Keywords
Assistive Robotics, Computational Intelligence (Neural, Fuzzy, Learning, etc), Robot Vision and Monitoring, Vision-based Control, Human-Robot Interaction
This article is included in the Japan Institutional Gateway gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Dignity in Aging collection.
Assistive Robotics, Computational Intelligence (Neural, Fuzzy, Learning, etc), Robot Vision and Monitoring, Vision-based Control, Human-Robot Interaction
This study proposes an IoT control system that automatically identifies the position of clothing boundaries and calculates the actual spatial height distance information using a stereo camera. It is used in toilet environments where the elderly or patients have hand muscle weakness or difficulty moving their hands without the assistance of a nurse or caregiver. Pant dressing assistance system with autonomous recognition and adjustment of assisted position using a vision recognition system. The traditional boundary line recognition method has the problem of difficult recognition in complex scenes and different clothing. Moreover, in the traditional method of recognizing the actual spatial location distance, sensors in addition to the camera are required for composite computational analysis. To address this problem. Responding to different recognition scenes and recognizing multiple types of clothes. We adopted deep learning and machine learning methods for clothing boundary recognition. We utilized semantic segmentation-related algorithms for clothes boundary line identification as preliminary data processing. Eventually, the actual spatial position information of the clothing boundary line can be calculated from the multiple fusion information obtained from the stereo camera, and the position information can be fed back to the control system.
Recently, depth cameras have been used in robotics, autonomous driving, and other fields. For example, object size is measured using a single camera.4 The stereo camera object size measurement algorithm uses the Euclidean algorithm.5 Furthermore, a single camera was used to acquire the video to calculate the length, width, and height of the object using a mathematical model.3 Vision applications for robot dressing assistance.9,10 Point cloud information or fused data with other sensing information11 is used to obtain location information for dressing assistance. Using depth map information for top-dressing assistance.13 This study proposed a robot-assisted dressing system. Based on stereo camera depth sensing and a deep learning algorithm, the size and position of the auxiliary position two-point measurements of the actual spatial coordinates were calculated. Utilizing IoT communication to an auxiliary device for clothing auxiliary position selection and auxiliary robot movement control. Dressing assistance through multiple fusion technologies.
Figure 1 shows the 3D simulation image, and Figure 2 shows the actual toilet clothing dressing support robot. The toilet clothing dressing support robot is a branch of life support robot. It is a robot that solves the aging problem and provides assistance in living for the elderly. For example, in the toilet, hand muscle weakness, or hand immobility, Dressing Assistance will provide great convenience. There are five main areas of life support robots: mobility, food, toilets, bathing, and caregiving support. Life Support Robot has five main areas: mobility, food, toilet, bathing, and caregiving support. These five types of support are not only geared toward the elderly and patients, but can also reduce the workload of medical workers.


In recent years, deep learning models for the recognition and extraction of object edge contours(e.g., HED17 and RankED18) have made significant progress. However, the identification and extraction of boundaries in specific areas has many challenges. For example, CASENet15 and RINDNet16 are semantic segmentation edge boundary recognitions of objects. However, semantic segmentation edge boundary recognition has difficulties such as difficult training, low accuracy and inability to be applied with a designated part of the edge boundary recognition. In this study, we propose a multi-stage approach with good accuracy that is applicable to complex scenarios and capable of identifying recognition solutions for specific boundaries in specific regions. Semantic segmentation and SVM models are used in machine learning for specific boundary recognition. There are also many challenges in selecting a semantic segmentation model, for example, because the image recognition in this task is real-time image data and requires stability and high accuracy. In popular models, we present evaluations. The final selection was the PSPnet model with high semantic segmentation accuracy; however, the model with high semantic segmentation accuracy does not have good real-time processing capability. If a model with high a real-time recognition capability is chosen, the recognition accuracy of the model is reduced. To ensure recognition accuracy, we did not choose a model with a high real-time recognition. Subsequently, the SVM algorithm was used for boundary computation using semantic segmentation results. This greatly increases the cost of computational time; therefore, before calculating using the SVM algorithm, we used the data dimensionality reduction process to improve the calculation speed. Improved real-time recognition performance.
Second, it is related to distance sensors. In this study, we did not use traditional ultrasonic ranging or laser ranging sensors. Instead, a depth camera combined with an image algorithm was used to obtain the actual distance. This can be combined with semantic segmentation and SVM to obtain specific boundaries to compute the actual distance in space between pixel points in an image. This makes it easier to perform fused data processing than to use data information from traditional ranging sensors. A depth camera cannot directly acquire the actual spatial distance between the two points of an image pixel. In previous studies, the real spatial distances between image pixel points were rarely considered. Therefore, we propose a simple design scheme for ranging between pixel points based on the principle of depth measurement using a depth camera. In the design of the measurement calculation method, the obtained image information and the actual required information results are not in the same calculation coordinate system. Consequently, transformations between multiple planar coordinate systems are used in the design. For example, a depth map can be obtained using a binocular camera and then converted into a 3d point cloud map. This study aimed to develop a highly self-regulated recognition control system for intermediate care dressing support in a washroom scene. In the next section, we describe the proposed solution.
