Keywords
Traffic Accidents, Accident Severity, Road Safety, Accident Prediction Modeling, Random Forest
Traffic Accidents, Accident Severity, Road Safety, Accident Prediction Modeling, Random Forest
We express our gratitude to the reviewers for their constructive comments that greatly enhanced the manuscript's quality. In response to Reviewer-1's insightful observation on the term "accident", we have clarified the context and regional usage of the term in the paper, while also acknowledging the global standards. As per suggestions, we've incorporated the Random Forest algorithm formulation in the methods section and discussed the significance of the Gini impurity test in understanding the importance of explanatory variables.
Addressing Reviewer-2's feedback, we've emphasized the motivation behind our work and its academic contribution in the Introduction section, ensuring a comprehensive understanding of our study's significance. We revisited and corrected specific literature citations, particularly references 7, 14, and 15. The choice of factors, their contribution, and the transferability of the developed model are now prominently highlighted in a dedicated subsection. Further, to address the concerns about the novelty, we've incorporated a detailed paragraph in the conclusion, elucidating the innovative aspects and unique contributions of our predictive model in comparison to existing literature.
We believe these revisions have amplified the clarity, depth, and significance of our research, ensuring alignment with the journal's standards and objectives.
See the authors' detailed response to the review by Sanjeev Sinha
See the authors' detailed response to the review by Hamsa Zubaidi
Road accidents are a significant public health concern worldwide, with an estimated 1.35 million deaths caused by road traffic accidents each year.1 Developing countries, such as India, are disproportionately affected, with over 150,000 fatalities reported annually.1 Road safety is a major concern in India, with a large number of accidents and fatalities reported each year. According to the Ministry of Road Transport and Highways, there were 449,002 road accidents in India in 2019, resulting in 151,113 deaths and 451,361 injuries.2
Road accidents pose a threat to health, leading to approximately 1.35 million deaths globally each year. Countries such as India are particularly affected, experiencing over 150,000 fatalities annually. This alarming situation emphasizes the importance of comprehending the factors that contribute to these accidents in order to develop prevention measures. Our research is motivated by the urgency to improve road safety in high-risk areas, like India, where the number of accidents and fatalities remains distressingly high.
Our research delves into the modeling of accident severity, a statistical technique in the field of road safety. Traditional statistical models like logit and probit have been used since the 1990s to predict traffic accident severity, but they have limitations, especially when their underlying assumptions are violated.3,4 On the other hand, Artificial Intelligence (AI) models offer adaptability and can handle complex nonlinear relationships without being constrained by such assumptions. We focus on the Random Forest (RF) algorithm, an advanced machine learning model with distinct advantages over other algorithms for predicting accident severity.5 Through tuning parameters and preprocessing techniques, we aim to improve the performance of RF even further, making our academic contribution significant in the pursuit of more accurate and reliable predictions for accident severity.
The modelling process involves analyzing data on past accidents and identifying the factors that contributed to their occurrence and severity.6 These factors can include road conditions, weather, driver behaviour, and vehicle type, among others. The goal of accident severity modelling is to identify the most important factors contributing to accidents and to develop evidence-based strategies to improve road safety and reduce the number and severity of accidents.7–9
Statistical models have been widely used for predicting traffic accidents’ severity.3,4 Artificial intelligence models, in contrast, do not make any assumptions and are more adaptable. They can handle intricate nonlinear relationships and generally offer higher predictive accuracy than statistical approaches.5 RF, in particular, has been successfully applied in various contexts, and its performance can be further improved by tuning key parameters and careful data preprocessing.4,5,10,11 The performance of the RF algorithm is significantly influenced by the selection of hyperparameters.12 To optimize its performance, identifying the optimal parameter values is crucial.
The main objective of our study is to develop a predictive model for the severity of traffic accidents on Indian highways using RF models due to their accuracy and interpretability.
The findings of our study will be used to develop a predictive model for accident severity that can inform road safety policies and interventions. This model can be used to identify high-risk areas and prioritize resources for accident prevention and mitigation.
