Keywords
Software Defect Prediction; Feature Selection; Wrapper approach; Chernobyl Disaster Optimizer, Optimization
This article is included in the Kalinga Institute of Industrial Technology (KIIT) collection.
Software Defect Prediction; Feature Selection; Wrapper approach; Chernobyl Disaster Optimizer, Optimization
The reviewer's suggestions have been incorporated into the revised manuscript. There have been several new additions in addition to textual changes. Figure 1 has been updated. Once more, to preserve high quality, all of the figures are provided in PNG format. There are two new tables in the updated version. A summary of the cited literature on software defect prediction is presented in Table 1. Likewise, Table 2 provides useful information on the datasets that were employed in this investigation. Tables have since been renumbered. The updated DOI has been indicated in the paper's data availability section, and the new data has been added to the Fighshare data repository.
See the authors' detailed response to the review by Francis Palma
See the authors' detailed response to the review by Shabib Aftab
See the authors' detailed response to the review by Ahmed Abdu
In today’s scenario, humankind needs good-quality and reliable software to help them perform their daily tasks without spending more time and effort. Owing to this immense call for exceptional and dependable software, conducting a rigorous investigation of software under development is crucial. However, the complexity of software increases every passing day, making the overall software development work very challenging.1,2 A fault in software can significantly damage its quality and reliability, leading to more frequent maintenance activities. This can result in higher operational costs for the software, ultimately leading to user dissatisfaction. A software fault can be characterized as the disparity between the actual and predicted behaviors of the software. Software testing empowers developers to identify and rebuild faults. However, conventional testing approaches are costly and time-consuming. Hence, it is imperative to detect faults in a software module during the early stages of evolution.3
Software Defect Prediction (SDP) enables developers to expose deficiencies in software components in the early stages of development by employing data analysis and machine learning (ML) approaches. An effective SDP mechanism can lead to the systematic and profitable advancement of high-quality and reliable software products without defects.4 Researchers have suggested several ML-based SDP approaches5–8 for effectively predicting defects. These methods analyse past data from different stages of development, such as testing data and debugging records, to derive any pattern or trend that can detect potential defects. The most widely employed ML methods in SDP are DT,9 SVM,10 neural networks,11 logistic regression,12 and NB.13 However, these approaches suffer from many challenges including high dimensionality being one of them.
Feature Selection (FS)14 is a potent mechanism that can be employed to overcome the issue of high dimensionality. FS allows developers to select only relevant features and carefully discard insignificant features. In SDP, FS is a vital step that will enable developers to choose the best set of features that can significantly enhance the predictive accuracy of a defect prediction model. Applying FS approaches is essential when dealing with datasets with high dimensionality. Several FS approaches have been implemented in the SDP. FS techniques are broadly classified into three categories: filter techniques,15 wrapper techniques,16 and embedded techniques.17,18 Filter-based FS techniques are autonomous for any training strategy, and apply statistical properties to identify the best traits. Nonetheless, wrapper-based FS procedures select the best characteristics based on the classification accuracy of the prediction model. Embedded-based FS techniques combine feature selection with model training. Existing literature shows that researchers have mainly applied evolution-based algorithms19 and swarm-based algorithms20 for FS purposes.
This exploration aims to boost the classification truthfulness of a defect-foretelling model while minimizing errors. For this purpose, this study uses some of the widely used meta-heuristic algorithms, namely the Genetic Algorithm (GA),21 Particle Swarm Optimization (PSO),22,23 Differential Evolution (DE),24 and Ant Colony Optimization (ACO).25 Although GA has been a proven FS approach,26 it is costly because it computes the optimal features using genetic techniques such as selection, crossover, and mutation over a set of generations. The PSO-based FS approach27 aims to find the optimal traits by emulating the fragment’s movement while probing a search arena with several dimensions. The algorithm adjusts the location and velocity of the fragment by considering singular and group knowledge. However, the PSO-based FS approach sometimes results in a local optima trap and a lower convergence rate. DE-based FS techniques28 compute optimal characteristics by employing operators such as mutation, crossover, and selection on a population of potential solutions over several iterations. However, these approaches require several parameter tunings, making them a tedious choice among researchers. ACO-based FS methods29 determine the excellent characteristics of a search space by implementing the foraging behavior of ants. However, these methods suffer from a slow convergence speed and low accuracy, especially in large datasets.
The limitations of the FS as mentioned earlier approaches motivated us to propose a novel FS approach (FSCOA) inspired by the Chernobyl Disaster Optimizer (CDO).30 CDO mimics the process of nuclear radiation, which involves the propagation of alpha, beta, and gamma fragments while attacking humans after an explosion. These radiations fly at a very high speed from a high-pressure point (the point of explosion) to a low-pressure point (the standing of the individual place). The proposed algorithm comprises an initial population of the candidate solutions. Furthermore, it computes the gradient descent factor (GDF) for alpha, beta, and gamma fragments when they attack humans. Finally, the optimal solution was achieved by calculating the average of the GDF values over several iterations. The primary objective of the proposed FSCOA approach is to unwrap the most informative features to produce a precise prediction model. The proposed algorithm has advantages such as its ability to deal with convoluted, high-magnitude datasets that are not grounded in local optima, which can be an issue in alternate FS procedures. The primary contributions of this study are as follows.
(i) To implement a novel FS technique namely FSCOA, by applying the CDO,30 a metaheuristic algorithm
(ii) To assess the conduct of the proposed FSCOA-based fault forecasting model on four different classification algorithms, NB, QDA, DT, and KNN using 12 benchmark NASA software defect datasets.
(iii) To correlate the performance of the proposed FSCOA approach with several baseline FS approaches such as FSGA, FSPSO, FSDE, and FSACO.
(iv) To validate the statistical implications of the proposed FSCOA approach using Friedman and Holm tests.
The experimental outcome shows that the proposed FSCOA was better than the other FS approaches examined in most situations and then became the best-performing FS technique for designating the best array of features.
The remainder of this paper is organized as follows. Related Works Section discusses the existing literature on FS approaches. The next segment i.e., Feature Selection based on Chernobyl Disaster Optimizer Algorithm, elaborates on the proposed FSCOA approach and the detailed methodology used in this study. Result analysis segment presents the empirical findings and interpretations. Statistical analysis segment outlines the statistical analysis. Threats to Validity section discusses the risks to the validity of the proposed work. Finally, the conclusion segment presents the conclusions and scope for prospective work.
Defect prediction role, in software modules, is critical in creating high-quality and reliable software. SDP permits developers to detect and debug defects in software modules during the prior stage of the software advancement process. Unfortunately, conventional SDP processes face several threats, including the curse of dimensionality. The curse of dimensionality indicates the presence of many attributes in a dataset. Many of these attributes do not make any compelling knowledge and hence, are treated as noise. Feature selection (FS) is a potent tool to tackle the challenge of the curse of dimensionality. FS allows developers to establish the best possible set of traits that can enhance the model’s predictive accuracy by discarding irrelevant traits. However, it is imperative to observe that conventional FS procedures are expensive and time-consuming.31 Recently, the application of ML to SDP has gained considerable traction. Several ML-based SDP approaches have been proposed. This section describes some of these studies as follows.
Das et al.32 proposed a novel FS technique called FSGJO based on the Golden Jackal Optimization (GJO) algorithm. The proposed FSGJO technique was employed on four classifiers, namely, KNN, DT, NB, and QDA, using 12 SDP datasets from the PROMISE repository. The authors compared the efficacy of the recommended FSGJO technique with alternative FS techniques, namely, FSDE, FSPSO, FSACO, and FSGA. Based on their experimental findings, the authors observed that the proposed FSGJO technique enhanced the prognostic performance of the model. It was also noted that the prospective FSGJO method was exceptional compared to other studied FS techniques in selecting the optimal set of characteristics. However, the authors mentioned that the proposed FSGJO technique needs its parameters to be tuned.
Khalid et al.33 inspected numerous existing ML methods and optimized ML procedures on three publicly accessible NASA datasets. The authors applied PSO and ensemble approaches and scrutinized the results. The experimental findings revealed that the SVM and optimized SVM outperformed the other models in terms of accuracy. However, this study was conducted using a limited number of datasets. Again, the experimental findings cannot be generalized owing to the need for additional optimization algorithms.
Kumar and Das34 enforced GA to supervise learning classifiers such as KNN, DT, and NB. Twelve NASA datasets from the PROMISE archive were used. Using accuracy and failure rate as performance metrics, the performance of the proposed model was assessed. Based on their experimental results, the authors asserted that the suggested FSGA technique improved the behaviour of the defect forecast model correlated with the scenario in which the FS was not made. However, in this study, the FS approach used only the GA. The effects of alternative optimization methodologies were not investigated.
