Keywords
Ensemble Learning, Differential Evolution, Class Imbalance,AUC Optimization, SMOTE, ADASYN.
This article is included in the Data: Use and Reuse collection.
This article is included in the AIDR: Artificial Intelligence for Data Discovery and Reuse collection.
This article is included in the AI in Medicine and Healthcare collection.
Ensemble Learning, Differential Evolution, Class Imbalance,AUC Optimization, SMOTE, ADASYN.
Machine learning has become increasingly popular in medical and healthcare services in recent years because it can be employed to analyze multidimensional datasets and detect subtle patterns that may not be detectable using traditional standard statistical methods.1,2 Disease diagnosis, estimation of survival, and risks using machine learning models are becoming more common in assisting clinical decision-making. However, one of the most common and serious issues in medical datasets is class imbalance, in which an individual class label with a smaller number of instances occurs more infrequently than the others.3 As a result, traditional models may be biased in favour of the majority class, which may lead to a loss of sensitivity and misclassification of rare but significant minorities.
Many real-world medical datasets, such as cancer prediction, surgical outcomes, and disease screening, suffer from moderate to severe class imbalance. Models trained on imbalanced data often achieve high overall accuracy because they only predict the majority class but may have a poor generalization to the minority class. This is a problem in healthcare, where a missed positive result can be catastrophic. People face this challenge with traditional resampling methods such as SMOTE4 and ADASYN5 and ensemble methods6 such as AdaBoost (AB), CatBoost (CB), Gradient Boost (GB), XGBoost (XGB), Random Forest (RF), Balanced Random Forest (BRF), LightGBM (LGBM), Easy Ensemble (EE), and Extra Trees (ET). Some of these studies enhanced the performance to some extent, but they were not flexible in assigning weights based on the weights and did not directly optimize the corresponding relevant evaluation measure.
For imbalance classification, there is still a gap in ensemble model design, where most models use static or heuristic weights for the base models. Hence, an adaptive ensemble model is needed that incorporates class balance into training and learns to correctly weight the outputs of the base learners. To address these goals, we proposed a novel ensemble model called Optimized Ensemble by Differential Evolution (OEDE) using an adaptive weighted ensemble, where the optimal weights are determined by Differential Evolution (DE). The main contributions of this study are as follows:
Dey and Pratap7 studied different oversampling techniques, such as SMOTE, Borderline-SMOTE, and ADASYN, on different statistical models, such as SVM, KNN, GNB, DT, and RF, concluding that RF combined with SMOTE outperforms others. T.-C.T. Chen et al.8 used an ensemble approach for the classification of diabetes, where DNN performed the classification, and a modified RF was used to explain the results of the proposed model. MARTÍNEZ-VELASCO9 et al. have used both oversampling and under-sampling along with 8 different ML models and concluded that the balanced bagging and balanced RF (BRF) beat every other setup, even without balancing the dataset. To address this class imbalance problem, Agyemang et al.10 used several oversampling techniques such as Random Oversampling (RO), SMOTE, SMOTE-Tomek, and ADASYN, along with ML models such as K-Nearest Neighbour (KNN), Support Vector Machine (SVM), Logistic Regression (LR), Random Forest (RF), and Decision Tree (DT), and concluded that RO-SVM gave the best result. Abayomi-Alli et al.11 proposed a 2-phase ensemble model combining DNN with 15 other ML models (ExtraTrees, SVM, RBF, etc.) for COVID-19 classification, showing that the DNN-ExtraTrees ensemble performed better than the other combinations.
Elgendy et al.12 used a stacking-based ensemble of seven base models for diabetes prediction and concluded that the stacked multilayer perceptron (MLP) provides the highest accuracy. Dutta et al.13 applied weighted average ensemble strategies with GNB, BNB, RF, DT, XGB, and LGB and concluded that the DT+RF+XGB+LGB pair achieves 73.5% accuracy, which is the highest among all other pairs. Alzakari et al.14 proposed a two-stage ensemble combining XGBoost and Bi-LSTM, where XGBoost performs feature selection and early classification and Bi-LSTM performs second stage classification and pattern recognition. Das et al.15 conducted studies of different ML models in different class-imbalanced datasets and concluded that RF performs remarkably well in both balanced and imbalanced datasets. Senthilvadivu et al.16 used RF and XGB for decision making in ICU patients and showed that XGB performs better than RF.
For the prediction of heart disease, Abdellatif et al.17 proposed a weighted random forest ensemble model, used along with an infinite feature selection strategy, and concluded that the proposed model performed better than the SMOTE-RF combination. Yalin et al.18 proposed the XGBoost-BLR method for the classification of diabetes, where XGBoost is used to transform selected features into higher dimensions, and binary logistic regression (BLR) was used for modelling the higher dimensional data. Abnoosian el al.19 used a normalized weighted ensemble to aggregate the results of six different ML models for the classification of diabetes, showing that the proposed ensemble model performed better than the individual base models. Liu et al.20 used bagging to overcome the problem of an imbalanced dataset, where LR was used for feature selection, and SVM was used as a weak classifier. For heart disease prediction, Masruriyah et al.21 used SMOTE and ADASYN along with four ML models and concluded that the oversampling techniques cause a reduction in the accuracy of the model.
