Keywords
Quality of Life, Aging, Machine Learning, ANN, Population
This article is included in the Artificial Intelligence and Machine Learning gateway.
Quality of Life, Aging, Machine Learning, ANN, Population
The World Health Organization (WHO) projects that by 2050, there will be nearly 1.6 billion older people in the world, or roughly 16% of the total population.1 We are currently experiencing significant sociodemographic and lifestyle changes, particularly in industrialized nations, where we are witnessing the shift from an aging to a super-aging population.2,3 Nigeria, the largest nation in Africa with a leading economy, has the 19th-highest percentage of the world’s elderly population, and it is expected that this percentage would almost treble over the next two decades.4 However, the rise of older Nigerians is taking place against a backdrop of utter poverty, unresolved development issues, socioeconomic disparity, and a loss in the traditional support and care of senior citizens.
Human life expectancy has increased globally due to advancements in medicine and social science, leading to the aging of populations becoming a problem for all nations.5,6 While the extension of life expectancy is a significant scientific achievement, it has also resulted in increased expenses for social welfare and care for the elderly.7 This demographic shift has not only influenced disease patterns and increased chronic illnesses worldwide but has also posed socioeconomic challenges for governments and families.8–10 In light of these developments, it is essential to consider the quality of life of the elderly and their preferences during this stage of life. Although everyone desires to live longer, it is more important for both individuals and society to focus on enhancing quality of life and reducing the burden of diseases in old age.11
To address the challenges associated with population aging, the concept of successful aging (SA) has emerged. SA recognizes that the aging process is unique to each individual and encompasses various aspects across disciplines.12,13 Although there is no formal definition for SA, it is widely accepted that it involves being free from chronic illnesses and having healthy physical and mental functioning.14,15 Rowe and Kahn proposed an operational hypothesis for SA, which consists of three components: active engagement in life, absence of illness or impairment, and optimal physical and cognitive functioning.16,17 This hypothesis is widely recognized in academic circles and emphasizes how elderly individuals adapt to the physical, spiritual, and social changes brought about by aging.18,19
The concept of SA has evolved from a single-dimensional focus on the presence of disease or functional decline to a multidimensional perspective aligned with the World Health Organization’s definition of health, encompassing physical, mental, social, and spiritual well-being.20 However, defining this complex and multidimensional phenomenon has proven challenging due to inherent ambiguity.21
The fact that non-genetic factors have a considerable impact on aging in addition to genetic influences is noteworthy.15 There haven’t been many long-term studies on SA, although prior research has usually concentrated on factors that affect SA.22,23 Because of the co-dependence and complexity of the factors impacting SA, traditional statistical models are inappropriate.24 Machine learning (ML) methods have been increasingly important in recent years for handling challenging, multidimensional, and nonlinear issues.25 As a result, it is possible to develop an intelligent model to forecast whether SA will exist or not.
The use of machine learning to forecast and identify social aspects of aging has been studied in some detail. For instance, the authors in Ref. 26 used a sample of 983 to train five fundamental ML models (ANN, DT, SVM, NB, and K-NN) using one ensemble technique. The outcome of the prediction was achieved by implementing a method known as majority voting, which relies on the collective decision of the developed base models. The authors attained 93% accuracy, 92% specificity, and 87% sensitivity. Authors in Ref. 27 created questionnaires and fitness tests to gather the necessary information from the elderly population. The models used were gradient boosting decision trees, random forests, deep learning, and logistic regression. In a study involving 890 samples, a deep learning model demonstrated superior performance compared to other models. The deep learning model achieved an accuracy of 89.3%, a positive predictive value of 85.8%, and a specificity of 93.1%. They came to the conclusion that the deep learning model is excellent for SA maintenance prediction. The use of machine learning approaches to successfully predict aging in the elderly was discussed in Ref. 28. For the analysis, the researchers looked at the SA and non-SA data of 975 elderly persons. The Chi-square test at P > 0.05 was used to determine the factors that had the greatest impact on the SA. In this study, several algorithms such as Adaptive Boost, Random Forest, Artificial Neural Network, Support Vector Machine, and Naive Bayes were employed to develop prediction models. The performance of these models was evaluated using various metrics. The sensitivity, which measures the ability to correctly identify positive cases, was found to be 91%. The specificity, indicating the ability to correctly identify negative cases, was determined to be 98%. The overall accuracy of the models was 95%. The F-test, which assesses the model’s overall performance, yielded a value of 90%. Additionally, the area under the curve (AUC) test, which measures the model’s ability to distinguish between positive and negative cases, resulted in a score of 88.4%. Based on these evaluations, it was concluded that the Random Forest algorithm exhibited the best performance in predicting SA in elderly individuals (presumably referring to a specific condition or event). The previous works, however, have some limitations, including: insufficient data for training the models, class imbalance in the dataset, technique used to replace missing values in the dataset, use of training ratios and hyper-parameter tuning to improve the model’s accuracy, and selection of significant aging-related features in the dataset. In order to get the optimal form of the raw data from the hospital’s electronic medical record, this study performed analysis on enough data while utilizing data preparation techniques and consultations from gerontologists. To increase the suggested system’s predictability, effective feature selection and dropout were also coupled, and classification was carried out using ANN. Therefore, in this study, three key ML models for SA prediction were created, described and evaluated. The main objective was to develop SA prediction models using geriatric data while taking into account sociodemographic, clinical, and lifestyle characteristics in the dataset, which are crucial factors for early SA prediction. In addition, the SA prediction models were used to further investigate key determinants ascertaining progression of the aging condition. The subsequent sections present and discuss the proposed SA prediction system’s development process, the results and conclusion.
Figure 1 depicts the main steps of the proposed system architecture. Data pre-processing, feature selection, model construction, performance measurements, and successfully classifying aging are among the phases. The original dataset, which is unstructured and not beneficial for the design of the model, is created during the data pre-processing stage by sorting out variables from the electronic medical records of elderly patients. Additionally, feature selection was utilized to separate the features that are redundant from the features that support accurate prediction in the system and to extract the significant variables that are relevant to successful aging. Thirdly, Support Vector Machine, Naive Bayes, and Artificial Neural Network were among the prediction models developed for this study. During the developmental process, particular hyperparameters for the SVM and NB models were carefully selected. Thereafter, the preprocessed data, was inputted into the model, using it to train the classification model. A better learning pattern for predicting successful aging is provided by the ANN model in combination with a dropout strategy. The combined technique offers increased classification accuracy, specificity, and sensitivity when compared to the other models. ReLu and sigmoid activation functions are used in the network’s hidden and output layers during the training and testing phases, respectively. Initially, three core classification algorithms, namely artificial neural network (ANN), support vector machine (SVM), and naive Bayes (NB) models, underwent training with the purpose of identifying whether an individual possessed the status of SA or non-SA. Then, the best hyperparameters and training ratios are used to increase the models’ predictive accuracy.