In our previous study we used three models Fcns8, SegNet, and DeconvNet for semantic segmentation of clothes boundary recognition.1 In this study, we used the PspNet model for semantic segmentation of clothes. In a prior study, there were four categories: jacket, pants, hands, and background. We added a 5th category of shoes. Figure 4 shows a flow chart of the image processing in the third part of Figure 3. Figure 5 shows the recognition categories in the semantic segmentation part of this study. This approach is a multi-stage training and processing method. The clothing boundary identification and control system must be based on a real-time situation for identification and control. In terms of model selection, PspNet has a good correct rate of semantic segmentation among many models. However, PspNet does not exhibit a high real-time recognition rate in real time semantic segmentation models. However, in this task, more focus was placed on the recognition rate of semantic segmentation such as clothes. Therefore, PspNet was selected as the model for this task. Figure 6. shows a comparison of the speed and recognition rate of the models for real-time semantic segmentation in our used model.14
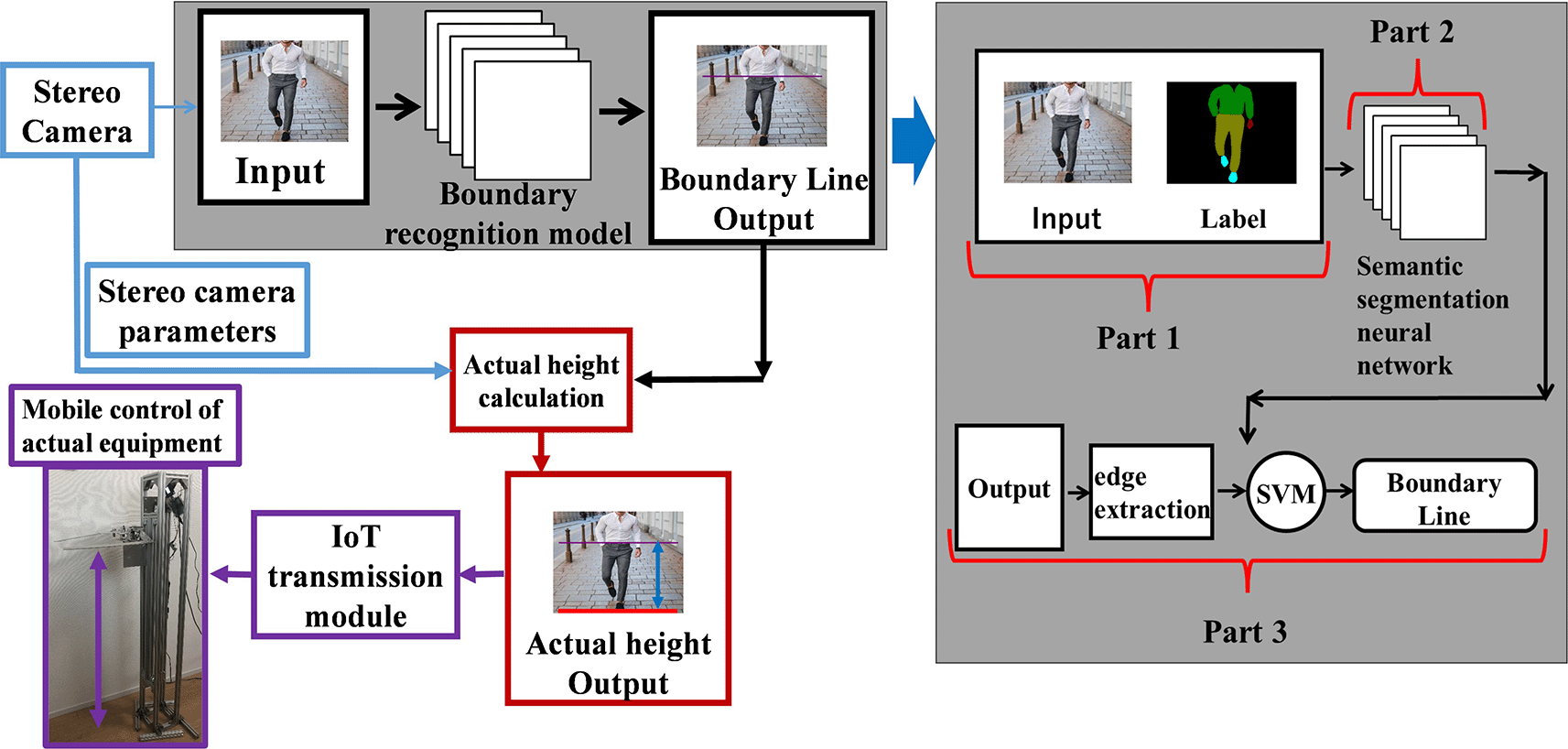
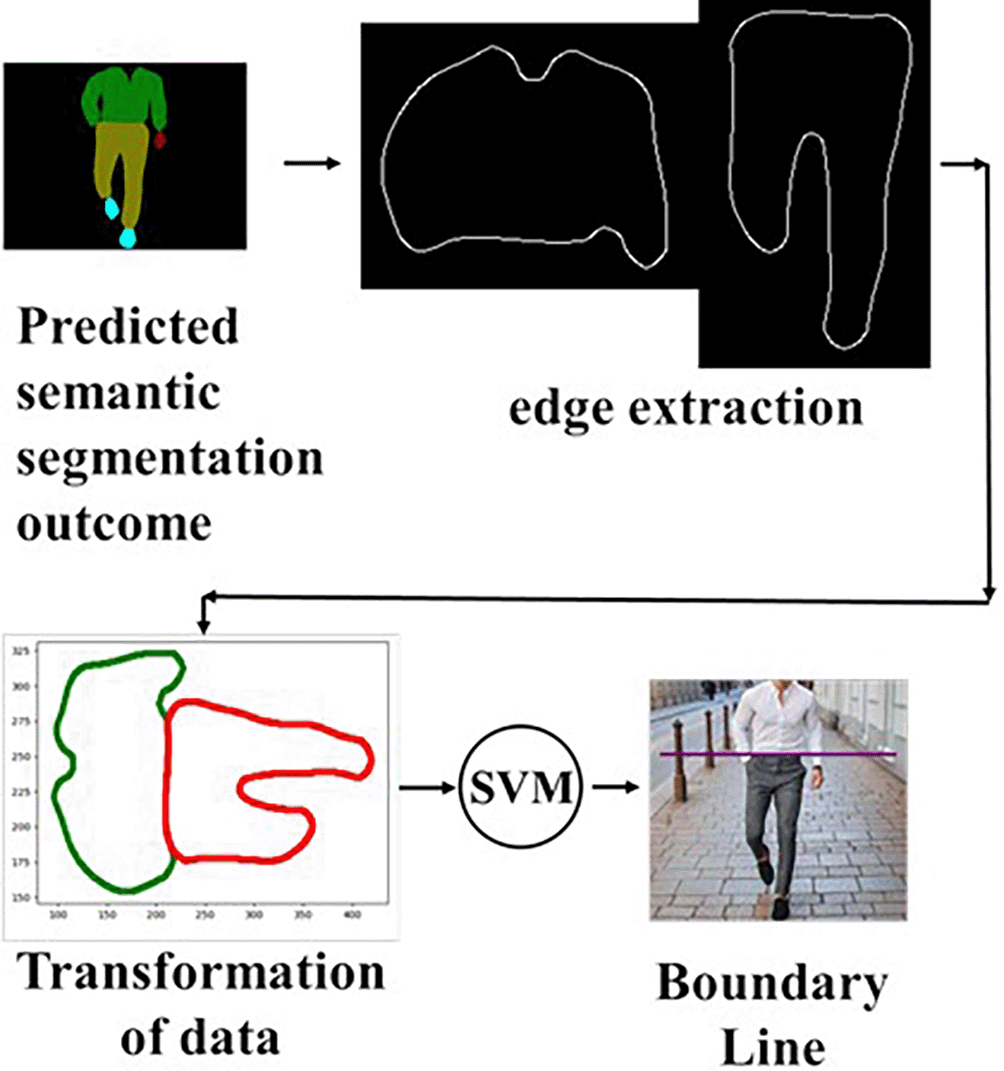

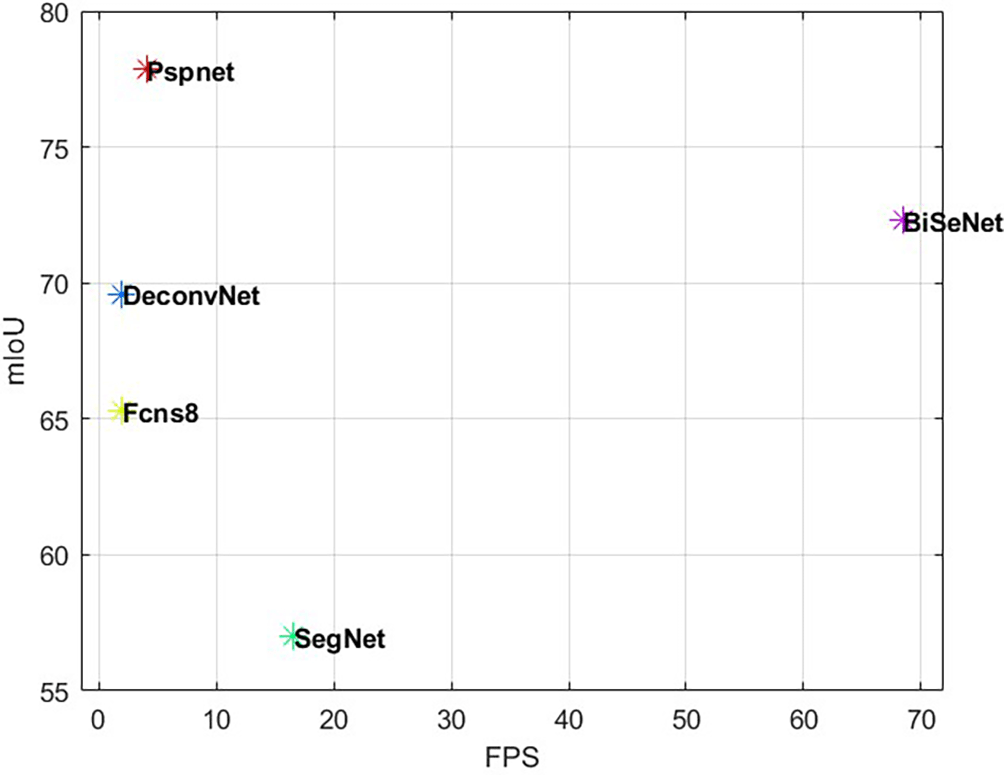
Figure 3 show a flowchart of the stereo camera-based clothing recognition control system. The gray area on the right side of Figure 3 shows the detailed processing flow of clothing and boundary recognition for the boundary recognition model. The boundary recognition model in the gray part of Figure 3 is a clothing boundary recognition method that uses semantic segmentation for deep learning and machine learning SVM.1 We used a 2-stage processing for clothes boundary recognition. First, the semantic segmentation of clothes is recognized using a deep model. Subsequently, using the semantic segmentation results, binary classification of the jacket and pant semantic segmentation results was performed. The clothing boundary recognition model in Figure 3 is divided into three parts (the gray part on the right side of Figure 3).
