Keywords
Measurement Error, Bias, Measurement reliability, Type I Error, Covariate Adjustment
Measurement Error, Bias, Measurement reliability, Type I Error, Covariate Adjustment
The changes made to the article were done mostly in response to the reviewers comments/suggestions. We have revised the manuscript to integrate the energy-blood pressure example more consistently across the discussion of each model, as suggested. Specifically, we have added this example to clarify key concepts, including the role of measurement error, the implications of assuming different relationships between variables, and the evaluation of predictive ability. We also refined the discussion on optimal study design, highlighting cases where improving the measurement of confounders, such as sodium intake, may be more critical than improving the measurement of the primary exposure. Additionally, we have ensured that the notation used for variables is consistent throughout the text. These revisions, we think, improve the clarity, coherence, and applicability of the models presented. We also expanded our discussion to include recommendation for researcher working with secondary data with potential measurement error. We have revised the manuscript to incorporate some clarification regarding assumptions in nutritional epidemiology research. Specifically, we replaced the original statement with one that acknowledges that many high-quality studies avoid assuming a linear or monotonic dose-response by using splines or categorical exposure modeling. However, we also emphasize that numerous other studies continue to rely on these untrue yet seemingly implicit default assumptions. Finally, we included a sentence highlighting that the results obtained in this manuscript were obtained in the case of linear model and do not directly extend to the case of non-linear or generalized models. We also include references discussing measurement error in non-linear models.
See the authors' detailed response to the review by Nicola Bondonno
See the authors' detailed response to the review by Tolulope Sajobi
The challenges of measuring dietary intake and other variables in observational epidemiology in nutrition and obesity research have been widely discussed.1–3 Data on nutrient or energy intake inform prevention and treatment guidance and policies for many health conditions. Fidelity of data to true nutrient and energy intake is essentially related to the ability to draw valid scientific conclusions about nutritional effects. It is not easy to obtain food intake information, however, particularly from a large number of individuals as is done for the highly reputable and influential National Health and Nutrition Examination Survey (NHANES). NHANES obtains nutrient and energy intake data through self-reported dietary recall questionnaires. This approach involves individuals reporting food and drinks consumed in the past 24 hours followed by detailed questions to accurately gauge the amounts of nutrients and energy consumed. Another such subjective approach that is popular is the food-frequency questionnaire, which asks individuals about the frequency of consumption of various foods.
Understandably, such information related to nutrient and energy intake is influenced by intentional or unintentional misreporting, which substantially impacts accuracy. For example, a study pooled data from five large studies that had examined the validity of food-frequency questionnaires and 24-h dietary recalls against recovery biomarkers. Across this diverse sample of Americans, subjective estimates of energy intake explained less than 10% of the variance in true energy intake.1 It appears that the self-reported measures systematically underestimate energy intake by hundreds of kcal per day, and the NHANES surveys may underreport energy intake by as much as 800 kcal per day.2,3
Accuracy of data should be a concern for any researcher, and this level of inaccuracy should be disconcerting. However, it is a common practice to acknowledge the limitations of such measurements and to then carry on with the research as though it has at least some validity despite these limitations. Some common practices to dismiss or minimize concerns around lack of accuracy of data include rationalization that self-reported data about energy or nutrient intake have good reproducibility, or that they could be adjusted by a common factor.4 There are serious counterarguments against such rationalizations. Settling for reproducibility of data instead of accuracy is like using a mismarked measuring tape. One can reproduce the result, but it is still inaccurate. Also, dietary underreporting varies with the type of food consumed, gender, age, smoking habits, social class, education level, dietary restraints, body mass index (BMI) of the respondents, and other life stage factors,5 which makes it implausible that one could adequately correct a given dataset by a single factor and arithmetic operation.
Considering the serious implications of using decidedly inaccurate information, some investigators have raised concerns that some limitations are so severe that we are better off not conducting certain research or not using certain methods at all until more accurate methods become available. For example, Lear wrote “One may wonder if we should stop nutritional research altogether until we can get it right”.4 While this may be an extreme rhetorical position, Dhurandhar et al.5 noted that in some cases, measurement properties are so bad that it is better to not perform the research at all than to use the poor measurement instruments (even if the instruments are the best available for a particular context). Putting it succinctly, on some occasions, something is not better than nothing.
Recently, we became aware of a particular finding regarding the effects of controlling for a confounding variable that is measured with error. Westfall and Yarkoni6 showed results that seemed to imply that there is not necessarily a monotonic relationship between (a) the degree of measurement error in a confounding variable and (b) the extent to which controlling for the measurement of the confounding variable reduces bias in testing for an exposure association with an outcome. Rather, the degree of bias in testing appears to increase as one moves from a completely unreliable measure of the confounder to a partially reliable measure and then decreases again as one approaches a perfectly reliable measure.
Note that in frequentist significance testing (the type of testing generally used in this journal), a test may be said to be biased when the sampling distribution of P values from applying the test is not uniform on the interval [0,1] under the null hypothesis.7 The main concern is that the “size of the test” is inflated such that, in probability, too many small P values are generated, leading to too many type I errors.
