Keywords
Classification; Land Cover ; Deep Learning; CNN
This article is included in the Computational Modelling and Numerical Aspects in Engineering collection.
Classification; Land Cover ; Deep Learning; CNN
We have carefully addressed reviewer suggestions in the revised version. Firstly, we updated the abstract to include a clearer motivation for the research, a fundamental overview of the study, and detailed results from our experiments. In the introduction, we enhanced the content to highlight the significant contributions of our work more explicitly. We also incorporated the recommended references into the related work section to provide a broader context for our research. Additionally, we included a comprehensive description of the dataset in the results and discussion section to clarify our methodology. To improve comprehension, we revised the confusion matrix to present the data in percentage form. Lastly, we clarified the unique contributions of our research, emphasizing how it advances human activity recognition through a comparison of six machine learning algorithms, showcasing the exceptional performance of neural networks with an accuracy of 98.93%. These revisions collectively enhance the clarity, depth, and quality of our paper.
The revised paper was rewritten according to the suggestions given by the reviewers.
See the authors' detailed response to the review by Nurul Amin Choudhury
Human activity recognition is the process of identifying physical activities performed by individuals based on observations captured while they engage in various actions within a specific environment. With the rise of wearable and pervasive computing technologies, this field has seen significant growth, leading to the development of numerous applications. These applications include assistive technology, health and fitness tracking, elder care, and automated surveillance.
The goal of human activity recognition is to enhance the quality of life by making devices more aware of and responsive to users' needs. This technology can monitor daily activities, provide assistance in real-time, and offer insights that can improve health and safety. The motivation behind this task lies in its potential to revolutionize various aspects of daily living, from supporting the elderly to ensuring security in sensitive environments.
Mobile phone sensors, such as accelerometers and gyroscopes, play a crucial role in this process. By capturing precise motion data, these sensors enable the prediction of human actions through machine learning algorithms. This ability to continuously monitor and interpret human behavior makes human activity recognition a powerful tool for understanding and enhancing the way we interact with the world around us.
This research significantly advances the field of human activity recognition by providing a comprehensive exploration of machine learning techniques applied to a dataset derived from triaxial accelerometer and gyroscope sensors. The study focuses on six distinct classes of activities, namely Sitting, Standing, Laying, Walking, Walking_Downstairs, and Walking_Upstairs. The primary contributions can be summarized as follows:
Methodological Diversity: The study employs six prominent machine learning algorithms—naïve Bayes, decision tree, random forest, K-nearest neighbours, logistic regression, and neural network. This diverse approach allows for a thorough investigation into the strengths and limitations of each algorithm in predicting human activities.
Performance Analysis: Through rigorous experimentation, the research provides a detailed performance analysis of each machine learning model. Notably, the neural network emerges as the standout performer, achieving an impressive accuracy rate of 98.93%, surpassing other models such as naïve Bayes, decision tree, random forest, K-nearest neighbours, and logistic regression.
High Accuracy Achievements: The study successfully classifies activities like Sitting, Standing, Laying, Walking, Walking_Downstairs, and Walking_Upstairs with a remarkable accuracy of 98%. This achievement underscores the potential for accurate human activity recognition, a crucial aspect in applications such as e-health systems.
Insights into Algorithmic Strengths and Weaknesses: By presenting varied accuracies achieved by each model, the research sheds light on the strengths and weaknesses of different machine learning algorithms. This information is valuable for researchers and practitioners seeking to optimize activity recognition models for specific contexts.
Prominence of Neural Networks: The findings highlight the efficacy of neural networks in enhancing human activity recognition, positioning them as a promising approach for future endeavors in this domain. This insight can guide future research and development efforts towards leveraging neural networks for improved accuracy and reliability in activity prediction.
In conclusion, this research significantly contributes to the field of human activity recognition by offering a thorough examination of diverse machine learning methodologies. The emphasis on neural networks and their exceptional performance opens new avenues for advanced applications in e-health systems and beyond. The insights gained from this study not only deepen our understanding of machine learning applications in activity recognition but also pave the way for more effective methodologies in predicting and classifying human activities.
This section encompasses selected literature papers pertaining to human activity recognition, with specific details.
Schüldt et al.1 employed Support Vector Machines (SVM) for recognizing human activities in video sequences. The technique was effective, but the authors recognized the need to enhance recognition rates further. To achieve this, future work may involve utilizing more advanced neural network techniques, which have shown promise in improving classification performance in similar tasks.
Laptev et al.2 utilized an SVM with a multichannel Gaussian kernel for activity recognition. This approach allowed for a more nuanced analysis of video data by leveraging the multi-channel information. However, like other traditional machine learning methods, there is a need to improve the recognition rate. Future efforts should explore more sophisticated models or hybrid techniques that can capture the complex patterns in human activities more effectively.
Yamato et al.3 used Hidden Markov Models (HMM) in conjunction with feature vectors to recognize activities in video data. HMMs are particularly useful for modeling temporal sequences, making them suitable for this task. However, the recognition rates were not optimal, suggesting that there is room for improvement. Future research could focus on integrating HMMs with other models or exploring more advanced techniques like deep learning to boost performance.
Oliver et al.4 utilized Coupled Hidden Markov Models (CHMM) for activity recognition. CHMMs offer an enhanced capability over standard HMMs by modeling multiple interacting processes, which can be beneficial in complex activity recognition tasks. Despite these advantages, the authors noted that recognition rates could still be improved, indicating a potential area for future work, such as incorporating deep learning methods to handle more complex scenarios.
Natarajan et al.5 explored the use of Conditional Random Fields (CRF) for detecting human actions. CRFs are powerful for sequence modeling, especially in structured prediction tasks like activity recognition. However, the authors identified a need for further improvements in recognition accuracy, which could be addressed by integrating CRFs with deep learning frameworks or by refining the feature extraction process.
Ning et al.6 applied a standard method for human activity detection, though the specifics of the technique were not groundbreaking. The recognition rates achieved were satisfactory but not exemplary. To push the boundaries of what is currently possible, future research should consider incorporating more advanced or novel techniques, possibly exploring deep learning or ensemble methods to achieve higher accuracy.
Vali M. et al.7 combined Hidden Markov Models (HMM) and Conditional Random Fields (CRF) to enhance activity recognition. This hybrid approach leverages the strengths of both models—HMMs for temporal modeling and CRFs for sequence prediction. Despite this, the recognition rates were not optimal, suggesting that there is a need to further refine the model, possibly by integrating deep learning techniques or optimizing the existing hybrid approach.
Madharshahian R. et al.8 utilized Multinomial Logistic Regression (LR) for activity recognition. While LR is a robust statistical model, its application in complex tasks like activity recognition may fall short in terms of accuracy. The authors acknowledged this limitation and pointed out that future work should focus on enhancing activity identification, potentially by adopting more complex models like deep neural networks.
Kiros R. et al.9 employed consecutive Recurrent Neural Networks (RNNs) in their study. RNNs are well-suited for sequential data like human activities, but the authors noted that the network’s performance could be improved. They suggested that adding more layers to the network might enhance its ability to capture intricate temporal dependencies, leading to better identification rates.
Grushin A. et al.10 also utilized consecutive Recurrent Neural Networks (RNNs) for activity recognition, similar to Kiros et al. They observed that while RNNs perform well in handling sequential data, the recognition rates could still be better. To achieve this, they proposed that expanding the network by adding more layers could improve its capacity to model complex patterns in the data.
Veeriah et al.11 implemented differential Recurrent Neural Networks (RNNs) for recognizing human activities. This variation of RNNs aims to improve the model’s ability to capture subtle changes in the data. However, the authors noted that the recognition rates were not as high as desired. They suggested that adding more layers to the network could potentially enhance the model’s ability to detect activities more accurately.
Du Y., Wang W.,12 and Wang L. explored hierarchical Recurrent Neural Networks (RNNs) for activity recognition. Hierarchical RNNs can model different levels of abstraction in the data, making them powerful tools for this task. Despite their advantages, the authors acknowledged that further improvements could be made by incorporating Deep Neural Networks (DNNs), particularly Long Short-Term Memory (LSTM) units, to boost recognition rates.
Anna Ferrari et al.13 developed automated methods to identify daily activities (ADLs) using sensor signals and deep learning techniques. While their approach was innovative, the authors noted that the deep learning model could benefit from additional layers to improve its accuracy in detecting activities. This suggests that there is still room to optimize the model for better performance.
Li et al.14 proposed the HAR_WCNN algorithm, which uses a wide time-domain Convolutional Neural Network (CNN) combined with multienvironment sensor data for daily behavior recognition. The method shows promise, but the authors pointed out that the activity identification process could still be enhanced. Future work might focus on refining the CNN architecture or incorporating additional data sources to achieve better recognition rates.
Sarkar A.15 applied a Convolutional Neural Network (CNN) augmented with Spatial Attention for accurate human activity recognition. The spatial attention mechanism helps the model focus on relevant parts of the input data, improving accuracy. However, the authors recognized the need to further enhance the efficiency of activity recognition, which could be achieved by optimizing the network architecture or increasing the complexity of the model.
Choudhury N.16 used an adaptive batch size-based CNN-LSTM model to discern various human activities in uncontrolled environments. The combination of CNN for feature extraction and LSTM for sequence modeling makes this approach effective. However, the authors suggested that increasing the number of layers in the network could further boost the recognition rate, indicating that there is still potential for improvement.
Gholamiangonabadi D. and Grolinger K.17 employed a personalized Human Activity Recognition (HAR) model that utilizes CNN and signal decomposition. This approach allows for customized activity recognition based on individual differences. Despite its personalized nature, the authors acknowledged that the recognition rates could be better and suggested that incorporating Deep Neural Networks (DNN), particularly LSTM units, could lead to improved performance.
Dua N.18 introduced “ICGNet,” a hybrid model combining Convolutional Neural Networks (CNN) and Gated Recurrent Units (GRU) for Human Activity Recognition (HAR). This hybrid approach leverages the strengths of both CNNs and GRUs, but the authors noted that adding more layers to the network might enhance recognition rates. This suggests that there is still room to optimize the model for better accuracy.
Wu, Hao19 proposed the Differential Spatio-Temporal LSTM (DST-LSTM) method for Human Activity Recognition (HAR). This method is designed to capture both spatial and temporal dependencies in the data. However, the authors pointed out that expanding the network’s layers could improve recognition rates, indicating that the model’s current performance might benefit from further refinement.
Liciotti, Daniele 20 utilized Long Short-Term Memory (LSTM) networks to model spatio-temporal sequences obtained from smart home sensors and classify human activities. LSTMs are well-known for their ability to handle long-term dependencies in sequential data. Despite this, the authors acknowledged that there is still a need to improve recognition rates, suggesting that future work might focus on optimizing the LSTM architecture or incorporating additional data sources.
