Keywords
Classification algorithm, COVID-19 Vaccine, ensemble learning, machine learning, Sampling methods, Side effects.
Classification algorithm, COVID-19 Vaccine, ensemble learning, machine learning, Sampling methods, Side effects.
All the reviewers' comments have been addressed, and a new section was added to clarify the algorithm and sampling method selection, as well as parameter tuning. Additionally, a new table and figure were included.
See the authors' detailed response to the review by Jinran (Ryan) Wu
See the authors' detailed response to the review by Aritra Ghosh
See the authors' detailed response to the review by Dhamodharavadhani S
See the authors' detailed response to the review by Samir Kumar Bandyopadhyay
From seven to 13 years of research and development (R&D) and 1.8 million clinical trials to develop a vaccine in the past, we have transitioned to 10 to 18 months of R&D and tens of thousands of clinical trials to start vaccinating against COVID-19 in 2021.1
Vaccines are biologics that provide active adaptive immunity against particular diseases. The vaccine usually contains drugs similar to the microorganisms that cause the disease. It is generally made from one of the killed or attenuated micro-organisms, its toxins, or its surface proteins. Giving us an injection, nasal spray, or oral vaccine stimulates our immune system to recognize and destroy foreign bodies.2
As a result of the novel coronavirus's rapid dissemination and disease burden, pharmaceutical companies and researchers were forced to create vaccinations quickly using either novel or preexisting technologies.3 There are several different types of vaccines, and the purpose of each type is to boost your immune system and prevent serious, life-threatening diseases from occurring.4 The COVID-19 vaccines that have been approved employ a variety of mechanisms of action, including mRNA, DNA vaccines, viral vectors, protein subunits, and virus-inactivated vaccination techniques.5 Three vaccines have been widely administered: Pfizer and Moderna (mRNA) vaccinations targeting the SARS-CoV-2 surface protein, and the Janssen (viral vector) vaccine, which employed pre-existing technology with an adenovirus vector to trigger an immune response and provide protection against further infection. As these vaccines were developed using various approaches, they differ in efficacy and storage conditions.6
However, no vaccine is entirely free from complications or adverse reactions. Any vaccination can have early adverse reactions, including local ones like pain, swelling, and redness, as well as systemic ones like headache, chills, nausea, fatigue, myalgia, and fever.7 Also, several existing health conditions or symptoms the candidate already has can lead to severe adverse reactions after taking the COVID-19 vaccine. The candidate's death could be the worst-case scenario. As a result, it's critical to know about the candidate's previous medical history.8
This paper delves into an in-depth analysis of adverse effects associated with COVID-19 vaccination using data mining techniques to predict the most appropriate vaccine for individual candidates and identify patients at high risk of mortality from COVID-19 vaccination. To accomplish these pivotal objectives, an extensive analysis was conducted using a comprehensive COVID-19 vaccine adverse reaction dataset, shedding light on crucial factors influencing vaccine outcomes.
This work's main contribution can be summarized as follows:
1. Identify the most important features of an individual's medical history that could contribute to adverse reactions to vaccination.
2. Identify the most important features that contributed to the death of the candidate based on his or her medical history.
3. Address the challenge of the imbalanced dataset by employing sampling methods to effectively handle the imbalance and improve the reliability of the analysis.
4. Develop a machine learning (ML) model capable of predicting and classifying the most suitable vaccine types for each candidate, thus helping to prevent severe consequences and ensure optimal vaccination outcomes.
The rest of this paper is organized as follows: In the next section, we discuss a brief review of the literature on various related works. Section 3, provides a detailed explanation of our methodology and dataset. Section 4 discusses the study findings, while Section 5 covers the strengths and limitations. Section 6 presents the conclusions, and Section 7 outlines the future work.
Due to the rapid advancement of technology, there are numerous opportunities and possibilities for ML in healthcare.9 Classification is the most well-known machine-learning technique in medical applications because it is similar to everyday problems. A classification algorithm builds a model based on training data and then applies it to test data to obtain a prediction.10
Interestingly, some studies have utilized machine learning applications to predict side effects, reactogenicity, and morbidity incidence following COVID-19 vaccinations. Research by Sujatha et al.,8 the authors developed a model to predict whether a candidate is suitable for COVID-19 vaccination. Four machine learning approaches, namely Logistic Regression, AdaBoost, Random Forest, and Decision Tree were employed in the task of prediction. The authors found that AdaBoost was the classifier with the best performance, achieving an accuracy of 0.98. The number of symptoms has been restricted to five for the sake of proper implementation. While this limitation streamlines the analysis process, it may overlook potential rare symptoms or nuances in symptomatology, impacting the comprehensiveness of the study's conclusions.
In research by Hatmal. M et al.,11 the authors used machine learning and ensemble methods to predict the severity of side effects, defined as none, mild, moderate, or severe. The analysis revealed that random forest and XGBoost achieved the highest accuracy (0.80 and 0.79, respectively) and Cohen’s κ values (0.71 and 0.70, respectively). Statistical data analysis revealed that side effects significantly varied based on vaccine type. According to this study, the COVID-19 vaccines approved by the CDC are safe, and vaccination instills a sense of safety in people. However, severe cases may require additional medical care or even hospitalization. The dataset suffered from uneven gender and profession representation, potential result misclassification, and reliance on a self-reported online survey.
In research by Lian et al.,12 the goal was to collect and analyze tweets about the COVID-19 vaccination to find posts about personal experiences with COVID-19 vaccine adverse events. The authors found that the ensemble model-based RF achieves the best performance with an F1 score of 0.926, an accuracy of 0.908, and a recall of 0.946. The named entity recognition (NER) model achieved an F1 score of 0.770 for detecting adverse events using the conditional random fields (CRF) algorithm. Also, the results show that the three COVID-19 vaccines' (Pfizer, Moderna, and Johnson & Johnson) most common side effects are soreness to touch, fatigue, and headache. Notably, the majority of the participants were young. Additionally, the survey was conducted in a single language, which may present challenges for individuals with Limited English Proficiency (LEP). This linguistic limitation could impact the inclusivity and representation of diverse perspectives in the study.
The overview of the general methodology for developing a machine learning models is visualized in Figure 1. In this study, we focus on predicting which vaccine will be most effective for a candidate without causing severe adverse reactions (output) based on several factors (input) and handling the imbalanced data that falls under the Pre-processing step where the data preparation process takes place.