Thirumoorthy et al.35 suggested a hybrid SDP method based on the TOPSIS and hybrid Rao algorithms (THRO) to uncover the finest traits. The authors used three benchmark NASA SDP datasets to implement their proposed THRO-based FS algorithm on SVM and NB classifiers. The impact of the proposed algorithm was assessed using six metaheuristic FS techniques. The authors noted that the proposed THRO-based FS algorithm enhanced the model’s classification performance and outperformed other studied FS approaches. However, they also pointed out that this enhanced performance of the proposed method came at the price of increased computational cost.
Batool et al.36 offered a comprehensive and well-organized analysis of the extant literature. That employed DM, ML, and DL, among other techniques, for fault prediction. The endeavour was motivated by the need to find answers to research problems stated in the evaluation that might not have been addressed in the works evaluated or called for a different viewpoint. The authors claimed that SDP frequently employs DM and ML techniques, such as DT, NB, SVM, NN, ET, and EA. Although they are used less frequently, researchers have also used DL approaches such as CNN, MLP, LSTM, and DNN to predict software errors. The authors emphasized the need for larger datasets and the importance of concentrating on using the same methods with combinations of different datasets.
An SDP architecture based on stacked stacking and heterogeneous FS was proposed by Chen et al.37 The two main objectives of this study were to increase SDP accuracy and optimize software testing resource allocation. The method is divided into three steps: feature selection, model creation with a nested-stacking classifier, and evaluation of the predictive behaviour of the model. For the experiments, two datasets were used: Kamei and PROMISE. The investigation included both within-project and large-scale cross-project defect prediction (CPDP). The model’s behaviour was illustrated using the AUC and F1-score evaluation metrics. The initial results showed that for the two sets of software failure datasets, the proposed framework performed better in terms of classification than the baseline models. However, the authors pointed out that nested-stacking is ineffective and that the optimal combination of the baseline model was determined via complex experiments.
Arora and Kaur38 suggested a heterogeneous fault prediction (HFP) model to develop an effective forecasting model utilizing supervised training approaches. The writers completed the FS in two phases. They began by selecting features based on their importance. They removed the shared features from the datasets in the next step. An integrated approach was used to select the best characteristics. Random Forest Importance (RFI) was used for the FS. According to the suggestion made by Gao et al.,39 the authors selected the top 15% of attributes throughout the FS phase. The proposed framework was applied to two open-source projects, MySQL and Linux, for the supervised ML classifiers, SVM, NB, RF, AdaBoost, DT, and LR. The behaviour of the planned model was graded using the Area under the ROC curve (AUC). The authors concluded that the most accurate logistic regression fault prediction is based on the recommended approach. The AUC data demonstrated that the suggested technique accomplished better than the existing Cross Project Fault Prediction (CPFP). However, in this study, other commonly used performance criteria such as accuracy, precision, and recall were not employed to grade the impact of the proposed approach. Once again, only supervised learning algorithms were used in the study, and no optimization algorithms were used.
Anand et al.40 conducted a correlative performance assessment of various FS techniques in SDP. Chi-Square (CS), Correlation Coefficient (CC), Fisher’s Score, Information Gain (IG), Mean Absolute Difference (MAD), and Variance Threshold (VT) are among the filter-based FS approaches used in this investigation. Wrapper-based FS strategies also encourage the use of Backward Feature Elimination (BFE), Exhaustive Feature Elimination (EFE), Forward Feature Elimination (FFE), and Recursive Feature Elimination (RFE) methodologies. RFI and LASSO Regularization are among the embedded FS techniques utilized in this study. The recommended model uses six publicly accessible benchmark NASA datasets for the NB, SVM, DT, and KNN classifiers. The authors used the performance evaluation criteria of the F1-score, recall, accuracy, and precision. The authors’ experimental results showed that Fisher’s score behaved more precisely than other FS techniques. However, compared to the no-FS situation, it was found that all FS strategies enhanced the model’s behaviour. A drawback of this study is that it neglected to examine the impact of optimization strategies on the FS.
The dynamic re-ranking approach-based WFS technique was introduced by Balogun et al.41 in response to the exorbitant processing expenses of wrapper-based FS (WFS) methods. The recommended technique was constructed using 25 public domain datasets that were extracted from the NASA, AEEEM, PROMISE, and ReLink archives using classifiers such as DT and NB. The findings of the experiment illustrated that the recommended method reduced computing time and enhanced model performance when executing FS. The suggested method used both the FFS and WFS techniques, which is a disadvantage. FFS has variable performance across datasets and classifiers, whereas WFS suffers from the stagnation of local optima and high computing costs. Once more, only two supervised classifiers were examined in this work: SVM and K-NN, two more well-known classifiers, were not examined.
Balogun et al.42 proposed an inventive hybrid multifilter wrapper FS arrangement based on rank aggregation to select critical features to address the aforementioned shortcomings. The recommended course of action was implemented in two steps. In the first lap, a multifilter FS mechanism based on rank aggregation was used, which combined the separate rank lists from multifilter methods to build an original, dependable, and non-disjoint rank list. This resolves the filter rank choice issue. In the second lap, the upgraded wrapper FS approach, which was predicated on dynamic re-ranking, was used once more to preprocess the accumulated ranked attributes. The competence of the recommended method is illustrated using NB and DT classifiers on benchmark software fault datasets. The tests used accuracy, area under the curve (AUC), and F-measure values as evaluation criteria. The authors used their findings to concentrate on the issues of filter rank choice and local optima stagnation in HFS, demonstrating the suggested method’s ingenuity in selecting the best characteristics while enduring or boosting the impact of the forecasting models. They concluded that applying the recommended technique significantly improves the behaviour of the model. However, the model was limited to only two classifiers to achieve satisfactory results. Consequently, the potential of extrapolating the results to alternative classifiers has not been explored.
Alsghaier and Akour43 presented an SDP model by fusing the GA, SVM, and PSO. Three stages were implemented: GA-SVM for GA integration, PSO-SVM for PSO integration, and GAPSO_SVM for the reciprocal iteration-based integration of GA-SVM and PSO-SVM. During the experimentation phase, 24 benchmark SDP datasets (12 NASA MDP and 12 open-source Java applications) were subjected to the proposed model using the SVM classifier. Experiments were conducted using the WEKA Tool and MATLAB 2015 to validate the theoretical model. The impact of the developed approach was assessed using evaluation metrics, such as accuracy, recall, precision, F-measure, specificity, error rate, and standard deviation. The experiment results showed that combining the GA with SVM and PSO had a beneficial effect on the model and enhanced its performance when applied to both small- and large-scale datasets. However, the precision metric needed to be more sufficient to appraise the suggested procedures.
Alsghaier and Akour44 built on their earlier work43 by combining GA, SVM, and Whale Optimization Algorithm (WOA) to forecast defects. The remainder of the experimental configuration remained the same as in a previous study.43 Through experimental data, the researchers discovered that the behaviour of the defect forecast model was improved for both large-scale and small-scale datasets when the GA was integrated with SVM and WOA. For the datasets under study, WA-SVM performed more accurately than GAWA-SVM, and GAWA-SVM produced the worst outcomes. Again, the proposed method outperformed SVM for the NASA MDP and open-source Java projects regarding SD scores. This illustrates how combining SVM with optimization techniques enhances the prediction performance. The NASA, GA-SVM, and GAWA-SVM datasets produced the best outcome in terms of specificity. This proved that the GA-SVM and GAWA-SVM procedures are appropriate for software defect predictions when enforced on an enormous dataset.
Balogun et al.45 used NASA datasets from the PROMISE archives to thoroughly evaluate the FSS algorithms on NB, DT, LR, and KNN. Their findings imply that the studied FS techniques enhanced the system’s performance. Information Gain, one of the FFR techniques, demonstrated the best results. Consistency Feature Subset Selection (CFSS), based on the Best First Search in FSS methods, has the most significant impact on forecasting models. However, there were variations in the performances of the classifiers’ and datasets.’ Scientists have also found that models constructed using FFR-based techniques are more stable than those constructed using FSS-based approaches. This study focused only on FFS procedures, and the effects of the WFS techniques were not investigated in detail.