The first part is the input layer, which is used as the input for the non-trained dataset and data labeling. The training set did not have any special preprocessing and was in the same form as the semantic segmentation data.
The second part was the semantic segmentation model network, in which this case we used the PspNet model.6 The model is used to extract image features and categorize each pixel in the final output layer. Finally, we used the softmax output function as the output layer. The final result is the classification probability of each pixel in the W*H.
The third part extracts the feature information of jackets and pants based on the results of semantic segmentation. Then, the traditional Canny edge detection algorithm was used to obtain the edge line features of the jackets and pants. The edge line features extraction process can reduce the dimensionality of the data. On the other hand, edge contour boundary extraction can also reduce data noise and reduce training data. In the prediction of semantic segmentation, the prediction position error was latent. This increases the cost of training time and affects the accuracy of SVM algorithm classification training. Therefore, using the Canny algorithm to extract edge boundaries is beneficial for training accuracy and improving training speed. Furthermore, using the Canny algorithm did not change the features of the original data. Because the image results of semantic segmentation is multidimensional data W*H*3, semantic segmentation results through the Canny filter, and feature extraction can be performed to obtain one-dimensional data W*H of contour features and reduce the amount of data. Without contour feature extraction, the semantic segmentation results are directly used as one-dimensional binary classification data for the SVM computation. Owing to the large amount of data, this results in low computational efficiency. To improve the computational speed, we considered the processing of the Canny filter on the image result of semantic segmentation as a process of data dimensionality reduction.
