Keywords
Anomaly Detection, Graph Deviation Network, Graph Neural Network, Multivariate Time Series, Graph Attention Forecasting, Spatio-temporal Data, Complex Systems
This article is included in the Ecology and Global Change gateway.
Anomaly Detection, Graph Deviation Network, Graph Neural Network, Multivariate Time Series, Graph Attention Forecasting, Spatio-temporal Data, Complex Systems
Minor revisions based on reviewer feedback, notably the inclusion of an ablation study surrounding the choice of percentile used for the threshold calculation for GDN+ across various datasets.
See the authors' detailed response to the review by Maurício Araújo Dias
See the authors' detailed response to the review by Ailin Deng
River network systems play a vital role as freshwater habitats for aquatic life, and as support for terrestrial ecosystems in riparian zones, but are particularly sensitive to the anthropogenic impacts of climate change, water pollution and over-exploitation, among other factors. As a United Nations Sustainable Development Goal,1 water quality is a major environmental concern worldwide. The use of in-situ [1] sensors for data collection on river networks is increasingly prevalent,2,3 generating large amounts of data that allow for the identification of fine-scale spatial and temporal patterns, trends, and extremes, as well as potential sources of pollutants and their downstream impacts. However, such sensors are susceptible to technical errors relating to the equipment, herein defined as anomalies, for example due to miscalibration, biofouling, electrical interference and battery failure. In contrast, extreme events in rivers occur as result of heavy rain and floods. Technical anomalies must be identified before the data are considered for further analysis, as they can introduce bias in model parameters and affect the validity of statistical inferences, confounding the identification of true changes in water variables. Trustworthy data is needed to produce reliable and accurate assessments of water quality, for enhanced environmental monitoring, and for guiding management decisions in the prioritisation of ecosystem health.
Anomaly detection in river networks is challenging due to the highly dynamic nature of river water even under typical conditions,4 as well as the complex spatial relationships between sensors. The unique spatial relationships between neighbouring sensors on a river network are characterised by a branching network topology with flow direction and connectivity, embedded within the 3-D terrestrial landscape. Common anomalies from data obtained from in-situ sensors are generally characterised by multiple consecutive observations (subsequence or persistent5), including sensor drift and periods of unusually high or low variability, which may indicate the necessity for sensor maintenance or calibration.6 Such anomalies are difficult to detect and often associated with high false negative rates.7 The taxonomy employed to categorize anomalies into distinct types follows Ref. 7.
Earlier statistical studies have focused on developing autocovariance models based on within-river relationships to capture the unique spatial characteristics of rivers.8 Although these methods are adaptable to different climate zones, and have recently been extended to take temporal dependencies into account,9 data sets generated by in-situ sensors still pose significant computational challenges with such prediction methods due to the sheer volume of data.10 Autocovariance matrices must be inverted when fitting spatio-temporal models and making predictions, and the distances between sites must be known. Previous work,11 aimed to detect drift and high-variability anomalies in water quality variables, by studying a range of neural networks calibrated using a Bayesian multi-objective optimisation procedure. However, the study was limited to analyzing univariate time series data, and the supervised methods required a significant amount of labeled data for training, which are not always available.
There are limited unsupervised anomaly detection methods for subsequence anomalies (of variable length), and even less so for multivariate time series anomaly detection.5 One such method uses dynamic clustering on learned segmented windows to identify global and local anomalies.12 However, this algorithm requires the time series to be well-aligned, and is not suitable for the lagged temporal relationships observed with river flow. Another method to detect variable-length subsequence anomalies in multivariate time series data uses dimensionality reduction to construct a one-dimensional feature, to represent the density of a local region in the recurrence representation, indicating the recurrence of patterns obtained by a sliding window.13 A similarity measure is used to classify subsequences as either non-anomalous or anomalous. Only two summary statistics were used in this similarity measure and the results were limited to a low-dimensional simulation study. In contrast, the technique introduced by Ref. 14, DeepAnT, uses a deep convolutional neural network (CNN) to predict one step ahead. This approach uses Euclidean distance of the forecast errors as the anomaly score. However, an anomaly threshold must be provided.
Despite the above initial advances, challenges still remain in detecting persistent variable-length anomalies within high-dimensional data exhibiting noisy and complex spatial and temporal dependencies. With the aim of addressing such challenges, we explore the application of the recently-proposed Graph Deviation Network (GDN),15 and explore refinements with respect to anomaly scoring that address the needs of environmental monitoring. The GDN approach15 is a state-of-the-art model that uses sensor embeddings to capture inter-sensor relationships as a learned graph, and employs graph attention-based forecasting to predict future sensor behaviour. Anomalies are flagged when the error scores are above a calculated threshold value. By learning the interdependencies among variables and predicting based on the typical patterns of the system in a semi-supervised manner, this approach is able to detect deviations when the expected spatial dependencies are disrupted. As such, GDN offers the ability to detect even the small-deviation anomalies generally overlooked by other distance based and density based anomaly detection methods for time series,16,17 while offering robustness to lagged variable relationships. Unlike the commonly-used statistical methods that explicitly model covariance as a function of distance, GDN is flexible in capturing complex variable relationships independent of distance. GDN is also a semi-supervised approach, eliminating the need to label large amounts of data, and offers a computationally efficient solution to handle the ever increasing supply of sensor data. Despite the existing suite of methods developed for anomaly detection, only a limited number of corresponding software packages are available to practitioners. In summary, we have identified the following gaps in the current literature and research on this topic:
1. An urgent need exists for a flexible approach that can effectively capture complex spatial relationships in river networks without the specification of an autocovariance model, and the ability to learn from limited labeled data, in a computationally efficient manner.
2. Lack of data and anomaly generation schemes on which to benchmark methods, that exhibit complex spatial and temporal dependencies, as observed across river networks.
3. Limited open-source software for anomaly detection, which hinders the accessibility and reproducibility of research in this field, and limits the ability for individuals and organisations to implement effective anomaly detection strategies.
Our work makes four primary contributions to the field:
1. An improvement of the GDN approach via the threshold calculation based on the learned graph is presented, and shown to detect anomalies more accurately than GDN while improving the ability to locate anomalies across a network.
2. Methods for simulating new benchmark data with highly-sophisticated spatio-temporal structures are provided, contaminated with various types of persistent anomalies.
3. Numerical studies are conducted, featuring a suite of benchmarking data sets, as well as real-world river network data, to explore the strengths and limitations of GDN (and its variants) in increasingly challenging settings.