Table 1 presents the summary of the above-discussed literature, along with some recent advancements in software defect prediction.
| Author / Year | Objective | Description / Methods used | Findings |
|---|---|---|---|
| Das et al. 202332 | To propose a novel FS technique called FSGJO based on the Golden Jackal Optimization (GJO) algorithm to identify the best traits from a defect prediction dataset. | KNN, DT, NB, and QDA classifiers were employed using twelve SDP datasets extracted from the PROMISE project. The behaviour of the proposed FSGJO method was compared with other FS techniques, including FSDE, FSPSO, FSACO, and FSGA. | The proposed FSGJO method achieved enhanced accuracy compared with other studied FS techniques. On the drawback side, the suggested method requires parameter tuning. |
| Khalid et al. 202333 | To investigate various ML techniques and optimized ML processes on three NASA publicly available datasets. | The authors used ensemble and PSO techniques in their work and carefully examined the outcomes. | The SVM and optimized SVM performed better than the other models. This investigation used a small number of datasets, and other widely used optimization techniques were not explored. |
| Kumar and Das 202234 | To enforce Genetic Algorithm based FS technique to select fine traits from a defective dataset. | This study used classifiers like DT, NB, and KNN on twelve NASA datasets from the PROMISE archive. Accuracy and failure rate were used as performance measures. | The proposed FSGA technique enhanced the defect forecast model's behaviour. However, the impact of alternative optimization techniques still needs to be examined. |
| Thirumoorthy et al. 202235 | To propose a hybrid SDP approach to find the best set of attributes, based on the TOPSIS and hybrid Rao algorithms (THRO). | Using three benchmark NASA SDP datasets, the authors implemented their suggested THRO-based FS algorithm on SVM and NB classifiers. The impact of the suggested algorithm was evaluated using six metaheuristic FS approaches. | The suggested THRO-based FS algorithm improved the model's classification performance and outperformed other tested FS approaches. However, a shortcoming was the high computing cost. |
| Batool et al. 202236 | To provide a thorough and structured analysis of the body of existing literature. | Numerous pertinent published publications that employed DM, ML, and DL, among other techniques, for fault prediction were studied. The endeavour was motivated by the need to find answers to research problems stated in the evaluation that might not have been addressed in the works evaluated or called for a different viewpoint. | SDP regularly uses DM and ML techniques such as DT, NB, SVM, NN, ET, and EA. Researchers have also employed DL techniques, including CNN, MLP, LSTM, and DNN, to forecast software problems despite their less frequent application. |
| Chen et al. 202237 | To propose an SDP architecture based on stacked stacking and heterogeneous FS. This study's two main objectives were to increase SDP accuracy and optimize software testing resource allocation. | Two datasets, PROMISE and Kamei, were employed for the experiments. The study encompassed both large-scale cross-project defect prediction and within-project defect prediction. The AUC and F1-score assessment measures were used to show the model's behaviour. | The suggested approach outperformed the baseline models in terms of categorization for the two sets of software failure datasets. Nevertheless, nested stacking could be more effective and challenging trials were used to find the baseline model's ideal combination. |
| Arora and Kaur 202238 | To propose a heterogeneous fault prediction (HFP) model using FS on both origin and destination datasets to create a successful forecasting model using supervised training techniques. | For the FS, RFI was utilised. The suggested framework was used for the supervised machine learning classifiers SVM, NB, RF, AdaBoost, DT, and LR in two open-source projects, MySQL and Linux. The Area under the ROC curve (AUC) was used to grade the proposed model's behaviour. | The LR-based model was found to be the most accurate. According to the AUC data, the proposed method outperformed the current Cross Project Fault Prediction (CPFP). However, other popular measures like accuracy, precision, and recall were not used. Once more, no optimization methods were employed in the study. |
| Anand et al. 202240 | To evaluate the correlated performance of several FS methods used in SDP. | This study employed several filter-based FS techniques, including Chi-Square (CS), Correlation Coefficient (CC), Fisher's Score, Information Gain (IG), Mean Absolute Difference (MAD), and Variance Threshold (VT); Wrapper-based techniques like Recursive feature elimination (RFE), forward feature elimination (FFE), backward feature elimination (BFE), and exhaustive feature elimination (EFE); and embedded FS approaches including RFI and LASSO Regularisation. The suggested model used six publicly available benchmark NASA datasets for the NB, SVM, DT, and KNN classifiers. | Fisher's score behaved more precisely than other FS approaches. Nonetheless, every FS strategy improved the model's behaviour compared to the no-FS scenario. This study's failure to investigate how optimization tactics affect the FS is one of its shortcomings. |
| Balogun et al. 202141 | To introduce the dynamic re-ranking approach-based WFS technique to address the excessive processing costs of wrapper-based FS (WFS) approaches. | The suggested method was built using classifiers like DT and NB. It was based on 25 public domain datasets from the NASA, AEEEM, PROMISE, and ReLink archives. | The significant findings were improved performance and decreased computation time. The drawbacks of FFS and WFS approaches threatened the proposed work. Only two supervised and two other popular classifiers, SVM and K-NN, were not considered. |
| Balogun et al. 202142 | To suggest a creative hybrid multifilter wrapper FS configuration that uses rank aggregation to choose important aspects | Benchmark software fault datasets were used to demonstrate the effectiveness of the suggested approach, which employed NB and DT classifiers using the proposed method. The tests employed F-measure values, accuracy, and area under the curve (AUC) as evaluation criteria. | The suggested method greatly enhanced the model's behaviour. However, the model could only use two classifiers to get good results. As a result, the possibility of extrapolating the findings to other classifiers is yet to be investigated. |
| Alsghaier et al. 202043 | Combining the GA, SVM, and PSO to present an SDP model | The suggested model was tested using the SVM classifier on 24 benchmark SDP datasets (12 NASA MDP and 12 open-source Java apps). Evaluation criteria like accuracy, recall, precision, F-measure, specificity, error rate, and standard deviation were used to gauge the effectiveness of the created method. | When the GA was combined with SVM and PSO, the model's improved performance benefitted both small—and large-scale datasets. Nevertheless, the precision metric was inadequate and required improvement to evaluate the recommended techniques. |
| Alsghaier et al. 202144 | To foresee flaws, they combined the Whale Optimisation Algorithm (WOA), SVM, and GA, building on their previous work.43 | During the experiment, 24 benchmark SDP datasets (12 NASA MDP and 12 open-source Java apps) were used to test the proposed model using the SVM classifier. The efficacy of the developed method was assessed using evaluation criteria such as accuracy, recall, precision, F-measure, specificity, error rate, and standard deviation. | The GAWA-SVM yielded the lowest results for the datasets under investigation, while WA-SVM outperformed GAWA-SVM in accuracy. Regarding SD scores, the suggested approach fared better than SVM for all datasets. The GA-SVM and GAWA-SVM approach yielded the best specificity. This demonstrated the suitability of the GA-SVM and GAWA-SVM processes for software defect predictions when applied to a large dataset. |
| Balogun et al. 201945 | To comprehensively analyse the FSS algorithms on NB, DT, LR, and KNN. | They used NASA datasets from the PROMISE archives on NB, DT, LR, and KNN. | Information Gain emerged as the best FFR technique. Consistency Feature Subset Selection (CFSS), based on Best First Search in FSS techniques, significantly impacts the forecasting models. |
| Abdu et al. 202454 | To provide a defect prediction model using a deep hierarchical convolution neural network (DH-CNN) based on several source code representations. | Semantic-graph features collected from the control flow graph and data dependence graph using Node2vec were fed into semantic-level DH-CNN, while syntax features derived from abstract syntax trees using Word2vec were given into syntax-level DH-CNN. Furthermore, the suggested model incorporated a gated merging method that combined DH-CNN outputs to estimate the ratio of both feature types. | In both cross-project and within-project scenarios, DH-CNN performed better than current techniques. |
| Abdu et al. 202455 | To suggest a unique defect prediction model that leverages a hybrid deep learning approach to combine traditional and semantic information. | A CNN-MLP hybrid classifier was used, where semantic characteristics were retrieved from projects' abstract syntax trees (ASTs) using Word2vec and processed by the CNN. A multilayer perceptron (MLP) processed the conventional features taken from the dataset repository. After integration, the CNN and MLP outputs were sent into a fully connected layer for defect prediction. Extensive testing was done on several open-source applications to confirm CNN-MLP's efficacy. | CNN-MLP significantly improved defect prediction performance. Additionally, CNN-MLP performed better than current techniques in effort-aware and non-effort-aware scenarios. |
| Abdu et al. 202356 | To propose a graph-based feature learning model for Cross project defect prediction (GB-CPDP). | Used Long-Short-Term Memory (LSTM) networks to learn predictive models. Node2Vec was used to convert CFGs and DDGs into numerical vectors. Nine open-source Java programs from the PROMISE dataset were used. F1-measure and Area under the Curve (AUC) were the performance measures. | The experimental evaluation showed that GB-CPDP performed better than state-of-the-art CPDP techniques. The outcomes demonstrate how well GB-CPDP works to enhance cross-project defect prediction performance. |
| Abdu et al. 202257 | To methodically illustrate current software defect prediction methods based on the salient characteristics of the source code. | Ninety of the 283 articles on software defect prediction that were the subject of an extensive literature assessment were critically reviewed by analysing the semantic feature approaches to present critical problems and challenges. | Such an extensive survey may help research communities determine the present issues and potential avenues for future investigation. |
All the previously stated FS approaches, whether supervised or unsupervised, have disadvantages that significantly impact the model’s performance, including (i) high cost, (ii) entrapment in local optima, (iii) low convergence rate, and (iv) fine-tuning of excessively many parameters. The primary drawback of the previously stated FS techniques is the need to modify the regulating parameters accurately while choosing ideal characteristics. These shortcomings motivated us to propose a novel FS technique (FSCOA) that draws inspiration from the Chernobyl Disaster Optimizer (CDO).30 The 1986 nuclear reactor core outburst in Chernobyl served as an impetus for the development of the CDO meta-heuristic algorithm. The process of nuclear radiation, in which alpha, beta, and gamma fragments propagate and damage humans following an explosion, is replicated by CDO. From the high-pressure point (explosion site) to the low-pressure point (individual standing), the above-mentioned radiations travel extremely rapidly. The algorithm comprises an initial population of potential solutions. Moreover, it calculates the alpha, beta, and gamma fragment gradient descent factors (GDF) during human attacks. Determining the average of these GDF values over several iterations yields the best result.