Another key point from the article by Westfall and Yarkoni6 that appears counterintuitive is that the larger the sample size, the higher the error rate. This is critical in nutritional epidemiology because greater importance is regularly given to the largest cohort studies when in fact the largest studies may be the most susceptible to biasing in significance testing both because they have more power to detect all effects, including spurious ones, and because large scale studies may be less well able to measure variables well.8
Although we were able to identify some articles in the nutrition and obesity literature that cited the Westfall and Yarkoni article,9–17 none of them addressed the issue of modest reliability potentially being worse than poorer reliability. To the best of our ability to discern, this issue has not been recognized in the nutrition and obesity literature. Yet, this methodologic issue in which intermediary measurement reliability may be worse than either very low or very high reliability seems especially concerning for the nutritional epidemiology field, where even aspects of dietary intake that can be measured with some degree of reliability and validity often have very modest degrees of reliability or validity.18 Thus, this non-monotonicity problem may be a particular concern, and if true, might suggest the startling conclusion that in nutrition epidemiology it is better to not measure some covariates at all than to include them in the study, if they have only modest reliability.
Here we provide an explanation of the phenomenon in simple scenarios so that researchers, reviewers, and editors in the nutrition and obesity research communities can see that the conclusion about non-monotonicity of bias as a function of covariate reliability holds only under specific and arguably contrived circumstances. Awareness of this offers some modest reassurance and also interesting insights into the design, analysis, and interpretation of studies.
Consider the following extension to simple linear classical measurement error model
Additionally, we depict Model 1 in Figure 1 (omitting the error terms for , , and ).
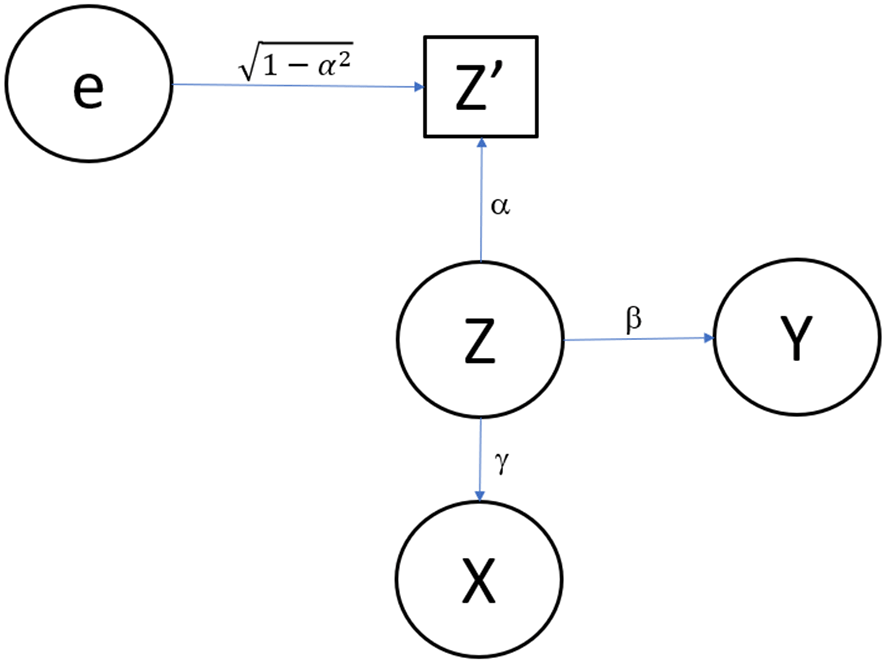
Simple model including one confounder measured with error.
In Figure 1, represents the independent variable (i.e., exposure, predictor, the putatively causal factor of interest), which could be a measured nutrient, a treatment received or not received, a personal factor, or any other measurable quantity. represents a confounding variable which we assume is not observed. Again, could be any measurable variable, particularly an aspect of dietary intake. Random measurement error is represented by . Here we consider classic true score phenomenon, which is a simple conceptualization of measurement error. We denote the error-contaminated measure of as , with being a simple additive function of and , where is independent of .
“Classical test theory, also known as true score theory, assumes that each person has a true score, T, that would be obtained if there were no errors in measurement. A person’s true score is defined as the expected score over an infinite number of independent administrations of the scale. Scale users never observe a person’s true score, only an observed score …. It is assumed that observed score … = true score (T) plus some error (E) …. It is also assumed that … the expected value of such random fluctuations (i.e., mean of the distribution of errors over a hypothetical infinite number of administrations on the same subject) is taken to be 0. In addition, random errors are assumed to be uncorrelated with a true score, with no systematic relationship between a person’s true score and whether that person has positive or negative errors”.19
Finally, represents the outcome variable (i.e., the dependent variable, the thing to be predicted).
It is noteworthy that:
(a) With minor modifications, the model depicted in Figure 1 can specify a situation of confounding, causal mediation, or correlated predictors.
(b) The resulting correlation matrix among the variables depicted will be unchanged as a result of these modifications.