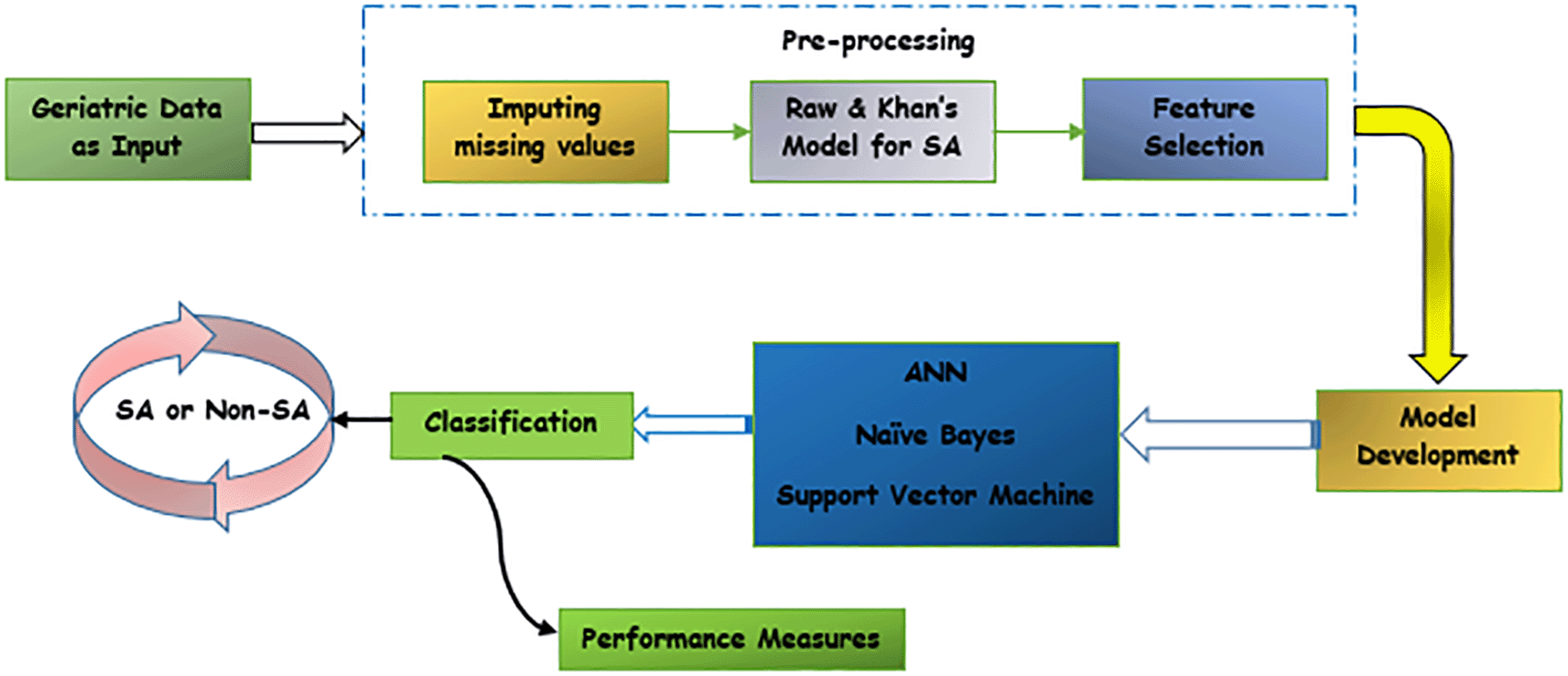
The present study is retrospective and concentrates on sociodemographic, clinical, behavioral, and psychological parameters for the assessment of specific patients by accessing the medical records of older (> 60 years old) patients.29 There are multiple variables based on the preliminary data gathered. The machine learning model’s performance was validated while the most useful features from the gathered data were taken out and used as input parameters. Additionally, the factors linked to successful aging were determined through interactions with gerontology experts and analyses of relevant literature. The description of the output class variables (i.e., SA & Non-SA), are as follow: age, sex, reading proficiency, marital status, occupation, and income level are the seven parameters considered in this category of socio-demographic factors.
The clinical factors involve diseases including hypertension, heart disease, kidney, liver, bone, and muscular disorders as well as depression, eye and eyelid disorders, diabetes, and cancer.
The ability to carry out daily living activities (ADLs), life satisfaction, quality of life (QOL), a healthy lifestyle, interpersonal relationships, nutrition, physical activity, illness prevention strategies, and stress management are all included in the category of behavioral and psychosocial factors. The sociodemographic and clinical information was taken from medical records of elderly persons.
The outcome variable was split into SA-related (coded 1) and non-SA-related (coded 0) classes. Rowe and Khan’s approach,16 which consists of three fundamental elements such as maintaining good mental and physical function, ongoing involvement in life, and lack of disease and disease-related disability was used in this study to quantify SA.
For this study, 2000 older persons were included in the dataset that was taken from the Afe Babalola University Multi-System Hospital’s electronic medical record between January 2019 and April 2023 in Nigeria. The ethics research committee of the hospital granted access to conduct the study (Approval Number: AMSH/REC/AVA/133) with requirements of complying with all international guidelines and regulations. The data collected for this research was retrospective and did not involve interviews with participants. All data used in this research were anonymised and do not reveal the patient’s identity in any form. Several techniques for data pre-processing were employed to generate optimal models. The dataset employed in this study contained certain missing values. Excluding these instances from the dataset would diminish the overall quality of the data, as they could potentially possess vital information that could influence the accuracy of predictions. However, a range of methods exist to address the issue of missing values and rectify the dataset, one of which was employed to address the issue. The gaps created by the missing values were filled in using the mean value of the corresponding feature in the data set. Another problem with the data that had been acquired was data that was out of balance. An uneven data class distribution is when one class has a disproportionately smaller number of samples than the other. This decreases the effectiveness of ML algorithms.30 The dataset includes 2000 records of both successfully aged and unsuccessfully aged persons after pre-processing and balancing. Based on the absence of fewer than or equivalent to two diseases, quality of life, nutrition, and capacity for daily activities, the data was categorized as SA. Following classification of the full dataset, there were 1100 occurrences of SA and 900 instances of Non-SA.
The feature selection strategy was used to reduce the dataset dimension and enhance ML performance. Feature selection is a crucial technique in data mining that plays a significant role in eliminating redundant and irrelevant features. It holds immense importance as it helps filter out duplicate and unrelated features from the dataset. Through feature selection, statistical techniques are utilized to reduce the dataset dimension. In a summary, this method’s advantages include better comprehension, avoiding algorithm overfitting, boosting processing power, and enhancing mining performance.31,32 With the help of gerontologists and the identification of pertinent data that is relevant to the results of successful aging in the aged group, features for our model were sorted based on Rowe and Khan’s model for successful aging as well as their model for successful aging.
Age, hypertension/CVD, renal illness, liver disease, neuromuscular disease, depression, eye disease, diabetes, cancer, ADLs, Nutrition Status, and quality of life (QOL) were the determinant variables that were most pertinent to SA. These characteristics were therefore thought to be the most important ones in defining SA in elderly people. The dataset has information like marital status, occupation, educational level, gender, and hospital department removed from it. This was done to increase the precision, sensitivity, and accuracy of all produced models. Figure 2 shows the correlation between selected features in the extracted dataset, and a maximum correlation is observed between renal disease and the ability to carry out daily activities.
