Keywords
Transformed-transformer family, Quantile function, Statistical properties, Estimation methods, Monte Carlo simulation, Real data application and Goodness-of-Fit.
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Transformed-transformer family, Quantile function, Statistical properties, Estimation methods, Monte Carlo simulation, Real data application and Goodness-of-Fit.
In contrast to other facets of life, statistical modeling is important, particularly in probability theory, which is frequently applied to find variation and draw conclusions from observable data. Over the past few decades, a number of novel generalized distributions have been developed and gained importance. The idea that these distributions had more parameters served as the main foundation for their development. Many expansions of traditional statistical models are being used to model the data in every aspect of life.
The majority of new distributions are made using contemporary methods, even though researchers are currently examining methods that have been utilized to build new distributions since 1980; see for example Refs. 1-10.
One of the more recent methods used in this study is the transformed-transformer methodology, which was developed by Alzaatreh et al.11 A novel class of distribution functions was obtained by transforming an extra variable through (-∞, ∞) using the density and distribution functions of a random variable X with r(x) and R(x), respectively.
Anywhere Z(F(X)) belong to [c,d] is monotone increasing, less than infinity, in addition to , besides the following matching pdf
Numerous research have employed the transformed-transformer approach; for example, Refs. 12-14. Aljarrah et al.15 developed a novel family of distributions by substituting the quantile function of extra r. v. Y in relations of F (x) for the function Z (F (x)). This resulted in the T-X{Y} distribution class.
When F(x) equal to λ and p(y) greater than 0 for all y in neighborhood of Qy (λ), such that 0 < λ< 1, this implies that Y (λ) less than infinity and it is equivalent to P[Qy (λ)]−1.
Consequently, the correlated pdf of G(x) is
Assume T, R, and Y are random variables having the quantile functions: QT (p), QR (p) and QY (p); suppose that their distribution functions are FT (x), FR (x) and FY (x), and their corresponding densities which is represented for instance fT (x), fR (x) and fY(x) respectively, through T, Y∈[c, d], besides R∈[e, f] for -∞ < c < d < ∞ and -∞ < e < f < ∞.
Following that, the new class’s distribution function is shown as
In 2021, Ibeh et al.16; introduce new Weibull–Exponential {Rayleigh} distribution based the idea of T-X{Y} family distribution.
The Transformed-Transformer (T-X) Family approach is a modern statistical strategy that offers a flexible framework for generating new probability distributions beyond the limitations of conventional models, utilizing the quantile function as its foundation. This method enables the generation of customized statistical models through the combination of the quantile function of a generating distribution with the cumulative distribution function (CDF) of a base distribution, allowing precise control over shape characteristics such as smoothness, kurtosis, and tail behavior. Its significance arises from its ability to accurately represent non-standard data, provide direct control over the resulting distribution’s shape, and facilitate risk analysis and simulation. This methodology is an effective instrument for scholars and applied statisticians, having demonstrated efficacy across diverse fields, including industrial engineering, medical statistics, financial modeling, and environmental sciences.
In various applied fields, particularly in healthcare and finance, data infrequently follows to the assumptions of fundamental probability models such as the Gaussian (Normal) distribution. Empirical data regularly exhibits skewness, heavy tails, and sometimes multimodal characteristics, interpretation conventional parametric models less effective. In healthcare, variables such as hospital length of stay or blood glucose levels are sometimes markedly skewed: most patients fall within a typical range, whilst a minority exhibit extreme values. In finance, asset returns and market fluctuations exhibit fat-tailed behavior, indicating that significant profits or losses occur more frequently than predicted by Gaussian models. Such deviations from the norm necessitate more adaptable probabilistic modeling techniques capable of managing these complexities while providing precise evaluations of uncertainty. The integration of modified distributions, transformed-transformer family using quantile functions, provides a robust and flexible approach to analyzing complex real-world data.
This paper aims to present and examine the key statistical and mathematical properties of the IDNAII distribution, a novel sub-family of the Lomax–Weibull {Exponential} distribution. Method of estimation will be introduced to estimate the parameters of the new class distribution. Simulation tools have been created to evaluate the effectiveness of estimation approaches. A real-world dataset application has been demonstrated, and the examination to fit the real dataset of the new class distribution with the particular specific distributions, using several types of information criteria will be made.
This article’s additional parts are arranged as follows. The construct of IDNAII distribution, also known as the Lomax–Weibull {Exponential} distribution, is introduced in Subsection 2-1. In Subsection 2-2, most of the aspects of the distribution are presented and analyzed. Parameter estimate techniques for the distribution are introduced in Subsection 2-3. The simulation study and comparison estimators are shown in Subsection 2-4. The application of the real data set is shown in Subsection 2-5. The results are displayed in Section 3. Discussions of the results are exhibited in Section 4. The paper’s summary and conclusions are given in Section 5.