(c) The same statistical test will be needed when testing for an association while controlling for confounding, testing for direct effects beyond mediated effects in a mediation model, or testing for incremental predictive validity.6,20,21
For example, in the model as depicted, Z is a confounder of the association between X and Y, and the test of interest is whether the squared partial correlation of X and Y after controlling for Z is not zero. However, if we reverse the direction of the arrow from Z to X (the arrow labeled with the coefficient γ), we are describing a mediation model22 in which Z is the hypothesized mediator and the test for the direct effect of X on Y can again be whether the squared partial correlation of X and Y after controlling for Z is not zero.23 Suppose for example we want to test whether energy intake (X) is associated with blood pressure (Y), after controlling for sodium intake (Z). X and Z represent their true (unobserved) intakes, while X′ and Z′ are the error-prone measures obtained from self-report. In Model 1, we assume that energy intake (X) is measured without error, but sodium intake (Z′) is the error-prone measurement of true sodium intake. As an example, Feng et al.24,p. 3336 assessed both the direct effects and “the potential indirect effect of sodium intake on blood pressure via body mass index.” That is, Feng et al. modeled BMI as the mediator of sodium intake on systolic and diastolic blood pressure and performed mediation analysis to evaluate the total effect, direct effect, and indirect effect via BMI.
Finally, if we replace the arrow from Z to X with a double-headed arc,25 we are not specifying the causal relation between X and Z, only that they are correlated. In this case, we can then test whether, after accounting for the predictive ability of Z, X can add to the ability to predict Y. In the context of our energy-sodium-blood pressure example, imagine we do not assume that sodium intake (Z) causally impacts energy intake (X) or vice versa. Instead, the two might be correlated, because people who consume high-sodium foods may also consume higher total energy. We then can ask whether after accounting for sodium’s predictive ability for blood pressure (Y), energy intake provides additional predictive value for blood pressure - how much variance in blood pressure each can explain beyond the other. As another example, Pichler et al.26,p. 616 aimed “to assess the accuracy and precision of a BIA [bioimpedance analysis] device and the relative contribution of BIA beyond the anthropometric parameters [emphasis added].”
Given points a, b, and c above, the implications of the methodological issue we are addressing apply to a broad swath of the research questions and hypotheses typically addressed in our field.
For smplicity, we consider that all variables are such that the use of ordinary least squares linear multiple regression (i.e., multivariable regression27) is appropriate. Extensions to other data forms are available.28 Suppose that investigators wish to test whether X is associated with (i.e., predicts) Y after controlling for Z. However, the investigators do not have measures of Z. Rather, they have measures of Z′, the error-contaminated or imperfect measurement of Z. That is why in Figure 1, Z′ is depicted in a rectangle whereas the other variables, which are assumed to be measured without error for this stylized example, are depicted in ellipses.
The question then becomes, will the type I error rate (i.e., sometimes called the false-positive rate) be maintained at its appropriate nominal levels if we control for Z′ rather than Z and how will any degree of bias in the significance testing be related to the reliability of Z′? From Figure 1, the reliability29 of Z′ is . If controlling for Z′ leads to unbiased inference using standard frequentist significance testing at the 0.05 significance level, then (because in this hypothetical, X has no effect on Y) the null hypothesis for the test or the association of X with Y after controlling for Z′ would yield significant results only 5% of the time. The (false) power (i.e., type-1 error rate inflation above the nominal significance level) of the test of the association of X with Y after controlling for Z′ would be the degree of bias in the significance testing procedure under these circumstances. To calculate this degree of bias or false power, we can begin by constructing the correlation matrix depicted in Table 1.
| Z′ | X | Y | |
|---|---|---|---|
| 1 | |||
| 1 | |||
| 1 |
The correlation coefficients in the cells of the matrix in Table 1 are derived by simple application of the standard rules of path analysis.30 From there, we can calculate power by writing out the F-test31 of the association of X with Y after controlling for Z′. In our specific example, these yields (with N the sample size):
For any fixed sample size and specific model, the number of covariates and sample size are constant, meaning that the rightmost term of the equation becomes irrelevant if one is only concerned with the power as a function of the measurement reliability, which is our context here. Therefore, recognizing that the non-centrality parameter and the power (false power or bias) will be monotonic functions of only the left term on the right side of equation 1, , we can deal only with that. This term, , is in fact none other than the squared partial correlation coefficient (in nonmathematical terms, a squared partial correlation coefficient can be defined as the proportion of the remaining variance in the dependent variable after controlling for the covariates that can be “explained” by the independent variable of interest32) of X and Y after controlling for Z′. It is important to note that this is the squared partial correlation coefficient and not the squared semi-partial correlation coefficient [in nonmathematical terms, a squared semi-partial correlation coefficient can be defined as the proportion of the total variance in the dependent variable that can be “explained” by the independent variable of interest, after controlling for the covariates32], because the difference in the denominators of the two coefficients can be helpful in understanding the phenomena of interest in this paper. The quantities and can then be expressed as functions of the elements of Table 1, as follows:
The squared partial correlation of Y and X controlling for (i.e., after partialing out) Z′ is:
Substituting the right sides of equations 2 and 3 into the right side of equation 4 yields:
Equation 5 can then be re-expressed by substituting the zero-order correlations expressed as ‘ρ’s in terms of the path coefficients from Figure 1 as follows:
One can then calculate the squared partial correlation coefficient (the quantity in equation 6) as a function of the reliability of Z′. The reliability of Z′ is . The first derivative of the squared partial correlation coefficient with respect to (the square root of the reliability coefficient) is
The first derivative of with respect to has no real roots within the open intervals . The value of the derivative for any value of and, in (-1,1) is negative indicating that is a decreasing function of for fixed values of in (-1,1) (see Figure 2).
