Keywords
bioinformatics; bioinformatics education; Latin America; multilingualism; scientific translation
This article is included in the Bioinformatics gateway.
This article is included in the Galaxy gateway.
This article is included in the CABANA: Computational Biology Resources for and from Latin America collection.
bioinformatics; bioinformatics education; Latin America; multilingualism; scientific translation
Bioinformatics - the intersection of biology and computational science - has revolutionized biological research since its emergence in the late 20th century. The field of bioinformatics has evolved drastically from simple sequence analysis tools to sophisticated algorithms capable of handling vast datasets generated by high-throughput sequencing technologies (Baxevanis et al., 2020). As the field of bioinformatics continues to expand, there is an increasing demand for the education and training of the next generation of bioinformaticians. This necessity has prompted scrutiny into the development and accessibility of training programs and materials (Mulder et al., 2018), particularly evident on a global scale (Attwood et al., 2019; Aron et al., 2021; Marangoni et al., 2023). Such work demonstrates the growing recognition of the importance of ensuring that bioinformatics training is comprehensive, accessible, and tailored to meet the diverse needs of learners worldwide.
However, there are several challenges inherent in delivering bioinformatics training and creating accessible materials. One significant challenge is the steep learning curve associated with bioinformatics, which is exacerbated by the lack of linguistic diversity in available resources (Işık et al., 2023; Ras et al., 2021). Language barriers in science, coupled with the dominance of English, poses obstacles to achieving open and inclusive science, further limiting accessibility for scientists globally (Amano et al., 2016, 2021, 2023; Woolston & Osório, 2019). This trend particularly affects geographical regions such as Low-and Middle-income Countries (LIMCs). In regions like Latin America, scientists encounter numerous hurdles in accessing scientific knowledge, with the lack of linguistic representation and multilingual resources being prominent barriers (Kalergis et al., 2016; Ramírez-Castañeda, 2020; Valenzuela-Toro and Viglino, 2021; Massarani and de Oliveira, 2022; Yáñez-Serrano et al., 2022; Basilio, 2023). Despite the increasing interest in developing bioinformatics initiatives in Latin America (De Las Rivas et al., 2019; Hernández-Rosales, 2021), bioinformatics in this region faces similar challenges. An example of such initiatives is the CABANA project (https://www.cabana.online/), a collaborative effort aimed at enhancing bioinformatics capacity in Latin America. This project, orchestrated by an international consortium of organizations, including partners from Latin America and the UK, has also identified the critical necessity for making multilingual bioinformatics resources accessible to scientists (Stroe, 2022). This pilot study aims to address these challenges by advancing the creation of multilingual bioinformatics resources by and for Spanish-speaking bioinformaticians. The Open University, with the collaboration of the Galaxy Training Network (GTN, https://training.galaxyproject.org/) (Hiltemann et al., 2023), designed a virtual and asynchronous workshop titled “Spanscriptomics: Análisis de células únicas usando Galaxy|Single cell analysis using Galaxy” and collected pre- and post-workshop data from the participants.
The pilot study was guided by the main objective to identify the need, reception, and impact of translated bioinformatics training materials among Spanish-speaking bioinformatics trainees.
Approvals were obtained from the Open University Human Research Ethics Committees (HREC, reference number 4135). A full Data Protection Impact Assessment (DPIA) was carried out as part of the ethics application. Written informed consent was obtained from participants for the use of their anonymized data in publication.
The study involved the creation of a virtual and asynchronous workshop which lasted two days (from 2021-11-29 to 2021-11-30) during which all data was collected. The workshop was hosted on the Gallantries platform (https://gallantries.github.io/about) as part of the Galaxy Training Network (GTN). The workshop was comprised of two slide decks with videos, and three tutorials and three walkthrough videos. The participants were randomized into three groups:
• HES (Human-translated Spanish content and video captions, and Spanish dubbing for audio),
• ENG (English content, and English audio and captions),
• CAT (Machine-translated Spanish content and video captions, audio in English).
