Keywords
COVID-19, preprints, checklist, science education, science communication
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the Innovations in Research Assessment collection.
COVID-19, preprints, checklist, science education, science communication
During the COVID-19 pandemic, there has been both a proliferation of scientific data, and a major shift in how results were disseminated, with many researchers opting to post their work as preprints ahead of or instead of publication in scientific journals.1–4 Preprints are scientific manuscripts that are posted on freely accessible preprint servers (such as medRxiv, bioRxiv, PsyArXiv, MetaArXiv or arXiv), and which have not gone through formal peer review. Preprints take an extremely short time to become ‘live’ – between 24 and 48 hours after basic checks by server administrators, such as that the content of the manuscript is scientific text within the scope of the server, and not spam or plagiarised text.5 This is clearly advantageous in a rapidly-evolving pandemic.6,7 However, unlike journal submissions, the dissemination of preprints is not predicated on any quality control procedure.8 Even before the pandemic, concerns have been raised about the potential of such unvetted results and interpretation of findings leading to widespread misinformation.9 Indeed, in the past three years, we have seen prominent examples of non-peer-reviewed COVID-19-related claims10,11 that were promptly uncovered as misleading or seriously flawed by the scientific community,12,13 nonetheless infiltrate the public consciousness14 and even public policy.15 In this high-stakes context, two things have become clear: 1) that preprints have become a tool for disseminating disease outbreak research,16 and 2) that evaluating preprint quality will remain key for ensuring positive public health outcomes.
Since the start of the pandemic, the number of preprints on COVID-19 has been steadily rising, with over 55,000 preprints to date (as of June 27, 2022; see also Figure 1). In the early stages of the pandemic, studies have shown that COVID-19 preprints were typically less well-written in terms of readability and spelling correctness,17 and that most did not meet standards for reproducibility and research integrity.18–20 A number of preprints also contained extremely serious issues, such as ethical and privacy concerns, data manipulation, and flawed designs.21 These data support the notion of a proliferation of bad quality work over the course of the pandemic (‘research waste’,22,23), ultimately leading to a spread of misinformation.24
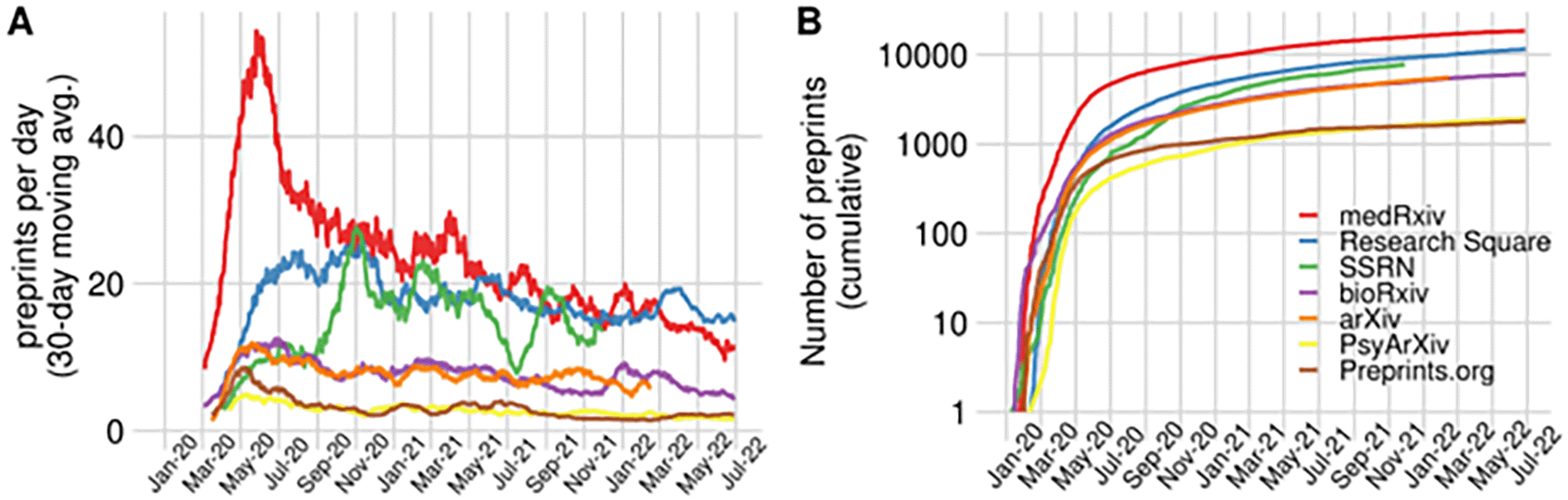
(A) Preprints appearing per day on a selection of preprint servers indicated in the figure’s legend, from January 2020 to June 2022. To account for daily variation in the upload of preprints, 30-day moving averages are represented, i.e. the average of the last 30 days. (B) The cumulative number of preprints posted to the same set of preprint servers, indexed in Europe PMC since the first WHO statement regarding a novel infectious disease outbreak on January 9, 2020.68
Such initial findings are countered by a much more nuanced story of COVID-19 preprint quality. While it is true that many preprints never convert into publications (70-80% as of April 2021, see e.g., Refs. 25, 26) and that preprints tend to be less cited than the resulting peer reviewed publication,27,28 this is not necessarily due to poor quality. For one, the link between a preprint and its publication may be lost when it is the preprint that gets cited.29 Alternatively, the authors’ decisions could be the cause, as some may avoid the publication process altogether.30 Others may intentionally use preprints to release replications, and null results that are difficult to publish,31 or works in progress which may be less well-written and inadequate at sharing data/code.17–20 Many preprints actually report their results in a balanced way so as not to ‘oversell’ their findings,30 and there is growing evidence of high concordance between findings published in preprints and in peer-reviewed journals.25,32–39 Nonetheless, a large portion of COVID-19 preprints show substantial changes in methods and results after peer-review (nearly half of the preprints analysed by Oikonomidi (2020) and Nicolalde et al. (2020)25,31), suggesting flaws in the most essential elements of many COVID-19 preprints. At least two potential solutions for distinguishing high- from low-quality research in preprints are possible: 1) introducing quality control measures, and 2) educating the readership of preprints to make quality evaluations themselves. Of the extant efforts to improve preprint quality, most have focused on introducing quality control via quick peer-review, e.g., Prereview (https://www.prereview.org/), Review Commons (https://www.reviewcommons.org/), PreLights (https://prelights.biologists.com/)[1]. Though peer-review is often considered the gold-standard for scientific quality control, it has limitations: it can be time consuming,3 at times inefficient at weeding out fraud, and often contaminated with reviewer bias, negligence, and self-interest.39–45 Automated problem detectors are a promising way forward,46 however such tools still require continued refinement and human verification of results.47 When research is under a stress test, such as during a world-wide pandemic, alternative forms of quality control have to be considered.