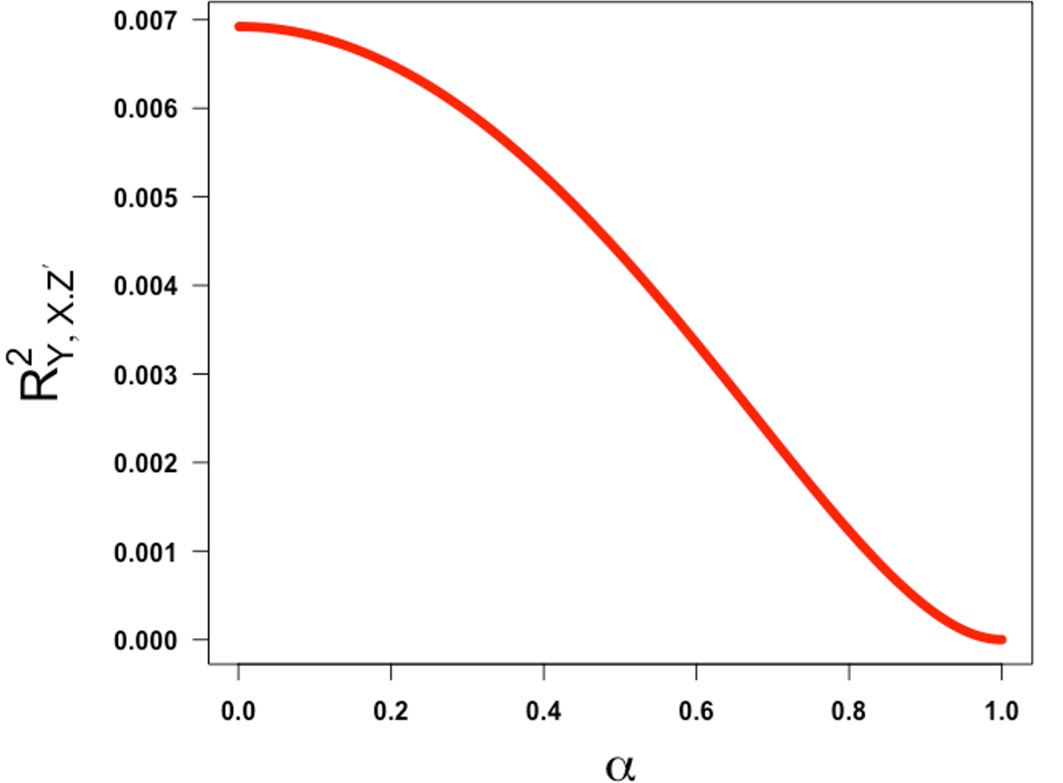
All symbolic calculations for the derivative and root solutions were performed in the computer algebra system, Wolfram Mathematica 12.0.
This shows that the squared partial correlation coefficient quantifying the association between X and Y conditional on Z′ is always decreasing in α over the half-closed interval [0,1). This means that the lower the value of α (i.e., the lower the reliability of the confounder measurement), the higher the (spurious) partial correlation of X and Y controlling for Z′ will be. This illustrates the classic concept of residual confounding. This is intuitively sensible and reassuring and refutes any implication that bias due to imperfect reliability of a confounding variable increases as the reliability increases before coming back down.
