Keywords
Machine learning, feature extraction, image classification, medical imaging, precision medicine, Convolutional neural networks, Deep learning, low resources environments.
Machine learning, feature extraction, image classification, medical imaging, precision medicine, Convolutional neural networks, Deep learning, low resources environments.
Medical imaging performs a significant role in modern medicine. Its advent has revolutionized diagnosis, treatment planning, and monitoring of various diseases.1 Techniques such as magnetic resonance imaging (MRI), X-ray, ultrasound, and computed tomography (CT) scans among others provide non-invasive methods to visualize the interior structures of the body, enabling timely discovery of conditions like cancer, cardiovascular diseases, and neurological disorders.2 Accurate diagnosis and effective treatment strategies are achieved traditionally by employing the services of experienced radiologists to reliably interpret these images. However, the continuous increase in volume of medical imaging data produced poses significant challenges, necessitating the development of automated and efficient image analysis methods.3
Machine learning (ML) and consequently deep learning (DL) has surfaced as a formidable means of handling the complexities resulting from the presence of vast amounts of medical imaging data.4 Among other use cases, image classification has been a key application area where, ML algorithms aim to automatically classify images into pre-defined classes. This is particularly valuable in medical diagnostics, where rapid and accurate classification of images can significantly improve the clinical decision-making process and treatment outcomes.5
Convolutional Neural Networks (CNNs) have demonstrated remarkable excellence in image classification tasks, outperforming traditional ML methods and even human performance in certain scenarios.6,7 The hierarchical structure of CNNs allows them to effectively capture spatial hierarchies and intricate features within images making CNNs particularly well-suited for medical imaging.8 Notable successes of CNNs in medical imaging include the detection of lung cancer,9 breast cancer,10 diabetic retinopathy,11 classification of skin lesions,12 and segmentation of brain tumours,13 among others. Despite their advantages, the adoption of CNNs in low-resource environments faces several hindrances such as high computational costs, energy constraints, limited annotated datasets, network connectivity issues, hardware constraints (storage and memory limitations), and limited technical expertise. In addition to increased time complexity, training CNNs requires substantial computational resources, including large amounts of memory and powerful graphics processing units (GPUs), which may not be available in resource-constrained settings.14 These challenges necessitate the development of more accessible and efficient solutions for deploying CNNs in low-resource environments.
In many image classification experiments, CNNs are not only used as classifiers but also as feature extractors.15 Feature extraction (FE) is a fundamental aspect of image classification. Traditionally, this process relied on manual techniques and domain-specific knowledge to design features that could be fed into ML algorithms. However, CNNs have revolutionized feature extraction by automating this process. Through the successive layers of convolutions and pooling, CNNs can learn to extract hierarchical and informative features directly from raw image data, eradicating the need for handcrafted feature engineering.16 By leveraging the pre-trained layers of a CNN, researchers can extract features from images and use them as inputs to other ML algorithms or for further analysis.15
This study investigates the use of pre-trained CNNs as feature extractors in medical imaging analyses and emphasizes the important factors to consider when utilizing these extractors. Questions answered by this study include:
1. What is the overall impact of using the feature extractors? What is the best feature extractor?
2. What is the impact of data imbalance on the performance of the models?
3. What is the impact of the number of classes on the performance of the models?
4. What is the impact of the number of images on the performance of the models?
5. Which model benefits most from the use of feature extractors?
The remainder of this paper is structured as follows: Section 2 covers the methods. In Section 3, we present the results for our experiments and provide critical discussions in Section 4. Finally, we end with a conclusion and the lessons learned.
Eight image datasets were used in this study. Table 1 presents the description as well as the links to each of these datasets.
| class | Designation | Disease | nImages | nClasses | Distribution | link |
|---|---|---|---|---|---|---|
| Binary | DS1 | Malaria | 27,558 | 2 | Balanced | 17 |
| DS2 | COVID-19 | 800 | 2 | Balanced | 18 | |
| DS3 | Breast Cancer | 7909 | 2 | Imbalanced | 19 | |
| DS4 | Skin Cancer | 9605 | 2 | Imbalanced | 20 | |
| Multiclass | DS5 | Brain Tumor | 3264 | 4 | Imbalanced | 21 |
| DS6 | Lung and Colon Cancer | 25,000 | 5 | Balanced | 22 | |
| DS7 | Skin Lesions | 10,000 | 7 | Imbalanced | 23 | |
| DS8 | Colorectal Cancer | 5,000 | 8 | Balanced | 24 |
CNNs have proven to be very beneficial in image preprocessing and classification. The deep (convolutional and pooling) layers in CNN architectures enable them to obtain highly descriptive features that leads to better representation of images in a dataset.25,26 In this study, three pre-trained CNNs were used, they include VGG-16,27 EfficientNet-B0,28 and ResNet-50.29 These feature extractors were implemented with default settings in python using the Tensorflow framework.30
Five ML algorithms were utilized in this study. They include logistic regression (LR),31 k-nearest neighbours (KNN),32 naive Bayes (NB),33 radom forests (RF),34 and light gradient boosting machine (LGBM).35 LR, NB, KNN and RF were executed in python via the Scikit learn library,36 while LGBM was implemented using the stand-alone python library developed by its authors.37
Using ten-fold cross validation, the models’ performances were evaluated and benchmarked using the following performance metrics; time and memory requirements, accuracy, sensitivity, specificity, AUC-ROC, MCC, precision, and F1-score. To eliminate bias from excessive hyperparameter tuning, all models’ parameters were left at their default values. As RF and LGBM are affected by randomization, we used a “random state” parameter to ensure reproducibility. All random states were set to zero and other parameters were set to default values.
