Keywords
Fraud Detection, Autoencoder, Isolation Forest, XGBoost, Random Forest, Hybrid Model, Anomaly Detection, Imbalanced Dataset.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Fraud Detection, Autoencoder, Isolation Forest, XGBoost, Random Forest, Hybrid Model, Anomaly Detection, Imbalanced Dataset.
Credit card fraud remains one of the most persistent and damaging threats to the digital financial ecosystem. As the volume of online transactions continues to grow, so too does the complexity of fraudulent activities increases. Global losses are projected to exceed $40 billion annually by 2025, driven by the increasing digitalization of financial services and constant evolution of fraud tactics.1 The core challenge in this domain lies in accurately detecting fraudulent transactions that are rare (less than 1%), adaptive, and often indistinguishable from legitimate user behavior. This imbalance (between legitimate and fraudulent transactions) significantly impairs the performance of both conventional and machine learning-based detection systems, often leading to biased predictions and poor generalizability across datasets.2,3 Traditional fraud detection methods struggle to scale effectively in such dynamic and imbalanced environments, frequently resulting in missed fraud cases or excessive false positives. Detection systems frequently encounter difficulties in balancing sensitivity and specificity; enhancing fraud detection (true positives) often leads to an increase in false positives, thereby disrupting the customer experience and straining resources. Conversely, conservative models may fail to identify fraudulent activities, leading to financial losses and reputational harm.
Recent research has highlighted the potential of hybrid models that combine supervised classification techniques with unsupervised anomaly detection to enhance both the precision and robustness of fraud detection. For instance, studies integrating techniques, such as autoencoders, isolation-based methods, and gradient boosting classifiers, have demonstrated improved performance in identifying complex and evolving fraud patterns.4 However, many of these models still lack generalizability or require substantial computational resources, which limits their practical application in real-time financial environments.
The aim of this study is to develop and evaluate a hybrid anomaly detection framework that integrates both supervised and unsupervised learning techniques to improve the accuracy, robustness, and generalizability of credit card fraud-detection systems. This study specifically targets the challenges posed by imbalanced data, evolving fraud patterns, and limitations of single-model detection strategies.
Our approach is empirically validated using the publicly available European credit card fraud dataset, which presents realistic challenges including severe class imbalance. We conducted comprehensive experiments to measure the performance of the model across standard evaluation metrics and benchmarked its results against state-of-the-art techniques. Using this approach, this study aims to demonstrate the practical value and academic contribution of hybrid learning models in improving credit card fraud detection.
This study makes the following contributions:
1. A novel hybrid anomaly detection framework that integrates supervised (XGBoost, Random Forest) and unsupervised (Autoencoder, Isolation Forest) models is proposed to address the challenges of data imbalance and concept drift in credit card fraud detection.
2. Comparative analysis of the hybrid model against state-of-the-art models using the publicly available and widely adopted Kaggle creditcard.csv dataset.
3. A reproducible pipeline suitable for adaptation in real-world applications that balances detection accuracy with computational efficiency.
Credit card fraud detection has become increasingly critical with the rapid expansion of online transactions and growing sophistication of fraudulent activities. Contemporary trends underscore the adoption of advanced machine learning (ML) techniques, which have shown considerable promise in enhancing both the accuracy and efficiency of fraud-detection systems. Nevertheless, these advancements have introduced several challenges, particularly the limitations of traditional anomaly detection methods and the constraints inherent in current ML-based models.
Traditional approaches to anomaly detection, including rule-based systems and statistical models, have long served as the foundation for fraud detection. However, these techniques frequently struggle to address the dynamic and adaptive nature of fraudulent behavior, which often mimics legitimate transaction patterns. Consequently, they tend to exhibit high false positive rates.5,6 Moreover, such approaches generally fail to scale effectively with the vast and continuously growing volume of transaction data, rendering them less viable in real-time fraud detection scenarios.7,8 Consequently, there has been an increasing shift toward machine learning models that are better equipped to manage large datasets and adapt to evolving fraud strategies.9,10
Despite their advantages, the existing ML models are not without limitations. A primary concern is the class imbalance inherent in credit card transaction datasets, where legitimate transactions overwhelmingly outnumber fraudulent transactions. This imbalance often leads to skewed model performance, resulting in a high rate of false negatives in which fraudulent transactions remain undetected.2,3 Additionally, many ML models demand extensive feature engineering and frequently struggle to generalize across datasets because of variations in consumer behavior and transaction patterns.11,12 The scarcity of accurately labelled fraudulent transactions further complicates the training process, as acquiring such labels is challenging in real-world settings.13
Hybrid approaches have emerged as promising solutions for mitigating these issues. By combining different methodologies, researchers have been able to enhance the detection accuracy and reduce false positives.14,15 For example, hybrid models that integrate convolutional neural networks with support vector machines have demonstrated improved performance in identifying anomalies in financial datasets.15 These methods exploit the strengths of diverse algorithms and contribute more robust and generalizable detection capabilities. Moreover, similar hybrid strategies have shown effectiveness in other domains facing anomaly detection challenges, including healthcare and cybersecurity.14
In the context of fraud detection research, several benchmark datasets are frequently used, notably the European Credit Card Transactions dataset and the Kaggle Credit Card Fraud Detection dataset. These datasets are distinguished by their high dimensionality and extreme class imbalance, with fraudulent instances often comprising less than 1% of the total records.2,3 In particular, the European dataset includes anonymized transaction features derived from Principal Component Analysis (PCA) to ensure user privacy, making it suitable for academic use.12,16 Such datasets are instrumental in training and evaluating fraud-detection models because they closely reflect the complexities encountered in real-world applications.
