Keywords
Latent Dirichlet allocation, document labels, natural language processing, accreditation, quality assurance, Intelligent model, CSPC
This article is included in the Artificial Intelligence and Machine Learning gateway.
Latent Dirichlet allocation, document labels, natural language processing, accreditation, quality assurance, Intelligent model, CSPC
Based on the feedback of the reviewer, we have adapted the new title as suggested.
See the authors' detailed response to the review by Zbigniew H. Gontar
See the authors' detailed response to the review by Shahid Naseem
The creation of a smart campus is a step toward the creation of a smart city. Teaching and learning will be more difficult in the future due to the rapid advancements in information and communication technology (Kwok, 2015). With this rapid advancement, there is already a shift from the “smart” era to the “intelligent” era. A “smartphone,” “smart building,” or “smart home” is capable of adapting to changing conditions. The term “intelligent,” on the other hand, refers to more than just being smart; rather, it refers to having the ability to think, reason, and understand and adapting to adapt to changing conditions. If you apply this to a device example, “smart devices” can perform tricks, but “intelligent devices” can learn new tricks in response to their changing surroundings (Ng et al., 2010).
As part of every Higher Educational Institution (HEI)’s transition to an intelligent campus, the Commission of Higher Education (CHED) has launched a program under CHED Memorandum Order No. 9 s. 2020 for developing smart campuses for State Universities and Colleges (SUCs). In fact, CHED releases a budget to assist SUCs in developing smart campuses in which HEIs use next-generation digital technologies woven seamlessly within a well-architected infrastructure in developing tools to enhance teaching and learning, research, and extension, as well as to improve operational efficiency. On the other hand, as a requirement by CHED and maintaining the quality of education in HEIs, CHED gives accountability and responsibility to the accrediting body, such as the Accrediting Agency of Chartered Colleges and Universities of the Philippines (AACCUP), Philippines Association of Colleges and Universities Commission on Accreditation (PACU-COA), Philippine Accrediting Association of Schools, Colleges, and Universities (PAASCU), and many others to assess and provide certifications of quality education in the accredited program/institution as stated in the CHED Memorandum Order No. 1 s. 200.
Achieving a smart/intelligent campus requires consideration of different areas by the institution. Based on the study of Ng et al., there are six main areas of intelligence, namely (1) iLearning, (2) iManagement, (3) iGovernance, (4) iSocial, (5) iHealth, and (6) iGreen. The accreditation process alone will fall under iManagement; however, that entire aspect and purpose of accreditation fall in all the areas.
As a state college, Camarines Sur Polytechnic Colleges (CSPC) will be one setting for the initial implementation of the system. As part of the goal of CSPC to be the center for development and center of excellence, the institution opted to go along with the launch of the CHED program to become one of the smart campuses in the region. In connection to this, the institution also undergoes continuous accreditation through AACUP, as depicted in Figure 1, and ISO quality assurance to achieve the goal and gain the university status as the Polytechnic University of Bicol.
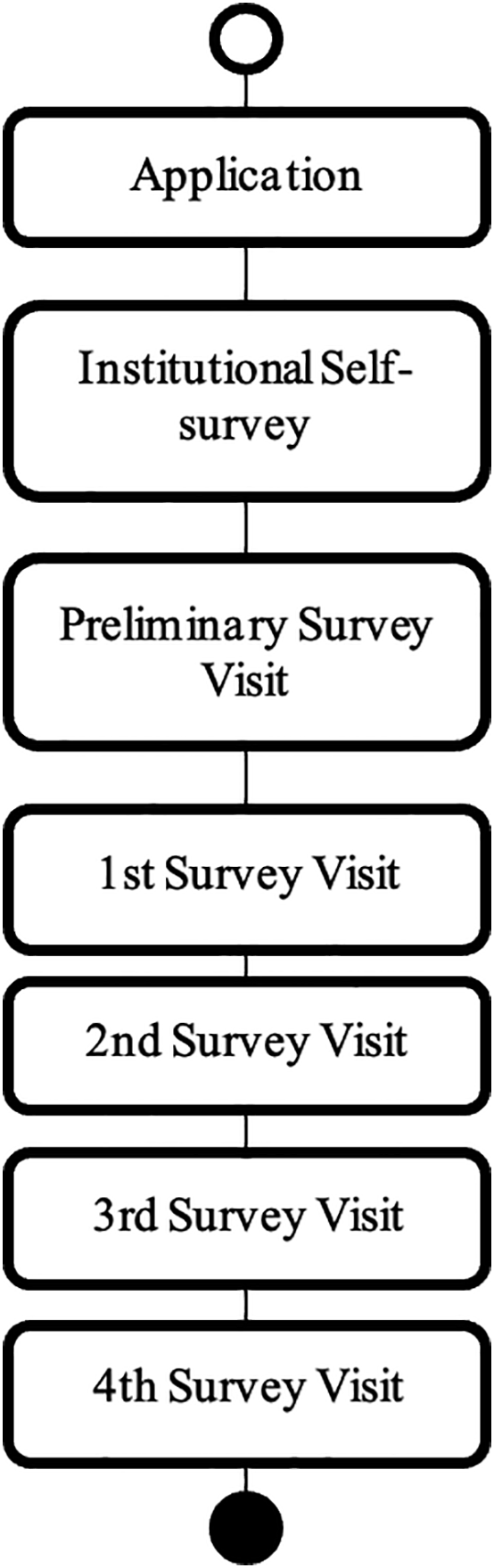
As shown in Figure 1, the accreditation process passes through various phases or actions: (a) Application: An educational institution submits an application to AACCUP for accreditation. (b) Institutional self-survey: After the application has been approved, the applicant institution is expected to conduct an internal evaluation by its internal accreditors to evaluate whether the program is ready for an external review. (c) Preliminary survey visit: This is when external accreditors evaluate the program for the first time. The program is eligible for a Candidate status that is good for two years after passing the assessment. (d) The first formal survey visit reviews the program that has obtained Candidate status. If it has met a higher standard of excellence, it is given a Level I Accredited status, valid for three years. (e) The second survey visit entails evaluating an accredited program. Suppose it has met the standards for a greater degree of quality than the survey visit that came before it. In that case, the program may be eligible for a Level II Re-accreditation status valid for five years. (f) During the third survey visit, the accreditation level is completed by a program after five years of holding Level II Re-accreditation status. The program is reviewed and must perform exceptionally in four categories, namely instruction, and extension, which are essential, and two other areas, which must be selected from among research, performance in licensure exams, faculty development, and links. (g) The fourth survey visit is a more difficult level that, if passed, may grant the organization institutional accreditation status.