Aside from improving the contents of preprints directly, more could be done to educate the readership of preprints on the judicious interpretation of their contents. Preprints receive large attention on social and traditional media,48 but so far, their contents have not always been reported adequately, as many news reports do not provide explanations of the publication process, of how preprint platforms work, and of the implications of non-peer-reviewed research.44,45 This is made all the more disappointing by recent findings showing that a simple, one-paragraph explanation of the nature of preprints and the scientific publishing process can meaningfully change laypeople’s perceived credibility of scientific results.46
Public education initiatives on understanding preprints (on COVID-19 or more generally) have been next to non-existent. Apart from the study by Wingen et al.,49 only one effort was identified,50 which aimed to provide a set of guidelines for providing feedback on preprints, whether for reviewers or members of the broader community. In the absence of a set of guidelines on interpreting and evaluating information in preprints, we created the PRECHECK project (www.precheck.site). As the first project of its kind, the aim was to develop a simple, user-friendly tool to guide non-scientists in their evaluation of preprint quality. Though we were inspired by the proliferation of preprints and misinformation during the COVID-19 pandemic, we created a tool that can be applied to preprints or publications on other topics, with hopes that it can help empower non-scientists and non-specialists in making their own judgments.
The entire project “PRECHECK: A checklist to evaluate COVID-19 preprints” was conducted under the ethical policies of the University of Zurich. As stipulated in sections 5 and 6 of these policies (https://www.rud.uzh.ch/dam/jcr:c42f07d3-2e89-485c-8a8b-3a3c3f46a3f5/UZH%20Policy%20on%20the%20Ethical%20Review%20of%20Research%20Projects%20Involving%20Human%20Subjects%20 (UZH%20Ethics%20Policy).pdf), our project falls outside the scope of the Swiss Human Research Act and, per section 8.1 of these policies, can be considered as a study that “generally cannot harmfully affect study participants”. Therefore, our project did not require explicit prior ethical approval from the institution, and for this reason we did not ask for ethical approval from the institution. A post-hoc verification with the University of Zurich ethical commission’s ethics review checklist (available in in the OSF repository for this project68) confirmed that we did not require ethical approval from the current project per the regulations of the University of Zurich. Written consent for participating in student workshops was not required because the workshops were administered as part of their regular university courses (details in manuscript) to which students do not need to exceptionally consent.
The aim of the study was to develop simple and clear guidance, in the form of a checklist, to help assess the quality of a preprint. Our target audience for the checklist were scientifically literate non-specialists, such as students of medicine and psychology, and science journalists. To develop a checklist that would be both user-appropriate, and discriminative of preprints of different levels of quality, we applied a multi-step approach inspired by the qualitative Delphi method.51,52 As such, our study could be considered a qualitative study, and we have thus followed the Standards for Reporting Qualitative Research (SRQR) (Ref. 53; see Ref. 69 for a completed version of the checklist for the current project). The Delphi method uses successive voting by expert groups to iteratively narrow down a pool of options until consensus is reached and is effective in determining consensus in situations with little to no objective evidence.54 Our procedure involved four main stages. In the first stage, the first draft of the checklist was reviewed internally by the senior members of our team (who were not involved in creating the draft) and subjected to a sensitivity test to verify whether the checklist could discriminate high- from low-quality preprints[2]. In the second stage, a panel of external experts rated the relevance of each element of the checklist and provided feedback, after which the checklist was updated. In the third stage, we conducted a final round of internal review producing the third draft of the checklist, which was also submitted to a final sensitivity analysis. At the end of the above three stages, we verified if members of our target audience could use the checklist successfully and if they appeared to find it useful, via workshops with university students and journalists. We called this stage the implementation of the checklist. In the workshop for journalists, some participants offered unsolicited yet helpful feedback, which was incorporated into the finalised version of the checklist (see also Figure 2).