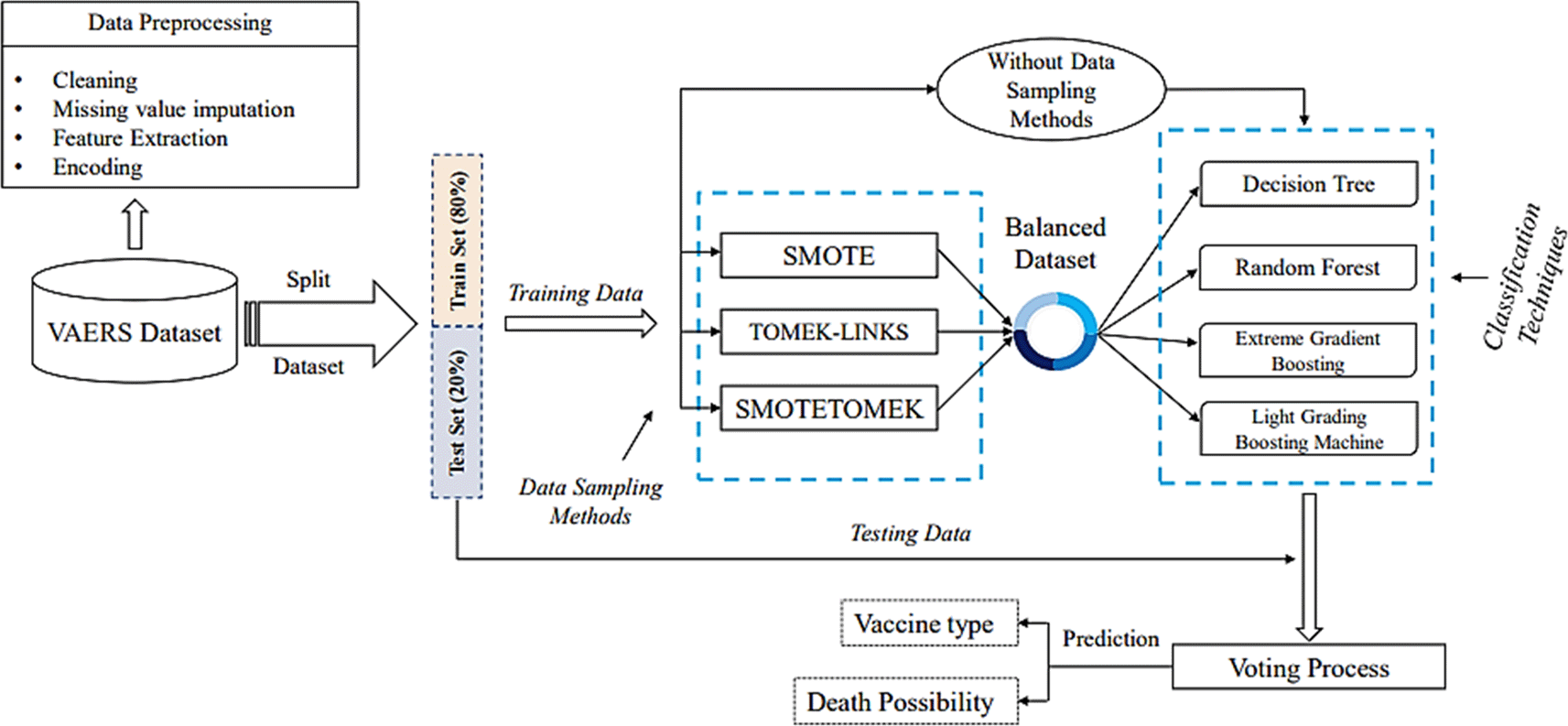
The raw data of individuals who received vaccinations and reported adverse reactions was obtained from the VAERS.13 This dataset contains vaccination information for individuals vaccinated against a variety of diseases including COVID-19, Polio, Tetanus, and Influenza. However, our current study omitted any non-SARS-CoV-2 (COVID-19) vaccination information. Therefore, the dataset being used consists of 49,810 individuals. This dataset has various attributes of individuals’ information such as age, gender, current illness, medical history, allergic history, type of vaccine, life-threatening illness, symptoms after vaccinations, etc. Some of these attributes have been found to be textual (e.g., medical history, symptoms text, etc.), while others have been found to be numerical (such as age, number of doses, etc.). The description of some different attributes in the VAERS data set is illustrated in Table 1.
The quality of raw data used to perform any analysis heavily influences its outcome. Therefore, the preprocessing and exploratory analysis of data becomes the most important parts of any data-driven investigation. The preprocessing of a dataset involved examining the data for missing values, irrelevant values, replicas, etc. whereas EDA assists in understanding data by visualizing it. It has been noticed that the dataset contains many missing and irrelevant values.
Any COVID-19 vaccine types that were not specified were removed, and only two types of values in the sex field were considered: “M” as male and “F” as female. Unknown values were excluded. In the died field, ‘Y’ was considered yes, and the rest were considered ‘no’; in the ‘prior vaccine’ field, ‘yes’ was considered yes, and the rest were considered ‘no’. The analysis of allergic history included considering mentioned allergic effects as positive cases and considering ‘null’, ‘none’, ‘NA’, and other negatively mentioned text as negative cases. The History column in the dataset contained written records of coexisting conditions, requiring the extraction of all of the patient's medical history separately. To better understand the patient's medical history, information about pre-existing chronic and non-chronic diseases, such as chronic obstructive pulmonary disease, hypertension, diabetes, and kidney disease, was extracted. All missing values (i.e., empty, null) were excluded from this field, and spelling/grammar mistakes were fixed.
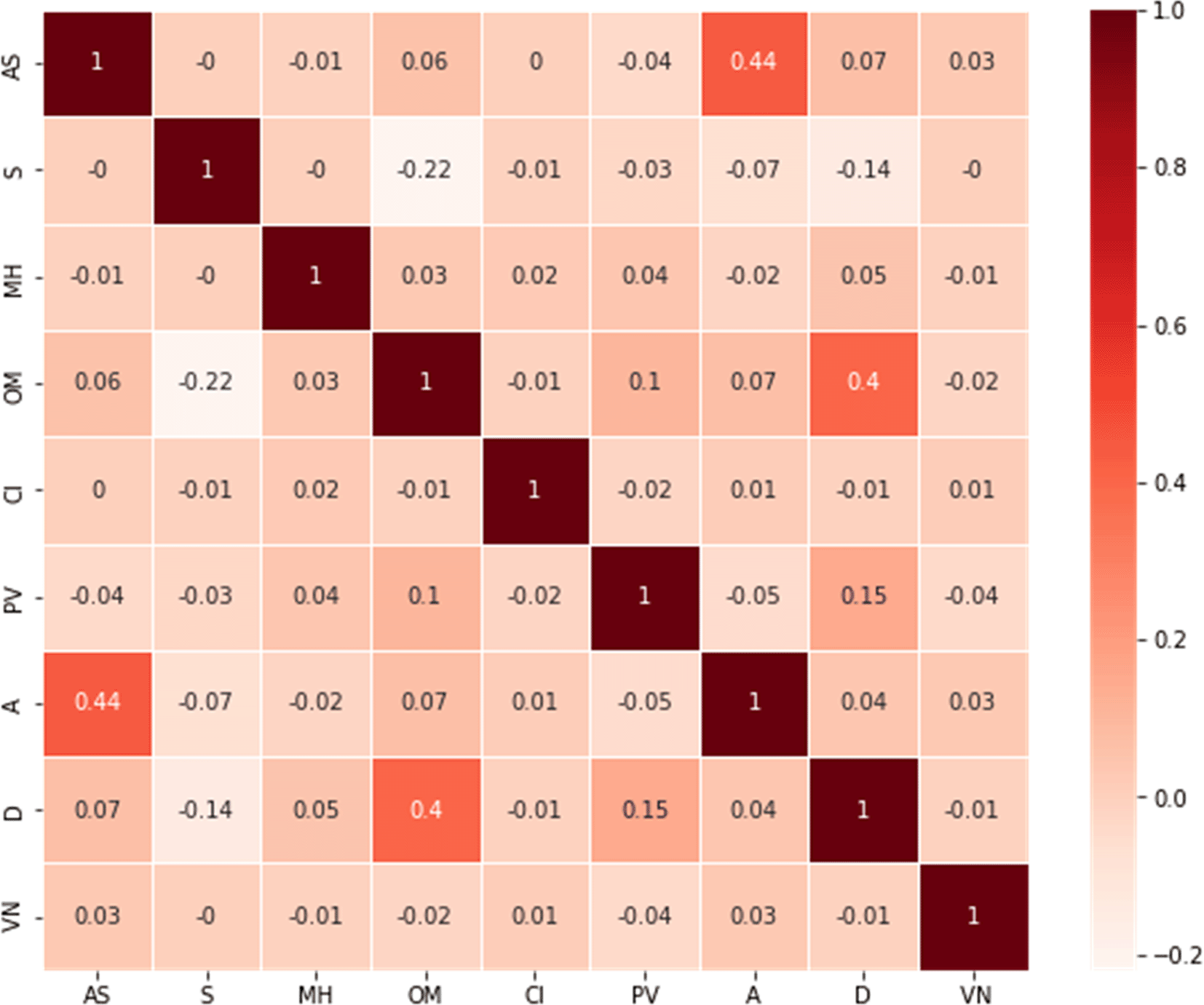
In the Feature extraction step, most of the important features in the acquired dataset are presented as textual data. However, in order to analyze them, they must be separated into separate entities. As a result, String matching was used to convert all text data into attributes. The correlation plot (Figure 2) did not demonstrate a significant relationship between various attributes and vaccine types. Yet, previous studies revealed a direct correlation between vaccine adverse reactions and medical and allergic histories. Therefore, the number of unique entries for the diseases in the patient's medical histories was counted. Diseases with more than 300 counts in patients' medical histories were considered attributes, while the rest were ignored due to the large dataset and the computational burden associated with each individual disease. This study, therefore, considered 21 diseases which are diabetes mellitus, thyroid, different pain, obesity, migraine, kidney disease, hypertension, hyperlipidemia, high cholesterol, heart disease, Gastroesophageal Reflux Disease (GERD), depression, dementia, positive history of COVID-19, Chronic Obstructive Pulmonary Disease (COPD), cancer, atrial fibrillation, asthma, arthritis, anxiety, and anemia from the patient’s medical history as attributes. Using the VAERS id, these files have been merged into one file after identifying and extracting features. The analyzed dataset has 28 different features and over 49,810 samples. The data was encoded using a one-hot encoding technique.