Accompanied with the tedious accreditation process are many documents that need to be produced. For most of the experiences in the current accreditation undertakings in CSPC, most of the tasks have been done manually. Though tools are available for cloud storage and automation like Google Drive, Dropbox, etc., problems such as repetition of work, invalid instruments, inefficient resource utilization, and inefficient monitoring before, during, and after the accreditation are still experienced by the personnel. With this perceived problem, an integrated system dedicated to quality assurance processes is a must.
Upon the CSPC’s goal of becoming a university and becoming a smart/intelligent campus, the researchers propose a centralized system that will cater to the institution’s needs in the accreditation process, which is part of quality assurance. Through this study, CSPC will benefit from being a smart/intelligent campus by using the system in the iManagement area, and, at the same time, it addresses the problems encountered during the accreditation processes.
Based on the problems identified and the commitment of the institution to be a smart/intelligent campus, the researchers propose this study as a component in the Integrated Quality Assurance System (IQAS) (RRID: SCR_023146). The study focuses on the documents required for the accreditation process. The system will have a document repository of archived documents, and the system will analyze these documents through the use of intelligent modeling. Using this, the documents will be categorized through the extracted labels.
The study aims to create a model supporting the categorization and automated tagging of archived documents used during accreditation.
Unstructured data makes it more difficult and time-consuming to find a relevant document due to the exponential growth of electronic documents. Text document classification, which organizes unstructured documents into pre-defined classifications, is crucial to information processing and retrieval (Akhter et al., 2020). The text documents provide several difficult data processing problems for retrieving pertinent data. One of the well-liked methods for information retrieval based on themes from biomedical documents is topic modeling. Finding the correct subjects from the biological documents is difficult in topic modeling. Additionally, redundancy in biomedical text documents has a detrimental effect on text mining quality. As a result, the exponential rise of unstructured documents necessitates developing topic-modeling machine-learning approaches (Rashid et al., 2019). In the framework of document categorization, they have conducted a comparative analysis of three models for a feature representation of text documents. The most popular family of bag-of-words models, the recently suggested continuous space models Word2Vec and Doc2Vec, and the model based on the representation of text documents as language networks are all taken into consideration in detail (Martinčić-Ipšić et al., 2019).
Based on the previous articles, unstructured text data refers to textual information that lacks a predefined structure, making it challenging to analyze and extract meaningful insights. Latent Dirichlet Allocation (LDA) is a probabilistic generative model that can be used for topic modeling, a technique that helps uncover latent topics within a collection of documents (Curiskis et al., 2020). When applied to document labeling, LDA can assist in organizing unstructured text into structured representations based on underlying topics (Maier et al., n.d.).
The LDA algorithm works properly, and it is suitable for text mining. It enables the user to extract important content from text data sets (Tong & Zhang, 2016). Apart from this, it converts inaccessible data into a structured format, which can be used for further analysis. It also emphasizes facts and relationships from large data sets (Yehia et al., 2016). This information is extracted and converted into structured data for visualization, analysis, and integration as structured data and refines the information using machine-learning methods (Gnanavel et al., 2022).