Priyadarshini I.21 explored machine learning techniques, including Random Forest (RF), Decision Trees (DT), K-Nearest Neighbors (k-NN), and deep learning algorithms like Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), and Gated Recurrent Units (GRU) for Human Activity Recognition (HAR). While these techniques are powerful, the authors noted that increasing the layers of the network could improve recognition rates, indicating that there is still potential to optimize the model for better performance.
Ronald M, et al. 22 introduces iSPLInception, a deep learning model based on the Inception-ResNet architecture, designed for efficient human activity recognition (HAR) on devices with limited computational resources. The model outperforms existing approaches in accuracy, cross-entropy loss, and F1 score across four public HAR datasets, demonstrating its effectiveness for real-world applications. In future need to focus on optimizing the iSPLInception model for real-time applications and expanding its use to more diverse datasets.
Poulose A, et al.23 introduces HIT HAR, a human activity recognition system using smartphone image data and a mask R-CNN for body detection, combined with a deep learning model for activity classification. Achieving 98.53% accuracy with ResNet, this approach overcomes misclassification challenges seen in sensor-based systems, especially for complex activities. In future need to focus on enhancing the HIT HAR system for real-time performance and expanding it to recognize more complex activities.
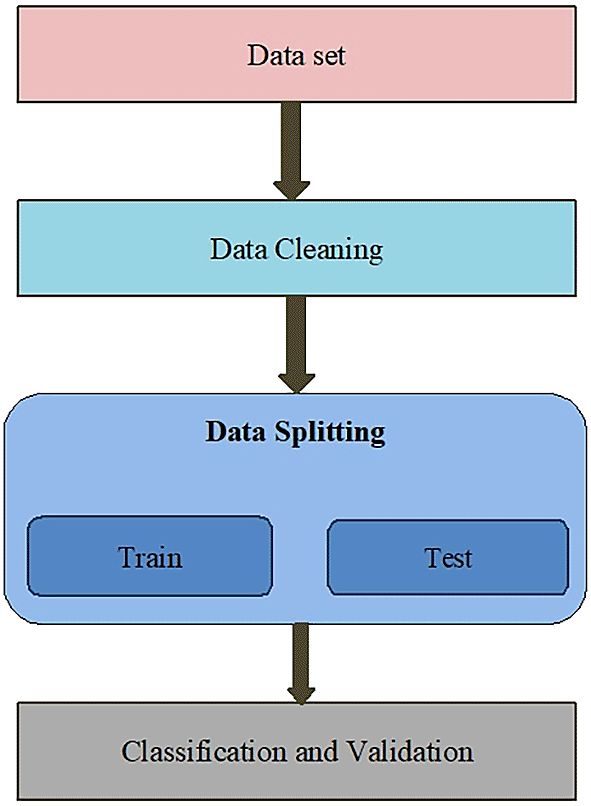
The human activity recognition methodology involves four key phases, namely input, data cleaning, data splitting, and classification and validation. Figure 1 illustrates the structure of the human activity recognition process.
Dataset: In our research endeavor, we drew upon the extensive resources offered by the kaggle, specifically selecting a dataset characterized by its wealth of information pertaining to triaxial acceleration derived from an accelerometer and triaxial angular velocity obtained from a gyroscope. This dataset, comprising a total of 10,299 entries, is distinguished by each entry being defined by a set of 561 features. This curated dataset plays a pivotal role in the domain of machine learning, providing a comprehensive array of features essential for thorough analysis and effective model training.
The foundation of our investigation lies in the Human Activity Recognition database, meticulously constructed from recordings capturing the daily activities of 30 participants. These individuals engaged in various activities of daily living (ADL), all while carrying a waist-mounted smartphone equipped with embedded inertial sensors. The primary objective was to classify these activities into one of six predefined categories: WALKING, WALKING_UPSTAIRS, WALKING_DOWNSTAIRS, SITTING, STANDING, and LAYING.
The experimental phase involved a cohort of 30 volunteers aged between 19 and 48 years. Each participant undertook the performance of six distinct activities while wearing a Samsung Galaxy S II smartphone on their waist. The smartphone, equipped with an accelerometer and gyroscope, captured 3-axial linear acceleration and 3-axial angular velocity at a consistent rate of 50Hz. To ensure the accuracy of the recorded data, the experiments were video-recorded, enabling manual labeling of the dataset. Subsequently, the dataset was randomly partitioned into two sets: 70% of the volunteers were allocated to generate the training data, and the remaining 30% constituted the test data.
The raw sensor signals, originating from both the accelerometer and gyroscope, underwent a pre-processing phase that included noise filtering. The processed signals were then sampled in fixed-width sliding windows, each lasting 2.56 seconds with a 50% overlap (128 readings per window). Further refinement involved the separation of the sensor acceleration signal, which encompasses both gravitational and body motion components. This separation was achieved using a Butterworth low-pass filter, isolating body acceleration and gravity. The gravitational force, primarily composed of low-frequency components, was effectively filtered using a cutoff frequency of 0.3 Hz.
Each window in the dataset resulted in a feature vector, totaling 561 dimensions, comprising variables derived from both the time and frequency domains. The attributes associated with each record in the dataset include triaxial acceleration from the accelerometer (representing total acceleration) and estimated body acceleration, triaxial angular velocity from the gyroscope, the 561-feature vector, the corresponding activity label, and an identifier specifying the subject who conducted the experiment.
Data cleaning: Data cleaning is a crucial process in refining a dataset, involving the removal of redundant columns and the correction or replacement of inaccurate records. As part of this process, an encoding technique is often employed to transform categorical data into numerical format; however, in cases where all feature values are already numerical, such encoding may be unnecessary. The primary objective of data cleaning is to mitigate the risk of errors recurring in the dataset.
The initial step in data cleaning entails the elimination of unwanted observations, which encompass both irrelevant and duplicate data. Duplicate entries commonly emerge when data is amalgamated from various sources, while irrelevant data pertains to information that does not contribute to addressing the underlying problem. This meticulous process is imperative for enhancing the dataset’s integrity.
Following the removal of undesirable observations, the subsequent step involves addressing missing data, which can be approached through two methods: either removing the entire record containing missing values or filling in the gaps based on other observations. However, outright removal or manual filling may not be optimal, as it could result in information loss, such as replacing a range with an arbitrary value. To address missing numerical data effectively, a dual-pronged approach is employed:
▪ Flagging the observation with an indicator value denoting missingness.
▪ Temporarily filling the observation with a placeholder value, such as 0, to ensure that no gaps exist.
This technique of flagging and filling not only aids in preserving the overall dataset but also allows algorithms to estimate missing values more optimally, mitigating potential information loss. In essence, data cleaning is a meticulous process that goes beyond mere elimination, involving strategic measures to enhance the accuracy and completeness of the dataset.
Feature fusion pipeline: In the realm of human activity recognition using sensor data, the feature fusion pipeline plays a pivotal role in amalgamating diverse sets of features extracted from various sensors to provide a comprehensive and nuanced understanding of human movements. The feature fusion pipeline is essentially a systematic process that integrates information from different sensors, such as accelerometers, gyroscopes, and magnetometers, to create a unified representation of human activities. This integration of features not only enhances the accuracy of activity recognition but also ensures a more robust and holistic analysis of complex human behaviors. For instance, by fusing data from accelerometers measuring linear motion with gyroscopes capturing rotational movements, the feature fusion pipeline enables a more nuanced differentiation between activities like walking, running, or even specific gestures, contributing to the refinement of human activity recognition systems.
The feature fusion pipeline involves multiple stages, beginning with the extraction of relevant features from individual sensors. These features may include acceleration patterns, orientation changes, or temporal characteristics. Subsequently, a fusion mechanism is applied to combine these diverse features into a cohesive representation, often using techniques such as concatenation, averaging, or weighted summation. The resultant fused feature set serves as input to machine learning models, allowing for more sophisticated and context-aware human activity recognition. By seamlessly integrating information from various sensors, the feature fusion pipeline significantly enhances the capability of systems to discern intricate human activities, making it a cornerstone in advancing the accuracy and applicability of human activity recognition using sensor data.
Data splitting: During the pivotal phase of data splitting, the dataset undergoes a discerning segmentation, effectively yielding two distinctive components with unique roles and significance:
Training Data: At the core of this phase lies the training data, a crucial subset meticulously employed to educate and refine the model. Specifically, we judiciously allocated 60% of the entire dataset to serve as the bedrock for training our model. This subset plays a pivotal role in shaping the model’s understanding, fostering its ability to generalize patterns, and ultimately enhancing its predictive capabilities.
Testing Data: The counterpart to the training data, the testing data serves a distinct purpose in evaluating the model’s proficiency and generalization beyond the training set. Carefully designated as the dataset reserved for assessing the model’s performance, we conscientiously earmarked 20% of the dataset for this purpose. This subset represents a critical measure of the model’s ability to extrapolate its learned knowledge to unseen instances, thereby validating its robustness and reliability.
Classification and validation: The intricate process of classification and validation unfolded in two distinct phases, namely:
Classification: Within the realm of data analysis, classification stands as the pivotal process dedicated to predicting the target class of novel observations, a task fundamentally grounded in the patterns discerned from the training data. The dataset meticulously chosen for our analysis already encompasses the essential target class information. To harness this data effectively, we executed the model by employing a suite of sophisticated classification algorithms. The algorithms we incorporated in this analytical journey were carefully selected and included the following advanced techniques: [list of algorithms]. Each of these algorithms brought its unique strengths and nuances to the forefront, enhancing our model’s predictive capabilities.
Decision Tree: The decision tree classification utilizes a tree representation to address a problem, with each internal node representing features, branches denoting feature outcomes, and leaf nodes indicating target class labels. The algorithm for constructing the decision tree involves several stages with a critical consideration of hyperparameters.
Hyperparameter: Attribute Selection Measure
▪ Identify the best attribute to serve as the root of the tree.
▪ Subdivide the training set into sections based on the selected attribute.
▪ Repeat the above steps until all branches of the tree have leaf nodes.
Hyperparameter: Attribute Selection Measures
Information Gain is mathematically defined as Equation 1:
where Pi is the probability of class i
Information Gain (Equation 2) is then calculated as:
Gini Index, another measure, quantifies the likelihood of a randomly chosen element being incorrectly classified (Equation 3):
Considering the unbalanced nature of the dataset with multiple classes, the decision tree primarily relies on Information Gain to select the most appropriate attribute.
Logistic regression: Logistic regression is a statistical method used for classification which falls under supervised learning. It is used for predictions based on probability concepts. It analyses data set and take discrete independent input values and give a single output.
Logistic function: Logistic function is also known as the sigmoid function, which takes a real-value number as input and maps it into a value between 0 and 1, but not exactly at those limits. It maps predictions to probabilities.