Feature selection determines the crucial attributes that have the greatest impact on the desired variable, which helps increase machine learning model accuracy, reduce computing costs, and reduce the risk of overfitting. The mechanism of selecting the best features begins with creation of a set of subgroups of attributes. Further, the adequacy of these subgroups is assessed and compared to determine which subgroup is the best or until the abort standards are met. In the final lap, the subgroup with best features is incorporated to build the defect forecasting model to compute the predictive accuracy. The 1986 Chernobyl nuclear reactor catastrophe46 is recognized as one of the lowest nuclear disasters in the modern human past, in terms of both cost and casualties. Inspired by the Chernobyl nuclear reactor core eruption, the Chernobyl Disaster Optimization (CDO)30 is a meta-heuristic optimization technique. In order to choose the most appropriate subset of characteristics for classification, a novel FS approach using Chernobyl Optimization Algorithm (FSCOA) is therefore proposed in order to address the aforementioned problem. Figure 158 shows the blueprint for the proposed FSCOA method.
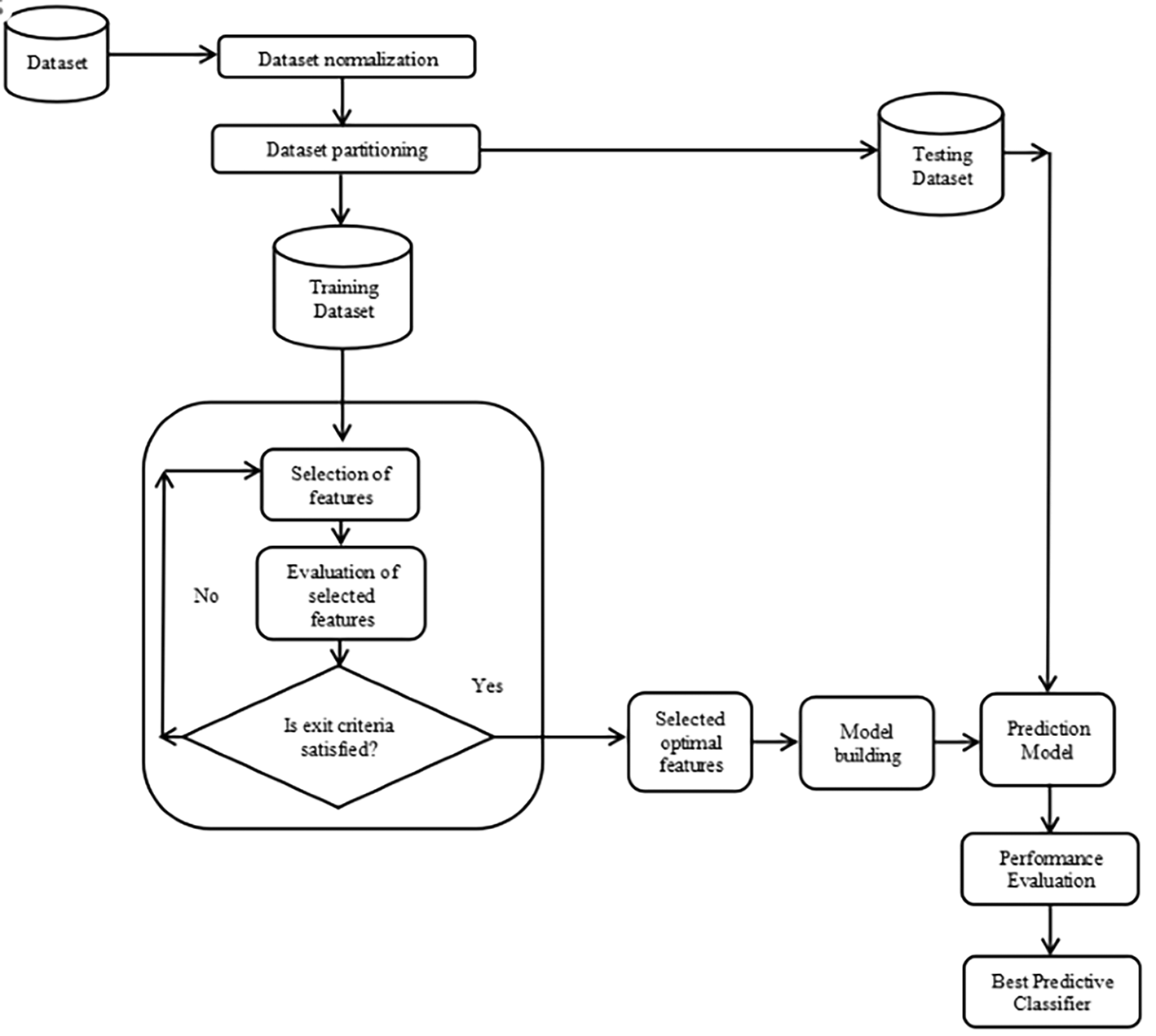
This study suggests a novel FSCOA technique for selecting the first-rate subgroup of attributes for categorization. The primary intent of the recommended technique is to identify the best attribute combination that will lower the model’s fitness. Broadly, the proposed methodology has been implemented in the following three steps:
Step-1: First, the selection of the relevant SDP datasets is crucial. Twelve publicly benchmarked NASA software defect datasets taken from the PROMISE archive48 were used to assess the persuasiveness of the suggested FSCOA strategy. The datasets were AW1, PC1, PC2, PC3, PC4, KC1, KC3, CM1, JM1, MC1, MC2, and PC5. Following the selection of the datasets, an in-depth examination of the datasets was carried out to determine any missing, inconsistent, or categorical data. It became apparent that there were no missing data in the datasets. Nevertheless, a few datasets contained categorical data. The data were categorized prior to the generation of the numbers. Furthermore, the original feature value ranged from 0 to 1 and was normalized. Subsequently, an 80:20 split between the training and testing datasets was created for each normalized dataset.
Step-2: The two preeminent criteria to develop and investigate the model are the population size and maximum number of iterations. Higher values will improve the model’s performance will also lengthen the computation time. In this study, the population size and maximum tally of the iterations were set to 30 and 200, respectively.
Step-3: By applying the recommended FSCOA methodology, four supervised learning classifiers (DT, KNN, NB, and QDA) were used to construct the model using the optimal features that were chosen. The best predictive classifier was then determined by comparing the accuracy of the proposed FSCOA approach with that of the other FS models under study.
Figure 258 shows a complete flow diagram of the proposed FSCOA technique.