Assume a random variable T with the Lomax distribution, including shape parameter (λ), in addition to cdf, pdf and quantile function which are provided as
Where λ > 0, x > 0 and 0 < P < 1.
Similarly, let a random variable R follows the Weibull distribution with one shape parameter α. The distribution function, probability density function, and the quantile function of R are provided as
Where α > 0, x > 0 and 0 < P < 1.
Furthermore, the cdf, pdf, and quantile function are given as follows if a random variable Y follows the exponential distribution with the scale parameter β.
Equation (8), together with Equation (9), gives us
Accordingly, using Equation (7), we get
Consequently, the cdf of the IDNAII distribution or Lomax–Weibull{exponential} distribution is given by
Therefore, we obtain from Equation (7)
Afterwards, from Equation (9), we acquired
Upon modifying Equation (6) using the previously mentioned equations, the relevant IDNAII distribution pdf is generated as
We deduce that the cdf and pdf of the new class IDNAII distribution with three parameters (α,β,λ) are given by Equations (10) and (13) respectively.
Furthermore, the reliability function for the IDNAII distribution will be determined using Equation (10).
Moreover, this section provides a number of fundamental statistical and mathematical characteristics of the IDNAII distribution, like the following:
2-2-1 Additional IDNAII distribution probability functions
Together with the three functions discussed before in Equations (10), (13), and (14), we present the majority of the probability functions in this section.
2-2-2 The quntial function of IDNAII distribution
The th quantile function of the IDNAII distribution may be found as
The median (xmed) of the IDNAII distribution can therefore be determined with the setting q = 0.5 as
2-2-3 The Mode of IDNAII distribution
The following formula may be used to determine the IDNAII distribution’s mode:
From Equation (13);
2-2-4 Limit of the pdf and cdf of IDNAII distribution
2-2-5 Moments
The IDNAII distribution’s th moments regarding origin and mean are shown in this section.
a- The th moments about origin
b- The rth moments about mean μ
2-2-6 Moment generating function M X(t)
An easy way to define the IDNAII distribution’s moment generating function (MGF) is as
MX(t) = MX(t) = E ( , from Equation (26) above we get
2-2-7 Characteristic function Ф X(t)
One may determine the IDNAII distribution’s characteristic function as
2-2-8 Factorial generating function Ʒ X(t)
The following formula may be used to get the IDNAII distribution’s factorial generating function:
ƷX(t) = , from Equation (26) above we get
2-2-9 Coefficients
We arrive to the following conclusions based on the preceding subsection 2-2-5 (a) and (b). The coefficients of Skewness, Kurtosis, and Variation for the IDNAII distribution are shown below.
a- Coefficient of Skewness (C.S.)
The definition of the skewness coefficient (C.S.) is follows
Thus, skewness coefficient for the IDNAII distribution will be
b- Coefficient of Kurtosis (C.K.)
The Kurtosis coefficient (C.K.) is defined as follows.
Thus, Kurtosis coefficient for the IDNAII distribution will be
c- Coefficient of Variation (C.V.)
The Variation coefficient (C.V.) is defined as follows.
Consequently, the IDNAII distribution’s variation coefficient will be
2-2-10 Probability density functions of order statistic (O.S.)
Assuming a random sample x1,x2,…,xn of size taken from the IDANII distribution having cdf F(x; ) and pdf f(x; ), where =(α,β,λ). Let y1< y2 <… < yn denote to order statistic for this sample. Then the probability density function of yr (r =1, 2,…, n) can be obtained by the following:
2-2-11 Cumulative distribution functions of order statistic (O.S.)
This section presents the order statistic’s cumulative distribution.
The common formula for the cdf of order statistic is
Hence, the cumulative distribution function of rth order statistic will be
2-2-12 Mean time to failure (death); MTTF
In this section, we introduce the mean time to failure (death)
2-2-13 The Average failure rate (AFR)
2-2-14 Self-reproducing property
Let y1< y2 <… < yn denote to order statistic for the sample x1,x2,…,xn of size n drawn from IDNAII distribution having cdf as well as pdf defined in Equations (10) and (13).
Using Equation (35) in property 2-2-10, the pdf of y1 is, f (y1) = nαβλ y1 α-1 (1+ β y1 α)- (n λ+1))
It is clear that y1 follows IDNAII distribution with the parameters (α,β,nλ). As a result, the self-reproducing property is satisfied by the IDNAII distribution.
2-2-15 Entropies
Entropy functions are fundamental concepts in information theory and statistics, as they offer precise estimates of uncertainty inside probability distributions. We present several uncertainty measurements, such as Shannon and Rényi entropies, that may be employed to measure the total amount of data in the system.
Shannon’s entropy has been used in many technical fields, such as physics and economics. Shannon entropy quantifies the anticipated information content of a random variable and is extensively utilized in statistics to characterize variability, inform model selection, and underpin information-theoretic criteria like the Akaike Information Criterion (AIC).