By using the sigmoid function, if we give an input value on x, then it predicts the target value on the y axis.
Here k = 1, x0 = 0, L = 1
Naïve Bayes classifier: Naïve is a probabilistic classification algorithm which is based on Bayes theorem. It assumes that the occurrence of an instance is independent of other instances.
The conditional probability of an object with feature vector x1,x2, … … ., xn belongs to a particular class Ci, and it is calculated with Equation 7.
Gaussian naïve Bayes: As values of each feature of our data set are continuous, we use the Gaussian distribution, which is also called the normal distribution.
Where μ is the mean of all the values a feature and σ is the standard deviation.
K-nearest neighbours is one of the essential classification algorithms. It falls under the category of supervised learning. It assumes that similar data are close to each other. Here the data is classified into groups based on an attribute. It is used in applications like pattern recognition, intrusion detection and data mining.
Let N be the number of training samples of data and U is the unknown point.
The data set is stored in an array each element represented as a tuple (x, y).
For i = 0 to n-1
Begin
Euclidian distance from each point to U is calculated.
S is the set of m smallest distances (all the points related to distances must be classified)
end
Return (Mode (m labels))
Random forest: Random forests are ensembles, which means combination of two or more models to get better results. Random forests create a forest of decision trees on data samples. Each decision tree gives a target class as output and the final target class is identified by performing some measures on outputs from each decision tree of corresponding input record.
Artificial neural network (ANN): Artificial Neural Network (ANN), an intricate computational model, is comprised of interconnected nodes that collaboratively process and store property values. These nodes serve as pivotal entities where input values, derived from the distinctive characteristics of training examples, are meticulously aggregated. The interconnection between nodes involves weighted values (W) and biases (), which are then systematically forwarded to the subsequent layer of nodes. A crucial aspect of this progression includes subjecting the weighted total to a non-linear activation function (, with the resultant value efficiently transmitted to the subsequent layer. This iterative process persists until the network culminates in generating the final output, as illustrated in the intricate structure depicted in Figure 2.

Figure 2 exemplifies the complex architecture of a neural network model, visually portraying the interplay of nodes, weighted values, and biases that characterize its underlying structure.
In the quest to enhance the accuracy of output predictions, the manipulation of weights (W) and biases (b) within the ANN plays a central role. These parameters are optimized through the employment of various optimization algorithms, each tailored to address specific challenges in training neural networks. These algorithms are characterized by hyperparameters, including: Gradient Descent (GD), Stochastic Gradient Descent (SGD), Mini-Batch Gradient Descent.
Gradient Descent (GD): Update Rule
θt represents the parameters (weights and biases) at iteration t
∝ is the learning rate, controlling the size of the step taken during each iteration.
Stochastic Gradient Descent (SGD): Update Rule
Similar to GD,but instead of using the gradient of the entire dataset, it uses the gradient of the cost function for a single data point (xi,yi) at each iteration.
Mini-Batch Gradient Descent: Update Rule
An intermediate approach between GD and SGD,where updates are computed using a small andom subset (mini-batch) of the entire dataset.
The neural network architecture is defined by the number of layers (L) and the number of neurons in each layer (Nl). The weights (W) and biases (b) are initialized and updated through the training process, adjusting their values to minimize the cost function (J). The activation function (σ) introduces non-linearity to the model, enabling it to learn complex relationships within the data.
Number of Layers and Neurons: The neural network architecture is defined by the number of layers (L) and the number of neurons in each layer (Nl).
Initialization of Weights and Biases: The weights (W) and biases (b) are initialized before the training process begins. This initialization is typically done randomly or using specific strategies to break symmetry and aid convergence.
Forward Propagation: The forward propagation computes the predicted output (al) for each layer using the following equations:
Cost Function: The cost function (J) measures the difference between the predicted output and the actual output. For regression problems, Mean Squared Error (MSE) is commonly used:
Backward Propagation: The backward propagation computes the gradients of the cost function with respect to the weights and biases, enabling updates in the direction that minimizes the cost. The gradients are calculated using the chain rule:
The iterative nature of the learning process in ANN, combined with the dynamic adjustments introduced by these parameters and hyperparameters, showcases the adaptability and efficiency in navigating the complex parameter space to converge towards optimal solutions.
Validation: Validation is a crucial step in assessing the performance of a machine learning model, where evaluation metrics are employed to gauge the model’s compatibility with the underlying dataset. The process involves employing various metrics designed to provide insights into different aspects of the model’s performance. Among these metrics, commonly utilized for assessing classification models, are accuracy, precision, recall, and the F1 score.
Precision: Precision is also known as positive predicted value which is a measure of accuracy. It is mathematically defined as true positives divided by the sum of true positives and false positives.
Recall: Recall is also referred toas sensitivity, which is a measure of accuracy. It is mathematically defined as true positives divided by sum of true positives and false negatives.
F1 score: The F1 score is calculated with equation 11
Accuracy: Accuracy defines how well the model predicts the class. It is mathematically defined as the number of truly predicted classes divided by total number of classes.
In our research, we utilized a rich dataset from Kaggle, which contains detailed measurements from both an accelerometer and a gyroscope. The accelerometer captures triaxial acceleration, while the gyroscope records triaxial angular velocity, providing a comprehensive view of movement and rotation. This dataset consists of 10,299 individual entries, with each entry described by 561 unique features. These features offer a wide range of valuable data points, making the dataset highly suitable for in-depth machine learning analysis and effective model training, particularly in the field of human activity recognition.
The total number of rows and columns in a dataset are identified by using the ‘shape’ function.
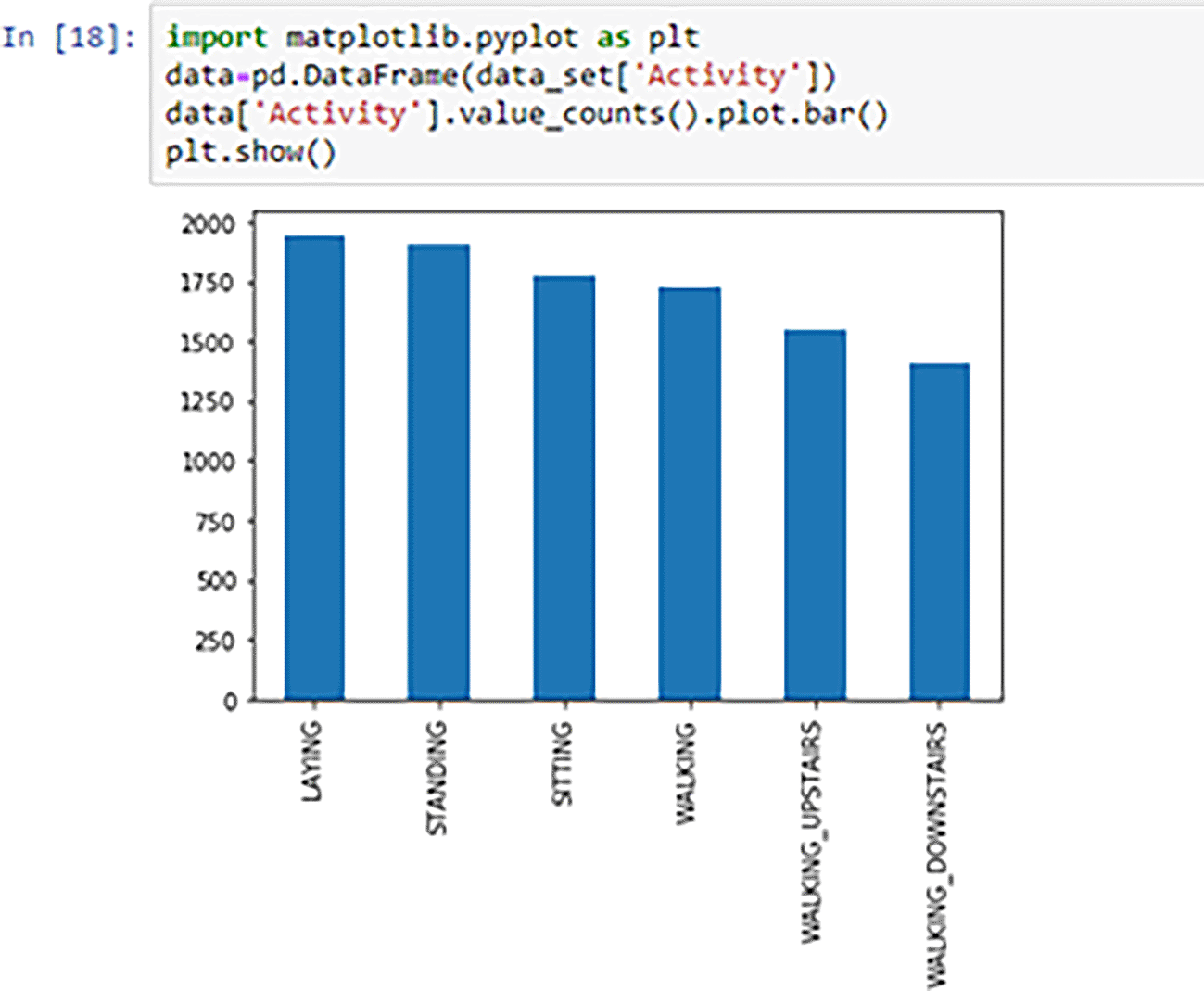
The shape function reveals that the dataset comprises 10,299 instances and 562 attributes. Among these attributes, 561 are independent, while one serves as the dependent variable. Our exploration of the data involved the utilization of various graphs, including a bar graph, box plot, and heatmap. Specifically, the bar graph facilitated the comparison of different target classes. Figure 3 displays the bar graph, illustrating the distribution of classifications among individuals. The observations extracted from Figure 3 are as follows: LAYING—1944 instances, STANDING—1906 instances, SITTING—1777 instances, WALKING—1722 instances, WALKING_UPSTAIRS—1544 instances, and WALKING_DOWNSTAIRS—1406 instances.
Box plot: In Figure 4, a box plot illustrates the data distribution for the ‘Activity’ target class and the ‘tBodyAcc-max()-X’ feature. This visualization incorporates five key measures: minimum, first quartile (Q1), median, third quartile (Q3), and maximum.