Participants were allowed to change groups at any stage of the workshop. Participants had access to trainers across multiple time zones throughout the workshops via an online chat workspace. The human translations of the workshop materials were generated by bilingual workshop presenters, instructors, and organizers with bioinformatics expertise. The machine-generated translations were produced by Google Translate (https://translate.google.com/), a free on-line Machine Translation (MT) tool.
An interest registration link was available on the main workshop web page. A leaflet invitation containing the dates and the details of the workshop along with an interest registration link was also sent to the study authors to share across their networks and institutions. The workshop was publicized on existing Galaxy platforms. Additionally, the workshop was publicized on social media through institutional accounts. Consent to participate in the study was obtained during registration, where participants were also given a project information sheet and the pre-course survey. The workshop’s target audience was clearly identified as being native speakers of Spanish.
Two sets of survey questions were created using Jisc (https://www.onlinesurveys.ac.uk/) with the aim of collecting information and feedback from participants. The first survey was shared with participants during registration (pre-workshop survey), and the second survey was shared with participants after the workshop (post-workshop survey). The pre-workshop survey contained 15 questions on demographics, education, English-proficiency levels, and preferred language for workshop materials. The post-workshop survey contained 17 questions pertaining to participants’ learning outcomes as well as feedback from participants on their learning experience.
Out of the 155 participants who filled in the pre-workshop survey, four opted out, leaving 151 participants’ data for analysis. 25 participants filled in the post-workshop survey, out of which five were incomplete and removed, leaving 20 participants’ data for post-workshop analysis. For participant self-assessment of learning, a rating system based on a revised Bloom’s taxonomy was developed. Revised versions of this tool are widely utilised in life sciences education (Larsen et al., 2022). Learning was also assessed using three traditional, exam-style questions developed by the workshop trainers.
The majority of the data outlined in this article is descriptive. The correlation between participants’ English language proficiency and their preference for training materials was evaluated using a Pearson’s Chi-Square test (McHugh, 2013; Sharpe, 2015). A thematic analysis was conducted to uncover key themes in participants’ feedback (Fugard, 2020).
Figure 1 illustrates the distribution of participants based on their countries of origin (Figure 1A) and work (Figure 1B). Peru was the primary destination for work, attracting nearly 25% of participants, while also serving as the country of origin for 26% of the participants. Furthermore, a significant majority, approximately 75% of the participants, were engaged in work activities within the geographic regions of South, North, or Central America. Similarly, approximately 80% of the participants originate from these same regions. Almost 20% of the participants declared hailing from and working in Spain. 77% (n = 116) of participants had never worked, studied, or lived in an English-speaking country (Figure 2A). Sex representation was even across participants, with 73 self-identifying as male and 72 self-identifying as female (Figure 2A). Six participants preferred not to self-identify as either male or female.