Pablo et al.22 performed an analysis of different ML models and sampling techniques on the COVID-19 dataset and concluded that MLP stood out strongly in all combinations, whereas SVM gave lower performance in all combinations. To classify COVID-19, Chowdhury et al.23 proposed a two-step ensemble pipeline with four different ML models, where the results of KNN, SMV, and XGB were passed through RF for final prediction, and concluded that the proposed model outperformed the existing models. Prithula et al.24 proposed a stacking ensemble with ET, RF, and CB as base models and GB as a meta-learner, and concluded that CB outperforms the proposed model. A study by Chowdhury et al.25 Performance analysis of different ML models was performed in the original dataset, and after the dataset was balanced using oversampling, under-sampling, and hybrid-sampling techniques, it was shown that the ML models performed better in the original dataset, except that there was a minor improvement in recall after the dataset was balanced. To handle the imbalanced dataset, Mienye and Sun26 proposed four cost-effective ML models by tuning the hyperparameters and concluded that cost-sensitive XGB performs better than the other models.
In summary (as shown in Table 1), various strategies have been explored to address the class imbalance problem. Oversampling methods such as SMOTE and ADASYN, under-sampling techniques such as RUS and ENN, and hybrid sampling techniques such as SMOTE-ENN and SMOTE-Tomek have been widely used to improve the performance of the models. Many studies have shown that ensemble models can improve the performance by assembling multiple base models. In fact, models such as RF and XGBoost are highly effective across different healthcare applications, as shown in different studies. Overall, the literature suggests that there is no universal solution, and that the selection of the technique is typically based on the nature of the dataset.
| Author | Disease | Models | Is the original dataset imbalanced | Imbalance handle strategy | Observation |
|---|---|---|---|---|---|
| Dey and Pratap7 | Diabetes and Breast Cancer | SVM, KNN, GNB, DT, RF | Yes | SMOTE, Borderline-SMOTE, ADASYN | RF in combination with SMOTE outperforms others. |
| Chen et al.8 | Diabetes | DNN, RF | Yes | - | RF is used to explain the result of DNN. |
| Martínez-velasco et al.9 | Age-Related Macular Degeneration and Preeclampsia | Balanced Bagging, BRF, RF, GB, KNN, LR, SVM, DT | Yes | SMOTE and Under-sampling | Balanced bagging and BRF outperform others even in imbalanced datasets. |
| Agyemang et al.10 | Stroke | KNN, SVM, LR, RF, DT | Yes | RO, ADASYN, SMOTE, SMOTE–Tomek | SVM with Random Oversampling performs better. |
| Abayomi-Alli et al.11 | COVID-19 | DNN, ExtraTrees, SVM, RBF etc. | Yes | SMOTE | DNN-ExtraTrees ensemble outperforms others. |
| Elgendy et al.12 | Diabetes | LR, RF, MLP, AB, GB etc. | Yes | SMOTE | MLP with Staking gives the highest accuracy. |
| Dutta et al.13 | Diabetes | GNB, BNB, RF, DT, XGB, LGB | Yes | - | DT, RF, XGB, and LGB combination. performance than others. |
| Alzakari et al.14 | Heart Disease | XGB, Bi-LSTM | Yes | - | XGB performs feature selection and early classification, and Bi-LSTM performs second-stage classification. |
| Das et al.15 | Diabetes, Cancer | RF, XGB, AB, CB etc. | Yes | SMOTE | RF performs well in both balanced and imbalance datasets. |
| Senthilvadivu et al.16 | ICU Condition | RF, XGB | Yes | - | XGB performs better than RF. |
| Abdellatif et al.17 | Heart Disease | RF | Yes | SMOTE | Proposed weighted RF performs better than SMOTE-RF. |
| Yalin et al.18 | Diabetes | LR, XGB | Yes | - | The proposed ensemble outperforms other base models. |
| Abnoosian et al.19 | Diabetes | KNN, SVM, DT, RF, AB, GNB | Yes | - | The proposed ensemble outperforms the base models. |
| Liu et al.20 | Cardiovascular disease | LR, SVM, Bagging | Yes | Undersampling | SVM is used as a weak learner for bagging. |
| Masruriyah et al.21 | Heart Disease | C4.5, RF, SVM, LR | Yes | SMOTE, ADASYN | Oversampling decreases the model's performance. |
| Pablo et al.22 | COVID-19 | MLP, XGB, NB, DT, SVM | Yes | POS, RUS, SMOTE, ADASYN | MLP stood out strongly for all experimental setups. |
| Chowdhury et al.23 | COVID-19 | KNN, SVM, RF, XGB | Yes | SMOTE | The proposed pipeline outperforms other pairs and the base models. |
| Prithula et al.24 | Respiratory diseases | MLP, XGB, DT, SVM, AB CB etc | Yes | SMOTE | CB performs better than the proposed model. |
| Chowdhury et al.25 | Diabetes | LR, RF, AB, GB, Voting | Yes | ENN, SOMTE_N, SMOTE-ENN, SMOTE-Tomek | The performance of the models is better in original dataset. |
| Mienye and Sun26 | Diabetes, Cancer, CKD | LR, DT, XGB, RF | Yes | - | Cost-sensitive XGB performs better than others. |
To enhance the prediction accuracy on an imbalanced dataset, we propose a novel ensemble approach called Optimized Ensemble by Differential Evolution (OEDE). An overview of the proposed methodology is shown in Figure 1. Four different medical datasets with different imbalance ratio (1.89 to 14.6) were collected from the UCI Machine Learning Repository to assess the robustness of the model. After data preprocessing, a stratified train-test split was applied to maintain the class distribution in the training, test, and valuation sets. Logistic Regression (LR), Random Forest (RF), and XGBoost (XGB) were used as the base models, and Differential Evolution (DE) was used to combine their predictive strength based on prediction probability on the validation set, with Area Under the ROC curve (AUC) as the optimization objective. Before constructing the final model, the base learners were fine-tuned using GridSearchCV and Stratified-K-Fold cross-validation to ensure a robust model under class imbalance. The performance of OEDE was tested on the original imbalanced dataset, dataset balanced with SMOTE, and ADASYN. A performance comparison was performed against existing ensemble models such as AB, CB, LGBM, ET, EE, and RBF.