According to Shannon’s 1948 formulation, the entropy of a random variable X with density function f(x) is defined as follows17;
The Shannon entropy for T-R{Y} family distribution was defined as follows16;
Additionally, as was previously indicated; T~ Lomax (λ); R~ Weibull (α) and Y~ Exponential (β).
Where, the Shannon entropy of T is known as
Recall; ln (x) dx = [ ψ(a)- ln(s)]18;
Hence, Shannon entropy of IDNAII distribution will be as follow:
Everywhere, μT refer to the mean of the random variable T.
The Rényi entropy is an extension of Shannon’s formulation that modifies the relative importance of uncommon and frequent occurrences by adding a parameter. This generalization makes it possible to characterize distributions more freely and has been useful in fields including anomaly detection, clustering, robust estimation, and hypothesis testing.
The measure of uncertainty of a random variable X follows IDNAII distribution is determined by its entropy. The Rényi entropy is defined as follows19;
Consequently, The Rényi entropy of IDNAII distribution will be as follows
Consequently, The Rényi entropy IDNAII distribution will be as follows
2-3-1 Maximum Likelihood Estimator (MLE)
The Maximum Likelihood estimation methodology is particularly notable due to its invariance property, distinguishing it from other methods. We investigate the application of the maximum likelihood method to estimate the unknown parameters of the IDNAII (α, β, λ) distribution.
Let x1, x2, …, xn denote the observed values of a random sample of size n from the IDNAII (α, β, λ) distribution.
The probability density function of the IDNAII (α, β, λ) distribution is as follows:
The likelihood function for the vector = (α, β, λ) of parameters can be written as:
The log likelihood function is going to be
The log likelihood function with respect to α, β, and λ is derived as follows:
By setting the aforementioned nonlinear equations to zero and employing the Newton-Raphson approach, the maximum likelihood estimates for the three parameters , and were obtained.
2-3-2 Moment Method Estimator (MOM)
The moment method, proposed by Pearson in 1894, was among the earliest techniques employed to estimate population parameters. Let x1, x2, …, xn represent the observed values of a random sample of size n drawn from the IDNAII (α, β, λ) distribution. From the features of the IDNAII distribution in Equation (26), the non-central moment of order is
In this technique, the kth population moments E ( ) are equated with the kth sample moment , for .
We derive three equations as follows
Utilize the Newton-Raphson method to resolve the aforementioned three nonlinear equations, resulting in the moment estimates for the parameters , and
2-3-3 Least Squared Estimator (LS)
This subsection addresses the estimator of the Least Squares approach. This approach is utilized for numerous mathematical and engineering applications. The primary objective of this strategy is to reduce the sum of squared errors between the observed values and the expected value.
To estimate the three parameters (α, β, λ) of the IDNAII distribution using the specified least squares approach, let x1, x2, …, xn represent the observed values of a random sample of size n from the IDNAII (α, β, λ) distribution, and
Where, refers to the CDF of distribution which is defined as follows:
Derive S w.r.t. , we obtained the following three nonlinear equations respectively
By equating the above-mentioned nonlinear equations to zero and employing the Newton-Raphson approach, the Least Squares estimates for the three parameters , and will be achieved.
2-3-4 Shrinkage Estimator (SH)
In 1968, Thompson introduced the concept of reducing the traditional estimator (MLE) of the parameter α to prior knowledge α0, obtained from prior experiments or the author’s experiences, by utilizing a shrinkage weight factor ∅( ̂), where 0 ≤ ∅( ̂) ≤ 1. The result is a linear combination of the classical estimator, Maximum Likelihood Estimation (MLE), and the previous estimate, α0. Thompson states, “We are estimating α and believe that α0 closely approximates the true value of α, or we are afraid that α0 may be near the true value of α, and we fail to employ α0.” The shrinkage estimator of α, denoted as , is defined as follows:
Utilizing the maximum likelihood estimator as a conventional estimator alongside the prior information (initial value or prior estimate) of in Equation (55) above. Where denote the shrinkage weight factor as we mentioned above such that 0 1, which may be a function of , a function of sample size ( ), a constant or can be found by minimizing the mean square error of . Thus, the shrinkage estimators of the three parameter IDNAII distribution will be as follows:
Where, refer to modified Thompson type shrinkage weight factor by minimizing the mean squared error of as follows20:
The simulation study will be conducted to demonstrate the behaviour of estimators regarding parameters through four proposed estimating methods, followed by a comparison of outcomes utilizing two statistical criteria: bias and mean squared error (MSE). The simulation training is conducted 1000 times in order to gather independent samples of different sizes.