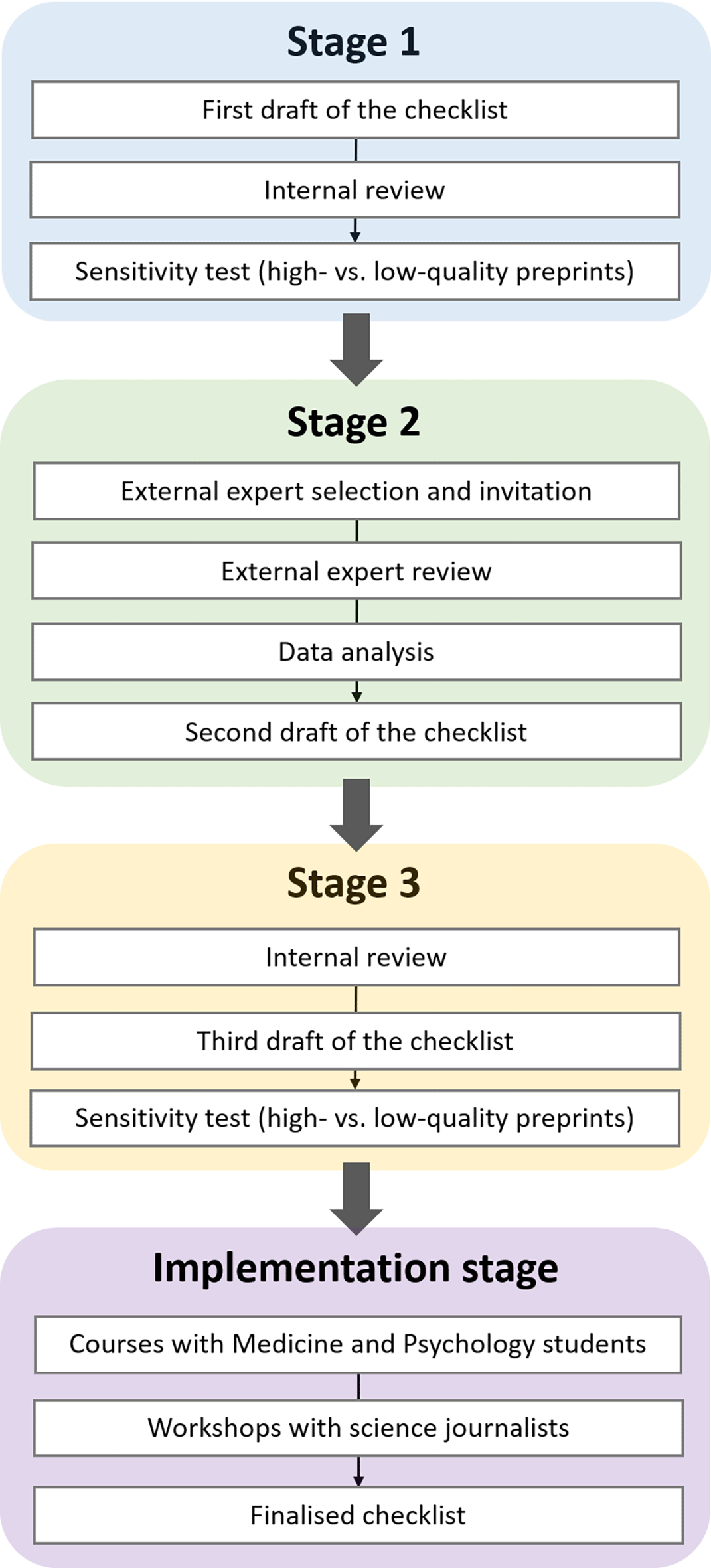
There are four successive stages (Stage 1 – Stage 3 and the implementation stage, in blue, green, yellow, and purple fields, respectively) where each is made up of a set of successive steps (in white rectangular fields).
The research team conducting the analysis was composed of three junior researchers (postdoctoral level) and three senior researchers (two professors and one senior scientific collaborator). All members of the team have experience in meta-research, but are trained in other disciplines (statistics and psychology).
In this step, the three senior members of our team gave written feedback on a draft of the checklist in the form of comments. After the written feedback was incorporated by two junior members of our team, final feedback in the form of verbal comments from the senior members was obtained in an online meeting round. A copy of each version of the checklist after feedback and other validation procedures below is available in the OSF repository for this project.68
After each of the two rounds of internal review (Stage 1 and Stage 3), we conducted a sensitivity test in order to verify whether the checklist, at its given stage of development, could successfully discriminate between preprints of different levels of quality. We did not perform any statistical analyses as part of this assessment. Since objective criteria for quality that would apply to all preprints across disciplines were difficult to envision, we used a list of milestone research works in the COVID-19 pandemic55 as a proxy of high quality, and we identified what would be the preprints in our high-quality set from this list. The preprints that would make up our low-quality set, on the other hand, were chosen from a list of retracted COVID-19 preprints,56 with retraction being a proxy for low quality. There were no a-priori criteria for selecting preprints. We selected three high-quality preprints57–59 and three low-quality preprints9,60,61 to test across multiple stages. Since preprint selection occurred in August 2021, we only included preprints that were available online from the start of the pandemic up until that point. In the Stage 1 round, one junior team member tested only the high-quality preprints and another junior team member the low-quality preprints. In the Stage 3 round, both team members tested all preprints independently. The same high- and low-quality preprints were used at both stages. To document the test results, a spreadsheet was generated with one field per checklist element, where the response to the checklist element for each preprint was entered. Fields were also coloured red, green, and yellow, to visually better represent ‘yes’, ‘no’, and ‘maybe’ responses to specific checklist elements, respectively. The results of each round of sensitivity tests with the links to the respective preprints are available in the Open Science Framework (OSF) repository for this project.68
Panel selection
We invited a total of 54 experts across four topic groups: research methodology (14 invitations), preprints (15 invitations), journal editors (15 invitations), and science journalists (10 invitations), as these fields of expertise were judged to be of the greatest relevance for evaluating our checklist. Experts were identified through personal connections, by identifying editors of relevant journals in the fields of psychology and medicine (for the editor cohort), science journalists from a list of speakers at the World Conference of Science Journalists, Lausanne 2019 (https://www.wcsj2019.eu/speakers); for the journalist group), and identifying individuals whose work in the topic areas of research methodology and preprints is noteworthy and well-known. There were no a-priori criteria for selecting experts, other than their perceived belonging to one of the topic groups. In actual Delphi designs, 5-10 experts may be considered sufficient,62 however, there is no clear consensus on how large expert groups should be.63 Of the total number of experts, 29 were personal contacts. Panel members were contacted by email between October 18 2021 and November 16 2021 with a standardised explanation of the project, their role in the refinement of the checklist, how their data would be used (that their name and email will not be shared, that their responses will be fully anonymous, and that the aggregated results will be published and shared on our OSF repository for the project), and a link to a Google Forms survey where they could enter their responses anonymously. By clicking on the link to the survey, the experts thus gave their implicit informed consent to participate. The Survey Form sent to the experts is available in the OSF repository for this project.68 Experts that replied to our email declining to take part in the survey were not contacted further. Any experts that did not explicitly decline to take part were reminded twice, as the survey responses were fully anonymous, and we had no way of linking responses to individual experts. A total of 26 experts (48%) responded to the invitation by filling our survey (14 of them were personal contacts). The experts (self-)reported that they belonged to the following expert groups: four experts in science journalism, four journal editors, seven meta-researchers/experts on preprints, and 11 methodologists.