Finally, the SVM algorithm was used for boundary identification between jackets and pants. However, the edge boundary data for jackets and pants can be transformed into two different clustered datasets, as shown in Figure 4. Because they have unique data attributes, there is not much intersection; however, the data are close. Therefore, the SVM binary classification algorithm is applicable. The SVM algorithm is categorized into linear and nonlinear classification. We choose linear classification method. SVM algorithm is a common classification algorithm that generates linear classification planes from binary or one-to-many results.
Equation 2 is a deformed derivation of Equation 1 for obtaining the value of the SVM hyperplane . The value of is determined based on the predicted image W pixel width.
The coordinates of the hyperplane boundary can be obtained using Equations 1 and 2 as follows: The SVM hyperplane boundary can be reconstructed to identify the specific clothing boundary. Figure 4 shows the semantic segmentation results obtained using semantic segmentation and the contours of the semantic segmentation results obtained using the Canny algorithm. For example, the green jacket contour and red pant contour in Figure 4 were used as the clustering data for the two categories. From the data transformations in Figure 4, we can see that there is a clear boundary between the green contour data and the red data, and that it has the characteristic of linear categorization under all conditions. Hence utilizing SVM for classification produces a linear classification hyperplane between the green and red data.
Figure 7.1 shows the principle of single-pixel point depth computation using stereo cameras L:left camera and R:right camera. is the disparity. f: focal length and T: center distance between the two cameras also called the base line. T and f are fixed values and disparity values are unknown variables. To obtain the disparity value, we must use Equation 3 to calculate the distance value Z between the object and camera.2 Finally, a depth map was obtained. in Equation 3 is the disparity value. Calculating the disparity value between two images is obtained by calculating using stereo matching algorithm. The left camera image and the right camera image are used as inputs to obtain the disparity values by stereo matching algorithm. For example, SAD (Sum of absolute differences) image matching algorithm, SGBM global matching algorithm and other methods. disparity value . In order to find the distance between two specific pixels. Thus, it is necessary to obtain the specific values of xl and xr for the selected pixel points. The method of calculating xl and xr for selected pixel points is based on obtaining a depth map. In the later part we further describe how to compute to obtain xl and xr.
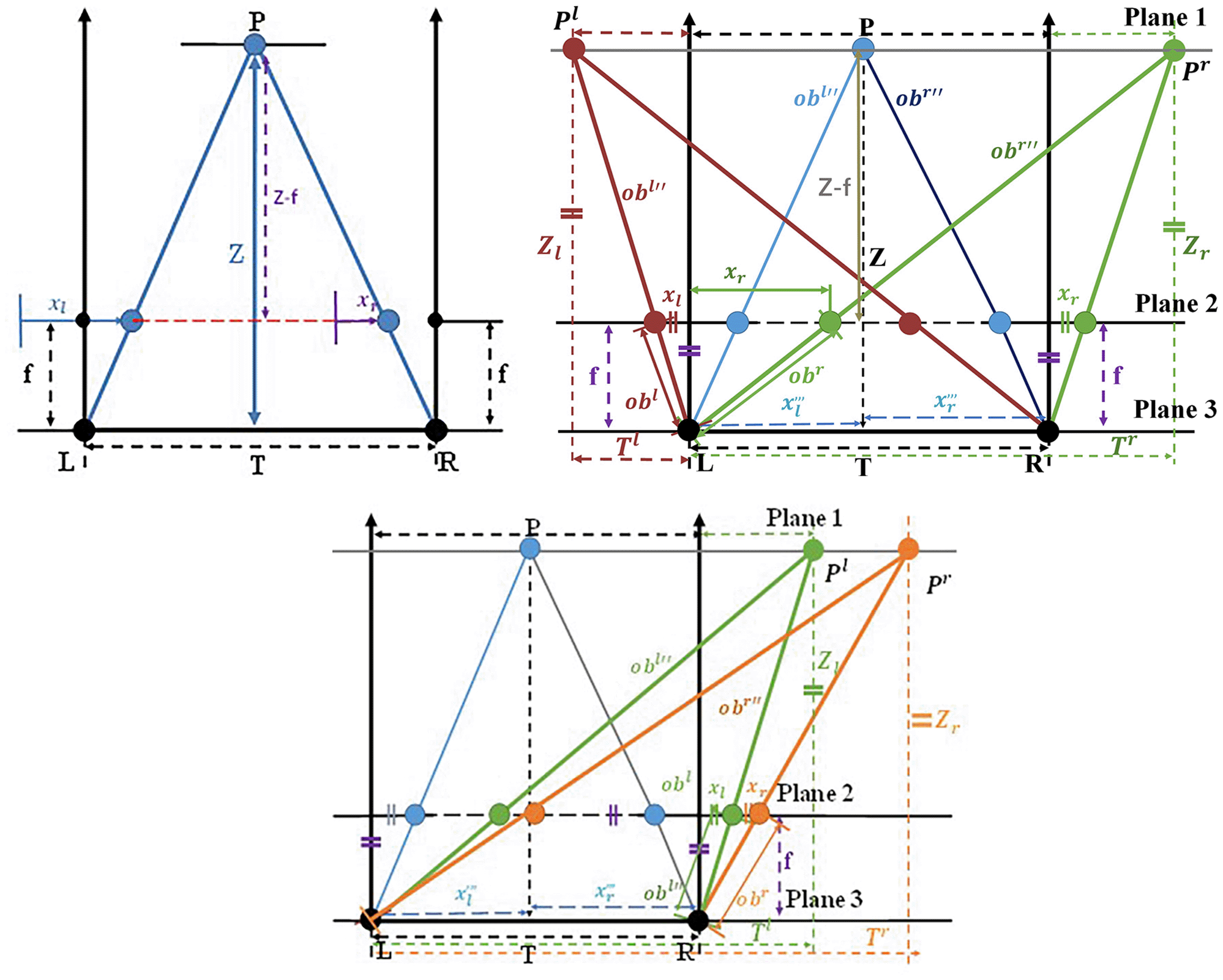
Figure 7.2 shows the principle diagram for calculating the actual distance between two measurement points using stereo camera zed2. Table 1 shows the calculation of the actual length of a single pixel in the real space. Our proposed method for measuring the distance between two points is an extension method based on stereo camera depth 3measurement. Figure 7.2 shows our proposed method to calculate the distance between two points based on the original single-point depth calculation.