In this study, only three methods of handling imbalanced data are used. In the first place, no changes are made to the data. Normally, it is divided into training and testing data at a ratio of 8 to 2. This first technique is referred to as “Normal” in this study. Next, experiments are conducted using well-known imbalanced data techniques called SMOTE, Tomek-links, and SMOTETOMEK, for balancing the dataset which combines SMOTE and Tomek links.14 As with the previous experiment, the dataset is divided into training and testing data at a ratio of 8 to 2. This experiment aims to handle imbalanced data and further improve the performance of machine learning classification models, especially in the multiclass classification scenario. This experiment aims to handle imbalanced data and further improve the performance of machine learning classification models, especially in the multiclass classification scenario. These Sampling methods were selected considering data nature, imbalance ratio, algorithm compatibility, and analysis goals.
To predict which vaccine will be most effective for a candidate without causing severe adverse reactions (output) based on several factors (input), different machine-learning algorithms were used to build the proposed model. These approaches were selected due to their accuracy, robustness, efficiency, scalability, and ability to handle large, high-dimensional datasets while reducing overfitting.
Random Forest (RF)
A multipurpose data mining approach for classification. It is based on decision trees that operate as an ensemble, an approach of combining multiple classifiers to identify problems and enhance accuracy. A classification is predicted by each tree independently, and votes for the relevant class, and the majority of votes decide the model’s prediction. It can handle large dataset with high dimensionality, it also improves the accuracy of the model and eliminates the overfitting problem.15
Decision Tree (DT)
A DT is a supervised learning technique that can be used for classification and regression problems; however, it is most commonly used to resolve classification issues. In this tree-organized classifier, the internal nodes represent datasets, branches represent decision rules, and each leaf node represents the outcome. A DT has two nodes: the decision node and the leaf node. The leaf nodes are the result of such decisions and they do not have any extra branches, but decision nodes are frequently used to settle any decision and have several branches. Based on the features of the dataset, decisions or tests are made.16
Extreme Gradient Boosting (XGB)
XGBoost is an ensemble learning method combining multiple weak models' predictions to generate a stronger prediction. In the beginning, XGB fits the data to a weak classifier. Afterward, the data is fitted to another weak classifier to increase accuracy without affecting the current model. In the same way, the process continues until the best accuracy is achieved.17 Furthermore, XGBoost supports parallel processing, making it possible to train models on large datasets in a reasonable period of time.
Light Grading Boosting Machine (LGBM)
LGBM is an open-source gradient boosting algorithm based on a tree-based learning framework; it is an open-source GBDT algorithm designed by Microsoft Research Asia. This framework grew trees vertically (leaf-wise) rather than horizontally (level-wise) as other tree-based frameworks did. Therefore, it can reduce the losses more efficiently and handle huge dataset with less computational complexity due to its lighter version.18
Macro average and Weighted Average are used to calculate the performance of the four classifiers used for learning.
In general, a confusion matrices are a 2 × 2 matrix. Where rows represent the instances in the actual class, and the columns represented the predicted class. It results in four possible outcomes: TP, FP, TN, and FN.

(a) Binary classification confusion matrix. (b) Multiclass classification confusion matrix.19
Using the above outcomes, we can check whether the predictions are correct.16,20,21
ROC Curves show the performance of the classification model across all classification thresholds. In a ROC curve, the TP rate and FP rate are plotted at each threshold of classification. “AUC” stands for “Area Under the ROC Curve”. It can be used as a classifier to distinguish between classes. In general, the higher the AUC value, the better the classifier is at identifying positive from negative classes.22,23
Hyperparameter tuning is a crucial step in the data mining model development process, involving the refinement of hyperparameters within a data mining algorithm to uncover the optimal combination that enhances classifier performance. The Grid Search approach is a widely recognized and effective method for hyperparameter tuning.24 In the context of this paper, Grid Search was employed using the GridSearchCV object from scikit-learn to thoroughly explore and identify the hyperparameter set that consistently produces the most favorable results. Known for its systematic and methodical approach to hyperparameter tuning, Grid Search operates by specifying a set of hyperparameters and their potential values, creating a grid of all possible combinations, and assessing the model's performance for each. This method exhaustively searches through the grid, identifying the hyperparameters that consistently yield the best results, and fine-tunes the model for optimal performance.
A comprehensive overview of the default parameters for the data mining classifiers is provided in the appendix. Additionally, it details the parameters specifically assigned to each classifier for the purpose of randomized parameter optimization to enhance performance.