In summary, although traditional anomaly detection techniques have laid the foundational framework for credit card fraud detection, the adoption of machine learning and hybrid methodologies opens new possibilities for improving the detection efficacy. Nonetheless, persistent challenges necessitate ongoing research in this field. The advancement of more sophisticated hybrid models and the utilization of comprehensive real-world datasets will be essential to overcome these hurdles and further progress in this critical area.
In the domain of credit card fraud detection, unsupervised learning methods have garnered increasing attention owing to their capacity to identify anomalies without relying on labelled data. Among these, clustering algorithms such as DBSCAN and HDBSCAN have demonstrated considerable potential. For instance,1 reported that combining HDBSCAN with UMAP and SMOTE enables the identification of previously unseen fraud patterns, while significantly reducing false positives. Similarly, deep-learning-based anomaly detection frameworks, such as the attentional anomaly detection network proposed by,16 show promise for capturing behavioral transaction anomalies without the need for predefined class labels. These approaches are particularly advantageous in real-world contexts where labelled fraudulent data are limited, allowing the detection of novel fraud patterns that traditional supervised models may overlook.17
Conversely, supervised learning techniques, particularly gradient boosting methods, such as XGBoost, have been widely adopted owing to their robustness and interpretability.2 highlighted the effectiveness of XGBoost when paired with data augmentation strategies, such as SMOTE ENN, achieving high accuracy with low false-positive rates. Further evidence from18 demonstrated that integrating XGBoost with resampling methods enhanced the overall performance across a range of machine learning models. Notably, the inherent capability of XGBoost to handle imbalanced datasets makes it particularly well-suited for credit card fraud detection, where fraudulent transactions comprise only a small fraction of the total dataset.10
Hybrid approaches integrating supervised and unsupervised learning have emerged as promising strategies,14 for example, presented a deep learning model combined with SMOTE oversampling, which effectively addressed the class imbalance issue while improving the detection accuracy. Similarly,19 illustrated the benefits of combining neural networks with traditional machine learning techniques to enhance the overall detection efficacy. These hybrid models exploit the complementary strengths of each learning paradigm, thereby resulting in adaptive and accurate systems.
Despite these advancements, several persistent challenges continue to hinder optimal fraud detection performance. A primary issue is class imbalance, wherein the overwhelming dominance of legitimate transactions can bias models and reduce their sensitivity to fraudulent instances.11 Additionally, the constantly evolving tactics of fraudsters necessitate frequent model retraining and updates, which can be both computationally and operationally demanding.11 Scalability is also a concern, as many models exhibit performance degradation when deployed in large-scale or real-time transaction streams.20
The performance metrics across existing models vary significantly in terms of scalability, accuracy, and operational efficiency. Research indicates that ensemble techniques that combine multiple classifiers tend to outperform individual models in terms of their robustness and accuracy.21 However, the increased computational requirements of ensemble models may limit their applicability in time-sensitive scenarios.20 In contrast, XGBoost has often been identified as a suitable compromise, offering a favorable balance between predictive performance and computational efficiency, which makes it attractive for real-world fraud detection systems.2,22
Research into hybrid anomaly detection models typically seeks to fulfil several key objectives, including enhancing detection accuracy, improving robustness against emerging fraud patterns, and integrating both supervised and unsupervised learning techniques to capitalize on the strengths of each approach. Hybrid models are particularly advantageous in scenarios where labelled data are limited because they enable the use of unsupervised methods to identify anomalies, whereas supervised models refine and validate these detections.23–25 For example, integrating supervised models that learn from historical transaction data with unsupervised models capable of detecting novel anomalies facilitates a more comprehensive detection framework, addressing the limitations of methods that rely solely on a single-learning paradigm.23,24
The literature highlights notable gaps in existing anomaly detection frameworks, particularly their limited adaptability to evolving fraud patterns and poor generalizability across diverse datasets. Hybrid models offer a promising solution to these issues by leveraging various data sources and learning strategies, thereby increasing their effectiveness in real-world deployment.26,27 For instance, studies incorporating Generative Adversarial Networks (GANs) into traditional machine learning workflows have demonstrated improved detection of complex fraud patterns that may elude conventional models.4 Moreover, the flexibility of hybrid models supports continuous learning and adaptation, which are essential features of the constantly evolving fraud landscape.23,24
Success in fraud detection research is typically measured using performance metrics such as accuracy, precision, recall, and F1-score, which collectively evaluate a model’s capability to correctly identify fraudulent transactions while maintaining operational efficiency.28,29 Minimizing false positives and effectively identifying previously unseen fraud cases are also critical indicators of success.23,24 Models that strike a balance between high accuracy and low false positive rates are particularly valued, as they reduce the burden of manual transaction reviews and minimize disruption to legitimate users.23,24,29
Both supervised and unsupervised learning play an integral role in addressing the research challenges in fraud detection. Supervised learning is particularly effective when sufficient labelled data are available, enabling the model to learn the distinctions between fraudulent and non-fraudulent transactions.30,31 By contrast, unsupervised learning excels in scenarios where labels are unavailable, identifying novel or emerging fraud patterns without prior examples.23–25 The integration of both techniques enhances not only the model’s detection capacity but also the interpretability and adaptability of the fraud detection framework, as evidenced by research that underscores their complementary nature.24,25
In the literature, “success” in fraud detection is frequently defined in terms of balancing detection performance with operational efficiency. This includes the ability to accurately detect fraudulent transactions with minimal false positives, thereby ensuring that genuine users are not adversely affected.23–25 Furthermore, a model’s adaptability to new fraud typologies and its performance across various datasets are equally important for assessing its practical applicability and overall robustness.23–25