In contrast, consider the just slightly more complex model as
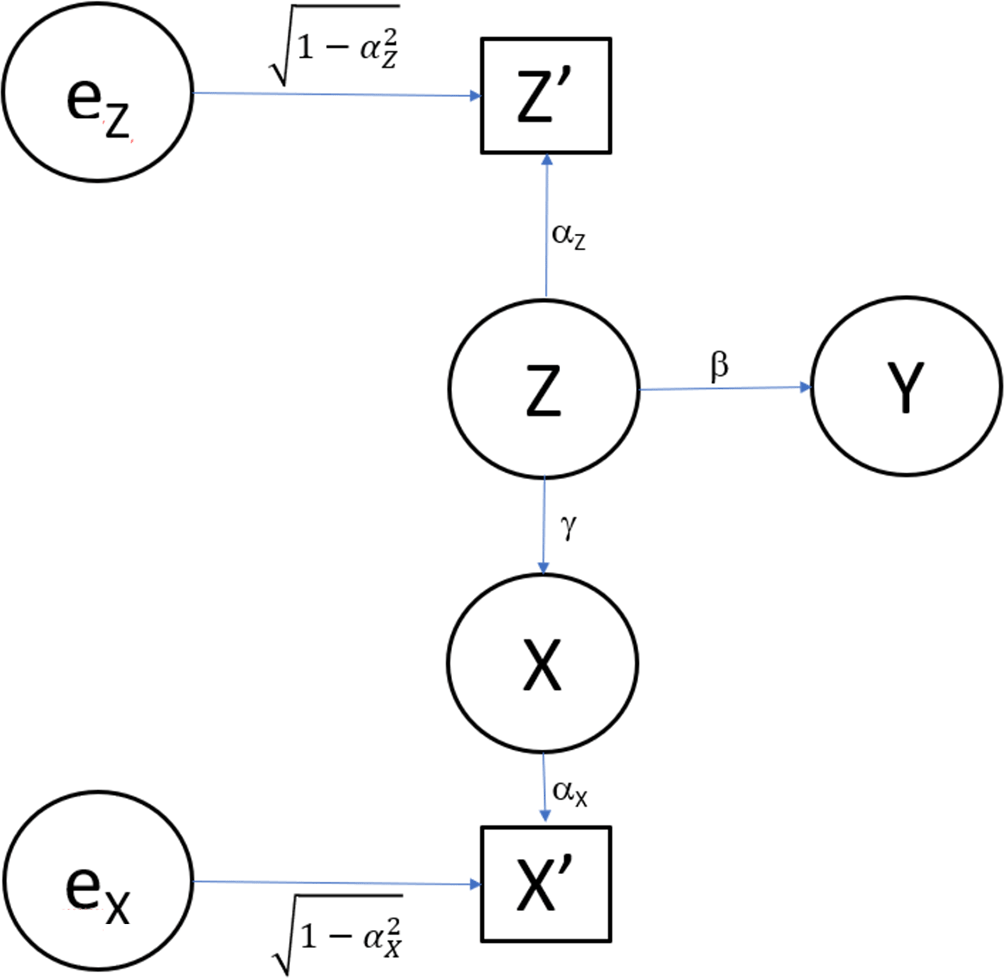
Mapping Model 2 ( Figure 3) to our energy-sodium-blood pressure example, we now assume that both energy intake and sodium levels are self-reported and prone to measurement error, so we observe X′ and Z′, but that blood pressure (Y) can still be assessed objectively. This then produces the 3×3 correlation matrix in Table 2.
| Z′ | X′ | Y | |
|---|---|---|---|
| Z′ | 1 | ||
| X′ | 1 | ||
| Y | 1 |
The analogues for equations 5 and 6 from Model 1 are now equations 7 and 8 for Model 2, which are:
Equation 7 can then be re-expressed substituting the zero-order correlations expressed as ‘ρ’s in terms of the path coefficients from Figure 3 as follows:
For pedagogical purposes, let us follow Westfall and Yarkoni’s approach and let: .
Then, equation 8 simplifies to:
One can then calculate the squared partial correlation coefficient (the quantity in equation 9) as a function of , or the reliability of Z′ and X′, which is . Taking the first derivative of the squared partial correlation coefficient with respect to the reliability coefficient, , we obtain:
Setting the derivative equal to zero and solving for under the constraints that are all in the interval (-1,1) results in a unique critical point, . Because is an even function of , there is a symmetric critical point, . The region where is a reflection of the region across the y-axis; therefore, we can restrict our analysis to the region, . In this region, with , the derivative is positive for and negative for in the interval (0,1), verifying that the function increases before the critical point and decreases after. As a result, the squared partial correlation coefficient quantifying the association between X′ and Y conditional on Z′ is not monotonic in α over the half-closed interval [0,1). This is illustrated in Figure 4 below with ).
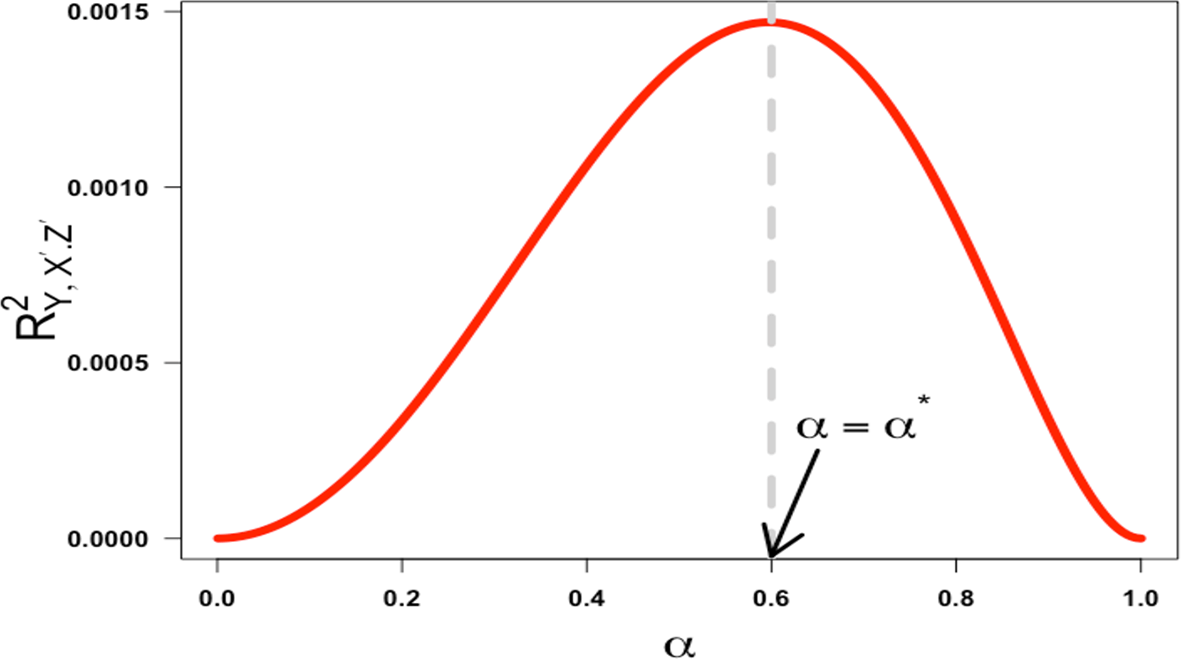
This would seem to support Westfall and Yarkoni’s statement that “the effect of reliability on error rates is even less intuitive: there is a non-monotonic relationship, such that type 1 error approaches 5% [the nominal rate they set] when reliability nears 0 or 1, but is highest when reliability is moderate”.6 What is not made clear in their paper is the reliability of what? Specifically, their statement is not true when referring to a single reliability coefficient. It is only true because they have constrained the reliability of the exposure measurement and the reliability of the confounder measurement to have the same value. If we decouple them (as there is no a priori reason that they must have the same value), and return to equation 8 instead of equation 9, we can see that, when Z is a confounder, the squared partial correlation coefficient (the quantity in equation 8) as a function of , or the reliability of Z′, is always increasing as a function of , or the reliability of Z′.