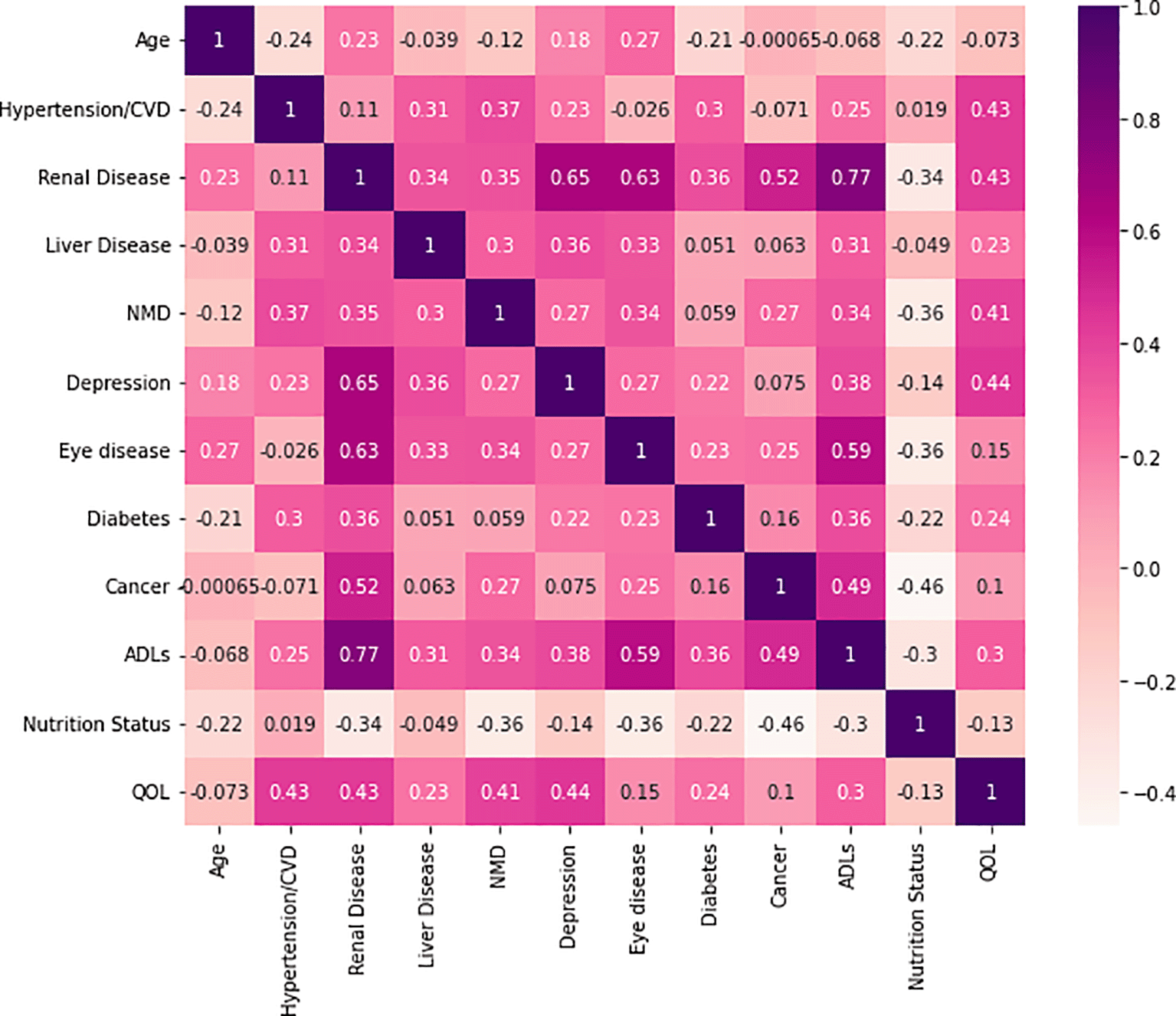
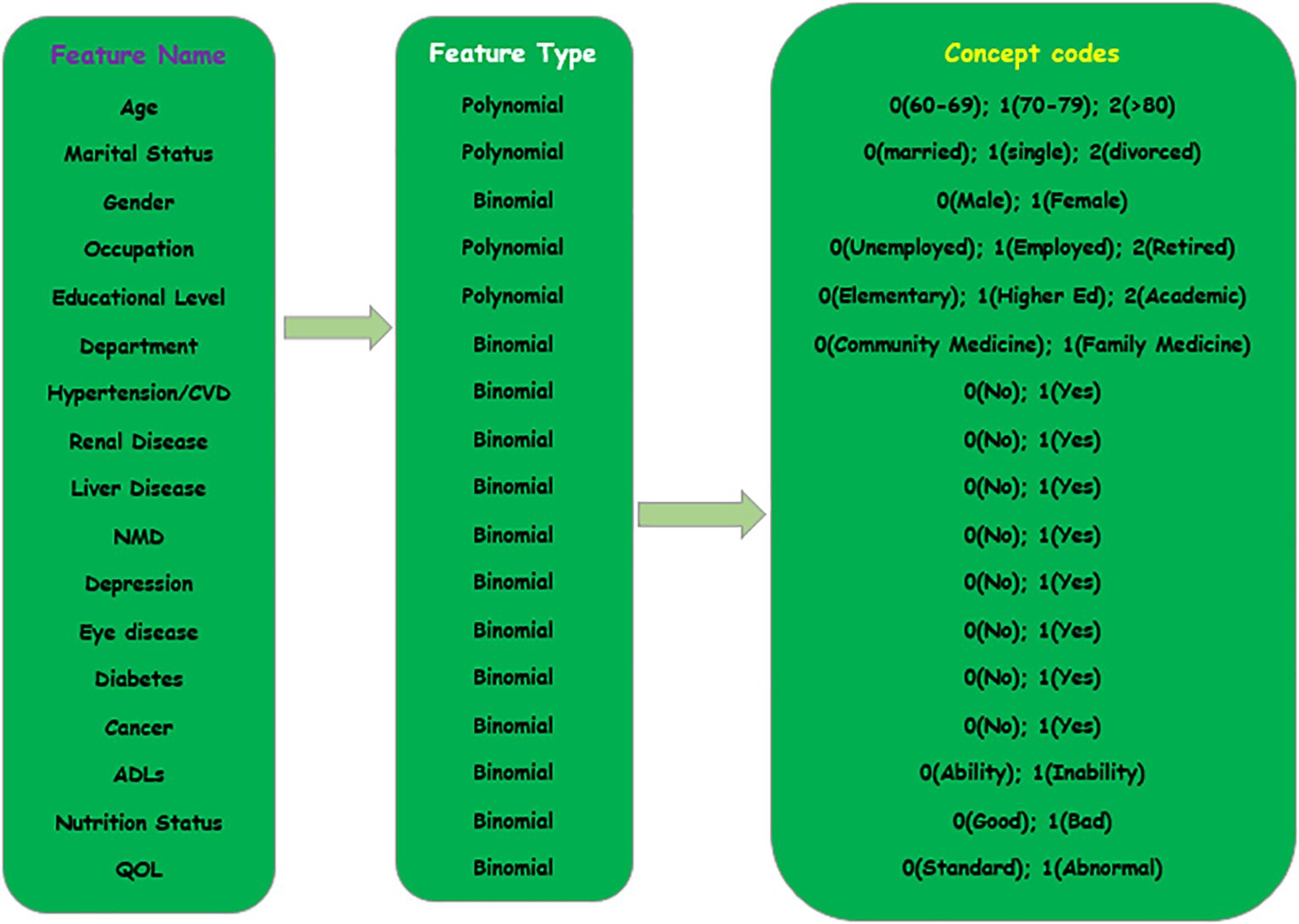
Figure 3 denotes the variables in the dataset including the feature name, feature type, and concept codes. In the dataset, NMD represents all categories of neuromuscular diseases, while QOL refers to the quality of life of each individual, and lastly ADLs represents the ability of aged people to carry out daily activities regularly.
