Koponen J, Haataja K and Toivanen P. A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.12688/f1000research.131775.1)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
Background: Text recognition of cardboard pharmaceutical packages with machine vision is a challenging task due to the different curvatures of packaging surfaces and different printing methods. Methods: In this research, a novel deep learning method based on regions with convolutional neural networks (R-CNN) for recognizing binarized expiration dates and batch codes printed using different printing methods is proposed. The novel method recognizes the characters in the images without the need to extract handcrafted features. In detail, this approach performs text recognition considering the whole image as an input extracting and learning salient character features straight from packaging surface images. Results: The expiration date and manufacturing batch codes of a real-life pharmaceutical packaging image set are recognized with 91.1% precision with a novel deep learning-based model, while Tesseract OCR text recognition performance with the same image set is 38.3%. The novel model outperformed Tesseract OCR also in tests evaluating recall, accuracy, and F-Measure performance. Furthermore, the novel model was evaluated in terms of multi-object recognition accuracy and the number of unrecognized characters, in order to achieve performance values comparable to existing multi-object recognition methods. Conclusions:The results of this study reveal that the novel deep learning method outperforms the well-established optical character recognition method in recognizing texts printed using different printing methods. The novel method presented in the study recognizes texts printed with different printing methods with high precision. The novel deep learning method is suitable for recognizing texts printed on curved surfaces with proper preprocessing. The problem investigated in the study differs from previous research in the field, focusing on the recognition of texts printed with different printing methods. The research thus fills a gap in text recognition that existed in the research of the field. Furthermore, the study presents new ideas that will be utilized in our future research.
Keywords
Text recognition, Machine Vision, Deep Learning, Regions with Convolutional Neural Networks, R-CNN, Character Recognition, Printing Methods, Expiration Date, Batch Codes, Handcrafted Features, Image Recognition, Multi-Object Recognition, OCR, Tesseract OCR, Precision, Recall, Accuracy, F-Measure, Curved Surfaces, Preprocessing
By the end of 2023, the market value of the pharmaceutical packaging sector is expected to reach USD 101 billion.1 Recognizing product codes using machine vision enables the storage and processing of package-specific manufacturing data, as well as the electronic search and extraction of codes and dates, which is important in the development of intelligent product handling systems.
Cardboard is typically used in pharmaceutical product packaging. Boxes made of cardboard have curved surfaces. When accurate text recognition of text printed on surfaces is needed using 2D machine vision, the curvature is a difficulty in itself as it causes uneven illumination of the packaging surface as presented in Figure 1. Several printing methods are used to print the expiration date and manufacturing batch codes that are important for the usage and handling of pharmaceutical packages. Changes in physical conditions in package imaging as well as printing methods that generate low-contrast text and irregular letter forms make it more difficult to recognize these codes. The recognition process is especially challenging because there are many variants in the codes used on various packages using different printing methods, as well as variances in the codes’ forms, structures, regularity, and colors. In the past ten years, product code recognition techniques have advanced, and several researchers have become more interested in this area of study.
Figure 1. Two cardboard pharmaceutical packages with the expiration date and batch codes printed on the curved packaging surfaces.
The purpose of this research is to demonstrate that, despite field difficulties, texts with imperfections printed on pharmaceutical packaging can be effectively recognized using appropriate pre-processing and deep learning. In the experimental part of the study, the recognition accuracy of the text recognition method trained on a real-life image set and the number of unrecognized characters is measured using generally comparable metrics, and the novel deep learning text recognition method is compared to the Tesseract OCR method in the recognition of dot matrix and ink-printed characters using four multi-object recognition metrics. It is important to note that information related to expiration dates and manufacturing batch codes on pharmaceutical packages is important for safety and must be accurate and reliable. The rest of the paper is organized as follows: we discusses the related works from a survey of the literature. A description of the proposed methodology is then presented. Analysis of experimental results is then presented and finally, the conclusion and future works are presented in the final section.
Related works
The product’s manufacturing markings are recognized by a computer and optical character recognition software from the digitized image produced by an imaging system, which is based on the amount of light energy reflected from the surfaces of the objects in the scene.2 Optical Character Recognition (OCR) methods that compared groups of pixels detected on the surface of a product to models given to the system have been increasingly overtaken by methods utilizing deep learning technology.2 OCR software can recognize characters that are regularly shaped and have good contrast against a simple background.3 However, the difficulties in recognizing packaging texts, which are described with solutions,2 reduce the usability of the OCR method in this high-accuracy task.
Tesseract OCR is a widely used open-source optical character recognition program. It has been in use since 1985 and has evolved significantly throughout the years. Over time, Tesseract OCR has changed. Numerous languages are supported, image binarization is included, and Tesseract 4 added an OCR engine with an LSTM-based neural network, which process an input image line by line into boxes and then feeds them to the LSTM network, which produces the recognition result.4
OCR text recognition was used in the research by Gong et al. (2020) to recognize text in images of food packaging. The text that was printed on the product package had slanted characters. Some images were light-exposed, and some texts were printed with poor print quality. The Tesseract OCR method correctly recognizes 31.1% of characters.5 In the same study, the deep learning text recognition method achieves 95.4% recognition accuracy with identical data.
Deep neural networks are being used more frequently for product text recognition as of 2018, which has made it possible to recognize inconsistent characters, detect and recognize the text of various sizes in images taken in real-world conditions, and even recognize texts from moving packaging.2 Before that, it appears that conventional recognition methods were more frequently employed.2
Methods
This research focused on utilizing deep learning to recognize texts printed on the surface of differently curved packages. Dot matrix printed texts and pressed ink-marked texts are the focus of our study. As part of our research work, we have developed a novel algorithm for recognizing text from images taken from packages. The source images are taken in a controlled imaging environment and binarized with a method in Ref. 6, which, despite the variable contrast between the text and the background and the curvature of the packaging surface, is capable of accurate and robust binarization. The novel method’s text recognition ability is first tested in terms of text recognition accuracy and the number of unrecognized characters. Furthermore, using four criteria, the performance of the deep learning network constructed for text recognition is compared against Tesseract OCR. Text recognition of texts pressed without ink, stamped, or laser printed is excluded from the study. In the experimental recognition tests, we used a set of images of a Finnish health technology company taken from real medical packages, of which 16 pcs were with dot matrix printed texts, and 11 pcs with pressed ink-marked texts. The study’s text recognition was performed on the packaging production batch and expiration date markings, and titles. An example of the binarized images used for text recognition is shown in Figure 2. In the experimental tests, real pharmaceutical packages have been used to ensure that the results of our research are reliable. Since the text recognition of pharmaceutical packages is a new area of research, the number of source images was limited. However, this limitation is only temporary, and research will continue as more source images become available.