This leads to the insight that it is the relative values of and that determine this pattern. To make this clear, we re-express and then substitute into equation 8 to yield:
in reduced form we have
provided that
Using this expression, we can make the following observations. This expression is a product of all positive terms hence is positive. If we relax the assumptions made above and only impose that and and are both set at 1.0 and = -1, then we can show that the partial correlation above is monotone increasing with the reliability and converges to ½ as get close to 1 from the left ( Figures 5 and 6 show the plots of the partial correlation and its first derivative, respectively, as a function of when and are both set at 1.0 and = -1, both illustrating that the partial correlation is a non-decreasing function of in these settings. Further, it turns out that if we assume and we set and while keeping and both at 1.0, the partial correlation is also monotone in .51 We provide a small R code to reproduce the plots presented in this paper along with the case where we set and while keeping and both at 1.0.51
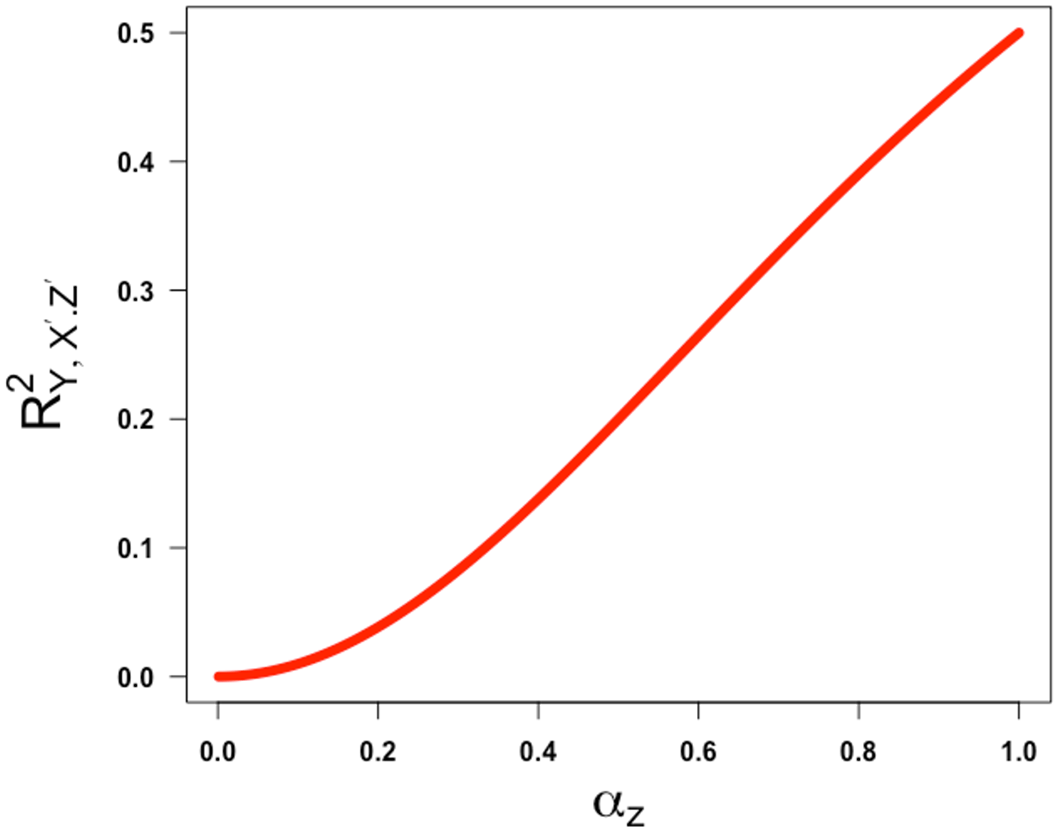
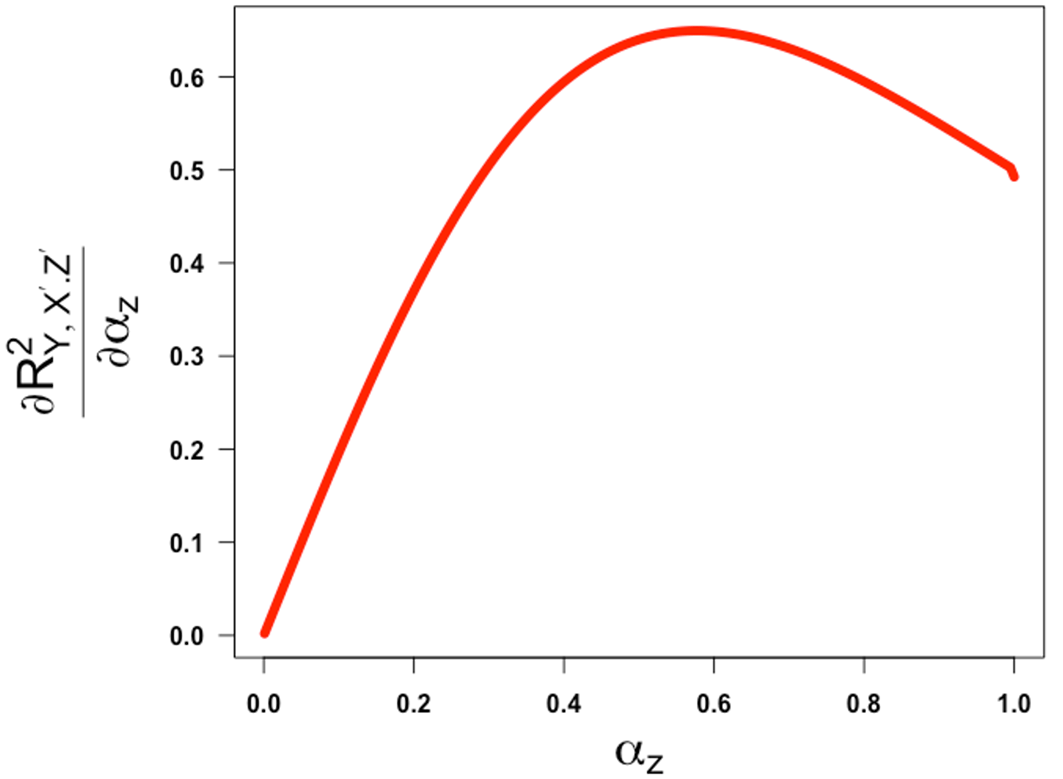
What these derivations and illustrations show is that the degree of ‘false power’ or bias can actually goes up as one moves from a completely unreliable measure of a confounding variable to a modestly reliable measure of a confounding variable as Westfall and Yarkoni opined, but only if one artificially constrains the reliability of the exposure measurement to also be increasing as a function of the reliability of the confounder measurement. This is because, as we showed previously,33 although the numerator of a ratio and the denominator of a ratio may both move toward their “proper” values monotonically as a function of a single variable, they may do so at different rates such that the ratio may change non-monotonically.
Many epidemiologic studies involve observational (not interventional) studies and as such are not under experimental control.34 Such observational data are often prone to measurement error, missing data, and confounding. While it is well known that measurement error associated with a single exposure, X, under some very specific circumstances, leads to attenuated associations in simple linear regression, less is known about how measurement error influences estimation, testing validity, and optimal study designs when investigators are interested in modeling the association between the exposure, and an outcome, Y, after controlling for Z, a confounder, where are all measured with error and complex error structures and analysis methods may prevail.