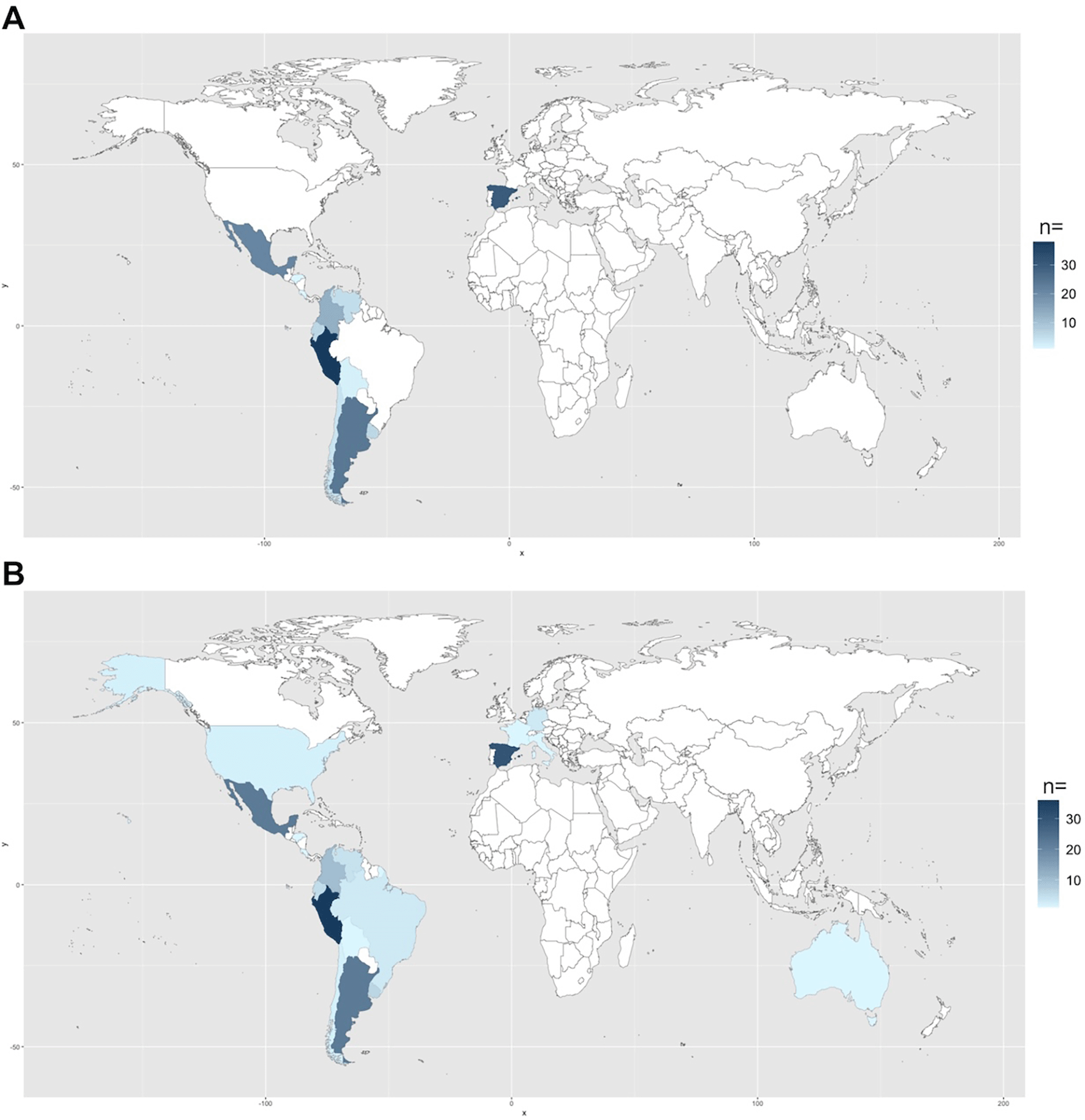
(A) Distribution of participants across their country of origin, and (B) country of work.
(A) Participants with experience living or working in an English-speaking country and sex representation across participants (self-identified), (B) Participants’ highest level of education and English proficiency, (C) English proficiency across education groups.
Figure 2B presents the distribution of participants’ highest level of education. Approximately 76% of the participants reported possessing a university qualification, while around 20% stated having a baccalaureate or A level qualification only. A subset of 5 participants possessed neither a university qualification nor a baccalaureate/A level qualification. Within the university qualifications, Undergraduates (28%), Masters (23%) and PhD degree holders (25%) were evenly represented.