In Figure 7.3 and Figure 8, the parameters of the camera are f: focal length. R: rotation matrix. T: translation matrix. : Physical x-axis size of a single pixel of the light sensor in the camera. : Physical y-axis size of a single pixel of the light sensor in the camera. : number of X-axis pixels that are the difference between the center pixel coordinate and the origin pixel coordinate of the image. : the number of Y-axis pixels that represent the difference between the center pixel coordinate and origin pixel coordinate of the image. : intrinsic parameter value of the origin point. The intrinsic parameters of the camera were obtained using the camera calibration method.
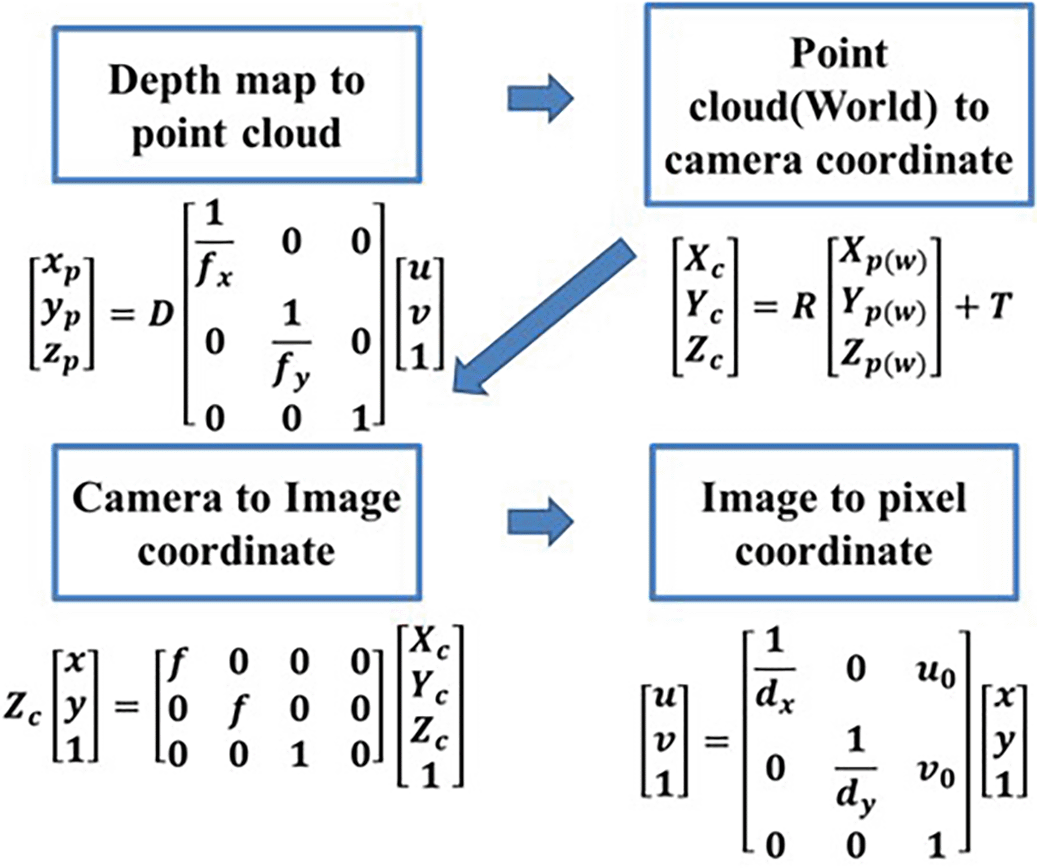
For example, we measure to calculated the distance between and in Figure 7.2. First, we used the Depth Perception API of the stereo camera zed2 SDK to calculate the depth map to obtain the depth distances and for two points and . Then, the stereo camera zed2 SDK API was used to calculate the depth map for conversion to a 3d point cloud. Sets the 3d point cloud coordinates to the actual world coordinates. Using the formula shown in Figure 8 the 3d point cloud coordinates were finally converted to pixel coordinates. When calculating the distance between two points and , we did not use the left and right camera parameters to calculate the measurements. We use the left (point L) camera in Figure 7.2 for the mapping and calculation of the pixel coordinates of the two points and . First, we obtained the depths and of and . Using the 3d point cloud coordinate system was used for conversion to a pixel coordinate system. Later, the pixel coordinate system is utilized with u: x-axis pixel coordinate values and v: y-axis pixel coordinate values. The of Equation 4 is the measurement point x-coordinate converted to a pixel coordinate value ( Figure 8 Pixel coordinate u value). It is possible to obtain the values of dark red and green for points and by using Equation 4. Equation 5 was used to obtain and . Equation 6 was used to obtain and values. Equation 7 is then used to obtain the value of at point and the value of at point .
In Figure 7.2 plane1 is the object reality plane, plane2 is the image pixel plane, and plane3 is the camera lens plane. Figure 7.2 shows the pixel coordinate x-values of and in the negative and positive fields. : x-coordinate values in the pixel coordinate system and : x-coordinate values in the pixel coordinate system. In the ideal model, the point is to the left of the left camera center line and the point is to the right of the right camera center line. Using Eqs. Equations 4, 5, 6, and 7 it is possible to obtain and using Eqs. Equations 8.1, 8.2, and 8.3. If two points are distributed in the positive and negative value domains use Equation 8.1 to calculate the distance L between the points and . Figure 7.3 shows the pixel coordinate x values of both and in the positive domain. If both points and are distributed in the positive domain use Equation 8.2 to calculate the distance L between points and . If the two points of and are completely in the negative domain and the value domain of Figure 7.3 is taken to be opposite, the distance L between the two points of and is calculated using Equation 8.3 when, the two points are distributed in the negative domain.