Autoencoders have emerged as powerful tools for feature extraction in anomaly detection, particularly fraud detection. By leveraging their ability to learn compressed representations of data, autoencoders can effectively identify anomalies by reconstructing the input data and measuring the reconstruction error. This process allows for the extraction of relevant features that distinguish normal data from anomalies, as the model learns to ignore noise and irrelevant information during training.32–34 The architecture of autoencoders, which typically consists of an encoder and decoder, facilitates dimensionality reduction, making them suitable for high-dimensional datasets often encountered in fraud detection scenarios.35,36
Despite their advantages, autoencoders have limitations when applied to unsupervised-learning tasks. A significant challenge is determining an appropriate reconstruction error threshold, which is crucial for distinguishing between normal and anomalous instances. This threshold can be influenced by the distribution of reconstruction errors, and improper selection may lead to high false positive rates or missed detections.33,37,38 Moreover, autoencoders can struggle with class imbalances because they are typically trained on predominantly normal data, making it difficult to generalize to rare fraudulent instances.37,39 Additionally, the complexity of the model can lead to overfitting, particularly when the training dataset is small or lacks diversity.40,41
When comparing autoencoders to other unsupervised methods in fraud detection, such as clustering and traditional statistical methods, autoencoders often demonstrate superior performance because of their ability to learn complex, non-linear relationships in the data.35,39,42 For example, while clustering methods may struggle with high-dimensional data, autoencoders can effectively reduce dimensionality and capture intricate patterns that signify fraudulent behavior.35,39,42 Furthermore, ensemble methods that combine autoencoders with other algorithms, such as Random Forests or Gradient Boosting, have shown promising results in improving detection accuracy and robustness against class imbalance.40,41
In summary, autoencoders are effective for feature extraction in anomaly detection, particularly fraud. Their architectures, such as VAEs and LSTM autoencoders, are suitable for various data types. However, issues, such as threshold determination and class imbalance, require further investigation. In this study, we combined autoencoders with other models to enhance the results and address these challenges.
The Isolation Forest algorithm is a powerful tool for anomaly detection, particularly in financial datasets. It operates based on the principle of isolating anomalies, instead of profiling normal data points. This is achieved by constructing a random forest of isolation trees, where each tree is built by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of that feature. Anomalies are identified as instances that require fewer splits to be isolated because they are often located far from the majority of the data points in the feature space.43,44 This characteristic makes isolation forests particularly effective in high-dimensional datasets, where traditional methods may struggle owing to the curse of dimensionality. Studies have shown that isolation forests maintain robust performance in high-dimensional settings, effectively identifying outliers, even when dimensionality increases significantly.43,45
Parameter tuning is crucial for optimizing the performance of an isolation-forest algorithm. Common techniques include adjusting the number of trees in the forest and subsampling size, which can influence the sensitivity of the model to anomalies. For instance, increasing the number of trees generally improves the robustness of the model, while the subsampling size can be tuned to balance between computational efficiency and detection accuracy.45,46 In terms of computational advantages, the Isolation Forest algorithm is highly efficient and requires linear time complexity relative to the number of data points, making it scalable for large datasets.44,47
Isolated forests can also be integrated into hybrid models to enhance their anomaly detection capabilities. For example, it can be combined with supervised learning techniques to refine the detection process by leveraging labelled data for training. This integration allows for improved feature selection and anomaly characterization, leading to better overall performance in detecting complex patterns in financial datasets.48,49 Such hybrid approaches can utilize the strengths of multiple algorithms, thereby improving the robustness and accuracy of anomaly detection frameworks in various applications, including fraud detection in banking and finance.49
In summary, the Isolation Forest algorithm is a robust method for detecting anomalies in financial datasets, and is particularly effective in high-dimensional spaces. Parameter tuning plays a critical role in optimizing the performance, whereas its computational efficiency makes it suitable for large datasets. Despite these limitations, the integration of isolated forests with other methods in hybrid models can significantly enhance their anomaly detection capabilities.
Extreme gradient boosting (XGBoost) has emerged as a powerful tool for fraud detection, particularly in the context of imbalanced datasets. The algorithm’s inherent ability to handle imbalanced data stems from its gradient boosting framework, which optimizes the model by focusing on misclassified instances, thereby enhancing its sensitivity to minority classes, such as fraudulent transactions. This characteristic is crucial in fraud detection, where fraudulent cases often significantly outnumber legitimate ones.50,51 Furthermore, XGBoost incorporates regularization techniques that help mitigate overfitting, which is a common challenge in machine learning models trained on imbalanced datasets50,51
Hyperparameter tuning is essential for optimizing the performance of XGBoost in fraud detection tasks. Techniques such as grid search, random search, and more advanced methods such as Bayesian optimization have been employed to identify the most effective hyperparameters. For instance, the use of Bayesian optimization has been shown to enhance the model’s ability to balance training weights for asymmetric examples, which is particularly beneficial in fraud-detection scenarios.52,53
When comparing XGBoost with other supervised learning methods, it consistently demonstrates superior performance in fraud-detection tasks. Studies have shown that XGBoost outperforms traditional models such as logistic regression and decision trees as well as other ensemble methods such as random forests. This superiority is attributed to its ability to capture complex non-linear relationships and interactions between features, which are often present in fraud detection datasets.54,55 Moreover, XGBoost’s feature importance capabilities allow practitioners to gain insights into the most influential predictors of fraud, further enhancing model interpretability and decision-making processes.19,56
Researchers have also explored the integration of XGBoost with hybrid anomaly-detection models. For instance, combining XGBoost with unsupervised learning techniques allows for the extraction of patterns from data that can be used as new features, thereby improving the robustness of the model against noise and outliers.57
In conclusion, XGBoost’s optimization for fraud detection in imbalanced datasets is facilitated by its robust handling of misclassifications, effective hyperparameter tuning techniques, and superior performance compared to other supervised learning methods. The role of feature importance is critical in refining model performance, while hybrid approaches continue to expand the capabilities of XGBoost in anomaly detection scenarios.