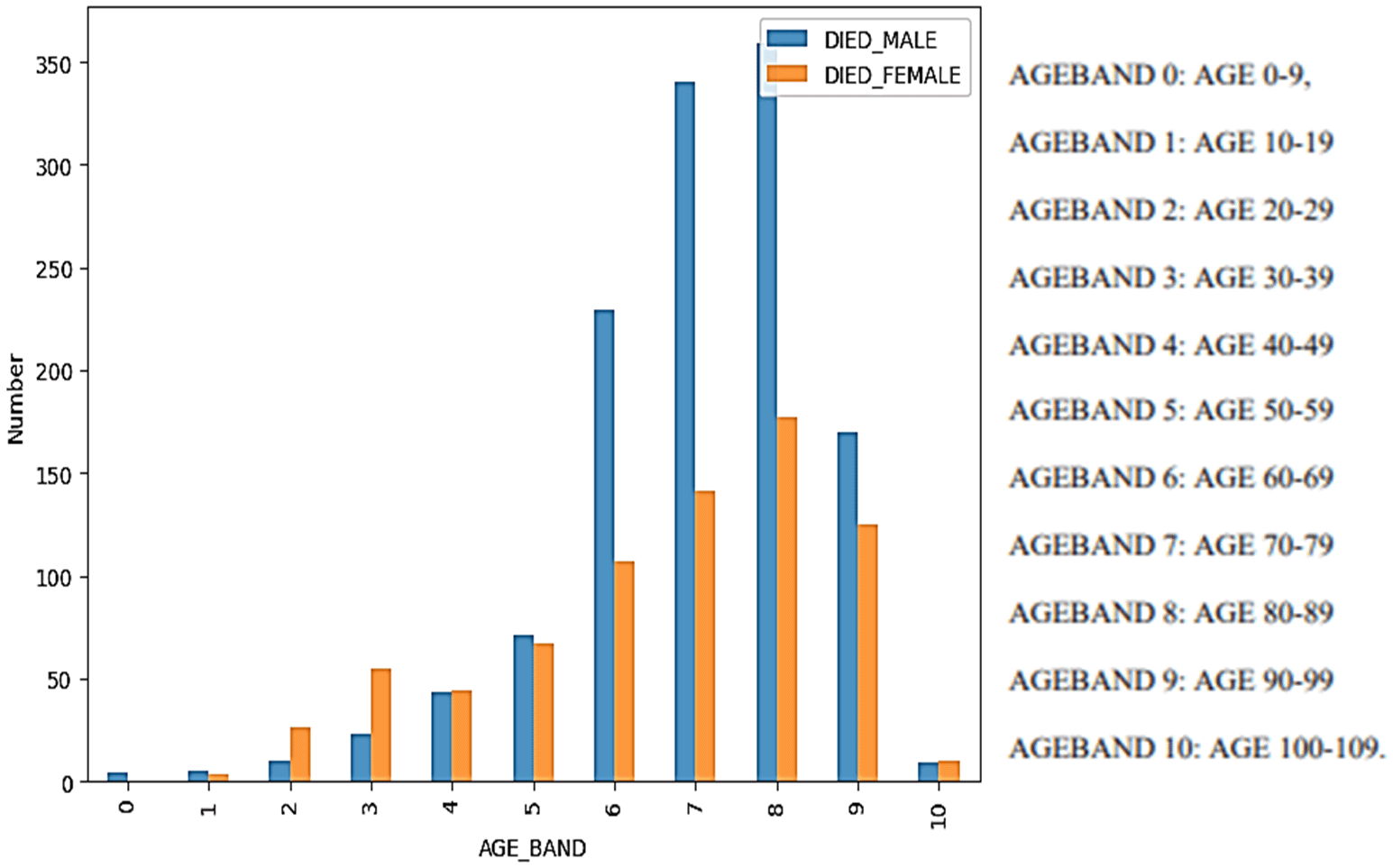
The majority of the individuals, 74% in total, were identified as female It was estimated that the average age of the individuals was about 53 years old and that the average age of those who died was about 72 years. Thus, there is a noticeable age difference between the two groups. In terms of the reported chronic diseases, chronic hypertension emerged as the most prevalent at 13%, followed by asthma at 12%. Kidney issues and anemia were reported in approximately 2% of the cases. Understanding the prevalence of pre-existing conditions is crucial in assessing the potential impact of the vaccine on individuals with specific health conditions. Additionally, a history of allergies, including various types of allergic events not limited to anaphylaxis, was frequently observed, representing approximately 20% of the total cases and close to 25% of the fatality cases (Figure 6). According to reports, 10.7% of individuals who have received vaccinations have died. From Figure 5, one can clearly observe that the majority of COVID-19 vaccination case fatalities are concentrated among individuals aged 70 to 89, regardless of gender, highlighting this age group as particularly vulnerable to severe outcomes. Additionally, a significantly higher mortality rate is observed among males compared to females between the ages of 60 and 99, indicating that males within this age range are more susceptible to severe adverse effects leading to fatalities from the COVID-19 vaccination. These findings underscore the heightened vulnerability of elderly individuals, particularly those in their 70s and 80s, and emphasize the increased risk of severe outcomes among older males.
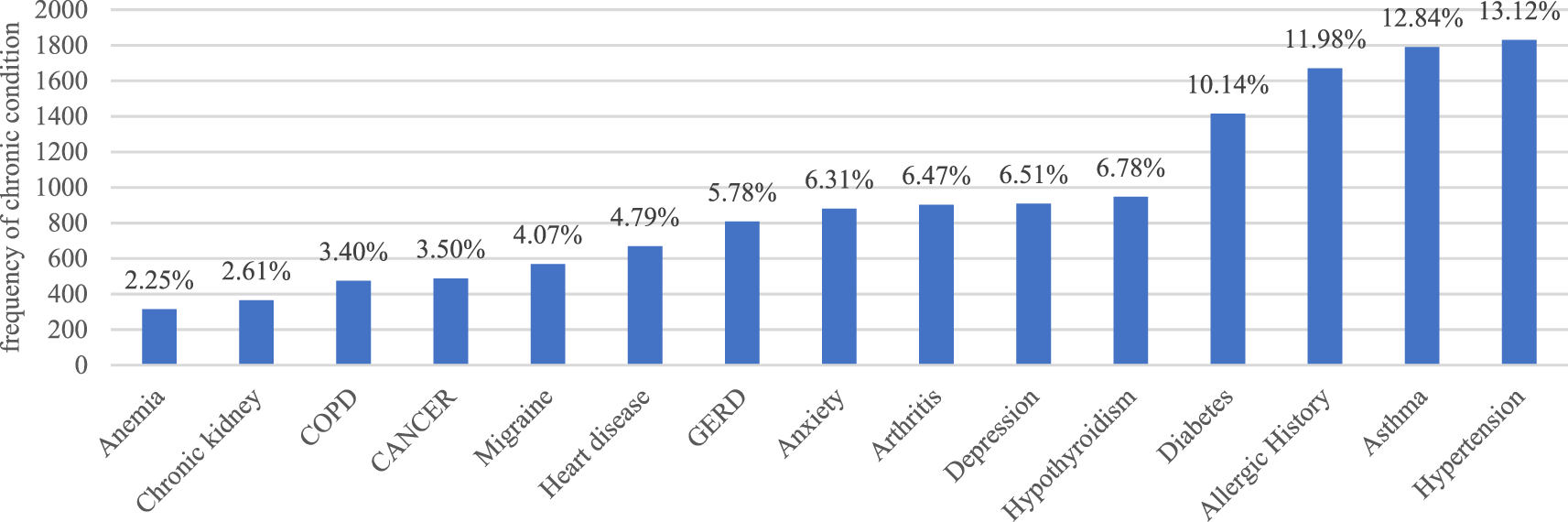
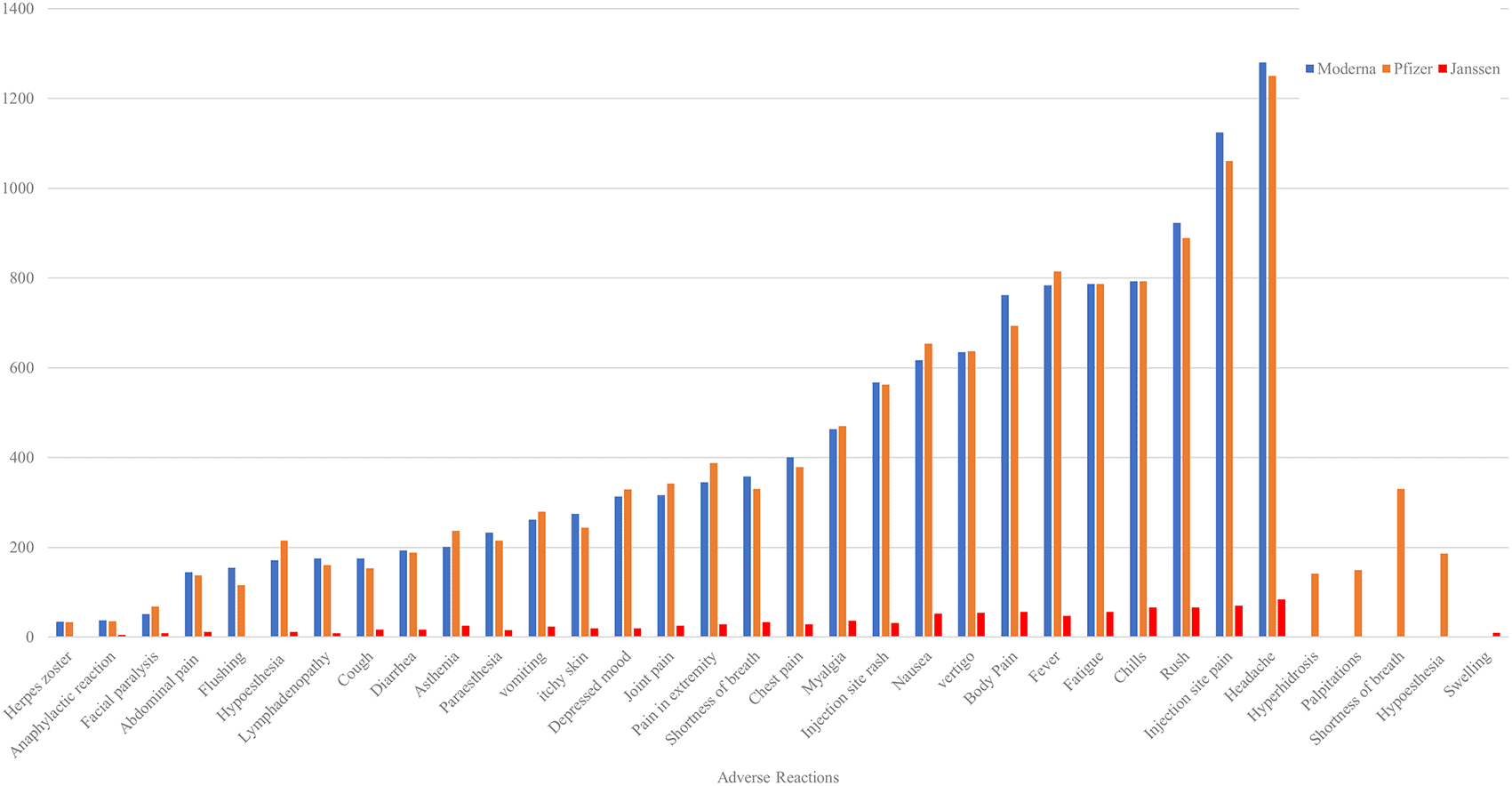
The most frequently reported local and systemic side effects after each of the three available COVID-19 vaccinations include headache, pain at the injection site, rash, chills, fatigue, fever, body pain, and vertigo. These symptoms collectively accounted for nearly 10% of all observed cases, typically presenting as mild and transient, reflecting the body's natural immune response to vaccination. Additionally, several other adverse reactions were commonly reported, including various types of pain, nausea, rash at the injection site, muscle aches (myalgia), and shortness of breath. The incidence of these reactions ranged from 4.8% to 9.4%, while the occurrence of other adverse reactions was less than 5% (Figure 7).