Figure 2. Batch code and expiration date texts in a binarized images printed with a pressed ink-marked (left) and with the dot matrix printing methods.
Deep Learning
Deep Learning (DL) is a subset of machine learning in which neural networks are used to learn from data and generate predictions or choices. It is described as a method of teaching a computer to learn from data and make predictions or judgments using neural networks, much like a child does. Deep Learning can be used for a variety of tasks, including image classification, speech recognition, and natural language processing.
R-CNN for expiration date and batch codes recognition
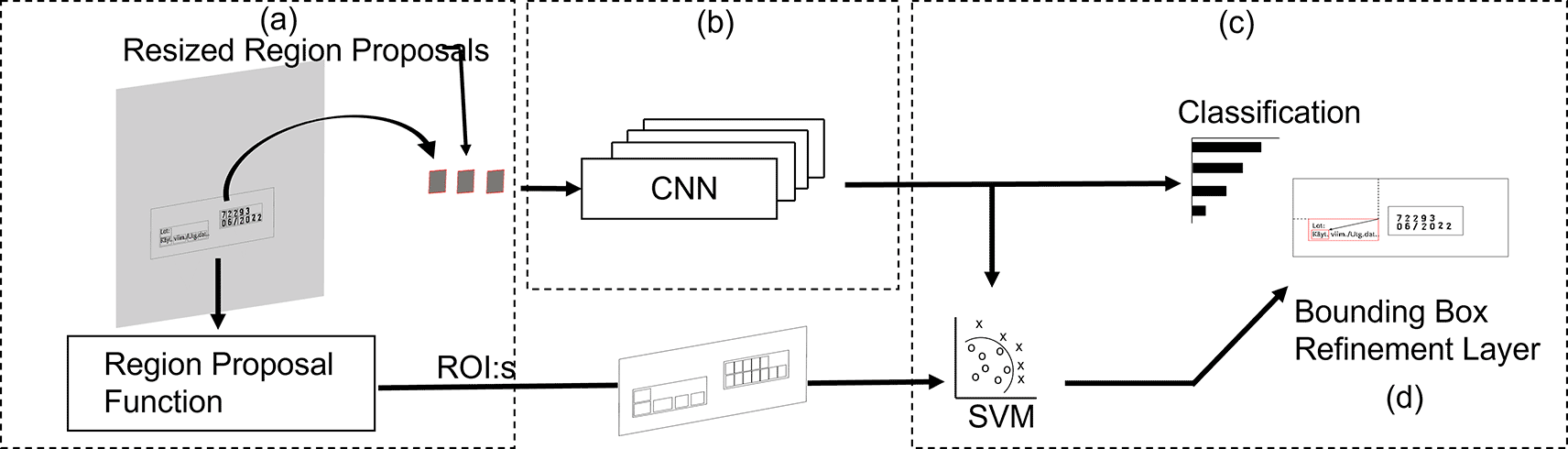
Regions with Convolutional Neural Networks (R-CNN) architecture combines rectangular region proposals with convolutional neural network features. Figure 3 represents the R-CNN architecture in character recognition. For character recognition, R-CNN first extracts several object-independent region proposals from the source image using the method of selective search (Figure 3a). Each region is sent on to the convolution neural network, for the creation of a fixed-size feature vector corresponding to them (Figure 3b). The feature vector is then used as the input to a set of linear SVMs that are trained for each class and output a classification (Figure 3c). To obtain the most accurate coordinates, the vector is also fed into a bounding box refinement layer of a network (Figure 3d).7,8
Figure 3. Region-CNN model working principle.
Training details
The dataset contains 27 binarized source images, 16 of which have dot matrix texts and 11 of which have pressed, and ink-marked texts. The network was trained using the stochastic gradient descent with a momentum optimization algorithm, with a learning rate of 1e-4 that is reduced by 0.02 after every eighth epoch. Other network training parameters include max epoch 400, and a mini-batch size 58. A pre-trained Alex-Net network with transfer learning is combined with a Region-CNN deep learning network to recognize the 43 different categories of objects in the images. First, images are fed into Alex Net CNN (i.e., 227×227×3). The dataset is divided into two parts: training and validation. The final layers of the pre-trained Alex Net CNN were modified to match the number of classes in the training dataset. To prevent network overfitting, data augmentation was used for training images. Modified Region-CNN was trained using the augmented training images and labels.
Results
The experiments aimed to evaluate the recognition accuracy of the deep learning method for text recognition on real-world pharmaceutical packages. The experiments were carried out on available dot matrix, printed, and ink-marked texts. The recognition results were achieved by comparing the recognition results obtained with the test image set to the ground truth data.