2-4-1 Generating random variables
Let U be a random variable uniformly distributed over the interval (0,1). The data for the IDNAII distribution can be produced with the inverse transformation method for the cumulative distribution function (CDF), where if21:
Then = { [ (1- )-1/λ -1] / β }1/ α
2-4-2 Simulation study
The Monte Carlo simulation program built with MATLAB 2022 includes the following steps for comparing consistency estimators:
1. Random samples x1, x2, …, xn, of sizes , where = 10, 20, 50, 100, are produced from the IDNAII distribution in subsection 2-4-1.
2. The actual parameter values for four cases (α, β, λ) are considered in Table 1.
3. The Bias for all suggested estimators for the parameters was calculated as follows, utilizing L=1000 duplicates, which showed in Tables 2-5.
4. The MSE for all proposed estimators w.r.t. parameters was calculated as below using L=1000 duplicates: as demonstrated in Tables 6-9.
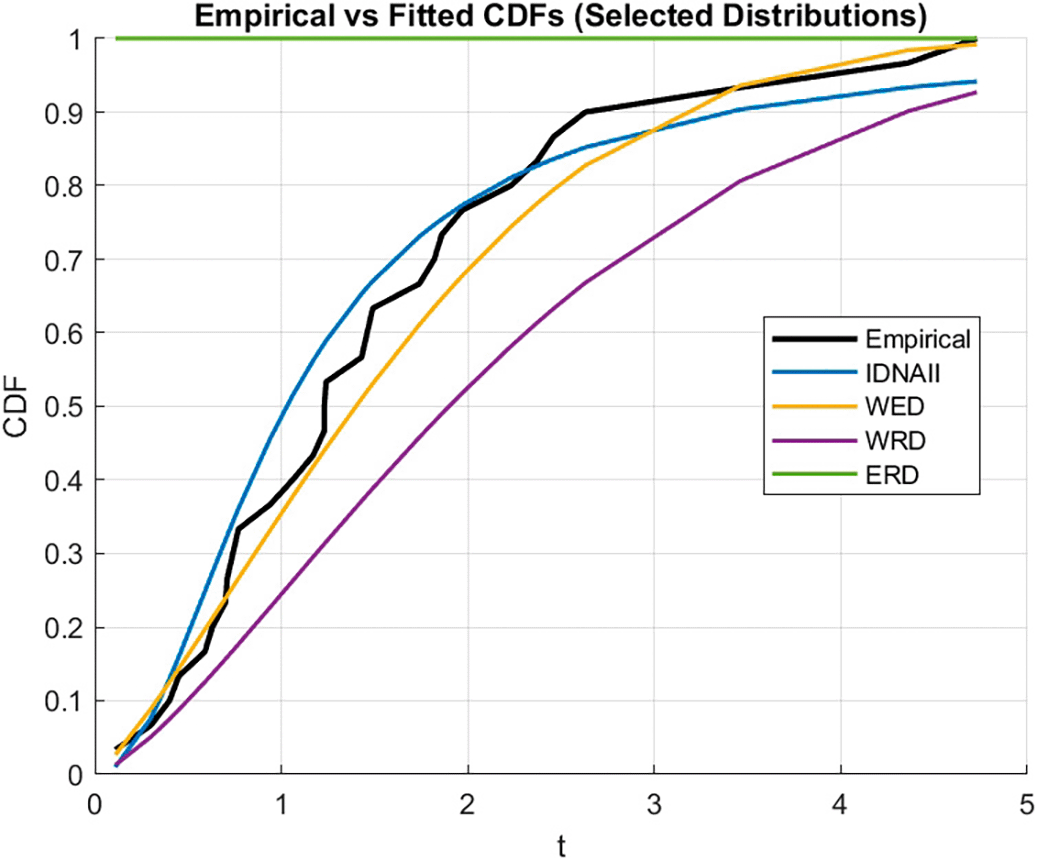
This section does an analysis based on a real dataset. The dataset illustrates the period of time between failures for a repairable item obtained from Refs. 16 and 22. IDNAII appears to be a very competitive model for this data compared to the Lomax distribution, Weibull-Exponential distribution (WED),23 Weibull-Rayleigh distribution (WRD),24 and Exponential-Rayleigh distribution (ERD),25 each with their associated probability density functions (PDFs). The data set and its descriptive statistics are shown respectively in Tables 10 and 11.
To verify that IDNAII distribution is suitable model for the data set, a minus two times of negative log-likelihood value, Akaike information criteria (AIC), Bayesian information criteria (BIC), corrected Akaike information criterion (AICC), Hannan-Quinn information criterion (HQIC), consistent Akaike information criterion (CAIC) and Kolmogorov-Smirnov K-S distance with P-values are used and shown in Table 12, where:
Where logl denotes the log-likelihood at MLEs, k is the number of parameters, and n is a sample size.