Extensive experiments have been conducted to predict three significant events in COVID-19 vaccination according to different scenarios. ML’s most relevant model to classify vaccines in each scenario includes RF, DT, XGB, and LGBM. We used 80% training data and 20% test data to evaluate the effectiveness of different ML-based approaches. As was previously mentioned, this dataset was unbalanced; therefore, We employed sampling strategies to address this problem. A number of well-known performance measures were used to assess the results of classification, including accuracy, precision, recall, F1 score, and ROC-AUC.
Our results are presented in two parts each with two scenarios: (a) multiclass classification with sampling, (b) binary classification with sampling, and (c) a comparison of the best model for each part.
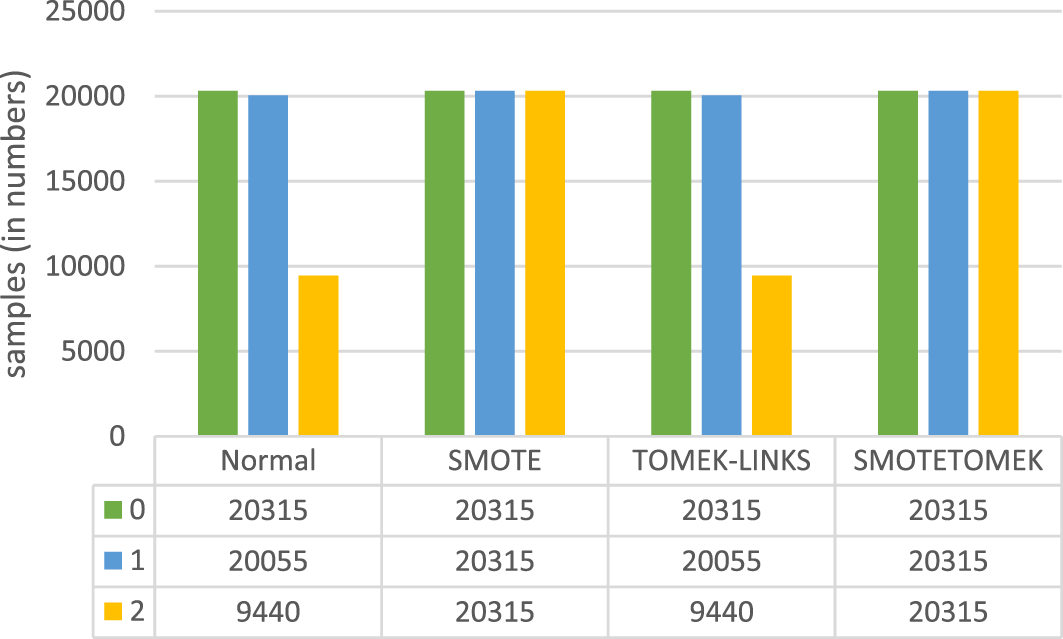
This section presents the results of the multiclass classification for covid-19 vaccine predicting problem, along with the analysis and the discussion. Firstly, we considered the patient’s medical history as independent features and the vaccine type (value 0 means Moderna, 1 means Pfizer, and 2 means Janssen) as dependent features that depend on the independent features. Then each of the three data-sampling procedures—SMOTE, TOMEK-LINKS, and SMOTETOMEK—was applied separately. Figure 6 illustrates the effects of applying various data-balancing techniques.
The performance parameters for each model on the test dataset are presented in Table 2. As a result, the following observations have been noted:
• The testing accuracy values range from approximately 75% to 81% across different models and methods. The Random Forest (RF) models with Normal, TOMEK-LINKS, and SMOTETOMEK methods achieved the highest testing accuracy of around 80.8%, while the XGBoost (XGB) and LightGBM (LGBM) models with Normal, SMOTE, and TOMEK-LINKS methods achieved slightly lower testing accuracy, ranging from 75.2% to 76.2%.
• The training accuracy values are relatively close to the testing accuracy values, indicating that the models are not overfitting to the training data. The training accuracy values range from approximately 76.9% to 81.2%.
• Macro Precision, Recall, and F1 Scores: These metrics provide insights into the models' performance for each class, and the macro averaging considers all classes equally. The RF and DT models consistently show similar precision, recall, and F1 scores across different methods, ranging from around 78.9% to 81.6%. The XGB and LGBM models tend to have slightly lower scores, ranging from approximately 70.5% to 74.6%. The RF models generally achieve the highest scores, while the XGB and LGBM models have the lowest scores.
• The AUC (Area Under the Curve) values represent the performance of the models in terms of their ability to rank samples correctly across all classes. The AUC values range from approximately 78% to 85%. The RF models with SMOTE and SMOTETOMEK methods achieved the highest AUC values of around 85%, indicating better overall performance in distinguishing between different vaccine types.