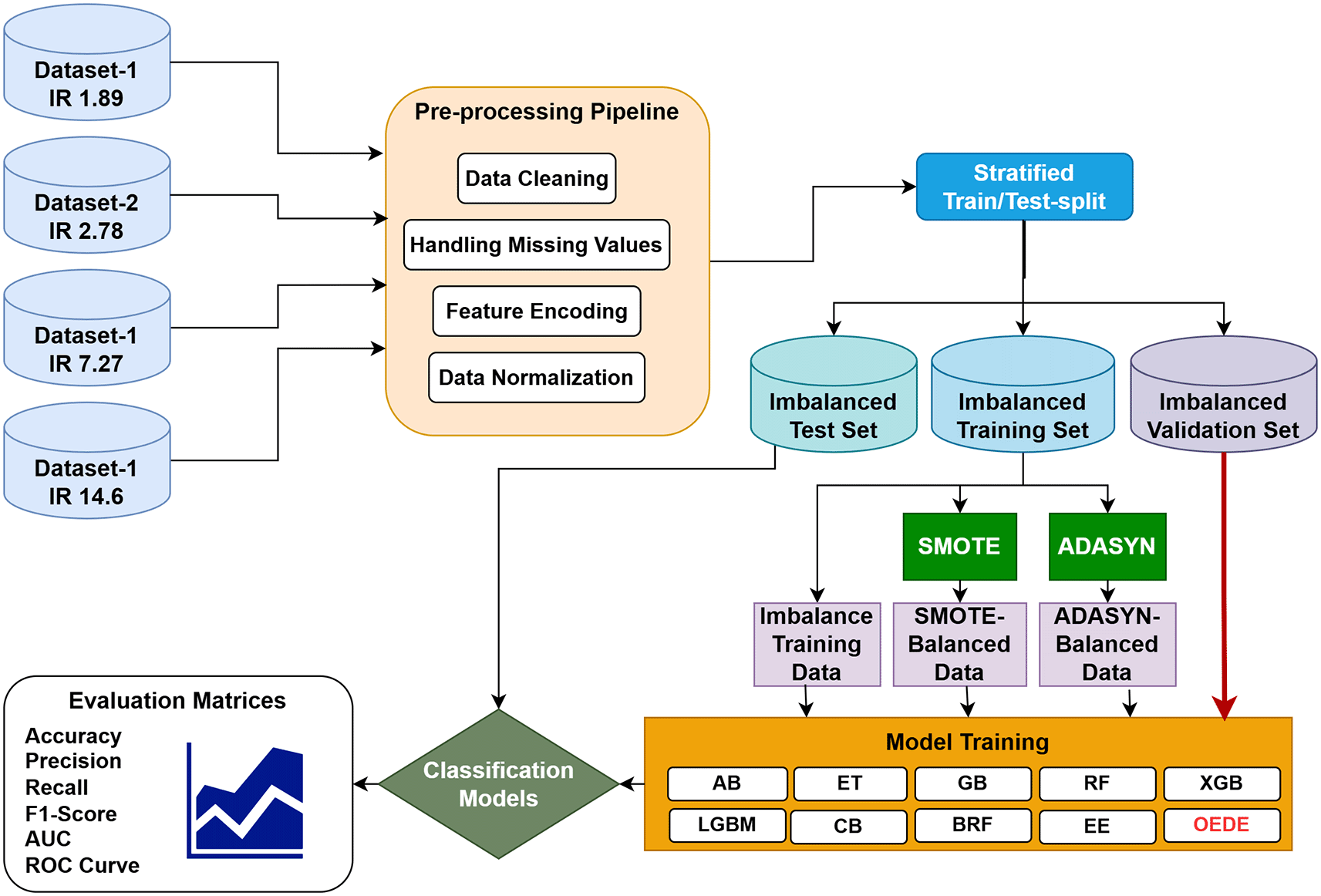
To evaluate the robustness and adaptability of the proposed OEDE model, we used four widely used public medical datasets from the UCI Machine Learning Repository, with different class Imbalance Ratios (IR), as shown in Table 2. These datasets were carefully chosen to cover a broad range of real-life situations where minority class data are clinically significant. The Pima Indiana Diabetes Dataset (IR = 1.89) includes the inception of diabetes in female patients based on diagnostic measurements. The Haberman’s Cancer Survival Dataset (IR = 2.78) has patient records for those who had undergone breast cancer surgery, aimed at predicting post-operative survival. The Thoracic Surgery Dataset (IR = 7.27) is based on predicting survival following major lung surgery for patients, considering clinical and surgical factors. Finally, the Cervical Cancer Risk Dataset (IR = 14.6) uses personal health information and screening results to assess the risk of cervical cancer. These datasets provide a range of imbalance ratios where the minority class proportion is less than 40%, offering a robust testbed for validating the effectiveness of the OEDE.