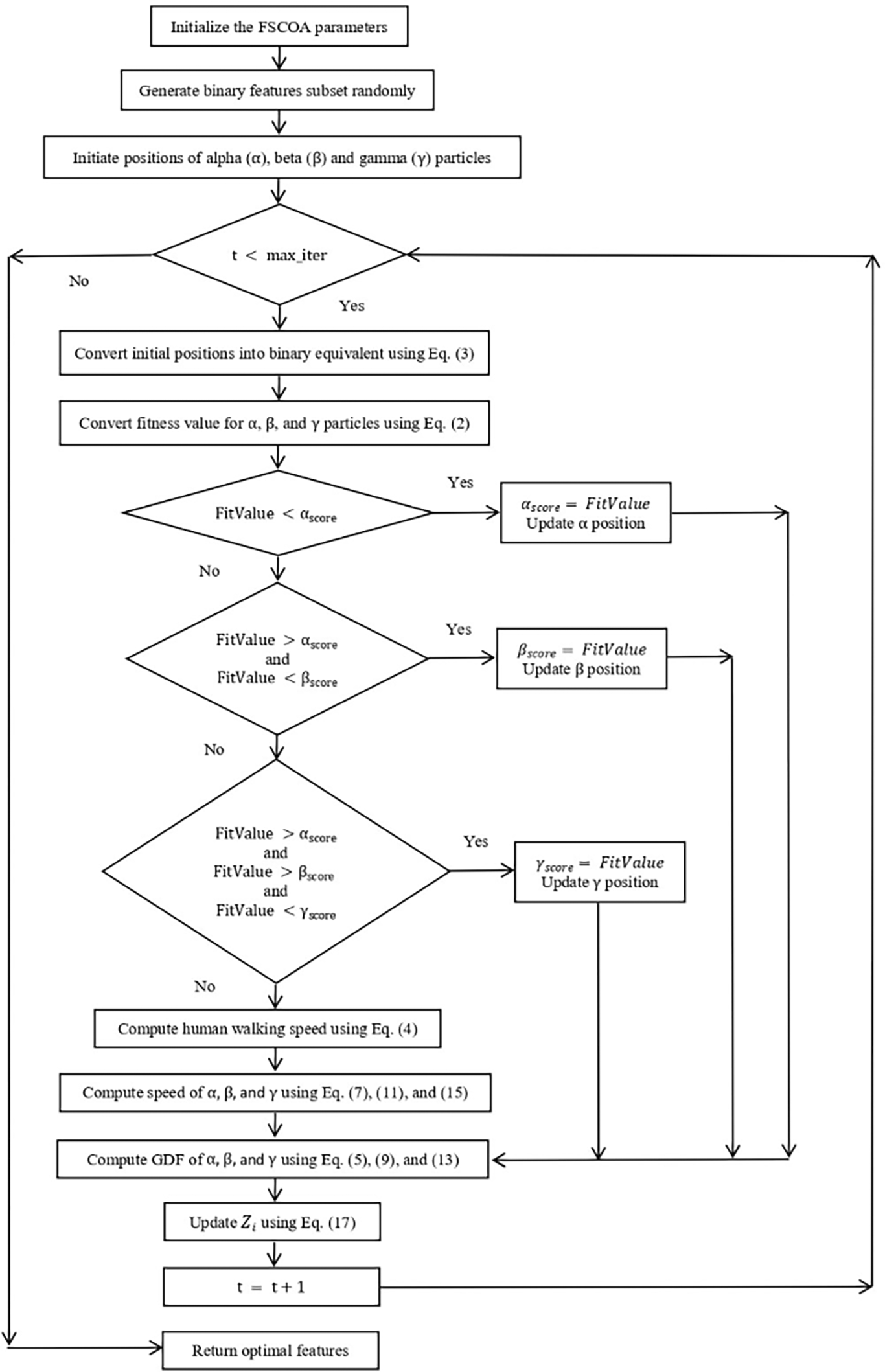
Initializing the criteria, such as population size , problem dimension , lower bound , and upper bound , is the first step of the procedure. Subsequently, a random binary population of fragments with dimension F, where is the total number of features. is the fragment location in the dimension feature space, where is the specimen proportion, and is the fragment standing of the trait of the population. Many classification techniques, including DT, KNN, NB, and QDA for fitness (error) computation, have been considered for the examination of randomly selected characteristics. The FS algorithm aims to select the best subset of ideal features that may reduce the fitness of the learning algorithm. The error is estimated as the disparity between the estimated outcome and actual outcome . Eq. (1) can be used to describe this phenomenon.
By distributing the aggregate of the total errors by the entire count of instances in the testing data, the fitness ( ) of the learning algorithm was calculated. This is characterized by Eq. (2).
Here, and represent the tally of the instances in the trial data, represents the current iteration.
The transfer function depicted in Eq. (3) was employed to transform the initial fragment standings into a binary equivalent.
The proposed FSCOA approach employs the CDO algorithm to determine the optimal features for a given dataset. In CDO, different types of emissions are released from the nuclei as a result of radioactivity caused by nuclear instability. The most prevalent types of these emissions are alpha, beta, and gamma fragments. These fragments, which are very dangerous to people, fly from a high-pressure point (the point of explosion) to a low-pressure point (the standing of individual standing). When a human is attached to a CDO following a nuclear explosion, it simulates the effects of radioactive decay. The primary processes of nuclear explosion and human attachment require the use of gamma, beta, and alpha fragments. Humans were most likely to be on foot when they were attacked. Human walking speed can be enhanced, and it can be estimated to be between 0 and 3 miles per hour.47 Based on this, Eq. (4) can be used to model linear reduction at this speed.
Alpha fragment
The gradient descent factor of the alpha fragment while threatening humans can be computed using Eq. (5).
Here, is the prevailing standing of alpha fragments, represents the dispersion of alpha fragments and can be calculated using Eq. (6); is the discrepancy between the individual standing and standing of alpha fragments, which can be determined using Eq. (8).
Here, is a random value between 0 and 1, is the speed of alpha fragments that can be in the range of 1–16,000 kmps. This can be normalized using Eq. (7)
Here, is the propagation area of gamma fragments that can be calculated as where is a random value between 0 and 1, is the average of the total standings that can be determined using Eq. (17).
Beta fragment
Eq. (9) can be used to determine the gradient descent factor of a beta fragment assaulting a human.
Here, is the current standing of beta fragments; represents the propagation of beta fragments and can be calculated using Eq. (10); is the discrepancy between the human standing and the beta fragment’s standing, which can be determined using Eq. (12).
Here, is a random value between 0 and 1, is the speed of beta fragments that can be in the range of 1–270,000 kmps. This can be normalized using Eq. (11)
Here, is the propagation area of the beta fragment and can be calculated as where is a random value between 0 and 1. is the average of the total standings that can be computed using Eq. (17).
Gamma fragments
The gradient descent factor of the gamma fragment while making an assault on humans can be computed using Eq. (13).
Here, is the prevailing standing of gamma fragments, represents the dispersion of gamma fragments and can be calculated using Eq. (14); is the discrepancy between the standing of the human and the standing of gamma fragments, which can be determined using Eq. (16).
Here, is a random value between 0 and 1, is the speed of the gamma fragment in the range of 1 to 300,000 kmps. This can be normalized using Eq. (15)
Here, is the propagation area of gamma fragments that can be calculated as where is a random value between 0 and 1, is the average of the total standings that can be determined using Eq. (17).
Finally, Algorithm 1 provides a summary of the entire proposed FSCOA process.
1. Initialize Populace Size , Dimension , Lower Bound , UpperBound , Maximum Iteration
2. Generate the binary feature subset randomly
3. Initialize the alpha ( ), beta ( ), and gamma ( ) standings
4. while do{
5. for : M do
6. for F do
7. The values of the initial standing of the fragments are converted into their corresponding binary values using Eq. (3).
8. Compute the fitness value for the alpha, beta, and gamma fragments using Eq. (2)
9. if
10.
11. Update
12. endif
13. if
14.
15. Update
16. endif
17. if
18.
19. Update
20. endif
21. end for
22. end for
23. Compute human walking speed using Eq. (4)
24. Compute the speed of alpha , beta , and gamma fragments using Eq. (7), Eq. (11), and Eq. (15), respectively.
25. for : M do
26. for : F do
27. Determine using Eq. (5)
28. Determine using Eq. (9)
29. Determine using Eq. (13)
30. Update using average of total standings using Eq. (17)
31. end for
32. end for
33.
34. } //end of while loop
35. Return finest solution,
36. end procedure
This section deliberates on the empirical findings of this research. The persuasiveness of the proposed FSCOA approach was graded by employing 12 publicly benchmarked NASA software defect datasets extracted from the PROMISE archive.48 KC1, KC3, CM1, JM1, MC1, MC2, MW1, PC1, PC2, PC3, PC4, and PC5 were the datasets. First, an in-depth examination of the datasets was performed to identify missing, inconsistent, and categorical data. It became apparent that there were no missing data in the datasets. Nevertheless, a few datasets contained categorical data. The data were categorized prior to the generation of the numbers. Again, we noticed that the datasets comprised of continuous data. The datasets were altered using the min–max normalization method49 with the goal of overcoming this problem. The original feature value, which originally ranged from zero to one, was transformed using this technique. Subsequently, an 80:20 split between the training and testing datasets was created for each normalized dataset. Extensive information regarding the datasets enforced in this exploration is shown in Table 2.
The configuration of the computer on which the experiments were administered was as follows: Intel Core i5-6200 CPU with clock rate 2.40 GHz and 8 GB RAM. The aforementioned techniques were employed in a Python 3 environment using the Jupyter notebook. First, the input dataset was uploaded using Pandas. The datasets were altered using the min-max normalization method.49 Using train_test_split from sklearn.model_selection, the dataset was partitioned into training and testing datasets at a ratio of 80:20. Populace size and the highest number of iterations were the two primary criteria for developing and validating the model. The model will provide superior outcomes with higher values, but it will also increase computing time. In this investigation, the population size and highest number of iterations were set to 30 and 200, respectively. Four supervised learning classifiers, DT, KNN, NB, and QDA, were used to assess the behaviour of the proposed FSCOA approach. Further, the conduct of the proposed technique has been correlated with the some of the widely used FS techniques namely FSDE, FSPSO, FSGA, FSACO. The fitness error plots for the suggested FSCOA approach and other studied FS strategies utilizing the examined classifiers, DT, KNN, NB, and QDA, were obtained using matplotlib.pyplot. This study used accuracy, a frequently applied performance indicator metric, for assessment purposes. Accuracy can be expressed as a simple proportion of the total instances of instances that were correctly classified. Eq. (18) is used to calculate it from the confusion matrix, as follows:
Here, , , , and represent true positives, true negatives, false positives, and false negatives, respectively.