• Overall, the RF models consistently perform well across different methods, with relatively higher accuracy, precision, recall, F1 scores, and AUC values. The XGB and LGBM models have lower performance compared to RF and DT models. The SMOTE and SMOTETOMEK methods generally improve the performance of the models, as seen in higher AUC values compared to the Normal and TOMEK-LINKS methods. These models achieve relatively high testing accuracy, balanced precision, recall, and F1 scores, as well as high AUC values.
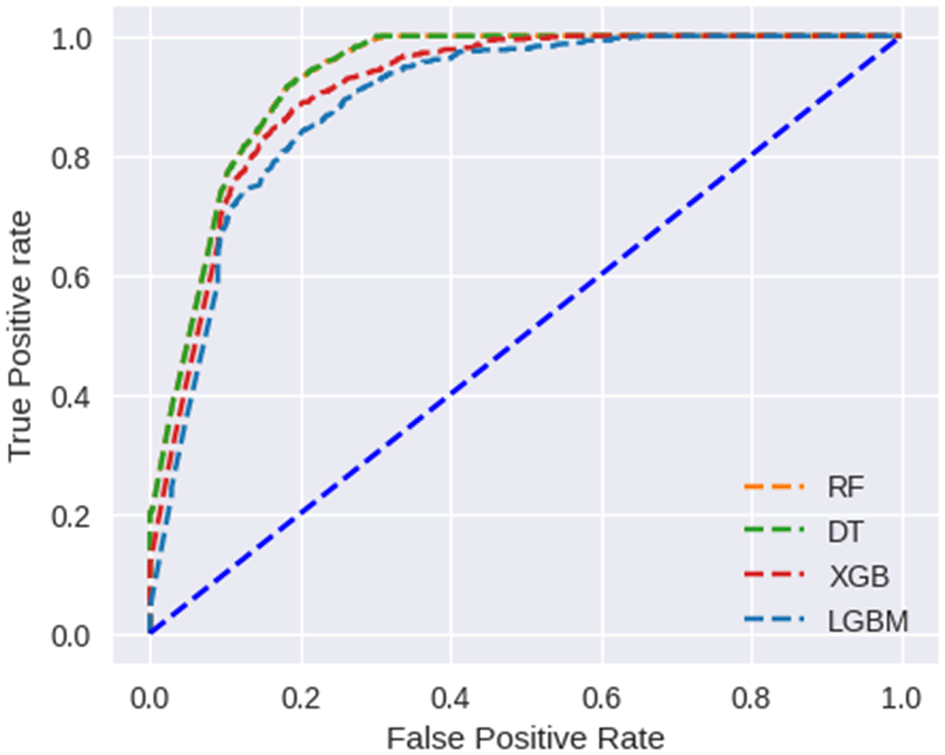
ROC curves have been used to further analyze the predictive capability of these developed models, which are shown in Figure 8. The RF and DT models prove their effectiveness. Taking AUC into account, all developed models perform satisfactorily.

In our model’s analysis, firstly, we considered the patient’s medical history as the independent features, and the vaccine type (value 0 means Moderna and value 1 means Pfizer) and the patient death (value 0 mean alive, and value 1 mean died) as dependent features. We trained and evaluated our models using test data by measuring accuracy, precision, recall, and AUC.
Scenario 1: Based upon both medical history and vaccine type
The performance parameters for each model on the test dataset are presented in Table 3. As a result, the following observations have been noted:
1. RF achieved high testing accuracy (0.87091) and training accuracy (0.87439), indicating good generalization and low overfitting. It demonstrated high precision (0.87974), recall (0.87091), and F1 score (0.87424), suggesting a balanced performance between identifying positive and negative instances. The AUC (0.93) indicates a high discriminatory power of the model. The precision value for both RF and DT was reported as 0.87. XGB and LGBM also show a comparable precision value of 0.86 and 0.0.84, respectively.
2. DT achieved similar testing accuracy (0.86975) and training accuracy (0.87439) as RF. It showed slightly lower precision (0.8779), recall (0.86975), and F1 score (0.8728) compared to RF. The AUC (0.93) suggests a good ability to distinguish between positive and negative instances.
3. XGB achieved a slightly lower testing accuracy (0.85905) and training accuracy (0.86122) compared to RF and DT. It demonstrated comparable precision (0.86031), recall (0.85905), and F1 score (0.8596) to the testing accuracy, indicating a balanced performance. The AUC (0.91) suggests a reasonably good ability to discriminate between positive and negative instances.
4. LGBM showed the lowest testing accuracy (0.84953) and training accuracy (0.85038) among the models. It had slightly lower precision (0.84771), recall (0.84953), and F1 score (0.84857) compared to the other models. The AUC (0.89) suggests a good ability to distinguish between positive and negative instances, although it is lower than RF and DT.
5. The RF and DT models with vaccine-type target consistently achieved the highest accuracy, Recall, Precision, F1 score, and AUC, especially RF outperforms all others. XGB and LGBM models had slightly lower performance metrics but still maintained reasonable accuracy and AUC.
