Keywords
Community screening, discrete choice experiment, D-efficient design
This article is included in the Health Services gateway.
Community screening, discrete choice experiment, D-efficient design
According to the Australian Institute of Health and Welfare, chronic diseases such as heart disease, diabetes, cancer, and respiratory disease are the leading cause of illness, disability, and death in Australia, and their burden is projected to rise due to factors such as population aging, changing lifestyles, and environmental factors.1 Community screening programs for chronic diseases need to be implemented to address this challenge. However, to ensure the success and sustainability of such programs, eliciting population preferences for the types of health screening services offered is crucial. Understanding the community’s preferences is critical in designing community screening programs that are both effective and well-received by the target population.2 By doing so, these programs can be tailored to the specific needs and preferences of the community, increasing their acceptability, and improving their effectiveness in identifying and managing chronic diseases.
Discrete choice experiments (DCEs) are gaining popularity in finding otherwise unavailable answers for problems in healthcare. The insights provided by DCEs into patients’ and healthcare workers’ preferences can help make decisions in health services and allocate scarce resources. DCEs being a stated preference method, facilitate decisions holding multiple trade-offs simultaneously and allow consideration of the relative importance of various attributes (and their levels) when making that decision.3 This method allows insights into subtleties of decision-making within stakeholder groups, making it possible to explore the trade-offs between alternatives that sometimes are hypothetical.4 For example, a DCE could simultaneously examine provision of care in hospital or a community setting, care provided by a nurse or specialist, acceptable waiting times, and acceptable out-of-pocket costs.4
The theoretical basis of the DCEs originates from the random utility theory (RUT), which describes choices made by individuals using discrete sets of alternatives.3 A utility function can be used to describe the preference for an alternative by an individual. It is assumed that the alternative with the highest utility (most preferred) will be chosen. This utility depends on the attributes of the alternative (e.g., wait time, travel distance) and the individual making the choice (e.g., age, sex) and the unobserved attributes the data collector may not be aware of (e.g., co-morbidities of the individual making a choice). The observed (collect data on) and unobserved attributes are represented in the utility function by explanatory and random variables, respectively.3
The attributes and their levels are used for the experimental design, which develops hypothetical choice sets to be compared by the respondents.5 The respondents attach a utility to alternatives based on their preference for attribute-level combinations. The choices made by the respondents are considered mutually exclusive (can choose only one option) and collectively exhaustive (all the options are available for decision-making). As such, all the information must be provided within the attributes and levels for valid choices.5 The presentation of all relevant information within a choice set reduces the random effects of the models in question.6 To reduce the randomness of the developed model, it is of upmost importance to use attributes of the greatest relevance to those completing the DCE.
Some DCEs used in healthcare policy settings have failed to report rigorous methods employed to develop appropriate attributes for the alternatives.7 In health policy settings, the attributes are the characteristics of the intervention (e.g., community screening programme for chronic diseases), and each attribute (e.g., place of screening, waiting time) is designated with levels (e.g. hospital, community clinic, one week, one month). Attribute selection to represent the characteristics of the intervention need to follow a rigorous methodology to ensure all vital information is presented for the choice experiment.8 Attribute selection ideally uses mixed methods, including qualitative methods such as focus groups, interviews, quantitative prioritisation, and final determination using expert panels. The participants in this data collection should include relevant stakeholders, including patients, care providers and decision-makers to ensure the representation of all views.8,9
An important part of the design process is where hypothetical alternatives are generated and combined to develop choice sets. By manipulating the design, the investigator can reduce the response burden, increase statistical efficiency, and construct a simpler DCE. A full factorial design containing all possible combinations of attributes may not be feasible due to too many resulting alternatives and choice sets. Therefore, a fractional factorial is often used.3 This design should be orthogonal and balanced. In orthogonal designs, attributes are statistically independent of each other so that the participants’ preferences can be estimated for each attribute. Balanced designs have each attribute occurring equally within choice sets. Choice designs that are both orthogonal and balanced are called orthogonal arrays and are not universally available for all combinations as they are not feasible for alternatives with five or more attributes with two or more levels. When orthogonal arrays are not feasible, designs need to find efficiency by trading off orthogonality and balance.3 Compared to orthogonal designs, efficient designs increase the precision of parameter estimates by reducing coefficient standard errors and allowing some limited correlation between attributes. Most designs use D-efficient designs (D-error (inverse)/D-efficiency/D-optimal) to achieve this efficiency and are recommended to maximise statistical efficiency and minimise the variability of parameter estimates.3,5 D-efficiency ranges from 0% to 100% where 100% denotes the greatest statistical efficiency. Prior information about the parameters in the model is required for efficient designs.10 Since these priors may not always be available for the design algorithm, investigators should look for subsequent D-efficient designs after pilot surveys. The efficient design can use fixed point estimates (prior design) or probability distribution (Bayesian).10 It is preferable to pilot at least with very small priors with hypothetical directions for some parameters and estimate the models to learn the direction and magnitude of priors for the next D-efficient design.