All images were resized into an array of 224 by 224 pixels with 3 colour channels to prevent disparities due to image size. For each of the (n=8) datasets, five ML algorithms were used. To ascertain the impact of the three FE techniques, the baseline performance of each ML algorithm was obtained followed by the performance of the models after FE with each of the FE techniques. As a result, 160 (8 × 5 × 4) experiments were conducted. These experiments were conducted on a server featuring 20 Intel(R) Xeon(R) Silver 4210R CPU processors, 526GB of RAM, and running the Ubuntu 22.04.4 LTS operating system.
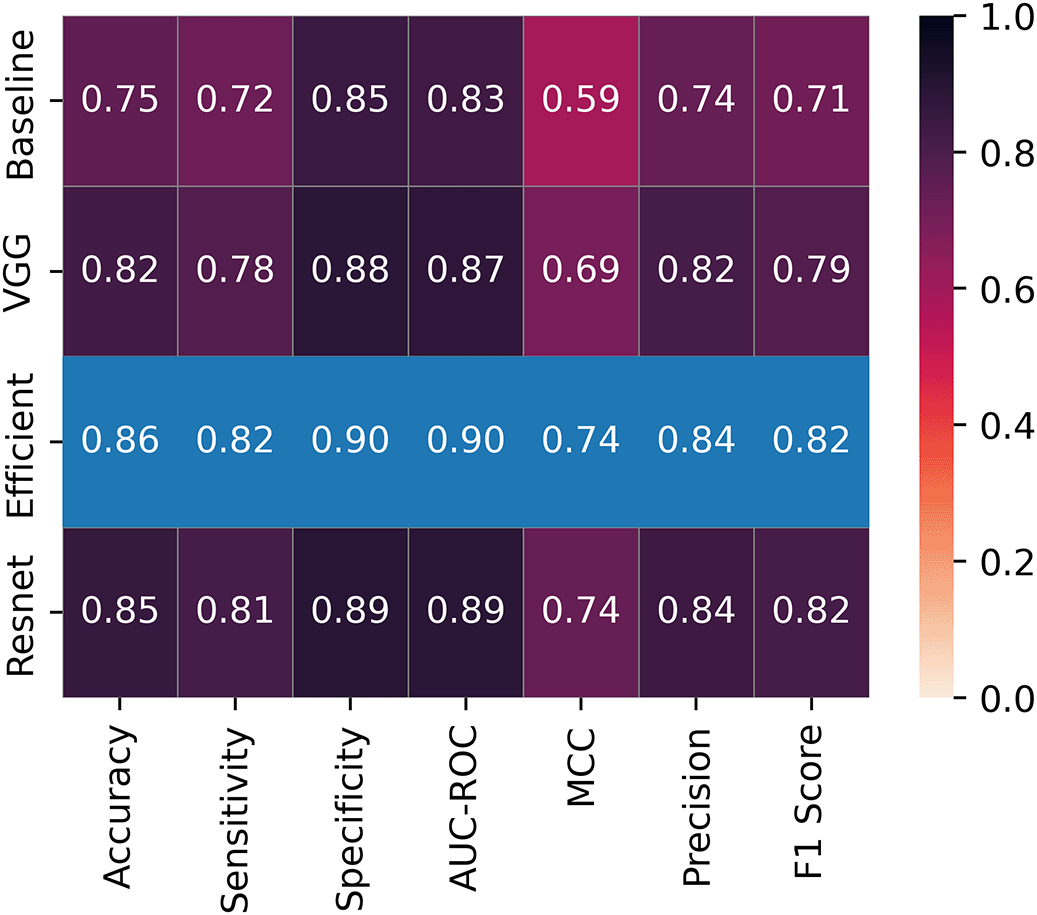
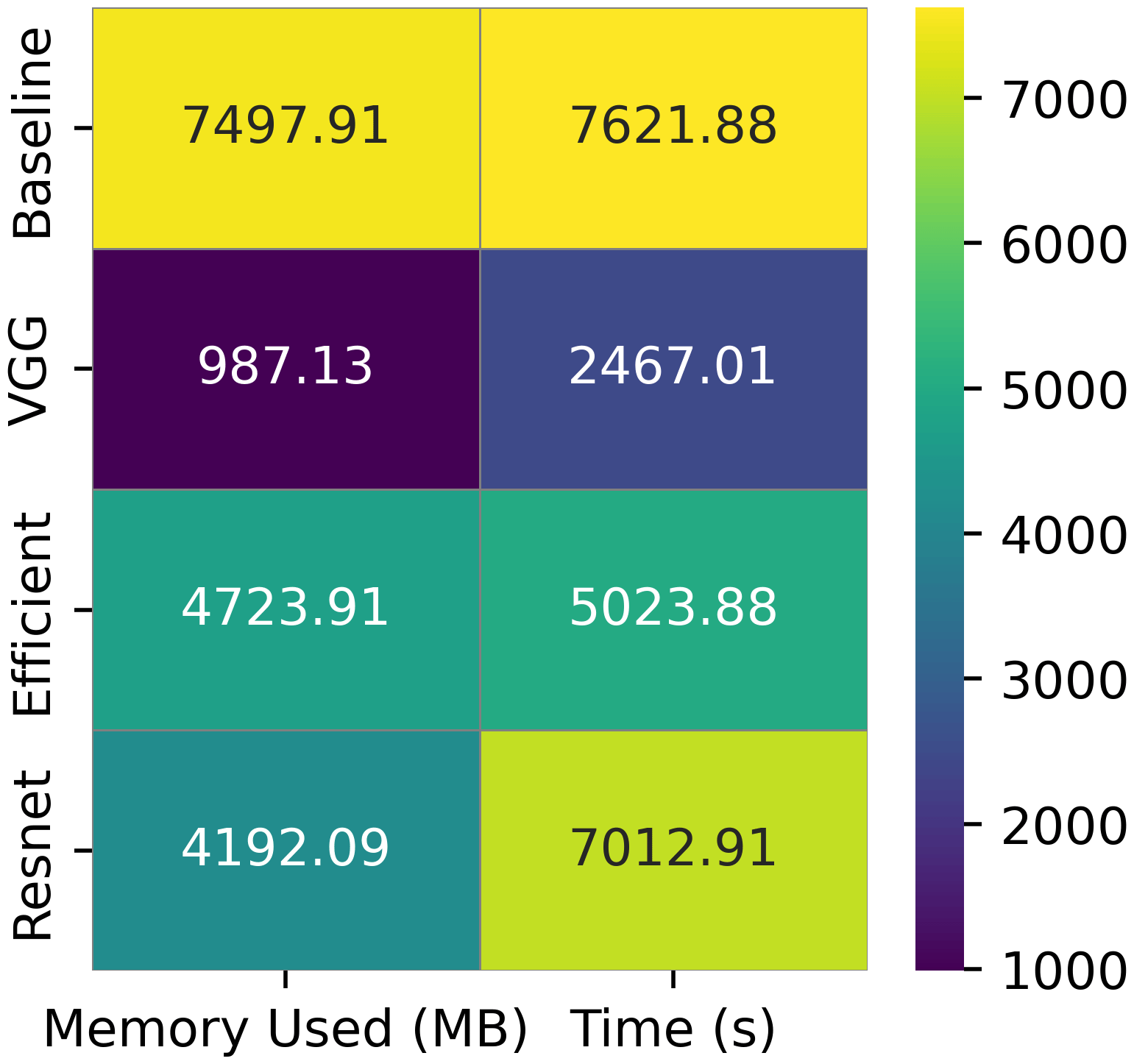
Figure 1 shows the averaged performance of ML models across all datasets. it reveals that the adoption of FE generally results in an improvement in ML models’ performance. Our results show that EfficientNet-B0 had the best predicitive performance followed closely by ResNet-50. However, VGG-16 had better efficiency in terms of memory and time utilization ( Figure 2). FE generally led to a reduction in memory and time complexities when compared to the baseline models.