4. User-friendly, free open-source software for the GDN/GDN+ approach is made available on the pip repository as gnnad, with data and anomaly generation modules, as well as the publication of a novel real-world data set.
The structure of the remainder of the paper is as follows: The next section details the methods of GDN and the model extension GDN+, and describes the methodology of the simulated data and anomaly generation. In the Results section we present an extensive simulation study on the benchmarking data, as well as a real-world case study. The performance of GDN/GDN+ is assessed against other state-of-the-art anomaly detection models. Further details and example code for the newly-released software are also provided. The paper concludes with a discussion of the findings, and the strengths and weaknesses of the considered models.
Consider multivariate time series data , obtained from sensors over time ticks. The (univariate) data collected from sensor at time are denoted as . Following the standard semi-supervised anomaly detection approach,18,19 non-anomalous data are used for training, while the test set may contain anomalous data. That is, we aim to learn the sensor behaviour using data obtained under standard operational conditions throughout the training phase and identify anomalous sensor readings during testing, as those which deviate substantially from the learned behaviour. As the algorithm output, each test point is assigned a binary label, , where indicates an anomaly at time , anywhere across the full sensor network.
The GDN approach15 for anomaly detection is composed of two aspects:
1. Forecasting-based time series model: a non-linear autoregressive multivariate time series model that involves graph neural networks is trained, and
2. Threshold-based anomaly detection: transformations of the individual forecasting errors are used to determine if an anomaly has occurred, if such errors exceed a calculated threshold.
The above components are described in more detail below.
Forecasting-based Time Series Model. To predict , the model takes as input lags of the multivariate series,
The -th row (containing sensor ’s measurements for the previous lags) of the above input matrix is represented by the column vector, . Prior to training, the practitioner specifies acceptable candidate relationships via the sets , where each and does not contain . These sets specify which nodes are allowed to be considered to be connected from node (noting that the adjacency graph connections are not necessarily symmetric).
The model implicitly learns a graph structure via training sensor embedding parameters for which are used to construct a graph. The intuition is that the embedding vectors capture the inherent characteristics of each sensor, and that sensors which are “similar” in terms of the angle between their vector embeddings are considered connected. Formally, the quantity is defined as the cosine similarity between the vector embeddings of sensors and :
with denoting the Euclidean norm, and indicator function which equals 1 when node belongs to set , and 0 otherwise. Note that the similarity is forced to be zero if a connecting node is not in the permissible candidate set. Next, let be the -th largest value in . A graph-adjacency matrix (and in turn a graph itself) is then constructed from the sensor similarities via:for user-specified which determines the maximum number of edges from a node, referred to as the “Top-K” hyperparameter.The above describes how the trainable parameters yield a graph. Next, the lagged series are fed individually through a shallow Graph Attention Network20 that uses the previously constructed graph. Here, each node corresponds to a sensor, and the node features for node are the lagged (univariate) time-series values, . Allow a parameter weight matrix to apply a shared linear transform to each node. Then, the output of the network is given by
where is called the node representation, and coefficients are the attention paid to node when computing the representation for node , with:Threshold-based Anomaly Detection. Given the learned inter-sensor and temporal relationships, we are able to detect anomalies as those which deviate from these interdependencies. An anomalousness score is computed for each time point in the test data. For each sensor , we denote the prediction error at time as,
with denoting the absolute value, and the vector of prediction error for each sensor is, . Since the error values of different sensors may vary substantially, we perform a robust normalisation of each sensor’s errors to prevent any one sensor from overly dominating the others, that is,where IQR denotes inter-quartile range. In the original work by Ref. 15, a time point is flagged as anomalous if,using the notation for the error value at the -th index. Alternatively, the authors recommend using a simple moving average of and flagging time as anomalous if the maximum of that moving average exceeds . The authors specify as the maximum of the normalised errors observed on some (non-anomalous) validation data, denoted by variant epsilon, . However, this is applied to all sensors as a fixed threshold.The behavior of water quality variables may differ across space, for example, water level at high-altitude river network branches are generally characterised by rainfall patterns, whereas water level downstream near a river outlet can also be influenced by tidal patterns. A fixed threshold across the network does not allow for any local adaptations in error sensitivity. For this reason, this work also considers the novel sensor-specific threshold calculation,
where is chosen such that,for some user-specified percentile, , and where is the cardinality. In other words, the threshold for each sensor, , is set as the -th percentile of the normalised error scores across the neighbourhood of , on the validation data set. Unless otherwise stated, we set . In this way, the sensor threshold is based only on its direct neighbourhood, as opposed to the original method which uses the global maximum, and is thus in tune with the local behaviour of the system, and more robust as a percentile. We refer to the GDN model using this variant of the threshold-based anomaly detection as GDN+.The following is a method for simulating synthetic datasets with persistent anomalies inspired by the statistical models recently used to model river network data.9 Let denote an arbitrary set of individual spatial locations, with locations chosen by experimental design21 or otherwise. Consider a linear mixed model with response , and design matrix of explanatory variables spatially indexed at locations ,
Note that other distributions may be used. Above,
for some covariance kernel . For example,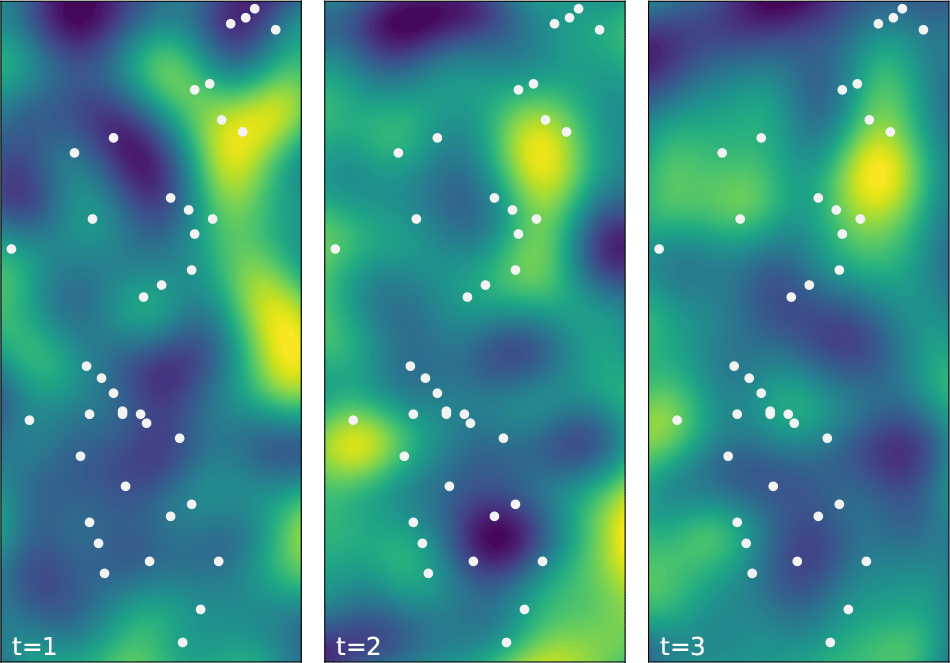
Examples of the field are shown for . Sensor locations are shown as white dots.