R-CNN evaluation in MATLAB
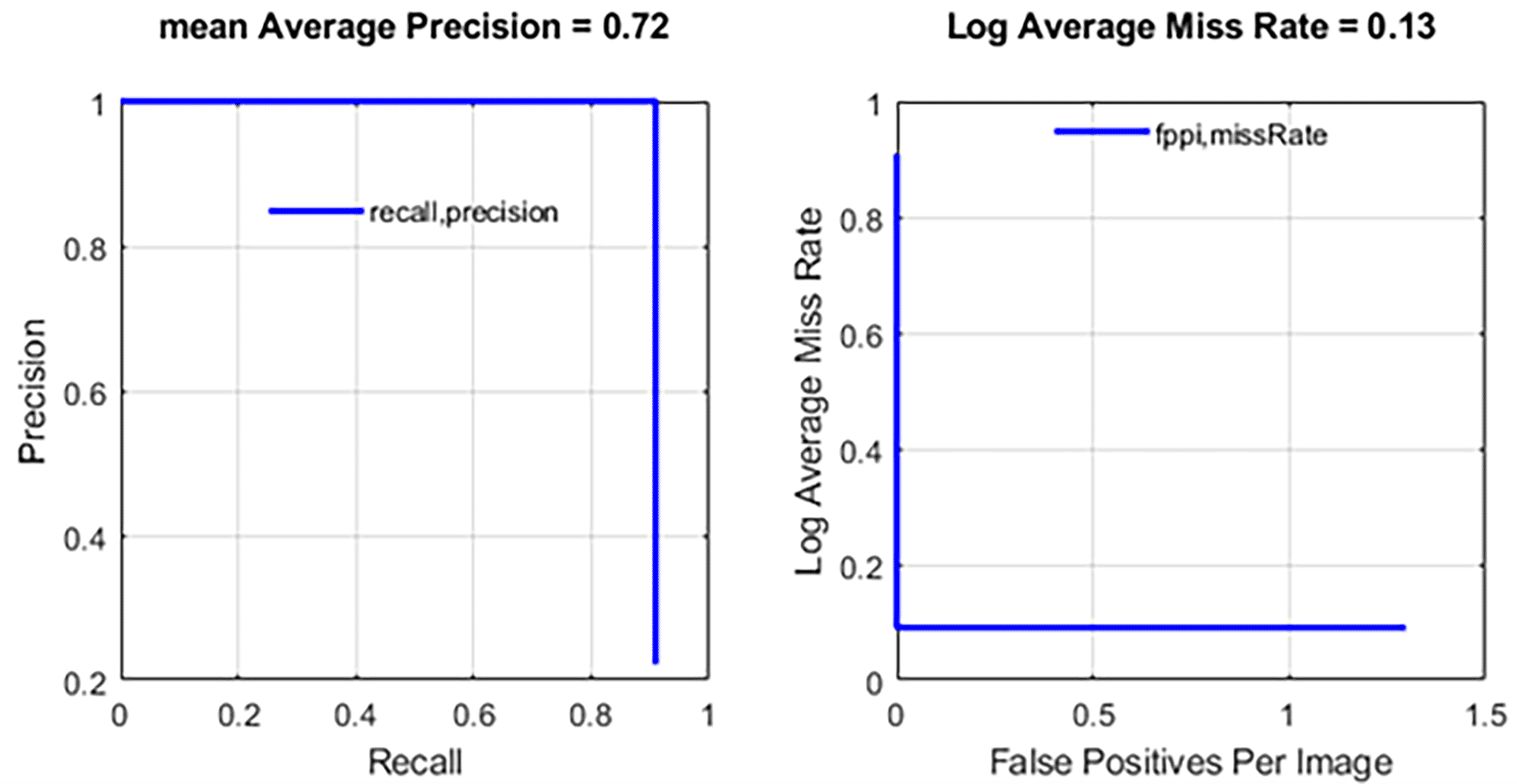
The accuracy of the text recognition of the novel model was analyzed in the first test with a dataset using a generally comparable evaluate Detection Precision9 function. The function outputs the accuracy of each object class for a multi-object detector. Also, the evaluate Detection Miss rate10 function was used in the evaluation, calculating the model’s performance based on the number of undetected objects in the recognition of multiple objects. Figure 4 shows the mean Average Precision- and log Average Miss Rate-curves plotted for all object categories in the character recognition test data set.
Figure 4. The proposed text recognition model’s mean average precision and log average miss rate analysis results.
Recall and precision are cell arrays for a multi-object detector, with each cell containing data points for each object category. Log Average Miss Rate (LAMR) is also calculated for each object category separately. The mean Average Precision (mAP) metric was used to evaluate the performance of the multi-object detection model. The mAP is calculated by taking the mean of the AP values for each object category yielding a Precision value of 0.96 and a Recall value of 0.72. The detector’s performance findings demonstrate the percentages of accurate classification (precision), and all searchable objects detected (recall). The mAP rating of 0.72 indicates that the detector performed well, produced accurate findings, and found a large percentage of the objects analyzed. The Log Average Miss Rate (LAMR) function was used to analyze the performance of the multi-object recognition task. The measured LAMR value of 0.13 demonstrates that the number of undetected objects was very low, and that the detector performed well in the multi-object detection test.
Comparison to Tesseract OCR
In the second experiment, the same data set with images containing text was given for text recognition to both the novel deep learning model and Tesseract OCR. The numbers of all characters for each image were first counted. The number of correctly identified and incorrectly recognized characters, as well as the number of unrecognized and double-identified characters, are calculated for performance evaluation. This gave detailed information on the methods’ text recognition accuracy. The threshold value (α) of the R-CNN model in the recognition accuracy test was set to 0.99.
IoU (Intersection over Union) is a common object detection evaluation metric. IoU is a measure of the intersection being the overlap between the ground truth boundary box and the algorithm-detected boundary box.11 IoU, as depicted in Equation (1), is calculated as the area of overlap between the ground truth bounding box and the predicted bounding box divided by the area of the union of these two.11
(1)
Introducing Key Metrics for Object Detection: TP, FN, TN, FP, Precision, Recall, Accuracy, and F-Measure
Positive and negative samples are required for all supervised learning methods. Using a human face detector as an example, images with faces are positive samples, whereas images without faces are negative.12 After testing, a group of positive and negative samples can be classified into one of four states, as shown in Table 1.12
Table 1. Prediction result of the sample.
