Keywords
Recommender Systems; Collaborative Filtering; Similarity Metrics; Predictive Modeling; Behavioral Analytics; Personalization; Decision Intelligence
This article is included in the Software and Hardware Engineering gateway.
Recommender Systems; Collaborative Filtering; Similarity Metrics; Predictive Modeling; Behavioral Analytics; Personalization; Decision Intelligence
Recommender systems have evolved into fundamental components of modern decision making, driving personalization and consumer engagement across multiple industries. From Amazon to Netflix, leading global enterprises rely on statistically driven recommendation algorithms to interpret customer behavior and tailor digital experiences accordingly.1 By leveraging user-item interaction data, these systems employ advanced techniques to predict future user preferences and optimize product exposure.
Empirical evidence underscores their economic significance. A McKinsey study estimates that nearly of Amazon’s total sales are directly attributable to its recommendation engine.2 Amazon’s multilayered deployment of recommender algorithms integrated across browsing, search, and checkout environments has redefined the e-commerce experience and raised competitive barriers for market entrants.3 Firms that systematically apply data driven recommender methodologies exhibit higher conversion efficiency, greater customer lifetime value, and stronger market differentiation.
Recommender systems are embedded across diverse digital ecosystems and serve as core engines for personalization and decision intelligence. They influence consumption patterns by filtering information and tailoring content according to user preferences. Key applications include:
• E-commerce: Personalized product ranking, bundling, and cross-selling on retail platforms such as Amazon.3
• News and Publishing: Dynamic content curation based on reading frequency, dwell time, and topical affinity.
• Music and Podcasts: Platforms such as Spotify employ collaborative filtering and similarity models to recommend audio tracks and playlists aligned with listener preferences.
• Video Streaming: Netflix and YouTube apply collaborative filtering to predict viewing patterns, optimize watch next queues, and enhance user retention.4
• Social Media: Systems on platforms like Instagram and Facebook infer interest clusters, enabling targeted recommendations and advertising.
• Travel and Hospitality: TripAdvisor and related services recommend destinations and accommodations based on spatial, behavioral, and preference proximity.
The economic impact of recommender engines is significant. For instance, Netflix offered a million prize for a model achieving a reduction in mean-squared error (MSE) relative to its production algorithm.5 Such incentives underscore the analytical rigor and commercial value associated with advancing recommender methodologies.
Recommender systems are analytical engines that identify and suggest products or services aligned with user preferences. By analyzing interaction patterns and behavioral signals, these systems infer latent interests and generate personalized recommendations tailored to individual consumption profiles. For example, a user who consistently engages with the horror genre in film platforms may receive suggestions for additional horror titles, thereby enhancing engagement and increasing platform retention.
Recommender systems learn from observed interactions by modeling the relationships between users and items. These relational structures form the foundation of preference inference and prediction. Three primary relationship types drive these systems:
User-Item Relationship User-item preference data forms the core of recommendation models. For example, a user who frequently purchases books on Amazon will receive suggestions for similar or complementary books. Likewise, a user repeatedly purchasing beauty products will be recommended related cosmetic items according to their purchase profile.
Item-Item Relationship Item similarity is derived from co-engagement patterns. Consider a viewer who watches Superman. The system may recommend Aquaman due to shared characteristics within the DC Comics universe. This mechanism is particularly effective in cold-start situations for new items, where similarity to known items accelerates exposure.
User-User Relationship Users with similar historical patterns can guide recommendations for one another. For instance, if two readers have both engaged deeply with the Harry Potter series, and one has also read The Lord of the Rings, the system can recommend the latter title to the other user. This process is valuable in early-stage engagement when a user is exploring a new category. The conceptual structure of similarity signals in collaborative filtering is illustrated in Figure 1.
