Keywords
Genetic Algorithm, Maximum Likelihood Estimation, Nelder-Mead algorithm, Power Density, Weibull Distribution, Wind speed analysis
This article is included in the Artificial Intelligence and Machine Learning gateway.
Genetic Algorithm, Maximum Likelihood Estimation, Nelder-Mead algorithm, Power Density, Weibull Distribution, Wind speed analysis
We have included some references as per the suggestions of reviewers 1 and 2, in the reference section.
See the authors' detailed response to the review by El-ghalia Boudissa and HABBI FATIHA
See the authors' detailed response to the review by Olympia Roeva
In the continuous pursuit of optimization, where achieving the finest possible outcomes with utmost efficiency and accuracy is crucial, the fusion of diverse methodologies frequently yields superior solutions. Optimization algorithms are always looking for ways to improve efficiency and robustness, encouraging professionals and scholars to investigate novel ideas that happen to be mostly inspired by nature or mathematical concepts. Hybridization in optimization algorithms has garnered significant attention in recent years, offering a potent means to enhance efficacy and efficiency. Among these methodologies, Genetic Algorithms (GA) and the Nelder-Mead Simplex Algorithm (NM) emerge as prominent contenders, each boasting distinct advantages and applications. However, the fusion of these theories has recently proven to be an enticing strategy for enhancing optimization capabilities across various domains.
Inspired by evolution and natural selection, genetic algorithms operate by repeatedly developing a population of potential solutions over a series of generations. The concepts of genetic recombination and survival of the fittest are collectively mirrored by the selection, crossover, and mutation operators involved in this evolutionary process. GAs are a popular choice in various industries, including engineering, finance, and biology, because of their impressive effectiveness in solving complicated, high-dimensional optimization problems with non-linear and multimodal objective functions.
The Nelder-Mead Simplex Algorithm, on the other hand, provides a geometric method for repeatedly refining a simplex—a multi-dimensional geometric shape in the direction of the ideal solution. Its foundation is mathematical optimization. Nelder- Mead algorithms are especially well-suited for problems with few variables or smooth objective functions because, in contrast to GAs, which rely on a population-based approach, they operate on a single point or simplex at each iteration. Due to its ease of use, simplicity, and speedy convergence to local optima, it now has a deserving place within the optimization toolbox.
Genetic Algorithm (GA) based hybrids have emerged as powerful tools for optimization, combining GA’s global search capabilities with the local refinement strengths of other algorithms. These hybrids balance exploration and exploitation, allowing for efficient navigation of complex, high-dimensional search spaces. However, they are not without limitations. Challenges such as slow convergence rates, parameter sensitivity, and computational overhead remain prevalent. Furthermore, many existing studies lack comprehensive comparisons of hybrid methodologies and fail to explore their scalability and adaptability to diverse optimization problems. Gaps also persist in understanding the interplay between exploration and exploitation in these hybrids, leaving room for novel approaches that address these issues.
Genetic Algorithm (GA) based hybrid approaches have become a cornerstone in modern optimization research, combining GA’s global exploration abilities with various techniques to enhance local refinement. The following highlights some key advancements:
1. GA-Nelder–Mead (GA-NM):1
• Methodology: Integrates GA for its broad search capabilities with the Nelder–Mead (NM) simplex algorithm, which excels in refining solutions locally.
• Strengths: Offers improved convergence speeds and precision in parameter estimation, effectively balancing exploration and exploitation.
• Weaknesses: Struggles with scalability in higher dimensions and demands careful tuning of parameters for optimal performance.
2. GA-Harris Hawks Optimization (GA-HHO):2
• Methodology: Combines GA’s exploration strength with the Harris Hawks Optimization (HHO) method for exploiting promising regions.
• Strengths: Demonstrates exceptional performance in handling complex, multimodal optimization problems.
• Weaknesses: Computational demands increase significantly, and parameter sensitivity can affect robustness.
3. Real-Value Genetic Algorithm and Extended Nelder–Mead (RVGA- ENM):3
• Methodology: Employs RVGA for global searches and the Extended Nelder–Mead (ENM) algorithm for refining solutions, specifically applied to energy demand forecasting.
• Strengths: Achieves superior accuracy in predictions and effective refinement of solutions.
• Weaknesses: Highly reliant on the quality of the initial population and available training data.
4. GA-Tabu Search (GA-TS):4
• Methodology: Utilizes GA for broad search capabilities and Tabu Search (TS) for local optimization, designed for maintenance scheduling in cogeneration plants.
• Strengths: Efficiently handles scheduling challenges in complex systems.
• Weaknesses: Suffers from significant computational overhead as the problem size grows.
5. GA-Machine Learning (GA-ML):5
• Methodology: Integrates GA with machine learning (ML) models to optimize graph-related problems.
• Strengths: Provides adaptability and enhanced performance through insights derived from ML techniques.
• Weaknesses: Complexity increases due to the integration of ML, leading to greater computational requirements.
6. Harris Hawks-Nelder–Mead (HH-NM):6
7. GA-Artificial Neural Network (GA-ANN):7
• Methodology: Couples GA with Artificial Neural Networks (ANNs) for optimizing process parameters, particularly in plastic injection molding.
• Strengths: Effectively enhances manufacturing quality and process efficiency.
• Weaknesses: Dependence on ANN training data can limit its applicability to diverse scenarios.
8. GA-Simulated Annealing (GA-SA):8
• Methodology: Merges GA’s exploratory capabilities with Simulated Annealing’s (SA) temperature-based refinement strategy.
• Strengths: Efficiently escapes local optima and maintains diversity in the search process.
• Weaknesses: Computational costs are high, with slower convergence for high-dimensional tasks.
9. GA-Particle Swarm Optimization (GA-PSO):9
10. GA-Nelder-Mead (GA-NM):10
These developments illustrate the versatility and potential of GA hybrids in addressing a range of optimization challenges while emphasizing the need for careful parameter tuning and scalability enhancements. GANMA builds on this foundation by offering a structured, robust framework that addresses existing limitations.
Despite advancements in hybrid optimization algorithms, several key challenges persist. Many studies lack comprehensive comparisons, failing to evaluate scalability, convergence, and adaptability across diverse tasks. Additionally, the balance between global exploration and local exploitation remains under-explored, limiting efficiency in finding optimal solutions. Scalability issues are prominent, as many hybrids falter in high-dimensional problems, highlighting the need for robust methods capable of maintaining performance in complex spaces. Parameter sensitivity is another hurdle, with insufficient adaptive tuning mechanisms leading to inconsistent results. Furthermore, validation is often restricted to benchmark functions, offering limited insight into real world applicability where constraints and objectives are more complex. These gaps emphasize the need for innovative hybrids that address these issues while ensuring efficiency, scalability, and practical relevance.
Individually, both GA and NM have strengths and limits that make them appropriate for specific optimization scenarios. GA excels in global exploration, utilizing population variety to explore large solution spaces and avoid local optima. On the other hand, NM excels at local refinement, expertly traversing convex and smooth terrain to locate specific optima. The hybridization of GA with NMA addresses the limitation of GA in fine-tuning solutions near optima, at which NMA excels. This synergy improves the algorithm’s convergence speed and solution quality. Other researchers have primarily focused on individual optimization methods or hybridizations excluding GA and NMA, leaving a gap in fully exploiting the complementary strengths of these methods.
The GANMA method effectively addresses these gaps through its innovative design and balanced approach. By seamlessly integrating Genetic Algorithm (GA) and Nelder-Mead Algorithm (NM), GANMA achieves a robust balance between global exploration and local exploitation, enhancing its efficiency in diverse optimization tasks. Its structured framework allows for improved scalability, maintaining performance even in high-dimensional problem spaces. Additionally, GANMA incorporates adaptive mechanisms for parameter tuning, reducing sensitivity and ensuring consistent results across various scenarios. Unlike many existing hybrids, GANMA has been rigorously tested on both benchmark functions and real-world parameter estimation tasks, demonstrating its adaptability and robustness. These features position GANMA as a superior hybrid optimization method, addressing the limitations of existing approaches while offering practical solutions for complex, multidimensional challenges.
Many industries are interested in using the Nelder-Mead Simplex Algorithm (NM) working together with Genetic Algorithms (GA), including bio-informatics,11 finance,12,13 and engineering.14,15 Combining these methods provides a potent method of resolving challenging optimization issues in engineering, where designs are complicated and rules are demanding. Combining GA with NM helps improve portfolio management and risk assessment in the financial industry, where on-time and correct choices are essential. Similarly, hybrid algorithms speed up tasks like genomic analysis and drug discovery16,17 in bio-informatics, where understanding biology relies on smart computer methods. This article explores how combining NM and GA enhances both, highlighting how they work together to solve real-world issues. This paper has tested the GANMA algorithm on fifteen benchmark problems in three dimensions (10, 20, and 30). According to the results from the experiment, the suggested GANMA algorithm is a promising one that can quickly find the best or almost the best solution for most of the functions examined.
The remaining portion of the research study is structured as follows: Section 2 provides the fundamentals of the Genetic Algorithm and the Nelder-Mead simplex search. Section 3 discusses the proposed hybridized method, benchmark functions, and an alternative hybridization approach. The parameter setup for all methods and computational configurations are detailed in Section 4. Section 5 presents the results and discussion for benchmark functions, while Section 6 focuses on the Weibull distribution. Parameter estimation methods are described in Section 7, and Section 8 provides an analysis of Monte Carlo simulations and results. Two real-world wind speed datasets are analyzed in Section 9 to demonstrate the effectiveness of the proposed technique. Finally, Section 10 concludes the study with key observations.
A brief overview of GA, and NM have been described below.
Metaheuristic optimization methods like GA are higher-level frameworks designed to guide heuristic or local search procedures. In contrast, heuristic searches are problem-specific strategies for exploring the solution space. GA leverages metaheuristic principles to perform heuristic searches iteratively, balancing exploration and exploitation. So, we can say that GA is an approach to heuristic search. The ideas of the biological evolution of species serve as its inspiration. In contrast to traditional optimization methods, GA11,18 starts with a collection of starting solutions known as chromosomes.
Genetic algorithms (GAs) work by continually improving solutions based on their fitness, which measures how well they solve a problem. Unlike some traditional methods, GAs don’t assume anything about the problem, like whether it’s smooth or has just one best solution. Instead, they explore different possibilities to find good solutions, even in complex situations where there might be many equally good answers. GAs have been used successfully in many difficult optimization problems. They often work better than traditional methods, especially when there are multiple equally good solutions. This flexibility and ability to handle complex situations make GA a valuable tool for solving optimization problems in various fields.
Following is a summary of the GA stages in this study:
I. Initialization:
II. Evaluation:
III. Selection:
IV. Crossover (Recombination):
V. Mutation:
VI. Combining Populations:
VII. Sorting:
VIII. Elitism:
IX. Termination:
This approach with elitism helps maintain diversity in the population while ensuring that the best individuals are preserved across generations, ultimately leading to the discovery of better solutions in the optimization process. Real-coded genetic algorithms are suitable for optimization problems with continuous decision variables and offer advantages such as direct representation of real-valued solutions, robustness, and ability to handle high-dimensional search spaces.
The simplex search technique has been widely used for basic unconstrained minimization problems, such as nonlinear least squares, nonlinear simultaneous equations, and general function minimization.19 Originally proposed by Spendley, Hext, and Himsworth (1962),20 the method was later refined by Nelder and Mead (1965)21 to improve its efficiency and applicability.
The Nelder-Mead Algorithm (NMA) is selected for its simplicity and effectiveness in local solution refinement, making it a strong complement to the Genetic Algorithm’s (GA) global search capabilities. While a variety of optimization algorithms exist, NMA’s low computational overhead and reliability in small-dimensional spaces make it an efficient and practical choice for hybridization.
However, NMA’s reliance on simplex geometry and localized operations restricts its exploratory capacity, often causing it to converge prematurely to local optima in complex, multi-modal landscapes. Preliminary experiments (to be included) under these limitations highlight the necessity of GA’s global search to overcome such challenges.
The steps of the Nelder-Mead21,22 algorithm are summarized in as follows:
I. Initialization:
II. Ordering:
III. Centroid:
IV. Reflection:
V. Expansion:
VI. Contraction:
VII. Update simplex:
VIII. Termination:
The algorithm converges when the simplex becomes sufficiently small or when the function values at the vertices are close to each other. The choice of parameters α, γ, and ρ can significantly affect the performance of the algorithm and may need to be tuned based on the problem characteristics.