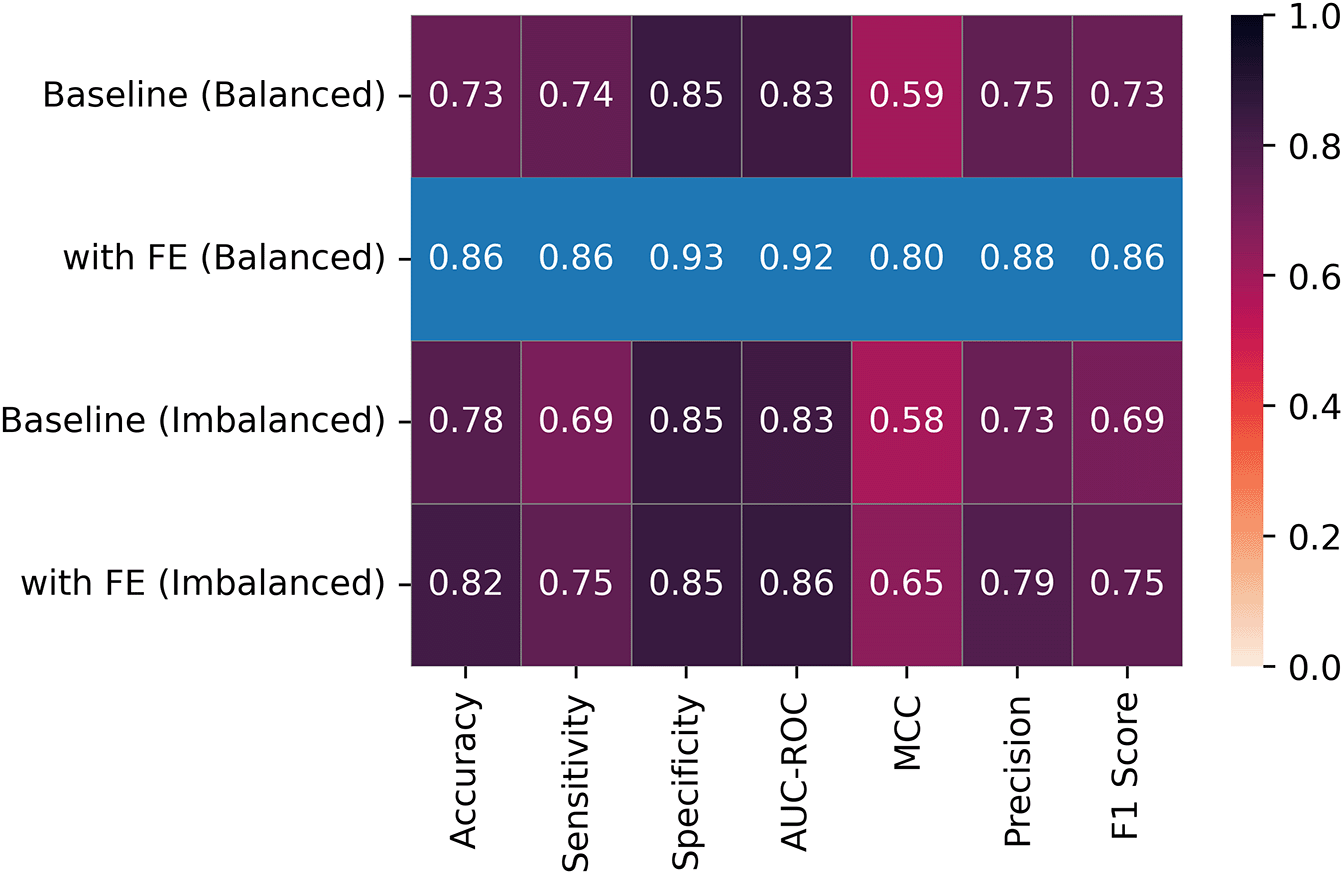
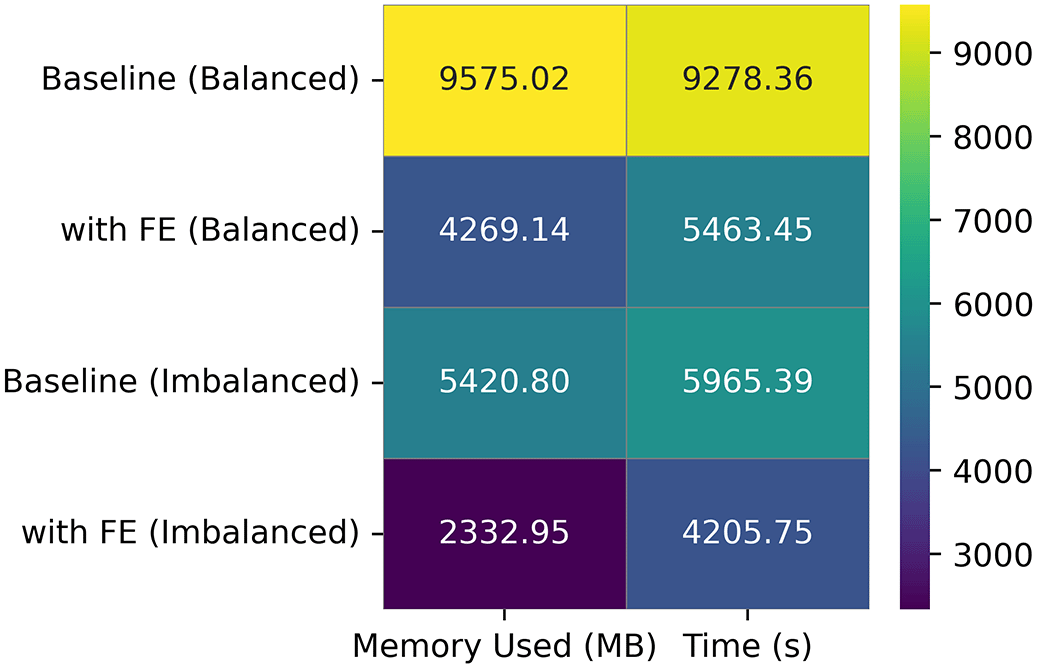
Four datasets (DS1, DS2, DS6, and DS8) have balanced distributions across the different classes of images while the other four (DS3, DS4, DS5 and DS7) have imbalanced distributions. From our results as presented in Figure 3, FE improves ML performance, with the effect being more significant on balanced datasets. There is also a reduction in memory and time required irrespective of whether datasets were balanced or not ( Figure 4).