The study areas selected are the National Highways two stretches as mentioned below

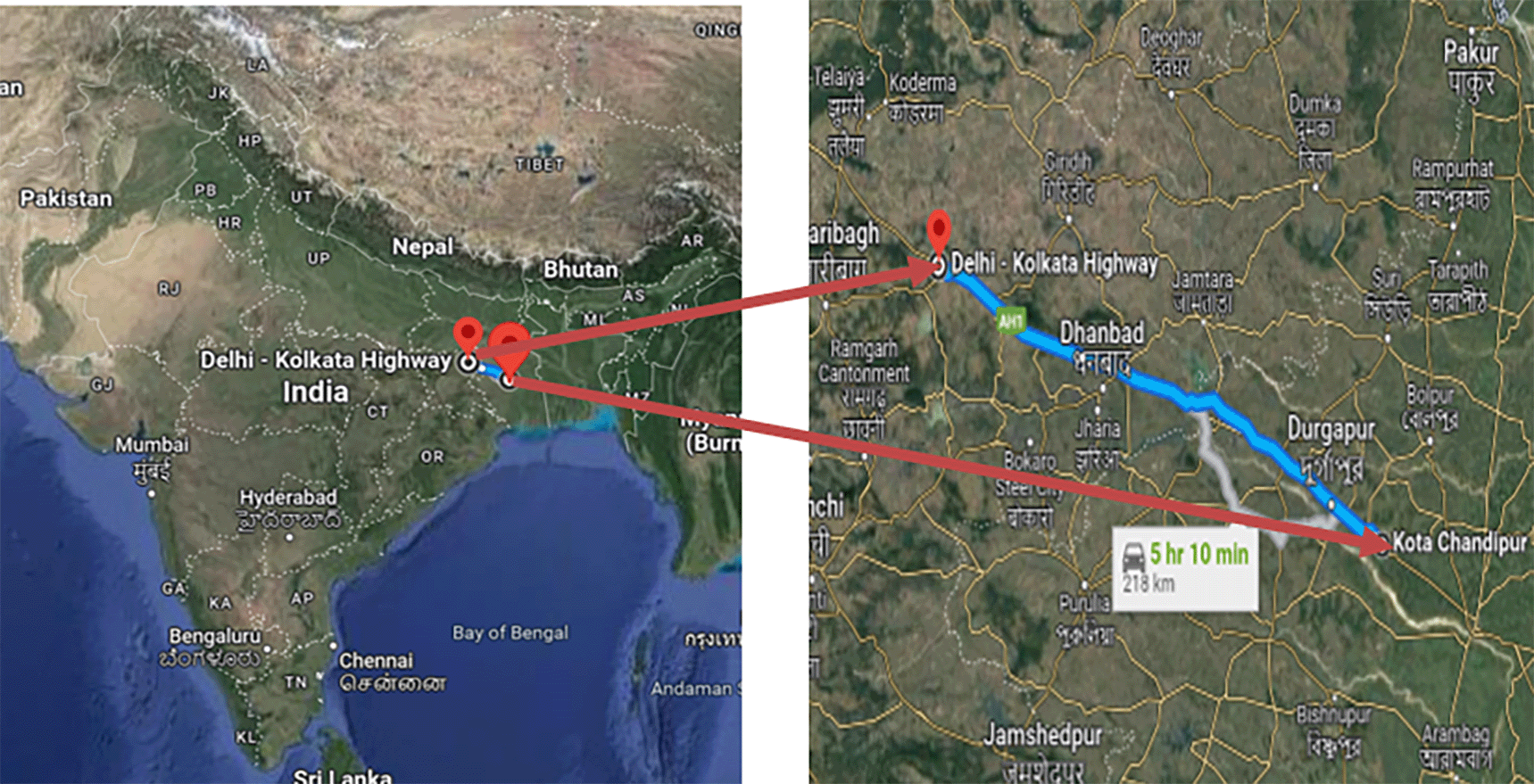
The study areas for this research project were selected based on specific criteria. Firstly, the researchers had prior experience of working on one of the stretches, which is the Pune-Sholapur Section of NH-9 in km.144/400 to Km. 249/000 in the State of Maharashtra. This experience could have provided insights and knowledge that could be useful in conducting the study.
Additionally, data was also provided by the same concessionaire as of the previous stretch on request for another stretch, which is the Six-Laning of Barwa-Adda-Panagarh Section of NH-2 from km 398.240 to km 521.120 including Panagarh Bypass in the States of and West Bengal. This data could have been relevant to the research objectives and could have assisted in achieving the desired outcomes.