Response collection and analysis
Experts rated the relevance of each element of the checklist on a five-point Likert scale, with the following response options: extremely irrelevant, mostly irrelevant, neither relevant nor irrelevant, mostly relevant, and extremely relevant. Response data were analysed by computing mean responses per element, using R (Version 4.04). We based our decisions on which elements to keep following the procedure used to establish the CONSORT guidelines for abstracts.64 That is, all elements with a mean score of four and above were kept (in the CONSORT for abstracts, this score was eight, as they used a 10-point Likert scale), elements with a mean score between three and four (four not included; between six and seven in the CONSORT for abstracts criteria) were marked for possible inclusion, and elements with a mean score below three were rejected.
Experts also had the option to provide free-text comments: general additional comments on the checklist elements, suggestions for potentially relevant items that are missing, and suggestions on the structure (a PDF of the survey, including the Likert scales and free-text options is available in the OSF repository for this project68). These comments were collected into a single document and responded to in a point-by-point manner akin to a response to reviewers document (also in the OSF repository for this project68), arguing our agreement/disagreement with expert comments and how they were addressed in the subsequent draft of the checklist.
First draft of the checklist
The first draft of the checklist was created from April 16 until May 17, 2021, and contained six categories of items: research question, study type, transparency, limitations, study reporting, and research integrity. The research question item asked whether the study mentioned the research question/aim, this being the most basic component of a research study. The study type question asked whether the study type was mentioned, and in the case that it was not, asked users to try and infer what the study type was, with guidance. In transparency, users were supposed to check the existence, availability, and accessibility of a protocol, and of data, code, and materials sharing. The limitations question asked whether any limitations of the study were mentioned, and asked users to try and evaluate any potentially unmentioned limitations (biases, specifically), with guidance. In study reporting, we asked to check for reporting guidelines that were followed explicitly or implicitly. Finally, the research integrity category asked users to check whether ethical approval, conflicts of interest, and contributor roles were reported.
Internal review results
In the first round of internal review, the senior members of our team provided feedback on the contents of the first draft of the checklist. This round revealed that explanations were needed as to the importance of considering each specific item in our checklist, and that both a more ‘superficial level’ and a ‘deeper level’ were necessary to account for all user needs. For these reasons, we expanded the initial checklist, such that each item consisted of a main question, an explanatory section entitled ‘Why is this important’, and a section entitled ‘Let’s dig deeper’. The main questions formed the basis of the checklist, as they were all closed questions that could be answered via the ‘yes’ box next to them. Users could tick the box in full to indicate that the preprint being read passes the question, in part to indicate a ‘maybe’ response, or not at all to indicate that the preprint does not pass the question. This level was also called the ‘superficial level’ of assessment, as the questions could mostly be answered after a quick read of a preprint, and by searching for keywords that appear in the questions. The’why is this important?’ section was added in order to increase the pedagogical value of the checklist, which was designed as a teaching tool, such that users could learn about the purpose behind the main questions, and their importance for evaluating research. The ‘let’s dig deeper’ sections were added as an optional part for users that wanted to go beyond the main questions in their evaluation of a preprint, or that wanted to learn more about how to structure their thoughts when evaluating research work. Thus, this section does not have a tick-box, as it usually contains open questions and suggestions. This section cannot stand alone and should be consulted after the main questions and ‘why is this important’ section, which is why we called this the ‘deep level’ of assessment. A full version of the checklist at this stage can be found in the OSF repository for this project.68 This was the version of the checklist that we submitted to a sensitivity test on high- and low-quality preprints.
Sensitivity test results
While searching for high- and low-quality preprint examples to apply the checklist to, we discovered that the checklist works best when applied to research with human subjects using primary data (or systematic reviews, meta analyses and re-analyses of primary data). That is, the questions turned out to be ill-posed (unanswerable) for research that did not fall into the above description, such as simulation studies, for example. We decided to indicate this in the introduction section of the checklist.
At the superficial level, the high-quality preprints that we used57–59 received mostly ‘yes’ and ‘maybe’ responses to the main questions. Only58 had a ‘no’ for mentioning/sharing their data/code. The low-quality preprints9,60,61 also received several ‘yes’ and ‘maybe’ responses, though fewer than the high-quality preprints. Interestingly, the Transparency and Study reporting items all received ‘no’ responses for the low-quality preprints, whereas the high-quality preprints mostly received ‘maybe’ and ‘yes’ responses. This demonstrates both that high- and low-quality preprints differ in terms of how they meet transparency and reporting standards, but also highlights that even high-quality preprints do not necessarily meet all these standards.