The combination of Genetic Algorithms (GA) with the Nelder-Mead simplex algorithm (NM) is driven by their supportive characteristics in both global exploration and local exploitation. GA is a population-based technique that effectively explores diverse sections of the search space, although fine-tuning solutions at local optima may provide issues. In contrast, it requires greater capacity for worldwide investigation. Combining both methods intends to take advantage of the characteristics of both algorithms, resulting in a more balanced and efficient optimization process. This hybridization method has the potential to improve convergence rates, solution quality, and robustness, making it a compelling choice for handling complicated optimization problems across several domains.
The suggested algorithm’s (GANMA) stages are summed up as follows:
I. Initialization:
II. Evaluation:
III. Genetic Algorithm (GA) Cycle:
• Selection: Select a parent from the current population. Selection techniques that are often used include rank-based, roulette wheel, and tournament selection.
• Crossover: Perform crossover to create offspring solutions. Since this is a real coded GA, a common method is the arithmetic crossover or simulated binary crossover.
• Mutation: Apply mutation operators to the offspring solutions. Here is where the Nelder-Mead simplex algorithm comes into play. After mutation, the simplex is formed around the mutated solutions.
• Elitism: Combine the initial population and offspring after mutation, then calculate the mean combination. Sort the combined population according to their fitness and keep the first half population while rejecting the other half.
• Replacement: Replace the initial population with the best half from the previous step.
IV. Nelder-Mead Simplex Algorithm:
• Define the simplex for the NM algorithm. This can be done by selecting a set of initial points around the best solution found by the GA so far. (The simplex in NMA is defined around the best GA solution to ensure the refinement starts near a promising region. This choice leverages GA’s exploration strength, as demonstrated in our results section.)
• Reflection: Take the centroid of the remaining points and reflect the worst point of the simplex.
• Expansion: Attempt to extend the simplex in that direction if the reflected point is superior to the second-worst but not superior to the greatest.
V. Termination:
VI. Output:
VII. Optimal:
NMA is applied to the best solution after reproduction and mutation in each iteration, not just the final solution. This strategy allows continuous refinement throughout the optimization process. By combining GA with NM in this way, you leverage the GA’s global exploration capability with the NM’s local refinement ability, potentially leading to improved convergence and robustness in optimization tasks.
GANMA stands out as a versatile hybrid algorithm capable of addressing a wide range of optimization problems, transcending the domain-specific focus of many existing hybrids. Its well-balanced framework effectively combines the global search power of Genetic Algorithms (GA) with the local refinement precision of the Nelder-Mead Algorithm (NMA), ensuring scalability, robustness, and efficiency. This synergy enables GANMA to overcome common challenges, such as parameter sensitivity and poor performance in high-dimensional or multimodal landscapes. Furthermore, GANMA’s structured approach is rigorously validated, making it a reliable solution for both theoretical benchmark functions and complex real-world applications.
The pseudo-code for the hybridization of the GA and Nelder-Mead simplex algorithm is presented in Algorithm 1.
1: Initialize GA parameters (size of population, rate of mutation, rate of crossover, number of generations)
2: Initial population
3: while termination condition is not met do
4: Evaluate each individual’s current level of fitness
5: Select parents (using tournament selection) for crossover
6: for each pair of parents do
7: Apply one-point crossover
8: Apply uniform mutation
9: end for
10: Combine initial population with offspring
11: Evaluate the fitness of the combined population
12: Sort the combined population by fitness
13: Keep the top half of the sorted population
14: Create a simplex from the best individuals (e.g., top 2)
15: Perform Nelder-Mead steps on the simplex:
16: - Reflection
17: - Expansion
18: - Contraction
19: - Shrink
20: Update the simplex
21: Replace the worst individuals with the simplex’s best individuals
22: Evaluate the fitness of the updated population
23: end while
24: From the final population, choose the best solution
25: Perform Nelder-Mead steps on the best solution
26: Find the optimal solution
The detailed flow diagram of the proposed algorithm is shown in Figure 1.
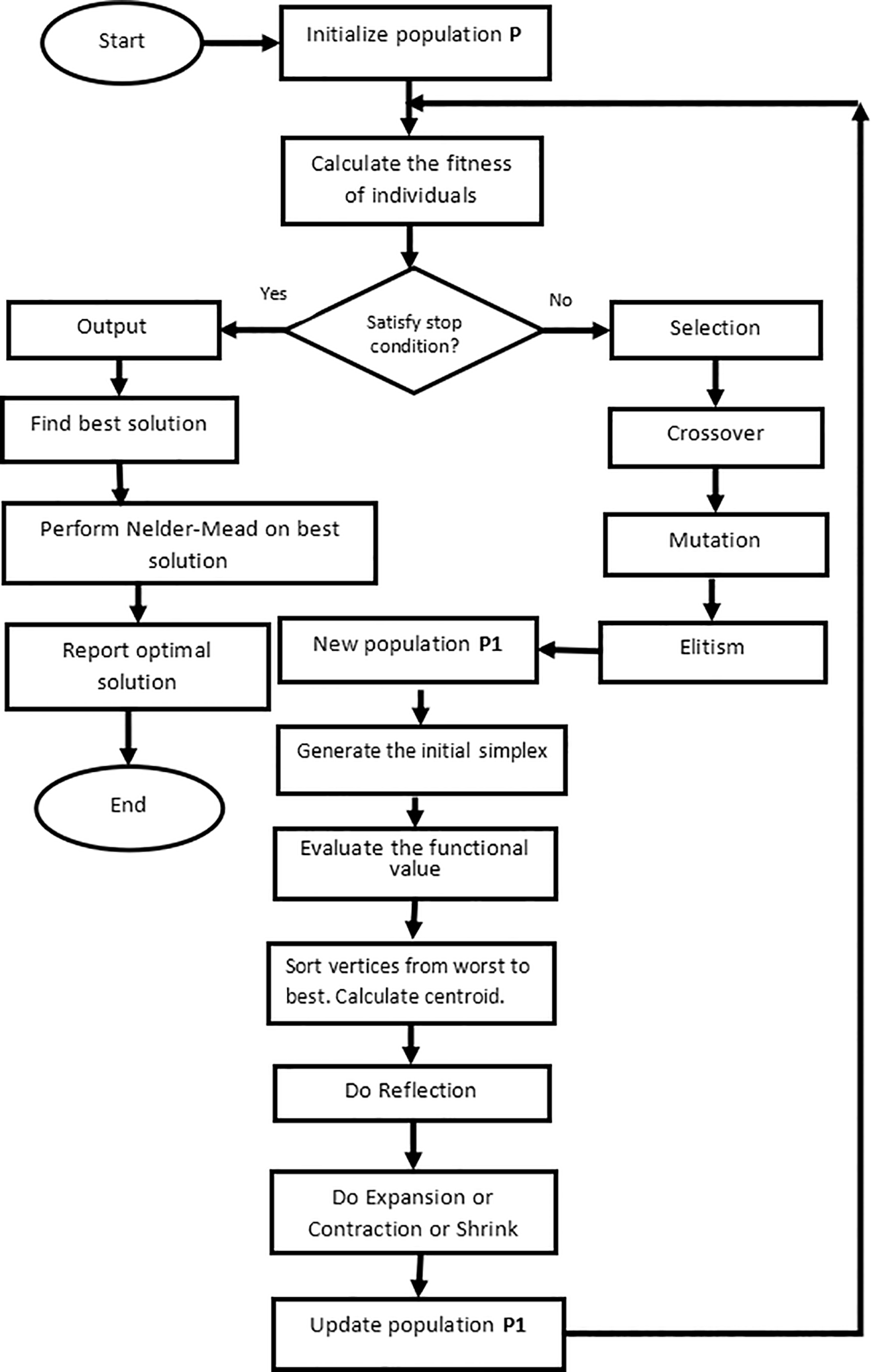
Here is an algorithm that combines a Genetic Algorithm (GA) with the Nelder-Mead Algorithm (NMA), where the GA first locates the interval containing the global minimum, and NMA refines the solution:
I. Initialize GA Population Generate an initial population of candidate solutions. Define the fitness function for evaluation.
II. Apply GA Operations Selection: Choose individuals based on their fitness. Crossover: Combine pairs of individuals to produce offspring. Mutation: Introduce random variations to maintain diversity.
III. Evaluate the Population Compute the fitness of each individual.
IV. Iterate GA Process Repeat the selection, crossover, mutation, and evaluation steps for a predefined number of generations or until convergence criteria are met.
V. Identify Promising Interval Extract the best individual(s) from the final GA population. Define the search interval around the best individual to locate the global minimum.
VI. Initialize NMA Use the best solution from GA as the starting point for NMA. Construct an initial simplex based on the chosen starting point.
VII. Apply NMA Iteratively refine the solution using simplex operations (reflection, expansion, contraction, and shrinkage). Stop when the termination criteria (e.g., small simplex size or convergence) are met.
VIII. Output Final Solution Return the refined solution as the global minimum estimate.
The pseudo-code for the hybridization of the GA and Nelder-Mead simplex algorithm is presented in Algorithm 2.
1: Initialize GA Population: Generate an initial population of candidate solutions.
Define the fitness function for evaluation.
2: while stopping criteria are not met do
3: Selection: Choose individuals based on their fitness.
4: Crossover: Combine pairs of individuals to produce offspring.
5: Mutation: Introduce random variations to maintain diversity.
6: Evaluate Population: Compute the fitness of each individual.
7: end while
8: Identify Promising Interval: Extract the best individual(s) from the final GA population and define the search interval around the best individual.
9: Initialize NMA: Use the best solution from GA as the starting point. Construct an initial simplex based on this starting point.
10: repeat
11: Apply Simplex Operations: Perform reflection, expansion, contraction, and shrinkage steps.
12: until termination criteria are met (e.g., small simplex size or convergence)
13: Output Final Solution: Return the refined solution as the global minimum estimate.
This study analyzes 15 benchmark test functions for simulation tests to fully investigate the feasibility as well as the effectiveness of GANMA. The 15 benchmark test functions (denoted as f1 to f15), cover different types. The unimodal functions (A function with a single peak or trough, making it straightforward to locate the global optimum) f1 through f4 are included in the first kind. Multimodal functions (A function with multiple peaks or troughs, presenting challenges in finding the global optimum due to local optima) f5 through f9 are included in the second category. Shifted unimodal and multimodal functions (Shifted Unimodal Function: an unimodal function whose peak or trough is relocated to a different position in the search space. Shifted Multimodal Function: A multimodal function with its peaks or troughs displaced, adding complexity by altering the relative positions of local and global optima), f10 - f15, are included in the third category. Table 1 displays the expressions, ranges, and global minimum values of the 15 test functions. The function’s dimensions (n) are 10, 20, and 30, in that order.
For problem dimensions 10, 20, and 30, the Genetic Algorithm (GA) was executed for 300, 400, and 600 generations, respectively, starting with a population of 100 individuals. Eighty percent of the population had a one-point crossover, which translates to a crossover rate of 0.8. With a mutation rate of 0.05, random mutation was employed. With a tournament size of five, parents were selected by tournament selection, and the top 10 percent of each generation’s top performers were preserved through an elitism technique.
The Nelder-Mead (NM) algorithm was initialized using the solutions provided by the GA. Standard transformation coefficients were applied, including a reflection coefficient (α) of 1, an expansion coefficient (γ) of 1.5, and both contraction (ρ) and shrinkage (σ) coefficients set to 0.5. The step size was maintained at 1.0. The algorithm’s simplex shrinking process concluded when the convergence tolerance reached 10 −6.
The hybrid process iterated through GA and NMA stages for 300, 400, and 600 generations for 10, 20, and 30 dimensions respectively. The stopping criteria were based on either the maximum number of iterations or fitness convergence, defined by a fitness tolerance of ϵ = 10 −5, ensuring early detection of optimal solutions. Table 1 displays the expressions, dimensions, ranges, and global minimum values of the fifteen benchmark test functions (denoted as f1 - f15).