| Dataset name | No. of instances | No. of features | Minority class | Minority class proportion (%) | Imbalance Ratio (IR) |
|---|---|---|---|---|---|
| Pima Indians Diabetes27 | 768 | 9 | Positive | 34.9% | 1.89 |
| Haberman’s Cancer28 | 306 | 4 | Negative | 26.5% | 2.78 |
| Thoracic Surgery29 | 470 | 17 | Negative | 12.1% | 7.27 |
| Cervical Cancer Risk30 | 858 | 36 | Positive | 6.4% | 14.6 |
The proposed ensemble model leverages three different base learners, namely Logistic Regression (LR), Random Forest (RF), and XGBoost (XGB), with the aim of improving predictive performance based on model diversity. The LR is a linear model that predicts the probability of a binary outcome using a sigmoid function.31 Its interpretability and probabilistic output make it a valuable baseline, particularly when modelling linear relationships.32,33 RF is an ensemble of decision trees that introduces non-linearity and robustness by aggregating predictions from a group of trees trained on bootstrapped datasets and random feature subsets, thus removing variance and overfitting.34 It performed well in capturing complex feature interactions.35 XGBoost builds a sequence of trees, where each tree corrects the errors made by its predecessors, optimizing a normalized objective function L = , where 36 Its ability to model non-linearities with good precision,37 regularization, and the ability to handle missing values18 makes it a strong learner in the ensemble. Together, these models provide distinct perspectives, such as linear separability, variance minimization, and gradient-based optimization, making the ensemble more robust and less prone to overfitting than any single learner.
We used oversampling techniques, the Synthetic Minority Oversampling Technique (SMOTE), and Adaptive Synthetic Sampling (ADASYN) to address the class imbalance of the original dataset. We assessed the performance of our proposed ensemble model on three different datasets: the original imbalanced dataset, SMOTE-balanced dataset, and ADASYN-balanced dataset. SMOTE creates synthetic instances for the minority class through interpolation between minority samples and their k-closest minority neighbour, thereby expanding the decision boundary and reducing overfitting to specific samples.38 While SMOTE assumes the same significance to all instances of the minority class,39 ADASYN focuses on varying the importance of individual minority instances according to their level of difficulty in learning.40 It individually generates a synthetic minority sample, which is harder to classify owing to its lower density in the feature space, thereby promoting the generalization of the challenging part of the data.41 Through this cross-dataset comparison of model performance, we aim to evaluate not only the generalizability of the proposed ensemble, but also how different balancing strategies influence its performance.
The Optimized Ensemble by Differential Evolution (OEDE) was designed as a novel ensemble model to alleviate the classification difficulties of imbalanced medical datasets. This method incorporates class-balanced base learners and a Differential Evolution (DE)-driven algorithm for AUC maximization. Three fundamentally different classifiers, LR, RF, and XGB, were used as base models. All base models were configured with a class-weighting mechanism during training to address the effects of class imbalance. LE employs class_weight= ‘balanced’, RF uses class_weight=‘balanced_subsample’, while XGB is fine-tuned for logloss with consideration taken for label imbalance. These learners were independently trained on the same dataset and produced probability estimates for the positive class that were combined using a learned ensemble set of weights. OEDE does not combine the outputs of the base learners using fixed or heuristic-based weights; instead, it uses Differential Evolution (DE) for adaptive weight optimization. DE is a stochastic population-based global optimization method that is well-suited for non-differentiable and non-convex functions.42–45
Let the prediction probabilities from M base classifiers for a given instance x be denoted by [p1(x), p2(x), …, pM(x)]. Assign weight wi to each base classifier i, where the weights satisfy:
For the proposed ensemble, assign a weight wi to each base model i such that:
The ensemble’s predicted probability is given by the weighted average:
The goal was to choose the weights w = [w1, w2, …, wM] to maximize the AUC on a validation set. Recall that the AUC represents the probability that a randomly chosen positive instance has a higher score than a randomly chosen negative instance.
Because many optimization algorithms (such as Differential Evolution) are formulated as minimization problems, the loss function is defined as the negative AUC:
Thus, the optimization problem becomes:
DE is selected for this task because of its robustness in optimizing non-differentiable and non-convex functions such as AUC. DE evolves a population of weight vectors over generations using mutation, crossover, and selection to converge to a globally optimal solution. The proposed process is described by Algorithm 1.
Input:
- Traini Set: X_train, y_train
- Validation Set: X_val, y_val
- Test Set: X_test, y_test
- DE parameters: population size P, generations G
Output:
1. Train LR, RF, XGB on (X_train, y_train)
2. For each model m ∈ {LR, RF, XGB}:
3. p_val_m = m.predict_proba(X_val)[:, 1]
4. P_val = [p_val_LR, p_val_RF, p_val_XGB]
5. function AUC_Loss(weights, P_val, y_val):
6. Normalize weights: w = weights/sum (weights)
7. Ensemble prediction: p_ens = dot(P_val, w)
8. Return -AUC(y_val, p_ens)
9. bounds = [(0, 1), (0, 1), (0, 1)]
10. w_opt = DifferentialEvolution (AUC_Loss, bounds, args=(P_val, y_val))
11. w_opt: w_opt = w_opt/sum(w_opt)
12. For each m ∈ {LR, RF, XGB}:
13. p_test_m = m.predict_proba(X_test)[:, 1]
14. P_test = [p_test_LR, p_test_RF, p_test_XGB]
15. p_test_ens = dot(P_test, w_opt)
16. y_pred = 1 if p_test_ens ≥ 0.5 else 0
17. Return y_pred, evaluation metrics
We used five common yet important classification metrics such as Accuracy, Precision, Recall, F1-Score, and Area Under the ROC curve (AUC), to evaluate the performance of the proposed OEDE model. While working with the imbalanced dataset, these measures offer a comprehensive insight into the efficiency of the model. Let PC, NC, PE, and NE represent the numbers of correctly classified positives, correctly classified negatives, false positives, and false negatives, respectively.