The performance of the recommended FSCOA algorithm is evaluated against several other FS procedures such as FSDE, FSPSO, FSGA, and FSACO in terms of classification accuracy and the count of selected attributes on 12 datasets studied in this research work. Because of the stochastic character of the previously mentioned techniques, we carried out ten runs of the trials to ensure that the performance of each procedure remained persistent, with an initial random population. The median accuracy of the proposed FSCOA, along with the other studied FS approaches, is listed in Table 3.59
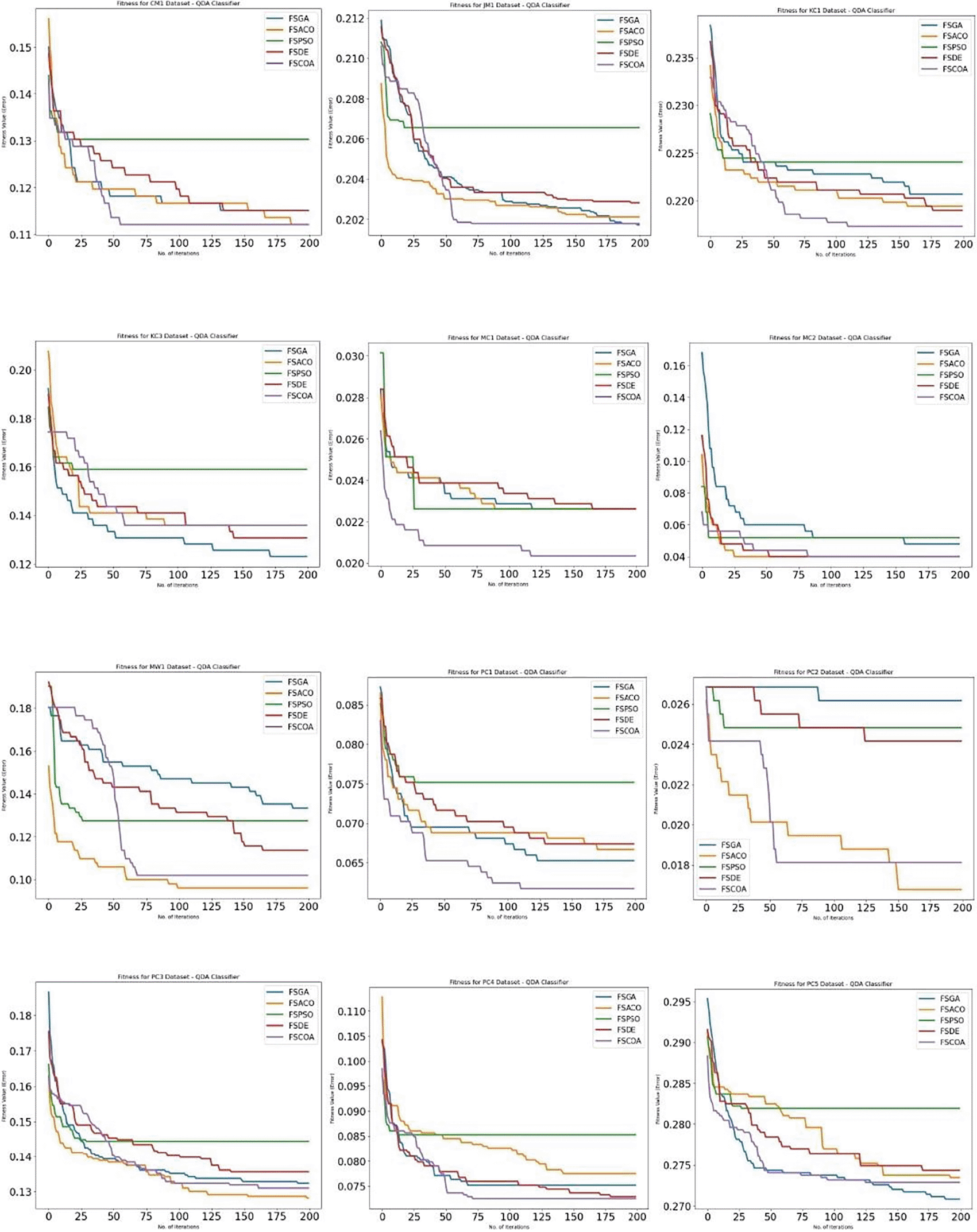
The median accuracy of several classifiers forced on diverse datasets, both with and without feature selection, is shown in Table 3. The table also displays the average tally of the attributes selected by the respective FS approach. The classifiers were evaluated using a range of datasets and previously discussed FS techniques. The experimental findings showed that the suggested FSCOA technique exceeded the other studied FS procedures in the majority of instances. The baseline methods studied in this work, such as FSPSO, FSDE, FSGA, and FSACO, suffer from several drawbacks, such as local optima trap, slow convergence rate, low accuracy, and parameter tuning. The proposed FSCOA technique addresses many of these limitations as it has ability to discover and search any domain of search space with good efficiency and speed and quickly escape from local minima. For most of the datasets, with the exception of KC1, KC3, JM1, and MC1, the suggested FSCOA performed best when combined with KNN. With the exception of KC1, MC1, and CM1, the bulk of the datasets showed that the recommended FSCOA worked best when paired with NB. The majority of the datasets demonstrated that the suggested FSCOA performed best when combined with QDA, with the exception of KC3, MW1, and PC5. With the exception of JM1, the majority of the datasets showed that the previously researched FS approaches outperformed the suggested FSCOA strategy when used in conjunction with DT. Similarly, applying the proposed FSCOA technique to the JM1 dataset with all the analyzed classifiers, except KNN, yielded the highest accuracy. Furthermore, the bulk of the datasets yielded the best accuracy for all examined classifiers, with the exception of DT. It is crucial to remember that the suggested FSCOA technique could only provide the best prediction using QDA and NB classifiers for the KC1 and KC3 datasets, respectively.
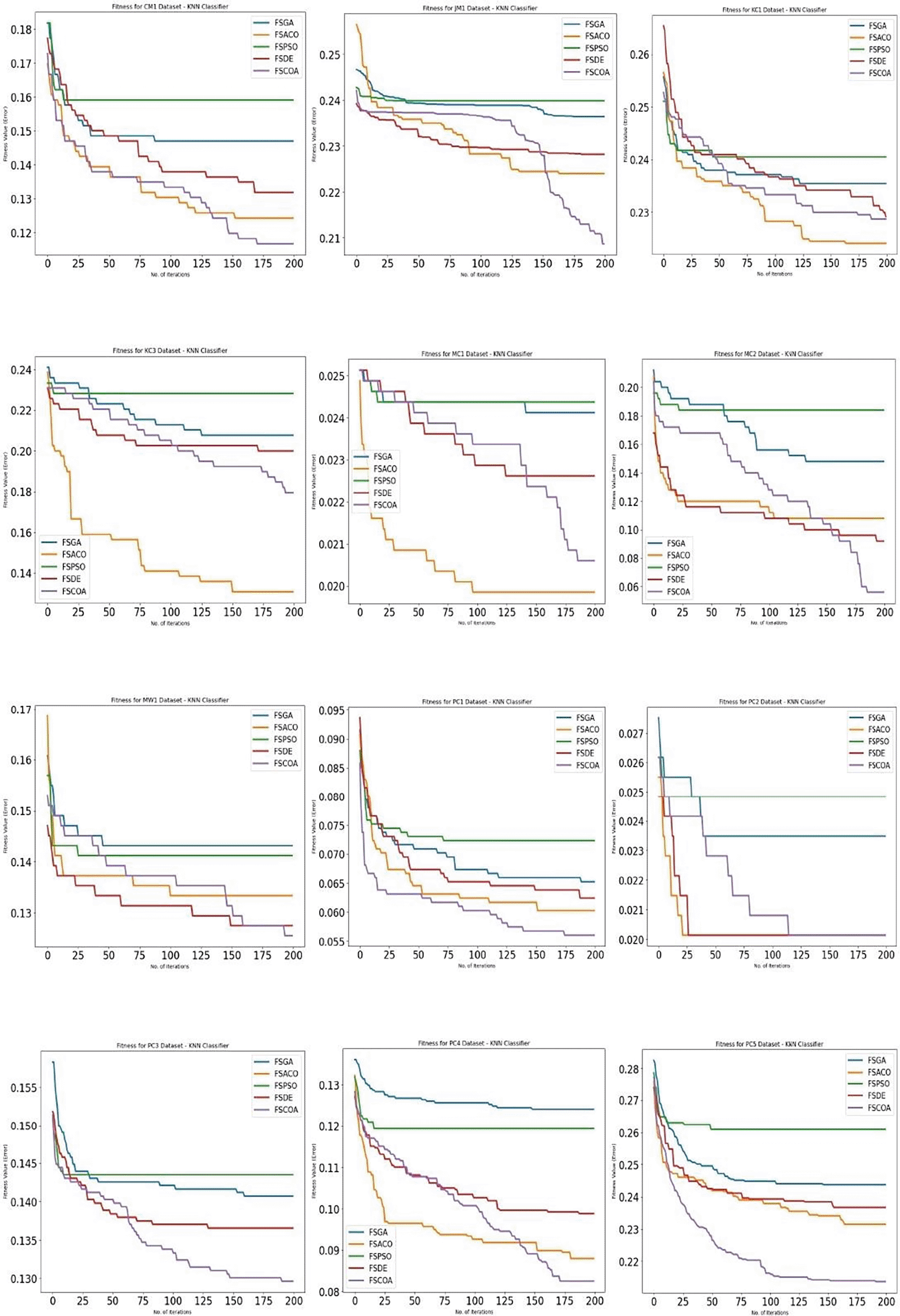
Figures 3 through 658 display, respectively, the fitness error plots for the suggested FSCOA approach and other FS strategies utilizing the examined classifiers DT, KNN, NB, and QDA. Error plots of all 12 datasets are included in each graph. The error plots show that in most cases, the error plot of the suggested FSCOA is smaller than those of the other FS approaches employed in this investigation. Furthermore, the error plot of the suggested FSCOA methodology matches that of the various existing FS methods. However, the error plot of the suggested FSCOA approach exceeds that of the other FS techniques that have been evaluated under certain circumstances.