Sample size calculations for DCE studies are evolving. However, it is an important part of the research as a appropriate sample size assures sufficient statistical power to detect a difference in preferences. Investigators tend to maximise the sample size to avoid underpowering DCEs.11 However, given limited budgets, online data collections and the notorious non-responsiveness of patients and clinicians within healthcare DCEs, it is not practical to overpower the sample in most cases. There are heuristic and parametric approaches to estimating sample sizes in DCEs. The disadvantages of these methods have been discussed elsewhere, and methods to estimate sample size have been proposed based on significance level, statistical power, model, priors and design.11
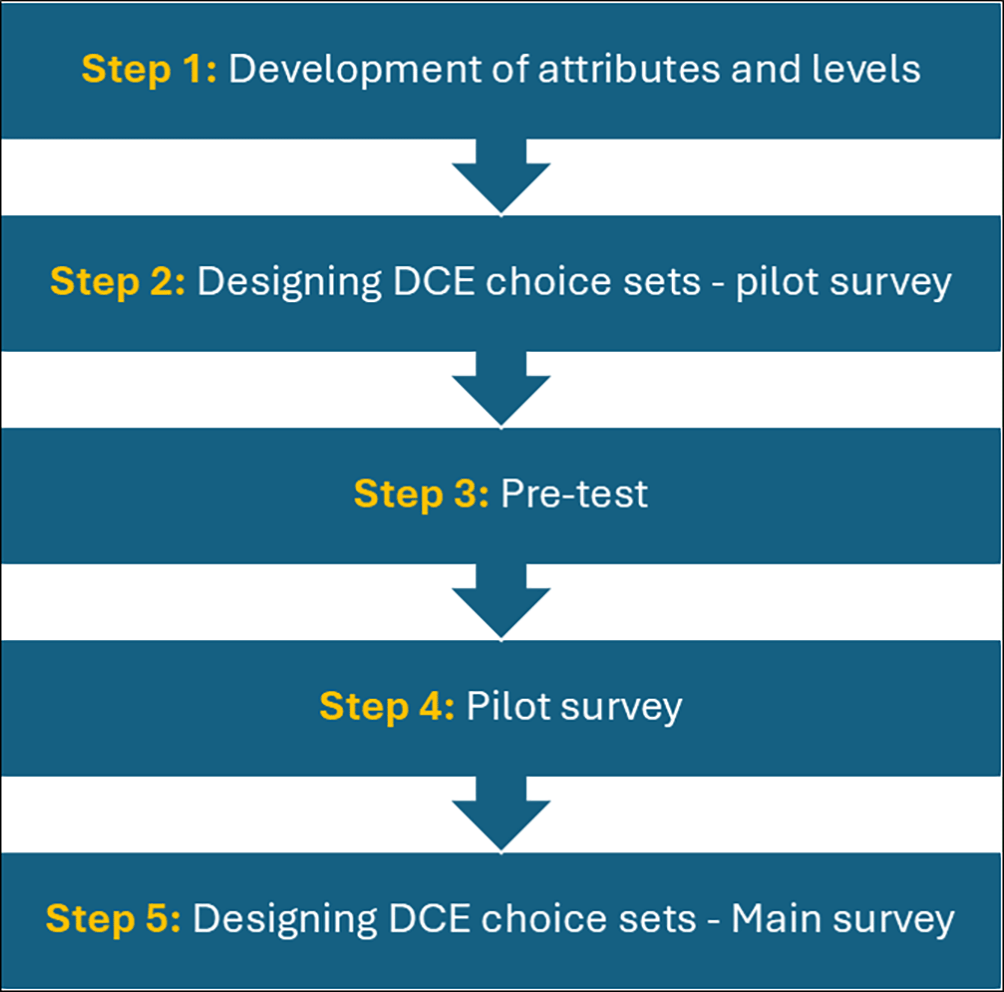
This paper presents methods for determining preferences for community screening programmes for chronic disease in Australia. We previously presented the attribute development for the choice sets. Here, we present the designing, pre-tests, pilots, and use of priors to organise the final design and the data collection for the DCE.