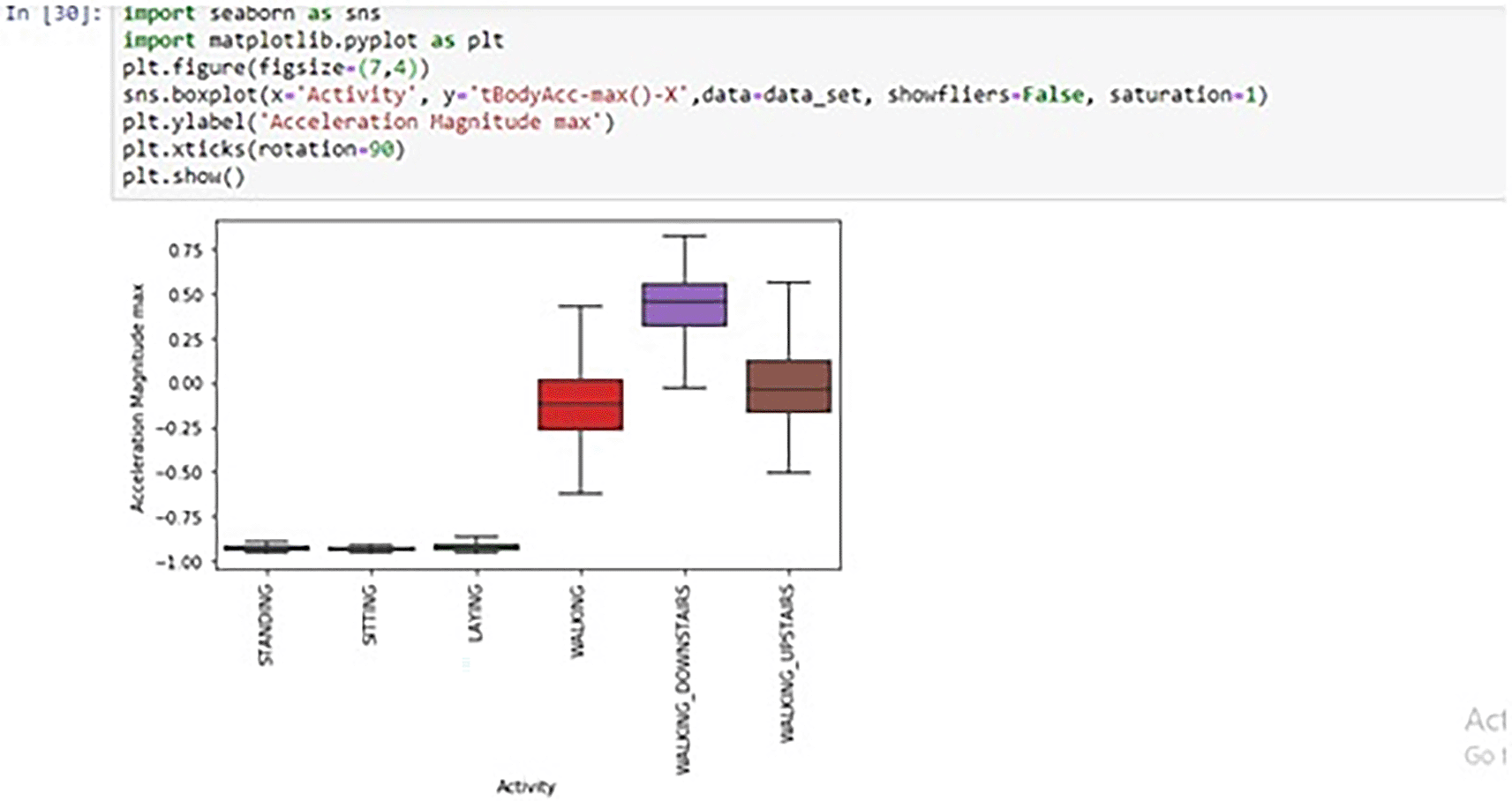
Analyzing the information presented in Figure 4, the following noteworthy observations were discerned:
▪ When the value of tBodyAcc-max()-X falls below -0.75, the corresponding activities are predominantly identified as Standing, Sitting, or Laying.
▪ In instances where tBodyAcc-max()-X exceeds -0.50, the categorization shifts towards activities characterized as Walking, Walking_Downstairs, or Walking_Upstairs.
▪ Notably, when tBodyAcc-max()-X surpasses 0.00, the specific activity discerned is attributed to Walking_Downstairs.
The confusion matrix for the naïve Bayes classifier is shown in Figure 5. From Figure 5, the following observations were made:
• The actual number of Laying was 389, but the model correctly predicted 92.8% as Laying and incorrectly predicted 5.7% as Sitting and 2.3% as Walking_Upstairs.
• The actual number of Sitting was 372, but the model correctly predicted 90.3% as Sitting and incorrectly predicted 0.5% as Laying, 8.3% as Standing, and 0.8% as Walking_Upstairs.
• The actual number of Standing was 375, but the model correctly predicted 41.9% as Standing and incorrectly predicted 57.1% as Sitting and 1.1% as Walking_Upstairs.
• The actual number of Walking was 345, but the model correctly predicted 74.4% as Walking and incorrectly predicted 9% as Walking_Downstairs and 16.8% as Walking_Upstairs.
• The actual number of Walking_Downstairs was 282, but the model correctly predicted 70.6% as Walking_Downstairs and incorrectly predicted 8.8% as Walking and 20.6% as Walking_Upstairs.
• The actual number of Walking_Upstairs was 297, but the model correctly predicted 92.6% as Walking_Upstairs and incorrectly predicted 5.7% as Walking_Downstairs and 1.7% as Walking.
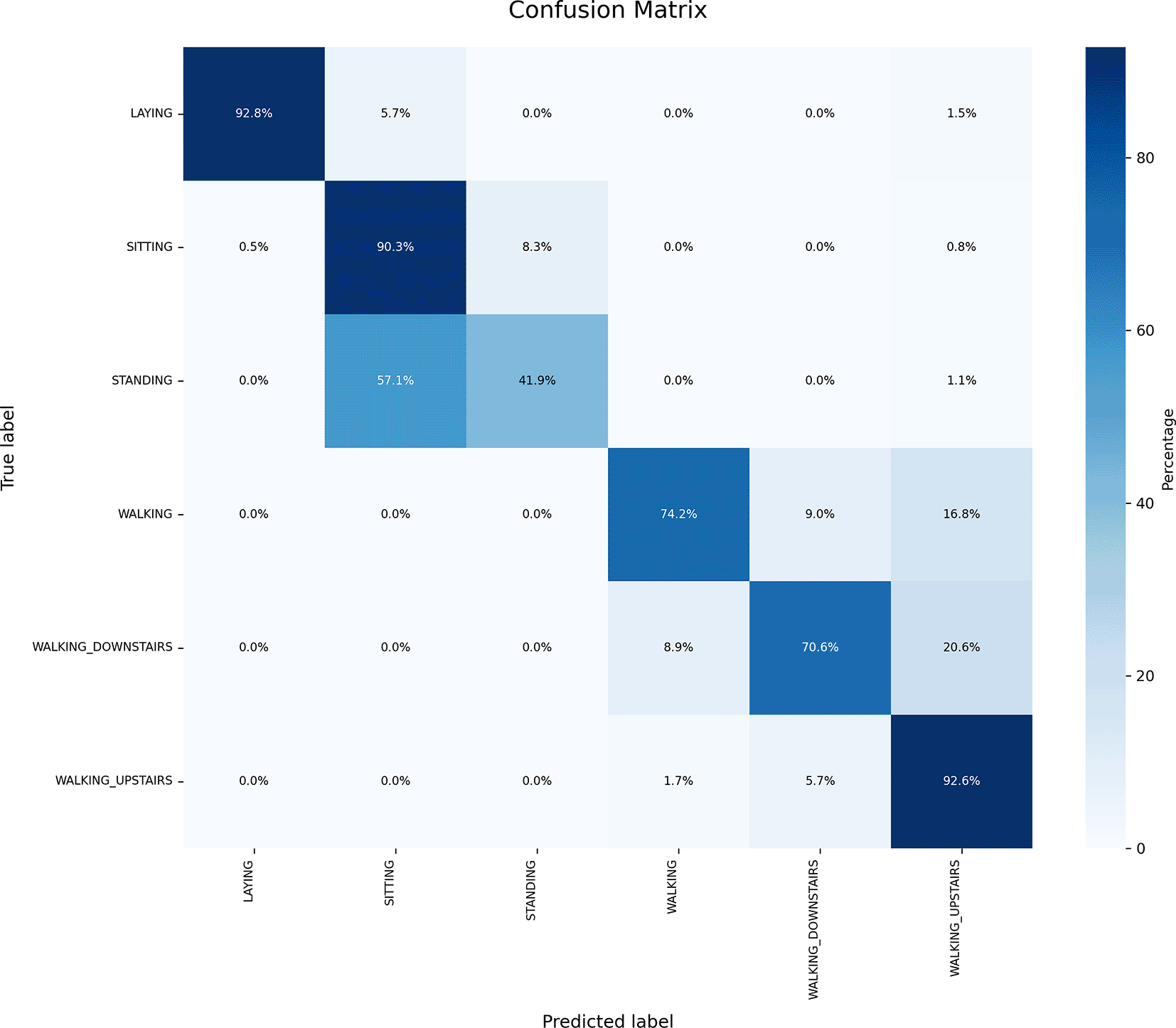
Figure 6 illustrates the precision, recall, and F1 score values for each activity class, providing insight into the classifier’s performance across different activities. The interpretations are:
• Laying: This class had the highest precision, recall, and F1 score, indicating that the model most accurately identified instances of “Laying” with minimal errors. The high scores suggest that the model effectively distinguishes “Laying” from other activities, likely due to its distinct features.
• Standing: On the other hand, “Standing” exhibited lower precision, recall, and F1 scores compared to other classes. This indicates that the model struggled to correctly identify “Standing” instances, often confusing them with similar activities such as “Sitting.” The low performance here reflects the challenges in distinguishing between activities with similar postures.
• Other Classes: The performance metrics for activities like “Walking,” “Walking_Upstairs,” and “Walking_Downstairs” showed moderate values, reflecting a balance between accurate predictions and some misclassifications. These activities have overlapping features, making it harder for the model to achieve higher scores.