Participants were requested to self-assess their proficiency in the English language. Approximately 45% of participants indicated possessing an intermediate level of English proficiency (Figure 2B). Around 30% of participants characterized their English proficiency as advanced, while thirteen participants regarded themselves as fluent in the language. Among the proficiency categories, beginners constituted the second smallest group, with roughly 15% of participants. When taking education level into account, the percentage of participants categorized as beginners in English diminishes with educational longevity. This reduction starts from 35% among participants with a Baccalaureate/A level qualification, reaching 0% for Master’s holders and 3% for PhD holders. English proficiency correlates with higher educational attainment, as illustrated in Figure 2C. Conversely, as the beginner category declines, the intermediate category experiences a corresponding increase. Among Baccalaureate/A level holders, 29% fall within the intermediate proficiency range, while the proportions rise to 43% for Master’s holders and further to 61% for PhD holders. Interestingly, Master’s degree holders demonstrate a notably more advanced English proficiency compared to their peers across other educational levels. Approximately 46% of participants in this group reported having an advanced proficiency level, in contrast to 26% for those with Baccalaureate/A level and PhD qualifications, and 28% for those with Bachelor’s degrees/Undergraduate degrees. Fluent category (13 total participants) remains consistent across all education levels, with an average of 9.5%.
When asked their preferred language for workshop materials - HES, ENG, or CAT - almost 74% of participants expressed a preference for HES. A notable 25% indicated a preference for ENG, while only one participant selected CAT (Figure 3A).
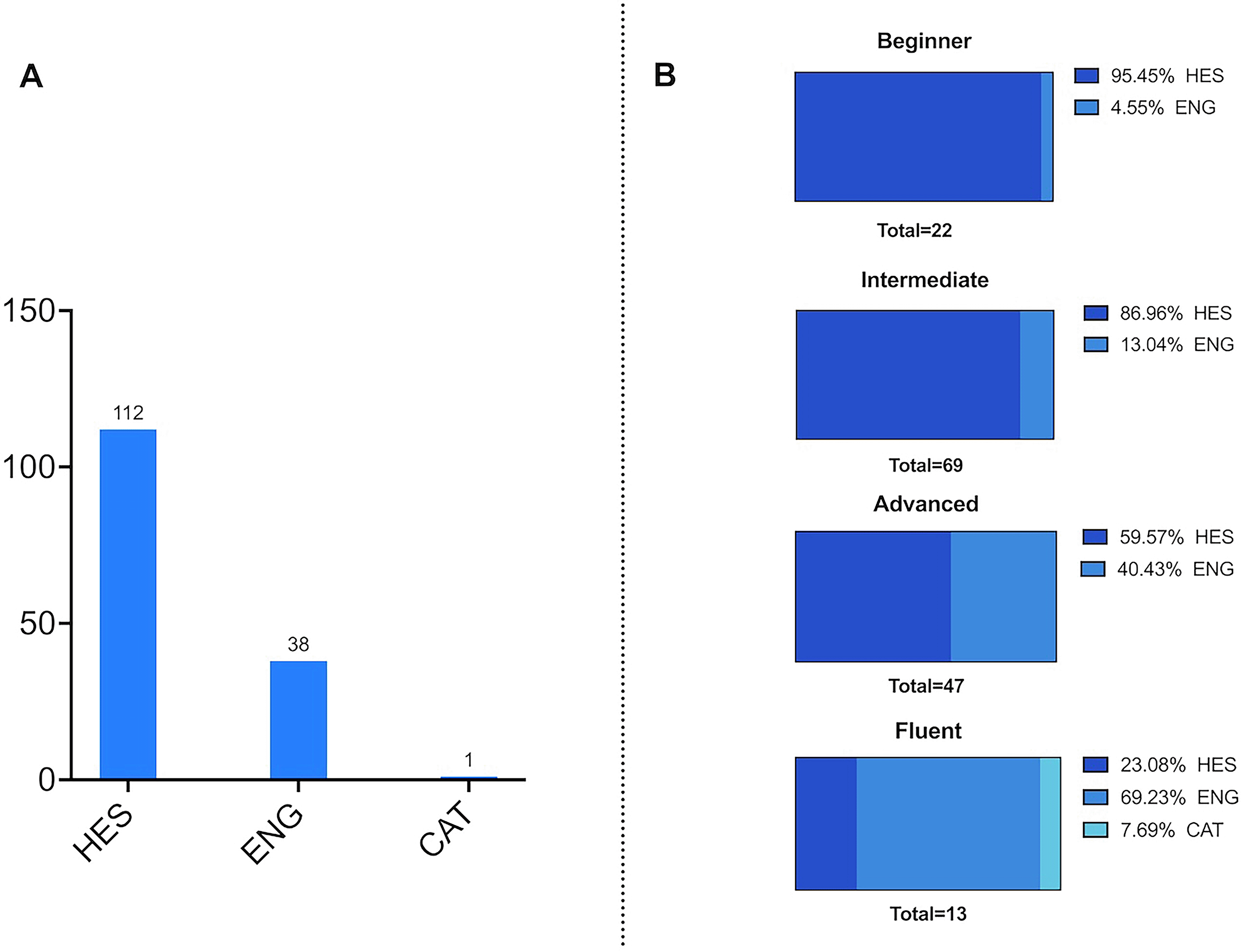
(A) Preferred language for workshop materials, (B) Preferred language for workshop materials per English proficiency.