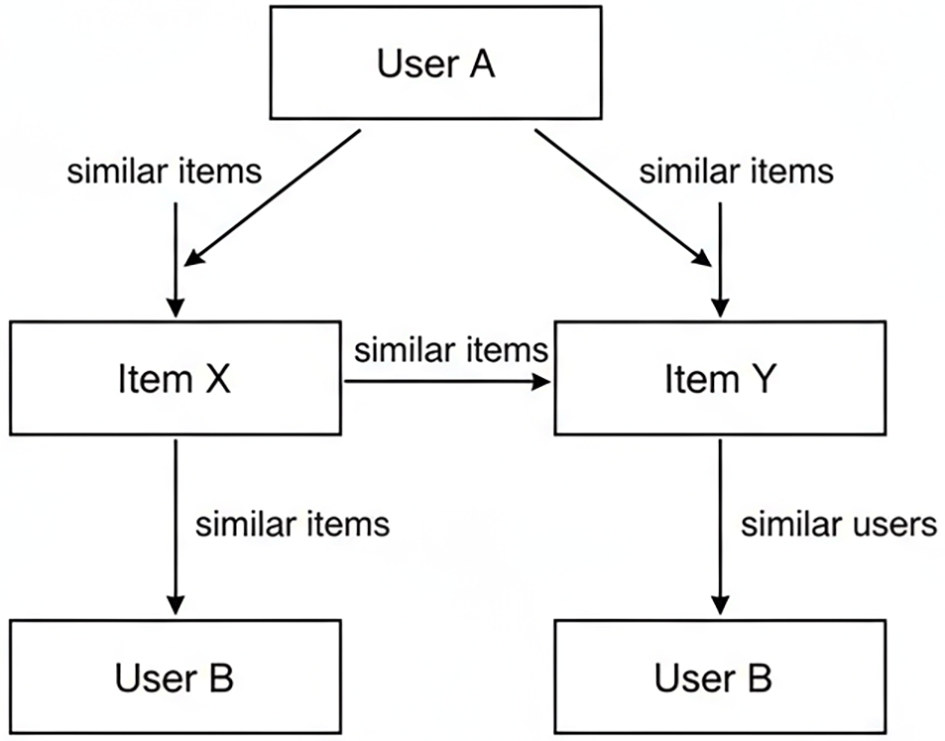
This diagram illustrates the foundational similarity relationships used in collaborative filtering, including user–user similarity, item–item similarity, and user–item interactions.
Collaborative filtering (CF) operates on the principle that users who have exhibited similar preferences in the past are likely to share comparable interests in the future.6 CF models leverage observed interactions-such as ratings, clicks, or purchase histories-to infer latent preference structures without requiring explicit content features.
Two primary CF paradigms exist: user-user filtering and item-item filtering. In user-user CF, recommendations are derived by identifying users with similar historical engagement patterns and estimating the target user’s interest based on their neighbors’ preferences. Conversely, item-item CF examines correlations among items; a user who interacts with an item is recommended other items that exhibit high similarity to it.7
To generate meaningful recommendations, collaborative filtering relies on the computation of pairwise similarity scores. These metrics quantify how strongly two users or two items align based on observed data structures. Common similarity measures include:
• Jaccard Similarity: Measures the ratio of shared items or interactions to the union of items across users, capturing the degree of overlap.
• Euclidean Distance: Computes geometric distance between rating vectors, reflecting dissimilarity based on absolute deviations.
• Cosine Similarity: Evaluates the cosine of the angle between two high-dimensional vectors, emphasizing directional alignment rather than magnitude differences. This metric is particularly effective in sparse rating matrices.
By applying these metrics, CF systems estimate preference scores and rank items to deliver personalized recommendations. The interaction between users and items within a collaborative filtering model is illustrated in Figure 2.
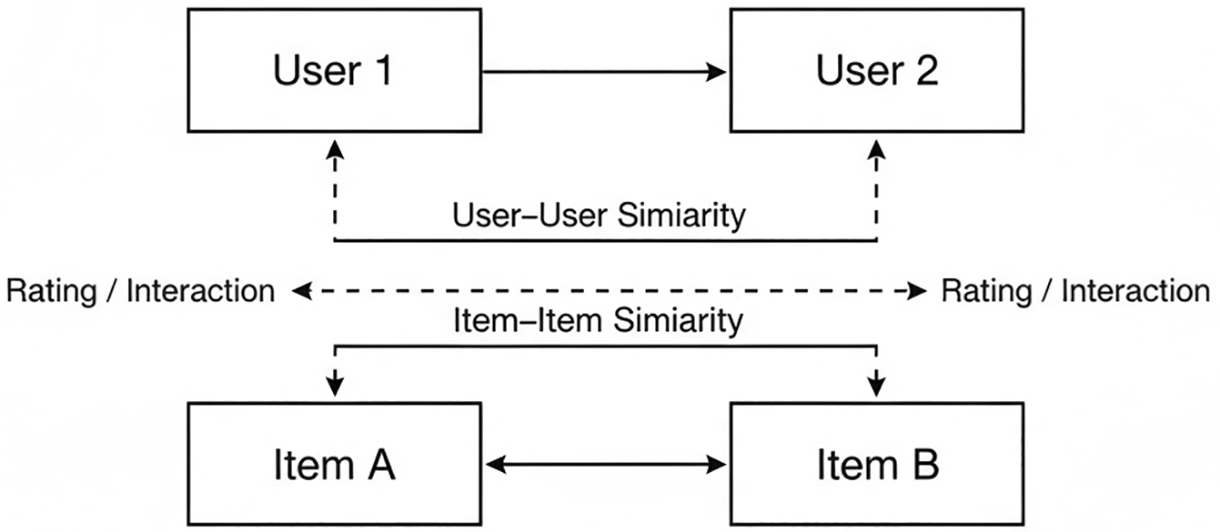
This diagram depicts how similarity is computed from user–user interactions and item–item rating patterns, forming the basis of collaborative filtering prediction.