Actual positive
Actual negative
Predicted positive
True positives (TP)
False positives (FP)
Predicted negative
False negatives (FN)
True negatives (TN)
Positive samples may create the following scenarios:
1. TP (true positive), in which a positive sample is determined as the target by the detector, IoU ≥ α.
2. FN (false negative), in which a positive sample is determined by the detector to be non-target.
Negative samples can create the following scenarios:
3. TN (true negative), in which a negative sample is determined by the detector to be non-target.
4. The detector determines FP (false positive), or a negative sample, as the target, IoU < α.
These formulas are used to calculate precision and recall:
Precision is the proportion of all correctly retrieved samples (TP) that account for all retrieved samples (TP + FP).12 Its equation is, as given in (2):
(2)
The recall is the proportion of all correctly retrieved samples (TP) that accounts for all objects that should be retrieved (TP + FN).12 Its equation is, as given in (3):
(3)
Accuracy is the proportion of all correctly retrieved samples that account for all samples.12 Its equation is, as given in (4) as follows:
(4)
The F-Measure, as depicted in Eq (5), is the weighted harmonic average of precision and recall.12
(5)
Using these four different metrics the text recognition performance of the novel deep learning and Tesseract OCR algorithms are compared in Table 2.
Table 2. Text recognition performance comparison table based on four metrics.
Region-CNN (%)
Tesseract OCR (%)
Precision
91.1
38.3
Recall
72.7
61.3
Accuracy
69.9
30.8
F-Measure
80.9
47.1
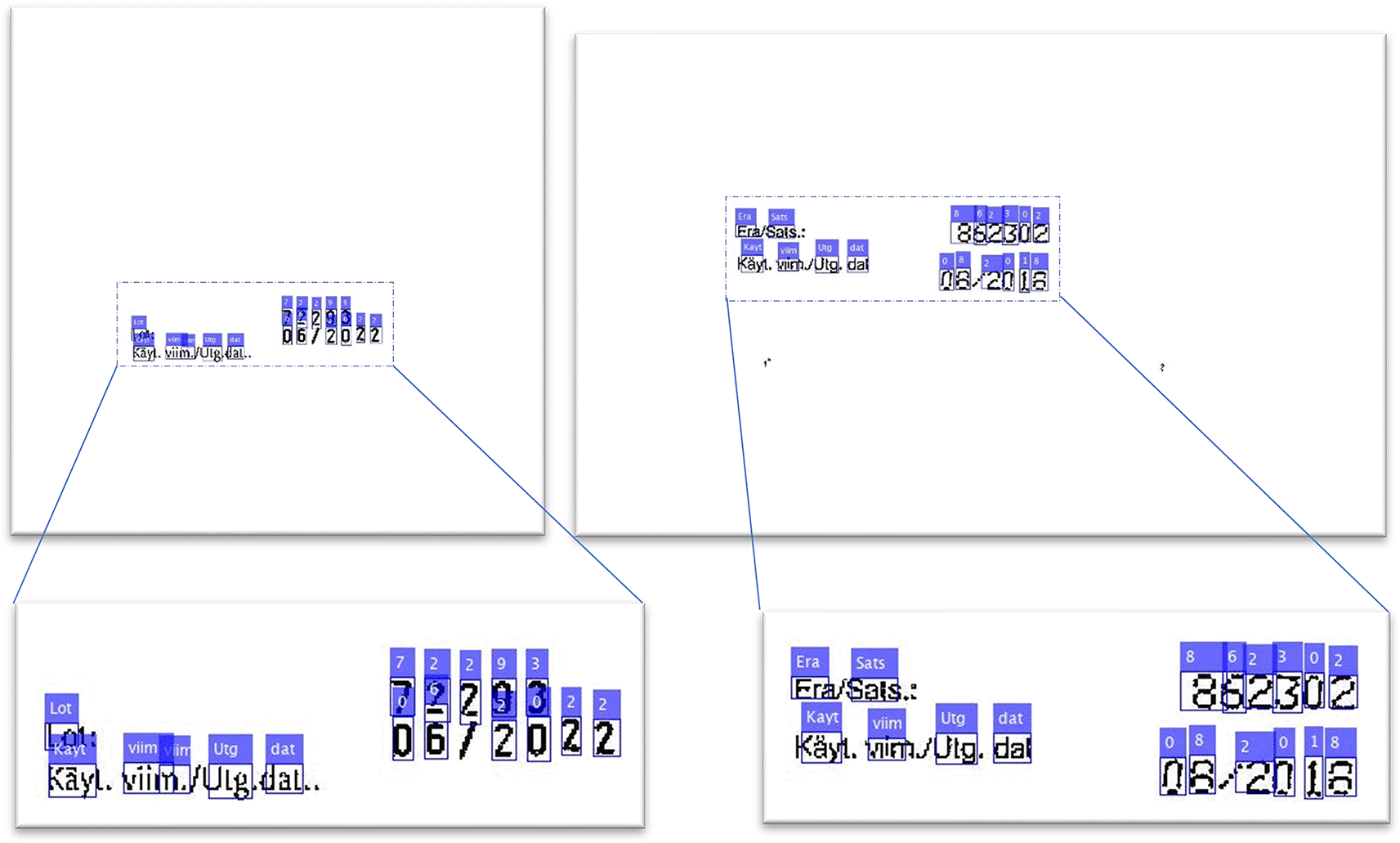
The comparison test results demonstrate that the developed deep learning character recognition accuracy outperforms the OCR method significantly. The deep learning model had a recognition precision of 91.1%, while the OCR method had a recognition precision of 38.3%. The novel deep learning model was significantly more precise and efficient than the OCR method in recognizing the test set’s texts. The deep learning model has a recall value of 72.7%, while the Tesseract method has a recall value of 61.3%. When compared to the Tesseract OCR approach, the novel model’s recall value in text recognition of the target test set is 11,4% higher. On the test image set, the deep learning model’s text recognition accuracy was 69.9%, whereas the Tesseract method’s text recognition accuracy was 30,8%. The F-Measure is a number that measures the object detector’s precision-to-recall ratio. Precision describes the proportion of correct recognitions made out of all retrieved recognitions, whereas recall refers to the proportion of correct recognitions accounts for all recognition’s should have been retrieved. The F-Measure combines these two results into a numerical result that describes the object detector’s overall performance. The F-Measure of the novel deep learning model is 80.9%, which is higher than the F value of the Tesseract OCR text recognition method, which is 47.1%. This shows that the deep learning model outperforms in terms of both Precision and Recall. The results demonstrate that the novel deep learning model is a more efficient text recognition method and can recognize characters in test images more consistently. The text recognition results using the novel Region-CNN method are shown in Figure 5.