For SA prediction, three supervised learning approaches were used. The elderly individuals were classified as either SAs or non-SAs using the ANN, Naïve Bayes, and Support Vector Machine algorithms.
ANN: An artificial neural network (ANN) is a technique in machine learning that emulates the natural information processing mechanisms of the human brain. Numerous processing units (neurons) make up the neural network’s structure, and they communicate with one another via weights. A nonlinear mechanism in the neural network enables parallel processing, learning, and decision-making. An ANN modifies its weighted connections by using a variety of learning cases. One of the process’s outcomes is to modify the network’s settings so that it can be retrained in a different environment.33
Naïve Bayes: This algorithm’s characteristics are assumed to be unrelated to one another. It is the Bayesian theorem generalized. NB calculates the likelihood that a data sample belongs to a specific class as part of its process because it is a probabilistic model.34,35 NB is another name for independent or simple Bayes. The development of this technique is straightforward and does not necessitate difficult initial parameter estimates. As a result, it offers tremendous accuracy and speed when handling large datasets and can be applied to enormous amounts of data. However, this technique has problems with conditional class independence and access to data probabilities.36,37
Support Vector Machine: According to Zach,38 the Support Vector Machine (SVM) is a supervised learning technique utilized for classification and regression tasks. Its primary purpose is to identify the most effective classifier that can divide a given dataset into two distinct classes. When dealing with datasets that can be linearly separated, the SVM employs a linear function to determine a hyperplane that passes through the middle of the two classes. Notably, there exist multiple potential hyperplanes for separation in such cases. However, the SVM ensures the identification of an optimal function by maximizing the margin between the two classes. The margin, as described in Ref. 39, refers to the degree of separation between the classes, which is represented by the hyperplanes. In the field of machine learning, hyperparameters refer to the parameters used to regulate the learning process. They are predetermined values that are set before the model begins learning, with the aim of enhancing the learning outcomes. It is worth noting that not all hyperparameters carry equal significance. The effectiveness of the ML algorithm is more significantly impacted by some hyper-parameters than others. Table 1 lists the hyperparameters that we employed in our models.
The training and hyperparameters tuning processes are part of the classifier design process. The Support Vector Machine, Naive Bayes, and Artificial Neural Network are the classification models investigated. For all generated models, training was typically done on between 50% and 70% of the dataset. Table 1 lists the optimized hyperparameters used in various iterations of the Naive Bayes and Support Vector Machine models.
Initially, epochs of 100 and 250 were utilized to train the ANN model; however, later in the experiment, a batch size of 32 and 500 epochs was used for adequate training. In order to find the best model configuration, we initially trained our models on a variety of train/test ratios (40/60, 50/50, 70/30, and 60/40). The 70/30 and 50/50 configurations produced the best accuracy with the least amount of over-fitting, and were thus presented in this study as the ideal model. The Adam optimizer was used to train the model, and network hyper-parameters like the number of hidden layers and activation function were modified as well. The ReLu activation was then used in all hidden layers, while the output layer for classification made use of a sigmoid activation function. To reduce over-fitting and improve the model’s accuracy, the dropout technique40 was applied. The proposed framework was created in Python using the Anaconda IDE and built-in modules including Scikit-Learn, Keras, Tensorflow, Numpy, and Matplotlib. All experimentation was carried out on a Dell Precision WorkStation Computer with 8GB RAM, 1TB HDD and a 3.3GHz Core i5 processor. The test dataset was used to assess the prediction performance of our model, and 20% of the test dataset was used for validation.
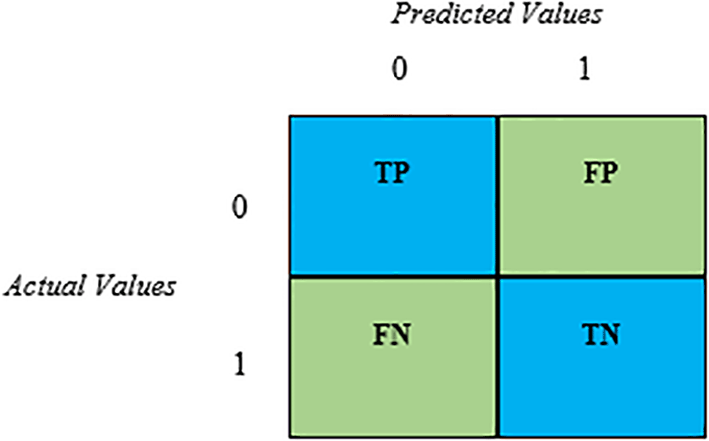
In this investigation, cross-validation was not employed. Since the dataset contains sufficient samples for both training and testing, the holdout validation technique was employed instead of the cross-validation method. Following the model’s training, the performance of the SVM, NB, and ANN models was assessed using the testing dataset. The most used metrics, including accuracy, precision, sensitivity, specificity, and F1 score, were utilized to assess performance. Accuracy is an indicator of the model’s classification or validation (training) accuracy. The number of true positives, true negatives, false positives, and false negatives can be estimated with the aid of a confusion matrix (Figure 4), which further assisted in evaluating the effectiveness of the suggested model. Table 2 provides the formulas needed to calculate the aforementioned measures.
| Performance metrics | Formulas |
|---|---|
| Accuracy | |
| Precision | |
| Specificity | |
| Sensitivity | |
| F1 Score |
Accuracy: This measures the proportion of accurate predictions to all other predictions.
Precision: a metric employed to assess the accuracy of a model in predicting positive outcomes. It measures the number of cases in which the model correctly projected a positive outcome out of all the instances it predicted as positive. It simply quantifies the ratio of true positive predictions to all the positive predictions made by the model.
Sensitivity: It is a measurement of how accurately the model has identified the good examples. It is described as the proportion of genuine positive predictions to actual positives.
Specificity: It is used to gauge how many true negatives the model accurately detected.
F1 score: It can be interpreted as the weighted harmonic mean of the precision and sensitivity.
The dataset is divided into four main groups in each of the experiments conducted in this work in order to employ the equations in Table 2: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN).
This section presents the findings that were drawn from the study. First, the findings from all experiments conducted on 50% of training are reported. The findings from experiments conducted on 70% of training are shown in the second section. The classification outcomes based on the actual information available are displayed in the confusion matrices. Each sample can belong to either of the two classes, 0 for unsuccessful aging or 1 for successful aging, as the dimensions of these matrices are 2*2, meaning there are two classes of data. The various performance measurements are defined in accordance with the results of the confusion matrix’s calculations. In order to comprehend how the datasets performed during the experiment utilizing the previously designed models, graphs and tables are also given and interpreted. Additionally, all three models’ performances are contrasted and critiqued.