Random Forest (RF) is a versatile ensemble technique that has been broadly applied in anomaly detection for both supervised and semi-supervised learning tasks. In fully supervised settings, RF algorithms are trained with labelled examples covering both normal and anomalous classes, thereby enabling the model to learn complex non-linear decision boundaries that can reliably separate rare and abnormal events.58 In contrast, semi-supervised applications typically exploit RF’s ability to capture underlying data distributions by training exclusively on normal (or “positive”) samples and subsequently flagging deviations as anomalies.59
The performance of RF is particularly noteworthy in high-dimensional and large-scale datasets such as those encountered in credit card fraud detection. RF can naturally handle large numbers of features owing to its random feature subspace selection at each split, which mitigates overfitting and improves generalization.60 Empirical studies have demonstrated that RF-based methods perform competitively in scenarios characterized by rare events, such as fraud detection, by effectively identifying subtle patterns that differentiate fraudulent from legitimate behaviors.60 Nevertheless, the class imbalance inherent in such applications often calls for hybrid or improved approaches, for example, through combination with feature selection procedures or integration with unsupervised algorithms, to further boost detection accuracy.
Hybrid models, which combine unsupervised and supervised learning techniques, have gained traction in various fields owing to their ability to leverage the strengths of both approaches. The integration of unsupervised outputs with supervised methods can enhance the predictive performance, particularly in scenarios where labelled data are scarce. This synthesis typically involves several strategies, including feature extraction, ensemble methods, and model stacking, which can significantly improve the overall performance of the hybrid models.
One effective integration strategy is the use of unsupervised learning for feature extraction, which can reduce dimensionality and capture underlying patterns in the data. For instance, autoencoders or clustering algorithms can preprocess data before they are fed into a supervised learning model, thereby enhancing their predictive capabilities.61,62 In addition, ensemble methods that combine predictions from unsupervised and supervised models can lead to more robust outcomes. For example, a hybrid model that integrates predictions from a clustering algorithm with those from a regression model can yield a better accuracy than either model alone.63
Handling conflicting outputs from unsupervised and supervised models is a critical challenge in hybrid modelling. Researchers often employ conflict resolution strategies such as voting mechanisms, where the final decision is based on the majority output, or weighted averaging, where outputs are combined based on their reliability or performance metrics.64,65 This approach allows for more nuanced integration of the models, ensuring that the final output reflects the strengths of both methodologies. In this study, we utilized a weighting method to combine the outputs of supervised and unsupervised algorithms.
In summary, hybrid models that integrate unsupervised and supervised methods offer significant advantages in terms of predictive performance and robustness. By employing effective integration strategies, resolving conflicts between outputs, and utilizing appropriate benchmarks for evaluation, researchers can harness the strengths of both methodologies to address complex challenges across various domains.
In fraud detection studies, various evaluation metrics were employed to assess the performance of the models. Commonly used metrics include accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). Each metric provides unique insights into the effectiveness of the model in identifying fraudulent activity.
Precision, recall, and F1-score are particularly significant in the context of anomaly detection. Precision measures the proportion of true positive predictions among all positive predictions, indicating the number of flagged instances that were fraudulent. However, recall assesses the proportion of true positives among all actual positives, reflecting the model’s ability to identify all relevant instances. The F1-score is the harmonic mean of the precision and recall, providing a single metric that balances both concerns. In fraud detection, where false positives can lead to unnecessary investigations and false negatives can result in undetected fraud, these metrics are crucial for evaluating the model performance.66,67
Precision means: Of all predicted positive cases, how many were actually positive.
Recall means: Of all actual positive cases, how many were correctly predicted.
F1-Score: Harmonic means of Precision and Recall — a balance between the two.
Where:
TP = True Positives
TN = True Negatives
FP = False Positives
FN = False Negatives
The trade-off between accuracy and computational efficiency is critical for fraud detection. While accuracy provides a straightforward measure of overall correctness, it can be misleading in imbalanced datasets, which are common in fraud-detection scenarios where fraudulent cases are rare compared with legitimate ones. Computational efficiency, on the other hand, refers to the time and resources required to train and deploy models. Models that achieve high accuracy may require extensive computational resources, making them less practical for real-time fraud detection applications. Therefore, it is necessary to strike a balance must be struck between achieving high accuracy and maintaining computational efficiency to ensure that the models can operate effectively in real-world environments.66,67
AUC-ROC curves are instrumental in assessing model performance, particularly in binary classification tasks such as fraud detection. The ROC (Receiver Operating Characteristic) curve plots the true positive rate against the false positive rate at various threshold settings, allowing for visualization of the trade-off between sensitivity and specificity. The AUC (Area Under the Curve) quantifies the overall ability of the model to discriminate between the positive and negative classes, with values closer to 1 indicating better performance. AUC-ROC is particularly useful in fraud detection because it provides a comprehensive view of the model’s performance across different decision thresholds, aiding in the selection of an optimal threshold for deployment.68–70
Several datasets and competitions exist in terms of benchmarks for comparing model results for fraud detection. For instance, Kaggle competitions often provide standardized datasets for benchmarking machine-learning models. Additionally, the UCI Machine Learning Repository includes various datasets relevant to fraud detection, allowing researchers to compare their models with established baselines. These benchmarks facilitate the evaluation of new methods against existing approaches and promote advancements in the field.66,67
In summary, the evaluation metrics commonly used in fraud-detection studies include precision, recall, F1-score, and AUC-ROC. Each metric offers valuable insights into the model performance, particularly in the context of imbalanced datasets. The trade-off between accuracy and computational efficiency highlights the need for practical solutions for real-time applications. AUC-ROC curves serve as vital tools for assessing model discrimination capabilities, whereas established benchmarks provide a framework for comparative analysis in the field. The researcher used precision, recall, and F1-score to evaluate the performance of the hybrid model. Additionally, AUC-ROC and MCC (Matthews Correlation Coefficient) values were calculated to obtain insights into the model results.