The output of LDA is structured data that organizes documents into topics, allowing for the identification of the most significant topics in the corpus and their associated words. This structured data provides insights into the underlying structure and themes of the corpus, enabling further analysis and interpretation (Liu et al., 2023).
By employing LDA, unstructured text data is transformed into structured representations through the identification of latent topics, facilitating improved organization, retrieval, and analysis of textual information (Camilleri & Miah, 2021). The labeled documents provide a meaningful and interpretable way to understand the content and themes within the corpus (Markowitz, 2021).
The study used word representation techniques to analyze how the similarity between English words is calculated. In a similar work, it used the Word2Vec paradigm to express words as vectors. The 320,000 English Wikipedia articles included in this study’s model served as the corpus, and the similarity value was calculated using the cosine similarity calculation method (Jatnika et al., 2019). Real-world text categorization problems frequently involve a multitude of closely related categories arranged in a taxonomy or hierarchical structure. When processing huge sets of closely related categories, hierarchical multi-label text categorization has grown more difficult (Ma et al., 2021). A popular technique for clustering functional data is the functional k-means clustering algorithm. The derivative information is not further considered by this approach when determining how similar two functional samples are to one another. The derivative information is crucial for spotting variances in trend characteristics among functional data. By including their derivative information, we establish a novel distance in this paper to compare functional samples (Meng et al., 2018). Due to its capacity to analyze data from numerous sources or views, multi-view clustering has drawn growing interest in recent years. In the research, they presented a unique multi-view clustering method called Two-level Weighted Collaborative k-means (TW-Co-k-means) to simultaneously address the issues of consistency across different views and weigh the views for improving cluster results. For multi-view clustering, a new objective function has been developed that leverages the unique information in each view while also cooperatively utilizing the complementarity and consistency between various views (Zhang et al., 2018). The various pattern matching algorithms are used to locate every instance of a constrained set of patterns inside an input text or input document to examine the content of the documents. This research utilized four string matching techniques that are now in use: the Brute Force approach, the Knuth–Morris–Pratt algorithm (KMP), the Boyer–Moore algorithm, and the Rabin–Karp algorithm (Bhagya Sri et al., 2018). Analogous to the technique used by the researcher in exploring all possible combinations using the functionality of LDA, the Brute Force approach is like exhaustively considering all possible topics and their distribution in the document (Robinson & Quinn, 2018). However, it’s inefficient, much like considering every possible combination of words as potential topics (Murray et al., 2022). On the other hand, the KMP algorithm’s efficiency in skipping unnecessary comparisons (Lu, 2019), similar to LDA it efficiently identifies topics in documents by leveraging models, optimizing the process of finding meaningful patterns (topics) in text (Rawat et al., 2022). In