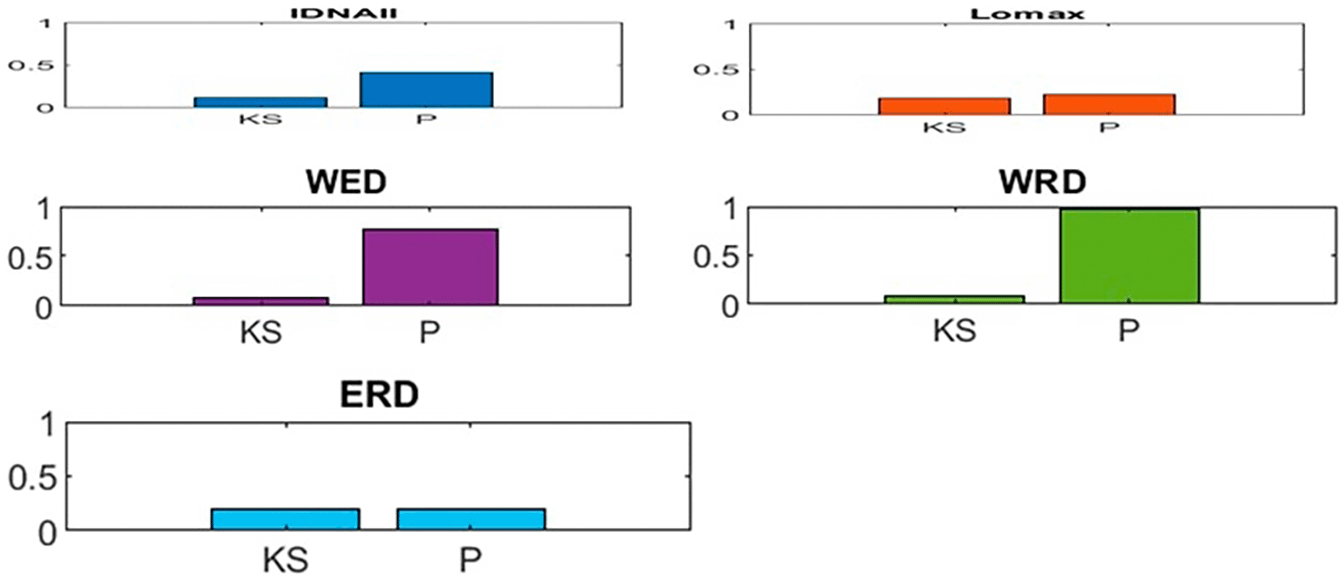
The empirical cdf and estimated cdf of IDNAII and the other distributions as well as the histogram of K-S and P-value are respectively presented in Figures 3 and 4.
This section presents the research findings.
The PDF of the suggested IDNAII distribution in (13) leads to the following conclusions.
(i) The IDNAII (α,β,λ) distribution follows the Lomax distribution with one parameter λ for the random variable y = βX α or Beta prime distribution with parameter 1 and λ.
(ii) When the random variable Z = X α, then the IDNAII (α,β,λ) distribution is interpreted to Lomax distribution with two parameters (β,λ).
(iii) When the random variable V = 1+ βxα then the IDNAII (α,β,λ) distribution reduce to power function distribution with one parameter λ, for V > 1.
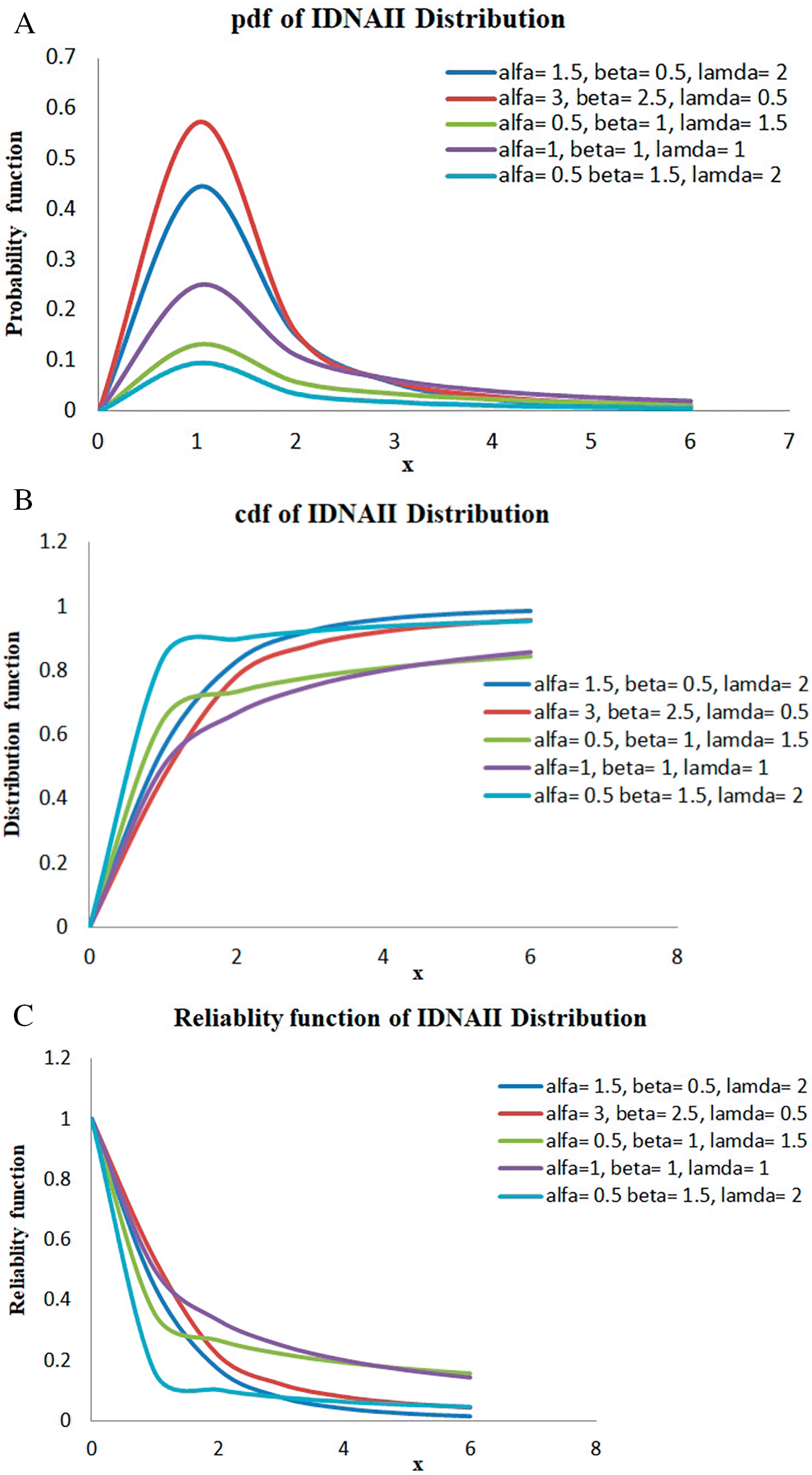
The graphs of the probability density function, cumulative distribution function, and reliability function for the IDNAII distribution for particular parameter values are shown in Figure 1 with the following details.
Figure 1(A) shows that the graph of the probability density functions for the IDNAII distribution with certain parameter values.
Figure 1(B) shows the cumulative distribution function graph for the IDNAII distribution with certain parameter values.
The graph in Figure 1(C) shows the Reliability function for the IDNAII distribution with certain parameter values.
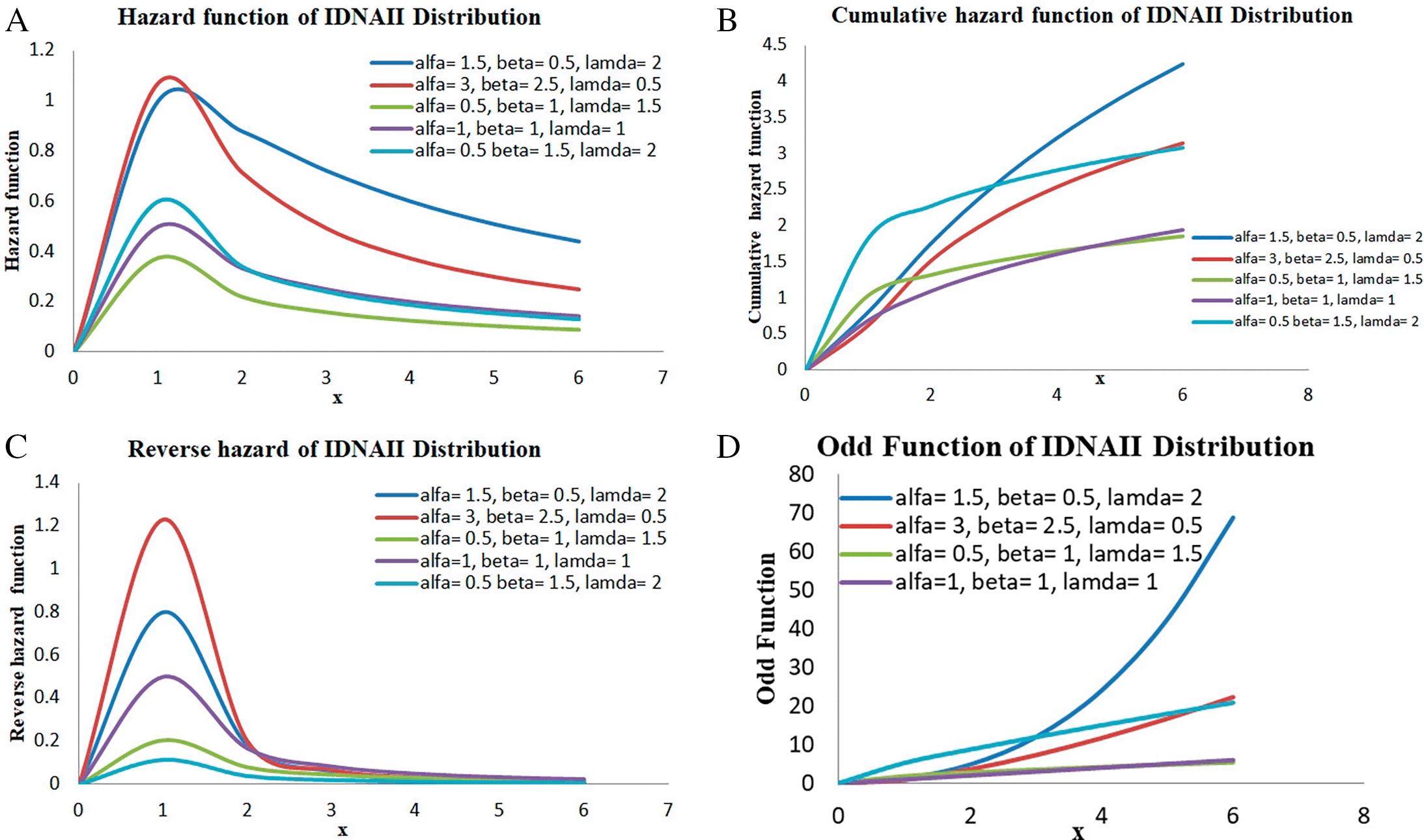
The graph in Figure 2(A) displays the hazard function for the IDNAII distribution for a range of parameter values.
Figure 2(B) shows the graph of cumulative hazard function of the IDNAII distribution.
The graph in Figure 2(C) illustrates the graph for the reverse hazard function with influenced by parameters α, β, and λ.
Figure 2(D) displays the graph for odd function with certain parameter values.