Figure 5. The result of deep text recognition in the whole image.
In this paper, deep learning-based text recognition of pharmaceutical packages has been studied, and our novel method for expiration date and batch codes text recognition was presented. The recognition results achieved by a novel method, which is based on a regional convolution neural network, appear to be excellent and significantly outperform those obtained by Tesseract OCR, allowing the recognition of texts with inconsistencies in character shapes printed on curved surfaces with proper preprocessing.
Various methods for recognizing text printed on products have been developed. Commercial OCR engines are available that can recognize high-contrast regularly shaped texts printed on flat surfaces. In the industry, large amounts of perishable food and pharmaceutical packages are produced daily, and the texts printed on their surface is read by people several times during the operation. Text is printed on product surfaces using various printing methods to achieve cost-effective production. The pharmaceutical industry employs various printing methods, such as laser printing, pressed without ink, and pressed with ink, resulting consistent character shapes. However, characters printed using dot matrix and manual stamping methods may have inconsistencies in their character shapes. In places where pharmaceutical product packaging is handled, such as pharmacies and drug storage facilities, where it is essential to recognize texts printed with various methods, a targeted method is required.
We compare the text recognition performance obtained using a Tesseract OCR and our novel targeted method with real-life pharmaceutical packaging in this study. We find that the novel deep learning method produces highly accurate recognition results that completely outperform the results obtained using a Tesseract OCR, indicating the limitations of optical text recognition for the research’s text recognition needs.
Although text recognition for pharmaceutical packaging texts printed with different methods is an essential task, it is still in its early stages due to the limited availability of source images of actual pharmaceutical packages for research purposes.
To the best of our knowledge, this is the first study in which deep learning is used to recognize inconsistencies in texts printed using different printing methods. We are confident that with more training data, the proposed method’s performance would increase even more.
In the following study, we focus on the domain-specific contextual processing of recognized text characters. This results in a three-phase text recognition pipeline targeted at recognizing manufacturing markings on pharmaceutical packaging. With this approach, we improve the understanding of how deep learning can be applied in this field.
Data availability
Underlying data
Open Scientific Framework: The underlying data for A novel deep learning method for recognizing texts printed with multiple different printing methods, https://doi.org/10.17605/OSF.IO/MP3RB.13
This project contains the following underlying data:
• Novel text recognition methods source code for the Octave software.
• RCNN and OCR recognition methods metrics spreadsheet.xlsx (An Excel spreadsheet containing the achieved recognition results).
2.
Koponen J, Haataja K, Toivanen P:
Recent advancements in machine vision methods for product code recognition: A systematic review.
F1000Res.
2022; 11(1099): 1099. Publisher Full Text
3.
Althobaiti H, Lu C:
A survey on Arabic optical character recognition and an isolated handwritten Arabic character recognition algorithm using encoded freeman chain code.
Paper presented at the 2017 51st Annual Conference on Information Sciences and Systems, CISS 2017.
2017.
4.
Tesseract User Manual|tessdoc (tesseract-ocr.github.io).
5.
Gong L, Thota M, Yu M, et al.:
A novel unified deep neural networks methodology for use by date recognition in retail food package image.
SIViP.
2020; 15(3): 449–457. Publisher Full Text
6.
Koponen J, Haataja K, Toivanen P:
Text Recognition of Cardboard Pharmaceutical Packages by Utilizing Machine Vision.
Electronic Imaging.
2021; 33: 235-1–235-7. Publisher Full Text
7.
Wang Y, Liu X, Tang Z:
An R-CNN based method to localize speech balloons in comics.
MultiMedia Modeling: 22nd International Conference, MMM 2016, Miami, FL, USA, January 4-6, 2016, Proceedings, Part I 22.
2016; pp. 444–453.
8.
Girshick R, Donahue J, Darrell T, et al.:
Rich feature hierarchies for accurate object detection and semantic segmentation.
Proceedings of the 2014 Conference on Computer Vision and Pattern Recognition.
2014.
11.
Nachappa CH, Rani NS, Pati PB, et al.:
Adaptive dewarping of severely warped camera-captured document images based on document map generation.
Int. J. Doc. Anal. Recognit.
2023; 1–21. PubMed Abstract
| Publisher Full Text
| Free Full Text
12.
Gong S, Liu C, Ji Y, et al.:
Advanced image and video processing using MATLAB.
Vol. 12. .
Springer;
2018; p. 581.
13.
Koponen J:
Recognition results of a Novel deep learning method for recognizing texts printed with multiple different printing methods.13 March 2023. Publisher Full Text
Koponen J, Haataja K and Toivanen P. A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.12688/f1000research.131775.1)
NOTE: If applicable, it is important to ensure the information in square brackets after the title is included in all citations of this article.
track
receive updates on this article
Track an article to receive email alerts on any updates to this article.
Share
Open Peer Review
Current Reviewer Status:
?
Key to Reviewer Statuses
VIEWHIDE
ApprovedThe paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approvedFundamental flaws in the paper seriously undermine the findings and conclusions
Ghosh M. Reviewer Report For: A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.5256/f1000research.144650.r201970)
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name
... Continue reading
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name R-CNN stands for Region-based CNN but the authors presented as region with CNN. What is the difference between them should be reflected in the paper.
2. The novelty in the framework is not seen. The authors should explain that.
3. The R-CNN framework is not explained in this paper. The authors should explain in detail.
4. The dataset section is weak. The number of images is very low. How deep-learning is working with these images though authors claim that they used data augmentation. But what are the techniques and how many images in the final dataset are not described?
5. The evaluation metrics are generally described in the experimental section before the results.
6. In the training the authors stated that they used Alexnet but it is not the R-CNN diagram. What are the requirements of these two deep learning methods?
7. In the training details the train-test rations are not mentioned.
8. The comparison with the state of the art is not performed.
9. The reference section is weak.
Is the work clearly and accurately presented and does it cite the current literature?
No
Is the study design appropriate and is the work technically sound?
No
Are sufficient details of methods and analysis provided to allow replication by others?