• The percentage of correct positive predictions among all positive predictions is known as the precision.
When it comes to an imbalanced dataset, the AUC is especially significant, which represents the area under the ROC curve by plotting the true positive rate and false positive rate across different classification thresholds. A higher AUC represents better separability. Finally, we visualized the ROC curve of each model, which offered an intuitive view of the trade-off between false alarms and sensitivity. The closer the curve is to the upper-left corner, the better is the classifier.
The experiment involved four different medical datasets with different imbalance ratios (1.89 – 14.6) used for the performance analysis of the proposed model. This section provides a detailed analysis of the proposed model and compares the performance matrices with the existing base models after training them in three different conditions: the original imbalanced dataset, data balanced using SMOTE, and data balanced using ADASYN. The performance matrices were evaluated using a never-observed imbalance test split.
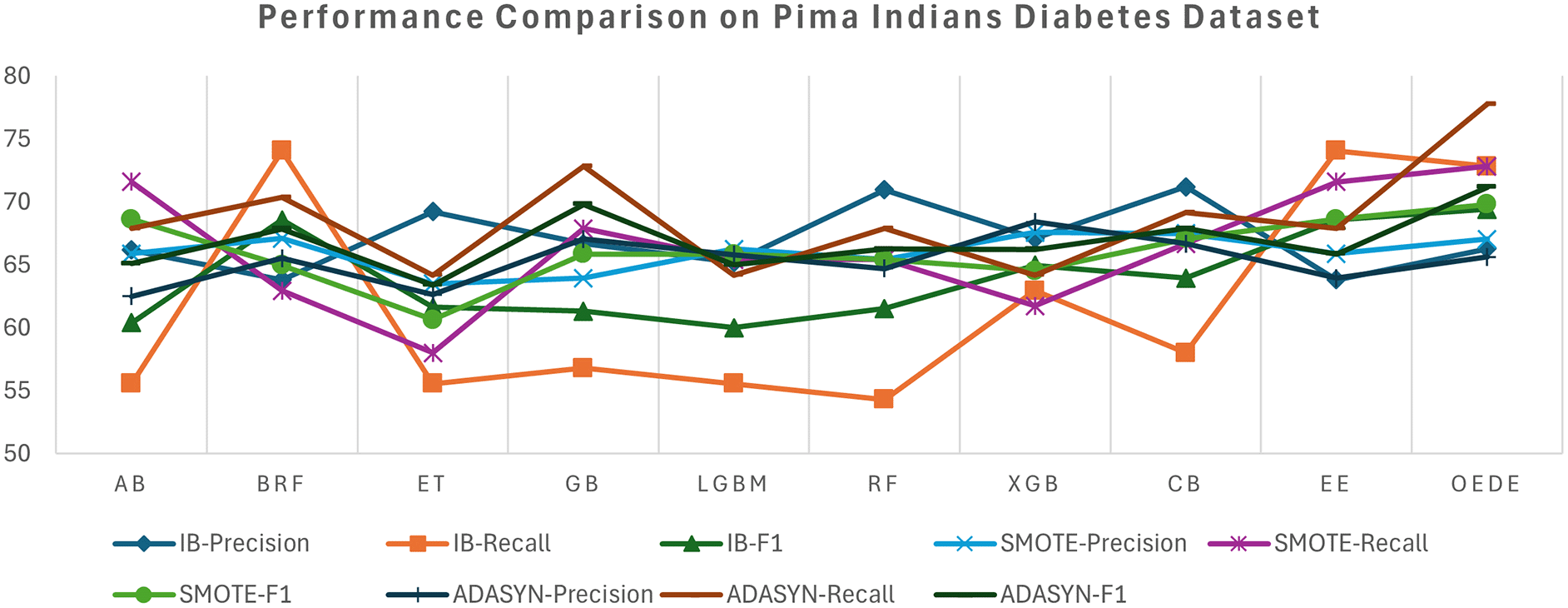
On the original dataset, OEDE achieved high accuracy and AUC score, as shown in Table 3, effectively discriminating between diabetic and non-diabetic samples without artificial rebalancing. Although ensemble models such as RF and XGBoost demonstrated competitive accuracy, their AUC and recall values were low, indicating a bias towards the majority classes. The OEDE tended to have a high F1 score, while maintaining a better balance between precision and recall, as shown in Figure 2. The overall performance of all models improved when the dataset was balanced using SMOTE, as indicated by the increased recall and F1-score, but OEDE still outperformed the others in terms of accuracy, AUC, and F1-score. Notably, the change in the AUC value was marginal, indicating that merely balancing the data may not be sufficient. In the ADASYN-balanced scenario, it tends to echo those of SMOTE but with minor instability for some models because ADASYN introduces noise in the minority samples. OEDE again outperformed other baseline models with a minor drop in precision while maintaining the AUC and showed a balanced performance throughout the datasets.