At the deep level, high-quality preprints mostly received ‘yes’ responses to the points in the ‘let’s dig deeper’ section, and a few ‘no’ and ‘maybe’ responses. Meanwhile, the low-quality preprints had no clear pattern of responses with many ‘no’, ‘yes’, and ‘maybe’ responses. However, low-quality preprints had more ‘no’ responses than high-quality preprints. At this level of assessment, one could delve into issues with study design, specifically in Limitations, where low-quality preprints performed demonstrably worse than high-quality preprints. Thus, it may be important to consider both levels of assessment when evaluating preprints using the checklist. The final version of the checklist at this stage was completed on October 18, 2021.
External expert review summary results
Experts were first asked how relevant they thought each of the six item categories were for assessing preprint quality on a five-point Likert scale: from extremely irrelevant (score of 1) to extremely relevant (score of 5). Here, all categories scored above four, except study reporting which received a 3.96. All elements with a mean score of four and above were kept, elements with a mean score between three and four were marked for possible inclusion and those with a mean score below three were rejected. Next, experts were to rate the relevance of each of the elements per category, including the main questions, and each of the points in the ‘let’s dig deeper’ sections. The results are summarised in Table 1 below. None of the elements has a score lower than three, which meant that none of the elements warranted immediate exclusion. However, several elements, including the entire study reporting category, had scores between three and four that placed them in the ‘possible inclusion’ category.
Summary of external experts’ comments
The full list of free-text comments submitted by the experts and our responses to them is available in the OSF repository for this project.68 Overall, the comments revealed enthusiasm about the checklist, but also important criticisms. First, there were concerns that the target audience as it was previously defined (non-scientists) would not be able to adequately use a checklist of the complexity present at the time. Paradoxically, however, there were also many suggestions for additional elements that could further increase complexity, such as: how the study fills the gap in the knowledge, if the study can be fully reproduced, if there is justification for the statistical methodology used, etc. Another prominent criticism was that the checklist inadvertently prioritised randomised controlled trials and could potentially discredit observational studies. Our sensitivity test did not find observational studies to be particularly disadvantaged in comparison with randomised controlled trials. However, we did acknowledge that some categories, specifically limitations, appeared more oriented towards randomised controlled trials. One specific comment raised the issue that our checklist did not include COVID-19 specific questions, despite the checklist’s motivation. We thus sought to correct and elaborate these points in the next versions of the checklist.
Some experts had additional ideas, some of which were outside the scope of this project, but others of which were easy to implement. In particular, the suggestion to ask users to check if the manuscript converted into a publication, and to include spin and overinterpretation of results as other examples of biases in the Limitations section. These suggestions were incorporated into the subsequent versions of the checklist.
Second draft of the checklist
The second draft of the checklist68 consisted of the following elements: Research question (main question only), study type, transparency (main question on mentioning the protocol, and two ‘let’s dig deeper’ questions on accessing the protocol, and accessing the data), limitations, and research integrity (two main questions on mentioning an ethics approval statement, and conflicts of interest). After expert feedback, we decided to omit the study reporting category, and instead incorporate the reporting guidelines mentioned there in the newly added descriptions of study types in the item study type, to reduce overall complexity, and increase clarity in this section specifically. After comments on the checklist’s complexity, we combined the transparency and research integrity categories and their remaining elements into a new category called ‘transparency and integrity’. Here, in response to a specific comment, we altered the main questions such that they probe if a study protocol, data sharing, materials sharing, ethical approval, and conflicts of interest, are mentioned, whereas the ‘let’s dig deeper’ section asks if the above are accessible (in the aforementioned section, we define what we mean by accessible). In addition to these changes, we realised the utility of looking both at the preprint and the preprint server when using the checklist, as sometimes the preprint does not mention data/materials sharing, but these resources are shared on the server.19 Thus, we added a recommendation into the introduction to consider both sources when using the checklist. In response to the comment on inadvertently disadvantaging observational research, we added disclaimers into the limitations section stating when certain sources of bias do not apply. Specifically, for the control group/condition, randomisation, and blinding elements, we added a clause to the end of each paragraph that states ‘(if your preprint is on an observational study, this item does not apply)’. In response to the lack of a COVID-19 element, we elaborated that, although the state of COVID-19 preprints and their effect on society was our inspiration for the project, our expertise (preprint quality in medicine and psychology) made it difficult to create an adequate COVID-19-specific checklist. With this, we modified the title of the checklist and expanded the introduction, to avoid further confusion. The final version of the checklist at this stage was completed on January 17, 2022. It is available in the OSF repository for this project.69 Also, we structured our workshops with students and journalists around issues with preprints and peer review more generally.
To provide more details on the workshops, we envisaged two for students: one for Bachelors’ students of Psychology at the University of Geneva, and one for Bachelors’ students of Medicine at the University of Zurich. Both workshops were given as invited lectures in standard classes taught to students as part of their respective Bachelors’ courses (as part of the “Scientific skills and competencies in psychology” class at the University of Geneva [in the original French: “Compétences et connaissances scientifiques en psychologie”], and the “Biostatistics for medical professionals” class at the University of Zurich [in the original German: “Biostatistik für Mediziner”]). The workshop content was made clear to the students in advance. Only those students that were enrolled in the above classes as part of their Bachelors’ courses could attend the workshops. Thus, no special consent was required to participate in the workshops. One junior member led the workshop at the University of Geneva, while at the University of Zurich, one junior and one senior member led the workshop. There was no relationship of dependence between either one of these members and the students they administered the workshops to (i.e., neither member was involved in the grading of the students’ course assignments or exams). Both workshops consisted of a theoretical presentation of the scientific publishing process, what preprints are, and current issues with preprints and peer review (based on the conclusions of the literature review in the present manuscript). Next, the purpose and component parts of the checklist were presented, together with instructions on how to use it for the subsequent in-class exercise. In the exercise, students were split into two groups according to their last names, each given 15-20 minutes to re-read a preprint (they were informed about the exercise and given the preprints beforehand; one group read,60 and the other group read65) and use the checklist to evaluate it. The answers were collected anonymously, in an aggregated (non-individual) fashion, via an in-house platform. At the University of Geneva, we used surveys on Votamatic (https://votamatic.unige.ch/) to gather the percentages of students that voted ‘yes’, ‘no’, or ‘partly’ for each superficial-level item, and Padlet (https://unige.padlet.org) to gather optional free text responses to the deep-level items. At the University of Zurich, Klicker (https://www.klicker.uzh.ch/home) was used to gather the percentages of students that voted ‘yes’, ‘no’, or ‘maybe’ for each superficial-level item, alongside optional free text comments. Once recorded, these percentages were discussed by the whole class, and compared against the researchers’ own evaluation of said preprint. The responses were only analysed inasmuch as percentages of ‘yes’, ‘no’, and ‘partly/maybe’ responses were automatically generated by the respective platforms, for the purpose of in-class discussion. There were no formal statistical analyses performed on these responses, and the responses did not influence the content of the checklist in any way.