Experimental results on 50% of training
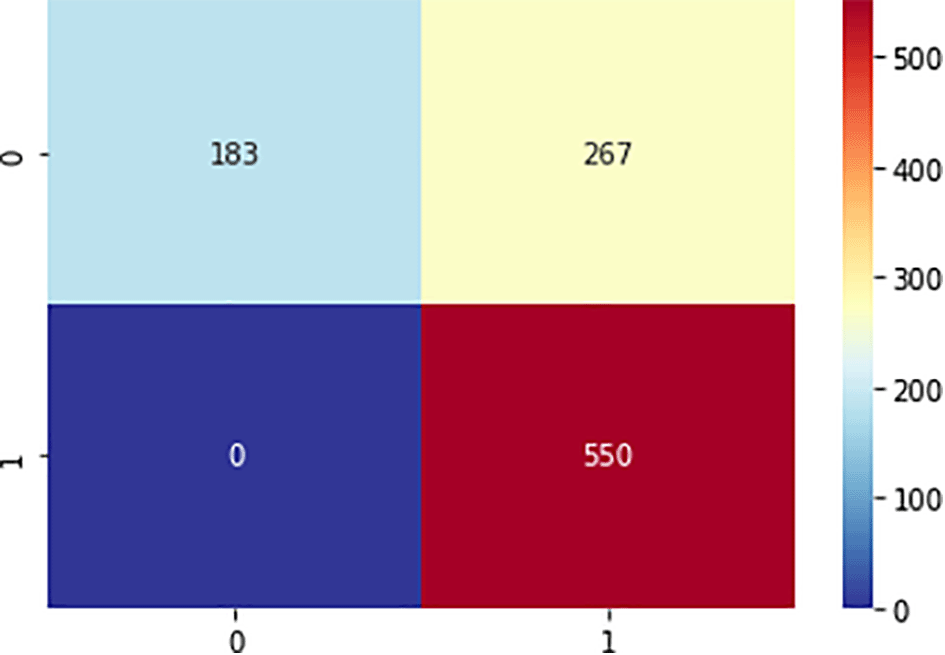
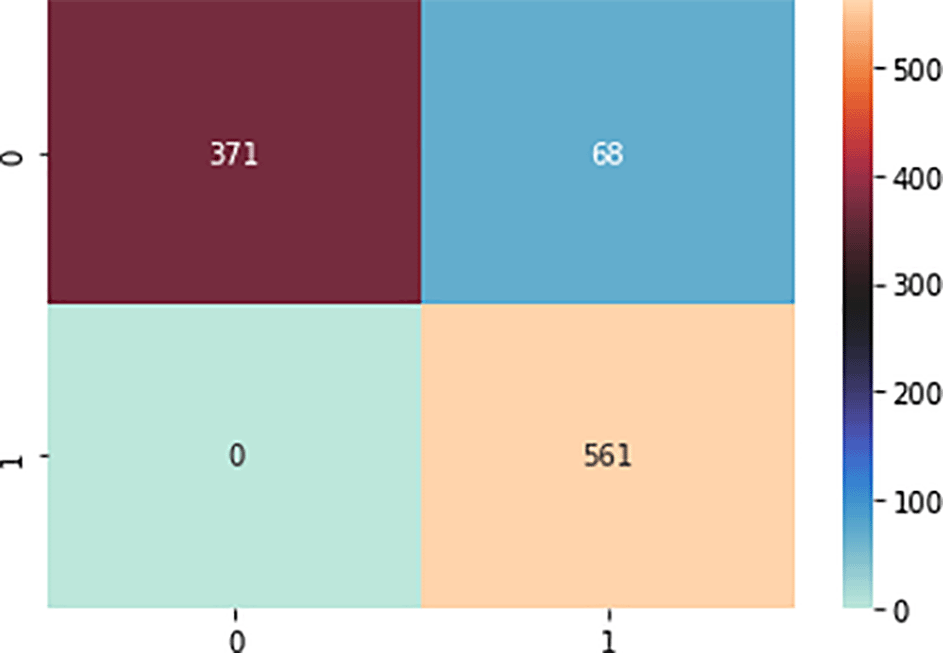
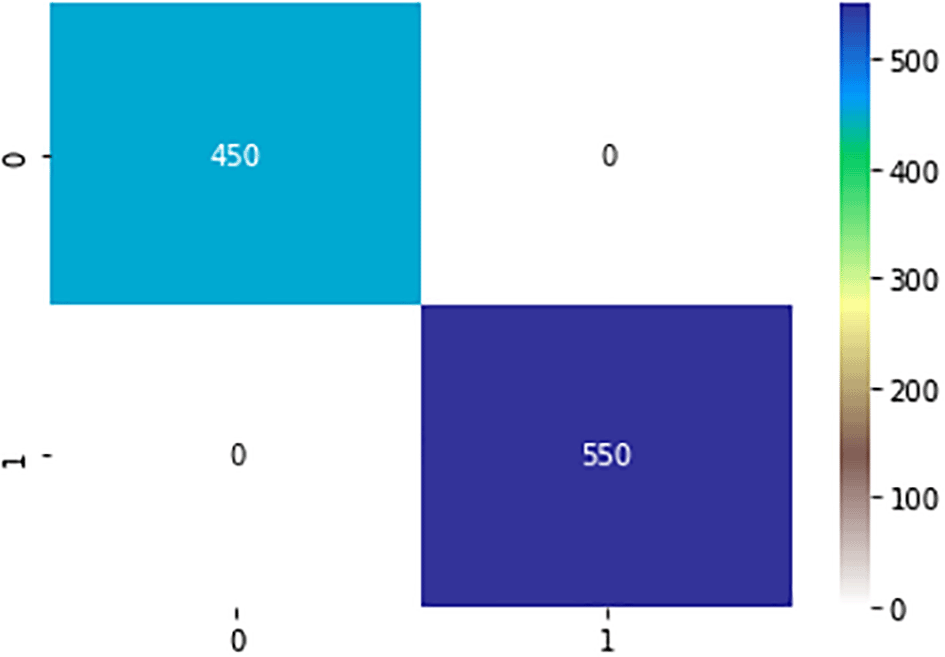
In this study, half the samples (1000 samples) were used for testing and the other half (1000 samples) for training. The confusion matrix in Figures 5, 6, and 7 were used to assess the ML algorithms (SVM, NB, and ANN). The confusion matrix was used to calculate the values of the performance measures. Figure 5 shows that the SVM model can accurately predict 550 cases of SA, whereas there were no cases of SA that were misdiagnosed. The model also properly predicted 183 non-SA cases while mispredicting 267 non-SA cases. The developed model yielded a 73.3% accuracy and a 67.3% specificity. Even though the SVM model had a sensitivity of 100%, it does not determine the total efficiency of the model when presented with unseen data in a large scale as it is evident in the F1 score (57.8%) of the said model. Figure 6 shows that the NB model can accurately predict 561 cases of SA, whereas there were no cases of SA that were misdiagnosed. Additionally, the model accurately forecasted 371 non-SA cases while mispredicting 68 non-SA cases. The generated model gave results with a precision of 84.5% and an accuracy of 93.2%. The NB model outperformed the SVM model by a large margin, and it is expected to be effective in forecasting successful aging in a fresh dataset. The confusion matrix for the ANN model on 50% of training, which correctly predicted 550 and 450 instances of SA and non-SA, respectively, is shown in Figure 7. With a 6.8% increase in accuracy, the ANN model with dropout fared better than the NB model.