The user-based collaborative filtering prediction is formally defined in Equation 1 which models the expected rating as a similarity-weighted adjustment of a user’s baseline preference.
This formulation estimates the unknown rating as the user’s baseline preference ( ) plus a weighted average of rating deviations from similar users, where the weights correspond to pairwise similarity scores. In other words, users with greater similarity to exert stronger influence on the prediction. This represents the foundational model for user-based collaborative filtering. The same logic extends to item-based collaborative filtering by interchanging the user and item indices, allowing the system to infer preferences by examining relationships among items rather than users.
Item-Based Collaborative Filtering Rating Prediction The corresponding item-based prediction model is expressed in Equation 2, where similarity among items guides the recommendation process.
In this formulation, recommendations are generated based on the similarity among items that the user has already interacted with. Unlike the user-based method, which compares users to one another, item-based collaborative filtering compares items using shared patterns of user engagement. This approach is computationally efficient and widely adopted in large-scale systems, such as Amazon’s item-to-item recommendation engine.
Jaccard similarity
Jaccard Similarity measures the degree of overlap between two users or two items based on shared interactions. It is defined as the ratio of the intersection of item sets to their union, producing values between 0 and 1. A higher score indicates greater similarity. The relationship between intersection and union in Jaccard similarity is illustrated in Figure 3.
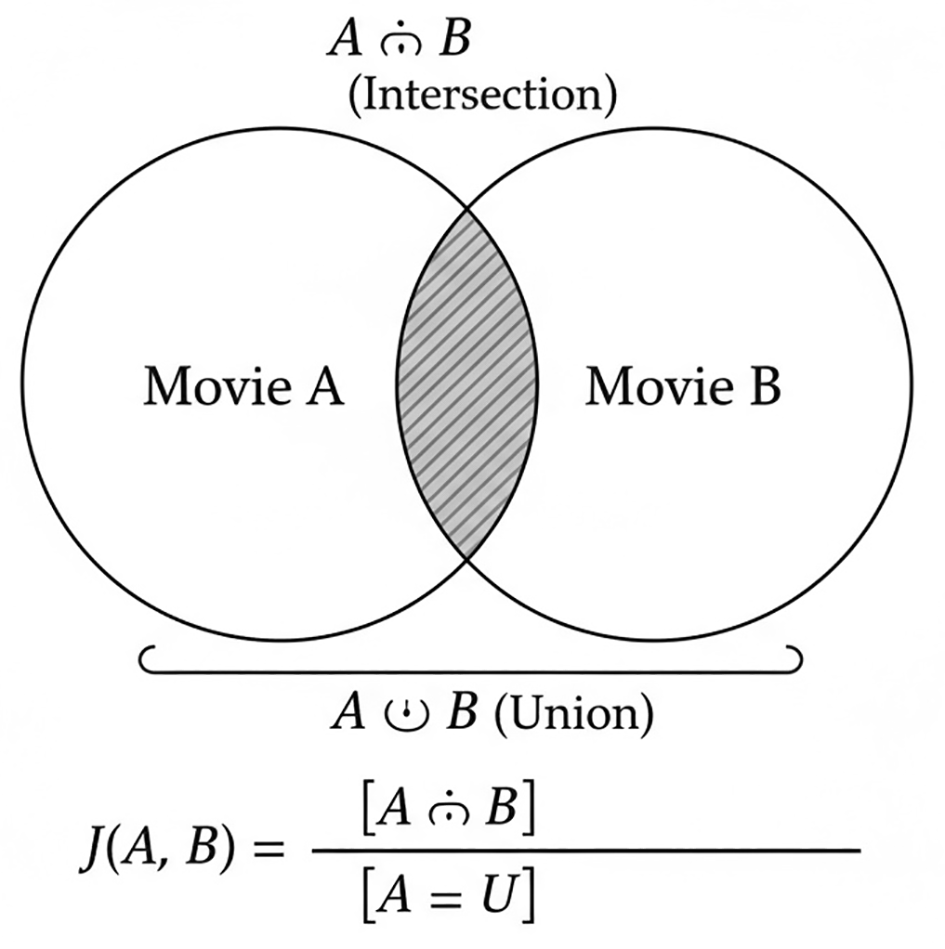
This diagram visualizes how Jaccard similarity is computed by comparing the overlap between two sets (intersection) relative to their combined unique elements (union). It demonstrates how shared items between Movie A and Movie B contribute to their similarity score.
The Jaccard similarity formulation is shown in Equation 3.
where:
Euclidean distance measures the geometric distance between two users or items in a multidimensional rating space. Unlike correlation-based similarity measures, Euclidean distance represents dissimilarity, where a smaller value indicates stronger similarity between two profiles. As shown in Figure 4, Euclidean distance captures the dissimilarity between items based on squared rating differences.