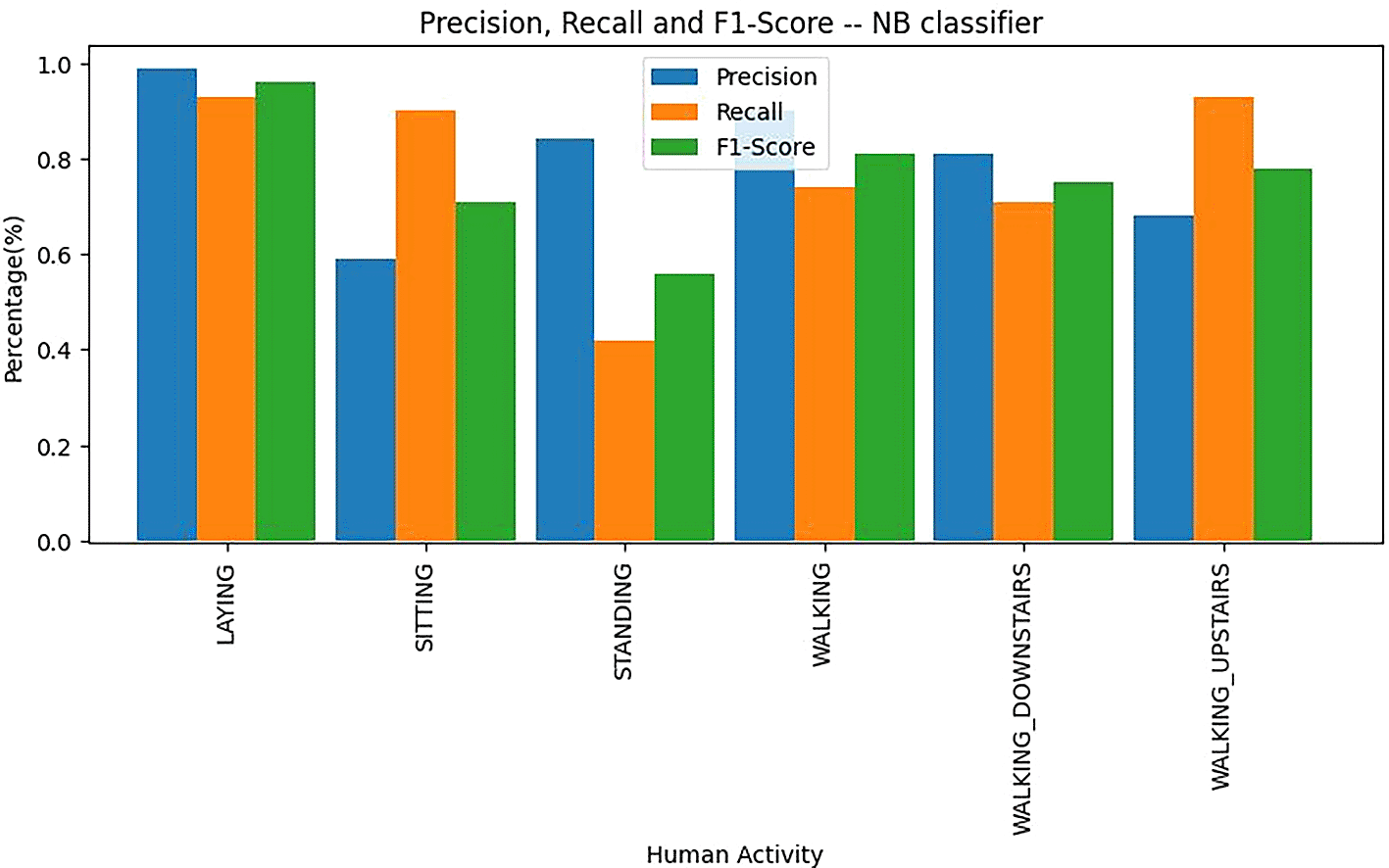
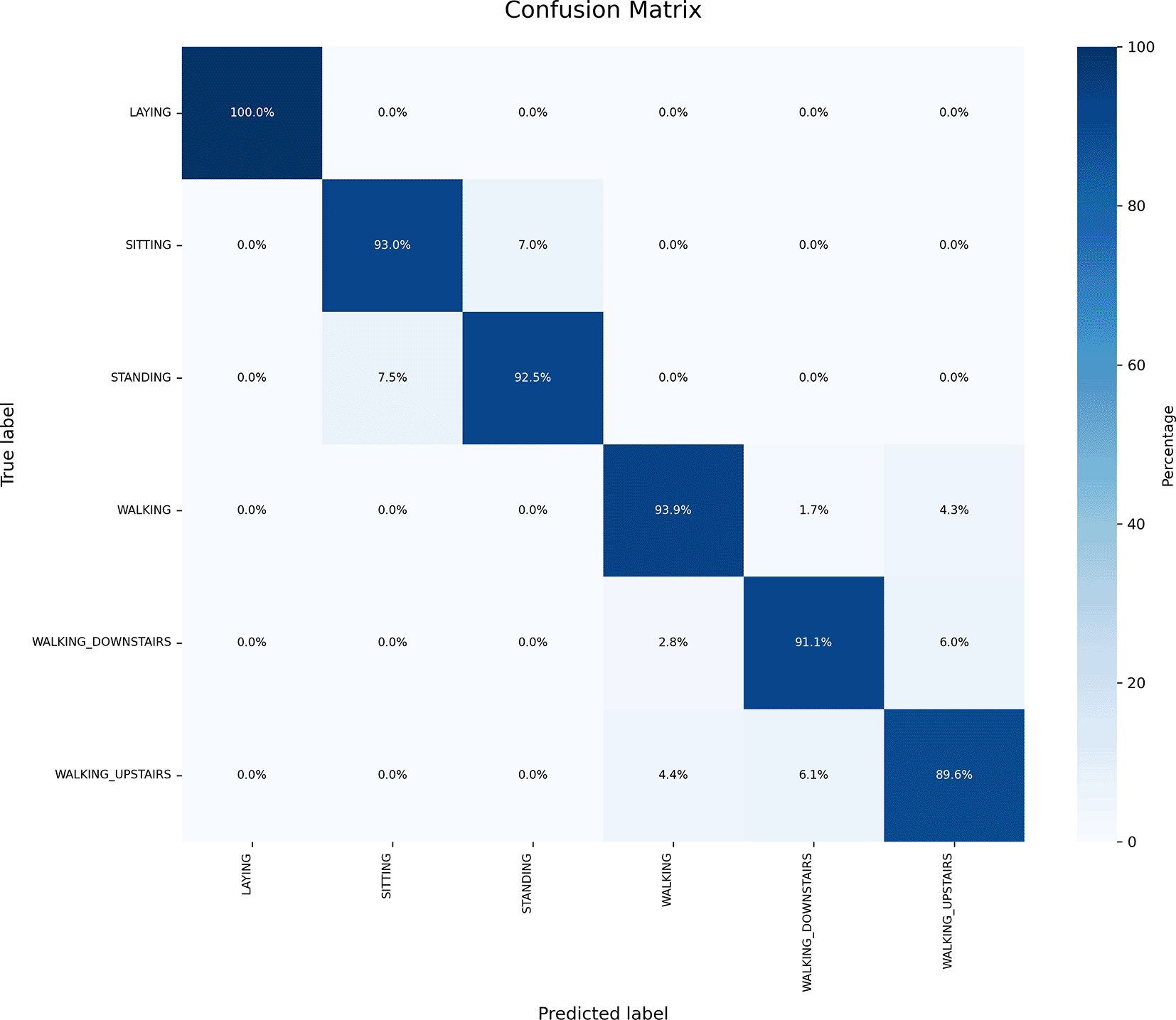
The confusion matrix for the decision tree classifier is depicted in Figure 7. Based on Figure 7, the following observations were made:
• The actual number of instances classified as “Laying” was 389, and the model correctly predicted 100% as “Laying.”
• The actual number of instances classified as “Sitting” was 372. The model correctly predicted 92.9% as “Sitting” and incorrectly predicted 7.0% as “Standing.”
• The actual number of instances classified as “Standing” was 375. The model correctly predicted 92.5% as “Standing” and incorrectly predicted 7.5% as “Sitting.”
• The actual number of instances classified as “Walking” was 345. The model correctly predicted 94.1% as “Walking” and incorrectly predicted 1.7% as “Walking_Downstairs” and 4.3% as “Walking_Upstairs.”
• The actual number of instances classified as “Walking_Downstairs” was 282. The model correctly predicted 91.1% as “Walking_Downstairs” and incorrectly predicted 2.8% as “Walking” and 5.3% as “Walking_Upstairs.”
• The actual number of instances classified as “Walking_Upstairs” was 297. The model correctly predicted 89.6% as “Walking_Upstairs” and incorrectly predicted 4.4% as “Walking” and 6.1% as “Walking_Downstairs.”
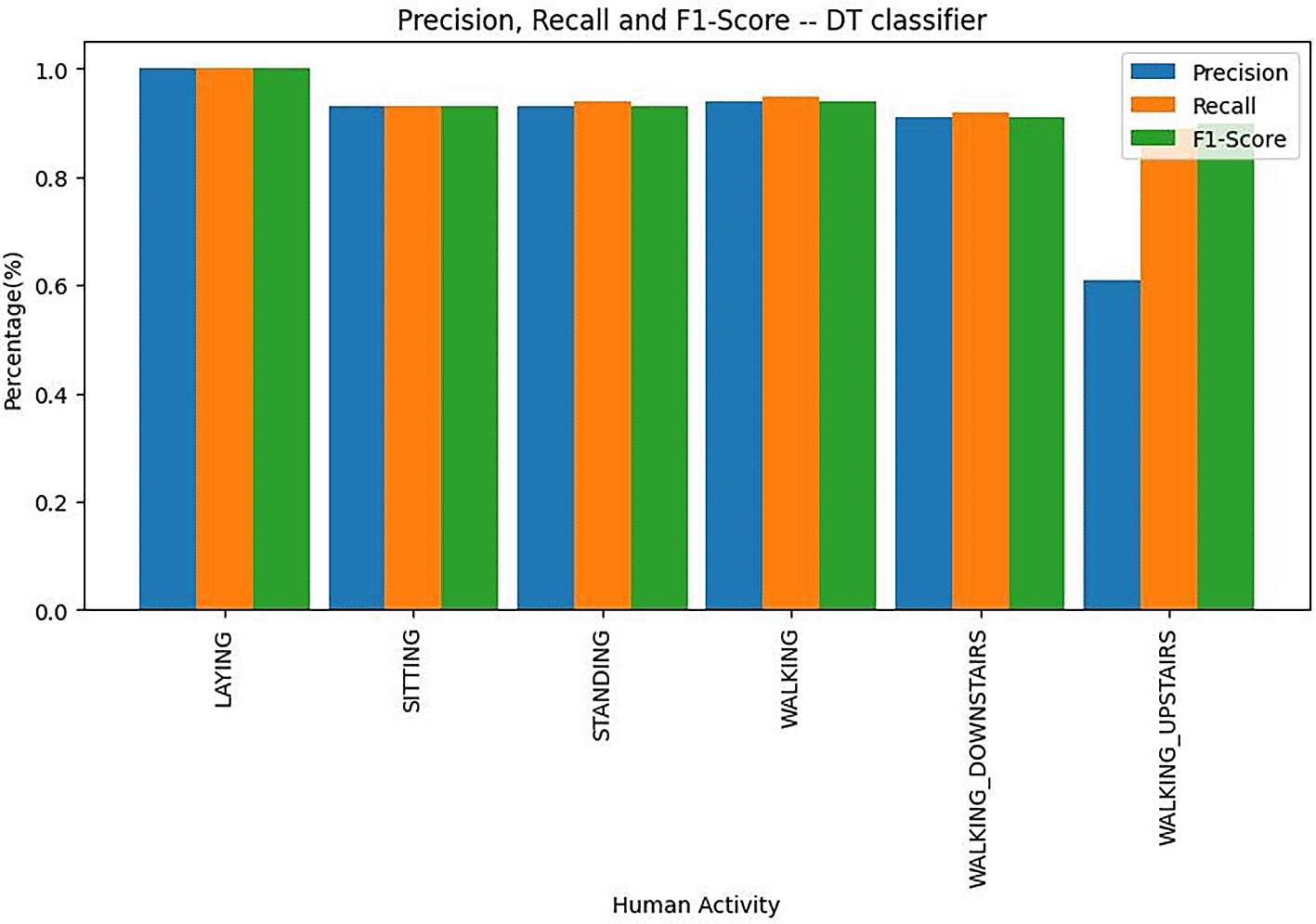
Precision, recall and F1 score values of decision tree classifier are depicted in the bar plot shown in Figure 8.