No
If applicable, is the statistical analysis and its interpretation appropriate?
No
Are all the source data underlying the results available to ensure full reproducibility?
Partly
Are the conclusions drawn adequately supported by the results?
Partly
Competing Interests: No competing interests were disclosed.
Reviewer Expertise: Artificial intelligence, Deep learning, image processing
I confirm that I have read this submission and believe that I have an appropriate level of expertise to state that I do not consider it to be of an acceptable scientific standard, for reasons outlined above.
Ghosh M. Reviewer Report For: A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.5256/f1000research.144650.r201970)
Jarmo Koponen, School of Computing, Kuopio campus, University of Eastern Finland, Kuopio, FI-70211, Finland
25 Jun 2024
Author Response
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the
...
Continue readingThank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name R-CNN stands for Region-based CNN but the authors presented as region with CNN. What is the difference between them should be reflected in the paper.
This is valuable feedback. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. The novelty in the framework is not seen. The authors should explain that.
Referring to the previous response, I would like to add that the application is in a new area that has been scarcely studied.
3. The R-CNN framework is not explained in this paper. The authors should explain in detail.
The paper has been revised to enhance the explanation of the R-CNN framework. Although the original version included an explanation through both text and an illustrative figure, we have now provided a more detailed description to clarify the framework further.
4. The dataset section is weak. The number of images is very low. How deep-learning is working with these images though authors claim that they used data augmentation. But what are the techniques and how many images in the final dataset are not described?
In training details include that information. In addition underlying data section provides more information on the matter
5. The evaluation metrics are generally described in the experimental section before the results.
I have thoroughly revised the evaluation metrics to ensure they are relevant to the research domain. The metrics have been updated and are now specifically tailored to better align with the study’s objectives and context.
6. In the training the authors stated that they used Alexnet but it is not the R-CNN diagram. What are the requirements of these two deep learning methods?
I have clarified the requirements and differences between AlexNet and the R-CNN methods in the revised manuscript, ensuring that their respective roles and implementations are clearly explained.
7. In the training details the train-test rations are not mentioned.
This information is provided both in the paper and in the 'Underlying Data' section.
8. The comparison with the state of the art is not performed.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication (Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.)) and an industry-validated method. Additionally, a systematic review article (Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
9. The reference section is weak
The related work section has been strengthened, particularly in relation to the context of the study.
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name R-CNN stands for Region-based CNN but the authors presented as region with CNN. What is the difference between them should be reflected in the paper.
This is valuable feedback. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. The novelty in the framework is not seen. The authors should explain that.
Referring to the previous response, I would like to add that the application is in a new area that has been scarcely studied.
3. The R-CNN framework is not explained in this paper. The authors should explain in detail.
The paper has been revised to enhance the explanation of the R-CNN framework. Although the original version included an explanation through both text and an illustrative figure, we have now provided a more detailed description to clarify the framework further.
4. The dataset section is weak. The number of images is very low. How deep-learning is working with these images though authors claim that they used data augmentation. But what are the techniques and how many images in the final dataset are not described?
In training details include that information. In addition underlying data section provides more information on the matter
5. The evaluation metrics are generally described in the experimental section before the results.
I have thoroughly revised the evaluation metrics to ensure they are relevant to the research domain. The metrics have been updated and are now specifically tailored to better align with the study’s objectives and context.
6. In the training the authors stated that they used Alexnet but it is not the R-CNN diagram. What are the requirements of these two deep learning methods?
I have clarified the requirements and differences between AlexNet and the R-CNN methods in the revised manuscript, ensuring that their respective roles and implementations are clearly explained.
7. In the training details the train-test rations are not mentioned.
This information is provided both in the paper and in the 'Underlying Data' section.
8. The comparison with the state of the art is not performed.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication (Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.)) and an industry-validated method. Additionally, a systematic review article (Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
9. The reference section is weak
The related work section has been strengthened, particularly in relation to the context of the study.
Jarmo Koponen, School of Computing, Kuopio campus, University of Eastern Finland, Kuopio, FI-70211, Finland
25 Jun 2024
Author Response
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the
...
Continue readingThank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name R-CNN stands for Region-based CNN but the authors presented as region with CNN. What is the difference between them should be reflected in the paper.
This is valuable feedback. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. The novelty in the framework is not seen. The authors should explain that.
Referring to the previous response, I would like to add that the application is in a new area that has been scarcely studied.
3. The R-CNN framework is not explained in this paper. The authors should explain in detail.
The paper has been revised to enhance the explanation of the R-CNN framework. Although the original version included an explanation through both text and an illustrative figure, we have now provided a more detailed description to clarify the framework further.
4. The dataset section is weak. The number of images is very low. How deep-learning is working with these images though authors claim that they used data augmentation. But what are the techniques and how many images in the final dataset are not described?
In training details include that information. In addition underlying data section provides more information on the matter
5. The evaluation metrics are generally described in the experimental section before the results.
I have thoroughly revised the evaluation metrics to ensure they are relevant to the research domain. The metrics have been updated and are now specifically tailored to better align with the study’s objectives and context.
6. In the training the authors stated that they used Alexnet but it is not the R-CNN diagram. What are the requirements of these two deep learning methods?
I have clarified the requirements and differences between AlexNet and the R-CNN methods in the revised manuscript, ensuring that their respective roles and implementations are clearly explained.
7. In the training details the train-test rations are not mentioned.
This information is provided both in the paper and in the 'Underlying Data' section.
8. The comparison with the state of the art is not performed.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication (Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.)) and an industry-validated method. Additionally, a systematic review article (Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
9. The reference section is weak
The related work section has been strengthened, particularly in relation to the context of the study.
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. According to the title of the paper the "novel deep-learning method for recognizing texts with multiple different printing methods" the novelty is questionable. The authors should clearly explain the novelty. They claim they designed the R-CNN framework. The name R-CNN stands for Region-based CNN but the authors presented as region with CNN. What is the difference between them should be reflected in the paper.
This is valuable feedback. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. The novelty in the framework is not seen. The authors should explain that.