We further examined participants’ language preferences in relation to their English proficiency. The higher the English proficiency, the less inclined participants are to opt for HES as their preferred language (Figure 3B). This trend relating English proficiency and preferred language group was statistically significant ( Table 1) (X2 = 41.53, df = 6, p = <.001). The “CAT” preference was under-represented across beginner, intermediate, and advanced fluency levels.
Adjusted residuals denoted in bold represent values that go beyond the range of +/- 2. Adjusted residuals suggest deviations from what would be expected if language fluency and language preference were independent.
Out of the 151 participants who completed the pre-workshop survey, only 20 completed (13%) the post-workshop survey, therefore the data presented here is descriptive only. The post-workshop survey was designed to collect data with regard to participants’ learning outcome as well as participants’ feedback regarding language groups.
Among those 20 participants, six were randomized in group ENG, seven in group HES, and seven in group CAT (Figure 4A). Participants were given the opportunity to migrate from their group of origin to a different group at any point (Figure 4A). Seven participants did so: one participant migrated from ENG to HES, two participants migrated from HES to ENG, and finally four participants migrated from CAT, two each to ENG and HES. The final number of participants for each group was nine for ENG, eight for HES, and three for CAT, as seen in Figure 4A.
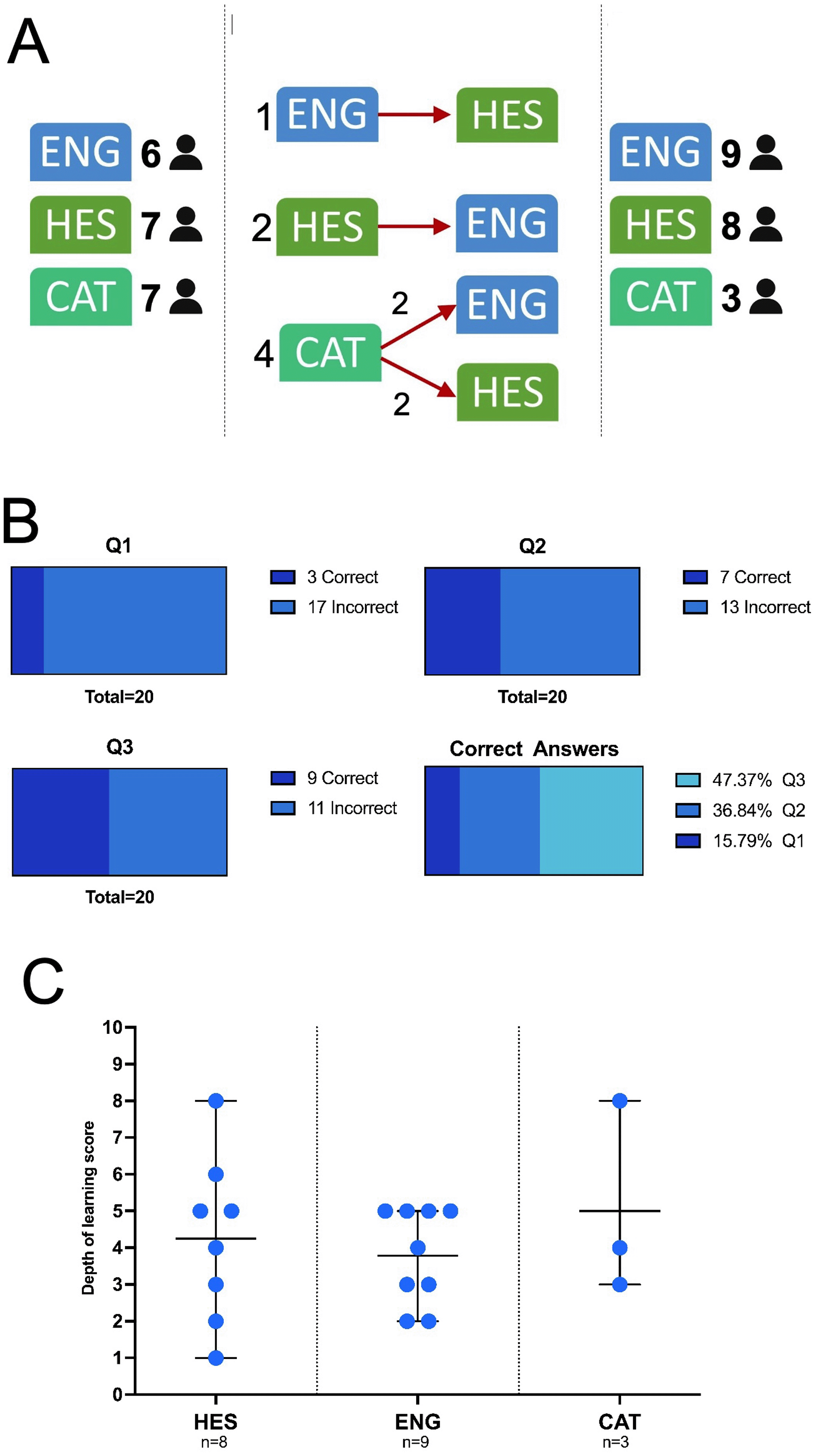