The above workshop format was also adapted for science journalists at the Universities of Geneva and Zurich. In practice, only the workshop at the University of Geneva was held (and led by the junior member of the team based at the University of Geneva), as the relevant personnel at the University of Zurich failed to respond to our requests to hold a workshop. The format was largely the same as that of the workshop for students, except that the initial presentation focused less on the scientific publishing process, and more on issues with preprints and peer review, and included more time for a mutual discussion of said issues. We intended for these to be small workshops open only to a select number of people, on a purely voluntary basis, invited by the main contact person at each University’s communications section. All of the invited parties were informed on the content of the workshop beforehand. Only those individuals that were interested in attending did so and provided verbal assent to participate in the workshop. The same in-house online platform as before (i.e., Votamatic) was used to collect data on percentages of ‘yes’, ‘no’, or ‘partly’ for each superficial-level item of the checklist in an anonymous, aggregated (non-individual) fashion, and this automatic generation of response percentages was the only analysis performed on these data. Deep-level item answers were informally discussed. As before, there were no formal statistical analyses performed on these data. Some informal verbal feedback (not previously solicited) that we received from the participants did influence the content of the checklist, as we detail in the Implementation section below.
Finally, the content of the workshop for university science journalists was adapted for a fact-checking seminar organised by the Swiss Association of Science Journalists (https://www.science-journalism.ch/event/spring-seminar-2022). Two junior members gave this workshop at the Swiss National Science Foundation headquarters in Bern. Participation was voluntary and open only to individuals that registered to attend the conference at which we were invited to give our workshop as part of the advertised programme. Thus, no special consent was required for participation. We used the same procedure as above, with the exception that a ‘nonsense’ preprint was read and evaluated (Ref. 66; i.e., a manuscript describing a made-up study to prove the point that predatory journals do not screen for quality) and no response data were collected (responses were probed and discussed verbally during the session).
Final draft of the checklist
In the second internal review round, we kept the four-item structure, most of the text, and visual separation between the superficial and deep levels from the second draft of the checklist. In addition, the wording was clarified and additional explanations were provided where necessary. In transparency and integrity, we added clauses to explain what to do in situations where data and materials are stated to be shared upon request, or if reasons against sharing are mentioned. Specifically, since acquiring data/materials after requesting it from authors that only share upon request happens only in a minority of cases,65 we advised that ‘mentioning only that data will be shared ‘upon request’ does not count’. However, if authors mention that they cannot share the data or materials for a specific reason, we advised that ‘mentioning any reasons against sharing also counts [as a ‘yes’]’. In the limitation section, we added examples of spin and overinterpretation as other sorts of biases to look out for. In the introduction, we added the recommendation to check whether the preprint has converted into a publication.
Sensitivity test results
At the superficial level, both high- and low- quality preprints had many positive responses, for both team members that tested the checklist. The elements that differed the most were transparency and integrity, with low-quality preprints having slightly more ‘no’ and ‘maybe’ responses than high-quality preprints. Additionally, both raters agreed that two of the three low-quality preprints did not discuss limitations. This is a slight departure from the prior sensitivity test results, in that the difference between high- and low-quality preprints appears to be smaller.
At the deep level, however, the differences were once again well-pronounced, as high-quality preprints had predominantly positive responses, while low-quality preprints had predominantly negative and ‘maybe’ responses. Thus, the deep level seems to be necessary to fully discern between high- and low-quality preprints. Similarly, to the prior results, the responses in the transparency and integrity section exposed that even high-quality preprints did not always meet the standards of transparency and integrity. The final version of the checklist at this stage was completed on March 1, 2022.
With an operational checklist, we set out to teach members of our target audience how to use the checklist and to verify if they could use it as intended. To this end, we gave courses including workshops to Bachelor students in Medicine and Psychology at the University of Zurich, and the University of Geneva, respectively. The workshop at the University of Zurich took place on March 11, 2022, while the workshop at the University of Geneva took place on May 9, 2022. For our journalist cohort, we provided a lecture and practical for members of the University of Geneva communications office and scientific information division. This workshop took place on May 19, 2022. We later also presented the checklist at a fact-checking seminar organised by the Swiss Association of Science Journalists on May 31, 2022.