Key misclassifications of decision tree classifier:
• Laying: The Decision Tree classifier achieved perfect precision, recall, and F1 scores for the “Laying” class, indicating that all instances of “Laying” were correctly predicted without any misclassifications. This suggests that the model effectively distinguishes “Laying” from other activities, highlighting its strength in accurately identifying this class.
• Standing: The performance for the “Standing” class is also depicted in Figure 8, showing the precision, recall, and F1 scores specific to this activity. The values here reveal how well the classifier managed to identify “Standing” instances. While exact numbers are not provided, the focus would be on understanding whether “Standing” had strong or weak scores compared to other activities.
• Other Classes: The metrics for other activities such as “Walking,” “Walking_Upstairs,” and “Walking_Downstairs” provide insight into the classifier’s performance across these classes. The precision, recall, and F1 scores reflect the model’s ability to correctly classify these activities and highlight any potential areas of misclassification.
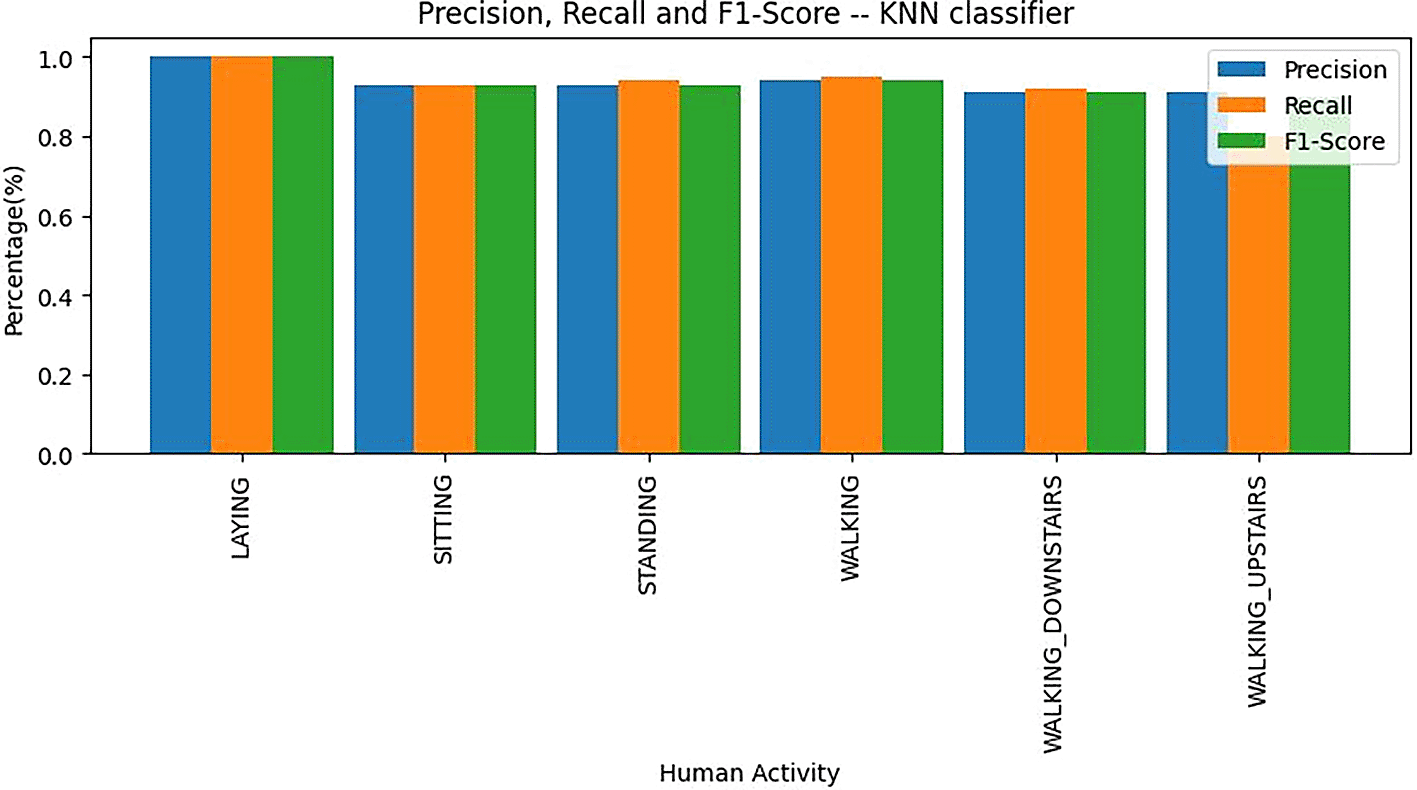
The confusion matrix for the K-nearest neighbors classifier is shown in Figure 9. From Figure 9, the following observations were made:
• The actual number of “Laying” was 389, and the model correctly predicted 100% as “Laying.”
• The actual number of “Sitting” was 372, but the model correctly predicted 89.0% as “Sitting” and incorrectly predicted 64.2% as “Standing” and 0.3% as “Sitting.”
• The actual number of “Standing” was 375, but the model correctly predicted 94.4% as “Standing” and incorrectly predicted 5.6% as “Sitting.”
• The actual number of “Walking” was 345, but the model correctly predicted 99.7% as “Walking” and incorrectly predicted 0.3% as “Walking_Upstairs.”
• The actual number of “Walking_Downstairs” was 282, but the model correctly predicted 99.3% as “Walking_Downstairs” and incorrectly predicted 0.7% as “Walking.”
• The actual number of “Walking_Upstairs” was 297, and the model correctly predicted 100% as “Walking_Upstairs.”

Precision, recall and F1 score values of the K-nearest neighbour classifier are depicted in the bar plot shown in Figure 10.
• Laying: The KNN classifier achieved perfect scores for the “Laying” class, with precision, recall, and F1 score values all at 100%. This indicates that the model correctly identified every instance of “Laying” without any misclassifications. The perfect metrics reflect the classifier’s exceptional performance in recognizing this activity.
• Other Classes: The precision, recall, and F1 scores for other activities, while not specified in detail, would be depicted in Figure 10. These metrics provide insight into how well the KNN classifier performed for activities other than “Laying.” High values across these metrics for other classes would indicate strong overall performance, whereas lower values might suggest areas for improvement.
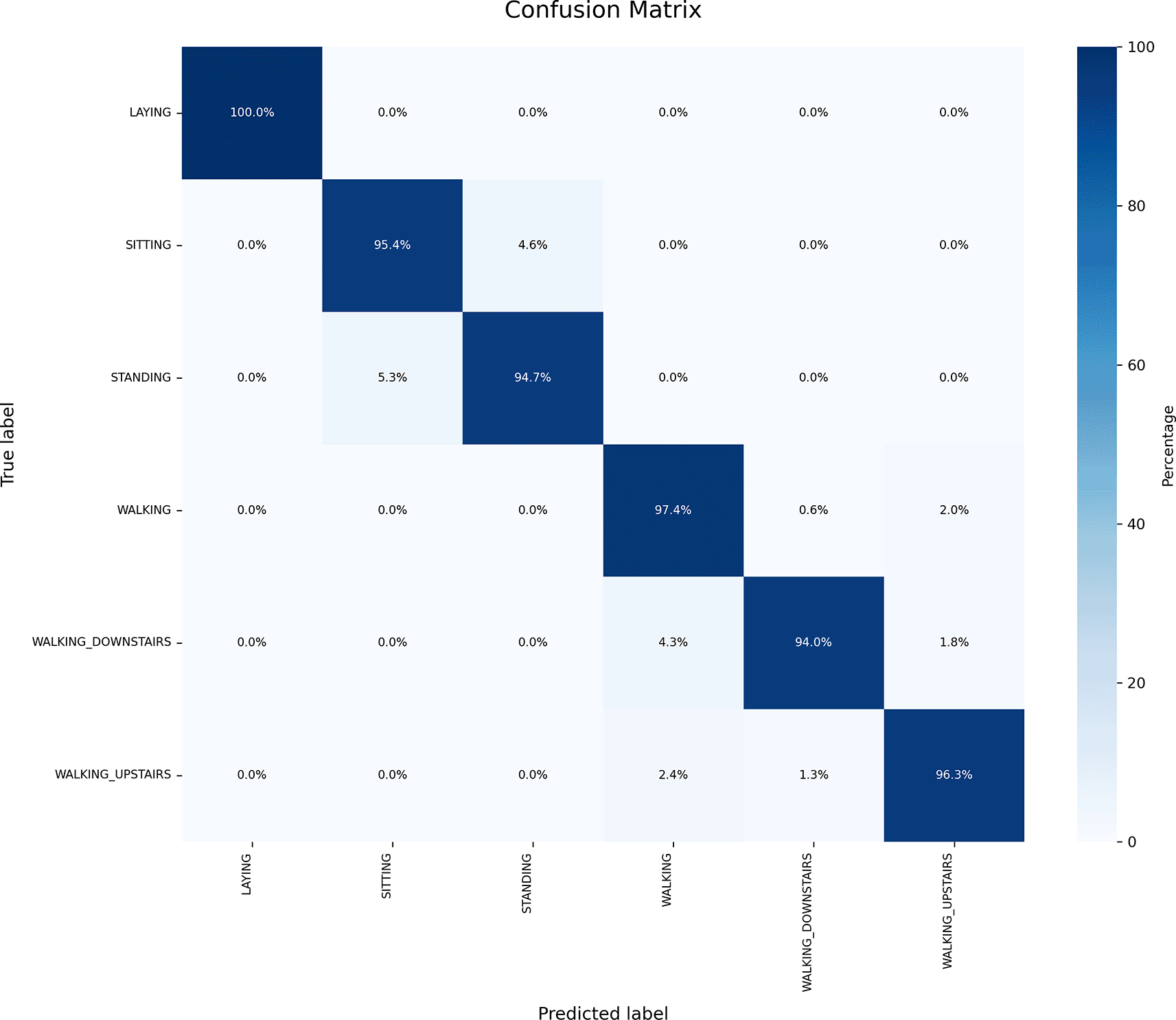
The confusion matrix for the random forest classifier is depicted in Figure 11. From Figure 11, the following observations were made:
• The actual number of instances labeled as “Laying” was 389, and the model correctly predicted 100% as “Laying.”