Referring to the previous response, I would like to add that the application is in a new area that has been scarcely studied.
3. The R-CNN framework is not explained in this paper. The authors should explain in detail.
The paper has been revised to enhance the explanation of the R-CNN framework. Although the original version included an explanation through both text and an illustrative figure, we have now provided a more detailed description to clarify the framework further.
4. The dataset section is weak. The number of images is very low. How deep-learning is working with these images though authors claim that they used data augmentation. But what are the techniques and how many images in the final dataset are not described?
In training details include that information. In addition underlying data section provides more information on the matter
5. The evaluation metrics are generally described in the experimental section before the results.
I have thoroughly revised the evaluation metrics to ensure they are relevant to the research domain. The metrics have been updated and are now specifically tailored to better align with the study’s objectives and context.
6. In the training the authors stated that they used Alexnet but it is not the R-CNN diagram. What are the requirements of these two deep learning methods?
I have clarified the requirements and differences between AlexNet and the R-CNN methods in the revised manuscript, ensuring that their respective roles and implementations are clearly explained.
7. In the training details the train-test rations are not mentioned.
This information is provided both in the paper and in the 'Underlying Data' section.
8. The comparison with the state of the art is not performed.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication (Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.)) and an industry-validated method. Additionally, a systematic review article (Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
9. The reference section is weak
The related work section has been strengthened, particularly in relation to the context of the study.
Chandio AA. Reviewer Report For: A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.5256/f1000research.144650.r174859)
The authors have worked on the text recognition from pharmaceutical images. This is a complex and challenges problem, however, the methods used by the authors are not state-of-the-art. Moreover, the comparison is not made with the related work.
... Continue reading
The authors have worked on the text recognition from pharmaceutical images. This is a complex and challenges problem, however, the methods used by the authors are not state-of-the-art. Moreover, the comparison is not made with the related work.
1. The paper lacks the novelty of the work.
2. A comparison has been made between a CNN model and Tesseract OCR, however, the Tesseract OCR works for scanned text documents. The authors should compare their work with text recognition from images (synthetic or natural scenes) methods.
3. The authors may use instance or semantic segmentation, which will give better accuracy than the RCNN.
4. Why the Recall and Accuracy values are very smaller than the Precision?
5. The Alex-Net is a very old model and is not preferred nowadays. The authors may use a state-of-the-art pretrained model.
6. The number of images in the dataset are very low. For this low data, RCNN model will not give better results.
7. There are several English grammar mistakes.
Is the work clearly and accurately presented and does it cite the current literature?
Yes
Is the study design appropriate and is the work technically sound?
Partly
Are sufficient details of methods and analysis provided to allow replication by others?
Partly
If applicable, is the statistical analysis and its interpretation appropriate?
I cannot comment. A qualified statistician is required.
Are all the source data underlying the results available to ensure full reproducibility?
Yes
Are the conclusions drawn adequately supported by the results?
Yes
Competing Interests: No competing interests were disclosed.
Reviewer Expertise: I am a PhD in Computer Vision and Image Processing. My area of research is related to text detection and recognition from natural scene images, document analysis and OCR.
I confirm that I have read this submission and believe that I have an appropriate level of expertise to confirm that it is of an acceptable scientific standard, however I have significant reservations, as outlined above.
Chandio AA. Reviewer Report For: A novel deep learning method for recognizing texts printed with multiple different printing methods [version 1; peer review: 1 approved with reservations, 1 not approved]. F1000Research 2023, 12:427 (https://doi.org/10.5256/f1000research.144650.r174859)
Jarmo Koponen, School of Computing, Kuopio campus, University of Eastern Finland, Kuopio, FI-70211, Finland
25 Jun 2024
Author Response
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks
...
Continue readingThank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks the novelty of the work.
This is valuable feedback. The title of the entire publication has been reconsidered and adapted. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. A comparison has been made between a CNN model and Tesseract OCR, however, the Tesseract OCR works for scanned text
documents. The authors should compare their work with text recognition from images (synthetic or natural scenes) methods.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication ( Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.) and an industry-validated method. Additionally, a systematic review article ( Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
3. The authors may use instance or semantic segmentation, which will give better accuracy than the RCNN.
Since OCR is proven to be in use in the pharmaceutical industry, we have not compared two new methods, but rather compared the new application to the previously used one. However, in a future study, we can compare this application using the Region CNN model to another application based on a different deep learning model.
4. Why the Recall and Accuracy values are very smaller than the Precision?
This feedback led to a thorough review and adaptation of the performance metrics. Now, the curve surpassing all threshold values enables evaluation with three relevant metrics.
5. The Alex-Net is a very old model and is not preferred nowadays. The authors may use a state-of-the-art pretrained model.
This is valuable feedback. However, although AlexNet and the Region CNN model are considered older, they contain beneficial features that are not present in newer members of the CNN family (Fast, Faster), such as a fixed size of 4096 feature vector for each region proposal.
6. The number of images in the dataset are very low. For this low data, RCNN model will not give better results.
This field of study, being new, is still in the development phase. The diagram of metrics added in the paper presents insights into the model's performance.
7. There are several English grammar mistakes.
I apologize for the errors. I have now corrected them.
Thank you again for your valuable feedback. I have taken it into account, and it has helped improve my skills.
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks the novelty of the work.
This is valuable feedback. The title of the entire publication has been reconsidered and adapted. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. A comparison has been made between a CNN model and Tesseract OCR, however, the Tesseract OCR works for scanned text
documents. The authors should compare their work with text recognition from images (synthetic or natural scenes) methods.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication ( Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.) and an industry-validated method. Additionally, a systematic review article ( Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
3. The authors may use instance or semantic segmentation, which will give better accuracy than the RCNN.
Since OCR is proven to be in use in the pharmaceutical industry, we have not compared two new methods, but rather compared the new application to the previously used one. However, in a future study, we can compare this application using the Region CNN model to another application based on a different deep learning model.
4. Why the Recall and Accuracy values are very smaller than the Precision?
This feedback led to a thorough review and adaptation of the performance metrics. Now, the curve surpassing all threshold values enables evaluation with three relevant metrics.