Equation 9 calculates the actual length of a single pixel between two points and . and are the x-coordinate values of and in the depth map. When we choose the coordinates of the two points and , we choose the same y-coordinate value. Therefore, only the x-coordinate variable was used in Equation 9 to calculate the actual distance of a single pixel.
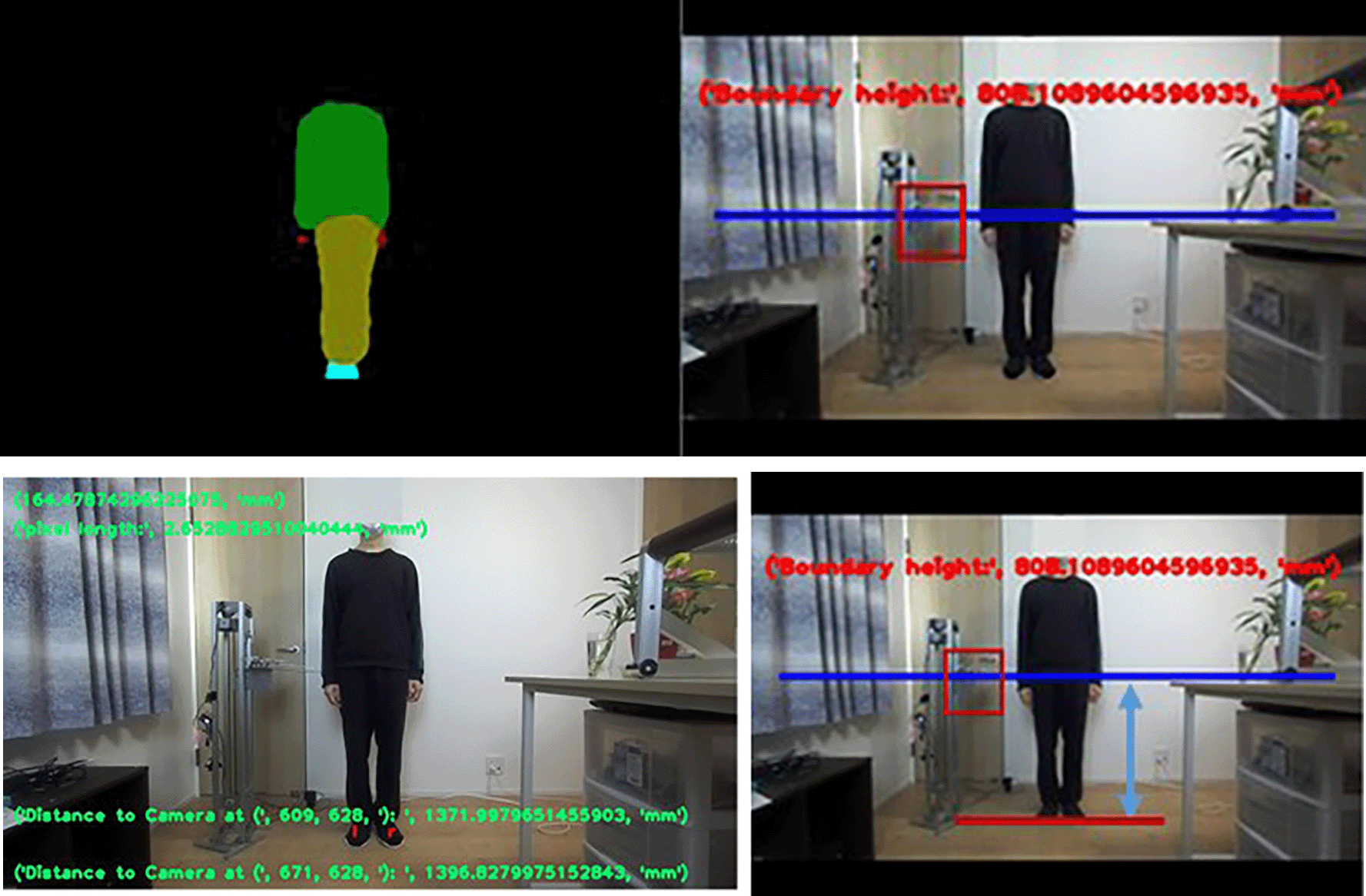
Figure 9(upper) on the left show the actual semantic segmentation recognized image. Figure 9(upper) on the right shows a the clothing boundary recognition image. Figure 9(lower left) shows the predicted shoe semantic segmentation result, after which the selected measurement points were red :l and :r. Two calculation points are selected in the shoe category, after which the size of a single pixel in the actual space was calculated. As shown in Figure 9(lower right), the actual spatial distance was obtained using the sum of the pixel points calculated between the clothing boundary and shoes. Finally, the data were transmitted to the control system to move to the auxiliary position using the IoT method.