The empirical cdf and estimated cdf of IDNAII and the other specific distributions as well as the histogram of K-S and P-value are respectively presented in Figures 3 and 4. It shows how well a model fits by comparing the empirical cumulative distribution function (CDF) of a dataset with many fitted CDFs from theoretical models and the p-values and Kolmogorov-Smirnov (K-S) statistics for five fitted distributions side by side.
The suggested real parameters are shown in Table 1, and the Bias computations for the proposed estimators are detailed in Tables 2 to 5. The Mean Squared Error calculations for the proposed estimators are presented in Tables 6 to 9. Tables 10 and 11 present the dataset and its corresponding descriptive statistics, respectively. Table 12 presents the information criterion and estimation parameters for each fitted distribution.
This section discusses the findings from the study in the following manner.
Since the proposed distribution is so adaptable, it can be used as a model for a wide range of data types, particularly containing skewed, kurtosis, or otherwise non-symmetrical data. It is more beneficial for studies of inequality and reliability because of its structural flexibility, which enables it to represent a variety of real world behaviors. Additionally, the distribution provides a coherent framework for statistical modeling by generalizing many well-known classical models and including them as particular cases.
This work introduces an innovative probability distribution that enhances statistical modeling, demonstrating adaptability and a solid mathematical foundation. It captures important statistical properties like skewness, kurtosis, and multimodality. The model’s validity is backed up by a rigorous derivation of its probability functions and a full graphical analysis, which shows that it can accurately represent a wide range of real-world data formats.