The experiments were conducted in a consistent computational environment using Python 3.11. The hybrid GANMA algorithm was implemented from scratch, leveraging key Python libraries. NumPy handled arrays and matrix operations, Matplotlib was used for visualizing convergence and results, and SciPy supported NMA-based optimization. All tests were executed in a Jupyter Notebook environment to allow for easy experimentation and tuning. Each experiment was repeated 50 times to ensure statistical reliability.
Table 2 demonstrates how the performance of the GANMA, GA, and NM algorithms for dimensions (n) 10, 20, and 30 have been evaluated by comparing the mean value (Mean), standard deviation (Std), and best value (Best) of the final solutions for each benchmark function throughout 30 trials. The algorithm achieves the best optimization performance with the least standard deviation, optimal value, and average value closer to the theoretical ideal value. Any value less than 10 −6 in terms of mean, standard deviation, and best value will be regarded as zero. The ideal experimental outcomes are truncated.
The statistical results of GANMA’s performance on 15 benchmark functions with dimensions (n) of 10, 20, and 30 are shown in Table 2. It also contains the final solutions’ best (Best), mean (Mean), and standard deviation (Std) across a 30-run period for each benchmark function. All benchmark functions for unimodal functions (f1 - f4) have been solved in all three dimensions (10, 20, and 30). For the multimodal functions (f5 – f9), the solutions for f5 and f9 occur in 10, 20, and 30 dimensions, whereas the solutions for f6 and f7 in 10 and 20 dimensions are almost optimal. The standard deviation range is 1.62E − 13 ∼ 7.89E + 00, 1.45E − 11 ∼ 1.57E + 01, and 1.29E − 11 ∼ 2.95E + 01, respectively, while the mean value’s variations range in the 10, 20, and 30 dimensions is 3.18E − 13 ∼ 1.46E − 01, 1.11E − 11 ∼ 2.52E − 01, and 4.39E − 11 ∼ 2.84E + 00.
Six shifted test functions have been chosen for this study to validate the performance of GANMA: three shifted multimodal test functions, denoted as f13 to f15; and three shifted unimodal test functions, denoted as f10 to f12, Sphere, Elliptic, and Rosenbrock. On functions f10, f11, f12 (in 10, 20, and 30), and f15 (in 10), GANMA achieved optimum solutions; on functions f13 (in 10) and f14 (in 10, 20, and 30), the solutions are nearly optimal. Even while GA is outperformed by the solutions of f13 and f15 (in 20 and 30) in GANMA, the solutions are still far from the optimal ones. Furthermore, the Std that GANMA found on five test functions is not too high, suggesting that GANMA’s performance on shifted test functions is steady.
Therefore, for all unimodal functions (in 10, 20, and 30 dimensions), GANMA can obtain the global optimum. GANMA can identify outcomes with negligible deviations from the global optimal value for multimodal functions. Except for f5 and f9 in dimensions 10, 20, and 30, the results of f6, and f7 in dimensions 10 and 20 are quite near to the optimal value. The outcomes produced by GANMA algorithms for shifted unimodal and multimodal functions are optimal or extremely near-optimal in all functions for all three dimensions, except f13 and f15 (in 20 and 30). The benefits of the GANMA algorithm include excellent robustness, high convergence accuracy, and steady performance in all scenarios, whether they involve multimodal functions, unimodal functions, or shifting unimodal and multimodal functions. This is shown in Table 2 under the various numbers of iterations for the corresponding dimensions, which are 300, 400, and 600 for the dimensions 10, 20, and 30, respectively.
GANMA consistently outperforms GA-NMA, shown in Table 2, across various function categories, particularly in unimodal functions. For example, in f1 and f4, GANMA achieves near-zero fitness values across all dimensions, demonstrating its ability to efficiently refine solutions in smooth landscapes. Its lower standard deviations further indicate robust and stable convergence compared to GA-NMA, which struggles to maintain similar precision. In multimodal functions like f8, GANMA excels by navigating complex landscapes with multiple local optima, achieving superior results in higher dimensions (e.g., n = 30). Its hybrid structure effectively balances global exploration and local exploitation, reducing the risk of premature convergence. In contrast, GA-NMA often stagnates in local optima due to less dynamic exploration capabilities, leading to higher fitness values and greater variability.
For shifted unimodal functions such as f10, GANMA demonstrates its adaptability by achieving significantly lower best and mean fitness values, overcoming challenges introduced by displaced optima. Similarly, in shifted multimodal functions like f13 and f15, GANMA showcases its robustness by effectively handling complex, displaced landscapes. GANMA achieves accurate and dependable convergence by fine-tuning solutions even in challenging environments by utilizing Nelder-Mead for local refining. GA-NMA, however, struggles with the combined challenges of shifting and multimodal complexity, resulting in higher fitness values and inconsistent performance. Overall, GANMA’s adaptability and superior optimization capabilities make it a robust choice for diverse and challenging optimization problems.