The proposed methodology for this research involves the following steps for implementing a RF model machine learning technique for accident severity prediction.
Data Preparation: The first step in implementing a RF model for accident severity prediction is to collect and prepare data. Raw data on road accidents for the selected stretches of the highway can be obtained from secondary sources such as the Ministry of Road Transport and Highways (MoRTH) and the National Highways Authority of India (NHAI).2 Data wrangling and mining techniques can be used to clean and preprocess the data.
Feature Selection: Once the data is prepared, selecting appropriate features for the model becomes crucial. Feature selection plays a vital role in reducing the dimensionality of the data and enhancing the model’s accuracy. There are several techniques available for feature selection, such as statistical tests, correlation analysis, and principal component analysis (PCA).13
Model Training: In the next step, an RF model can be trained on the preprocessed data. The model can be developed using a machine learning-based framework, as described in Breiman’s work on RF.14 The RF algorithm involves bagging and random feature selection techniques to create multiple decision trees that are aggregated to form a stronger learner.15
RF Algorithm Formulation: The RF algorithm can be represented as:
where X are the input features, B is the number of trees, and Tb(X) is the prediction of the b-th individual decision tree.Parameter Tuning: To improve the performance of a RF model, it is important to fine-tune its parameters. The three key parameters that significantly impact the tuning performance of the RF model are the total number of trees (n_estimators), the number of features used for each node segmentation (max_feature), and the maximum depth of a tree (max_depth).16
In the construction of the RF model for predicting accident severity, Gini impurity is employed as a criterion to evaluate the significance of different explanatory variables. Gini impurity, a measure utilized within the framework of decision trees (the base learners in a RF), is crucial for the optimal selection of features at each node split. It offers a quantitative metric to discern the effectiveness of a variable in segregating the target classes.
Mechanism of Gini Impurity: In the context of binary classification, the Gini impurity for a node is calculated as:
where, pk is the proportion of samples classified to class k at that node, and the summation operates over all classes. A lower Gini impurity score suggests a higher purity of the node, indicating an enhanced classification.Gini Importance in RF: In the developed RF model, the Gini impurity plays a dual role: Node Splitting: It aids in the identification of the most significant variable at each node by evaluating the potential reduction in impurity for each split, and Feature Importance: Post model training, the average decrease in impurity caused by each feature across all trees is computed, known as Gini importance. This metric offers insights into the relative significance of different features for the prediction task.
Model Evaluation: After training the RF model and optimizing its parameters, it is important to evaluate the model’s performance. Various evaluation metrics can be used, including accuracy, precision, recall, F1 score, and Area Under the Curve - Receiver Operating Characteristics (AUC-ROC) curve.17
Model Implementation: Once the model has been trained and evaluated, it can be deployed for accident severity prediction. The methodology can be designed using Python for building the model and forecasting the severity of road traffic accidents on Indian highways.
Data on road accidents from selected stretches of highways was obtained from the Concessionaires of the National Highways Authority of India (NHAI) for two projects: Pune-Solapur and Bengal (BAEL) Section. For the Pune-Solapur Section of NH-9, which is located between km. 144/400 and km. 249/000 in the state of Maharashtra, accident dates from 2013 to 2018 were used. For the Six-Laning of Barwa-Adda-Panagarh Section of NH-2, which includes Panagarh Bypass and is located in the States of Jharkhand and West Bengal Stretch, accident dates from 2015 to 2019 were used for the stretch between km 398.240 and km 521.120. The raw data was subject to exploratory data analysis, as detailed in the following section.
In this stage, data gathering and exploration is performed using secondary source data. The dataset consists of 3257 observations out of which the 1855 observations are of Bengal (BAEL) Section and 1402 observations are of Pune- Solapur and 32 variables, including the target variable “accident severity.” The 32 attributes and their corresponding mappings are presented in Table 1.
The RF classification algorithm has been employed in this study to forecast the severity of road traffic accidents in India. This section details the procedure for implementing the model, performance evaluation, and discuss the results obtained. The RF algorithm is written using python programming language.
The target variable for the random RF is selected as the’Accident Severity’ which has classes as Fatal, Grevious Injury, Minor Injury and No Injury and indexed as 1-Fatal, 2-Grevious Injury, 3-Minor Injury, 4-No Injury.