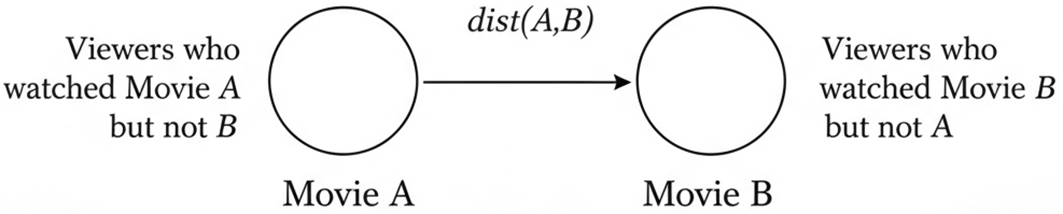
This diagram illustrates how Euclidean distance quantifies dissimilarity between items by measuring squared rating or interaction differences across shared users. A larger distance indicates more divergent user engagement patterns between Movie A and Movie B.
For two items and , the distance is computed using Equation 4.
• - Rating or interaction value of user for item
• - Rating or interaction value of user for item
• - Number of users who interacted with either item
For interpretability, practitioners sometimes use the squared distance form ( Equation 5):
Euclidean distance performs effectively in low-dimensional or moderately sized datasets, particularly when only a limited number of overlapping users or items exist.
Cosine similarity measures the cosine of the angle between two vectors representing user or item profiles in a multidimensional space. It captures how closely aligned two entities are in direction, irrespective of magnitude, making it highly suitable for sparse, high-dimensional datasets such as movie ratings or user-item interaction logs. A vector-space interpretation of cosine similarity is illustrated in Figure 5, showing how the angle between two item vectors determines their similarity.
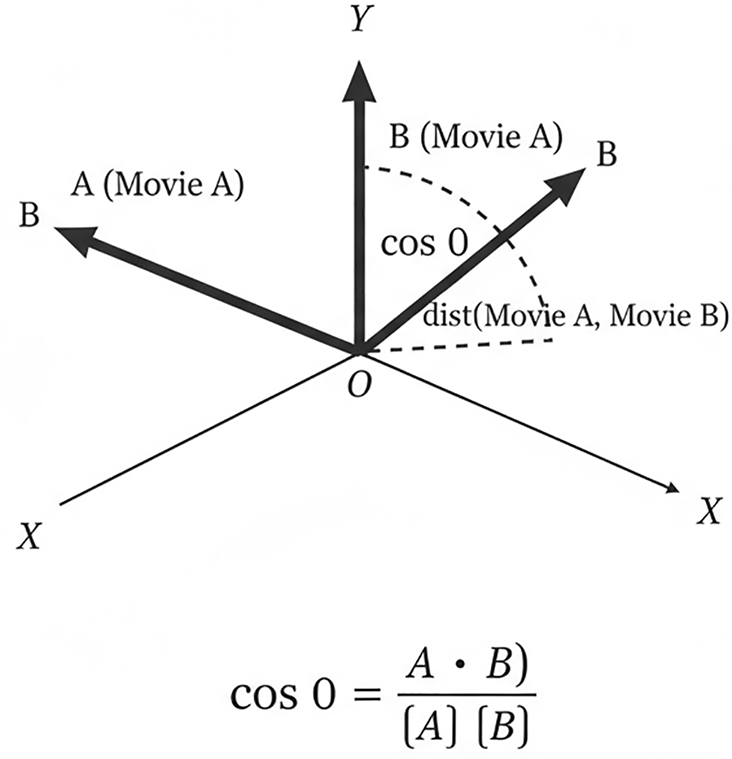
This diagram visualizes cosine similarity in a vector space, illustrating how the angle between item vectors (Movie A and Movie B) determines similarity. A smaller angle indicates stronger alignment between rating patterns, while a larger angle indicates divergence.
For two items and , cosine similarity is defined in Equation 6.
The cosine similarity score ranges between -1 and 1:
The directional interpretation of cosine angles is summarized in Table 1.
The recommender framework was developed using the IMDB Extensive Dataset available on Kaggle.8 This dataset provides comprehensive metadata such as movie titles, genres, release information, production studios, and user generated ratings, making it suitable for collaborative filtering research.
The complete implementation, including preprocessing scripts and model code, is publicly available in the author’s Zenodo repository.13
Two primary data files-one containing movie attributes and another containing user ratings-were merged using the movie identifier as the key field. Missing or inconsistent observations were removed to reduce noise and minimize sparsity in the user-item rating matrix.
Categorical attributes (e.g., language, genre) were encoded using binary indicator variables. For instance, English language films were encoded as 1, and non-English films as 0; similarly, each genre category was assigned an individual binary flag. After data cleaning and dimensionality reduction, the final working dataset consisted of approximately 65,000 observations and 80 predictor variables. Trends in movie ratings and review volume over time are summarized in Figure 6, which illustrates how viewer engagement has evolved across decades. Demographic differences in genre preferences are summarized in Figure 7, which compares average movie ratings across four major age groups.