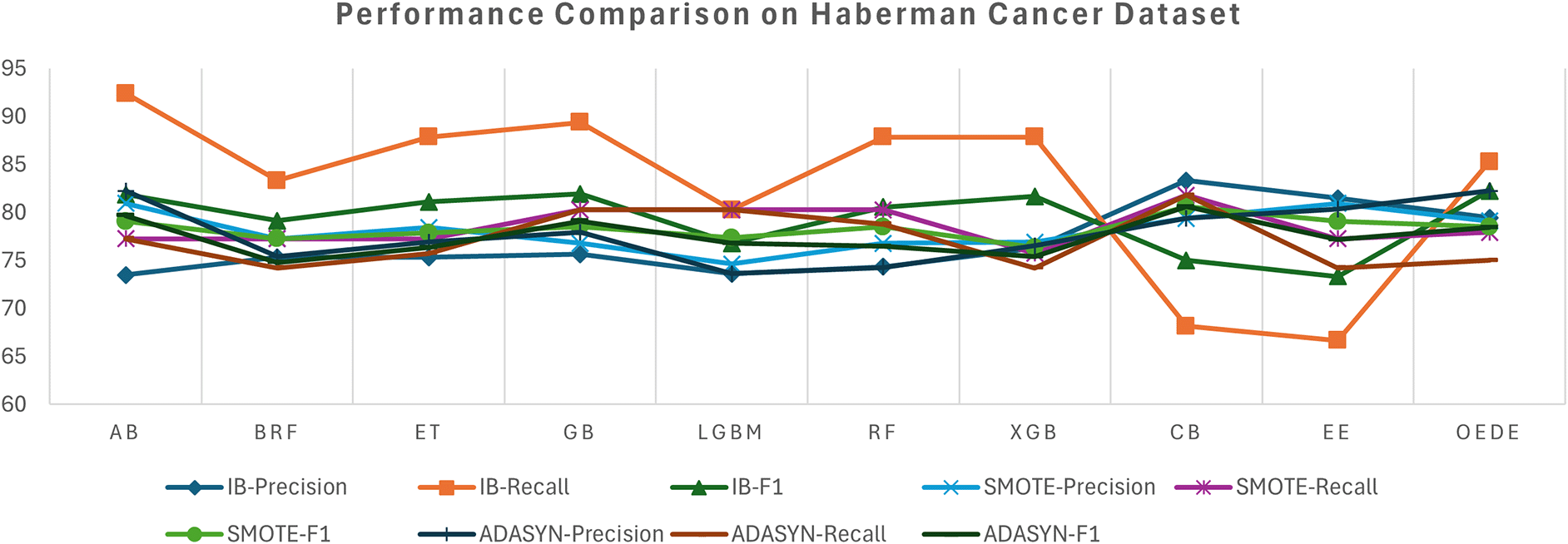
OEDE achieved a higher accuracy, AUC, and F1-score than traditional ensemble models such as RF, AB, and CB in an imbalanced dataset, as shown in Table 4. While some models show comparable accuracy, OEDE shows stability in precision and recall, leading to a better F1-score as shown in Figure 3, demonstrating its ability to detect the minority class without compromising the overall correctness. After the dataset is balanced with SMOTE, an improvement is observed in recall for most of the models, which shows that the models benefit from the synthetic sample. The OEDE maintained its AUC lead, highlighting its ability to influence informative patterns more effectively, even in a balanced dataset. Its high F1-score reflects food robustness against overfeeding for synthetic data. When ADASYN is used for data balancing, some models show instability in precision and recall, as ADASYN tends to produce harder-to-learn synthetic samples, while OEDE has a high-performance score without sacrificing stability and sensitivity.
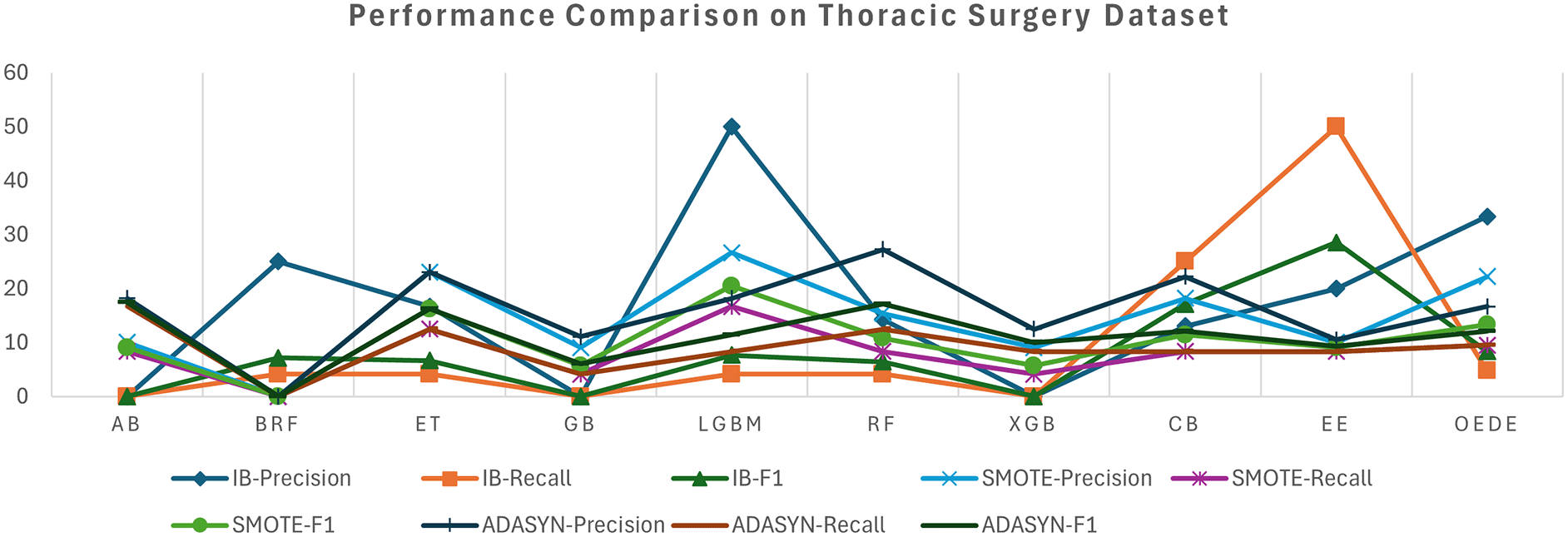
The thoracic surgery dataset showed a significant imbalance in class distribution, challenging most of the classifiers that favour the majority classes. OEDE outperformed traditional ensemble models such as RF, LGBM, and BRF in terms of AUC and F1-score, as shown in Table 5 and Figure 4, while the original imbalanced dataset was used. Although many baseline models achieve relatively high accuracy, OEDE maintains its balanced performance, achieving higher recall for minority classes and offering better overall performance. With the SMOTE-balanced dataset, most models improve recall values owing to synthetic samples. OEDE continues to display a superior performance matrix, especially the AUC value, which indicates the robustness of the model even when the dataset is balanced with synthetic data without dropping precision or overfitting. Similar to the previous datasets, the performance of the baseline models fluctuated in the ADASYN-balanced dataset, but OEDE maintained a stable performance and showed high F1 and AUC scores. This generalizability and consistent performance are possible owing to the differential evaluation-based weight optimization.