terms of skipping the portions of the text based on the information gathered during preprocessing in the documents, LDA skips irrelevant words and focuses on key terms that contribute to the identification of topics (Hwang et al., 2023) that are similar to the Boyer–Moore algorithm skipping portions of text during the matching process (Danvy & Rohde, 2006). Moreover, Rabin–Karp’s hashing for efficient matching (Siahaan, 2018) is akin to LDA, which also involves modeling to identify relevant topics in documents, quickly bypassing irrelevant information (Asmussen & Møller, 2019). All the literature listed has similarities in text clustering, modeling, and classification. It serves as proof that the study is feasible and the proposed intelligent model can be integrated to further assist in the accreditation process in CSPC.
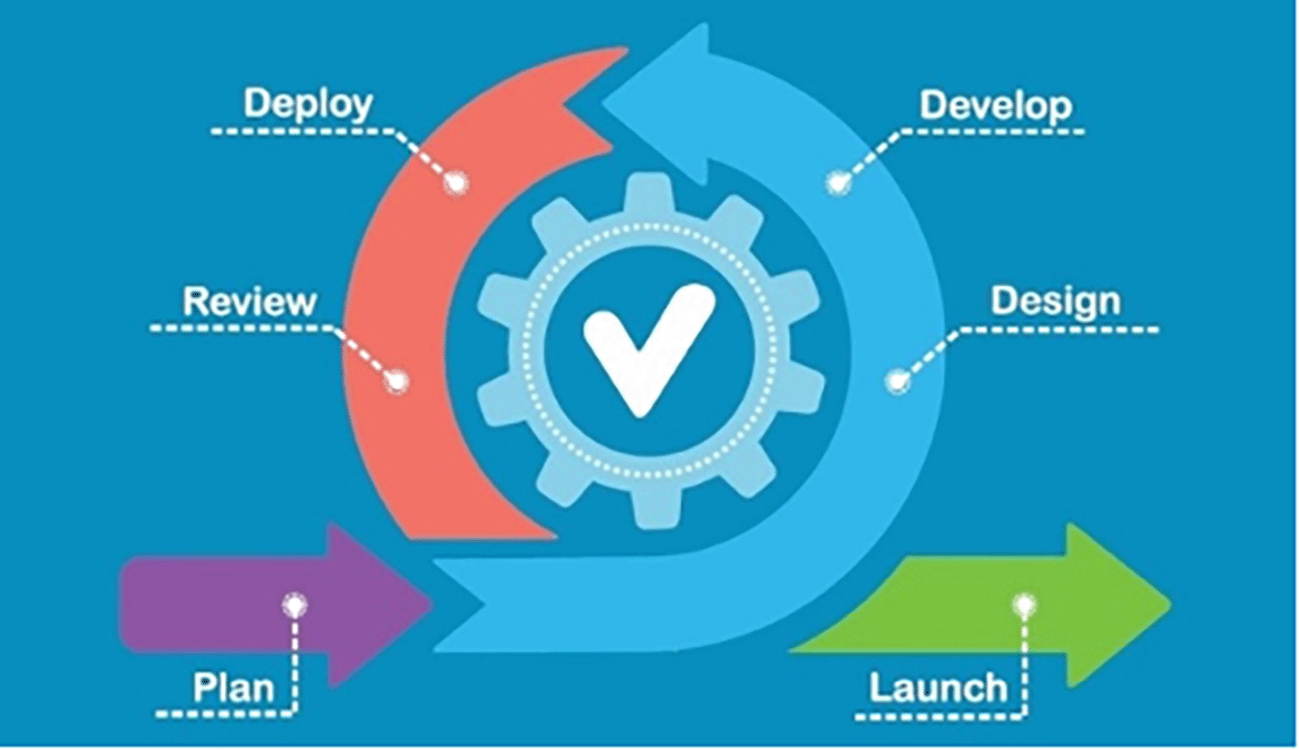
As a guide in modeling the study, the researchers used the agile method (https://dx.doi.org/10.17504/protocols.io.n2bvj82mxgk5/v2) as it promotes flexibility, speed, and, most importantly, continuous improvement in developing, testing, documenting, and even after delivery of the software. Since the phases of this model are light, the teams are not bound by a rigid systematic-based process on pre-set constraints and restrictions as some other models, like the waterfall model, can adjust changes whenever needed. This flexibility at every stage propagates creativity and freedom within processes. Furthermore, development teams can modify and re-prioritize the backlog, allowing for speedy implementation (Trivedi, 2021).
Following the agile methodology, the researchers adapted the stages presented in Figure 2. These are (1) Plan: the researchers collected previous documents involved in the accreditation process, such as compliance reports for student, faculty, facility, library, and administration. Also, understanding the existing problems in tracking, tagging, and duplicating these documents during the accreditation process. (2) Design: The requirement specifications in this stage were identified about the existing problem of the HEI in tracking, tagging, and duplicating the documents for accreditation and quality assurance. Along with this, the researchers also created the process of the intelligent model, which will be the basis of document labeling. (3) Develop: This stage is intended for the creation of the prototype, which involves processing the documents to identify the proper label for each document. (4) Deploy: the prototype undergoes a test run during this stage. (5) Review: the researchers conduct a checklist function review to check if each component runs properly. Lastly, (6) launch, wherein the prototype is embedded in the local system of the HEI together with the maintenance procedure upon full implementation of the system.
The results from this intelligent model are used for visualization in the super word vector and histogram. The super word vector is presented in a cloud map word to visualize the frequency of the words in the corpus, and the histogram is used to present the relationship of the words per sentence in the form of line graphs. The extracted labels and generated word vector and histogram are tagged and linked to the uploaded document, as patterned in the process shown in Figure 3. This model is implemented in the IQAS to assist in categorization and searching in the file repository of accreditation documents.

The design prototype presented in this section is focused on the label extraction feature for automatic tagging of the archive documents used in accreditation.