• The actual number of instances labeled as “Sitting” was 372. However, the model correctly predicted 95.4% as “Sitting” and incorrectly predicted 4.6% as “Standing.”
• The actual number of instances labeled as “Standing” was 375. The model correctly predicted 94.7% as “Standing” and incorrectly predicted 5.3% as “Sitting.”
• The actual number of instances labeled as “Walking” was 345. The model correctly predicted 97.4% as “Walking” and incorrectly predicted 0.6% as “Walking_Downstairs” and 2.0% as “Walking_Upstairs.”
• The actual number of instances labeled as “Walking_Downstairs” was 282. The model correctly predicted 94.0% as “Walking_Downstairs” and incorrectly predicted 4.3% as “Walking” and 1.8% as “Walking_Upstairs.”
• The actual number of instances labeled as “Walking_Upstairs” was 297. The model correctly predicted 96.3% as “Walking_Upstairs” and incorrectly predicted 2.4% as “Walking” and 1.4% as “Walking_Downstairs.”
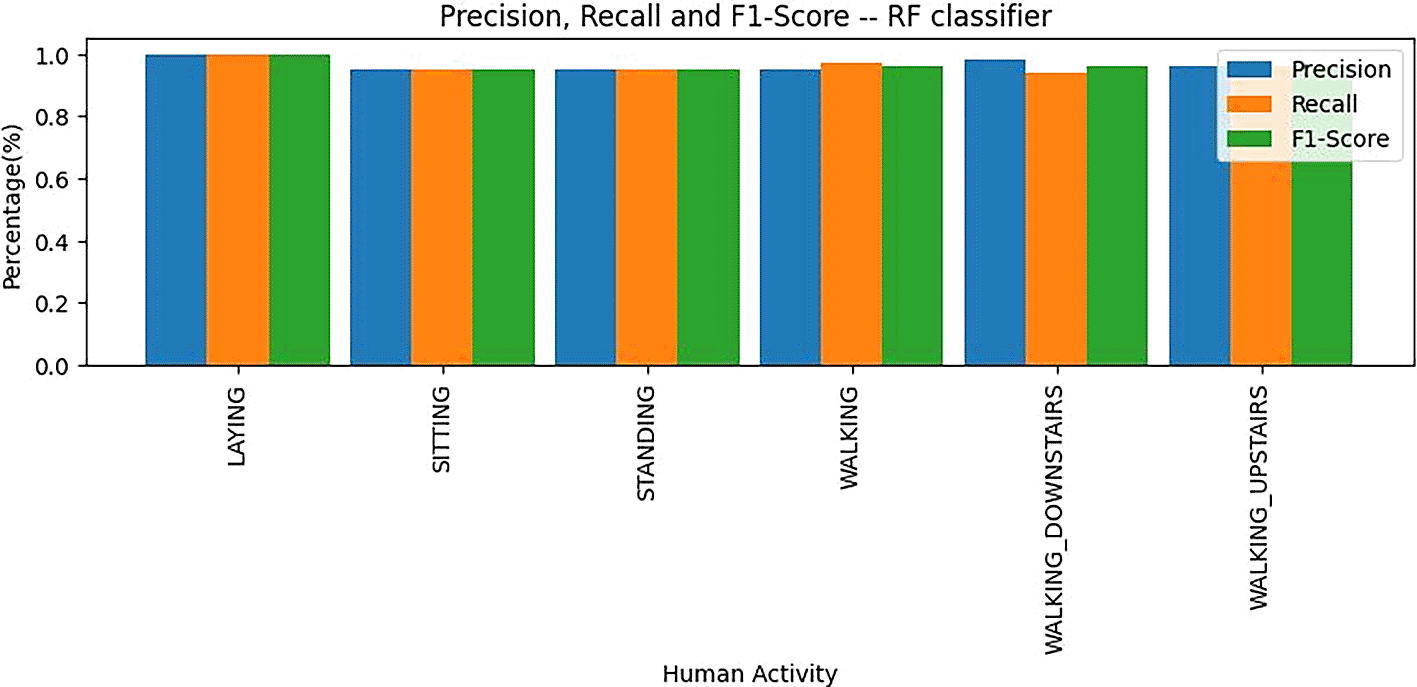
Precision, recall and F1 score values of random forest are depicted as a bar plot shown in Figure 12.
• Laying: The Random Forest classifier achieved perfect precision, recall, and F1 score values for the “Laying” class. This means that every instance of “Laying” was correctly identified by the model, with no misclassifications. The 100% scores across these metrics indicate exceptional accuracy in predicting the “Laying” activity.
• Other Classes: The precision, recall, and F1 scores for other activities are also shown in Figure 13. These metrics provide insights into how well the Random Forest classifier performed in predicting activities other than “Laying.” The values would help assess the overall effectiveness of the model in distinguishing between various activities.
The confusion matrix for logistic regression is shown in Figure 13. From Figure 13, the following observations were made:
• The actual number of Laying was 389, and the model correctly predicted 100% as Laying.
• The actual number of Sitting was 372, but the model correctly predicted 94.4% as Sitting and incorrectly predicted 5.6% as Standing.
• The actual number of Standing was 375, and the model correctly predicted 96.0% as Standing while incorrectly predicting 4.0% as Sitting.
• The actual number of Walking was 345, and the model correctly predicted 99.7% as Walking while incorrectly predicting 0.3% as Walking_Upstairs.
• The actual number of Walking_Downstairs was 282, and the model correctly predicted 99.6% as Walking_Downstairs while incorrectly predicting 0.4% as Walking_Upstairs.
• The actual number of Walking_Upstairs was 297, and the model correctly predicted 99.3% as Walking_Upstairs while incorrectly predicting 0.3% as Walking and 0.3% as Walking_Downstairs.

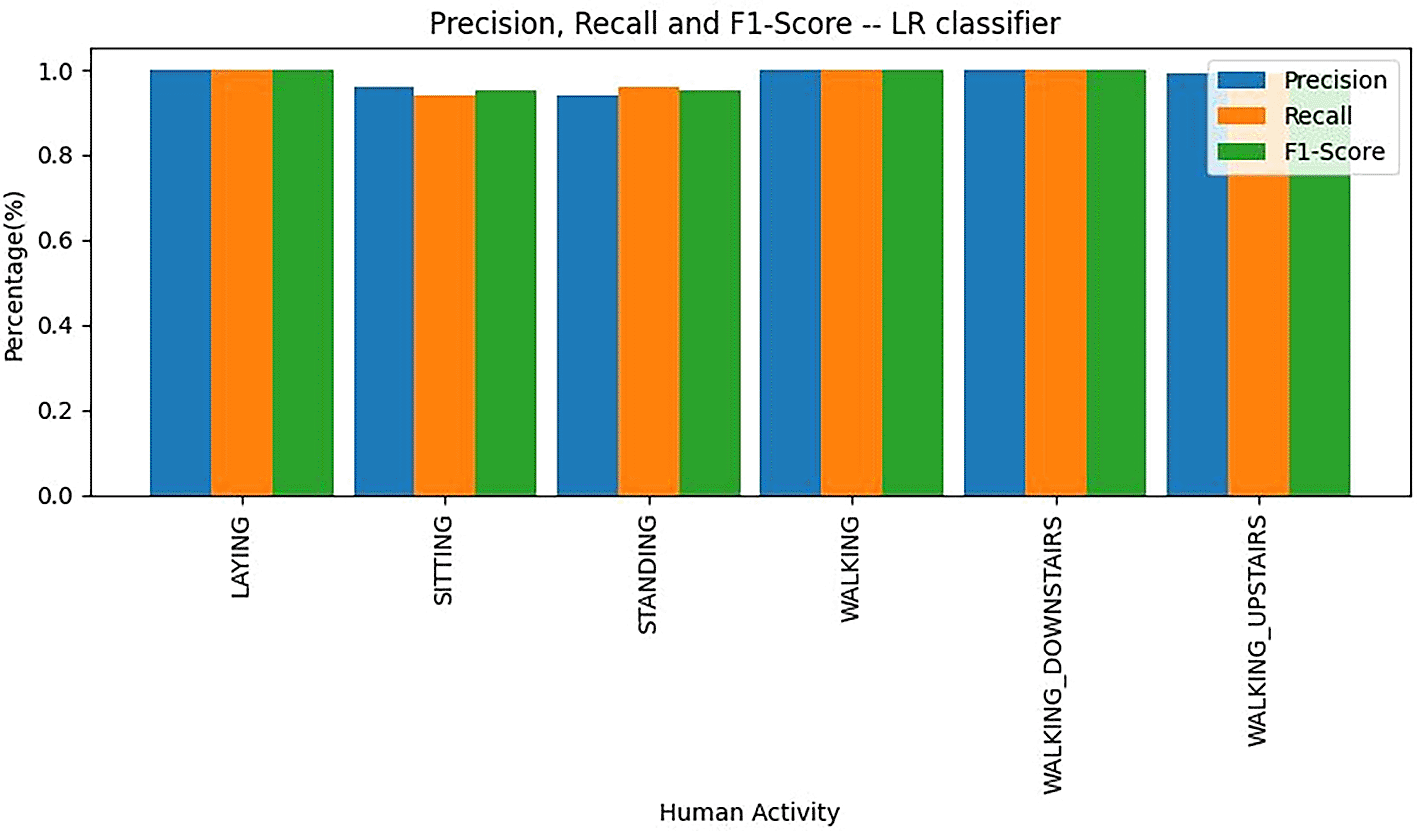
The graphical representation in Figure 14 illustrates the precision, recall, and F1 score values associated with logistic regression.
• Laying, Walking, and Walking Downstairs: The classifier demonstrated particularly strong performance for these activities. The precision, recall, and F1 scores for “Laying,” “Walking,” and “Walking Downstairs” are notably high, reflecting the model’s proficiency in accurately identifying and classifying these activities. The clarity and distinctiveness of the bar plot for these instances indicate that the logistic regression model effectively distinguishes these activities from others.
• Other Classes: The precision, recall, and F1 scores for other activities are also illustrated in Figure 15. While the focus is on the high performance for “Laying,” “Walking,” and “Walking Downstairs,” the metrics for other classes would provide additional context on the model’s overall classification capabilities.