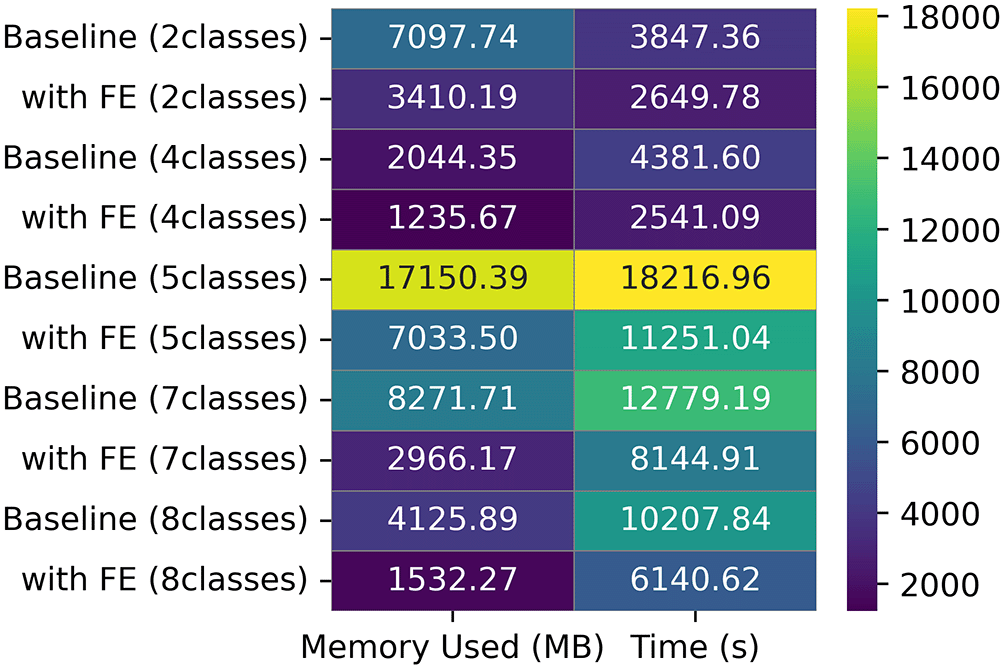
Four datasets (DS1, DS2, DS3, and DS4) had two classes of images while DS5, DS6, DS7, and DS8 had four, five, seven and eight classes respectively. As revealed in Figure 5, there was no correlation between the performance of ML models after FE and number of classes. The best results were obtained on DS6 (5 classes) while the worst results were obtained on DS7 (7 classes). Notably, DS6 had a balanced class distribution, while DS7 had the steepest imbalance among all the datasets used. The Melanocytic Nevi (NV) class had 6705 images, while the other six classes had 3295 images. Figure 6 shows that the least memory and time were required when ML models were trained on DS5 (4 classes).