Experimental results on 70% of training
For this experiment, 70% of the samples (1400 samples) were assigned for training and 30% (600 samples) for testing. The confusion matrix is shown in Figures 8, 9, and 10 for the evaluation of the three machine learning methods (SVM, NB, and ANN). The confusion matrix was used to calculate the values of the performance measures. Figure 8 shows that the SVM model can accurately predict 330 SA instances, whereas there were no cases of SA that were misdiagnosed. Additionally, the model accurately forecasted 178 non-SA cases while mispredicting 92 non-SA cases. The SVM model that was designed generated accuracy and precision of 84.7% and 65.9%, respectively. Figure 9 shows that the NB model can accurately predict 332 SA instances, while there were zero cases of SA that were misdiagnosed. Additionally, the model accurately forecasted 224 non-SA cases while mispredicting 44 non-SA cases. The created model generated accuracy and precision of 92.7% and 83.6%, respectively. The NB model outperformed the SVM model by a large margin, and it is expected to be effective in forecasting successful aging in a fresh dataset. The confusion matrix of the ANN model, which was trained for 70% of the time, is shown in Figure 10, where 330 and 270 instances of SA and non-SA, respectively, were correctly predicted. With a percentage gain of 16.4%, the ANN model with dropout surpassed the NB model in terms of precision.
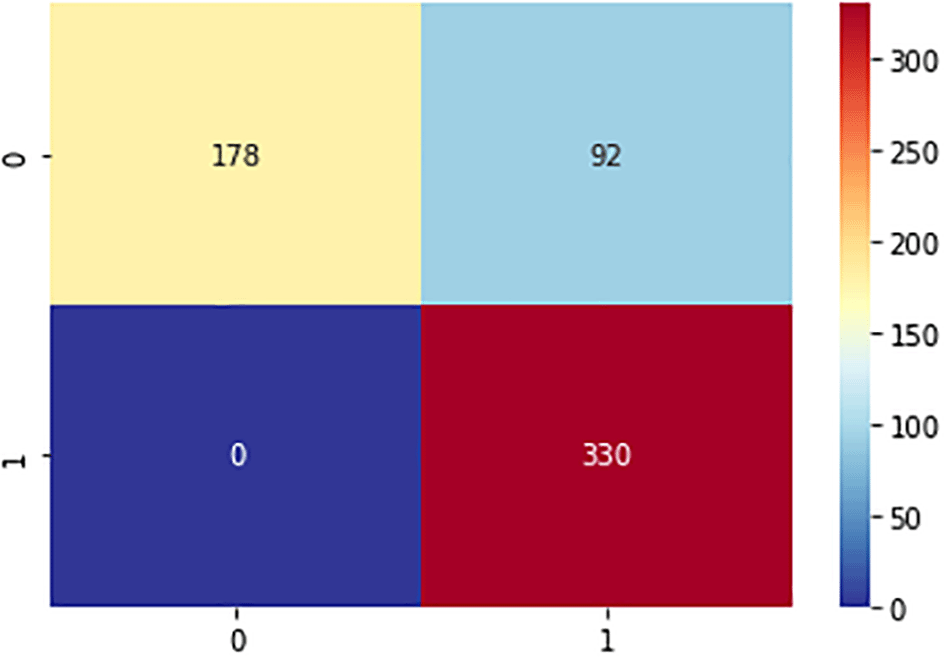
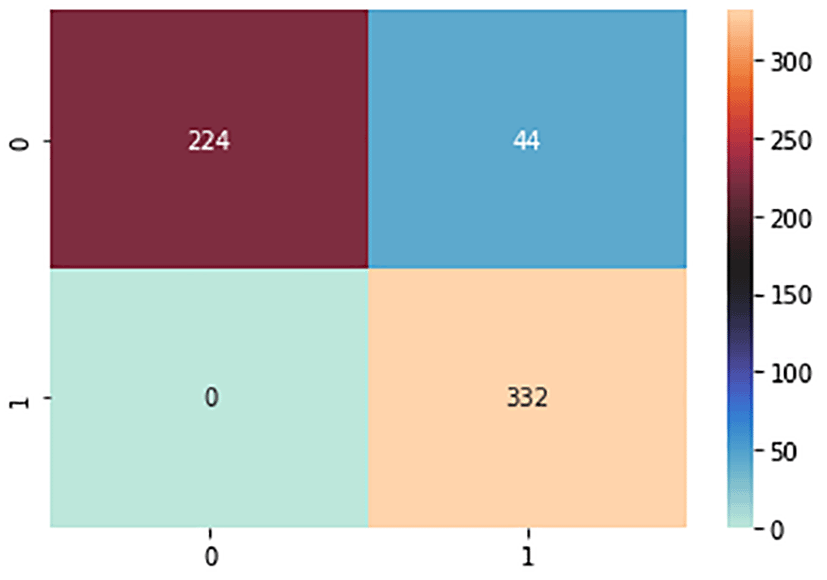
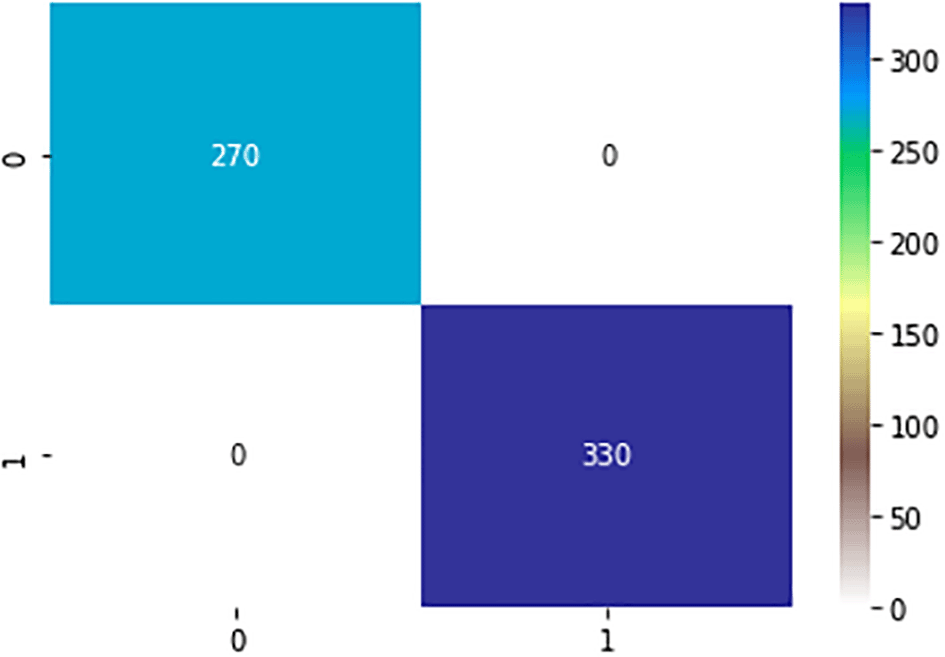
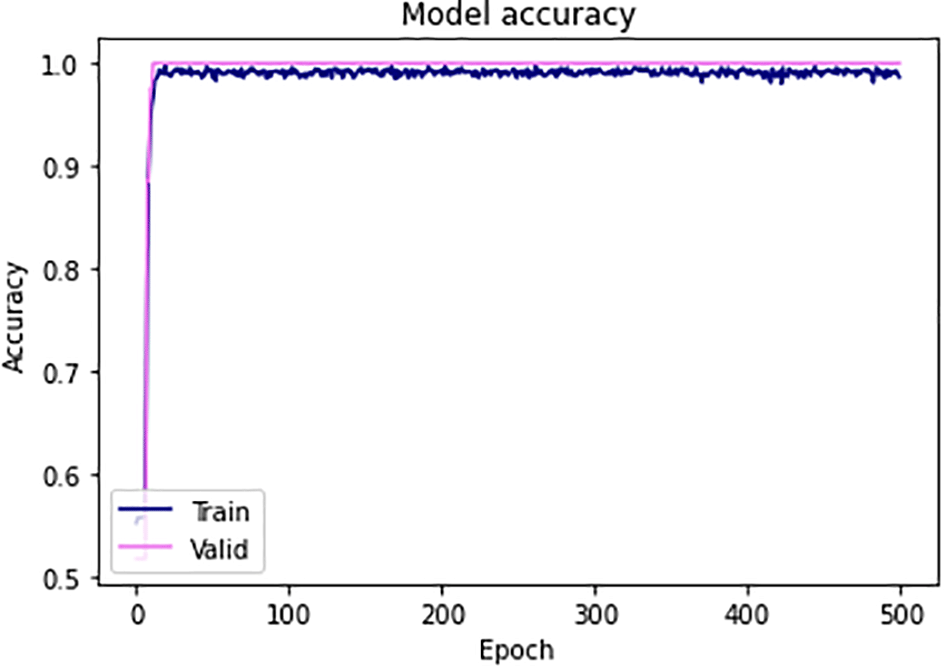
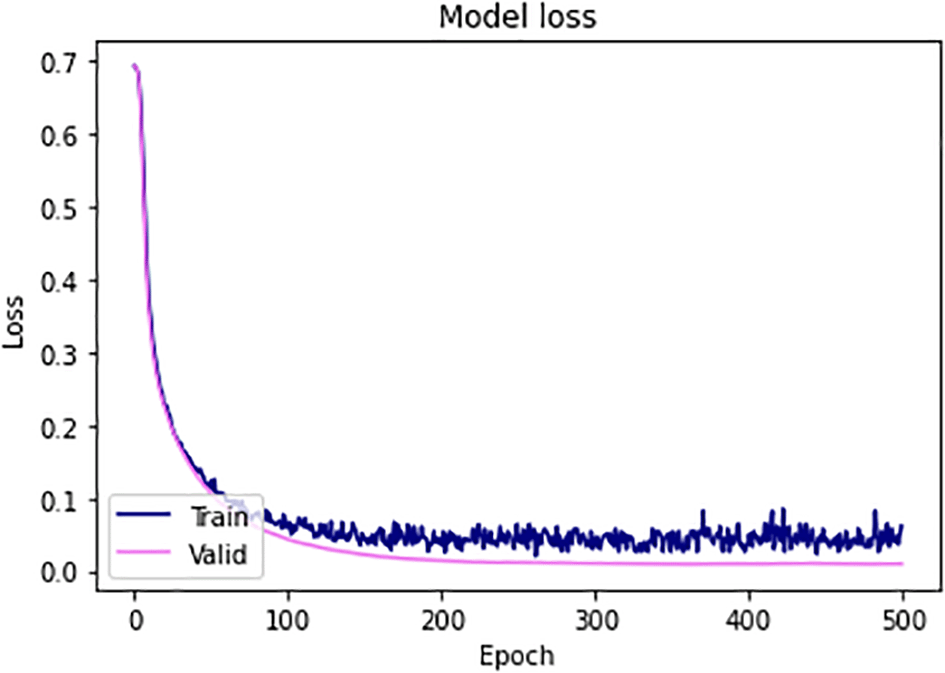
Figure 11 shows the accuracy plot of the ANN model. Between 50 and 100 epochs, the train’s accuracy grew from 0.8 to 0.9. At 300 epochs, the validation accuracy was 0.92, and it grew from there. The reported average training accuracy was 100%. The graphic shows that the ANN model is not over-fitting, which suggests that the model can be used to successfully predict aging in the event of new data. Figure 12 shows the model’s training and validation losses. The loss function had reached its lowest after training, or 500 epochs, as seen in the graph. As supported by research, the ANN model’s low loss function has significance in providing accurate predictions on successful aging.