Figure 1(A) shows that the graph of the probability density functions for the IDNAII distribution with certain parameter values. The density of the IDNAI distribution might be symmetric, adjacent symmetric, right-skewed, or bimodal.
Figure 1(B) shows the cumulative distribution function graph for the IDNAII distribution with certain parameter values. This graph shows that the cumulative distribution function of the IDNAII distribution is a function that does not decrease.
The graph in Figure 1(C) shows the Reliability function for the IDNAII distribution with certain parameter values. This graph shows that the reliability function of IDNAII distribution is a non-increasing function, which is what most people already know.
The graph Figure 2(A) displays the hazard function for the IDNAII distribution for a range of parameter values. The graphs display varying failure rate patterns, with sharper increases for larger λ values, such as the curve for α= 0.5, β= 1.5, and λ= 2. It is an excellent option for flexible reliability modeling because of this behavior, which demonstrates that the model is flexible to changes in parameters and may capture growing risk over time.
Figure 2(B) shows the graph of cumulative hazard function of the IDNAII distribution. This graph shows how it may be used in survival analysis and reliability theory by showing the overall failure risk up to time x. It demonstrates that when x increases, the cumulative danger escalates, conforming to standard survival model expectations. When λ is larger, the cumulative hazard is higher, which means the failure rates are higher. When α and β are removed, the curves are flatter, which means the risk increase is lower. The graphic shows how the properties of the IDNAII distribution change based on different dependability scenarios.