We consider two scenarios in generating simulated data: 1) spatial relationships characterised by Euclidean distance only, where the covariance matrix, , is constructed via the kernel function given in Equation 4, and 2) data simulated on a river network, where is constructed via the kernel function given in Equation 5. Together, this approach provides a variety of simulated data with highly-sophisticated dependency structure, see Figure 2.
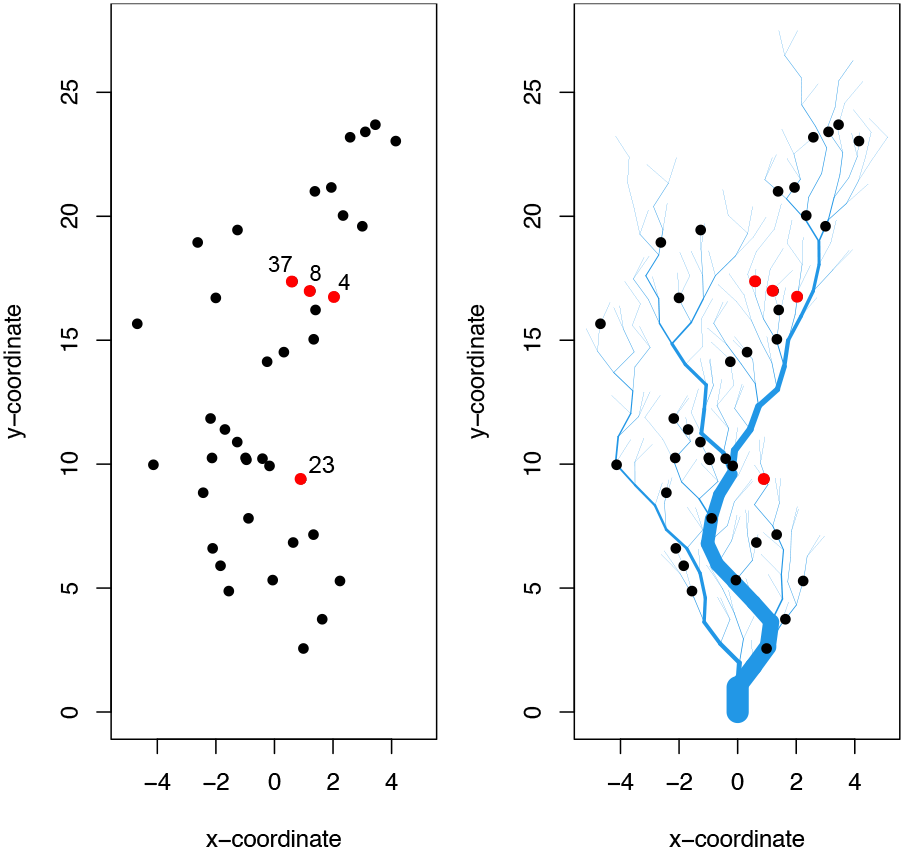
Both simulations use the same (x, y) coordinates for sensor locations. The direction of flow is from top to bottom for SimRiver. Red dots indicate sites for which time series have been shown in Figure 3 and Figure 4.
Two points , on a river network are said to be flow-connected if they share water flow, and flow-unconnected otherwise. We define stream distance, , as the shortest distance separating and when travelling along a given river network. Tail-up covariance models for river networks, introduced in,8 effectively represent spatial relationships when variables are dominated by flow (e.g. pollutants enter a stream and only impact downstream locations). By construction, the tail-up covariance function only allows for correlation between flow-connected sites:
Once the base multivariate time series is constructed as above, it is modified to include persistent anomalies as follows. Hyperparameters are, , the number of subsequence anomalies and, , the average length of an anomalous subsequence, for each anomaly type. In this example, we consider two types of anomalies, high-variability and drift, see Algorithm 1.
input : Time series data , number of locations , expected length of each anomaly type and , number of anomalies, and , variability anomaly scale , and drift anomaly parameter .
for do
for do
Draw location
Draw time
Draw length
if then
// drift
else
// variability
The Python package gnnad introduced in this paper extends and generalises the research code originally implemented by Ref. 15, which is incompatible with newer package dependencies and offers only a command line interface. The code is refactored to be modular and user-friendly, with a scikit-inspired interface, and extended to include visualisation, data and anomaly generation modules, as well as the GDN+ model extension. A continuous integration/continuous deployment (CI/CP) pipeline is established with unit testing to ensure that changes to the code are tested and deployed efficiently. Comprehensive documentation now accompanying the codebase enhances readability for future developers, facilitating maintenance, reuse, and modification. Furthermore, rigorous error handling is implemented to improve the software experience. The software developments have resulted in a more robust, user-friendly and easily distributable package that is available via https://github.com/KatieBuc/gnnad and the pip repository, gnnad. See below for example code that shows the process of fitting the GDN+ model.
from sklearn.model_selection import train_test_split
from gnnad.graphanomaly import GNNAD
from gnnad.generate import GenerateAnomaly
# split train test for input data frame, X
X_train, X_test = train_test_split(X, shuffle=False)
# generate anomalies on test set
anoms = GenerateAnomaly(X_test)
X_test = anoms.generate(anoms.variability, lam=3, prop_anom=0.07, seed=45)
X_test = anoms.generate(anoms.drift, lam=11, prop_anom=0.07, seed=234)
y_test = anoms.get_labels()
# instantiate and fit GDN model object
model = GNNAD(threshold_type="max_validation", topk=6, slide_win=200)
fitted_model = model.fit(X_train, X_test, y_test)
# sensor based threshold based on GDN+
pred_label = fitted_model.sensor_threshold_preds(tau=99)
# print evaluation metrics
fitted_model.print_eval_metrics(pred_label)
This section presents a summary of the main findings for anomaly detection using GDN/GDN+ on both simulated and real-world data. To ensure quality of data, the aim for practitioners is to maximise the ability to identify anomalies of different types, while minimising false detection rates. We define the following metrics in terms of true positive (TP), true negative (TN), false positive (FP) and false negative (FN) classifications. In other words, the main priority is to minimise FN, while maintaining a reasonable number of FP, such that it is not an operational burden to check the total number of positive flags. Accordingly, we use recall, defined by , to evaluate the performance on the test set and to select hyperparameters. That is, the proportion of actual positive cases that were correctly identified by the model(s). We also report the performance using precision , accuracy and specificity .
