classifier of interest (y-axis) number of false negatives (correctly labelled by the other classifiers) and the radius of the orange circle represents the combined number of exclusive false negatives labelled by the classifiers on the x and y-axis (correctly labelled by the remaining classifiers).

Bubble size is proportional to ShineThrough score: the larger the bubble, the higher the classifier(s) ShineThrough score.

Bubble size is proportional to Occlusion score: the larger the bubble, the higher the classifier(s) Occlusion score.

Note that orange circles can only be as small as their respective yellow or red counterparts, which in turn may be as small as zero (indicating that the classifier found no exclusive true positives or false negatives).
Individual classifier ETP counts can also be displayed via bar chart (Figure 4), allowing for prompt visual analysis of the classifiers’ individual capabilities, but providing no information about combined classifier target-class discovery efforts.
Conventional metrics (Table 4; columns 2-4) immediately identify C4 as the unquestionably strongest classifier, due to its high accuracy (column 2), precision (column 3), and recall (column 4) values. However, notice that the information presented in these columns (2-4) does not go beyond identifying the individually strongest classifier, there is no insight relating to the classifiers’ decision boundaries or prediction uniqueness. On the other hand, while MARS metrics (Table 4; columns 5-6) do not provide a clear-cut answer as to which classifier is individually strongest, they do bring forth valuable insight about the models’ decision boundaries and possible synergies.
| Classifier | Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | ST | OCC | |
| C1 | 0.50 | 0.60 | 0.50 | 0.33 | 0.16 |
| C2 | 0.20 | 0.40 | 0.33 | 0.0 | 0.0 |
| C3 | 0.30 | 0.33 | 0.16 | 0.0 | 0.0 |
| C4 | 0.70 | 0.80 | 0.66 | 0.16 | 0.0 |
MARS ShineThrough (ST) and Occlusion (OCC) scores (Table 4; columns 5 and 6, respectively) and MARS charts (Figures 2-4) reveal that C1 is uniquely adept at spotting one third (0.33) of the target class items, and, that while C4 performs reasonably well on its own (Table 4; row 4), it could be used alongside C1 to further optimize target-class item discovery. Occlusion scores further validate the combination of C1 and C4, as C1 is the only classifier that has an Occlusion score > 0 (Figure 2), indicating that it has a unique target-class prediction error (@ i = 2, Table 2) that may be best handled by a secondary model (C4 in this case, as it has the second highest ST score after C1).
While some classifier combinations may improve overall target-class discovery performance, the opposite is also possible. For example, Figure 2 shows that the combination of C3 and C4 produces MARS ShineThrough scores identical to those of C4 alone, indicating that it is a weak combination, and should, therefore, be avoided. Thus, while traditional performance metrics gauge individual classifier capabilities by quantitively interpreting classifier-data interactions, MARS scores and charts examine classifier uniqueness and target-class discovery power by simultaneously interpreting both classifier-data and classifier-classifier interactions.
Note that the MARS evaluation mechanism was developed for a prototypical application of maximizing the volume of safety concerns found in online reviews, while constraining the close-reading verification effort required to determine if predicted positives are true positive. That is, the MARS method assists with elevating binary classifier yield: that is, increasing verified true positives per unit of effort reviewing predicted positives. The MARS evaluation mechanism is best suited to applications where the false positive cost is low, such as our prototypical application of discovering safety concerns in online reviews: a true positive (online review that contains a safety concern) is valuable, while a false positive (online review that does not contain a safety concern) has low cost, as each false positive wastes only a little reading effort, especially when there are few online reviews (predicted positives) shortlisted by the ML algorithm(s) for escalated attention by a human reviewer who is manually reviewing the predicted positive observations. For other applications – such as disease discovery – where the false positives, and false negatives, have differing trade-offs, the MARS evaluation method presented here may not be appropriate, and an inverted MARS evaluation method, aimed at maximizing true negatives, may be preferable.
In this paper, we presented the mathematical background and interpretation for two novel binary classification performance metrics – MARS ShineThrough and MARS Occlusion scores, whose software-level implementation, in the Python language, was recently described in Ref. 19. The formal definition of the MARS method, provided in this paper, will allow the research community to verify the correctness of the MARS method (through peer-review), accurately implement the MARS method in other programming languages (such as JavaScript, PHP, and R), and develop novel alternatives to, and enhancements to, the MARS method (such as visualizations that chart MARS metrics across multiple classifier cut-off thresholds instead of the single classifier cut-off threshold illustrated here). The stylized dataset and worked sample calculations provided in the Use cases section of this paper, above, is usable by the research community as a test case, to validate the correctness of each computational step of future software implementations. MARS metrics and MARS charts add yet another layer to the process of classifier assessment, providing crucial insight about each classifier’s behavior relative to that of its peers. ShineThrough scores evaluate the comparative unique strengths of the classifier, by determining the proportion of total true positives that were exclusively found by the classifier. On the other hand, Occlusion scores measure the proportion of observations that were correctly labelled by the other classifiers but misclassified by the current classifier, i.e., the classifier’s comparative unique weaknesses.
Naturally, the metrics synergize well with conventional measures, as the latter are constrained to the individual classifier’s confusion matrix, while the former make use of the entire observation sample space, thus, evaluating classifier behavior from a previously unseen standpoint: the relative number of target class observations spotted or missed only (i.e., exclusively) by one classifier. This was demonstrated throughout the provided worked-out examples, which calculated ShineThrough and Occlusion scores for our stylized dataset (Table 2), and in Ref. 19 with a real dataset, albeit without the comprehensive mathematical explanation and examples presented in this paper. As a result, the MARS methodological framework adds a new classifier-comparison dimension – exclusive hits and misses – not expounded by conventional classifier evaluation methods.
All data underlying the results are available as part of the article and no additional source data are required.
Webapp: https://mars-classifier-evaluation.herokuapp.com
Source code available from: https://github.com/SoftwareImpacts/SIMPAC-2021-191
Archived source code at time of publication: https://doi.org/10.24433/CO.2485385.v120
License: MIT
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
{kind=link}
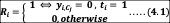{kind=link}
Comments on this article Comments (0)