The creditcard.csv dataset, which is widely utilized in fraud-detection research, is characterized by its focus on credit card transactions, specifically anonymized records from European cardholders. This dataset typically contains features such as transaction time, transaction amount, and various anonymized features derived from PCA (Principal Component Analysis) to protect user privacy. A notable aspect of this dataset is its significant class imbalance, where fraudulent transactions are vastly outnumbered by legitimate transactions, presenting a challenge for machine learning models.30,71,72 The dataset consists of approximately 284,807 transactions, with only 492 labelled as fraudulent, highlighting the difficulty of detecting fraud owing to the rarity of positive instances.9,73
The quality of datasets significantly affects the performance of hybrid models in fraud detection. High-quality datasets enable more accurate feature extraction and model training, leading to improved detection rates and reduced false positives.20,74 Conversely, poor-quality datasets can result in overfitting, where models perform well on training data but fail to generalize to unseen data, ultimately undermining their effectiveness in real-world applications.9,75 Therefore, ensuring high-quality data is essential for developing reliable and efficient fraud-detection systems.
This study employs the publicly available creditcard.csv dataset from Kaggle, which contains anonymized credit card transaction data from European cardholders. The dataset consists of 284,807 transactions, of which 492 are labelled as fraudulent, representing approximately 0.17% of the total data. The features include 28 principal components (V1–V28) derived through Principal Component Analysis (PCA) to preserve privacy, along with the Amount, Time, and Class attributes. The Class variable serves as the binary target label, where 1 indicates fraud, and 0 represents a legitimate transaction.
The preprocessing challenges in real-world financial datasets are prevalent and multifaceted. Common issues include handling missing values, addressing class imbalances, and ensuring data privacy and security.2,6,76
As a preprocessing step, The MinMaxScaler technique was used. MinMaxScaler is a widely used data pre-processing technique that transforms numerical features by rescaling them to a specified range, typically between 0 and 1. This scaling method preserves the relationships between the original data values while ensuring that all features contribute proportionately to model training. It is particularly effective for distance-based algorithms and neural networks, which are sensitive to differences in feature magnitude. This helps standardize features such as transaction amounts or time-related attributes, enabling models such as autoencoders to converge more quickly and effectively.
Additionally, researchers have employed Principal Component Analysis (PCA) as a preprocessing tool for dimensionality reduction. PCA is a widely used technique for dimensionality reduction during anomaly detection. By transforming high-dimensional data into a lower-dimensional space, PCA helps identify patterns and anomalies more efficiently. This is achieved by projecting the data onto the directions of maximum variance, effectively filtering out noise and irrelevant features, which can obscure the detection of anomalies.77,78
Furthermore, class imbalance, where legitimate transactions far outnumber fraudulent transactions, complicates the training of machine-learning models, often leading to biased predictions that favor the majority class.72,79 To address class imbalance, researchers employed the BorderlineSMOTE method to address class imbalance in the creditcard.csv dataset. However, this method is exclusively applied during the training of supervised methods because it adversely affects the unsupervised algorithms.
In this study, XGBoost and Random Forest were employed as supervised learning algorithms, whereas the Autoencoder and Isolation Forest were utilized as unsupervised methods to detect anomalies. The data preprocessing pipeline includes MinMax normalization to standardize the feature scales and remove statistical outliers to reduce noise and improve model stability. To address the high dimensionality of the dataset, Principal Component Analysis (PCA) was applied as a dimensionality reduction technique, preserving the most significant variance components.
In addition, BorderlineSMOTE was incorporated into the training process of the supervised models to address class imbalance and improve minority class learning. This technique was particularly beneficial in enhancing the sensitivity of classifiers to fraudulent transactions while also reducing the risk of overfitting to rare fraud instances. Moreover, BorderlineSMOTE contributes to increased robustness against boundary-region vulnerabilities and potential data-poisoning attacks, thereby strengthening the overall generalization capability of supervised components.
As an initial step, we analyzed the performance of each method. The table below ( Table 1) presents the results of the precision, recall, F1-score and accuracy for each method for both normal cases (0) and fraud cases (1).
Among the evaluated methods, XGBoost exhibited the best overall performance. It achieves near-perfect results for the majority class (Class 0) with precision (0) = 0.9999 and recall (0) = 0.9999 and maintains a high level of performance in the minority class (Class 1, i.e., fraud cases), with precision (1) = 0.9407, recall (1) = 0.9250, and F1-score (1) = 0.9328. This balance between precision and recall is crucial for fraud detection, indicating that XGBoost not only detects the most fraudulent transactions but also minimizes false alarms. The overall accuracy of 0.9998 further confirms its robustness, although in imbalanced datasets, the accuracy alone is not a sufficient indicator. In conclusion, XGBoost is a top-performing supervised method that effectively manages both false positives and false negatives.