In nutritional studies involving estimation of dietary exposures on disease outcome models, linear regression calibration is the most applied method.35 Linear calibration-based methods to measurement error correction involve two-stage models where replacement values for the true dietary exposure are simulated or obtained from its conditional distribution given the measured value and association between the simulated measures of the exposures and the outcome are estimated in the second stage.36 Under the linear calibration approaches, non-differential measurement error and uncorrelated errors between the dietary and reference instruments are assumed.35 In models where a confounder and an exposure are both measured with error or when multiple covariates are measured with error, multivariable regression calibration is often used in nutritional studies.37 The multivariable regression calibration approach is performed under assumptions of random within-person errors or under combinations of random error. In general, the effect of measurement error in a single mis-measured or imprecisely observed exposure is to attenuate its effects on health outcomes. However, how measurement error in both a confounder and exposure influence their estimated effects on the dependent variable is less clear. Measurement error can modify or mask the effects of a confounder when both the confounder and exposure are error prone.34
While efforts have been made to develop statistical approaches that correct for measurement error to reduce biases in the estimation of exposure effects, less has been done to determine how the presence of measurement error in an exposure or in both exposure and confounder influences optimal study designs. By optimal study design, we mean the design which minimizes some loss function (e.g., some weighted function of quantities of interest such as power, type 1 error rate, bias, financial cost, study duration, etc.) subject to user-defined constraints.38 Spiegelman and Gray39 developed cost-efficient and statistically powerful cohort study designs for continuous exposures measured with error in binary logistic regression models. The authors proposed three ways to optimize study designs in the presence of errors. These include the inclusion of an internal validation study, external validation of subsamples obtained from other studies, and the use of better exposure methods for assessment.39
Such thinking invites several questions for future research when we wish to test for the association between an independent variable and a dependent variable after controlling for a third variable, and all may be measured with error.