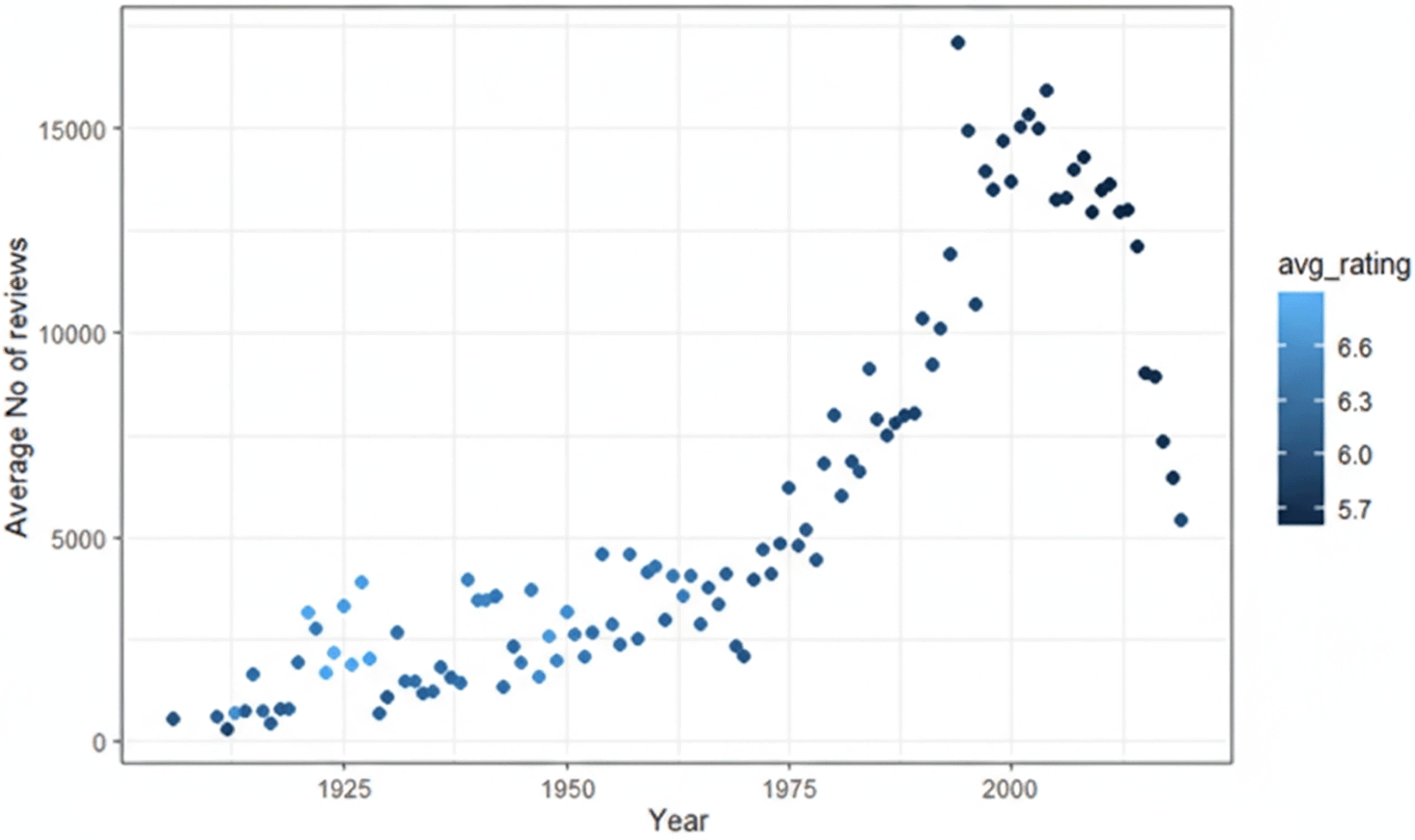
This scatter plot shows how movie popularity (measured by number of reviews) and average ratings evolve over time. Darker points represent higher average ratings, highlighting trends in viewer engagement across different decades.