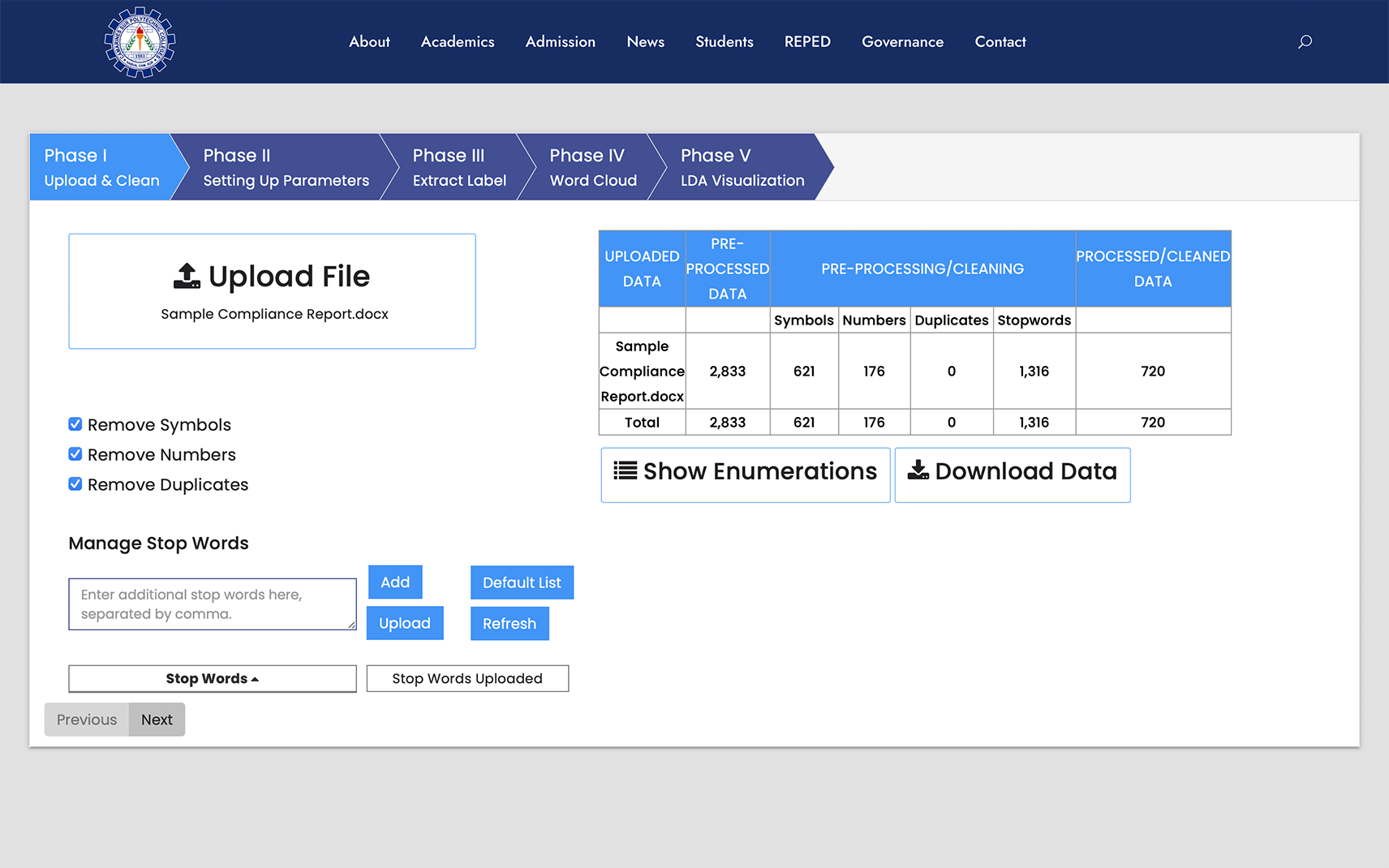
Upload and clean
As shown in Figure 4, this phase allows the user to upload and clean the document through tokenization. Once uploaded, the user may set the configuration to clean the document. The options are removing numbers, symbols, and duplicates, adding and uploading additional stopwords, and showing and downloading the pre-processed data. There are other useful features, particularly in managing the stopwords, such as showing the list of default stopwords and deleting the added and uploaded stopwords.
Setting up parameters
Phase II is intended to set up the parameters for topic modeling, as presented in Figure 5. Right after uploading and cleaning the document, the user can set the topic modeling parameters to identify and extract the labels. The parameters included are the desired number of topics, frequency of iteration, the number of words per topic to be generated, optimization interval, and the model’s name. These parameters are primarily the factors in modeling the topics and label identification for automatic tagging.