Moreover, Random Forest also demonstrates strong performance in the majority class, similar to XGBoost, with Precision(0) = 0.9998 and Recall(0) = 0.9999. However, it performed slightly lower on the minority class, with recall (1) = 0.8750 and F1-score (1) = 0.9091. This suggests that while Random Forest is highly effective, it may miss a small number of fraud cases compared to XGBoost. Nevertheless, its accuracy of 0.9997 confirms its high reliability. In conclusion, Random Forest is an effective and reliable ensemble method, but slightly less optimal than XGBoost for fraud detection.
In contrast, The Autoencoder, an unsupervised learning method trained on normal data (Class 0), performs exceptionally well on the majority class, with precision (0) = 0.9993 and recall (0) = 0.9994. However, its fraud detection performance was significantly lower, with precision (1) = 0.5847, recall (1) = 0.5750, and F1-score (1) = 0.5798. Although it still detects some anomalies, the model generates a large number of false positives and fails to detect many frauds. In conclusion, the autoencoder is moderately effective as a baseline anomaly detector but lacks precision and recall for minority class identification in isolation.
The isolation Forest produces poor results for fraud detection, with precision (1) = 0.0192 and F1-score (1) = 0.0376, despite a relatively high recall (1) = 0.9500. This suggests that while it flags nearly all frauds (high recall), it generates an extremely high number of false positives (very low precision), making it impractical for real-world fraud detection, where every alert carries a cost. The overall accuracy of 0.9230 was misleadingly high, inflated by the overwhelming presence of normal transactions. In conclusion, the forest isolation method is overly sensitive and lacks practical usefulness for fraud detection in imbalanced datasets.
In high-stakes domains, such as credit card fraud detection, the cost of false positives (customer complaints) and false negatives (missed fraud) must be minimized. Among the models tested, XGBoost provided the best trade-off between fraud detection and noise minimization. Hybrid approaches that combine the sensitivity of unsupervised methods (such as autoencoders) with the precision of supervised learners (such as XGBoost or RF) may offer better results when properly tuned.
Hence, in this study, we tested a hybrid model by combining these four methods (XGBoost, RandomForest, Autoencoder, and IsolationForest) and applied a weight tool as it assigns different importance levels (weights) to the outputs of various models (e.g., Autoencoder, XGBoost, Isolation Forest, etc.) when combining their anomaly scores into a single decision score.
The table below ( Table 2) presents the final performance results after combining the methods and applying the weights. We named the model XRAI, which is the first letter of each method (XGBoost, RandomForest, Autoencoder, and IsolationForest).
The hybrid XRAI model, which integrates the strengths of XGBoost, Random Forest, Autoencoder, and Isolation Forest using a weighted score, demonstrates outstanding anomaly detection capability. It effectively combines supervised and unsupervised methods to balance precision, recall, and generalization, which are crucial in high-stake fraud detection scenarios.
• Precision (0) = 0.9999 and recall (0) = 0.9999 indicate near-perfect classification of legitimate transactions.
This means that the model is extremely reliable for minimizing false positives, which is critical for avoiding the disruption of normal customer activity.
• The F1-score (0) = 0.9999 confirms that there is no trade-off between precision and recall for normal transactions.
• Precision (1) = 0.9569 indicates that when the model flags a transaction as fraudulent, it is correct approximately 96% of the time, which is vital to avoid wasting resources on false alarms.
• Recall (1) = 0.9250 shows that the model can capture over 92% of all fraudulent transactions, which is an impressive detection rate given the class imbalance and subtlety of the fraud patterns.
• The F1-score (1) = 0.9407 demonstrates a strong harmonic balance between precision and recall, making the model highly effective for real-world deployment.
Figure 1 illustrates the Receiver Operating Characteristic (ROC) curve for the proposed hybrid anomaly detection model, XRAI (XGBoost, Random Forest, Autoencoder, Isolation Forest). The ROC curve plots the True Positive Rate (recall) against the False Positive Rate (1 - Specificity) across a range of classification thresholds.
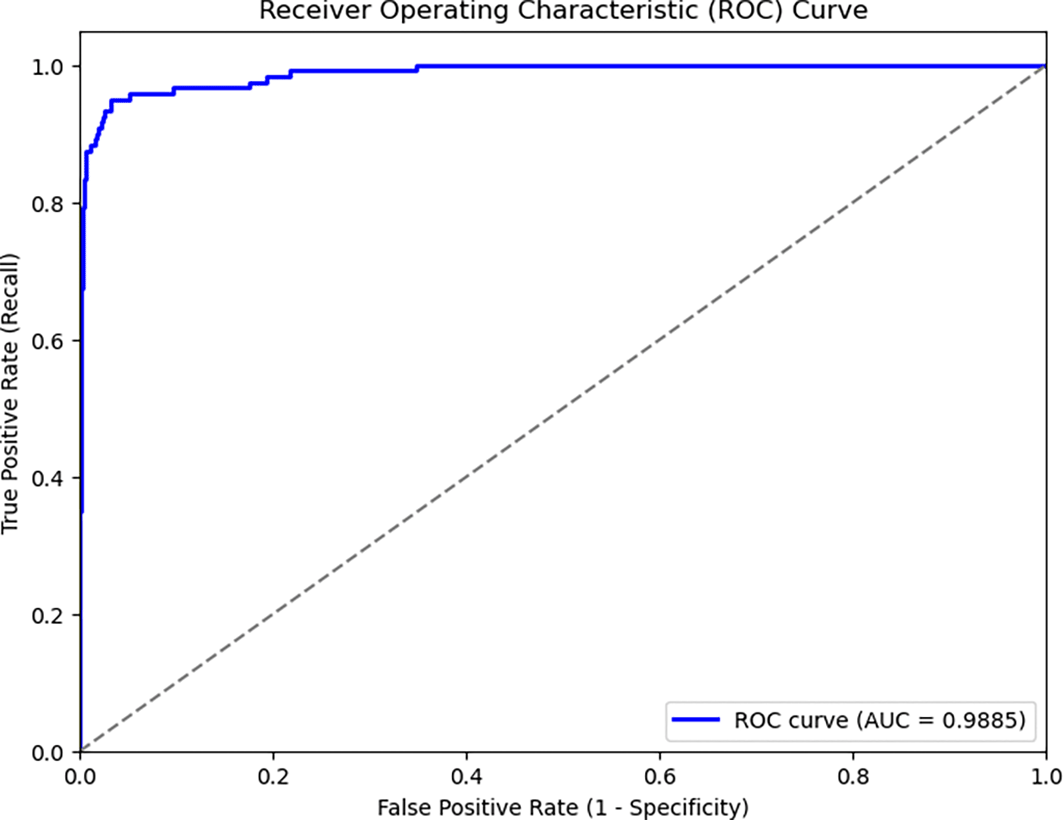
(XRAI: First letters of XGBoost, Random Forest, Autoencoder, Isolation Forest).