Three datasets (DS2, DS5, and DS8) have between 0 and 5000 images, Three datasets (DS3, DS4, and DS7) have between 5000 and 10000 images, while DS1 and DS6 have above 10000 images. Figure 7 reveals that the best performances were obtained with larger sample sizes. However, the increase in sample sizes also results in increased memory and time consumption ( Figure 8).
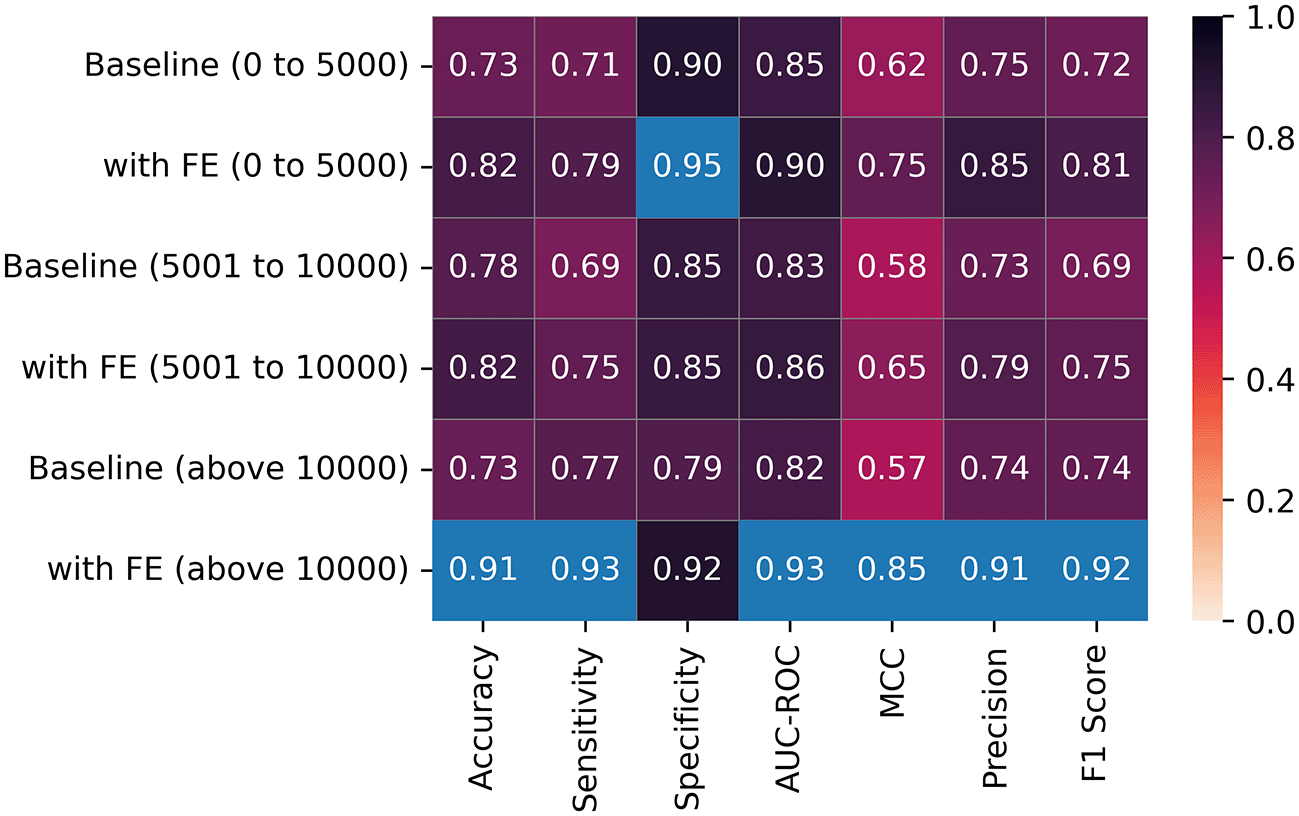
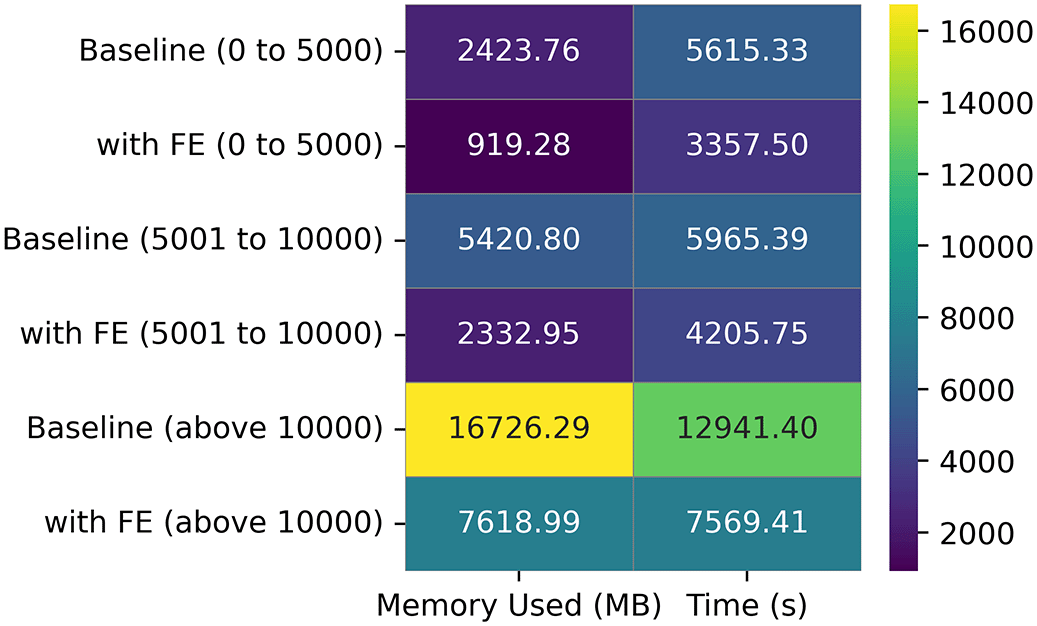
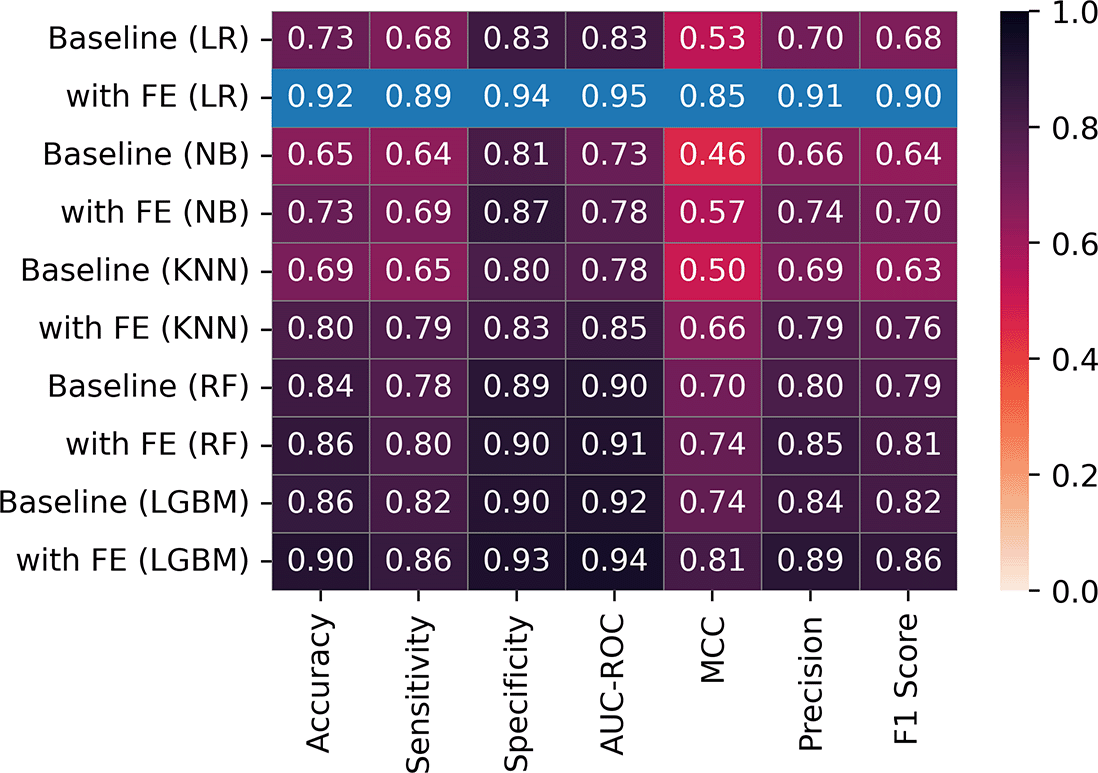
Figure 9 reveals that LR benefitted the most from the adoption of FE before model training while NB benefitted the least. There was a general increase in model performance after FE regardless of the choice of ML models. In terms of memory and time utilization ( Figure 10), there was a general decrease in time spent after FE, however memory utilization increased in NB, KNN, and RF.