Across all of these classes, except for the fact-checking seminar, we used the same high- and low-quality preprints as practice material, and explained both how to use the checklist, as well as the rationale behind its elements, as stated in our point-by-point response to experts. A few suggestions for improvement nonetheless emerged from the workshop with the journalists at the University of Geneva, as some participants wished to offer feedback. Some participants of this workshop pointed out that the necessity and function of both the superficial and deep level of assessment were not clear. Others had trouble understanding what mention of data and materials sharing counts as a ‘yes’ response and what counts as a ‘no’ response. Finally, one participant suggested that even before using the checklist, one should generally apply more caution when assessing controversial research or findings that sound ‘too good to be true’. We incorporated all of this feedback into the final version of the checklist, which was completed on May 20, 2022 (see also Table 2).68
| Category | Items | Yes | |
|---|---|---|---|
| Research question | 1 | Is the research question/aim stated? | □ |
| Why is this important? | A study cannot be done without a research question/aim. A clear and precise research question/aim is necessary for all later decisions on the design of the study. The research question/aim should ideally be part of the abstract and explained in more detail at the end of the introduction. | ||
| Study type | 2 | Is the study type mentioned in the title, abstract, introduction, or methods? | □ |
| Why is this important? | For a study to be done well and to provide credible results, it has to be planned properly from the start, which includes deciding on the type of study that is best suited to address the research question/aim. There are various types of study (e.g., observational studies, randomised experiments, case studies, etc.), and knowing what type a study was can help to evaluate whether the study was good or not. What is the study type? Some common examples include:
| ||
| Let’s dig deeper | If the study type is not explicitly stated, check whether you can identify the study type after reading the paper. Use the question below for guidance:
| ||
| Transparency and Integrity | 3 | (a) Is a protocol, study plan, or registration of the study at hand mentioned? (b) Is data sharing mentioned? Mentioning any reasons against sharing also counts as a ‘yes’. Mentioning only that data will be shared “upon request” counts as a ‘no’. (c) Is materials sharing mentioned? Mentioning any reasons against sharing also counts as a ‘yes’. Mentioning only that materials will be shared “upon request” counts as a ‘no’. (d) Does the article contain an ethics approval statement (e.g., approval granted by institution, or no approval required)? (e) Have conflicts of interest been declared? Declaring that there were none also counts as a ‘yes’. | □ □ □ □ □ |
| Why is this important? | Study protocols, plans, and registrations serve to define a study’s research question, sample, and data collection method. They are usually written before the study is conducted, thus preventing researchers from changing their hypotheses based on their results, which adds credibility. Some study types, like RCT’s, must be registered. Sharing data and materials is good scientific practice which allows people to review what was done in the study, and to try to reproduce the results. Materials refer to the tools used to conduct the study, such as code, chemicals, tests, surveys, statistical software, etc. Sometimes, authors may state that data will be “available upon request”, or during review, but that does not guarantee that they will actually share the data when asked, or after the preprint is published. Before studies are conducted, they must get approval from an ethical review board, which ensures that no harm will come to the study participants and that their rights will not be infringed. Studies that use previously collected data do not normally need ethical approval. Ethical approval statements are normally found in the methods section. Researchers have to declare any conflicts of interest that may have biased the way they conducted their study. For example, the research was perhaps funded by a company that produces the treatment of interest, or the researcher has received payments from that company for consultancy work. If a conflict of interest has not been declared, or if a lack of conflict of interest was declared, but a researcher’s affiliation matches with an intervention used in the study (e.g., the company that produces the drug that is found to be the most effective), that could indicate a potential conflict of interest, and a possible bias in the results. A careful check of the affiliation of the researchers can help identify potential conflicts of interest or other inconsistencies. Conflicts of interests should be declared in a dedicated section along with the contributions of each author to the paper. | ||
| Let’s dig deeper | (a) Can you access the protocol/study plan (e.g., via number or hyperlink) (b) Can you access at least part of the data (e.g., via hyperlink, or on the preprint server). Not applicable in case of a valid reason for not sharing. (c) Can you access at least part of the materials (e.g., via hyperlink, or on the preprint server). Not applicable in case of a valid reason for not sharing. (d) Can the ethical approval be verified (e.g., by number). Not applicable if it is clear that no approval was needed. By ‘access’, we mean whether you can look up and see the actual protocol, data, materials, and ethical approval. If you can, you can also look into whether it matches what is reported in the preprint. | ||
| Limitations | 4 | Are the limitations of the study addressed in the discussion/conclusion section? | □ |
| Why is this important? | No research study is perfect, and it is important that researchers are transparent about the limitations of their own work. For example, many study designs cannot provide causal evidence, and some inadvertent biases in the design can skew results. Other studies are based on more or less plausible assumptions. Such issues should be discussed either in the Discussion, or even in a dedicated Limitations section. | ||
| Let’s dig deeper | Check for potential biases yourself. Here are some examples of potential sources of bias.
|
Over four successive stages of refining the PRECHECK checklist, we arrived at a four-item checklist approved by internal and external review, that can help critically evaluate preprints. After a set of workshops with Bachelor students from Psychology and Medicine, and science journalists, we concluded that the checklist was in a state where it was ready to be used by scientifically literate non-specialists. Here we recapitulate the main findings and discuss their implications.
The results of the sensitivity tests can be divided into three key findings. First, across both tests, preprints deemed to be of high quality had consistently more positive responses on the checklist than preprints deemed to be of low quality. This indicates that the checklist is effective at discriminating preprints of high and low quality, since positive responses mean that the preprint in question ‘passes’ a given criterion for good quality. Importantly, this holds even when the checklist is reduced to only four items, which is important for maintaining the user-friendliness of the checklist.