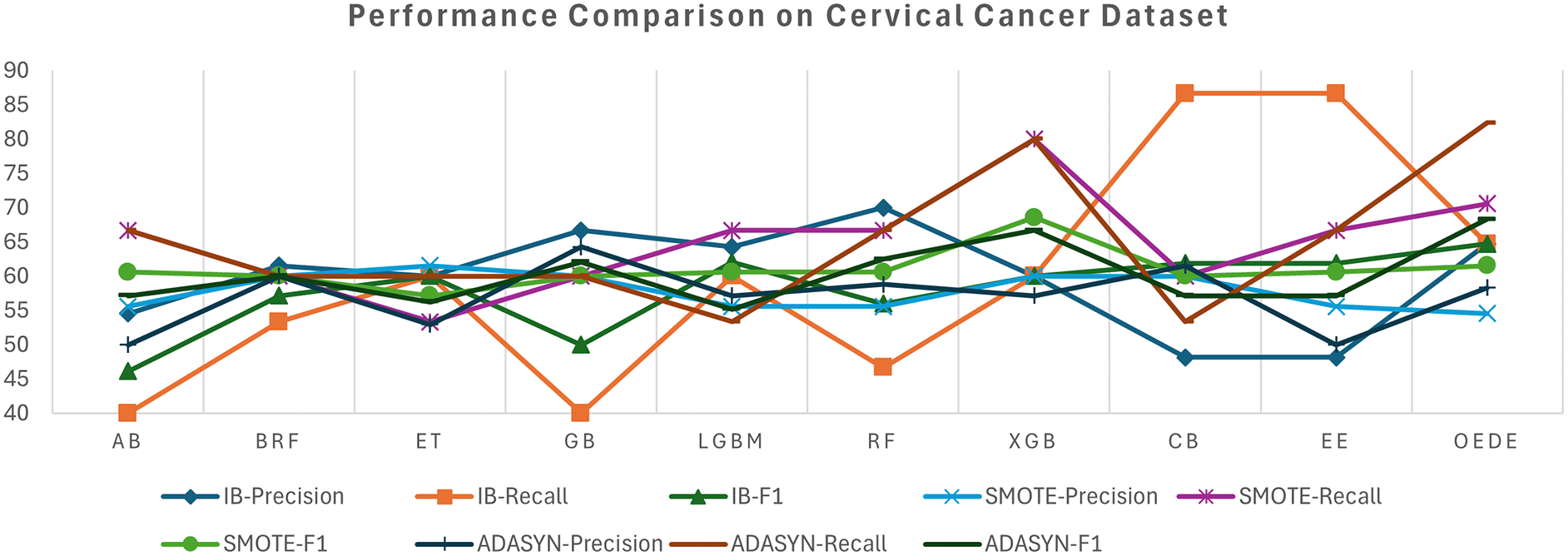
The Cervical Cancer Risk dataset shows a significant difficulty owing to high-class imbalance, where high-risk cases are less than 7% of the dataset, which tends to affect the performance of the traditional model. On the imbalanced dataset, most baseline models, such as RF, ET, and CB, struggle with the minority class and show a low recall and F1-score, despite considerable accuracy, as shown in Table 6 and Figure 5. In contrast, OEDE is able to distinguish the minority class effectively owing to adaptive weighting, as reflected in the AUC and F1-score. Again, SMOTE improves the recall for all models, including OEDE, while maintaining competitive precision and achieving the highest AUC. For the ADASYN-balanced dataset, OEDE maintained high performance with the highest AUC and F1-score, supporting its resilience and generalizability.