The dataset is partitioned into training and testing sets with a ratio of 80% and 20%, respectively. The hyperparameters’n_estimators’ and’max_depth’ are specified, and a grid search is conducted with cross-validation (cv=5) to identify the optimal hyperparameters. The best parameters and scores are obtained. The best estimator is fit on the training data. Predictions are made on the test data and the accuracy of the model is obtained.
The algorithm and programme for Accident Severity Modelling using RF are written in the Python programming language, and the code is made available to the public for further development. The source code can be accessed via the software availability statement.
Accuracy analysis on test data: Three metrics were employed to evaluate the effectiveness of the algorithms: accuracy, precision, and recall. These metrics are defined as follows:
Accuracy: The formula for a metric that measures the proportion of correctly predicted observations to the total number of observations is represented as:
Precision is a metric that indicates the ratio of correctly predicted positive observations to the total number of predicted positive observations, and is calculated using the formula:
Recall is a metric that reflects the ratio of correctly predicted positive observations to the total number of actual positive observations, and is determined using the formula:
The classification model used three hyperparameters -’max_depth’: 10,’max_features’:’sqrt’, and’n_estimators’: 100, and the results generated a confusion matrix for the training set. The matrix indicated the number of correctly and incorrectly classified instances for each class. The classification report provided precision, recall, and f1-score for each class, along with support. The model showed high precision and recall for class 1 but low precision and recall for classes 2, 3, and 4, with an overall accuracy of 67% and a weighted average f1-score of 0.64 on the training set. The macro average f1-score, which assigns equal weight to each class, was 0.53.
The optimal parameters for a RF classifier model were determined through a grid search, with a max depth of 2, n estimators of 5000, and a random state of 0. The model was then applied to the test data, and the predictions were saved in an Excel file called “predicted output3.xls” for further analysis. The accuracy of the model on the test data was determined to be 0.4147, or approximately 41.47%, indicating that it accurately predicted the severity of traffic accidents in about 41.47% of test cases.
Predicted outputs
Comparative analysis of observed and predicted accident severity index against dates
The actual accident severity indices are represented by the observed values, while the predicted values are generated by the RF model using the input features.
The following is a summary (Figure 3) of the comparison between the observed and predicted values:

On dates such as 25-02-2017, 17-04-2017, and 22-04-2017, the RF model accurately predicts the accident severity index.
In a number of instances, the model predicts a lower accident severity index value than the observed value. 18-02-2017, 23-02-2017, and 27-03-2017, for example.
Occasionally, the model overestimates the accident severity index by predicting a higher value than the observed value, as on 24-05-2017 and 20-10-2017.
In general, the model frequently predicts a severity index of 2 for accidents, even when the observed values are distinct. This may indicate a bias in the model, possibly as a result of an imbalance in the training dataset, in which severity index 2 occurs more frequently than other categories.
Comparative analysis of observed and predicted accident severity index against time
Figure 4 displays the date, day of the week, and time of the accident, as well as the observed and predicted accident severity indices. The plotted for the 165 rows of predicted data doesn’t fit in A4 sheet hence the data is published and the link is provided in the Tableau graphs visuals availbility [i].

The dataset contains accident data from February 18, 2017 to December 31, 2017, as determined by Tableau analysis of the plot generated from the provided Excel table.
The observed accident severity index ranges from 1 to 4, where 1 corresponds to the least severe accident and 4 to the most severe accident.
The observed severity index for the vast majority of accidents in the dataset is 3, followed by 4. 2 indicates a less severe accident, while 4 indicates a more severe accident.
The majority of accidents within the dataset have a predicted severity index of 2, followed by an index of 1.
The analysis of the scatter plot reveals that the predicted severity index is typically lower than the observed severity index. This suggests that the model used to predict the severity of accidents is not always accurate and could be improved.
The Tableau plot (Figure 5) presents a detailed visual analysis of accident data on the right-hand side of the road. The data is organized by date and day of the week, displaying the accident location, observed accident severity index, and predicted accident severity index for each incident. The plot effectively illustrates the spatial distribution of accidents and their severity over time, enabling the identification of patterns and trends. The Tableau plot doesn’t fit in A4 sheet hence the data is published and the link is provided in the Tableau graphs visuals availability [ii].