To evaluate model performance, three existing anomaly detection models are used as benchmarks: 1. The naive (random walk) Autoregressive Integrated Moving Average Model (ARIMA) prediction model from Refs. 7, 26; 2. HDoutliers,17 an unsupervised algorithm designed to identify anomalies in high-dimensional data, based on a distributional model that allows for probability assignment to an anomaly; and 3. DeepAnT,14 an unsupervised, deep learning-based approach to detecting anomalies in time series data.
Data are generated using the linear-mixed model described in Equation 2, with differing spatial dynamics: SimEuc where the random effect, , is characterised by Euclidean distance only, and SimRiver where simulates complex river network dynamics,27 using the same site locations and covariate values, . Detecting anomalies that involve multiple consecutive observations is a difficult task that often requires user intervention, and is the focus of this study. We consider scenarios with drift and high-variability anomaly types, which together contaminate of the test data, given , see Table 1.
| Dataset | #Train | #Test | %Anomalies |
|---|---|---|---|
| SimEuc | |||
| SimRiver | |||
| Herbert | 58.0 |
Figure 3 visualises aspects of the SimEuc dataset, where sensor 37 and sensor 8 are in close (Euclidean) proximity, resulting in a high correlation between the locations (0.65), as anticipated. Note that sensor 23 exhibits anomalous behavior, high-variability and drift, consecutively, over time. Compared to the SimRiver dataset, shown in Figure 4, we note how the time series from sensor 37 and sensor 8 are no longer strongly correlated (0.07), despite their close proximity, as they are not flow-connected in the simulated river network.
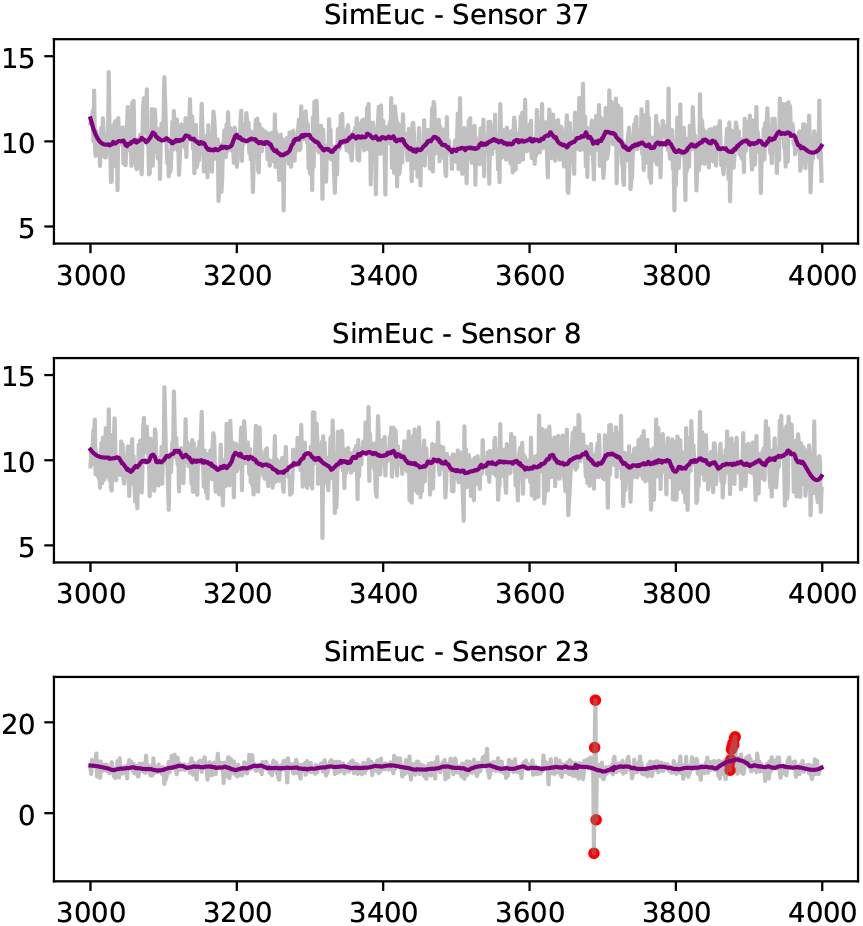
A Savitzky-Golay filter smoothens the time series (purple line). On the bottom, sensor 23 illustrates high-variability and drift anomalies, consecutively (red dots).
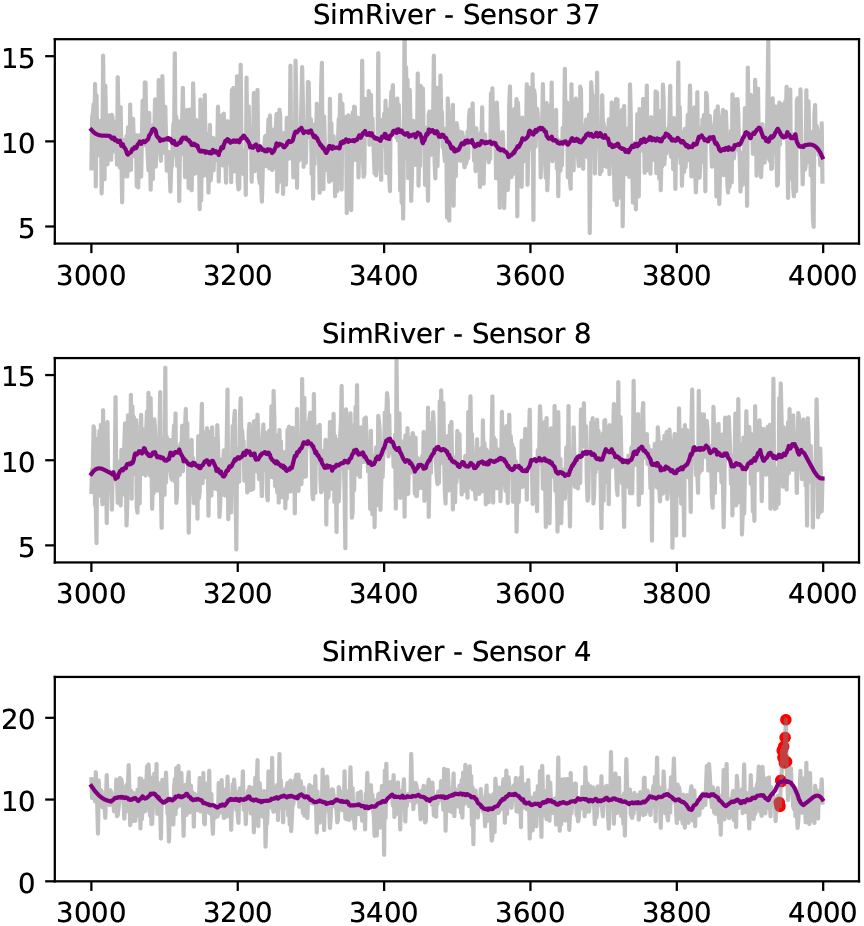
Drift anomalies (red dots) are shown in data from sensor 4. A Savitzky-Golay filter is used to smoothen the time series for visual representation (purple line).