6. Thus, the experimental analysis recommends the RF model is the most suitable for detecting vaccine type compared to the other models.
ROC curves have been used to further analyze the predictive capability of these models, which are shown in Figure 9. The RF and DT models prove their effectiveness. Taking AUC into account, all developed models perform satisfactorily.
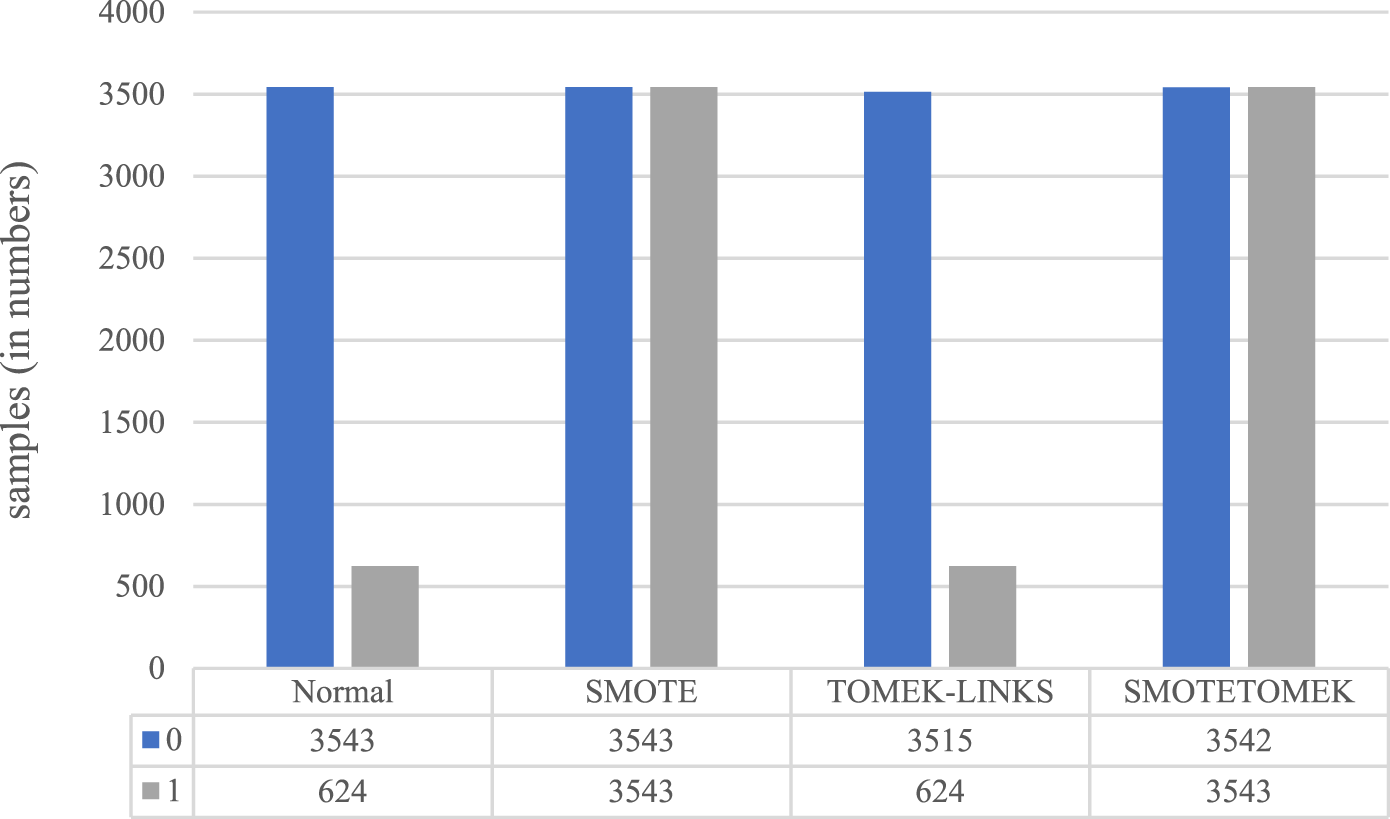
Scenario 2: based upon both medical history and death
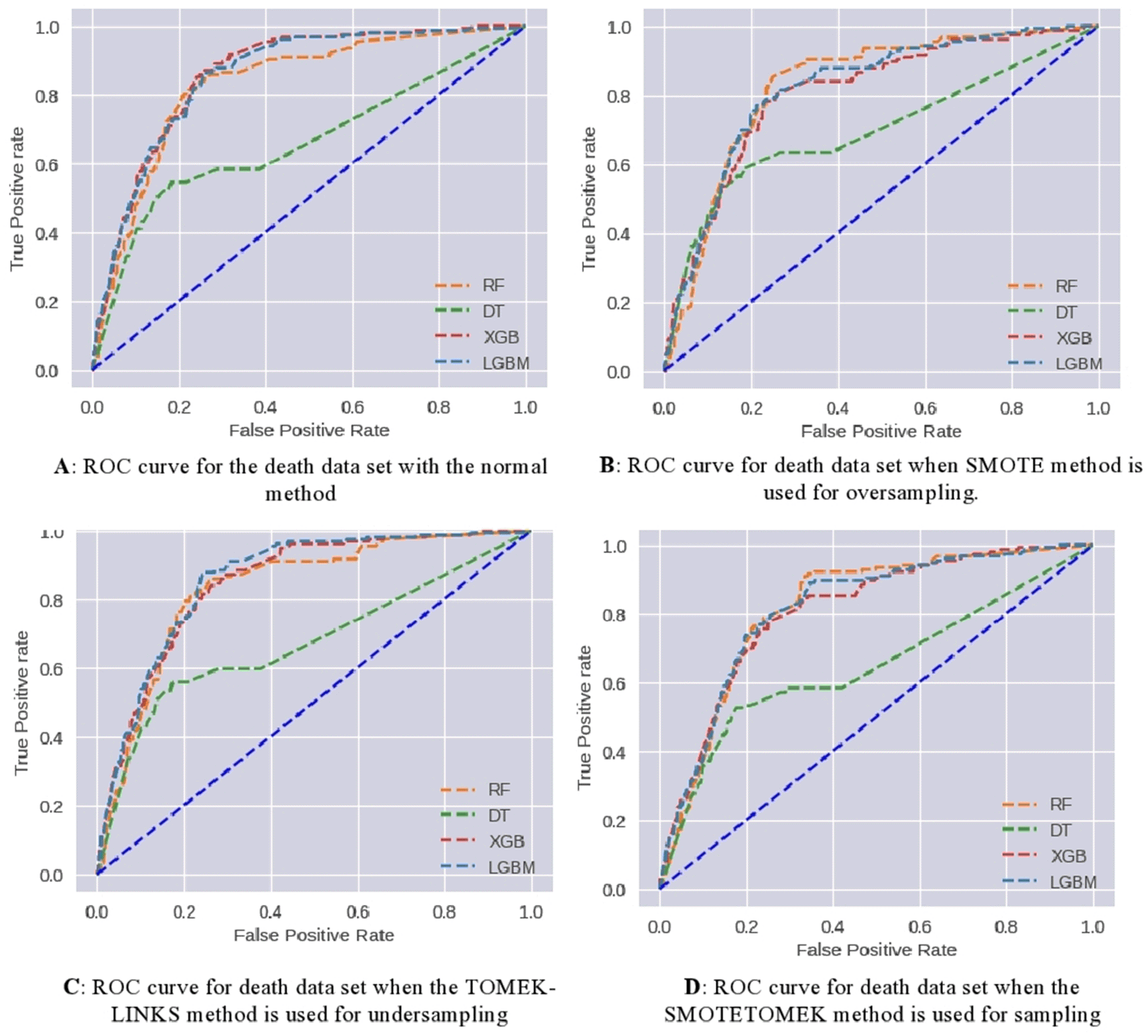
The patient’s death dataset was also experimented with as the vaccine-type dataset. Figure 10 demonstrates the effect of applying various data-sampling methods. The performance parameters for each model on the test dataset are presented in Table 4. As a result, the following observations have been noted:
1. The testing accuracy values range from approximately 79.9% to 85.7%, depending on the model and method used. The RF and XGB models consistently achieve higher testing accuracy compared to DT and LGBM models. Among the methods, TOMEK-LINKS and SMOTETOMEK methods tend to show slightly lower testing accuracy compared to Normal and SMOTE methods.
2. The training accuracy values are relatively high, ranging from approximately 87% to 95.2%. However, there is a notable difference between the training accuracy and testing accuracy values, suggesting potential overfitting issues, especially for the RF models.
3. Precision, Recall, and F1 scores: The precision, recall, and F1 scores provide insights into the models' performance for predicting the positive class (death possibility). The RF models consistently achieve higher precision, recall, and F1 scores compared to DT, XGB, and LGBM models. Among the methods, TOMEK-LINKS and SMOTETOMEK methods tend to show slightly lower precision, recall, and F1 scores compared to Normal and SMOTE methods.
4. The AUC (Area Under the Curve) values represent the models' ability to rank samples correctly and discriminate between positive and negative classes. The AUC values range from approximately 66% to 86%. The RF and XGB models consistently achieve higher AUC values, indicating better overall performance in distinguishing between COVID-19 death possibilities.
5. the models trained on the normal data generally performed better in terms of accuracy and AUC compared to the models trained on the modified datasets (SMOTE, TOMEK-LINKS, SMOTETOMEK). The Random Forest, XGBoost, and LGBM models consistently showed good performance across the metrics in all datasets, indicating their robustness and effectiveness in classification tasks. The Decision Tree model had relatively lower performance, especially in terms of AUC, in all methods.
ROC curves have been used to further analyze the predictive capability of these models, which are shown in Figure 11. The RF and DT models prove their effectiveness. Taking AUC into account, all developed models perform satisfactorily.
The importance of all the features in the COVID-19 vaccine adverse reactions dataset is calculated using the feature importance package from the Scikit-learn Python library. A visual representation of the calculated values for feature importance is displayed in Figure 12. The features are arranged based on their respective importance scores.