The graph in Figure 2(C) illustrates the variations in the reverse hazard function with increasing x, influenced by parameters α, β, and λ. A higher λ value (cyan curve, λ = 2) results in a steeper curve, indicating a higher likelihood of late failures and more pronounced tail behavior. In contrast, curves with lower λ values (red and blue curves, λ = 0.5) exhibit slower growth, reflecting lighter tails and more concentrated failure times. This function is crucial for reliability modeling, as it depicts distribution behavior in later life stages and highlights the sensitivity of reverse hazard to parameter changes, demonstrating the flexibility and controllability of the IDNAII model towards its conclusion.
Figure 2(D) illustrates that the odd function displays rapid growth with increasing x, especially with larger values of α.β and λ. Specifically, functions with λ = 1 show a significantly faster expansion rate compared to those with λ = 0.5, indicating a stronger influence on the upper range of x and pronounced tail behavior. This function is valuable for comparing configurations and understanding the impact of each parameter on the distribution’s shape, serving as an effective tool for evaluating the model’s adaptability and sensitivity to parameter variations.
Figures 3 shows how well a models fits by comparing the empirical cumulative distribution function (CDF) of a dataset with many fitted CDFs from theoretical models.
Figure 4 shows the p-values and Kolmogorov-Smirnov (K-S) statistics for five fitted distributions side by side.
4-3-1 Bias and Mean Squared Error (MSE) tables
Utilize summary statistics, specifically Tables 2-9 of Bias and Mean Squared Error (MSE) of proposed estimators for the parameters. It is particularly beneficial for assisting in the selection of an appropriate estimator in simulation tables to analyze the results.
Based on the mentioned Tables, bias and mean squared error (MSE), were ascertain:
1. Bias:
Distinctly demonstrated the patterns seen across the four scenarios according to Tables 2-5:
The SH method consistently demonstrated the lowest bias, regardless of sample size. MOM and MLE demonstrated differing levels of bias performance. The LS demonstrated amplified bias especially due to the estimation of λ.
2. Mean Squared Error (MSE):
Employing all methods over all four scenarios, SH had the lowest mean squared error overall across all parameter settings, according to Tables 6-9 of the estimators of parameters. MLE and MOM came next, but they weren’t consistent across cases. LS aren’t very effective, especially in the estimation of λ and in rare cases of β.
4-3-2 Data set tables
The data set and its descriptive statistics are shown respectively in Tables 10 and 11. The dataset illustrates the period of time between failures for a repairable item obtained from Refs. 16 and 22.
4-3-3 Parameter estimation and information criterion table
Table 12 indicates that the IDNAII exhibits lower values for -2Logl, AIC, BIC, AICC, HQIC, CAIC, and K-S distance compared to the other distributions, along with accurate P-values correspondingly. This suggests that the IDNAII may be selected as the most effective model for the proposed real dataset.
| 1.43 | 0.11 | 0.71 | 0.77 | 2.63 | 1.49 | 3.46 | 2.46 | 0.59 | 0.74 |
| 1.23 | 0.94 | 4.36 | 0.40 | 1.74 | 4.73 | 2.23 | 0.45 | 0.70 | 1.06 |
| 1.46 | 0.30 | 1.82 | 2.37 | 0.63 | 1.23 | 1.24 | 1.97 | 1.86 | 1.17 |
| Min | Max | Mean | Median | Mode | Std. Dev. | Skewness | Kurtosis | Sample size |
|---|---|---|---|---|---|---|---|---|
| 0.11 | 4.73 | 1.5427 | 1.2350 | 1.2300 | 1.1277 | 1.2955 | 4.3192 | 30 |
The Transformed-Transformer (T-X) Family method, grounded on the quantile function, serves as a robust mathematical framework for constructing tailored probability distributions. This method integrates the quantile function of a generating distribution with the cumulative distribution function (CDF) of a base distribution, so providing direct control over essential distributional attributes such as skewness, kurtosis, tail behavior (left or right), tail heaviness (heavy or light), and bimodality. Its versatility has been demonstrated across various domains, including environmental sciences, medical statistics, financial modeling, and reliability analysis, making it a valuable tool in modern applied statistics. The suggested family demonstrates various statistical and mathematical characteristics, covering probability density functions, moments, reliability functions, cumulative hazard functions, entropy measures, order statistics, and more aspects. The IDNAII distribution is a specific member of this family of distributions. We utilized various methods to estimate parameters for IDNAII, subsequently employing Monte Carlo simulation to assess their efficacy. The findings demonstrated that the shrinkage technique outperformed the other methods when evaluated from a bias viewpoint and regarding mean squared error. The proposed distribution was applied to empirical data, and a comparison shown that it exceeded existing models according to goodness-of-fit measurements, including the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC), and others.
The authors independently generated all scientific components of this research, including mathematical and statistical derivations, statistical analyses, and findings, without the assistance of AI technologies. The Microsoft Copilot (October 2025 edition) was utilized solely to enhance linguistic clarity, formatting, and structural organization in accordance with open scientific and academic publishing norms.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)