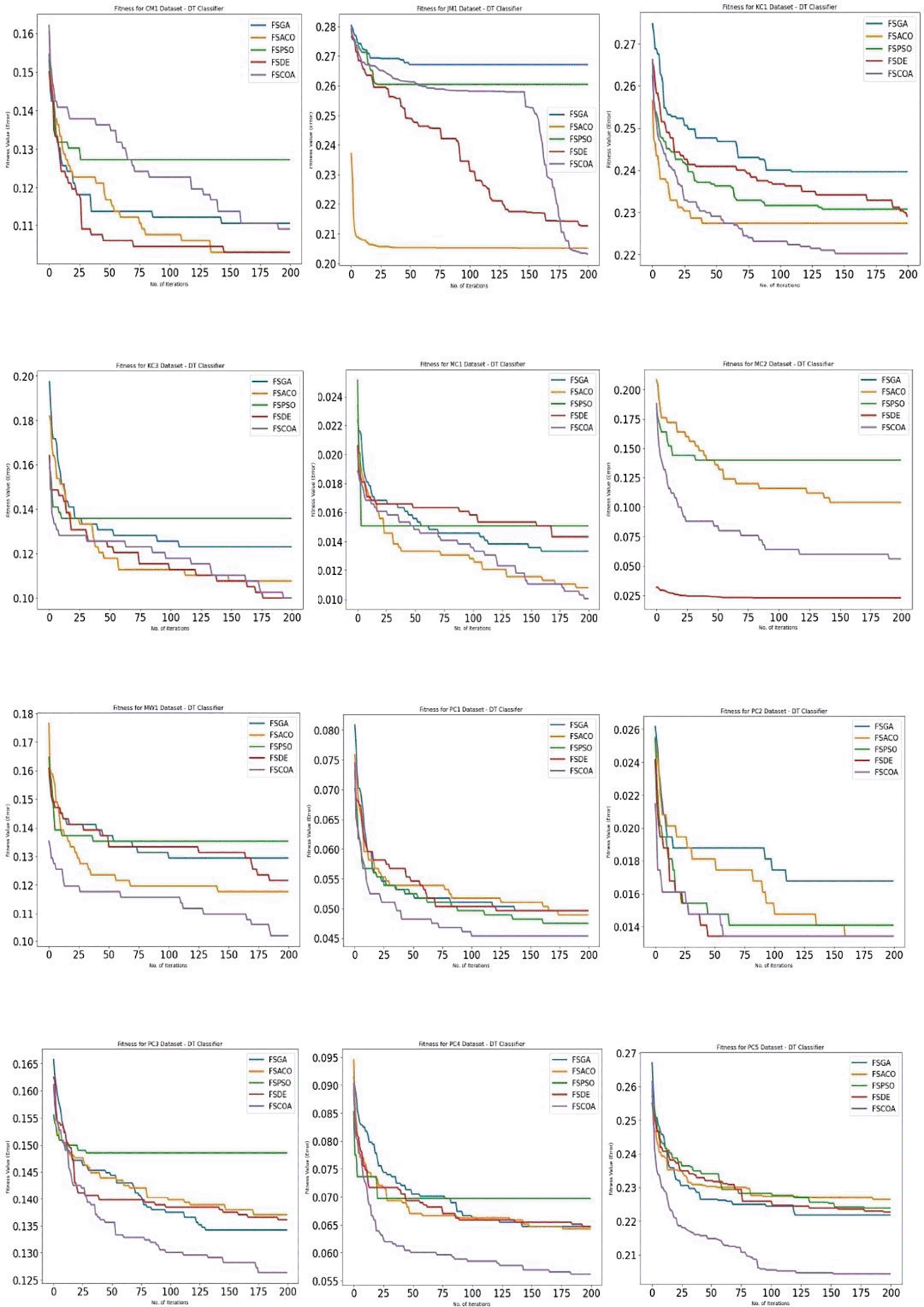
Figure 358 shows that in most datasets, the fitness error plot of the proposed FSCOA approach using the DT classifier is smaller than that of the other FS models, with the exception of CM1, MC2, and KC3. However, for the KC3 dataset, the error plot overlapped with that of the FSDE after 190 iterations. The error plot for the CM1 dataset is located above the FSDE and FSACO. Furthermore, the plot for the MC2 dataset is above the FSDE.
The fitness error plot of the proposed FSCOA approach with the KNN classifier is lower than that of the previous FS models for most datasets, as shown in Figure 4,58 with the exception of KC1, KC3, MC1, and PC2. The error plot after 115 iterations corresponds to FSDE and FSACO for the PC2 dataset, but it is above the FSACO model for the KC1, KC3, and MC1 datasets.
As shown in Figure 5,58 the fitness error plot of the suggested FSCOA technique with the NB classifier was lower in the majority of datasets than that of the prior FS models, with the exception of CM1, KC1, MC1, PC2, MC2, and PC3. After 75 iterations, the error plot for the MC2 dataset matches that of FSACO. For the PC3 dataset, the error plot of the suggested FSCOA method matches that of FSACO after 175 iterations. However, for datasets CM1, KC1, and MC1, the error plot was above that of the FSACO model. Moreover, for PC2 and KC1, the plot was above the FSDE.
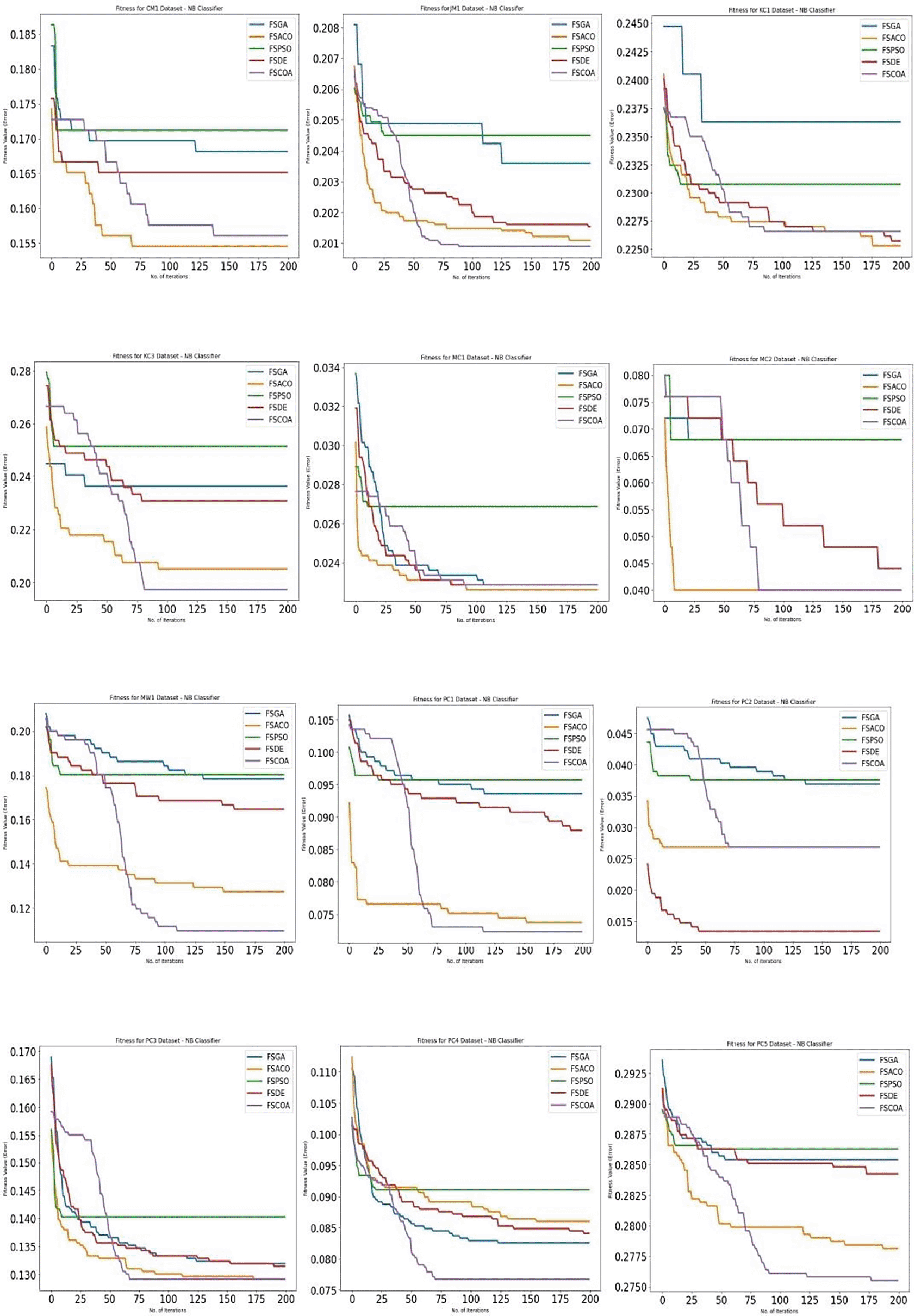
Figure 658 illustrates that for most datasets (except CM1, JM1, KC3, MW1, PC2, and PC3), the fitness error plot of the proposed FSCOA approach with the NB classifier is smaller than that of the previous FS models. Following 180 iterations, the CM1 dataset’s error plot aligns with that of the FSACO dataset. The error plot of the proposed FSCOA algorithm matches that of FSGA after 175 iterations for the JM1 dataset. The error plot is above that of the FSACO model for datasets MW1, PC2, and PC3. The graphic is also above FSGA and FSDE for the KC3 dataset. The error plot of the proposed FSCOA approach is above that of FSGA for the PC3 dataset.
