Keywords
Bayesian SEM, Latent Variable, Observed Variable, Heteroscedastic error structure, Predictive Performance
Bayesian SEM, Latent Variable, Observed Variable, Heteroscedastic error structure, Predictive Performance
Bayesian structural equation modeling (BSEM) analyses the relationship between the observed, unobserved, and latent variables within the Bayesian context.14,16,21,24 The data visualization can be done by path diagram. In Bayesian inference, is random, which depicts the level of uncertainty about the true value of because both the observed data and the parameters are assumed random. The joint probability of the parameters and the data as functions of the conditional distribution of the data given the parameters, and the prior distribution of the parameters can be modelled. More formally,
where
P(θ|y) is the posterior distribution
P(θ) is the prior distribution
P(y|θ) is the likelihood function
The un-normalized posterior distribution when expressed in terms of the unknown parameters θ for fixed values of , this term is the likelihood L(θ|y). Thus, can be rewritten as:
Studies abound on classical methods and Bayesian methods with a focus on homogeneous variance.8,19,22,25 This study explores the BSEM using different forms of heteroscedastic error structure.
This section develops a Gibbs sampler to estimate SEM with reflective measurement indicators.1,11,12 The Bayesian estimation is illustrated by considering a SEM that is equivalent to the mostly used model. A SEM is composed of a measurement equation (3) and a structural equation (4)9:
It is assumed that measurement errors are uncorrelated with and , residuals are uncorrelated with and the variables are distributed as follows:
, where and are diagonal matrices. The covariance matrix of is derived based on the SEM:
In order to enable Gibbs sampling from full conditional posterior distributions, natural conjugate prior distributions for the unknown parameters are considered.25 Let be the kth diagonal element of , be the th diagonal element of be the kth row of and be the lth row of M,
The joint posterior of all unknown parameters is proportional to the likelihood times the prior,
Given Y and , and are independent from . Draws of , can cause estimation of and as a simple regression model. Thus, sampling from the posterior distribution of and without reference to The same holds for inference with regard to M, and , which are independent from Y given .
The heteroscedastic error structure with different functional form of error variance under consideration are double logarithmic form, linear form, linear-inverse form and linear-absolute form as expressed in equation 17, 18, 19 and 20, respectively.
Each of the functional forms of heteroscedastic error structure will be incorporated into the modified model. The variance matrix for disturbance vector is given as
The posterior density is the product of the likelihood and the prior distribution chosen2,13
Since the full posterior distribution is intractable; a Markov chain Monte Carlo (MCMC) simulation method of Gibbs sampling is employed.25 This involves the use of marginal posterior distribution.
Consider an informative prior created by set.
And letting c
The posterior distribution of conditional on , h, is given by:
Solving the exponential part of the above equation, we will have:
The additional term not involving is factored out to give:
Factorization in terms of , the term in the exponential becomes:
So, the posterior density of conditioned on other parameter h, , y∗ is a multivariate normal with mean and variance .
The posterior distribution of h conditional on , , is given by:
The posterior distribution of Ω*, conditional on y*, λ*, h, is given by:
The Gibbs sampling procedure used in this study involves generation of sequence of draws from the conditional posterior distribution of each parameter.2,22,25
(i) Chose a starting or initial value, for
(ii) Take a random draw, from the full conditional,
(iii) Take a random draw, from the full conditional, using the updated values of
(iv) Repeat until M draws are obtained, each being a vector of
(v) Perform the Burn-in by dropping the first of these draws to eliminate the effect of , the remaining draws are then averaged to obtain the estimate of the posterior .
The right-hand side of (15) is proportional to the density function of an inverse Wishart distribution
• At different functional forms of3 heteroscedastic error structure with changes in sample size of 50, 100, 200 and 500. Hyper-parameter will be arbitrarily chosen for the simulation using Gibbs sampler an MCMC method.6,22
• The R code can be accessed via the Extended data.26
• Factor loading and error precision followed multivariate normal and inverse gamma distributions respectively to assess the prior sensitivity.21
• The criteria that will be used to assess the performance of the posterior simulation technique are the posterior estimates.