Table 2 shows the performance of the different anomaly detection methods. The best performance in terms of recall is highlighted in bold, while the second-best performance is underlined. We observe that GDN/GDN+ outperforms most other models in terms of recall, which is the fraction of true positives among all actual positive instances. Specifically, GDN has a recall score of 83.3% on SimEuc and 72.7% on SimRiv, while GDN+ has the second highest recall score of 85.6% on SimEuc and 78.0% on SimRiv. Although ARIMA performed best in terms of recall, the high percentage of detected anomalies, 81.6% and 85.6%, is impractical to use (discussed below) and results in low accuracy scores of 28.6% and 25.3%, respectively. HDoutliers did not flag any time point as anomalous in any test case. DeepAnT tends to classify most samples as negative, resulting in a low recall score. These results suggest that GDN/GDN+ are best able to detect a high proportion of actual anomalies in the datasets.
Figure 5 shows the classifications of anomalies in the simulation study. For reasons mentioned, recall is the performance metric of interest, but we also consider the trade-off between recall and precision. Lower precision means that the model may also identify some normal instances as anomalies, leading to false positives. In the context of river network anomaly detection, FP may be manually filtered, but it is critical to minimise FN. Note that GDN+ outperforms GDN in minimising the FN count, but at the cost of increasing FP, in both data sets. Such a trade-off is acceptable and considered an improvement in this context. Conversely, while ARIMA has the highest recall score, the number of FP classifications is impractical for practitioners to deal with (>70% of the test data). We also note that drift anomalies are harder to detect than high-variability anomalies, with drift as the majority of FN counts, in all cases.
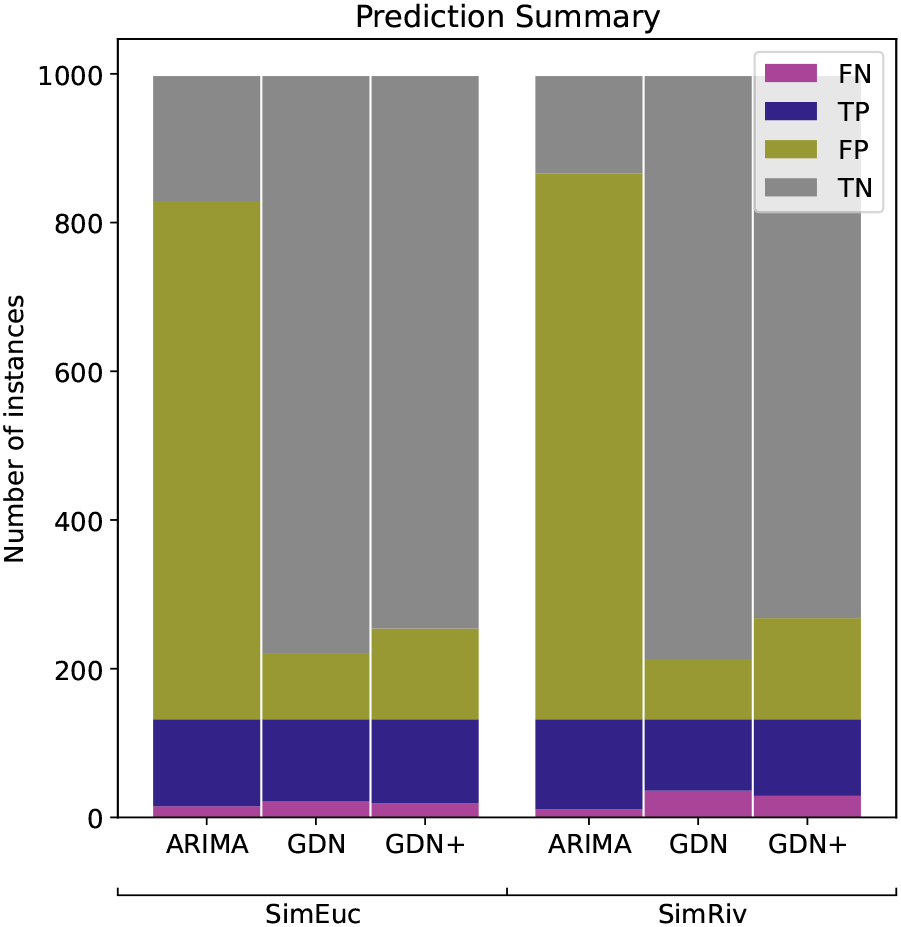
The authors of the GDN model demonstrated its efficacy in detecting anywhere-within-system failures at time by applying a threshold to all sensors within a system. However, the use of sensor-based thresholds in GDN+ has the advantage of indicating anomalies at the individual sensor level. In the context of monitoring river networks, it is crucial to identify the anomalous sensor, , at a given time . The percentage of true positives detected at the correct sensor, , using the sensor-based anomaly threshold, , in GDN+, was 92% and 89% for SimEuc and SimRiver, respectively. Similarly, the rate of true positives detected in the neighbourhood of the correct sensor were 96% and 91%, respectively. This granularity of information is essential for large networks consisting of independent sensors that are separated by significant spatial distances, where the cost of time and travel for sensor replacement or maintenance is substantial.
This section explores the anomaly detection performance of GDN/GDN+ across multiple simulated data sets. The approach is as follows. First, ten new sets of spatial sampling locations are created, and for each set a Gaussian random field evolving over time is simulated, as per Equation 3. For each set of locations, we again consider both the Euclidean spatial characterisation (SimEuc), and the river network spatial characterisation (SimRiver), yielding a total of 20 benchmark data sets. In the first case, we use the Euclidean covariance model in Equation 4, parameterised by, , and, , with independent noise parameter, , and regression parameters , and, , for the linear model in Equation 2. The values of the parameters are chosen uniformly at random. The Tail-up covariance model in Equation 5 is used in the second case, parameterised as above.