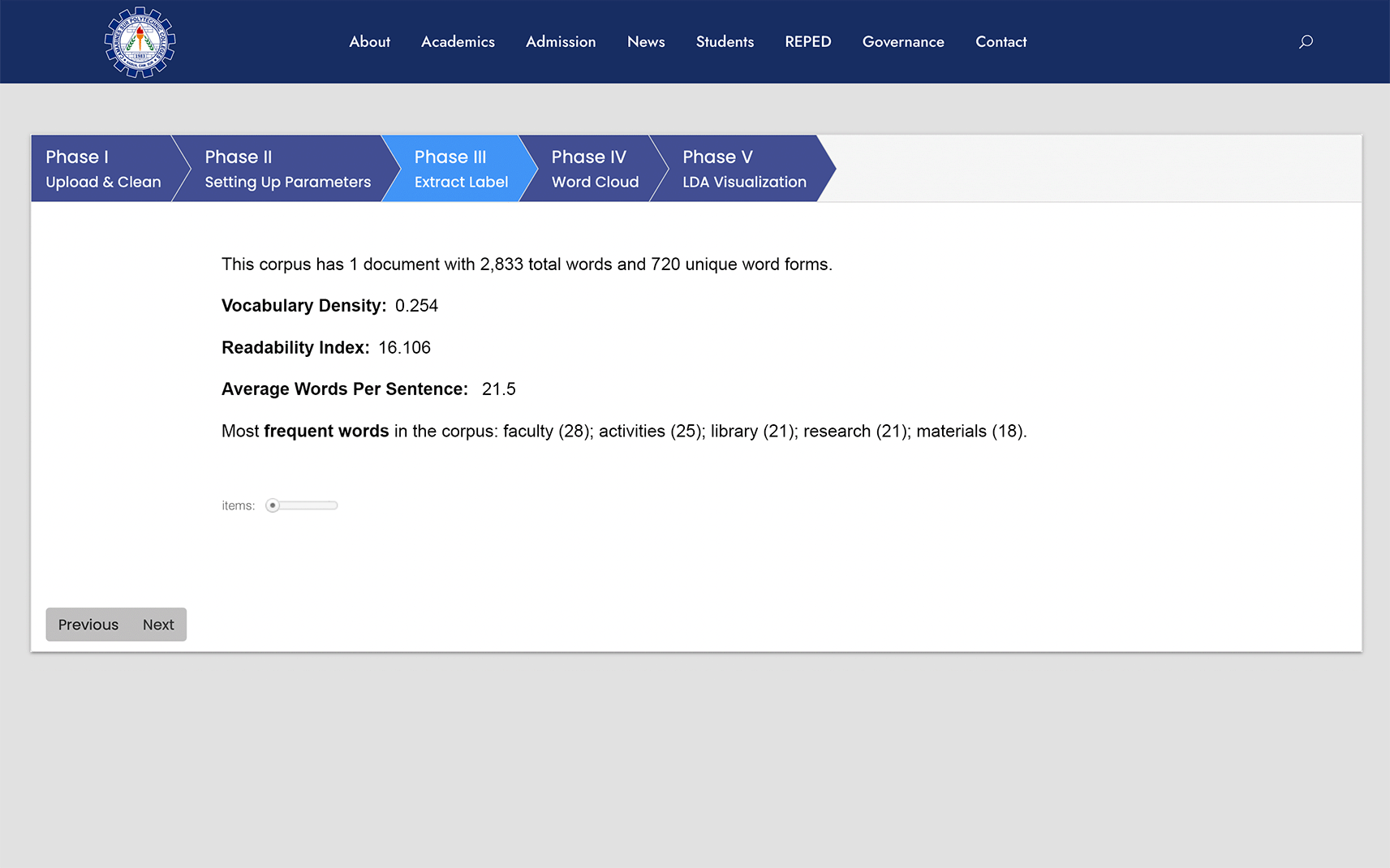
Extract label
This phase, as shown in Figure 6, provides the result of the processed corpus from the processing of the pre-processed document and the parameters that have been set up from the previous phase. This shows the number of documents uploaded, the total number of words in the document, the number of unique words, vocabulary density, readability index, average words per sentence, and most importantly, the frequent words in the corpus. These frequently used words are extracted to be the label for automatic tagging later. The user can also set the items to be shown in the most frequent words.
Word cloud
A word cloud is also generated with the results of phase III. Phase IV, as depicted in Figure 7, is a super word vector view of the frequent words in the processed corpus. The most evident words in the word cloud are the frequently used words from the previous phase: faculty, activities, library, research, and materials. The font size of the word is based on how many times this word is used in the corpus.

LDA visualization
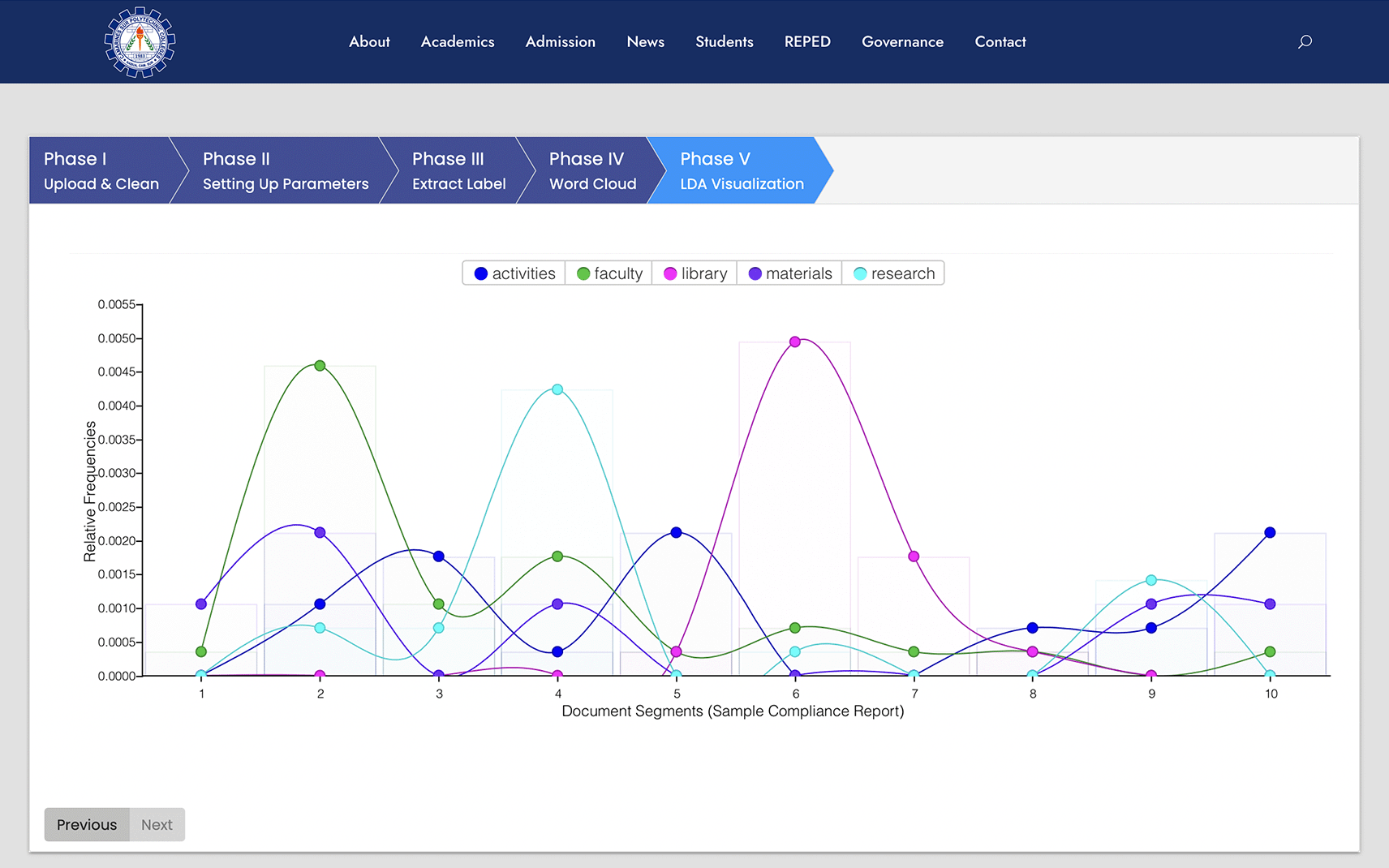
With the result generated during phase III, this phase provides the histogram presentation of the sample processed corpus with the support of the LDA visualization, as shown in Figure 8. The line graph provides the relative frequencies of each generated label per document segment.
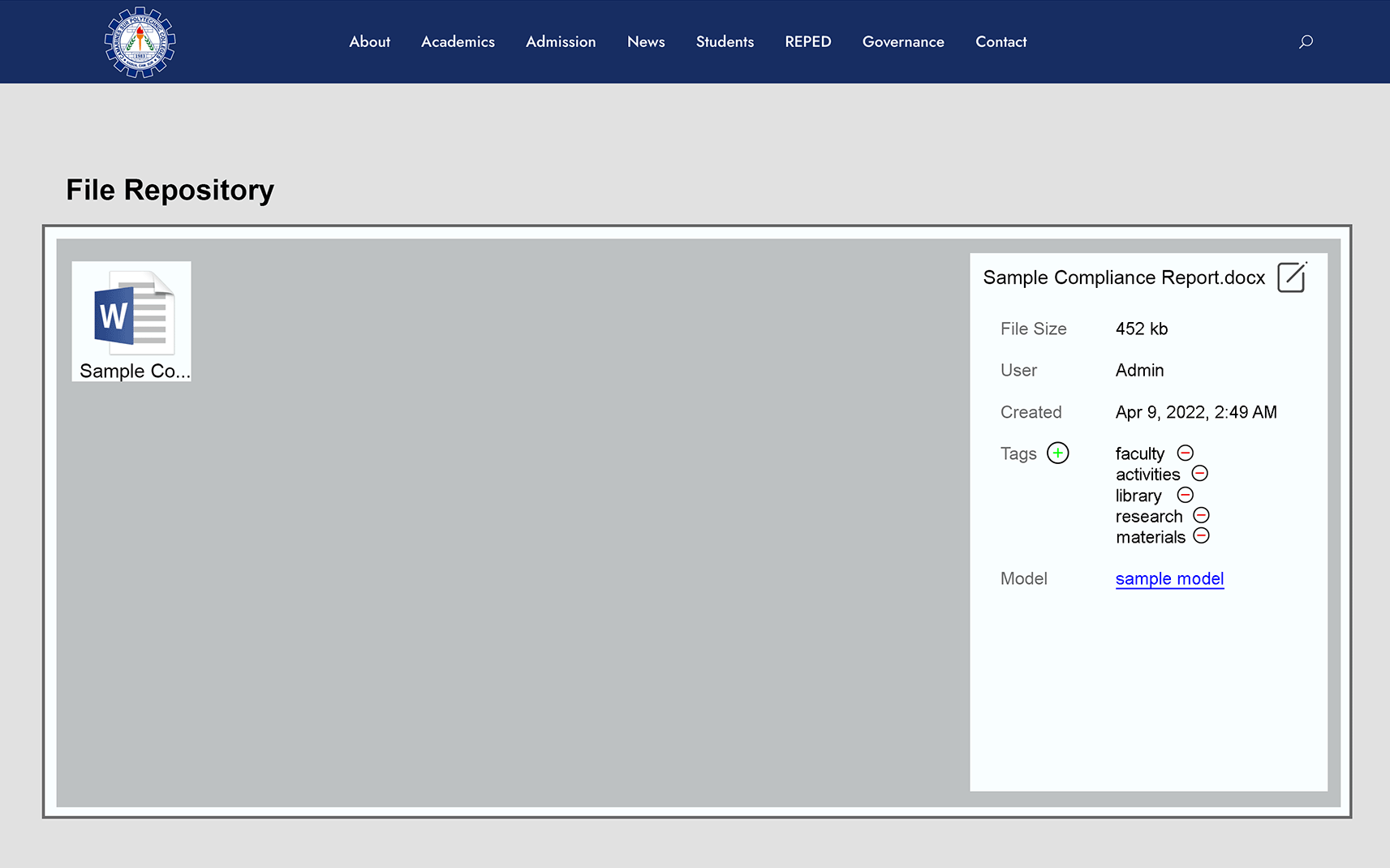
Auto-tagging to uploaded document
After the five phases, automatic tagging of the generated labels occurs which are faculty, activities, library, research, and materials, as shown in Figure 9. The document is then stored in the IQAS file repository. The uploaded document will have corresponding metadata such as filename, file size, user, date created, tags, and the link of the processed model. The filename can also be updated, and adding and removing tags is possible.