In order to evaluate the Bayesian model fit, we used the posterior predictive probability (PPP) procedure.4,5,7,24
After achieving convergence (after j iterations). can be regarded as observation from p(λ*, Ω|y) collect for statistical inference.
The section presents the discussion of analysis of results; performances of the estimators across the parameters for the different forms of heteroscedasticity, performances of Bayesian posterior simulation and analytical methods in the presence of heteroscedasticity via consideration of four (4) different forms of heteroscedastic error structures over four sample sizes of 50, 100, 200 and 500.
This gives the results for the latent and observed variables at various sample sizes for the four heteroscedastic error conditions considered.
Using the assumed values for the estimates which are = 2.0, = 3.0 and precision = 15.0.
The covariance matrix of ω was derived to be with M at fixed values (0 or 1). The Bayesian estimates of SEM using the independent normal-gamma priors were derived for the two classes of SEM. Hyper-parameter was arbitrarily chosen for the simulation using Gibbs sampler a Markov chain Monte Carlo (MCMC) method since the joint posterior density does not have a tractable form. For the double logarithmic form, at 95% credible interval, when n=50, Posterior Mean, PM, and Precision, PR (2.011, 2.435, and 13.202), Posterior Standard Deviation PSD (0.035, 0.033, and 0.223) and when n=100, PM, and PR (2.022, 2.528, and 13.70), PSD (0.023, 0.025, and 0.251), when n=200, PM, and PR (2.052, 2.611, and 14.4), PSD (0.017, 0.018, and 0.255), when n=500, PM, and PR (2.010, 2.801, and 14.7), PSD (0.031, 0.021, and 0.258).
For the linear form, when n=50, PM, and PR (1.845, 2.779, and 13.95), PSD (0.240, 0.242, and 0.235). When n=100, PM, and PR (1.861, 2.811, and 14.22), PSD (0.328, 0.226, and 0.325), when n= 200, PM, and PR (1.956, 2.921, and 14.72), PSD (0.219, 0.217, and 0.212), and when n=500, PM, and PR (2.120, 3.122, and 14.95), PSD (0.211, 0.311, and 0.114).
For the linear-inverse form when n=50, PM, and PR (1.882, 2.742, and 14.95), PSD (0.040, 0.028, and 0.291). When n=100, PM, and PR (1.972, 2.835, and 14.65), PSD (0.024, 0.023, and 0.229). When n=200, PM, and PR (1.988, 2.901, and 14.45), PSD (0.017, 0.016, and 0.109), and when n=500, PM, and PR (2.021, 3.003, and 14.21), PSD (0.011, 0.015, and 0.105).
For the linear-absolute form, when n=50, PM, and PR (2.036, 2.824, and 14.500), PSD (0.032, 0.034, and 0.122), When n=100, PM, and PR (1.908, 2.903, and 13.92), PSD (0.022, 0.026, and 0.234). When n=200, PM, and PR (1.893, 2.809, and 13.85), PSD (0.017, 0.023, and 0.311), and when n=500, PM, and PR (1.806, 2.788, and 13.55), PSD (0.031, 0.035, and 0.433).
Examining different forms of heteroscedastic error structures in Bayesian structural equation modeling using informative priors, rather than assuming homogenous variance which is often a statistical fallacy in many studies. We compare the models’ posterior means and standard deviations in Tables 1, 2, 3 and 4. The differences are unlikely to impact substantive conclusions, but two of them are noteworthy.
First, the posterior means of the loadings ( and ) are somewhat smaller under different heteroscedastic condition with the informative priors as observed in Tables 6 and 7. Second, the factor variance is larger under our model with informative priors, likely because the informative prior placed more density on larger values of the posterior standard deviation. An evaluation of the model fit was based on the values of PPP as shown in Table 5 and it was observed that the linear form is the best with minimum PPP value as sample size increases. It was also revealed by the downward slope of the model as the sample size increases from 50 to 500 shown in Figure 1b when compared with Figure 1a, 2a and 2b.