Then, anomalies are generated with the following parameters: drift , variability , length of anomalies , , and the number of anomalies, , (see Algorithm 1). Across all simulations, the size of the data set is fixed to have length, , and number of sensors, .
Figure 6 illustrates the anomaly detection performance for GDN and GDN+, run on each data set with sliding window length , and Top-K hyperparameter . Note that the total number of anomalies can be seen at the bar height of TP+FN. In every scenario, GDN+ improves the FN count (red line), but at the cost of an increased TP count (orange line). Whether such a tradeoff is tolerable depends on how critical it is in practical scenarios that true anomalies are successfully detected. Note, that performance varies from one scenario to the next. Nevertheless, despite the simulated datasets being extremely noisy and complex, GDN and GDN+ appear to succeed in successful anomaly detection when other methods cannot.
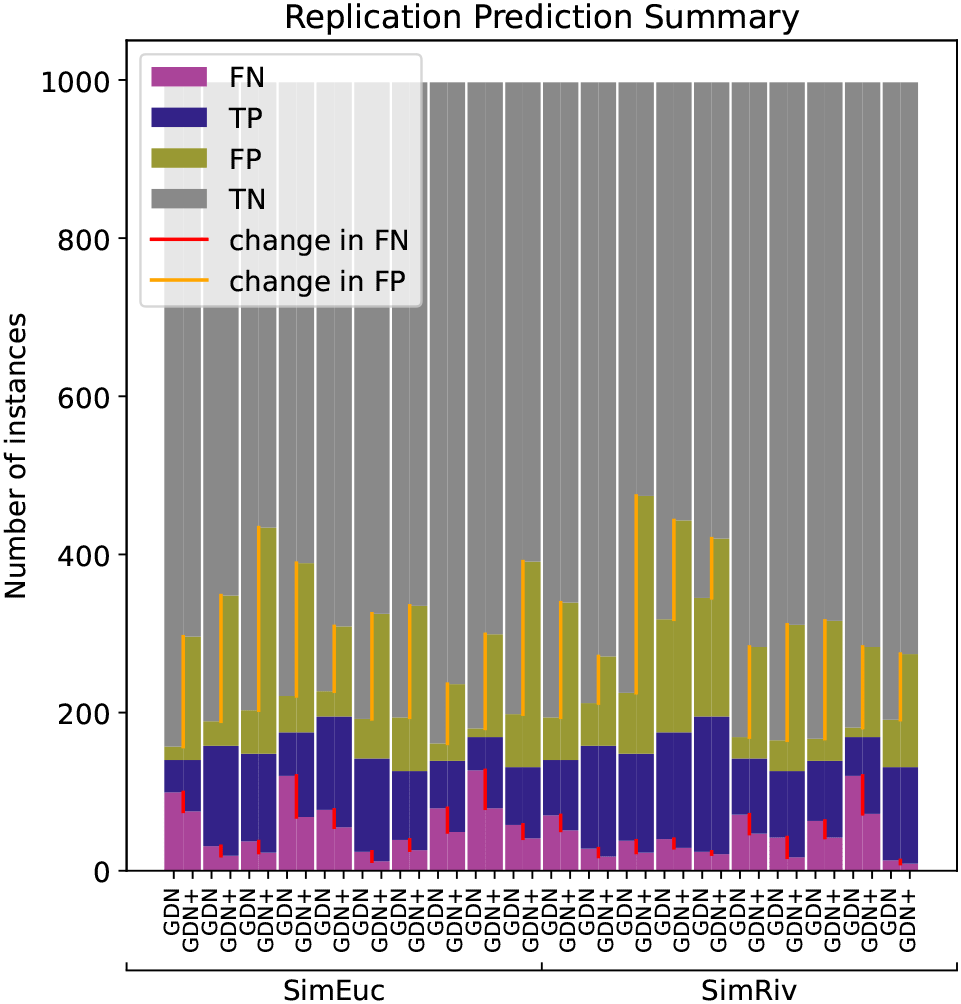
Note that GDN+ consistently decreases false negatives (red line) in every case, but also increases false positives (orange line).
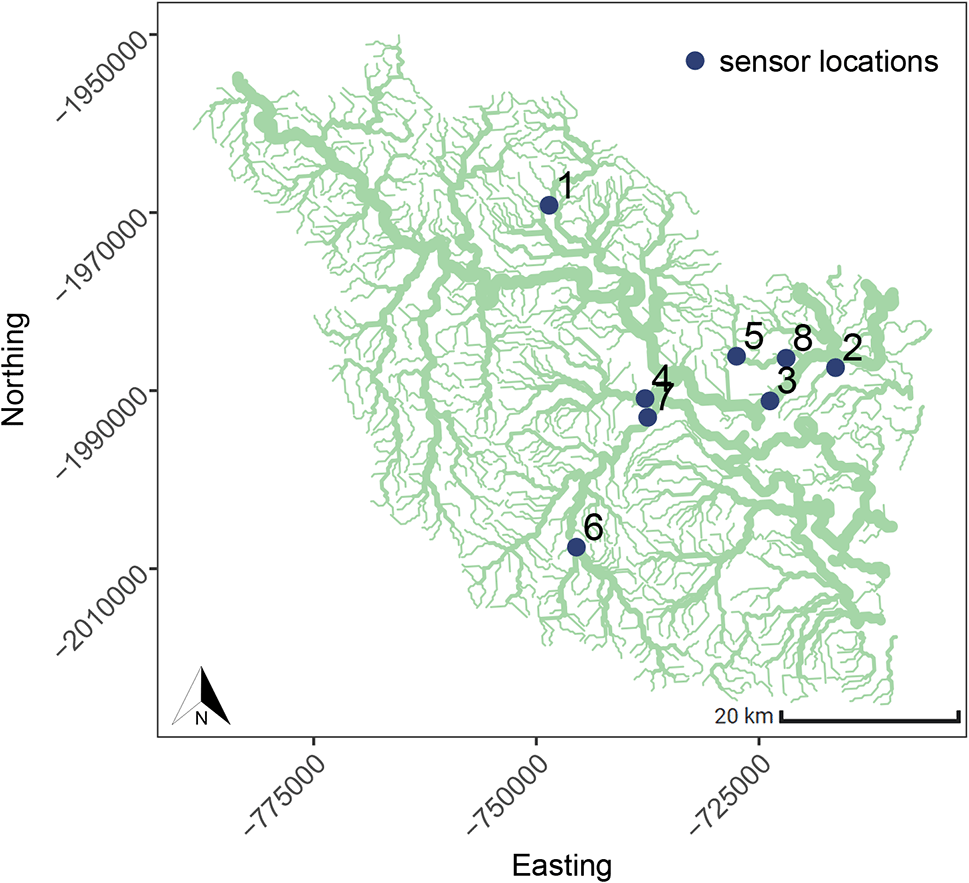
This case study examines water-level data collected from eight sites located across the Herbert river, a major river system located in the tropical region of Australia, as shown in Figure 7. The time series data is highly non-stationary, characterised by river events caused by abnormal rainfall patterns, with some coastal sites exhibiting shorter periodicity trends which can be attributed to tidal patterns, see Figure 8. The spatial relationships are complex, and depend on the surrounding water catchment areas, spatial rainfall patterns, dams, and other impediments. In-situ sensors are prone to various anomalies such as battery failure, biofouling (accumulation of microorganisms, plants, algae, or small animals), and damage. In some cases, anomalies can manifest as the absence of a water event (i.e., flatlining) rather than the presence of abnormal time series patterns (i.e., spikes, variability, drift). In real-world scenarios, anomalies can persist for extended periods, and resolving them may require traveling to remote locations to inspect and repair sensors. As seen in Figure 8, anomalies at time are largely attributed to Sensor 4, which was out of water for long periods of time.