The curve shows a steep rise toward the upper-left corner of the plot, which is indicative of a high-performing classifier. The area under the ROC curve (AUC) is 0.9885, suggesting that the model had excellent discriminative capability. An AUC value closer to 1 indicates that the classifier is highly capable of distinguishing between the positive class (fraudulent transactions) and negative class (legitimate transactions).
In summary, the ROC curve and its corresponding AUC of 0.9885 provide strong empirical evidence of XRAI’s ability to effectively separate fraud from non-fraud, even under class imbalance conditions, a critical requirement for robust fraud-detection systems in the financial domain.
The proposed XRAI model, an ensemble combining XGBoost, Random Forest, Autoencoder, and Isolation Forest, achieved a Matthews Correlation Coefficient (MCC) of 94.07%, indicating a strong and balanced predictive performance, particularly in the context of imbalanced classification tasks such as credit card fraud detection.
The XRAI model demonstrates a highly optimized hybrid ensemble for credit card fraud detection. It achieves excellent detection of rare fraudulent cases, while maintaining ultralow false-positive rates. The combination of supervised precision and unsupervised anomaly sensitivity is managed through a weighted mechanism that positions XRAI as a practically deployable solution in real-time financial anomaly detection systems.
To contextualize the performance of the proposed hybrid anomaly detection framework, a comparative analysis was conducted with recent studies on credit card fraud detection that utilized similar datasets and evaluation metrics. The objective of this comparison is to demonstrate the relative effectiveness of the proposed model in terms of precision, recall, F1-score, and MCC.
Several studies have explored both the single-model and hybrid approaches using the Kaggle credit card fraud dataset. These models include supervised methods such as Logistic Regression, Random Forest, and XGBoost as well as unsupervised techniques such as Isolation Forest and Autoencoder-based anomaly detectors. In more recent works, hybrid models combining deep learning and ensemble techniques have been proposed to address the limitations of detection accuracy and generalizability.
Table 3, summarizes the selection of comparable studies, outlining the key models used and their reported results. The evaluation metrics used in each study were also included to enable a standardized comparison. Where applicable, the performance of the proposed hybrid model is highlighted to illustrate the improvements over the existing approaches.
| Method | Accuracy | Precision | Recall (TPR) | F1-score | MCC | TNR |
|---|---|---|---|---|---|---|
| Our Proposed Method (XRAI) | 0.9998 | 0.9569 | 0.9250 | 0.9407 | 0.9407 | 0.9999 |
| Ding et al. (2024)80 - AE + LightGBM (AEELG) | 0.921 | 0.8875 | 0.3451 | 0.4722 | 0.4739 | |
| Du et al. (2024)81 - AE-XGB-SMOTE-CGAN | 0.9993 | 0.7839 | 0.8845 | 0.9997 | ||
| Alshameri & Xia (2024)82 – VAE | 0.93 | 0.92 | 0.92 | |||
| Wu & Wang (2022)83 - Autoencoder + Adversarial Net | 0.9061 | 0.9216 | 0.8878 | 0.9044 | 0.8128 | |
| Lok et al. (2022)23 - Hybrid Kmeans -KNN | 0.9579 | 0.7215 | 0.8231 | |||
| Ishak et al. (2022)84 - Enhanced Stacking Classifier System | 0.9837 | 0.8841 | ||||
| Benchaji et al. (2021)85 - Attention + LSTM | 0.9672 | 0.9885 | 0.9191 |
As shown in the Table 3, the proposed hybrid model achieved superior performance across multiple metrics, attaining the highest accuracy with value of 0.9998, precision of 0.9569 (in top threee) and recall of 0.9250 (top one), resulting in an F1-score of 0.9407 (top one) and MCC of 0.9407 (top one). These results reflect significant advancements over earlier models, particularly in balancing the trade-off between the sensitivity and specificity.
This comparison substantiates the effectiveness of the proposed framework and supports its relevance as a practical, high-performance solution for financial fraud detection.