(A) Number of participants randomized in each group and participants’ migration towards a different group with final number of participants per group after migration, (B) Correct answers per question, (C) Depth of learning scores across language groups.
Qualitative feedback was collected from participants to understand the rationale behind their migration towards a different group. The main reason why more than half of the participants originally randomized into CAT decided to leave this group was because of the quality of the translations generated by the Machine Translation. One participant mentioned that:
La traducción automática genera muchas incoherencies en palabras y por tal razón su interpretación. Los video tambien tenian sus problemas de traducción y de imagenes.
The automated translation generates many inconsistencies in words, and for this reason in their interpretation. The videos also had translation and image problems.
Another participant noted:
Había muchos errores de traducción en la traducción automática que dificultaban el seguimiento del curso.
There were many translation errors in the automated translation that made it difficult to follow the course.
In terms of other language group transfers, one participant transferred from HES to ENG with the following rationale:
Prefiero utilizar inglés cuando trabajo con este tipo de análisis porque estoy más acostumbrada a estos términos.
I prefer to use English when working with this type of analysis because I am more accustomed to these terms.
Finally, one participant transferred from ENG to HES, and explained:
Me parece más cómodo aprender usando mi idioma nativo.
I find it more comfortable to learn using my native language.
The participants were then tasked with answering three questions in order to test their comprehension of the material.