The performance results of all created ML models are displayed in Table 3. The number of individuals whose classifier has assigned them to a positive class (SA) and who are positive is calculated as part of the precision criterion. The proposed ANN model has the best performance by this criterion, whereas the SVM model is the least efficient technique. The NB50 model’s precision value is 93.2%, which is 0.5% higher than that of the NB70 model. The sensitivity criteria had the best value for the ANN/SVM/NB algorithms. The sensitivity criteria are crucial for locating every SA-positive person in the dataset. When it comes to identifying everyone who does not have SA, the ANN50/ANN70 model performs better than other ML models. This suggests that when these models achieve a value of 100%, they demonstrate the highest level of success in terms of specificity. When an algorithm can strike a favorable equilibrium between sensitivity and specificity, it is considered to be highly efficient. The best balance between these two requirements has been established by the optimal design suggested in this research. The F1-score, which takes into account both sensitivity and precision parameters, has a value of 100% in ANN-based models and is higher than that of the NB50/NB70 models (91.6%/91.1%).
Accuracy is the most fundamental and direct indicator of a classifier’s performance, and it typically manifests itself in the accurate detection of samples. Additionally, the SVM model has the lowest classification accuracy (73.3%), and the best classifier among the other models is the ANN-based approach, which has a value of 100%. Figure 13 shows a bar chart that contrasts the machine learning algorithms designed according to their F1 score, specificity, sensitivity, accuracy, and precision.