Computational analysis
This section provides the computational analysis of the actual result based on the processed document for better understanding.
In reference to the results of phase III, four significant results are evident in Figure 6. Vocabulary density is the ratio between the total number of words in the corpus and the unique words (Crane, 2023). To obtain the vocabulary density, the total number of unique words is divided by the total number of words wherein the values used for sample computation are derive from the result of LDA algorithm embedded in the prototype which can be seen in Figure 4; for the sample computation, see Equation 1.
Equation 1. Vocabulary density computation.
The vocabulary density of the processed corpus is 0.254, which implies that the corpus contains complex text with many unique words. Moreover, the readability index and average word per sentence use Java break iteration, a locally sensitive class with an imaginary cursor pointing to the current boundary in a string of natural language text. This contains different kinds of boundaries, such as text characters, words, sentence instances, and potential line breaks. These boundaries are the basis for the readability index and average words per sentence, which are 16.106 and 21.5, respectively. Frequently used words are identified based on the number counts of the word used in the processed corpus.
The LDA visualization is presented by correlating the relative frequency of the word per document segmentation, as shown in Figure 8. To identify the relative frequency, deciding the number of document segmentations is necessary. For this study, the researchers used ten (10) segments for the document. The grouping of words per segment is based on the total word count. The prototype now determines how often a particular word is used per segment. Upon determination, the identified number of counts is divided into the total word count. For the sample computation (Crane, 2023), see Equations 2 and 3.