Figure 4B gives an overview of the success rate across all 3 questions, which is around 33.3% on average. Question 1 recorded the lowest success rate with only 15% correct answers, whereas Question 3 recorded the highest success rate with 45% correct answers. Looking at the success rate per language group, we can observe that participants within the CAT group performed the worst, with 67% scoring 0 correct answer, and 33% scoring 1 correct answer only. ENG and HES groups display close performance, with HES being the only group scoring 3 correct answers.
In addition to scores based on knowledge questions, participants were asked to self-assess their depth of learning after completing the workshop. This was done using an 8-point scoring system based on the Bloom’s Taxonomy learning levels, as follow:
• 1: Repeat with help
• 2: Repeat without help
• 3: Describe what you are doing in the workflow
• 4: Describe why most tasks need to be done and their outcomes
• 5: Implement the analysis on public (or your own) data (not counting data already in the tutorials)
• 6: Compare and contrast analytical choices (i.e., for granularity of cluster calling)
• 7: Defend of critique interpretation of data based on its analysis
• 8: Design novel workflows for single cell analysis
Figure 4C provides an overview of the self-assessed scores for each participant based on their final language group. The average self-assessed score for the HES group is 4.25, with scores ranging from 1 to 8. For the ENG group, the average score is 3.8, with scores ranging from 2 to 5. Finally, the average score for the CAT group stands at 5, with scores ranging from 3 to 8.
Participants were given the opportunity to provide free-form feedback in both pre- and post-workshop surveys. Pre-workshop survey contained two such questions, post-workshop survey contained six. From this feedback, two main themes arose, along with seven sub-themes ( Table 2). In addition to the poor quality of machine translations, the general appreciation for translated materials was high, along with preferences for English or bilingual materials. Workshop design also appeared frequently, with a desire for more time, more detail, and an appreciation for the live trainer support.
Main themes and sub-themes identified from participants’ feedback. Description provided for each sub-theme. Participants’ quotations are available in the underlying data.
Along with the feedback collected from the participants, feedback was also collected from three of the translators involved in translating the materials from English to Spanish. One translator mentioned that the main challenge they faced during the translation process was:
Disciplinary vocabulary mainly. Also, the interface is in English and even in the term dictionary, there were certain things we agreed to keep untranslated.
It was also added that:
There was definitely a lack of resources directed to other language speakers.
Another translator mentioned that:
The main challenge was to translate the colloquial phrases we had in the video tutorials. In some cases, there was no real translation and we had to use completely different phrases with similar meanings. Also, some specialised terms used in the field were difficult to translate and in some cases, it turned out that no translation was required at all.
Lastly, one translator provided some insight into their translational approach and the resources they used:
I use The Carpentries’ Glossary (Multilingual and open-source glossary of terms used in computer science. Available at: https://github.com/carpentries/glosario) and I kept notes of how people were translating terms to favour the use of preferred terminologies.
The findings of this study provide insights into the demographics, language preferences, learning outcomes and experiences of Spanish-speaking bioinformatics trainees and trainers. This study is pioneering in its approach, by simultaneously providing a resource for bioinformatics learning across languages and a platform for voicing the experiences and preferences of native Spanish-speaking scientists. Additionally, the study facilitated contributions from educators and developers of bioinformatics training resources, enabling them to share insights from their experience.
While a few participants indicated working outside the hispanosphere, the large majority reported originating and working in a Spanish-speaking country, predominantly in Latin America. Participants displayed a broad range of English proficiency and education levels, with a significant portion self-assessing their English proficiency as beginner or intermediate. The study revealed a clear preference among participants for bioinformatics resources in Spanish, evident from their choice of language group and the feedback they provided. Also apparent was the general aversion towards machine-translated materials, as indicated by the lack of interest shown by participants in this language group and the feedback they provided. With regard to learning outcomes, knowledge questions recorded a majority of incorrect answers, contrasting with participants’ self-assessed depth of learning but corroborating general workshop feedback wanting more time and more explanation.