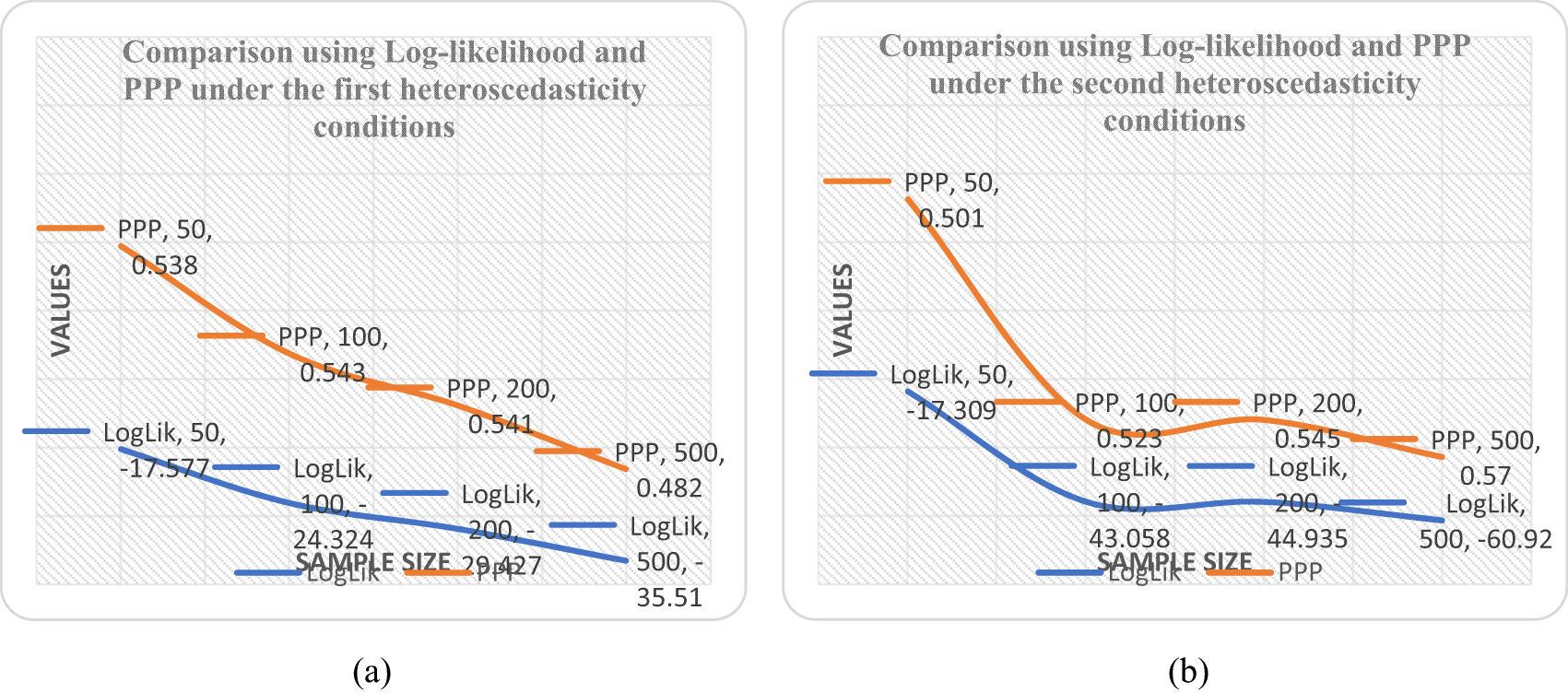
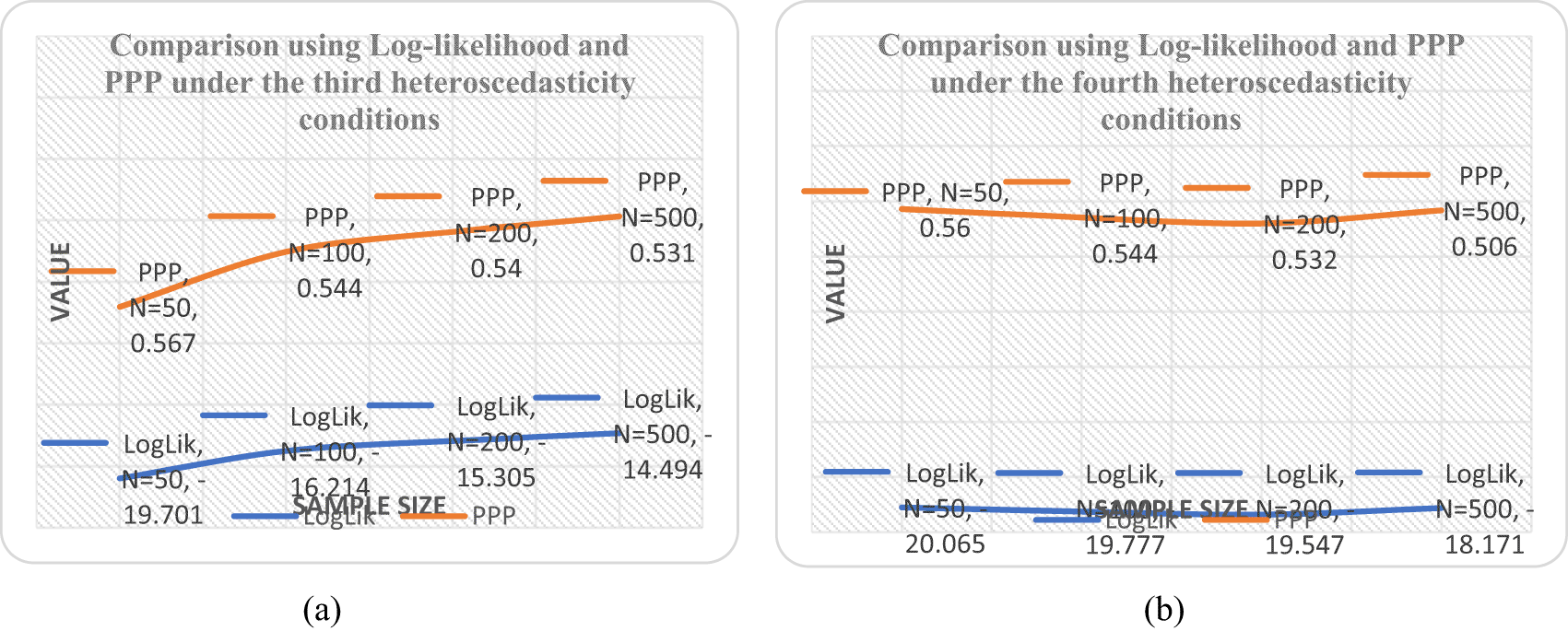
Considering an improvement to maximum likelihood method, in Bayesian estimations, parameters are considered as random with informative prior distribution also known as the conjugate family of the posterior, once the data is simulated/collected, it is combined with prior distribution using Bayes theorem, next posterior distribution is calculated reflecting the prior knowledge and simulated data.14,15,21 Joint posterior distribution is summarized using MCMC simulation techniques in terms of lower dimensional summary statistics as posterior mean and posterior standard deviations.5,25 We observe that the structural and measurement equation obtained from this study are adequate and in general we could accept the proposed model.
In this research, the derived Bayesian estimators of a structural equation model in the presence of different forms of heteroscedastic error structures validated accurate statistical inference. The study has also been able to address sufficiently the problem of heteroscedasticity of known form using four different heteroscedastic conditions for both linear and quadratic forms, and it has also successfully modified the homogenous error structure to heteroscedastic error structure in Bayesian structural equation model.20 The linear form outperformed other forms of heteroscedastic error structure thus can accommodate any form of data that violates the homogenous variance assumption by updating appropriate informative prior.16,18 Thus, this approach provides an alternative approach to the existing classical method which depends solely on the sample information.
All data underlying the results are available as part of the article and no additional source data are required.
Figshare: RCODE BSEM.docx. https://doi.org/10.6084/m9.figshare.19299851.26
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)