That said, and we consider this the second key finding, the deep level seemed to be especially important for discriminating preprint quality. It was especially evident in the second sensitivity test that combining the deep and superficial level is optimal for distinguishing high- from low-quality preprints. This is likely due to the nature of the questions at these two different levels of evaluation, as the superficial level probes surface level questions which can be considered a ‘bare minimum’ of quality. For example, it is standard scientific practice that the research question or aim of a study must be mentioned in its resulting manuscript, and indeed, most preprints, even ones that eventually end up being retracted, do offer this information. The issues with low-quality preprints rather seem to be in their designs, ethical considerations, handling of the data and interpretation of the results,21 and how transparently they report their results.18,19 In our checklist, the first set of issues is detected by the deep level of the Limitations item, as this level asks users to engage with the content of the research reported in the preprint, and to check for potential issues with the design. The second set of issues is addressed by the transparency and integrity question, at both the deep and superficial levels. Both levels have been successful at detecting problems in low-quality preprints, but also high-quality preprints, which brings us to the final key finding.
Third, for both high- and low-quality preprints, the checklist highlighted issues with transparency and research integrity. This mirrors the state of the COVID-19 literature, as we have seen that though the credibility of the research reported in preprints can be sound,37–39 data and materials sharing may nonetheless often be lacking.18,19 This could be taken as a weakness of the checklist, as this item is not particularly discriminative of preprint quality. However, we believe it is a strength, albeit an unintended one. On one hand, this feature highlights where there is room for improvement even in works that are otherwise of good quality. Thus, there is potential for integrating the checklist in peer-review procedures, as one of our external experts suggested. On the other hand, it informs non-specialist audiences of the importance of transparency and integrity when considering the quality of a manuscript. As another external expert pointed out, certain practices such as open data sharing are considered to be at the forefront of scientific endeavours, and not all researchers adhere to these standards, even if their research is sound. However, we believe that part of the reason for this non-adherence is that not everyone believes such Open Science practices to be sufficiently important, even despite a clear need to improve reproducibility in many areas of science.65,67 By dedicating an entire item to issues of transparent reporting and research integrity, we hope to encourage non-specialists as well as scientists to both pay attention to and think critically about issues of transparency and integrity, in addition to the soundness of the research being reported.
Apart from the external expert comments already mentioned, the (online survey) review process revealed several important insights. It was illuminating that many experts agreed that the initial draft was too complex for non-scientist audiences, while there were also suggestions for additional items that required, in our view, expertise that non-scientists would not reasonably have. This situation made it clear that we had to define our target audience more precisely, and strike the right balance between simplicity and functionality in our checklist to make it both usable and accurate. The implementation round confirmed that the checklist was indeed usable, as both our student and journalist cohorts across multiple sites appeared to understand how the checklist was supposed to be used. Further, in our workshops, there appeared to be an overlap in the students’ and journalists’ application of the checklist to the high- and low- quality preprints and our own. We do acknowledge that many important aspects of checking the quality of a scientific work that the experts mentioned were omitted, such as verifying the references, checking whether the work fills a gap in knowledge, and checking whether the statistical analyses are justified. Though this can be construed as a limitation, we believe it is justified by the feasibility constraint of the checklist being a teaching tool for audiences that will very likely not have the expertise to verify preprints in such ways.
Another prominent theme that emerged in the external experts’ comments was an implicit prioritization of randomized controlled trials, which could in turn disadvantage observational studies. Though we did not find the checklist to be as gravely biased, as all three of our high-quality preprints57–59 were on observational studies, and they ‘passed’ the items on the checklist very well. We nonetheless appreciated the importance of this point, as much of the COVID-19 research reported in preprints was indeed observational.16 In response, we made two substantial changes to the checklist. For one, we expanded the explanation of what observational studies are in the Why is this important? Section of Study type, by including concrete examples. This could help prevent non-experts from falsely identifying an observational study as having not indicated a study type, as unlike for randomized controlled trials, manuscripts on observational studies often do not explicitly mention that the research was observational. Moreover, we made it clear that the potential sources of bias mentioned in the ‘let’s dig deeper’ section in limitations were only examples, we added disclaimers for those sources of bias that may not apply to observational studies (control group/control condition, randomization, and blinding, specifically), and we included two more examples of biases that could apply to observational studies (spin and overinterpretation). We believe that these changes made the checklist more balanced towards all study types.
One important aspect of the checklist to note is its intended use as a teaching tool to guide non-specialist audiences to evaluate preprints more critically than they otherwise might. The checklist is not meant to be a litmus test for whether a preprint is trustworthy or not, but rather a set of guidelines for users to make their own judgements based on, and a pedagogical tool to improve people’s competences and confidence at evaluating the quality of research. Though the superficial level alone could, in theory, be automated, as we have seen, the best results are obtained when the superficial and deep levels are combined, and it is the deep level that allows the user to delve deeper into issues of study design and potential biases. Nonetheless, it is useful to have a division into a superficial and deep level of assessment, as this allows greater flexibility for users to apply the checklist according to their needs.
Over multiple iterative steps of internal and external review, sensitivity tests, and final polishing after the implementation phase, we created the PRECHECK checklist: a simple, user-friendly tool for helping scientifically literate non-experts critically evaluate preprint quality. We were inspired by the urgency of improving the public’s understanding of COVID-19 preprints, in which efforts to increase public awareness on preprint quality and competences at estimating preprint quality have been next to non-existent. Despite our COVID-19-related motivation, the PRECHECK checklist should be more broadly applicable to scientific works. With this, and the fact that our target audience could use the checklist, we believe that the checklist has great potential to help guide non-scientists’ understanding of scientific content, especially in preprint form.
Conceptualization: LH, EV, EF; Data curation: NT, SS, RH; Formal Analysis: NT, SS, RH; Funding acquisition: LH, EV; Investigation: NT, SS, RH; Methodology: NT, SS, RH; Project administration: NT, SS, RH; Resources: LH, EV; Software: NT, SS, RH; Supervision: LH, EV, EF; Validation: NT, RH, SS, EF, EV, LH; Visualization: NT, SS, RH; Writing – original draft: NT, RH; Writing – review & editing: NT, RH, SS, EF, EV, LH.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)