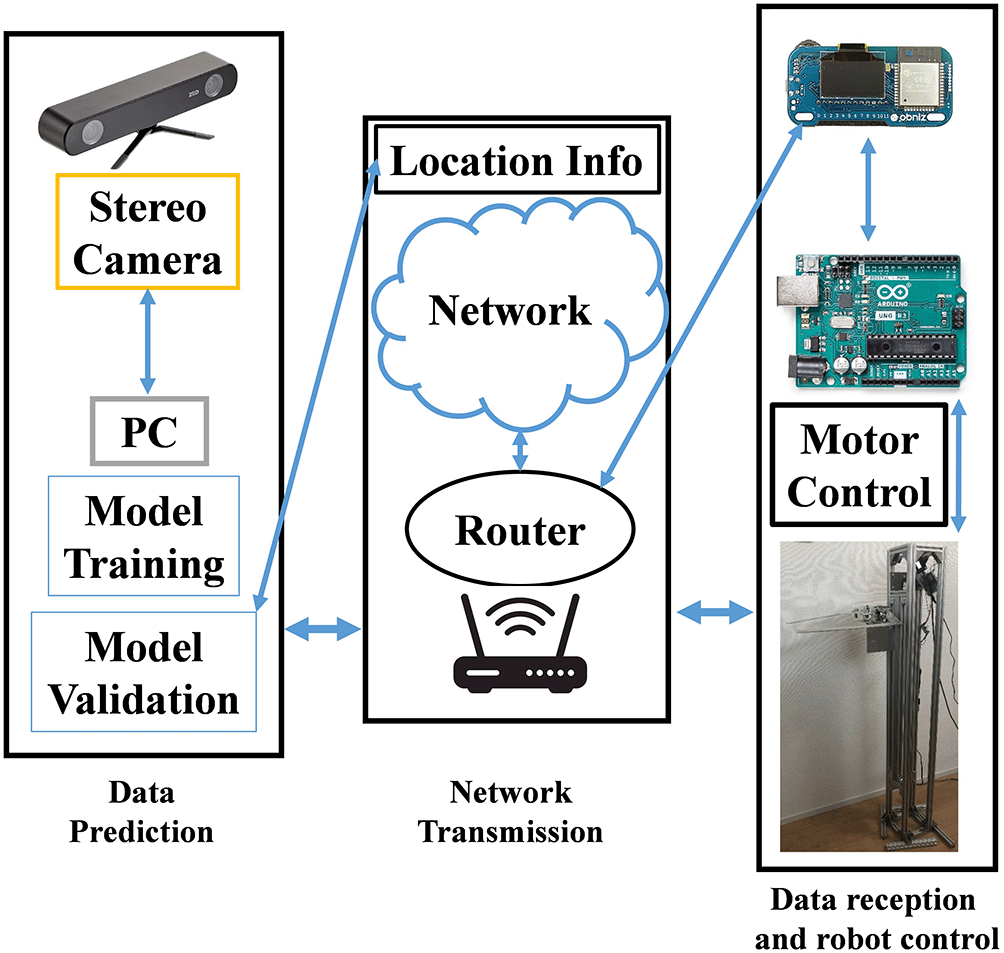
In recent years, the fusion of IoT technology and robotics for the Internet of Robots (IoRT) has been developed.7,8 In this study, a combined IoT and robotics approach is used for a clothing boundary recognition control system. Figure 10 shows the flowchart of IoT communication for the clothing boundary identification control system in Figure 3. The clothing boundary identification control IoT communication system is divided into three main layers: physical, network, and service application. Figure 10 Left: data prediction physical layer; middle: data transmission network layer; right: robot service application layer. Stereo cameras were used to acquire images and models to compute the predictions. The predicted control commands are then transmitted to the cloud in the network layer. Finally, control commands are received at the robot service application layer to realize the auxiliary position movement control of the support robot. Figure 11 shows the IoT data communication and control system hardware for dress-supporting robots in the robot service application layer. Obniz 1Y was used for the data communication. and Arduino for the control data processing. Finally, an L6470 control board was used to drive the lifting device of the support robot.

In the actual experiments, we fixed the relative position for stereo camera recognition to 79 cm high and the measurement distance to 130 cm. Because of the assistance of the system, the acquired recognition image must be a full-body image. However, it is not necessary to acquire and recognize dynamic images. Therefore, we fixed the relative position of the camera during our experiments. It is guaranteed that the entire body image information is obtained each time. The fixed height and measuring distance for the camera settings can also be adjusted to change if the acquisition of full-body image information can be guaranteed. In our experiments, we evaluate actual clothing boundary recognition and machine-assisted position control under different conditions. Examples include different lighting conditions, same-color or non-same-color pajamas, and standing or incomplete poses.
Table 2 presents the evaluation results of the clothes boundary recognition and control experiments. The composite average correct recognition rate for clothing boundary recognition in different lighting environments with different jacket and pant color schemes was 77.35%. As shown in Table 2, we used nine different conditions for clothes the boundary recognition and control experiments. The clothes boundary recognition and control system can be affected by multiple factors. Therefore, we used the average of nine different conditions tor evaluate the accuracy of the combined environment. The control experiment is to used a stereo camera to recognize the auxiliary clothing boundary and computation to obtain the actual spatial height position information, and then used the IoT control system for robot control. The control accuracy of the stereo camera recognition control system in the control experiment was 97.21%.
Table 2 of Experiments 1 and 2 shows the evaluation of recognition control experiments for same-color and non-same-color clothing in a nighttime environment. It can be seen that the experiment in the night environment hads good recognition and control accuracy. Moreover, we verified the recognition effect in the case of incomplete standing (as shown in Figure 12). In Figure 12, the pink recognition line of image is the recognition result at time, and the blue recognition line is the result of real time recognition. Because the recognition poses at time and are basically the same, only a small recognition difference, for example, in Figure 12, the time position information is 577.41mm and the time updated position information is 574.87 mm, the recognition control position difference is 2.54 mm.

In Figure 12, the recognition image at time has a large deviation for the actual distance position calculation of the recognition line. We used calculation results below or above the robot's movement range, in which case the last position information is retained, and the movement control processing is not updated. Setting up a constraint mechanism ensures user safety. It has been verified that the cause of the positional distance error is that the foot semantic segmentation recognizes that the difference between the coordinates of the two points is too small, causing an error in the calculation. To avoid errors in the prediction and measurement, calculations of the semantic segmentation result in incorrect control of the robot. We have included mechanism of security range control to ensure user the safety. For example, no control is performed when the semantic segmentation of clothes is incompletely recognized or when boundaries are incompletely recognized. In addition, if the control command is not within the safe movable range. Thus, the system does not process the control. The reason for the recognition errors is incomplete recognition of the semantic segmentation of clothes or incomplete recognition of boundaries. If the feature diversity of the training set is increased. This can be improved to reduce the error rate and enhance the safety of the system.
Incomplete recognition is caused by missing semantic segmentation categories. For example, the jacket category was not recognized and the other categories were correctly identified. The jacket and pant categories were recognized, but the shoes were not. We defined these cases as incomplete recognition. Incomplete recognition can lead to incorrect predictions of the actual spatial coordinates. This can ultimately lead to exceeding the control range of the robot.