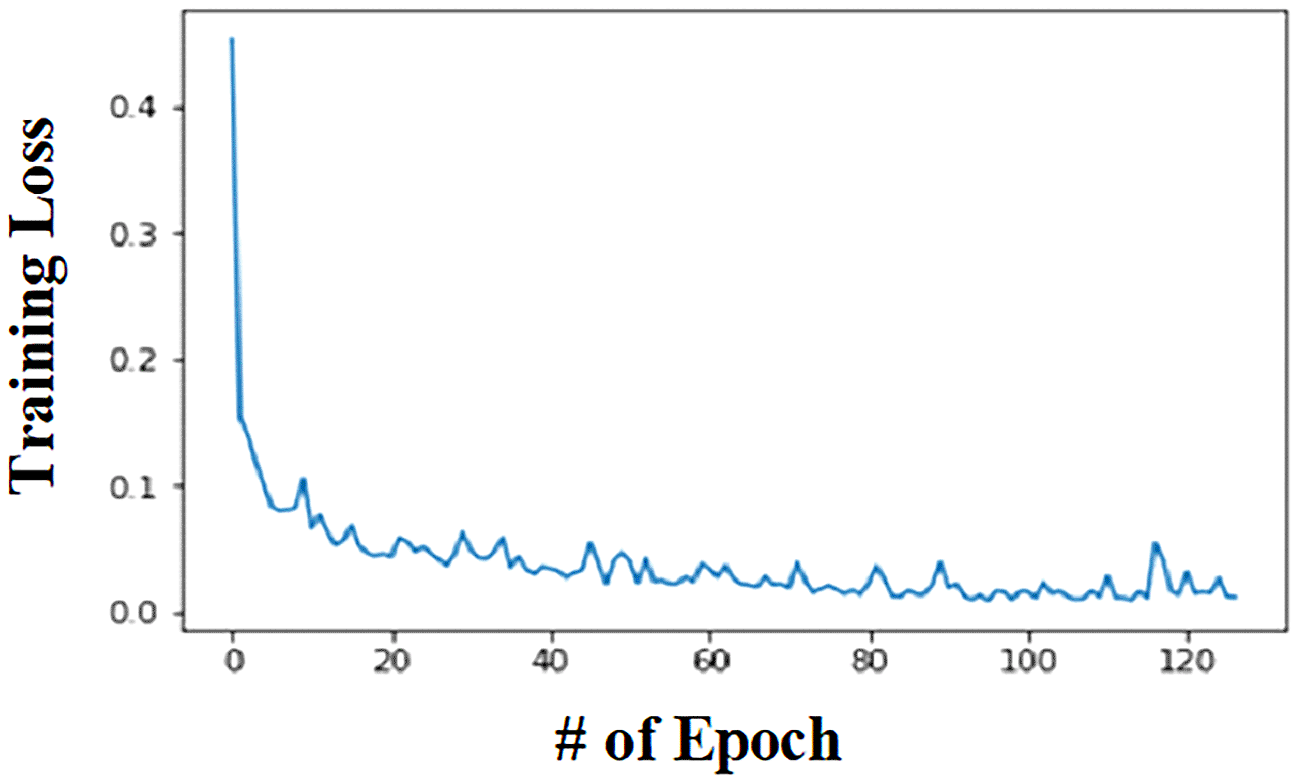
Neural network: The graphical representation of the relationship between epoch and training loss for the human activity dataset is visually depicted in Figure 15. This graph serves as a valuable visual insight into the model’s learning process over successive epochs. Upon close examination of Figure 15, it is evident that the testing loss exhibits a notable decrease, indicating an improvement in the model’s predictive performance. This reduction in testing loss aligns with an observed increase in accuracy, suggesting that the model has become more adept at making accurate predictions on the human activity dataset.
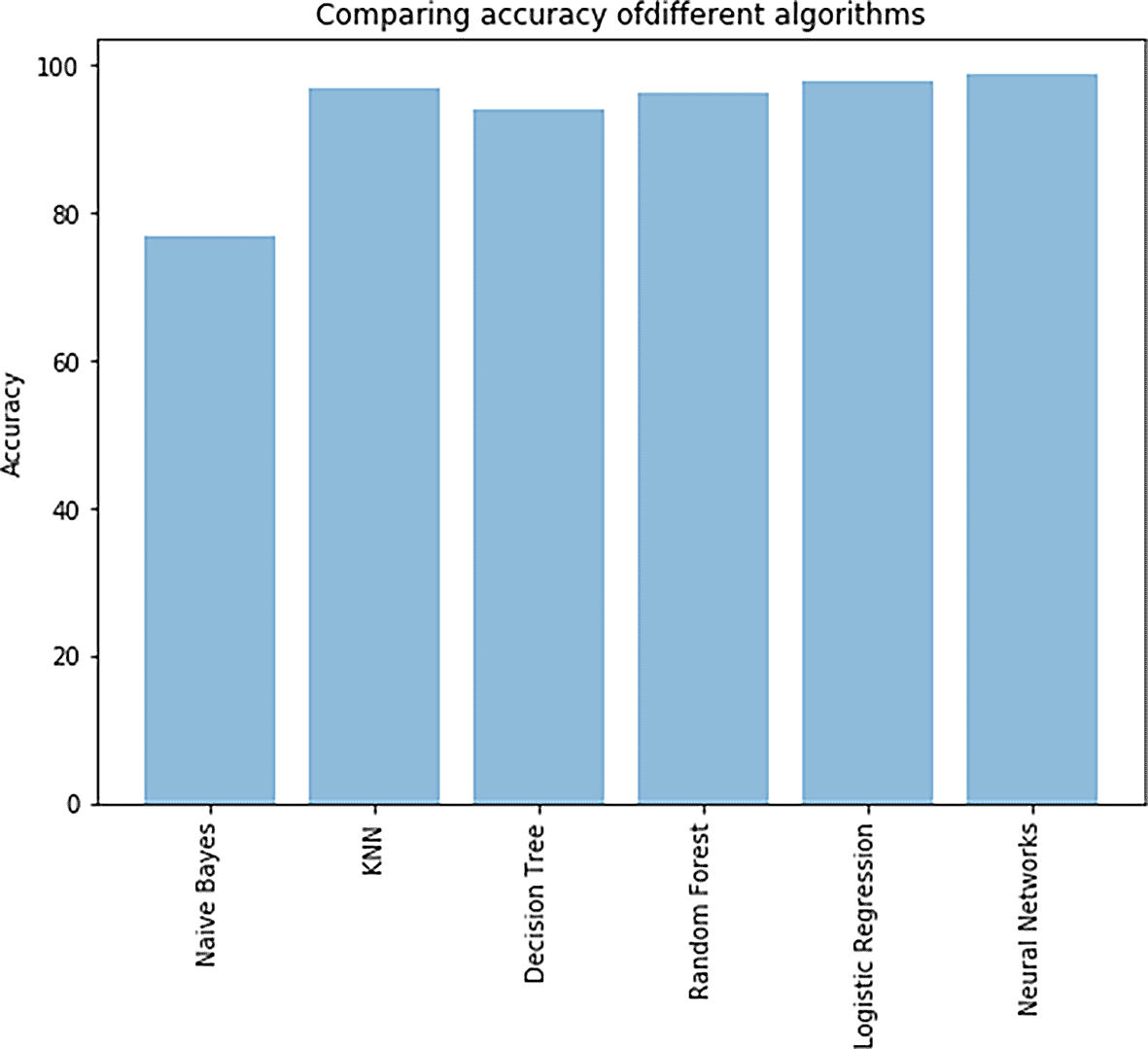
Comparison of different algorithms: The exploration of various algorithms employed in training the model has been represented by treating the algorithms as a variable denoted by x, while their corresponding accuracy serves as the dependent variable y. Notably, the proposed neural network model is subjected to a comparative analysis against benchmark models identified as CNN (Convolutional Neural Network) and GRN (Generic Reference Network). The respective accuracy results for all the models are summarized in Table 1.
Upon careful examination of accuracy Table 1, it becomes evident that the neural network model outperformed all other algorithms in terms of predictive accuracy. Specifically, the neural network achieved an impressive accuracy rate of 98.93%. This high level of accuracy signifies the model’s efficacy in accurately predicting outcomes, showcasing its superiority over benchmark models. The detailed exploration and visualization of algorithmic performance provide valuable insights into the strengths of the proposed neural network model in comparison to established benchmarks, establishing it as a robust and reliable choice for the given task.
Upon careful examination of Figure 16 and the accuracy comparison table, it becomes evident that the neural network model outperformed all other algorithms in terms of predictive accuracy. Specifically, the neural network achieved an impressive accuracy rate of 98.93%. This high level of accuracy signifies the model’s efficacy in accurately predicting outcomes, showcasing its superiority over benchmark models. The detailed exploration and visualization of algorithmic performance provide valuable insights into the strengths of the proposed neural network model in comparison to established benchmarks, establishing it as a robust and reliable choice for the given task.
In conclusion, this research addresses the vital task of human activity recognition, utilizing a dataset derived from triaxial accelerometer and gyroscope sensors. With 561 features and 10,299 records spanning six distinct classes, namely Sitting, Standing, Laying, Walking, Walking_Downstairs, and Walking_Upstairs, our study employed six machine learning algorithms—naïve Bayes, decision tree, random forest, K-nearest neighbours, logistic regression, and neural network.
Notably, our exploration contributes valuable insights to the field by presenting a comprehensive analysis of the performance of these algorithms in predicting human activities. The experimental results reveal the varied accuracies achieved by each model, with the naïve Bayes classifier demonstrating 76.89%, the decision tree classifier achieving 93.39%, the random forest classifier attaining 96.89%, K-nearest neighbours reaching 96.40%, and logistic regression classifier yielding 98.05%. However, the standout performer among these models is the neural network, boasting an impressive accuracy of 98.93%.
This study’s significant contributions lie in its thorough investigation of diverse machine learning methodologies for human activity recognition, shedding light on the strengths and limitations of each algorithm. Furthermore, our work underscores the efficacy of neural networks in achieving a remarkable accuracy rate, positioning it as a promising approach for future endeavors in human activity recognition. These findings not only enhance our understanding of machine learning applications in this domain but also pave the way for more nuanced and effective methodologies in predicting and classifying human activities.
Kaggle: Human Activity Recognition with Smartphones, https://www.kaggle.com/datasets/uciml/human-activity-recognition-with-smartphones
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
Analysis code
Source code available from: https://github.com/someshchinta/Human_Actiity_recognition
Archived source code at time of publication: https://doi.org/10.5281/zenodo.7108706
License: Apache-2.0
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)