• A first question is a meta-research question40: What is the state of practice? When investigators apply measurement error correction procedures, do they typically do so for X, Z, Y, or some combination? Although systematic reviews of related questions have appeared,35 we are not aware of one that has answered this exact question.
• A second question is how does applying such measurement error corrections affect power and bias if applied to various combinations of X vs Y vs Z?
• Third, do the answers to the second question suggest under which circumstances, to what extent, and for which variables (X, Y, or Z) investigators should invest their resources in improving the reliability of if the possibility of increasing reliability of each at the cost of finite funds exists? Such inquires might lead to the counterintuitive finding that under some circumstances one should invest more in studying the nuisance variables one is not interested in than the putative causal factors in which one is interested. For example, to the energy-sodium-blood pressure example, it may be optimal in certain scenarios to invest in a more accurate sodium-intake measure (Z′) rather than energy-intake (X′) if it is suspected that sodium may drive the confounding effects on blood pressure.
Without knowing the exact nature of any phenomenon or set of phenomena we are studying, we cannot know exactly which situation will prevail. If we did, we would not need to undertake the research. However, we can say from general knowledge of the measurement properties of variables frequently used in nutrition and epidemiologic research, and of the magnitude of associations typically studied in epidemiology and nutrition and obesity, that the hypothetical scenarios we have evaluated above are within the realm of the typical association study. Therefore, it seems plausible that not only is measurement error a substantial concern in our models but so are statements that may be patently untrue, such as that an association actually becomes more significant when controlling for a plausible confounder or that measurement error only attenuates effects. We thus may need to take observational research with more than a considerable grain of salt when drawing causal inferences. Yet further, the plausibility of our hypothetical example suggests the importance of not merely acknowledging measurement error as most of us do in our articles on nutrition epidemiology, but actually building formal measurement error corrections into the analysis as described elsewhere.41 Many quality papers in the field wisely do not assume there is a linear or monotonic dose-response of risk with intake of a food or nutrient and instead use splines or categorize exposures to avoid such assumptions (e.g., Refs. 42,43). However, included in overall implications for many other papers in nutritional epidemiology research (e.g., Ref. 44) are the reliance on the untrue yet-seeming implicit default assumptions that: 1) there is a linear or monotonic dose-response of risk with intake of a food or nutrient; 2) confounders act independently of one another, additively, linearly, with predictable effect, when they clearly do not, accentuating concerns about the ignoring of potential interactions of multiple confounders that are either not measured at all or not measured accurately45; and 3) unmeasured or poorly measured confounders can be dismissed as serious threats to statistical conclusion validity because it is implausible that a confounder or set of confounders could imbue sufficient bias to produce the observed association, when in fact large samples produce large power to mistakenly detect small biases as actual associations or effects. Finally, our illustrations and derivations point out the importance of evaluating the quality of our procedures and improving them when possible. The results obtained here were developed in the context of linear models and are not readily extendable to the case of generalized linear models with non-linear link functions.46–50
As outlined in the beginning, the topic of measurement error in covariates has critical application for nutritional epidemiology around the practice of determining nutrient and energy intake and using it for developing nutritional guidance and policies. It is unclear what role interpretations based on inaccurate measurements have played in national and local health-related policies or health care guidance for individuals. It should be recognized that a great need exists for accurately determining nutrient or energy intake. This need will not become a priority if we continue to accept inaccurate data as “good enough” for the purpose. Therefore, moving forward, we need to discontinue the use of methods that generate decidedly inaccurate data. Next, we urge that concerted efforts be made in redirecting resources to developing methods that objectively measure nutrient and energy intake with high fidelity and for long periods of time. Until such time, we need to be prepared to accept the counterintuitive conclusion that under some circumstances, in our efforts to improve the reliability or power of our methods, sometimes nothing is better than something.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
 . When we relaxed this assumption and allow the reliability of the exposure to be some linear function of the reliability of confounder, i.e.,
. When we relaxed this assumption and allow the reliability of the exposure to be some linear function of the reliability of confounder, i.e.,  , we obtain a monotone partial correlation as a function of the of the confounder reliability.
, we obtain a monotone partial correlation as a function of the of the confounder reliability.
Comments on this article Comments (0)