To help further investigate the evolutionary behavior of various methods, the convergence curves of GANMA and GA for a few chosen benchmark functions are displayed in Figure 2, Figure 3, and Figure 4 for dimensions (n) = 10, 20, and 30, respectively. These graphs demonstrate the convergence behavior of methods that can help to analyze the evolutionary behavior of various algorithms. The y- and x-axes, respectively, represent the values of the fitness function and the number of iterations. The blue solid line shows the genetic algorithm (GA), while the suggested method GANMA is shown by the solid orange line.

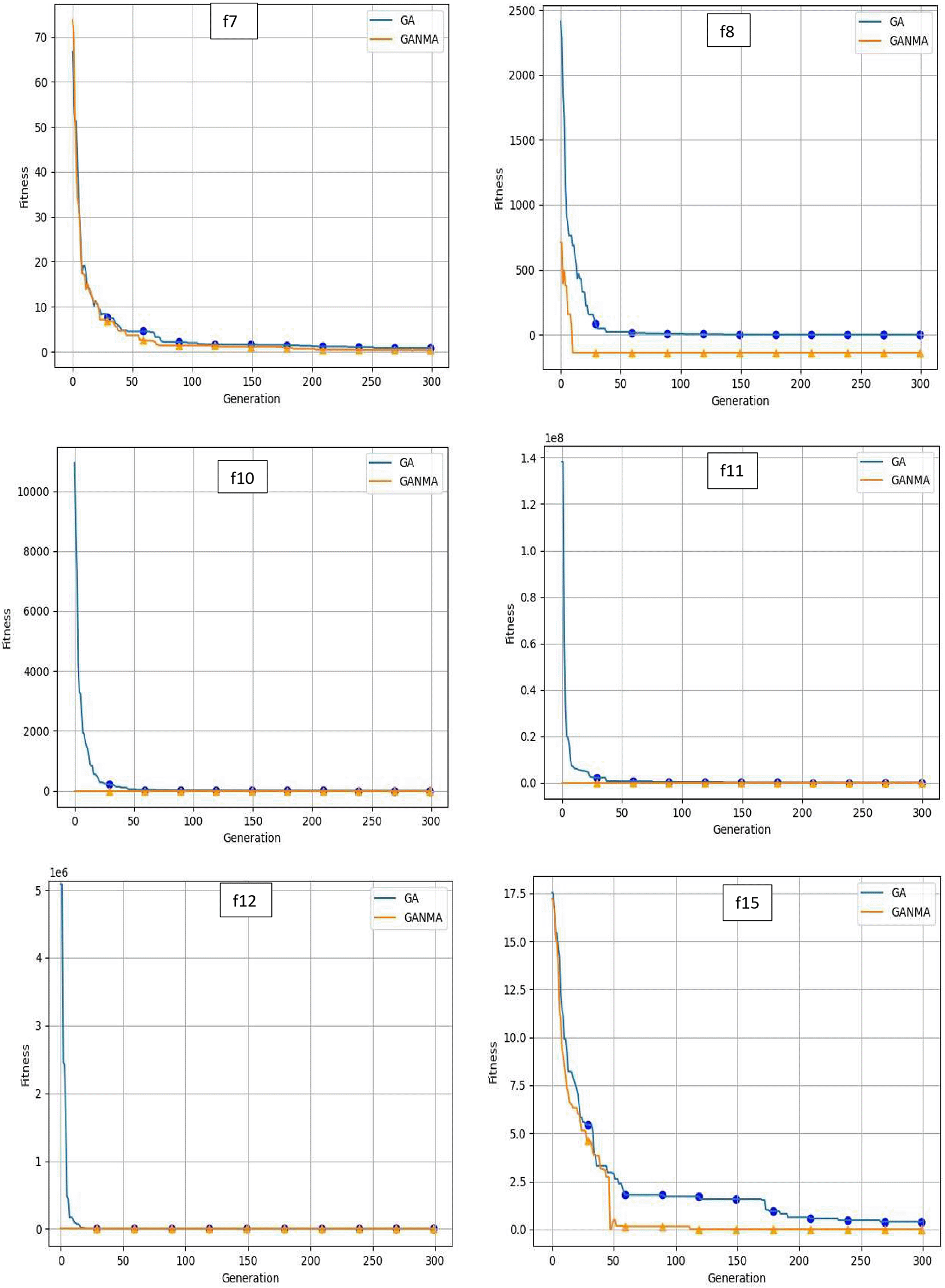
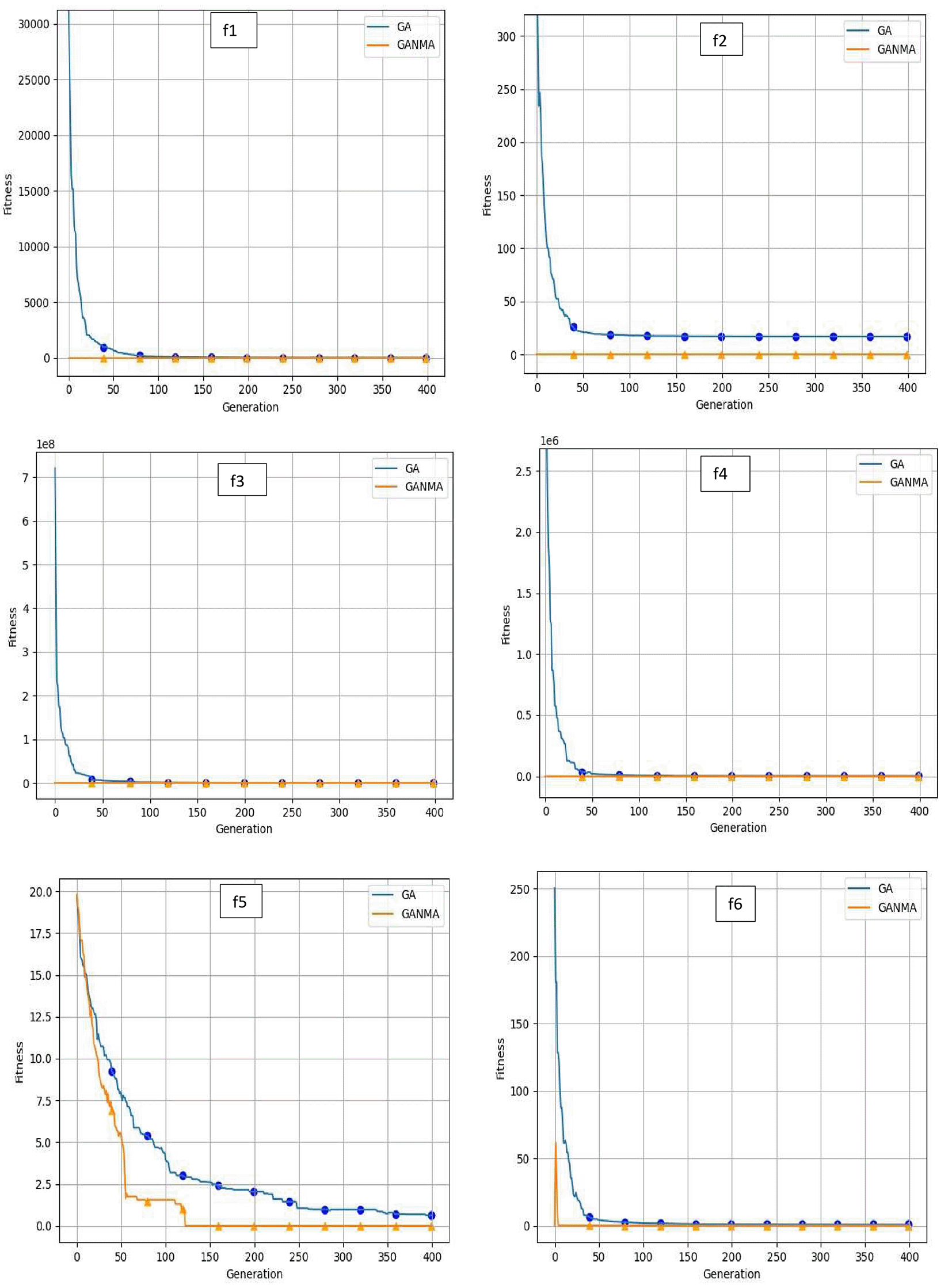
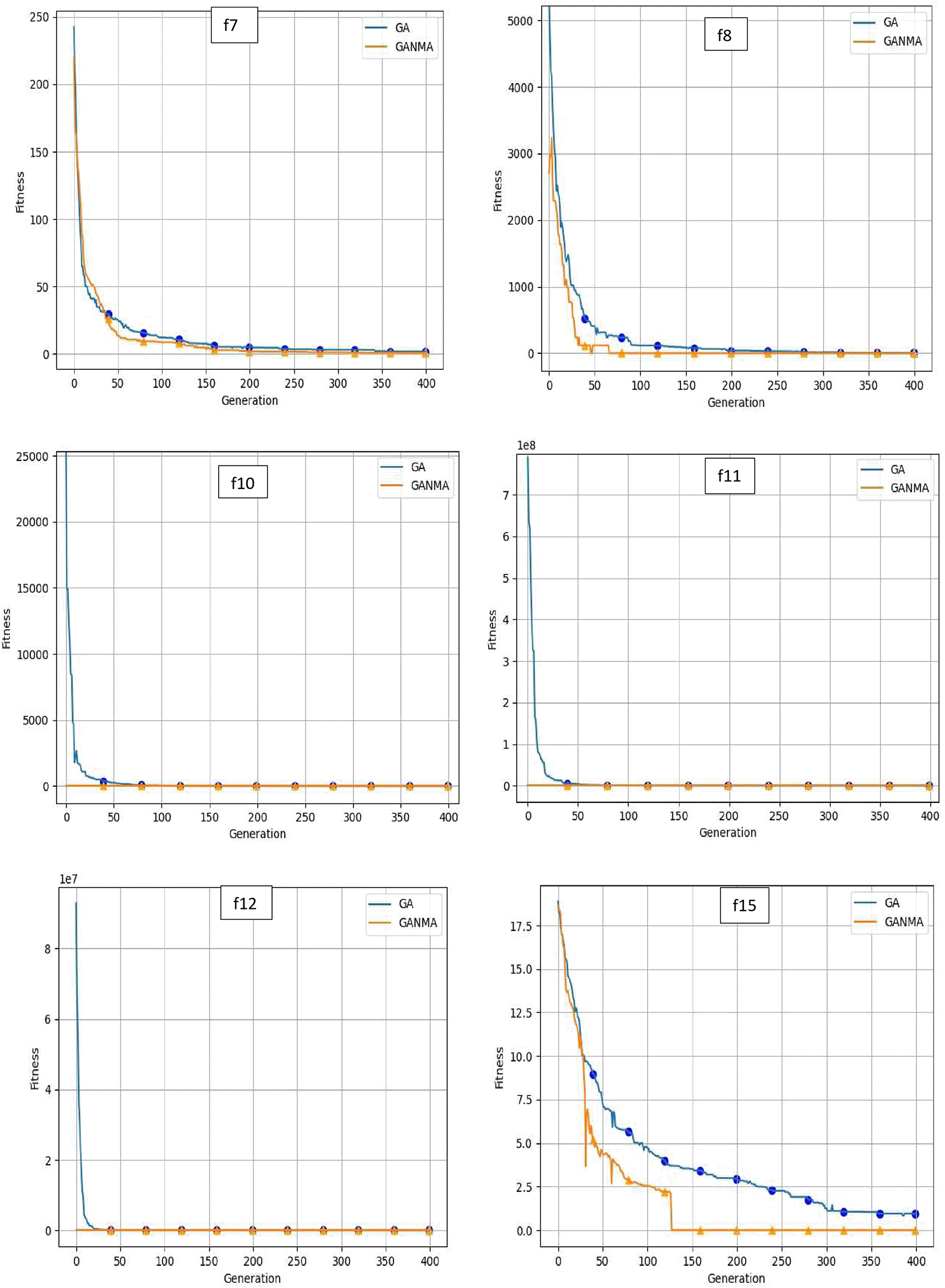
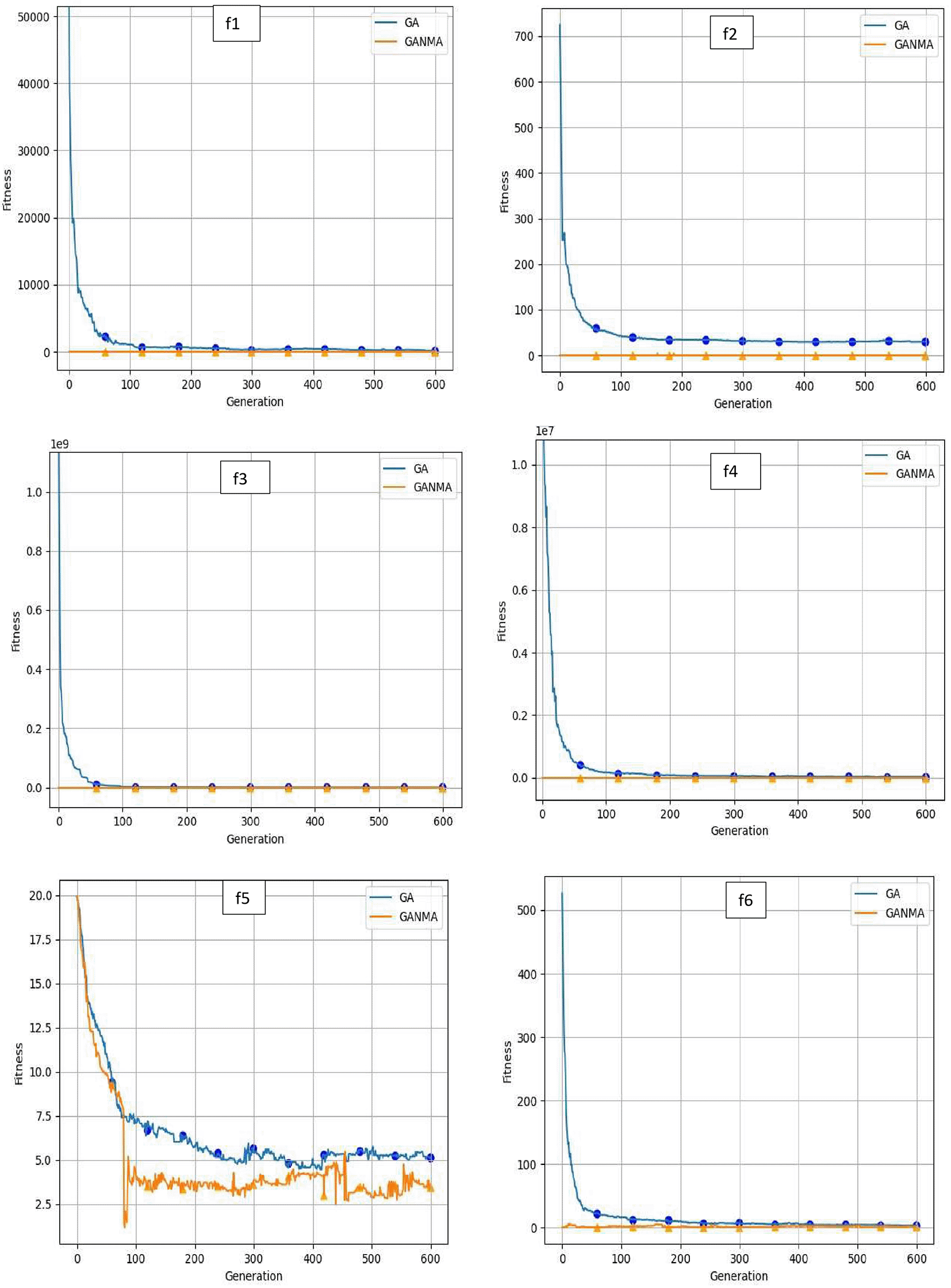

Until the ideal solution is discovered, GA shows a decreasing trend for unimodal functions like f1, f2, f3, and f4. In contrast, GANMA presents a straight line for all three dimensions (n = 10, 20, and 30). Similar to this, for multimodal functions other than f5 and f7 (in 30), there is a greater similarity between the global optimum solution and the GANMA optimal solution in f5, f7 (in 10, and 20), and f6, f8 (in 10, 20, and 30). As a result, of these two algorithms, the lowest optimum solution and the fastest rate of convergence are found through GANMA. The curves for shifted functions, except f15 (in 20 and 30), demonstrate how well the proposed method was able to obtain the ideal solution for other functions like f10, f11, and f12 (in 10, 20, and 30).
The dynamic character of the algorithm during its exploitation phases is reflected in the zigzag behavior shown in the figures. The main cause of this pattern is the optimization algorithms’ natural localized refinement processes. Local search methods cause local search methods cause local search methods cause these variations, such as the Nelder-Mead algorithm, which concentrates on enhancing solutions within a limited area of the search space. Furthermore, mutation processes in Genetic Algorithms (GA) add variation by slightly altering individual solutions. The observed zigzag patterns might result from these alterations, which can lead to brief departures from a smooth convergence trajectory. Even while these variations can seem erratic, they highlight how the exploration and exploitation stages actively interact, demonstrating the algorithm’s attempts to improve solutions and converge to the best result. Out of these two methods, GANMA yields the lowest optimum solution and has the fastest convergence rate than GA’s in both the multimodal and shifted functions.
It is demonstrated by analyzing the convergence curve and experimental findings that GANMA typically exhibits remarkable performance on the 15 test functions, with a fraction of proper convergence to the global optimal solution that is close to 90%. In terms of exploration and exploitation, GANMA performs better than GA and the NM algorithm. Consequently, GANMA achieves lower fitness values, less variability, and more steady convergence than GA-NMA, GA, and NM. GANMA is a flexible and dependable hybrid algorithm because of its capacity to adjust to optimization problems ranging from simple unimodal functions to intricate shifting multimodal ones. This robustness highlights its advantage in solving diverse real-world optimization problems.
The Weibull distribution is a probability distribution that is often used in reliability and survival research. Weibull et al.23 had shown that the Weibull distribution fit many different datasets and offered satisfactory results, even for small samples. The Weibull distribution, known for its flexibility in modeling various failure and survival scenarios, is defined by two parameters: the shape (β) and scale (η) parameters. In some cases, a location (α) parameter is added to create a three-parameter Weibull distribution, allowing for greater flexibility in fitting data with location shifts. The three-parameter probability density function (pdf ) will have only two parameters24 when the location parameter (α) is equal to zero. Due to the fact that no failure may occur before or after the time is zero, the two Weibull parameters are frequently utilized in failure analysis.25
Weibull parameter estimation employs a variety of methods. Method of Moments (MOM), the maximum likelihood (ML) approach, and modified maximum likelihood (MML) methods were all used by Seguro and Lambert.26 They discovered that the time series data sets are more suited for the ML approach. They advised utilizing the MML technique for data sets that were formatted as frequency distributions. The least squares approach, the ML method, and the MML method were contrasted by Akgül et al.27 ML was shown to be the most effective approach overall, but they also noted that MML and ML are equally effective for big data sets, despite MML’s lower computational complexity. The ML technique was used in the studies of Kollu et al.28 and Akpnar and Akpnar29 to estimate the Weibull parameters. Teimouri et al.30 investigated the MoM using their proposed L-moment estimator, the ML approach, the logarithmic moment method, and the percentile method. They discovered that the ML method and their suggested approach are the most effective estimators. The power density approach was proposed by Akda and Dinler.31 They concluded that it outperformed popular techniques like MoM and ML techniques. After evaluating five different methods for approximating the Weibull distribution, Saleh et al.32 recommended the mean wind speed methodology and the ML method. Azad and colleagues33 discovered that the MoM and ML techniques were more effective than other approaches.