The findings of this study have significant implications for real-world financial fraud detection, particularly in environments where data are imbalanced, adversarial, and evolving. The proposed hybrid model, XRAI, demonstrated exceptional accuracy and robustness in detecting anomalies in widely used credit cards. csv dataset. By leveraging the strengths of XGBoost, Random Forest, Autoencoder, and Isolation Forest through a weighted scoring mechanism, XRAI offers a holistic and practical approach for identifying fraudulent financial transactions in real-time.
One of the most critical applications of this model is early detection of credit card fraud. Financial institutions are facing increasing threats from sophisticated fraud schemes that are often hidden within massive volumes of transactional data. Traditional models that rely solely on supervised learning struggle with previously unseen and rare types of fraud. By incorporating unsupervised models, such as autoencoders and isolation forests, XRAI can detect previously unclassified anomalies, enabling systems to capture zero-day fraud attacks that evade conventional classifiers.
In addition to fraud detection, this hybrid approach can be adapted for anti-money laundering (AML) systems, insurance fraud detection, and transaction monitoring in e-commerce. Given the adaptability of the model to high-dimensional and noisy data, it can also be used in environments beyond banking, such as healthcare claim validation or cyber intrusion detection, where anomalous patterns are often rare and context dependent.
The practical benefits of this hybrid system extend beyond academic experimentation. It offers a deployable, scalable, and intelligent solution for industries facing complex fraud challenges. As financial crime continues to grow in scale and complexity, systems such as XRAI provide a promising blueprint for building more secure, proactive, and trustworthy fraud detection frameworks.
Although the XRAI hybrid model presents a strong case for fraud-detection performance, several limitations emerged during the development and evaluation that must be addressed to fully understand its practical applicability. These limitations can be grouped into three primary categories: data, models, and operational constraints.
First, it relies on the creditcard.csv dataset, which has certain constraints despite its popularity. It is highly imbalanced, anonymized, and preprocessed and does not fully reflect the diversity and noise found in real-world financial data. Features such as merchant category, transaction geolocation, and time-series behavior were not present in this dataset. This limits the generalizability of the model to broader financial environments. Moreover, the dataset lacks adversarial fraud samples that mimic legitimate behavior, which is increasingly common in real financial systems.
Second, the complexity of hybrid architecture introduces challenges in terms of interpretability, maintenance, and scalability. Although the ensemble combines multiple strengths, it also has its weaknesses. For example, autoencoders require careful tuning and are sensitive to reconstruction thresholds, whereas Isolation Forests tend to produce high false-positive rates unless precisely calibrated. Managing the balance of weights across all models adds an additional layer of complexity, particularly when adapting a system to new datasets or changing fraud patterns.
Another limitation is the requirement for labelled data for supervised components, such as XGBoost and Random Forest. Labeling fraud in real-world data is often delayed or incomplete, which can limit the speed of retraining and adaptation. In rapidly changing environments, supervised models become stable unless mechanisms are in place for online or incremental learning.
In summary, although XRAI provides strong fraud-detection performance in experimental settings, its real-world deployment requires careful consideration of data diversity, model manageability, latency, and compliance. Addressing these limitations can further enhance its reliability and adoption.
This study introduced a novel hybrid model, XRAI, designed to enhance the performance and robustness of anomaly detection in credit card fraud-detection systems. By strategically integrating supervised learning algorithms such as XGBoost and Random Forest with unsupervised techniques such as autoencoders and isolation forests, the model effectively overcomes the limitations of single-classifier approaches in highly unbalanced and adversarial environments.
The XRAI model demonstrated strong predictive power across a range of performance metrics, achieving an accuracy of 99.98%, precision of 95.69%, recall of 92.50%, and F1-score of 94.07%. The Matthews Correlation Coefficient (MCC) of 94.07% and AUC of 0.9885 further indicate a high discriminative ability and balanced performance between the fraud and non-fraud classes. These results highlight the model’s potential for real-time deployment in financial institutions aimed at reducing operational risks and minimizing false alarms.
Despite these achievements, the study also acknowledged key limitations, including reliance on a single publicly available dataset (creditcard.csv), the computational cost of the hybrid architecture, and interpretability challenges. These limitations pave the way for further research in this area.
Building on the current findings, future research on the XRAI model can pursue several promising directions to enhance its applicability and robustness in real-world settings. A critical improvement involves incorporating temporal and contextual features, as fraudulent behaviors often manifest as sequential patterns over time. Leveraging techniques such as LSTM-based Autoencoders or Transformer-based architectures can enhance the detection of complex and evolving fraud strategies. Moreover, integrating contextual data, such as customer profiles, merchant categories, and geographic transaction information, can further improve classification accuracy and reduce false positives.
Future studies should focus on adaptive ensemble strategies, explainable AI techniques, and robustness against adversarial attacks. Testing the model across diverse datasets and domains is essential to validate its generalizability and scalability.
In conclusion, the XRAI model presents a scalable, intelligent, and highly accurate solution for credit-card fraud detection. With further refinements in temporal modelling, explainability, and robustness, hybrid models such as XRAI hold significant promise for building trustworthy and resilient fraud detection systems tailored to the ever-evolving landscape of financial crime.
The contributions of each author are described according to the CRediT (Contributor Roles Taxonomy) system:
• Mohammad Shanaa: Conceptualization; Methodology; Data Curation; Formal Analysis; Software; Validation; Visualization; Writing – Original Draft; Writing – Review & Editing; Project Administration.
Mohammad Shanaa led the design and execution of the research, conducted the data analysis and model development, and prepared the initial and revised versions of the manuscript.
• Sherief Abdallah: Supervision; Conceptualization; Writing – Review & Editing.
Sherief Abdallah supervised the research process, contributed to refining the methodology and framing the research direction, and provided critical revisions to the manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)