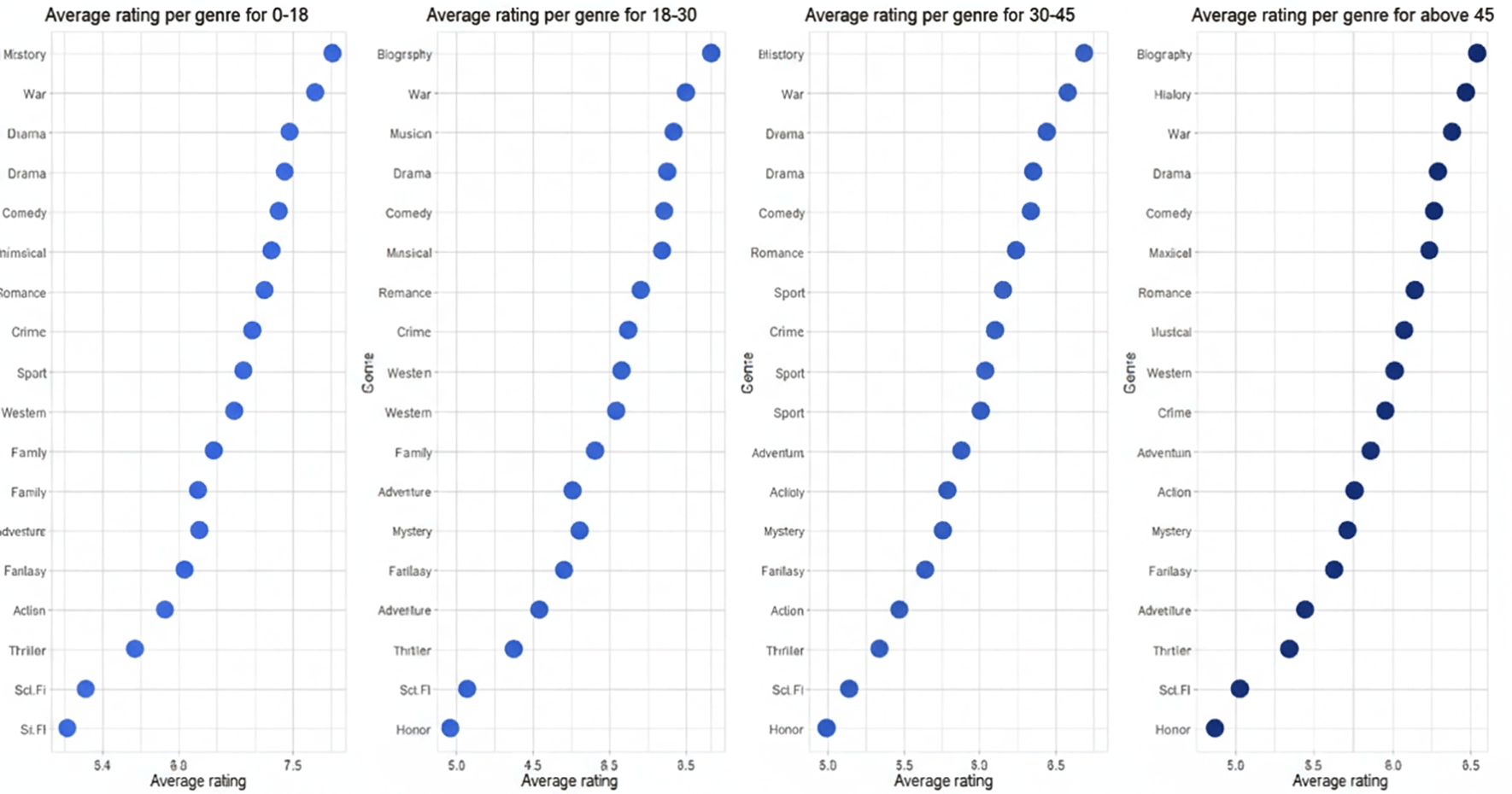
This figure compares how different age groups (0–18, 18–30, 30–45, and 45+) rate movies across various genres. Each panel represents one demographic segment, showing variations in genre preferences and average rating patterns across age groups.
The recommender model is built on collaborative filtering, using cosine similarity as the primary distance metric. Each movie is represented as a vector in a multidimensional feature space derived from metadata and user-rating attributes.
1. Data Integration: Merge movie metadata and user-rating tables.
2. Pre-processing: Remove missing values, encode categorical variables, normalize numeric features.
3. Feature Engineering: Retain key predictors such as release year, user vote counts, genre indicators, and language attributes.
4. Similarity Computation: Compute cosine similarity across the item-item matrix.
Recommendation Generation: Rank all movies by similarity and return Top- recommendations.
The end-to-end workflow of the recommender system is illustrated in Figure 8, showing the stages of data collection, preprocessing, model computation, and recommendation generation.