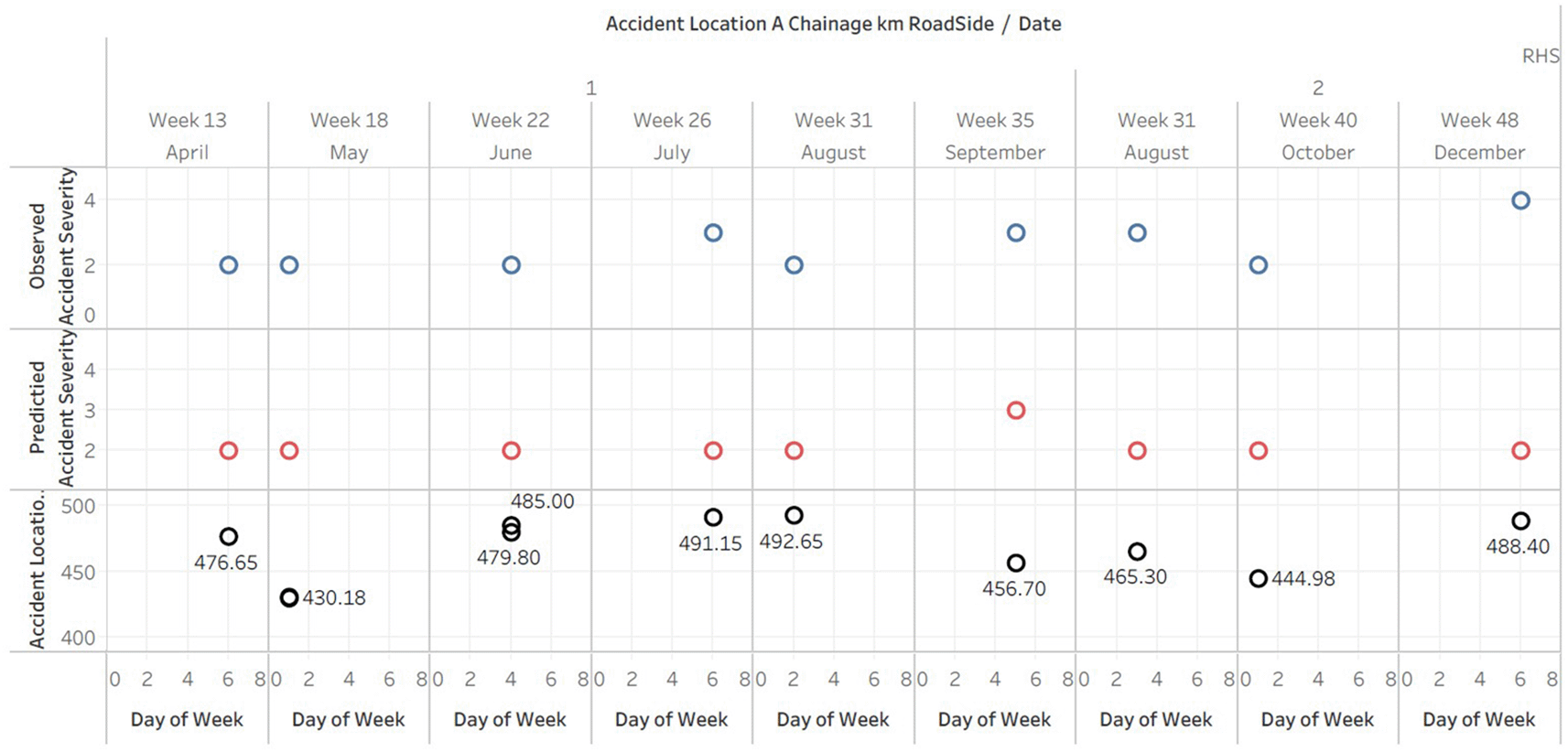
It is evident from the analysis that the majority of accidents have an observed severity index of 2 or 3, indicating a moderate severity. However, the predicted accident severity index largely remains at 2, indicating that the predictions may be somewhat conservative and do not fully capture the observed severity range.
In addition, there appears to be no correlation between the day of the week and the frequency or severity of accidents across the different days of the week. This may suggest that external factors, such as traffic patterns or weather conditions, have a greater impact on the occurrence and severity of accidents than the day of the week.