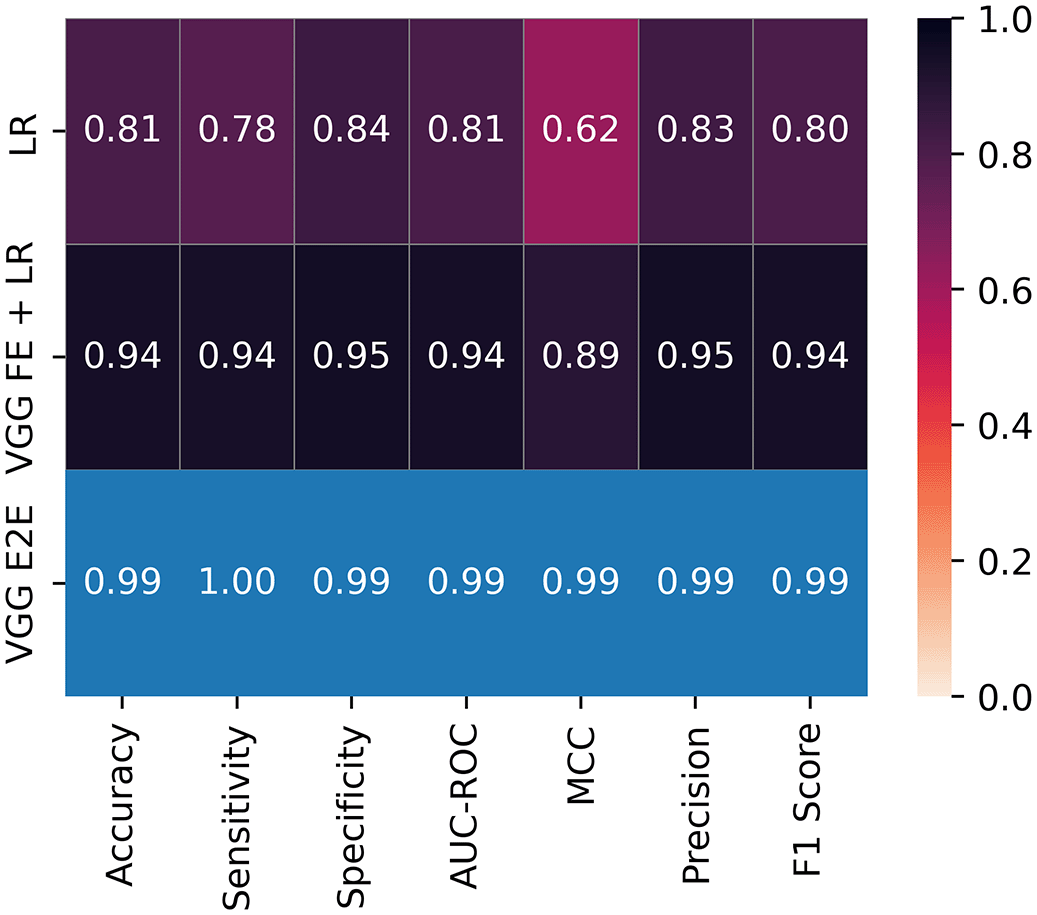
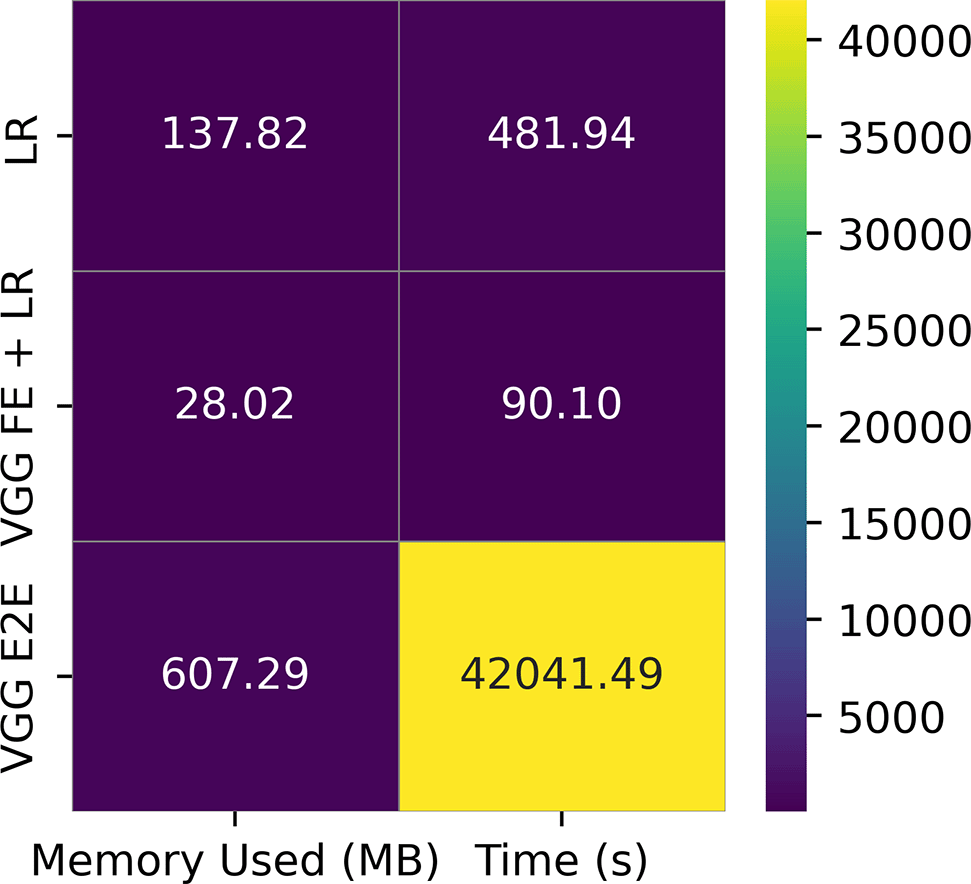
The baseline performance and resource usage of LR, LR after FE with VGG-16,and image classification with VGG-16 on the DS2 dataset are presented in Figures 11 and 12 respectively. The VGG-16 classifier was trained for 20 epochs with a batch size of 64 images. While the predictive performance of LR after FE is slightly lower than the end-to-end image classification with VGG-16, it produces comparable results, more resource efficient and it is significantly higher than the baseline LR. The VGG-16 + LR model required considerably lesser memory and time than both the baseline LR and the VGG-16 end-to-end models.
Here, we have investigated the use of VGG-16, EfficientNet-B0 and ResNet-50 as feature extractors to improve the performance of ML models. The models performed best after EfficientNet based FE. This is not surprising since EfficientNet has been known in literature to yield high performances.28,38 However, since VGG-16 produced smaller features maps (512 *7 * 7) than EfficientNet-B0 (1280 * 7 * 7), the computational cost for ML models after VGG-16 FE is lesser. Previous studies have reported that ML models perform better with balanced datasets that imbalanced ones.39 Our findings confirms this as the increase in ML model performance after FE was more pronounced in balanced datasets.
We observed that the impact of FE increases with the number of learning samples which agrees with existing studies.40,41 Multiclass classification is often believed to be more challenging than binary classification with many studies aiming to find optimal methods for binarizing multiclass problems.42 However, our findings reveal for the first time that the number of classes do not provide a hinderance to model improvement if there is adequate representation of learning samples in each class.