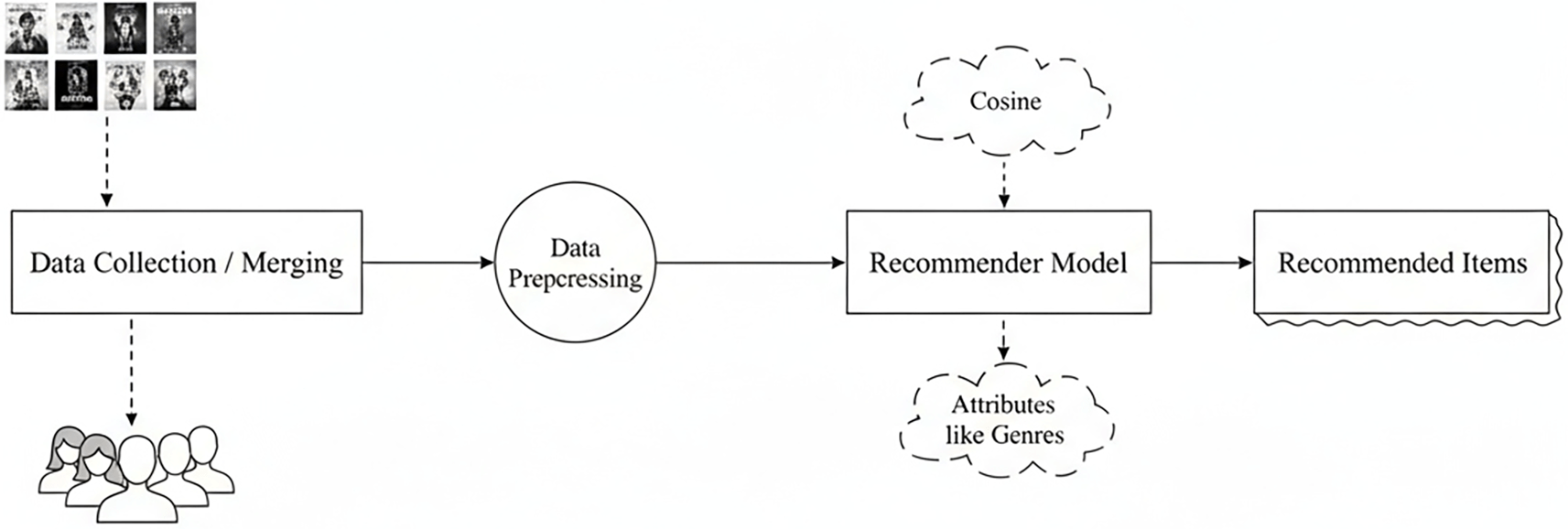
This diagram outlines the end-to-end pipeline used in the recommender system implementation, including data collection and merging, preprocessing, construction of item and user feature matrices, cosine similarity computation, and generation of Top-N recommended items.
The Python 3.10 implementation uses pandas, numpy, and scikit-learn. Full code is available in the GitHub repository.9
Execution steps
The recommender system was evaluated on a curated IMDB movie dataset using cosine-similarity-based collaborative filtering. The evaluation focuses on whether suggested movies align with behavioral and thematic tendencies observed in the user’s previously rated or viewed content.
Based on the input movie Saw (2004), the system retrieved the top five movies exhibiting the highest cosine-similarity values. The recommendation outcomes are shown in Table 2.
The recommender system successfully proposed closely related horror and psychological-thriller films, such as The Silent Scream and Catacombs, for a viewer who watched Saw. This demonstrates strong genre coherence and relevance in the generated suggestions.
The recommendations exhibit high internal consistency, indicating that cosine similarity effectively captures vector-space proximity between movies with comparable thematic and stylistic characteristics. The similarity scores, each approaching 1.0, reflect minimal angular separation between vectors, implying substantial shared audience engagement patterns. This alignment between the watched movie and the recommended titles is illustrated in Figure 9.
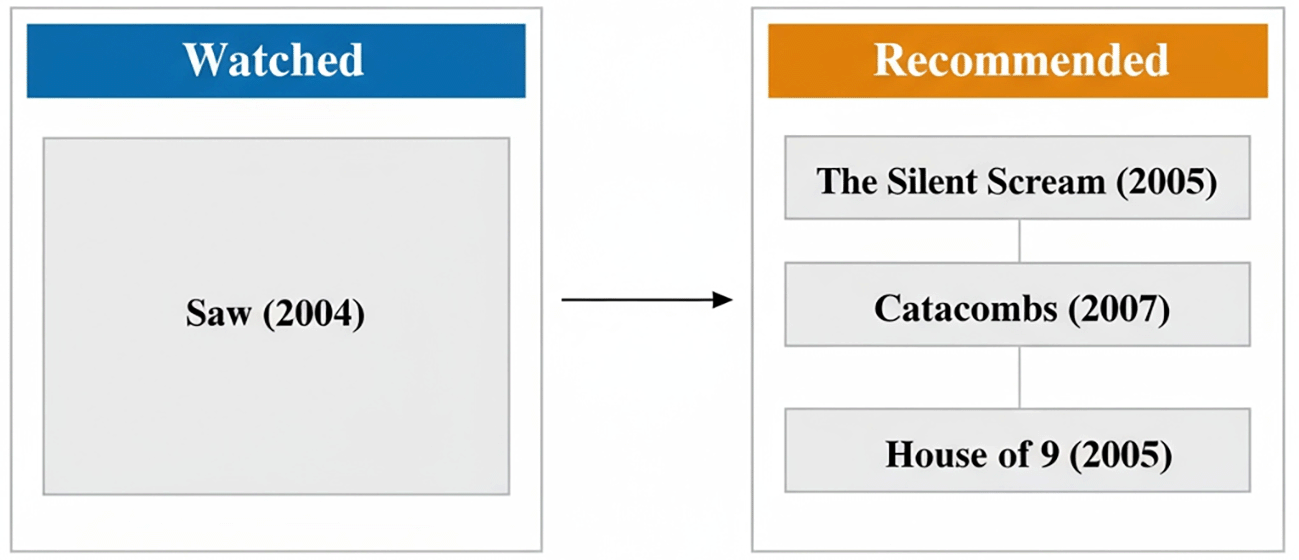
This diagram contrasts a user’s previously watched movie (“Saw”, 2004) with the system-generated recommendations. The suggested movies share strong thematic and stylistic similarities with the watched title, illustrating how cosine similarity captures genre alignment and audience-engagement patterns in the model’s output.