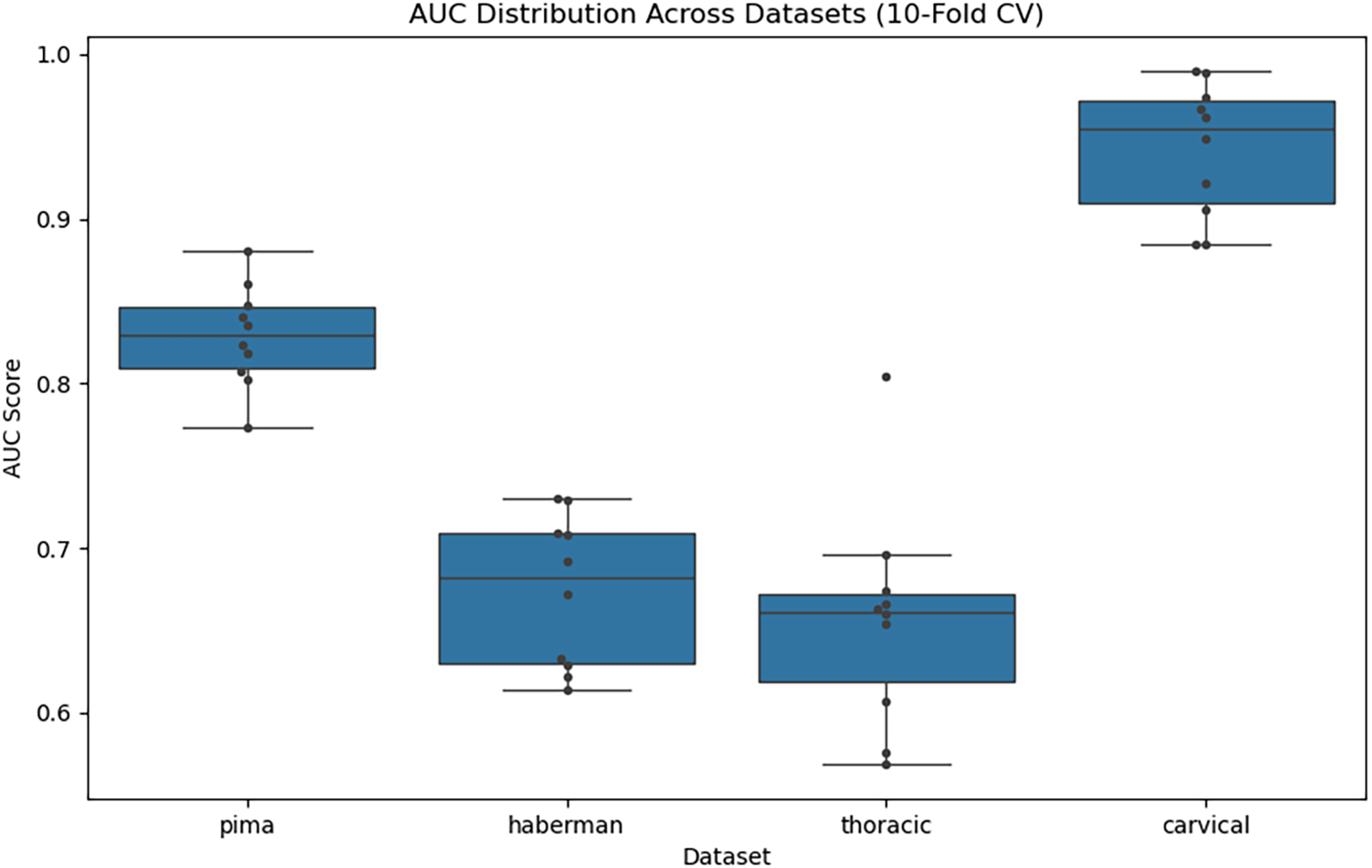
The box plot overlaid with swarm points ( Figure 6) demonstrates the diversity of the different datasets. The median and IQR of AUC on the Cervical dataset presented the highest AUC scores (~0.95 median), demonstrating excellent and stable classification performance. Even for the Pima dataset, a moderate spread was observed, indicating reasonable generalization for the model. The Haberman and Thoracic datasets, on the other hand, demonstrated lower and more variable AUCs, around a median of 0.66–0.68, suggesting struggles possibly with class imbalance or limited separability.
The performance of the OEDE across the four benchmark datasets demonstrates its robustness and adaptability across balanced and imbalanced datasets. Despite varying levels of class imbalance, OEDE achieved superior performance, outperforming a range of traditional baseline models. To support the numerical findings, ROC curves were plotted ( Figure 7) for all the datasets to visually represent the discrimination ability of the model. Consistently across all datasets, the ROC curve of OEDE was favourable, aligning with the AUC values achieved.


(A) Pima Indiana Diabetes Dataset. (B) Haberman’s Cancer Dataset. (C) Thoracic Surgery Dataset. (D) Cervical Cancer Risk Dataset.
In this study, a novel ensemble model, OEDE, was proposed to address the challenges of imbalanced medical datasets. The key innovation includes the aggregation of the predictive power of diverse classifiers such as LR, RF, and XGB through a differential evolution-based ensemble, which learns the optimal weight by maximizing the AUC. Unlike traditional models, OEDE adapts the decision boundary to enhance the discrimination capacity, especially in the minority class. The approach also includes class-balanced-based learning, ensuring that base models reduce the imbalance at the source, resulting in a robust ensemble model that generalizes well across datasets with different characteristics and imbalance ratios. The performance of OEDE was assessed on four different medical datasets with class imbalance ratios from 1.89 to 14.6, to verify its ability to handle class imbalance data. The results demonstrated that OEDE almost always performed significantly better than the state-of-the-art ML models in terms of AUC, accuracy, and F1-score, and the model was robust under different data balancing techniques such as SMOTE and ADSYN. Adding the ROC curves of all the models and datasets also confirms the superior separability of OEDE and makes it a useful framework for practical real-world classification problems.
This study does not require any ethical approval since this study only used publicly accessible, de-identified datasets. There were no experiments with human subjects, and no new data were gathered. The datasets do not contain any personally identifiable information and are available from recognized open repositories.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)