Considering the Weibull distribution has a nonlinear log-likelihood function and is compatible with numerical optimization techniques like Newton-Raphson (NR) and Nelder-Mead (NM), previous studies have often used MLE approaches for parameterizing the Weibull distribution.34,35 However, the effectiveness of these iterative methods heavily relies on the initial value chosen.36 In a departure from traditional approaches, this study employs Genetic Algorithms (GAs) as a heuristic search method, considering a set of solutions within the search space rather than individual points, to address the initial value problem in Weibull parameter Maximum Likelihood Estimation.37,38 GAs have been successfully applied in various optimization contexts, ranging from optimizing mixing parameters for high-performance concrete to signal control optimization.39 Parameterization of distributions such as the skew-normal distribution,40 nonlinear regression,41 and negative binomial gamma mixed distribution42 have all been applied in previous works.
Notably, Thomas et al.43 pioneered the use of GA for Weibull distribution parameter estimation in the context of breakdown periods of insulating fluid data, achieving performance comparable to traditional methods based on maximizing the log-likelihood function. Furthermore, hybrid approaches combining GA with other methods, such as the improved Nelder-Mead algorithm for controlling synchronous generator output voltage,36 and memetic algorithms applied to parameter identification in electrical engineering,44 underscore the versatility of heuristic and hybrid optimization techniques in solving complex problems. In addition, improved Nelder-Mead techniques have been used for synchronous generator output voltage control, as in the efforts of Boudissa et al.45 and Fatiha et al.46 In reliability analysis, Weibull parameter estimation is an important problem, with recent developments employing successive approximation47 and techniques specific to zero-failure data situations,48 enhancing estimation efficiency in small sample situations.
A versatile continuous probability distribution, the Weibull distribution is frequently used in survival analysis and reliability engineering. It is characterized by its ability to model the distribution of time until an event occurs. Named after Wallodi Weibull, who described it in the 1950s, the distribution is flexible and can take different shapes depending on its parameters. The shape parameter affects the structure of the Weibull distribution curve resulting in whether the distribution appears to be a Rayleigh distribution (β = 2), an exponential distribution (β = 1), or another shape. The scale parameter determines the distribution’s scale or size. Together, these factors enable the Weibull distribution to simulate a wide range of events with varying shapes and sizes.
The following is the Weibull two-parameter distribution’s probability density function (PDF):
The following represents the Weibull distribution’s cumulative distribution function (or CDF):
Probability density and cumulative distribution plots for some different parameter values are given in Figure 5.

Two-Parameter Weibull is Commonly applied in reliability engineering for modeling time until the failure of components. Whereas, Three-Parameter Weibull is Useful when considering scenarios where the event initiation may not be at zero, such as analyzing the time until an event occurs after a certain threshold.
Estimating the parameters of the Weibull distribution poses a significant challenge due to the intricacies involved in utilizing sample data for accurate estimation. Parameter estimation involves the process of determining the distribution’s parameters using available sample data, aiming to derive optimal values that provide meaningful insights into the underlying data. Making incorrect parameter choices can lead to misleading results, underscoring the importance of analyzing and selecting appropriate estimation techniques for accurate modelling. Therefore, a thorough evaluation of estimation methods is essential to determine the most suitable approach for a given dataset and analysis context.