* The first seven segments contain 283 words, while the last three segments contain 284 words.
Equation 2. Words per segment computation.
Equation 3. Sample computation for relative frequency (Word: research|2nd Segment).
For the overall results of the histogram, Tables 1 and 2 present the tabular representation of the relative frequency per label and segment.
| Labels | Word count per document segment | Total count | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| Faculty | 1 | 13 | 3 | 5 | 1 | 2 | 1 | 1 | 0 | 1 | 28 |
| Activities | 0 | 3 | 5 | 1 | 6 | 0 | 0 | 2 | 2 | 6 | 25 |
| Library | 0 | 0 | 0 | 0 | 1 | 14 | 5 | 1 | 0 | 0 | 21 |
| Research | 0 | 2 | 2 | 12 | 0 | 1 | 0 | 0 | 4 | 0 | 21 |
| Materials | 3 | 6 | 0 | 3 | 0 | 0 | 0 | 0 | 3 | 3 | 18 |
CSPC is in an exploratory phase when it comes to solving this particular accreditation problem. It is evident that the organization encountered problems pertaining to the accreditation process. Therefore, the researchers devised a model that supports the organization’s accreditation. In addition, the researchers also designed a prototype with the implementation of the model to help the organization through the process. As a result, retrieving and classifying the data is easier, which is the main problem of the task group. Furthermore, other text classification patterns may also be integrated into the system, and the results may be compared with given parameters.
Software available from: https://github.com/CraigList056/iqas/tree/v1.0.0-alpha
Source code available from: https://github.com/CraigList056/iqas
Archived source code at the time of publication: https://www.doi.org/10.5281/zenodo.7507492
License: MIT License
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)