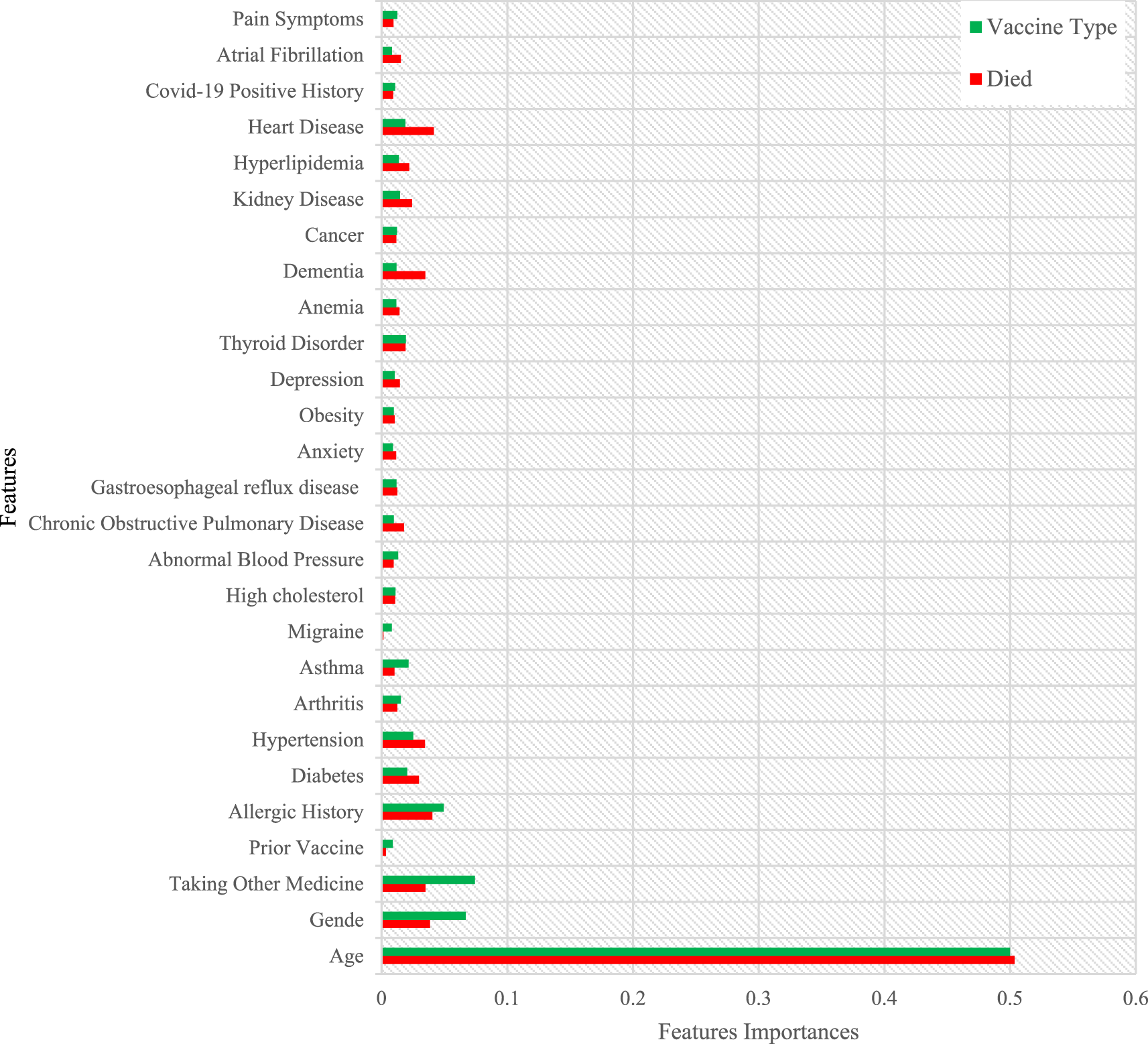
Figure 12 shows that patients' age, gender, and use of other medicines were significant factors in the past medical history of all target variables. WHEN examining the target variable of “vaccine type,” the analysis revealed a comprehensive set of critical attributes within the patient's medical history that strongly influence the selection of the administered vaccine. These attributes include previous vaccine history, allergic history, diabetes, arthritis, hypertension, and asthma. Furthermore, when investigating the target variable of death status, certain factors emerged as highly significant. These factors include heart disease, allergic history, dementia, hypertension, diabetes, kidney disease, and Chronic obstructive pulmonary disease (COPD). These attributes have shown a noteworthy impact on the desired outcome, indicating their importance in predicting the death status of patients.
The patient's age and gender provide essential demographic information that may impact the choice of vaccine, as certain vaccines have age or gender-specific recommendations. Additionally, considering the patient's current medication usage is crucial to ensure compatibility and potential interactions with the chosen vaccine. Previous vaccine history helps determine if the patient requires a booster or a specific type of vaccine.
The presence of underlying conditions such as diabetes, arthritis, allergic history, hypertension, and asthma is highly influential in the decision-making process. These conditions may affect the patient's immune response or make them more susceptible to certain vaccine side effects. By considering these attributes, healthcare professionals can tailor the vaccine type to maximize efficacy and minimize risks for each patient.
This section illustrates the comparison of our proposal model with the results of prediction models that are available in the related works. The comparison was structured around the methodologies employed and the achieved levels of accuracy. Table 5 presents the findings from four distinct studies on COVID-19 vaccine side effects. These studies utilized data from Twitter and the VAERS (COVID-19 World Vaccine Adverse Reactions dataset) spanning across different years. Each study employs a unique set of techniques to achieve specific objectives, resulting in varying degrees of accuracy.
As far as the authors are aware, this is the first study that attempts to predict the type of covid-19 vaccine appropriate for a candidate, along with the death probability risk. Additionally, we suggest approaches to address the issue of imbalanced data concerning adverse reactions to COVID-19 vaccines.
This study has some limitations. Because these data were collected online, we cannot rule out information-gathering bias in the study. Moreover, this data set contained a significant amount of missing data, which may lead to a misrepresentation of patient populations.
In this work, four ML models were evaluated: DT, RF, XGBoost, and LGBM. Three sampling techniques were executed for each model to handle imbalanced data. Below are some of the key findings of the study, which shed light on crucial insights and implications:
1. The tree-based model RF presented the best overall results with multiclass classification.
2. The SMOTE and SMOTETOMEK methods generally improve the performance of the models, as seen in higher AUC values compared to the Normal and TOMEK-LINKS methods.
3. For binary classification in scenario 1, the experimental analysis recommends the RF model as the most suitable for detecting vaccine type compared to the other models.
4. In scenario 2, the RF, XGBoost, and LGBM models consistently showed good performance across the metrics in all methods, indicating their robustness and effectiveness in classification tasks.
5. The Decision Tree model had relatively lower performance, especially in terms of AUC, in all methods.
6. The result revealed that patient age, gender, allergic history, prior vaccine, other medicines, diabetes, hypertension, and heart disease are significant pre-existing factors that strongly influence the selection of the administered vaccine.
According to the study's results, the RF model is recommended for machine learning tasks that demand high accuracy and robustness. While both the XGBoost and LGBM models are also viable options, the RF model could be preferable when dealing with imbalanced data. The effectiveness of these balancing algorithms has been evaluated, leading to the conclusion that no single technique can consistently produce the best results across all datasets. When considering the importance of data distribution, machine learning techniques and balancing algorithms are both crucial.
The findings of this study can be extrapolated to various other datasets related to vaccinations. While the inclusion of medical history features was restricted due to the substantial size of the dataset and the computational complexities associated with processing each disease, there is room for further advancement. By automating the system, its capability to analyze predictions based on a broader spectrum of medical history features can be enhanced. As new data streams into the dataset, fresh predictions can be dynamically generated by this automation, considering the prevailing factors at that specific moment. Additionally, the integration of deep learning methodologies presents an opportunity to uncover latent patterns within the data, thereby enhancing comprehension of the intricate dynamics governing COVID-19 vaccine acceptability. This multifaceted approach is poised not only to augment predictive accuracy but also to deepen the understanding of the nuanced interplay between medical history, vaccination patterns, and evolving epidemiological dynamics.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)