The statistical method known as Maximum Likelihood Estimation (MLE) is used to estimate Weibull parameters by maximizing the likelihood function, which determines how well the distribution fits the observed data. MLE is known for its efficiency, but its optimization can be complex due to non-linear equations and numerical stability issues. The PDF of the Weibull distribution is given by Equation (6). Given a sample x1, x2, … xn from a Weibull distribution, the likelihood function is given by:
The Weibull distribution’s log-likelihood function is as follows:
The log-likelihood function is differentiated for β and η, the derivatives are set to zero, and the resultant system of equations is solved to get the MLE.
By eliminating α from the above equations and simplifying the equations we get,
Eqn. (13) may be used to calculate the estimate . However, because of Eqn. (14) did not give an analytical solution, the estimate must be calculated numerically. This is possible by using the optimization strategy. The Nelder-Mead, Newton Rapson, simulated annealing, or GA algorithms can all be used to solve the nonlinear function that the ML estimator of the shape parameter β contains. In this study, the suggested method, GA, and NM were all used to optimize the log-likelihood function. Nelder-Mead is a powerful algorithm that converges quickly, but its performance is dependent on the initial guess. As a result, we took into account the GA while maximizing the Weibull distribution’s loglikelihood function. Eqn. (10) is considered a fitness function for GA and NM methods.
Below the proposed method on MLE of Weibull Distribution has been described briefly.
7.1.1 Proposed method
(Genetic and Nelder -Mead Algorithm (GANMA))
To improve the precision and reliability of parameter estimation, we proposed a hybrid approach GANMA that integrates the GA and the NM method with MLE for two-parameter Weibull distributions. The GA aids in exploring the parameter space globally, generating diverse candidate solutions, while the NM fine-tunes these solutions through local search, aiming for optimal parameter estimates. To the best of our knowledge, this is the first instance where the GANMA is being utilized to estimate the Weibull distribution’s parameters.
The steps of the proposed method in this study are summarized as follows:
Step 1: Problem Formulation - We aim to find the MLE parameters β (shape) and η (scale) for a Weibull distribution.
Step 2: Genetic Algorithm (GA) Phase -
• Generate an initial population (P) of possible solutions. For the Weibull distribution, each solution indicates a collection of parameters (β, η).
• Define the fitness function f(β, η) that measures the goodness of fit between the observed data and the Weibull distribution with the given parameters. A suitable fitness function could be the log-likelihood shown in Equation 10.
• Select individuals within the population according to their fitness by using a selection process (tournament selection). Higher fitness levels increase the probability of selection.
• Apply crossover operations (one-point crossover) to pairs of selected individuals to create new candidate solutions.
• Introduce small random changes (mutations) to the parameters of some individuals to add diversity to the population.
Step 3: Nelder-Mead Algorithm (NM) Phase -
• Take the best individual from the final population of the GA as an initial guess for the parameters (β1, η1).
• Define the log-likelihood function L(β, η) for the Weibull distribution shown in Equation 5.
• To minimize the log-likelihood function and improve the parameter estimations (i.e., reflection, expansion, contraction, and shrinkage), apply the Nelder-Mead method.
• Repeat the iterations until convergence criteria are met (e.g., small changes in parameters or a maximum number of iterations).
Step 4: Repeat the selection, crossover, and mutation steps for several generations until convergence is met (i.e. end of GA phase).
Step 5: Apply the NM method to the best GA solution once again after the GA phase.
Step 6: Result - The final parameters ( , ) obtained from the Nelder-Mead optimization represent the Maximum Likelihood Estimates (MLE) for the Weibull distribution.