Language can create a barrier in science and the use of English as lingua franca of science has both advantages and disadvantages (Woolston and Osório, 2019). While English serves as a facilitator of global collaboration in science, its dominance also raises concerns regarding linguistic diversity and inclusivity. The advantages of a common language for communication must be weighed against the disadvantages of potentially excluding non-English-speaking scientists and overlooking the rich scientific contributions emerging from diverse linguistic and cultural contexts. This barrier is exemplified within the demographic of native Spanish speakers in our study, the majority of whom reported possessing a beginner or intermediate level of English proficiency. This poses potential challenges for their ability to access and engage with English-language bioinformatics materials, which could hinder their capacity to understand training materials or replicate research findings in this field (Işık et al., 2023; Ras et al., 2021).
Additionally, the clear preference among participants for resources in Spanish underscores the importance of linguistic familiarity and cultural resonance in scientific communication. This preference reflects a desire to engage with materials in their native language, where nuances and context are more readily understood, potentially enhancing comprehension and knowledge retention. Participants’ choice of language for training materials was closely associated with their level of proficiency in English. The greater their proficiency in English, the more inclined participants were to opt for English as their preferred language. Nevertheless, Spanish was the favored language for training materials, except for those fluent in English. Fluent speakers constituted less than nine percent of all participants.
Machine-generated translation was the least preferred by our participants. Participants’ feedback showed that machine-generated translations lack precision and intelligibility for bioinformatics materials. Machine Translation (MT) has the potential to accelerate and facilitate knowledge exchange in science (Tinsley, 2019; Steigerwald et al., 2022), however such MT systems require training on domain-specific data in order to capture the complexity of the domain, such as specialised terminology. The limitations of current machine translation systems underscore the need for domain-specific adaptations to improve their efficacy in scientific contexts. This process of domain-adaptation (i.e., tailoring a MT system to a specific discipline) can be laborious and expensive, especially for low-resource domains, but has been proven to enhance the quality of MT-generated translations for the domain in which the system is adapted (Chu and Wang, 2018; Saunders, 2022). The system used to generate automated translations for this study was not specifically trained on bioinformatics data. As such, it is likely that this system failed to translate domain-specific elements, such as terminology. Furthermore, as emphasized in the feedback from translators, there is a scarcity of resources available to support translators in the translation of bioinformatics materials. This poses yet another challenge in the effort to develop multilingual resources in this field.
We acknowledge several limitations in our current study.
Firstly, there was a disparity between the number of participants who completed the pre-workshop survey and those who completed the post-workshop survey, preventing us from performing statistical analyses on the post-workshop data. In this study, participants were not incentivized to complete the post-workshop survey, which may have affected participation rates. We propose that offering incentives could enhance participation and motivate respondents to complete a post-workshop survey.
Secondly, based on participant feedback, there is room for improvement in the workshop design for future investigations, particularly by allowing participants more time to complete the tutorials. Moreover, the current study does not aim to gather data regarding participants’ socioeconomic backgrounds and access to language education. These factors could provide additional insights into the current landscape of bioinformatics education and training, as well as their accessibility, in Latin America.
Thirdly, as previously discussed, the machine-generated translations were conducted using a Machine Translation system not specifically tailored for the bioinformatics domain. It is likely that a system customized for this purpose would yield more accurate translations. It would be worth exploring the idea of a domain-adapted MT system for bioinformatics in a future study, and how this system performs, as the existence of such system could not be identified in the existing literature.
In conclusion, our study provides valuable insights into the demographics, language preferences, and experiences of Spanish-speaking bioinformatics trainees. We observed a clear preference among participants for Spanish content, emphasizing the importance of scientific translation and the availability of multilingual resources. However, machine-generated translations were found to be less preferred due to their lack of precision and intelligibility for bioinformatics materials. Addressing the language barrier in bioinformatics requires innovative solutions, such as the development of domain-specific machine translation systems tailored to the unique linguistic and terminological characteristics of the field. Overall, our study highlights the importance of addressing language barriers in bioinformatics to foster inclusivity and equity in scientific training, communication and research.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)