The graph displays (Figure 6) the date, day of the week, and accident location on Left Hand Side (LHS) of the road, as well as the observed and predicted accident severity indices. The plotted of predicted data doesn’t fit in A4 sheet hence the data is published and the link is provided in the Tableau graphs visuals availability [iii].

The scatterplot reveals that the majority of accidents on the left side of the road had a severity index of 2 or 3, with only a few instances of severity index 1 and 4. This indicates that the majority of collisions on the left side of the road were of moderate severity.
In the majority of cases, the predicted accident severity index was 2, with only a few instances of values 3 and 4. This suggests that the predictive model may be biased towards predicting less severe accidents.
There was no discernible pattern or trend between the day of the week and the occurrence of accidents. Accidents appeared to occur every day, indicating that the day of the week may not be a significant predictor of accident severity on the left side of the road.
The accident locations, as measured by Accident Location A Chainage km, were scattered along the roadway at various distances. This suggests that there may not be a particular accident hotspot or concentration on the left-hand side of the road.
The recording of road accident data in India must comply with the MoRTH & IRC guidelines, utilizing the Road Accident Recording and Reporting Formats. Despite this, there exists a need for a more advanced data recording system to effectively model road safety. The digital monitoring of road accidents can increase the frequency of data collection and minimize the absence of crucial information. Often, the lack of a system or individual to document the accident leads to the absence of important road accident data. This missing data can be regained through the use of machine learning, thus enhancing the accuracy of road safety modeling.
The RF classifier model predicted the severity of traffic accidents with an overall accuracy of 67% on the training set and approximately 41.47% on the test set. Indicating possible bias or imbalance in the training dataset, the model tended to predict a lower severity index than the observed values. There were no discernible relationships between the day of the week and the occurrence or severity of accidents. The performance of the model can be enhanced by correcting the dataset imbalance and refining the model’s hyperparameters.
The observed and predicted accident severity indices were compared against a number of variables, including dates, times, and locations on both sides of the road. In some instances, the model accurately predicted the accident severity index, but it frequently underestimated accident severity. No discernible patterns or trends were observed in terms of accident location, indicating that external factors may have a greater influence on the occurrence and severity of accidents.
To improve road safety modelling, it is essential to adopt a more sophisticated data recording system consistent with MoRTH and IRC recommendations. Digital monitoring of road accidents can increase the frequency of data collection and reduce the loss of vital information. Integrating machine learning techniques can contribute to more effective interventions and decision-making in the field of traffic accident prevention and mitigation.
In the field of accident severity modeling our research stands out for its contributions. We focus on leveraging Artificial Intelligence (AI) models, which excel at capturing the relationships that traditional statistical methods often overlook. Our, in depth study of the Random Forest (RF) algorithm, combined with careful parameter adjustment and data preprocessing highlights its potential in this area. This research addresses not concerns but also specifically tackles India’s road safety challenges providing insights applicable worldwide as well as tailored solutions for the region. A key aspect of our approach is our unwavering dedication to improving accuracy positioning our work as a standard for precise and reliable accident severity predictions. Overall this study makes a contribution to literature, in this field.
The study presented provides a good starting point for future research in the field of road safety modeling and accident prevention for Indian highways. However, with the limitations of the present study there opens potential areas for future research as mentioned below which will be taken up in continuation.
Dataset improvement: The study identified the possibility of dataset bias and imbalance affecting model performance. Future research will focus on improving the quality and quantity of data, reducing bias and improving model performance. This will involve exploring alternative data sources, enhancing data collection methods, and addressing data quality issues.
Model improvement: The study used the RF algorithm to develop a predictive model for traffic accident severity. In future research, other machine learning algorithms or ensemble models to improve model performance will be explored. Additionally, refining hyperparameters and addressing dataset imbalance will be done to improve model accuracy.
External factors analysis: The study highlighted the influence of external factors on accident severity prediction. Future research can focus on exploring the impact of external factors such as weather conditions, road infrastructure, and driver behavior on accident severity. This can enhance the accuracy of predictive models and inform decision-making in accident prevention efforts.
Real-time monitoring: The study highlighted the need for a sophisticated data recording system in line with MoRTH and IRC guidelines. Future research can focus on developing a real-time monitoring system that can capture road safety data in real-time and provide insights for accident prevention efforts.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
 G(p)=k=1np2k
G(p)=k=1np2k
Comments on this article Comments (0)