The two-parameter Weibull distribution parameter estimation methods were investigated using a Monte Carlo simulation. The scale parameter was set to 1, while the other shape parameters were set to 0.5, 1, 3, and 6. The simulation has been repeated 1000 times for sample sizes of 20, 100, and 500 respectively. With a population size of 100, the GA and GANMA have corresponding crossover and mutation rates of 0.1 and 0.8. The parameters that are used to compare the goodness-of-fit of different parameter estimating methods are mean absolute error (MAE) and bias. For the parameters β (shape) and η (scale), MAE and bias are computed using the formula provided by:
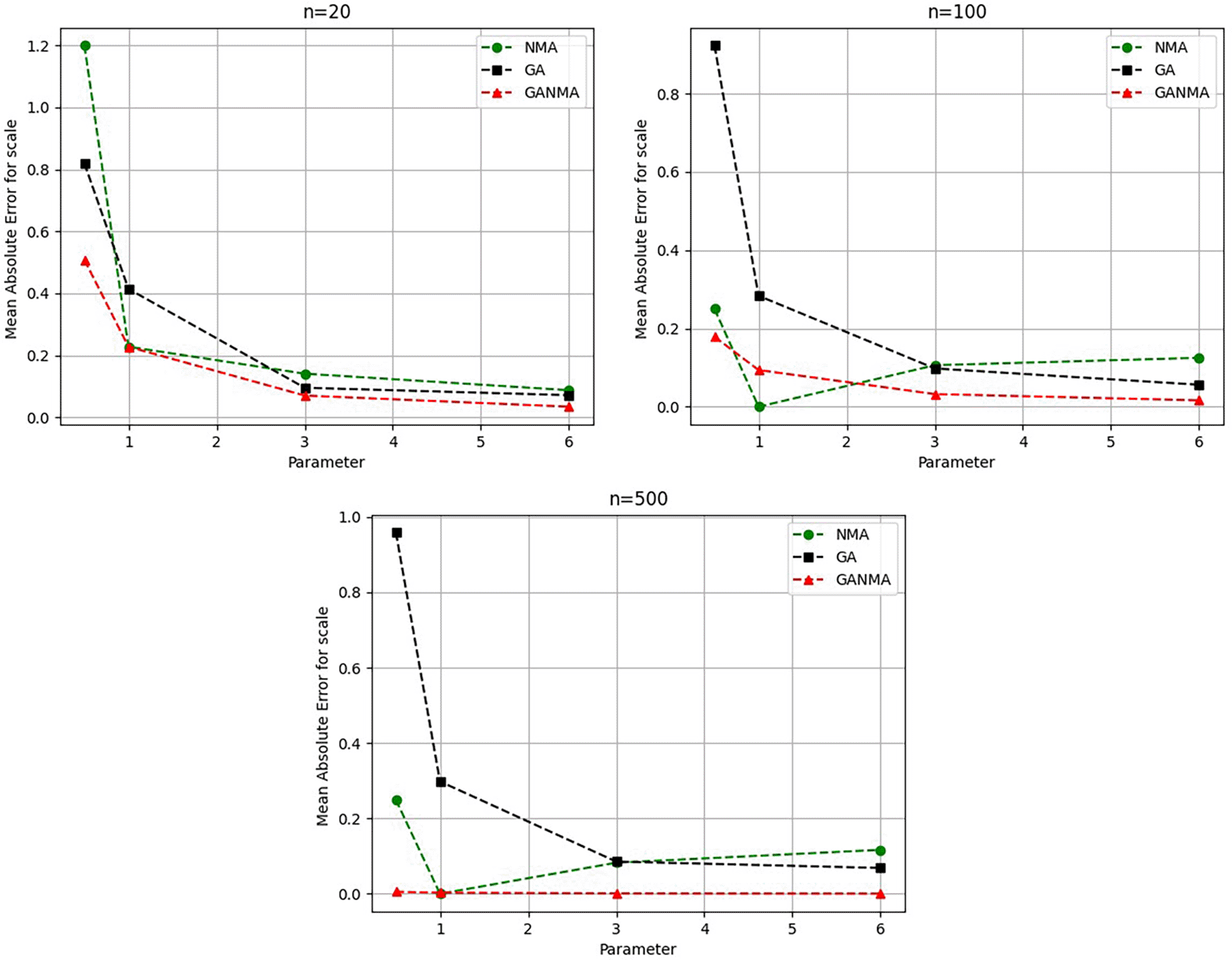
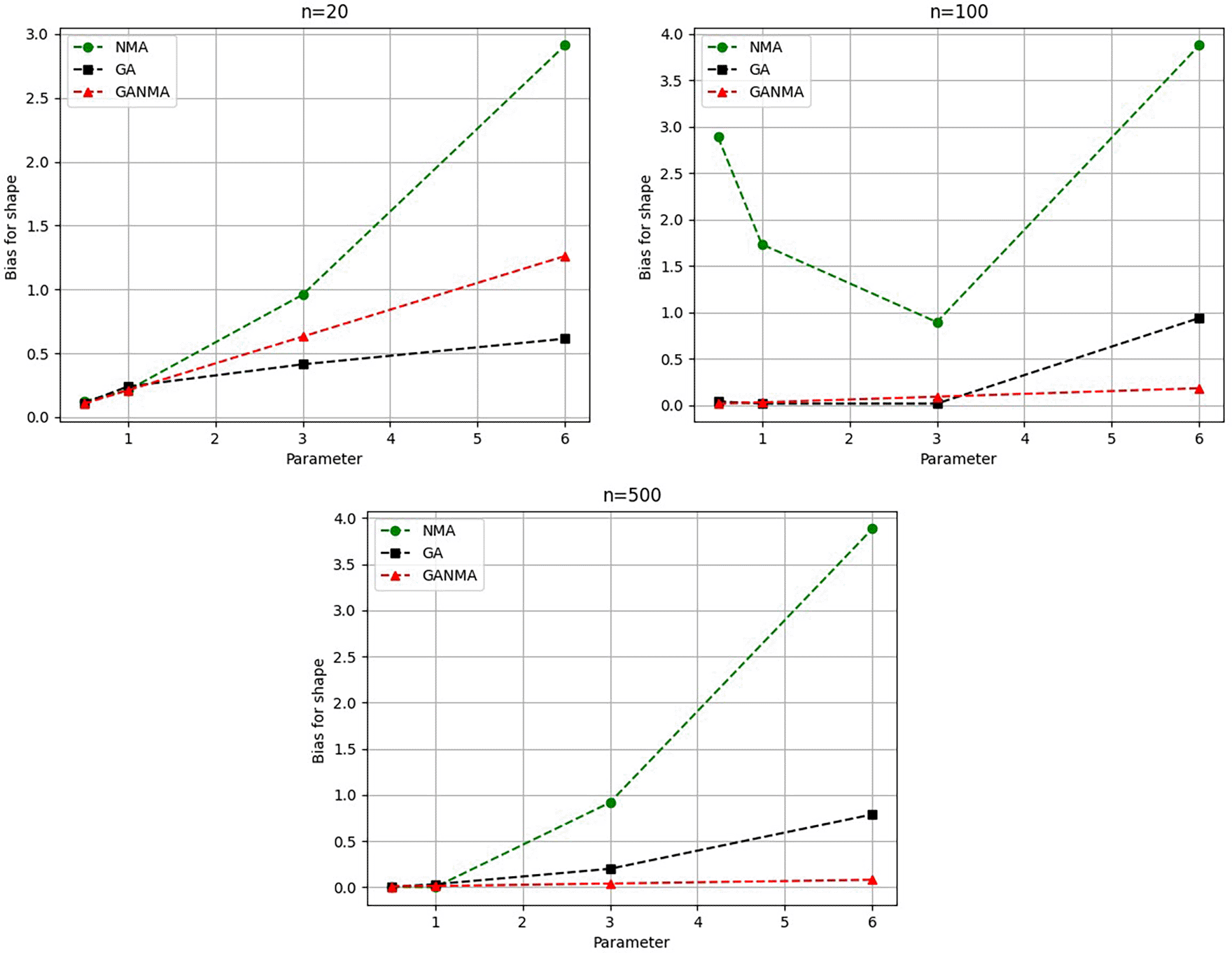
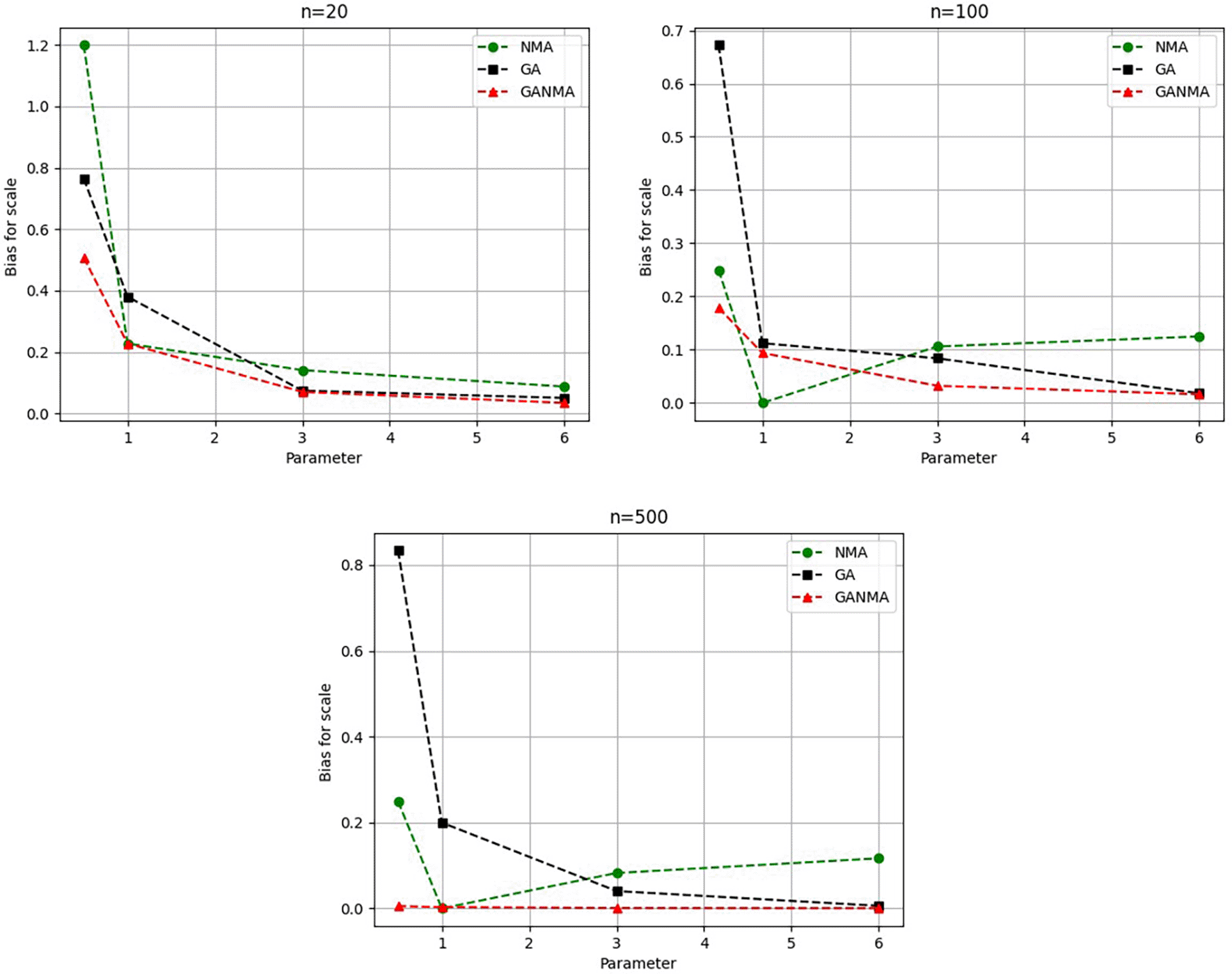
Greater efficiency is implied by lower absolute values of the bias and MAE. For various data sizes and shape parameters, Tables 3-5 display the parameter estimates, bias, and MAE for each parameter estimation method. The results of the simulation demonstrate that the GANMA approach performed better than NM and GA when estimating shape and scale parameters based on MAE and bias criteria. The best results are highlighted in bold.
Figures 6-8 illustrate the outcome across various shape parameters while keeping the scale parameter constant—as well as various data sizes by plotting the convergence graph of the PDF of Weibull parameters and the PDF of MLE of parameters using NM, GA, and GANMA. The solid black line depicts the PDF of parameters (β, η), whilst the usual genetic algorithm is illustrated by the solid green line, the yellow solid line shows the Weibull PDF using NM, and the suggested method GANMA is shown by the solid red line. It has been found that parameter estimation using the suggested technique converges with the original PDF as the shape parameter and data size increase. GANMA, the suggested algorithm, performs better than GA and NM in all types of situations.
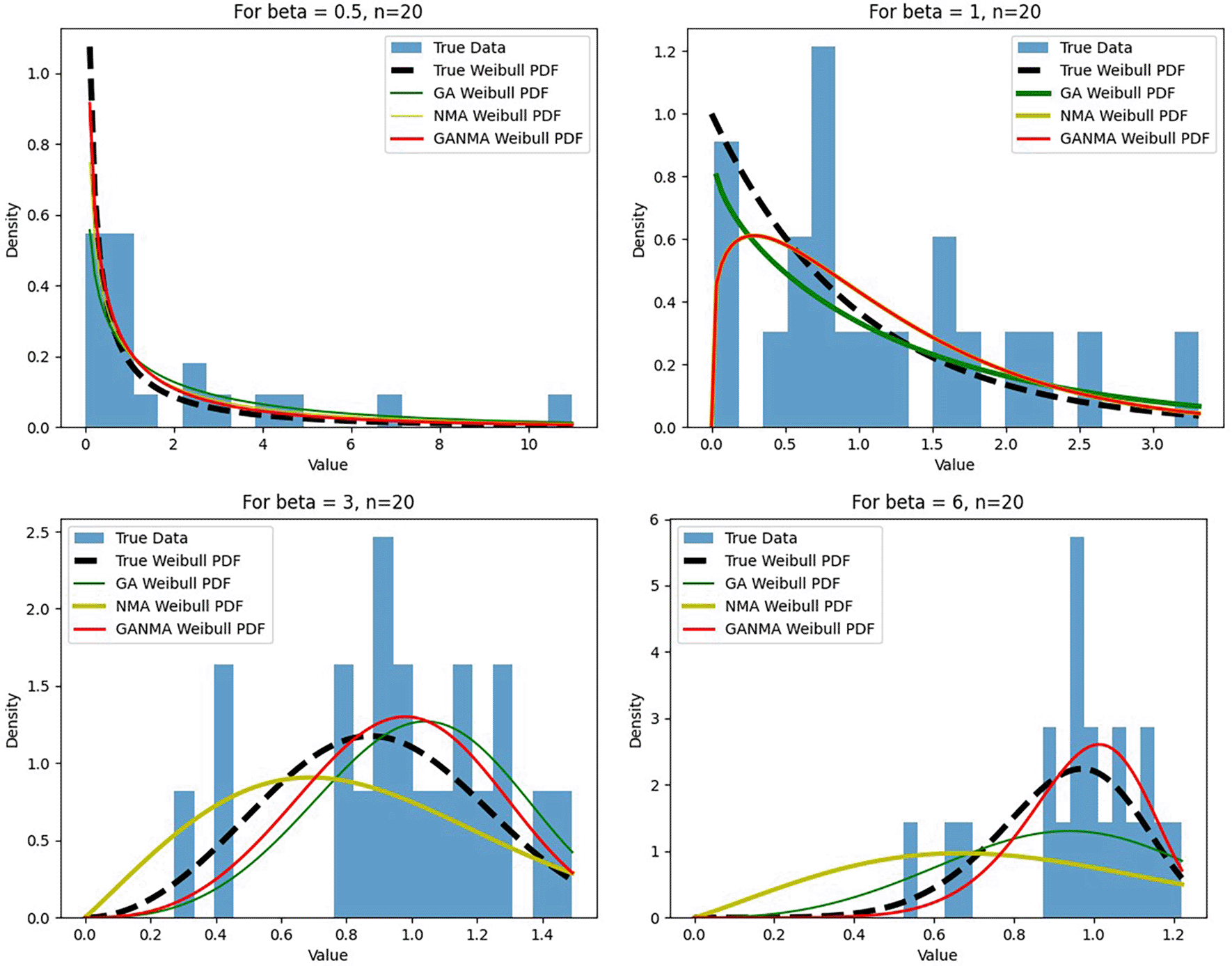
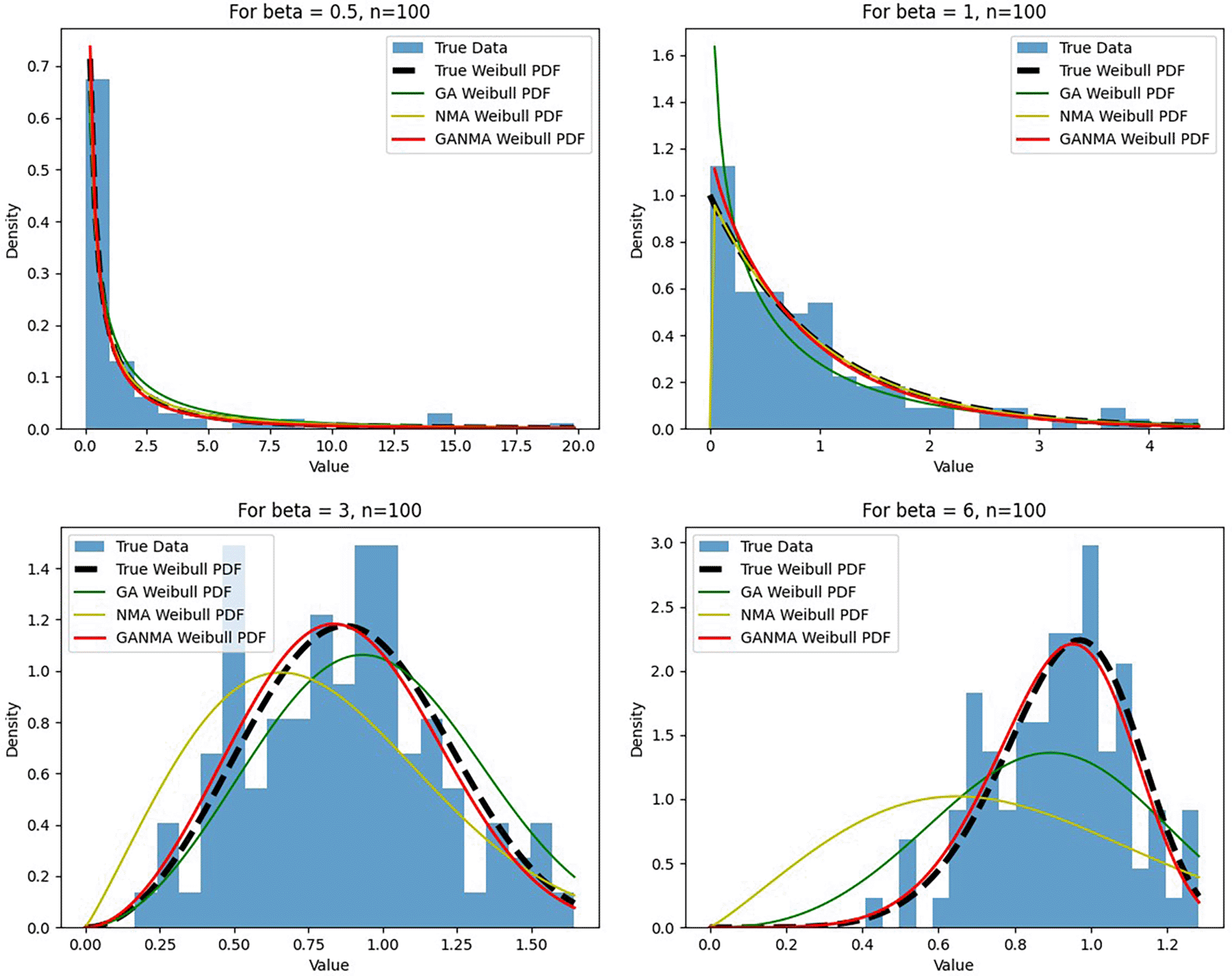
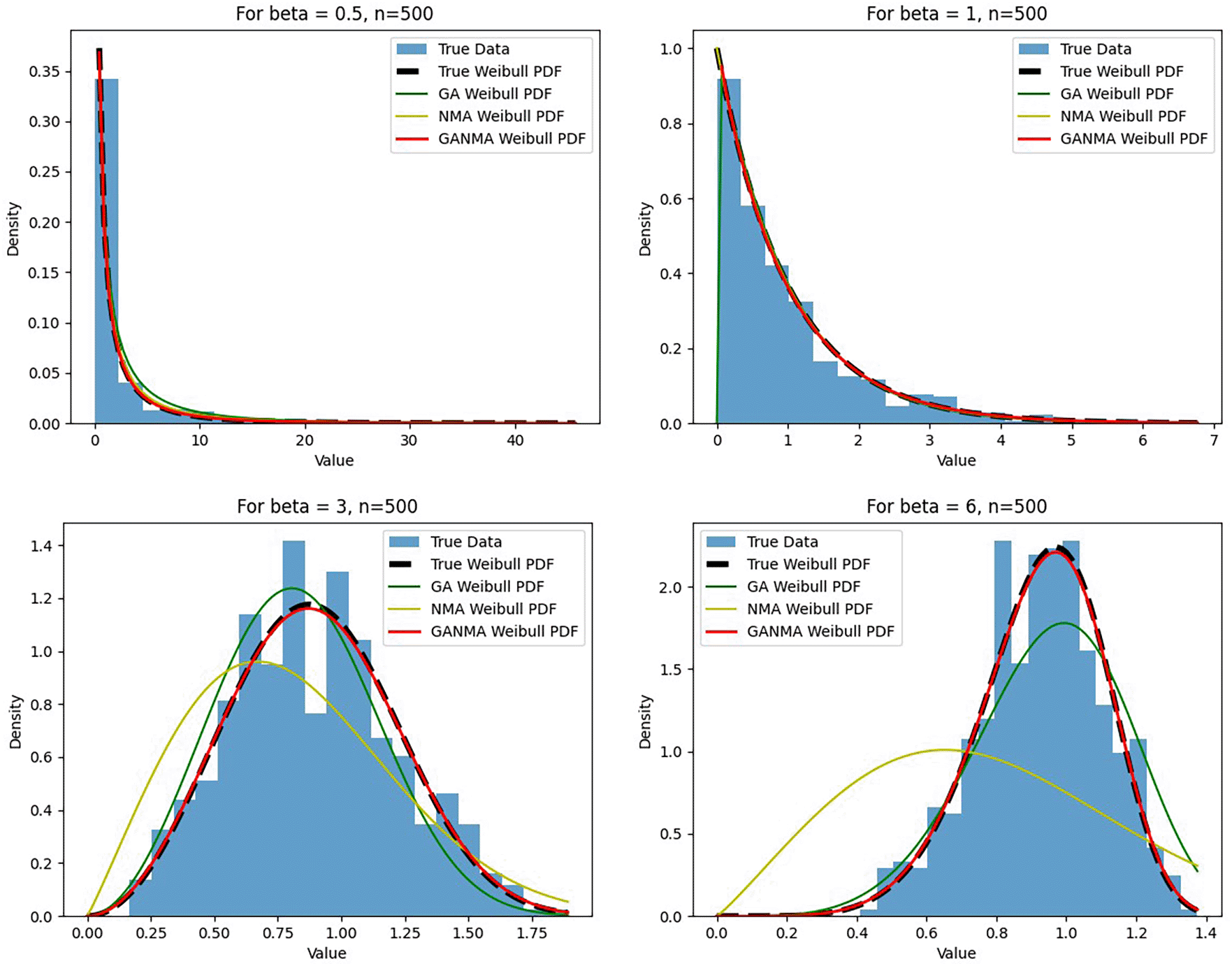
Based on MAE and bias criteria, the simulation results demonstrate that the GANMA technique outperformed NM and GA in the estimation of shape and scale parameters. In each simulated scenario, the GANMA technique yielded the best shape parameter efficiency in terms of bias and MAE for sample sizes of 20, 100, and 500 respectively.
Throughout almost every simulated scenario, GANMA achieved the maximum efficiency in the estimate of scale parameters for sample sizes of 20, 100, and 500, based on at least one decision criterion. By analyzing MAE and bias for each simulation scenario, GANMA proved to be the most effective approach for the data size 20. For small, moderate, and high sample sizes, GANMA is a fairly effective strategy overall. Additionally shown in Figures 9-12 are the absolute values of the biases and the MAE.
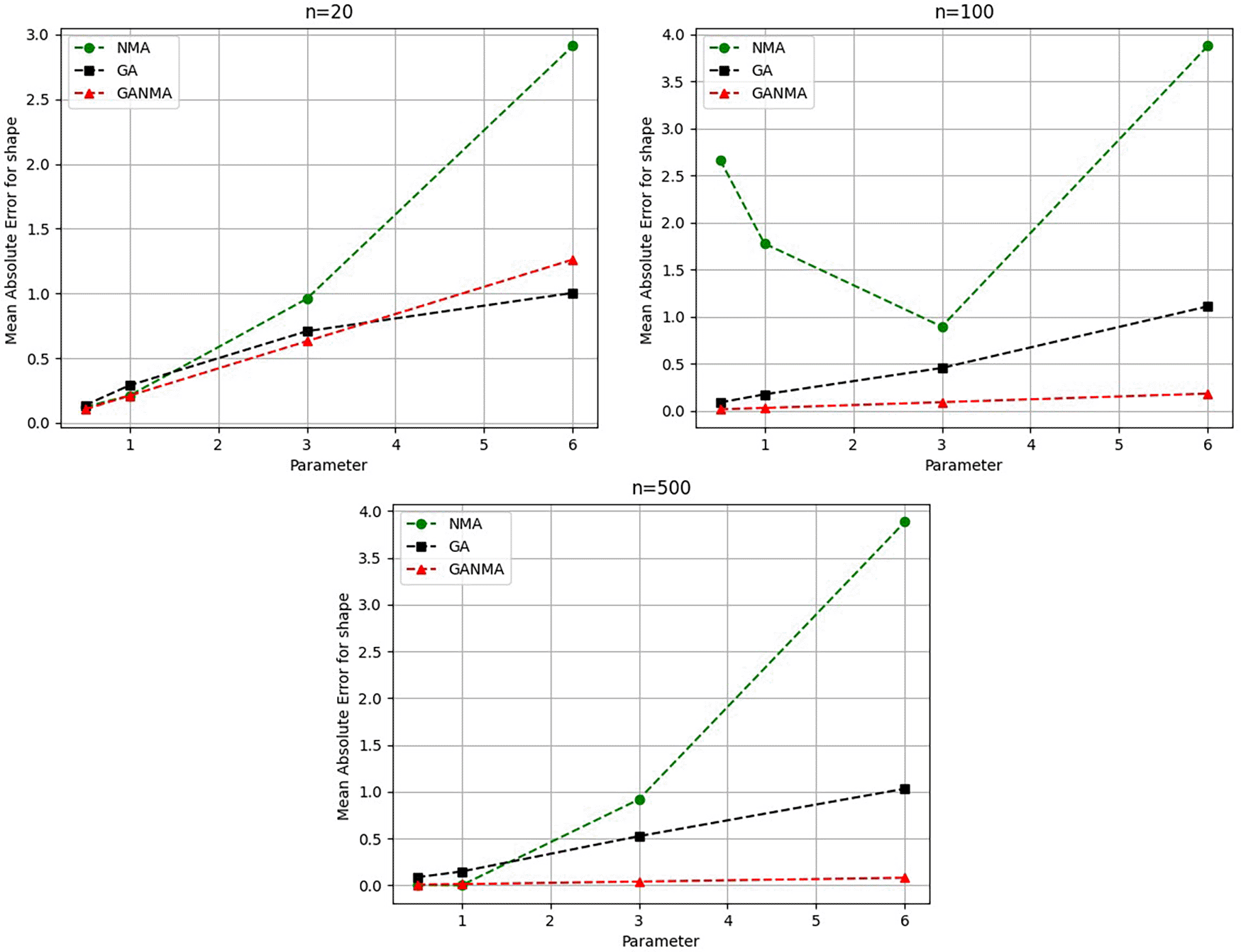
The MAE values for the shape parameter β are shown in Figure 9. In every simulated scenario, GANMA outperformed NM and GA in terms of efficiency. The second-best approach is NM. An increase in sample size resulted in lower MAE values. On the other hand, MAE values increased along with an increase in the form parameter value.
The scale parameter η’s MAE values are displayed in Figure 10. For sample sizes of 20, 100, and 500, GANMA proved to be the most effective approach. When the shape parameter is set to a higher value, the MAE values drop. Likewise, as the sample size is raised, the MAE values drop.
The shape parameter β’s absolute bias value is displayed in Figure 11. The most efficient results were obtained using GANMA. NM outperformed GA on some occasions. As with MAE values, larger sample sizes resulted in lower absolute bias levels. Increasing the parameter value resulted in higher absolute bias levels.
The absolute bias for the scale parameter η is shown in Figure 12. Most of the time, GANMA outperformed other methods in terms of efficiency. The second-best approach is NM. Increasing the shape parameter and sample size leads to lower absolute bias levels.