In Table 2, the jackets and trousers are homochromatic and non-homochromatic denotation symbols. ◯: clothes homochromatic, ×: clothes non-homochromatic, ∆: clothes non-homochromatic and homochromatic both. In Table 2, Experiments from 3 to 8 are the experiments performed in the daytime. In Experiment 3, the red boxed area in Figure 13(3) is the case of a large over exposed area and an unlit room; in this case, it is not possible to recognize the correct semantic segmentation clothing boundaries. Experiments 4 and 5 aim to reduce the overexposed area, as shown in Figure 13(4). The overexposed area is defined as the medium area, and 13(1) is the overexposed area defined as a small area. By changing the overexposure area, the recognition rate of the semantic segmentation of clothing boundaries was significantly improved in Experiments 3 and 4. Experiments 6, 7, and 8 were conducted with large-area overexposure and medium-area overexposure under weaker outdoor light than Experiments 3, 4, and 5. Experiments 3 and 6 compared the results, and it can be observed that there is a significant improvement in the recognition rate of clothing boundaries in a room with a light source. Experiments 7 and 8 showed higher recognition accuracy for non-homochromatic clothes than for homochromatic clothes in the non-homochromatic conditions for jackets and trousers. Experiments 4 and 8 show that overexposure to brightness reduces recognition accuracy.

In the experiment, semantic segmentation, clothing boundary prediction results, spatial distance information, and the control parameters were all without target parameters. Therefore, a manual evaluation method was used. A binary classification evaluation method. Equation 1012 is our adopted accuracy rate evaluation Equation; Equation 11 shows the precision rate12; Equation 12 is the recall rate12; We performed a binary evaluation for clothing boundary identification prediction, spatial distance calculation, and control. In the evaluation, incorrectly calculated position information that does not perform an incorrect update of the control signal is not recorded as an incorrect identification or control.
The experimental images evaluated were non-fixed test datasets, and real-time captured images were used as the evaluation data. The size of the evaluation image was fixed to the image size 480×480 for Pspnet network training. The training dataset comprised of 567 images. Table 3 shows the experimental data for the positive and negative samples in the boundary identification evaluation and control system evaluation experiments and the total number of evaluation data for each experimental condition.
| Clothing boundary recognition | ||
|---|---|---|
| Actual Ture+ | Actual False- | |
| Predicated P+ | 192 | 65 |
| Predicated N- | 30 | 0 |
| 222/287= 0.7735 | ||
In clothing boundary recognition, the TP of Equation 10 was used to successfully recognize the predicted clothing boundary, and the predicted clothing boundary was correct. TN indicates that the clothing boundaries are not recognizable, but the clothing boundary results are unpredictable and considered correct. The FP successfully identified the predicted clothing boundary, but the prediction results were erroneous. In FN, the clothing boundaries are unrecognizable, but the clothing boundaries are recognised and the prediction results are incorrect.
In addition, in evaluating the control system movement, the TP of Equation 10: the robot obtains the movement parameters and movement control command, and the movement parameters are correct. TN: The robot is given the no-movement parameter and no-movement control command, and the actual parameter command is no-movement, which is evaluated as correct. FP was successfully recognized to predict clothing boundaries, but the prediction results were incorrect. In FN, the clothing boundaries are unrecognizable, but the clothing boundaries are recognized and the prediction results are incorrect.
In our experiments, we used Equation 13 and Equation 14 to evaluate the stereo camera measurement accuracy by calculating the relative the mean error and mean error values obtained. Equation 13 is used to calculate the relative mean error percentage, where Amv is the mean measured value, and tv is the true value. Equation 14 represents the average error value.
Table 4 shows the data on the average error of the measurement of the actual distance between two point pixels of the stereo camera evaluated in our experiments. Four cases were used to evaluate of the average measurement error. The first experimental evaluation case is when the pixel coordinate values and were in the positive and negative ranges (between 566 pixels at point x-coordinate and 675 pixels at point x-coordinate), the relative average error was -1.87% and the average error value was -5.55 mm. The second experimental evaluation case was when the pixel coordinate values and were in the positive range, the relative average error was 13.87% and the average error value was 41.22mm. In the third experimental case was when the pixel coordinate values and were both in the negative domain, the relative average error was 23.18%, and the average error value was 68.86mm. In the fourth experimental case, when the pixel coordinate values and are evaluated in the overall average of the above three cases, the relative average error is 16.73%, and the average error value is 49.70 mm.
In this paper, we present the design and development of a clothing-assisted support robot for elderly people's homes or toilet environments in the home. In cases where the elderly or patients in the toilet have difficulty standing autonomously, hands are used to support standing or muscle weakness in both hands, the assisted position is identified and adjusted autonomously through a recognition system without the assistance of a nurse or a caregiver, Assist to complete the action of dressing and undressing. For this purpose, we propose a machine vision control scheme for a clothes-wearing support robot that can be applied to toilet scenes. Using stereo camera depth information and image information, the IoT control system is based on deep learning and machine learning for clothing boundary recognition and calculation of spatial position information. In an experiment to verify the standing or incomplete standing situation of the assisted person, the recognition of clothing-specific boundaries and the actual spatial height position calculation can be performed to control the robot to move to the assisted position.
We implemented a multi-technology fusion of a clothing boundary recognition and control system. However, it is still not possible to fully implement a high autorecognition control. Moreover, because of the fusion of multiple technologies, the accuracy is reduced. Because of, the accuracy of the image recognition, the accuracy of the binocular camera measurement and the accuracy of the communication control system each lose accuracy; therefore, the accuracy is greatly reduced in the final recognition control feedback. This is also a topic for future study.
In addition, it recognizes high real-time problems. This is because the Pspnet model is not highly real-time and uses multi-stage processing. The processing of data dimensionality reduction was used in the SVM stage to improve the computational speed. However, this does not fully realize the high real-time performance of clothing boundary recognition. Moreover, communication in combination with IoT has some latency, increasing the problem of not being able to operate in real-time. This will be addressed in a future study. This problem can be further improved if an end-to-end modeling pattern is used, and the model design and adjustment are based on prior research on semantic segmentation models with real-time capability.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)