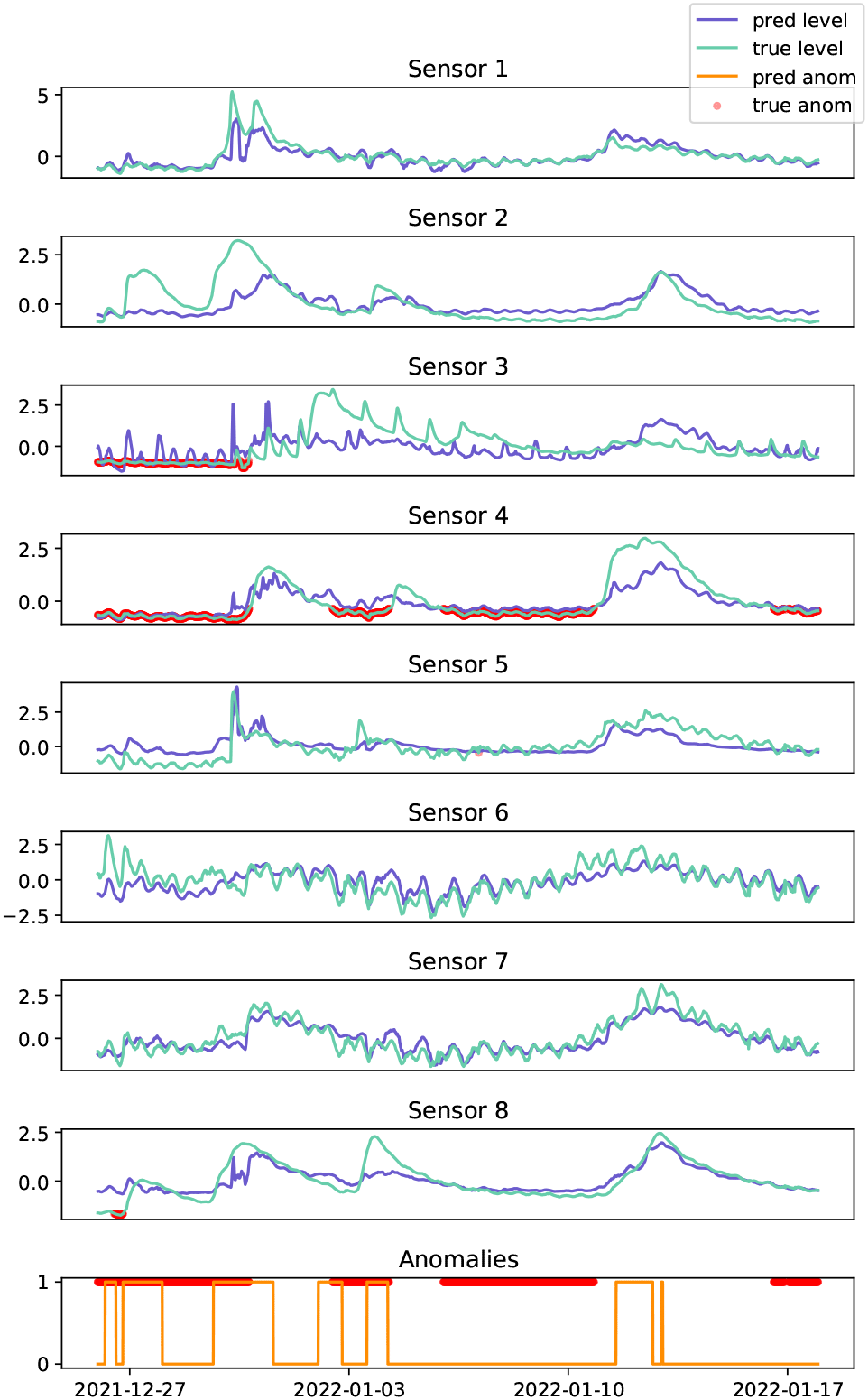
Actual anomalies (red dots) are shown, along with the predicted anomalies (orange line) on the bottom.
The Herbert river is a challenging data set for all of the anomaly detection models, due to the sparse placement of sensors across the network, i.e., fewer sensors at greater distances apart resulting in weaker spatial relationships, and the test set contains a high proportion of anomalies (58%; see Table 1). GDN applied to the real-world dataset yields a recall of , with GDN+ improving recall to , see Table 3. Model performance suffers primarily due to the failure to detect the large anomaly spanning across 2022-01-10 in Figure 8. This may be attributed to the learned graph relationships being characterised by river events in the training data, and without such events, it is difficult to identify when a sensor is flat-lining. However, the model successfully identified anomalies spanning across 2021-12-27 and 2022-01-03, which coincided with river events. See also the extended data36 (see Data availability) for an ablation study focusing on the effectiveness of anomaly detection across different thresholds, τ.
| Data | Model | Rec | Prec | Acc | Spec |
|---|---|---|---|---|---|
| Herbert | HDoutliers | 0.0 | 0.0 | 42.0 | 100.0 |
| ARIMA | 30.5 | 62.9 | 51.3 | 77.5 | |
| DeepAnT | 1.6 | 39.7 | 44.0 | 97.0 | |
| GDN | 29.2 | 60.6 | 50.1 | 76.2 | |
| GDN+ | 34.8 | 59.2 | 50.4 | 70.0 | |
| GDN++ | 100.0 | 80.7 | 86.7 | 70.0 |
Figure 9 shows the learned graph adjacency matrix, . Sensor 1, separated geographically by a large distance from the other sensors, has weaker relationships with the other nodes. Interestingly, the attention weights indicate that sensor 3 is strongly influenced by sensor 6, with tidal patterns from sensor 6 being evident in the predictions of sensor 3. Large error scores indicating an anomaly spanning across 2021-12-27 are primarily observed in sensor 2, impacted by anomalous sensors 3 and 4, where the predicted values are low. However, due to the small network of sensors in this case study, it is difficult to determine which sensor had the anomaly.