The FS algorithms employed in this study use several hyperparameters. For 200 iterations, an examination was performed with a population size of 30. The crossover rate in FSGA and FSDE was maintained at 0.8 and 0.9, respectively. For FSGA, the mutation rate is 0.01. In the FSDE, the scaling factor was set to 0.8. In FSPSO, the maximum inertia weight and the minimum inertia weight have been fixed as 0.9 and 0.4 accordingly. Two were chosen as the acceleration factors. The fixed values of alpha , rho , and beta in FSACO were 1, 0.2, and 0.1, respectively. The governing criterion speeds for alpha , beta , and gamma were adjusted appropriately for FSCOA using the Rand function. In addition, the radiation propagation radius was similarly fixed between 0 and 1 using the rand function.
This section provides extensive statistical scrutiny of the empirical findings of this work. Statistical analysis50 is a popular method for quantifying, examining, evaluating, and drawing conclusions from data. Tests classified as parametric or non-parametric were the two breeds used for statistical analysis. A type of statistical analysis, known as parametric statistical testing, assumes that the data under study conform to a specific probability distribution, most frequently a normal distribution. Several assumptions, such as the independence of observations, homogeneity of variance, and normality, must hold true to employ parametric tests. Ensuring that the assumptions are met is essential when conducting a parametric test, because failing to do so may result in erroneous results and invalid conclusions. Therefore, it is crucial to confirm these hypotheses in advance and, if necessary, to use non-parametric validation. A type of statistical scrutiny known as non-parametric statistical testing does not depend on a specific probability distribution hypothesis for the data under study. Non-parametric validations, on the other hand, are more broadly applicable and resilient to assumption violations than parametric tests because they depend on the hierarchy or placement of the data. However, when the presumptions of the parametric validations are satisfied, they might be less effective than the latter. It is essential to choose a statistical validation suitable for an exploration topic and the properties of the data being examined. In this study, the Friedman Test,51 a non-parametric rank-based test, has been carefully considered. Based on the effectiveness of the classification, each model associated with the trial was ranked according to the Friedman test. The lowest count correlates with the greatest slot and the largest count correlates with the smallest slot.
To begin with, Eq. (19) was employed to determine the average rank ( ) of all graded models (FSDE, FSPSO, FSGA, FSACO, FSCOA, and Without FS), in addition to a number of classification models (KNN, DT, NB, and QDA). Table 459 presents an illustration these findings.
Table 559 summarizes the findings of grading the median of all ranks of diversified amalgamation setups (FSDE, FSPSO, FSGA, FSACO, FSCOA, and Without FS) for all the datasets used in Eq. (20).
The following are the average ranks for all the correlated configurations included in this observation. . The median ranks of the models were employed to gauge the statistics, referred to as using Eq. (21) and a presented value of 23.29.
Twelve datasets (B=12) and six models (A=6) were considered in this experiment. The Friedman statistic ( ) value was computed using Eq. (22) using (B − 1) and .
The value of ( ) estimated to be 6.978. The critical value was determined as 2.383 by employing the degrees of freedom as (6 − 1 = 5) × (12 − 1 = 11) and (6 − 1 = 5), with α = 0.05, as the significance level. Given that the critical value of 2.383 is smaller than that of the Friedman statistic ( = 6.978), the null hypothesis is rejected. It also determines whether to adopt an alternate theory. This implies that two or more configurations are distinct from one another. The Holm method is usually employed to investigate the Post Hoc test after the null hypothesis is jilted and the substitute hypothesis is endorsed. By employing the Holm technique, the and were applied to assess how well each distinct model performed relative to the other models.52 Eq. (23) was used to obtain the value of z. The and normal distribution table were used to calculate the value of .
In this experiment, the terminologies B, A, and represent the number of datasets, number of configurations employed in this investigation, and value of z, respectively. The terms and represents the average rank of and model, respectively. The , e, and of the recommended configurations were compared, and Table 6 summarizes the findings. For this particular instance, we set the significance level, α, at 0.05.
Table 659 illustrates that in most cases, the p-value is lower than or equivalent to the value of with the exception of the FSCOA and FSGA models and FSCOA and FSACO models. It resolves that the FSCOA model is statistically noteworthy and attains a superior dossier when matched to other configurations, excluding the FSGA and FSACO models. However, there was no statistically significant variation in the performances of these models.
Any factual study must analyze the threats to the reliability of its investigatory observations and address them appropriately. This section reports the menace to the validity of the recommended procedure specified in this experiment.
• This research has utilized twelve standard public NASA datasets extracted from the PROMISE archive. However, the implication of the proposed FSCOA approach’s behaviour on the real-world project datasets largely remains unclear.
• The behaviour of the fault forecasting model largely depends on the selected applications, applied classification methods, and the quality aspects of the datasets.53 This experiment employed four supervised learning classifiers, DT, KNN, NB, and QDA, to choose the finest traits from a software defect dataset using popular optimization algorithms such as DE, PSO, ACO, and GA, along with the suggested FSCOA approach. However, the behaviour of the proposed approach may have a varied impact on its performance when combined with other meta-heuristic approaches and classifiers.
• To gauge the efficacy of the proposed FSCOA approach, this study utilized a well-known evaluation criterion known as accuracy besides fitness error. Several other performance measure metrics can be applicable to precisely examine the impact of the proposed approach on the suggested defect prediction model. Again, the study, in its current form, used two widely used statistical tests to establish the model’s validity. This may restrict the statistical findings of the suggested defect prediction model.
This study proposed a novel FS approach, based on a meta-heuristic approach called Chernobyl Disaster Optimizer (CDO), referred to as FSCOA to select the finest traits from a software defect dataset that can significantly enhance the predictive accuracy of the defect forecasting model. The proposed FSCOA technique exhibits nuclear core reactor disruption to determine the best attributes by carefully discarding irrelevant or insignificant ones. This study investigates the impact of the proposed FSCOA approach on twelve publicly available NASA datasets, taken from PROMISE archieve, by employing four widely used classifiers (DT, KNN, NB, and QDA). The proposed work was intended to enhance the classification of the defect prediction model using the optimal features. Besides, another purpose was to correlate the predictive behaviour of the proposed FSCOA approach with other existing FS techniques, namely, FSDE, FSPSO, FSACO, and FSGA. The experimental data suggested that the proposed FSCOA technique bettered the predictive performance of the defect forecasting model. Further, the statistical validity of the proposed FSCOA-based forecasting model was investigated by applying the Friedman test. The test outcome showed that at least two models were significantly different, leading to the repudiation of the null hypothesis. This necessitates the use of the Holm test. In this regard, the experimental findings suggested that the proposed FSCOA approach demonstrated higher performance when selecting the optimal set of features correlated to the studied FS procedures. However, the behaviour of the proposed FSCOA approach may vary across different datasets and classifiers. In the future, we aim to expand the scope of this research by employing real-world project datasets. We also look forward to investigate the efficiency of the suggested FSCOA approach by increasing the count and variety of classifiers, especially ensemble classifiers, and employing more optimization algorithms for feature selection along with exploring other widely used performance measures.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)