The decrease in fossil fuel supplies and their lack of reliability in meeting future energy demands have made renewable energy a hot topic for academics. Wind is one of the main sources of renewable energy, and wind speed modeling has been studied in great detail. In wind power applications, the most popular Weibull distribution is two parameters. It has been discovered that this PDF is correct for the majority of wind regimes observed in nature, is easy to use, and is adaptable. In several research, it has been noted that the wind speed data cannot be adequately represented for specific applications, including those with bimodal distributions, short time horizons, low and high wind speeds, and with a high frequency of nulls.49–51 The given equation may be used to determine the probability density function.
Power density
Power density in wind speed analysis refers to the amount of power that can be obtained from the wind per unit area. This statistic is critical when evaluating the feasibility and potential viability of wind energy projects since it quantifies the energy available from the wind at a given place. The power density (PD) may be easily calculated using the following equation once β and η have been established.
In this challenge, two real-world data sets have been used to examine wind-speed analysis. The very first set of data came from the seas surrounding the Maluku Islands and Sulawesi. The data under analysis were gathered by the satellite Quikscat, which measured the ocean wind 10 meters above sea level using a scatterometer. The measurement’s horizontal and vertical spatial resolution is 0.25°earth grid. The information from the January measurement point at latitude 116° and longitude 85.5° is included in the accessible data.52
Tarama Island and Iriomote Island, which are close to northern Taiwan, had their wind speeds recorded in the second data set. At Iriomotejima Meteorological Station, the maximum daily wind speed and direction were recorded in March 2012.53
The Kolmogorov-Smirnov (K-S) test is a nonparametric statistical test used to compare two distributions. The K-S test calculates the maximum absolute difference between the empirical cumulative distribution functions (ECDFs) of the distributions being compared, providing a test statistic (D). A p-value derived from this statistic indicates the significance of the difference, helping in goodness-of-fit testing, comparing sample distributions, and model validation without assuming any specific distribution for the data.
The statistical confirmation that the monthly data sets come from the Weibull distribution can be obtained by doing the K-S test separately for each data set. The most significant difference between the theoretical distribution, SN(x), and the observed distribution, F0(x), is the K-S test statistic.54
Monthly distributions from the Weibull distribution are selected for further investigation following the K-S test ), which indicates the probability of observing a discrepancy as large as the one computed if the two distributions were the same.
Results across shape and scale parameters were obtained by plotting the convergence graph between the PDF and CDF of MLE of parameters using NM, GA, and GANMA, as shown in Figures 13 and 14. The solid green line and dotted green line represent the PDF and CDF of the standard genetic algorithm, the yellow solid line, and dotted yellow line represent the Weibull PDF and CDF using NM, and the solid red line and dotted red line represent the suggested method for both the PDF and CDF, respectively. Figure 13 illustrates that the PDF and CDF for both GANMA and NM convergence are on the same line.
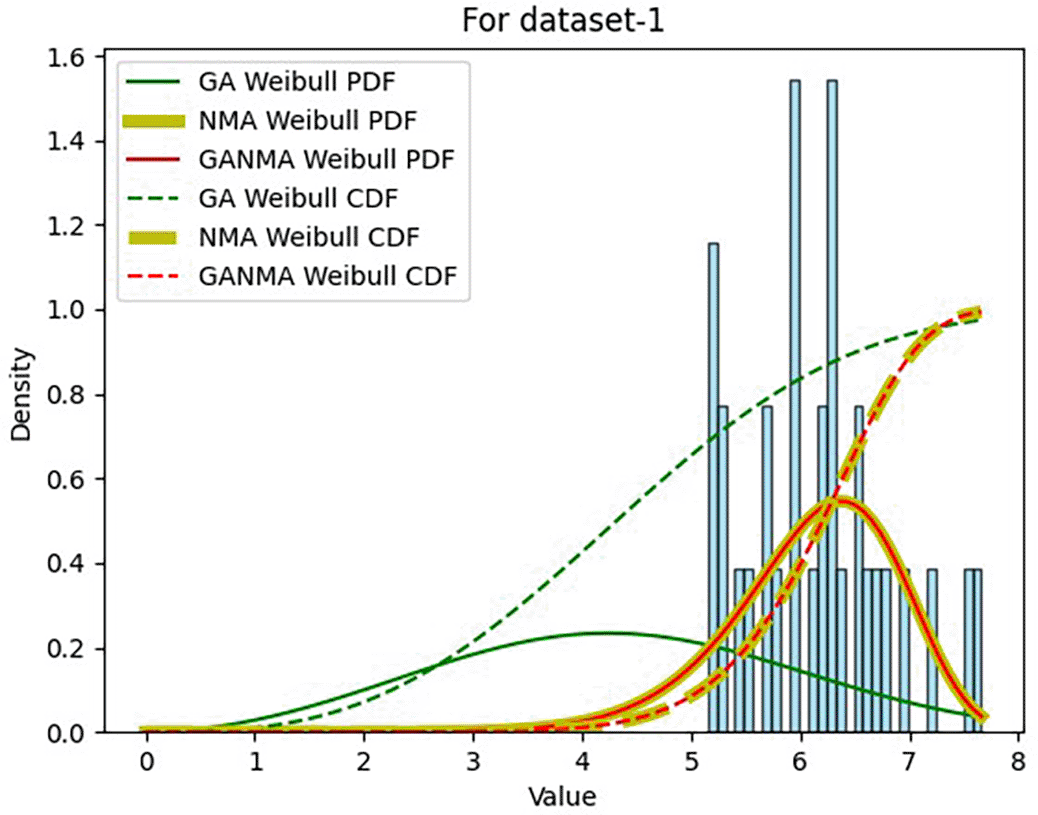
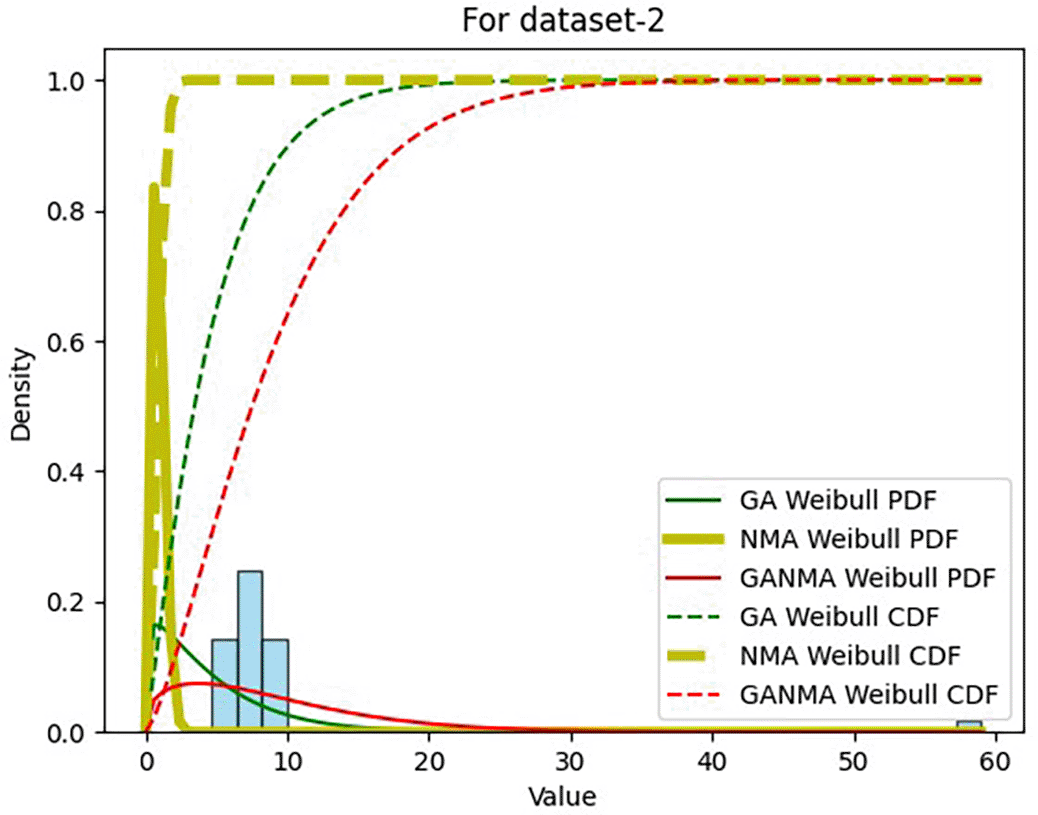
Tables 6 and 7 present the shape and scale parameters, k-s value, p-value, and power density for the first and second data sets, respectively, for all three estimation techniques. The greatest p-value and the lowest k-s statistic for both data sets are produced by the suggested approach (GANMA) out of the three estimation techniques. The Weibull distribution and the actual wind speed data seem similar, as indicated by the p-value exceeding the selected significance threshold (e.g., 0.05). In other words, the data is well-fitted by the Weibull distribution. The parameters estimated using GANMA are considered the best fit for describing the wind speed data, based on the K-S test findings. The observed wind speed data and the predicted Weibull distribution with these parameters were well recognized, as evidenced by the low K-S statistic and high p-value.
| Method | k-s value | p-value | PD (watt/m2) | ||
|---|---|---|---|---|---|
| NM | 9.52382 | 6.44868 | 0.13685 | 0.56069 | 147.05921 |
| GA | 3.48312 | 4.97007 | 0.67756 | 1.274E-14 | 71.36770 |
| GANMA | 9.52340 | 6.44863 | 0.13682 | 0.560978 | 147.05541 |
| Method | k-s value | p-value | PD (watt/m2) | ||
|---|---|---|---|---|---|
| NM | 2.0 | 1.0 | 0.99999 | 2.63E-285 | 0.81422 |
| GA | 1.07418 | 4.97152 | 0.62512 | 3.105E-12 | 350.27224 |
| GANMA | 1.35925 | 9.85611 | 0.35982 | 0.00042 | 1431.63678 |
The maximum power density is demonstrated by the parameters estimated through MLE implementing NM, as shown in Table 6. This suggests that the parameters possess greater absolute performance in terms of power generation. Despite the slightly lower power density value of the parameters estimated by MLE using GANMA compared to NM, they are nevertheless selected as the best fit since they have the greatest p-value and the least k-s statistic. This suggests that for wind speed data set 1, parameters calculated by MLE using GANMA offer the best match.
The parameters that are estimated by MLE using GANMA are found to provide the best fit in Table 7, as shown by their lowest K-S statistic and highest p-value. Additionally, superior performance in terms of power generation is indicated by the higher power density value associated with these parameters.
To improve the exploitation capabilities of GA, this study presents a unique hybridized approach called the Genetic and Nelder-Mead Algorithm (GANMA), in which NM is included. GANMA has been employed to verify the robustness and efficiency of the suggested technique on fifteen benchmark problems for three separate dimensions. Because of its high level of accuracy and stability, GANMA performs very well in improving unimodal, multimodal, and shifting unimodal/multi-modal functions, as shown by the test function comparison experiment table. According to the testing results, the suggested method is strong and has the potential to solve benchmark issues more quickly than the other two algorithms in the majority of situations.
Furthermore, estimating the Weibull distribution’s scale (η) and shape (β) parameters, this study aims to assess the efficacy of three estimation methods: ML estimators employing GA, NM, and GANMA. The MAE and bias criteria are used to assess the efficiency of the parameter estimating techniques. Based on the conclusions drawn from the Monte Carlo simulation and the examination of real-world wind speed data, the ML estimator using GANMA performs better in Weibull parameter estimation than the ML estimator using NM and GA estimator. We used the K-S test to compare three sets of parameters for two fitting wind speed data sets with a Weibull distribution and selected the set of parameters that minimized the K-S statistic and maximized the associated p-value, indicating the best fit. Moreover, it may be said that the two sets of data were collected in two different geographic locations with different meteorological conditions. In these data sets, which included a variety of meteorological situations, GANMA demonstrated superiority.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
 is not given in the paper. Also, the reason for the selected values of: γ=1.5, β=0.5 and η=0.5
is not given in the paper. Also, the reason for the selected values of: γ=1.5, β=0.5 and η=0.5 must be listed. Why didn’t you use the standard NMA values (α=1, β=2 and γ= η=0.5
must be listed. Why didn’t you use the standard NMA values (α=1, β=2 and γ= η=0.5 ). In addition, these values (α, β,γ and η)
). In addition, these values (α, β,γ and η) are the same values used for Weibull-Parameter Estimation.
are the same values used for Weibull-Parameter Estimation.
Comments on this article Comments (0)