The impact of FE was most significant when LR was trained on CNN-derived features. As stated in the work of Levy and O’Malley.43 LR should not be automatically dismissed when conducting ML experiments. Our findings provide novel evidence that simple/shallow ML models have the capacity to deliver comparable results as ensemble or DL models but they require extensive FE. For example, we observed that after FE, LR had a significantly improved predicitive performance and was still able to maintain its resource efficiency as a computational lightweight model. Our comparison in this study also show that LR performed well after VGG-16 FE and resulted in significant reduction in memory and time usage compared to baseline LR (memory = 79.68%, time = 81.28 %) and VGG-16 end-to-end model (memory = 95.39 %, time = 99.79%). This significant reduction in computational cost would greatly enhance the feasibility of adopting ML for medical imaging analysis in low-resource environments.44
This study however has a few limitations; only five ML algorithms were used, in the future, it would be beneficial to conduct studies involving more ML algorithms. This would enable researchers to compare the performance of CNN-based FE on several groups of ML algorithms (e.g. kernel based models vs tree-based models, shallow models vs ensemble models). Similarly, only three pre-trained CNNs were investigated, there are- more pretrained models such as the Inception and ConvNeXt series.45 Lastly, all datasets used in this study have less than 30,000 images. From our findings one could extrapolate that the improvement in performance of the models would only increase with more images.
In conclusion, our study revealed that using pre-trained CNNs as feature extractors holds much promise for improving model performance especially shallow ML models. Its ability to reduce computational demands and accelerate the ML training process makes it especially valuable in resource-limited settings. We observed that small sample sizes and class imbalance, rather than a higher number of classes, pose the greatest challenge to ML model improvement after feature extraction.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)