The edge weightings are determined by , which indicates attention and depend on model input, .
Adjusting the threshold in the GDN+ model can only enhance performance to a limited extent, since some anomalies may have insignificant error scores due to the underlying time series model. For instance, the anomaly spanning across 2022-01-10 has negligible error scores because the prediction model was performing well and no river events had occurred, making it challenging to detect the flat-lining type of anomaly in this particular scenario. Therefore, relying solely on the model may not be sufficient in practice, and we recommend implementing some basic expert rules. We introduce another model variant GDN++, by applying a simple filter to the time series ensuring that all values are positive, used in conjunction with adjusting the threshold calculation (GDN+). That is, an anomaly at time, , on sensor, , is flagged if, GDN++ successfully detects all anomalies.
Multivariate anomaly detection and prediction models for spatio-temporal sensor data have the potential to transform water quality observation, modelling, and management.7,8 The provision of trustworthy sensor data has four major benefits: 1. It enables the production of finer-scale, reliable and more accurate estimates of sediment and nutrient loads, 2. It provides real-time feedback to landholders and managers, 3. It guides compliance with water quality guidelines, and 4. It allows for the assessment of ecosystem health and the prioritisation of management actions for sustaining aquatic ecosystems. However, technical anomalies in the data provided by the sensors can occur due to factors such as low battery power, biofouling of the probes, and sensor miscalibration. As noted by Ref. 7, there are a wide variety of anomaly types present within in-situ sensor data (e.g., high-variability, drift, spikes, shifts). Most anomaly detection methods used for water quality applications tend to target specific anomalies, such as sudden spikes or shifts.28–30 Detecting persistent anomalies, such as sensor drift and periods of abnormally high variability, remains very challenging for statistical and machine learning research. Such anomalies are often overlooked by distance and kernel based methods, yet must be detected before the data can be used, because they confound the assessment of status and trends in water quality. Understanding the relationships among, and typical behaviours of, water quality variables and how these differ among climate zones is thus an essential step in distinguishing anomalies from real water quality events.
We investigated the graph-based neural network model, GDN,15 for its ability to capture complex interdependencies between different variables in a semi-supervised manner. As such, GDN offered the ability to capture deviations from expected behaviour within a high-dimensional setting. We developed novel bench-marking data sets for subsequence anomaly detection (of variable length and type), with a range of spatio-temporal complexities, inspired by the statistical models recently used for river network data.9 Results showed that GDN tended to outperform the benchmarks in anomaly detection. We developed a model extension, GDN+, by adjusting the threshold calculation. GDN+ was shown to further improve performance. A replication study with multiple benchmarking data sets demonstrated consistency in these results. Sensor-based thresholds also proved useful in terms of identifying which neighbourhood the anomaly originated from in the simulation study.
We used a real-world case study of water level in the Herbert river, with non-stationary time series characterised by multiple river events caused by abnormal rainfall patterns. In this case, most of the anomalies appeared as flat-lining, due to the river drying out. Considering an individual time series, such anomalies may not appear obvious, as it is the failure to detect river events (in a multivariate setting) that is indicative of an anomalous sensor. Despite the challenges in the data, GDN+ was shown to successfully detect technical anomalies when river events occurred, and combined with a simple expert-based rule, GDN++, all anomalies were successfully detected.
There are two recent methodological extensions to the GDN approach. First, the Fused Sparse Autoencoder and Graph Net31 which extends the GDN approach by augmenting the prediction-based loss with a reconstruction-based term arising from the output of a sparse autoencoder, and a further extension that allows the individual sensors to have multivariate data. Second, a probabilistic (latent variable) extension is trained using variational inference.32 Since these were published contemporaneously to the present research, and only the latter provided accompanying research code, these approaches were not considered in the paper. Future extensions of this work could consider incorporating the above methodological extensions, as well as developing on the existing software package.
Other applications could consider the separation of river events from technical anomalies. In terms of interpretability, since the prediction model aggregates feature data from neighbouring sensors, anomalous data can affect the prediction of any other sensor within the neighbourhood. Therefore, large error scores originating from one sensor anomaly can infiltrate through to the entire neighbourhood, and impairs the ability to attribute an anomaly to a sensor. The extensive body of literature on signal processing for source identification has the potential to inspire future solutions in addressing this issue.33,34
In summary, this work extends and examines the practicality of the GDN approach when applied to an environmental monitoring application of major international concern, with complex spatial and temporal interdependencies. Successfully addressing the challenge of anomaly detection in such settings can facilitate the wider adoption of in-situ sensors and could revolutionise the monitoring and management of air, soil, and water.
This work studied the application of Graph Deviation Network (GDN) based approaches for anomaly detection on the challenging setting on river network data, which often feature sensors that generate high-dimensional data with complex spatio-temporal relationships. We introduced alternative defection criteria for the model (GDN+/GDN++), and their practicality was explored on both real and simulated benchmark data. The findings indicated that GDN and its variants were effective in correctly (and conservatively) identifying anomalies. Benchmark data were generated via an approach that was also introduced in this paper, along with open-source software, and may serve useful in the development and testing of other anomaly-detection methods. In short, we found that graph neural network based approaches to anomaly detection offer a flexible framework, able to capture and model non-standard, highly dynamic, complex relationships over space and time, with the ability to flag a variety of anomaly types. However, the task of anomaly detection on river network sensor data remains a considerable challenge.
KB; Investigation, Formal Analysis, Methodology, Software, Validation, Visualisation, Writing – Original Draft Preparation. RS; Methodology, Supervision, Writing – Review & Editing. KM; Funding Acquisition, Conceptualisation, Supervision, Writing – Review & Editing. ES; Data Curation, Visualisation, Writing – Review & Editing.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)