The results indicate that a collaborative-filtering approach, supported by structured metadata and a lightweight similarity metric, can approximate human perception of content relatedness.
The framework is scalable and applicable to multiple domains beyond movies, including music, e-commerce, streaming services, and digital platforms. Item metadata-such as brand, category, or stylistic attributes-can seamlessly replace movie features in domain-specific deployments.
These findings reinforce the viability of similarity-based collaborative filtering as a practical and high-interpretability recommendation strategy for industrial systems.
The evaluation results demonstrate that cosine-similarity-based collaborative filtering can reproduce genre-consistent and thematically aligned recommendations using a relatively simple feature representation. The close alignment between the recommended titles and the seed movie Saw (2004) indicates that vector-space similarity captures meaningful behavioral patterns that extend beyond explicit metadata. This suggests that item-item proximity in rating space can implicitly encode narrative style, pacing characteristics, and audience affinity, even when these attributes are not explicitly modeled.
These findings are consistent with prior work that has shown the effectiveness of item-item collaborative filtering in sparse environments.3 Similar to observations by Bobadilla et al.,6 the model benefits from the fact that cosine similarity emphasizes directional alignment rather than absolute magnitude, making it well-suited for datasets such as IMDB where users interact with only a small fraction of available items. The high internal consistency of similarity scores supports prior evidence that neighborhood-based methods can be competitive benchmarks against more complex latent factor models when interpretability and computational efficiency are required.
The results also highlight the practical utility of similarity-based recommenders as scalable and domain-agnostic tools. Because the model relies on structural patterns in user-item data, it can be deployed in applications such as e-commerce, music streaming, news personalization, or digital media platforms with minimal architectural modifications. The workflow demonstrated here serves as a transparent baseline system that can be implemented rapidly while still offering actionable personalization insights.
Nevertheless, the study also exposes constraints associated with neighborhood-based collaborative filtering. The observed performance is influenced by sparsity in user rating behavior, and the model does not explicitly correct for individual rating bias, which can skew similarity computations. Additionally, similarity-based recommenders inherently struggle with the cold-start problem for new items or users lacking historical data. These limitations motivate further research into hybrid systems that integrate metadata-driven signals or latent embedding methods to enhance robustness.
Overall, the results reaffirm that lightweight similarity-based approaches remain powerful tools for recommendation tasks, especially when transparency and operational simplicity are prioritized. The system presented here provides a strong foundation upon which more advanced or domain-specific enhancements can be developed.
This study presented a comprehensive overview of recommender systems, their foundational principles, and their role in modern digital ecosystems. We outlined the conceptual framework of user-item, item-item, and user-user relationships that underpin recommendation algorithms, followed by collaborative filtering fundamentals and similarity measures such as Jaccard, Euclidean, and Cosine metrics.
Using publicly available IMDB data, a case study demonstrated the practical implementation of these concepts. The resulting system successfully identified and ranked movies similar to a user-provided title, confirming the ability of a similarity-based model to replicate genre associations through vector-space analysis. The findings reinforce that even a simple similarity-driven framework can effectively model user preferences and generate contextually relevant recommendations.
Future extensions could incorporate hybrid architectures that leverage both collaborative and content-based signals, as well as temporal and contextual features to improve personalization accuracy and robustness.
While the proposed framework effectively demonstrates similarity-based collaborative filtering, several methodological limitations exist. First, the use of linear similarity assumptions may oversimplify complex nonlinear preference patterns observed in real-world behavior.10 Second, reliance on pairwise similarity metrics restricts the model’s ability to learn latent representations of users and items.11 Third, the absence of normalization for individual bias and variance may introduce skewness in affinity scoring, particularly for users with extreme rating tendencies or highly popular items. Additionally, the framework does not address the “cold start” problem associated with new users or items that lack historical interaction data.12 Future research could address these limitations by employing matrix factorization or neural embedding techniques,10 probabilistic models to capture uncertainty and behavior variability,12 and hybrid recommenders that fuse collaborative filtering with contextual and content-aware learning to improve scalability and generalizability.
Source code available from: https://github.com/vinoalles/Recommender_System
Archived source code available from: https://doi.org/10.5281/zenodo.17822412
License: MIT License (OSI-approved)
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)