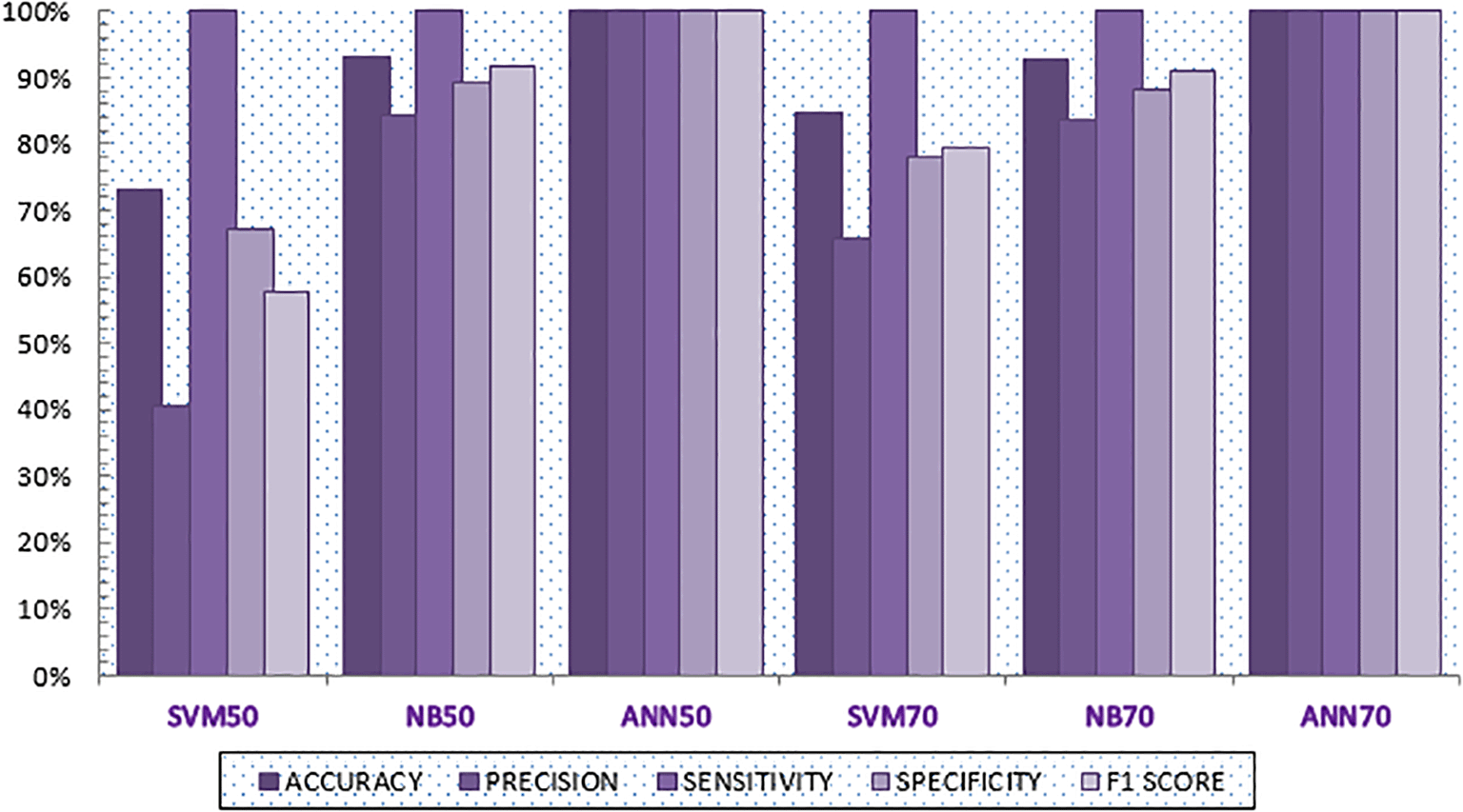
This study assessed subjective well-being by examining three key dimensions: physiological, cognitive psychological, and social functioning. This approach aligns with Rowe and Kahn’s theory.18 In order to determine if a person has SA or not, we developed prediction models that would utilize clinical and lifestyle factors as inputs. Our findings offer important new perspectives for determining SA likelihood. According to our main hypothesis, the proposed ML technique produced a potent SA status classifier. Here, we introduced a novel approach that uses three key ML techniques to forecast SA.
A prediction model can be created using a variety of ML methods. The numerous fundamental model assumptions in use today’s ML approaches preclude successful application. The optimal method for dealing with a dataset that is both highly variable and noisy, such as the case with successful aging data, which is inherently diverse and inconsistent, remains uncertain. This is because it is frequently challenging to verify fundamental assumptions. Furthermore, no single ML technique yields reliable prediction outcomes. Scientists and researchers are continually seeking well-trained machine learning models that demonstrate accurate and reliable performance on a consistent basis. However, in reality, only a few biased models can occasionally be produced, therefore training model outputs are not always flawless.
Table 4 presents a collection of studies that have explored the utilization of machine learning techniques to forecast and recognize instances of successful aging through diverse approaches. In this study, these studies were compared with the proposed approach. In addition, we provided an ANN-based technique to determine whether the tested individuals fall into the SA category or not. The data was preprocessed in the first phase to make it appropriate for use in data mining analysis. Thereafter, ANN was introduced, which proved more effective in predicting the SA than previously developed ML models such as SVM and NB. The results of the experiment demonstrate that by employing a holdout validation approach, the predictive system achieved outstanding performance in forecasting SA. It achieved perfect precision, specificity, accuracy, and F1-score, all reaching a flawless 100% level.
| Authors | Purpose | Classifier(s) | Accuracy (%) |
|---|---|---|---|
| 41 | Prediction of mental impairment in aged people | Ensemble classifier | 87.4 |
| 27 | Prediction of SA maintenance | Deep learning | 89.3 |
| 26 | Prediction of SA | Ensemble KNN | 89.6 |
| 28 | Prediction of SA | Random Forest | 95 |
| Implemented work | Prediction of SA | Artificial Neural Network | 100 |
Based on the findings of the current study, the examined machine learning (ML) methods demonstrate consistent accuracy in predicting successful aging (SA) in older individuals. The computed metrics indicate that the ML models, trained using specific attributes, accurately predicted SA. The use of past theoretical and empirical studies in feature selection may improve prediction accuracy by successfully reducing the number of irrelevant or superfluous variables in the model. In order to prevent overfitting, dropout regularization was also used, which improved the accuracy of the ANN model and extended the scope of its application.
Even though our study performed as well as it could have for estimating the SA in older persons, there were a few potential weaknesses that need to be mentioned. First, a dataset from a single database that affects the accuracy, completeness, and generalizability of data was retrospectively examined for this study. The prediction models could have been negatively impacted by several inconsistent, insufficient, inaccurate, and irregular data items while utilizing this dataset. Therefore, the standard selection of each variable was established through conversations with the gerontology experts in order to increase data homogeneity in for the pre-processing stage. The aforementioned method made it easier for us to extract the most useful raw data from the hospital’s electronic medical record. Second, using a 2000-item sample dataset, this study only applied three significant ML algorithms. Obviously, the accuracy and generalizability of our models would be more enhanced as we assess a wider range of machine learning methods using larger, multicenter, and prospective datasets. Thirdly, the outcomes of the current investigation should be confirmed using an external validation approach. Fourthly, the link between the predictor and outcome factors was not examined in this study. There is a need for future research to explore a series of long-term factors associated with successful aging including disability, mental illness (depression, schizophrenia), substance abuse, and poor quality of life. Additionally, the suggested model can also be enhanced to provide scalable prediction models for successful aging.
In this study, the assessment of successful aging (SA) was carried out by considering three aspects of a persons health state, namely: physiological, cognitive psychological, and social function. The study built upon the SA model proposed by Rowe and Kahn and employed machine learning techniques to accurately predict the aging process. The study’s findings indicated that using the proposed machine learning (ML) model has the capability to improve the prediction of SA, suggesting it as a promising approach. The accuracy of all six ML models employed in this study were on average, >90%, >87%, and >86% to predict successful aging in the aging population dataset. The developed ANN models, however, reached 100% accuracy and sensitivity. The results show that machine learning offers a promising method for improving SA prediction. The results in this study have the potential to greatly benefit geriatricians and senior nurses by enhancing their ability to provide excellent assistance and care to the elderly. Additionally, the presented prediction models can serve as a reliable and adaptable tool for healthcare executives and policymakers, enabling them to enhance geriatric outcomes. For future directions, improved data instances that better point out factors important to successful aging will be acquired to developed scalable and generalizable models for predicting successful aging across different sources of data.
JEZ – Conceptualization, Methodology, Software, Result Analysis and Writing (Original draft preparation, final review, and editing, VAO – Software, Data Curation, and Original Draft, AJO – Investigation, Visualization, Writing (final review and editing), ASO – Software, Data Curation, Methodology, Writing(final review and editing). All authors read and approved the manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)