5. The Alex-Net is a very old model and is not preferred nowadays. The authors may use a state-of-the-art pretrained model.
This is valuable feedback. However, although AlexNet and the Region CNN model are considered older, they contain beneficial features that are not present in newer members of the CNN family (Fast, Faster), such as a fixed size of 4096 feature vector for each region proposal.
6. The number of images in the dataset are very low. For this low data, RCNN model will not give better results.
This field of study, being new, is still in the development phase. The diagram of metrics added in the paper presents insights into the model's performance.
7. There are several English grammar mistakes.
I apologize for the errors. I have now corrected them.
Thank you again for your valuable feedback. I have taken it into account, and it has helped improve my skills.
Jarmo Koponen, School of Computing, Kuopio campus, University of Eastern Finland, Kuopio, FI-70211, Finland
25 Jun 2024
Author Response
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks
...
Continue readingThank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks the novelty of the work.
This is valuable feedback. The title of the entire publication has been reconsidered and adapted. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. A comparison has been made between a CNN model and Tesseract OCR, however, the Tesseract OCR works for scanned text
documents. The authors should compare their work with text recognition from images (synthetic or natural scenes) methods.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication ( Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.) and an industry-validated method. Additionally, a systematic review article ( Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
3. The authors may use instance or semantic segmentation, which will give better accuracy than the RCNN.
Since OCR is proven to be in use in the pharmaceutical industry, we have not compared two new methods, but rather compared the new application to the previously used one. However, in a future study, we can compare this application using the Region CNN model to another application based on a different deep learning model.
4. Why the Recall and Accuracy values are very smaller than the Precision?
This feedback led to a thorough review and adaptation of the performance metrics. Now, the curve surpassing all threshold values enables evaluation with three relevant metrics.
5. The Alex-Net is a very old model and is not preferred nowadays. The authors may use a state-of-the-art pretrained model.
This is valuable feedback. However, although AlexNet and the Region CNN model are considered older, they contain beneficial features that are not present in newer members of the CNN family (Fast, Faster), such as a fixed size of 4096 feature vector for each region proposal.
6. The number of images in the dataset are very low. For this low data, RCNN model will not give better results.
This field of study, being new, is still in the development phase. The diagram of metrics added in the paper presents insights into the model's performance.
7. There are several English grammar mistakes.
I apologize for the errors. I have now corrected them.
Thank you again for your valuable feedback. I have taken it into account, and it has helped improve my skills.
Thank you for your peer review feedback on my publication. I have revised the publication considering your comments. Here are detailed responses to the points raised:
1. The paper lacks the novelty of the work.
This is valuable feedback. The title of the entire publication has been reconsidered and adapted. I have not developed the Region CNN method, but I have created a new application that uses the Region CNN method.
2. A comparison has been made between a CNN model and Tesseract OCR, however, the Tesseract OCR works for scanned text
documents. The authors should compare their work with text recognition from images (synthetic or natural scenes) methods.
The comparison has been performed against both a method obtained from a pharmaceutical packaging publication ( Kumar, G. P., & Prasad, P. B. (2014). Machine vision based quality control: importance in pharmaceutical Industry. International Journal of Computer Applications, 975, 8887.) and an industry-validated method. Additionally, a systematic review article ( Koponen, J., Haataja, K., & Toivanen, P. (2022). Recent advancements in machine vision methods for product code recognition: A systematic review. F1000Research, 11.) did not find an existing solution but identified a research gap regarding the state-of-the-art method in the pharmaceutical packaging field.
3. The authors may use instance or semantic segmentation, which will give better accuracy than the RCNN.
Since OCR is proven to be in use in the pharmaceutical industry, we have not compared two new methods, but rather compared the new application to the previously used one. However, in a future study, we can compare this application using the Region CNN model to another application based on a different deep learning model.
4. Why the Recall and Accuracy values are very smaller than the Precision?
This feedback led to a thorough review and adaptation of the performance metrics. Now, the curve surpassing all threshold values enables evaluation with three relevant metrics.
5. The Alex-Net is a very old model and is not preferred nowadays. The authors may use a state-of-the-art pretrained model.
This is valuable feedback. However, although AlexNet and the Region CNN model are considered older, they contain beneficial features that are not present in newer members of the CNN family (Fast, Faster), such as a fixed size of 4096 feature vector for each region proposal.
6. The number of images in the dataset are very low. For this low data, RCNN model will not give better results.
This field of study, being new, is still in the development phase. The diagram of metrics added in the paper presents insights into the model's performance.
7. There are several English grammar mistakes.
I apologize for the errors. I have now corrected them.
Thank you again for your valuable feedback. I have taken it into account, and it has helped improve my skills.
Alongside their report, reviewers assign a status to the article:
Approved - the paper is scientifically sound in its current form and only minor, if any, improvements are suggested
Approved with reservations -
A number of small changes, sometimes more significant revisions are required to address specific details and improve the papers academic merit.
Not approved - fundamental flaws in the paper seriously undermine the findings and conclusions
Adjust parameters to alter display
View on desktop for interactive features
Includes Interactive Elements
View on desktop for interactive features
Competing Interests Policy
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Examples of 'Non-Financial Competing Interests'
Within the past 4 years, you have held joint grants, published or collaborated with any of the authors of the selected paper.
You have a close personal relationship (e.g. parent, spouse, sibling, or domestic partner) with any of the authors.
You are a close professional associate of any of the authors (e.g. scientific mentor, recent student).
You work at the same institute as any of the authors.
You hope/expect to benefit (e.g. favour or employment) as a result of your submission.
You are an Editor for the journal in which the article is published.
Examples of 'Financial Competing Interests'
You expect to receive, or in the past 4 years have received, any of the following from any commercial organisation that may gain financially from your submission: a salary, fees, funding, reimbursements.
You expect to receive, or in the past 4 years have received, shared grant support or other funding with any of the authors.
You hold, or are currently applying for, any patents or significant stocks/shares relating to the subject matter of the paper you are commenting on.
Stay Updated
Sign up for content alerts and receive a weekly or monthly email with all newly published articles


Comments on this article Comments (0)