This project was designed to elicit community preferences for health screening services for individuals with chronic diseases such as diabetes, cardiovascular and liver disease, using a discrete choice experiment. This paper describes the designing of the D-efficient design for the pilot survey (Step 2), the results of the pre-test (Step 3) and the pilot survey (Step 4) and designing of the final D-efficient design for the main DCE survey (Step 5) ( Figure 1). The final DCE design was developed after a pre-test and a pilot survey, and the methods and results are presented in later sections. The pilot survey (Step 4) was used to estimate the priors to develop the D-efficient design for the main DCE survey (Step 5). In developing this study and presenting the findings, we adhered to A Reporting Checklist for Discrete Choice Experiments in Health: The DIRECT Checklist, ensuring transparency and methodological rigour throughout the study process.12
Ethics approval for this study was granted by the Queensland University of Technology Human Research Ethics Committee (QUT HREC), with reference number HREC/QUT/4282, on 02/08/2021. The study was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki, ensuring the protection of participants’ rights, safety, and well-being throughout the research process.
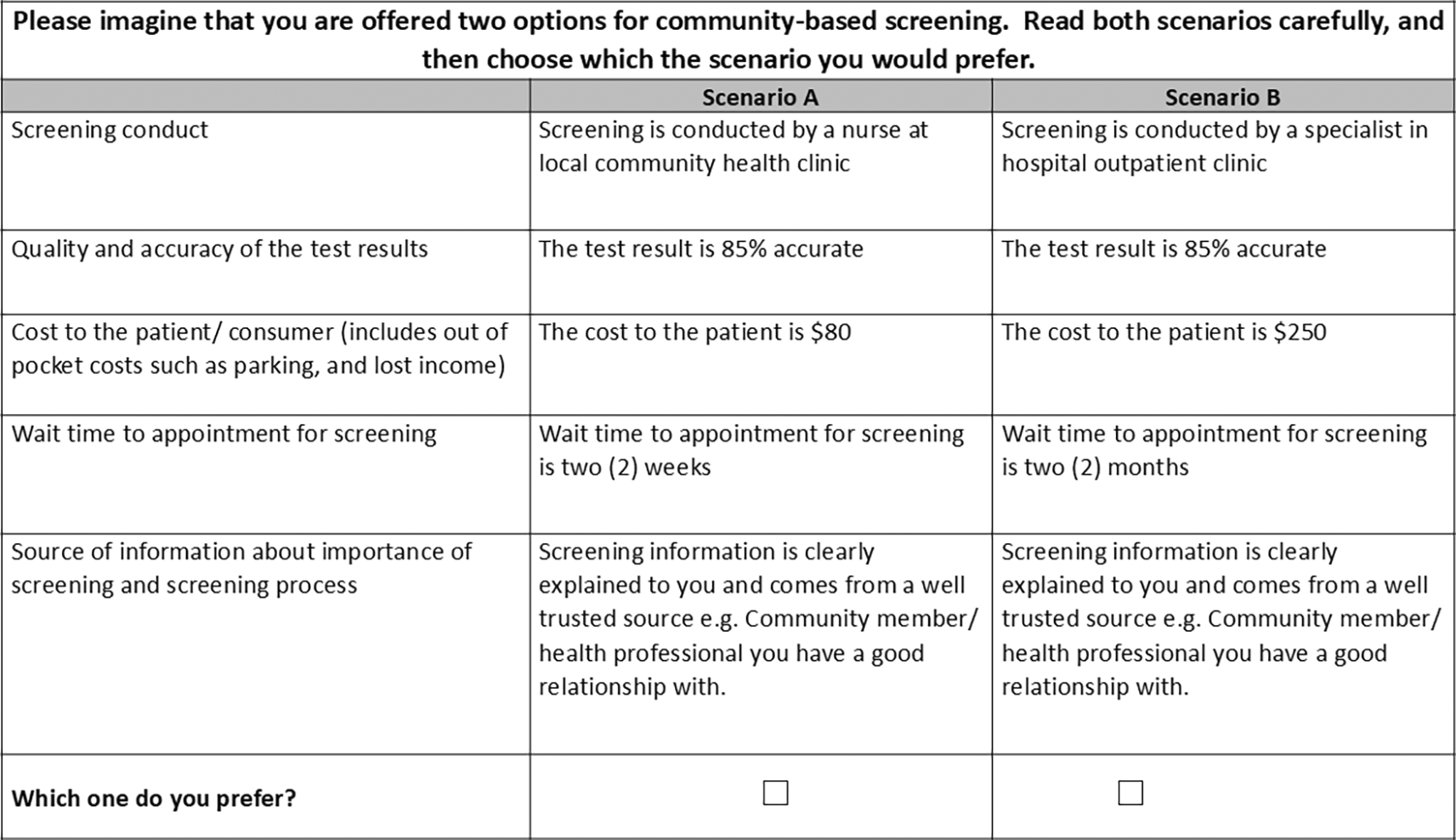
The design was a non-labelled DCE study with respondents presented with two hypothetical scenarios (i.e., choice sets), each containing five attributes with three levels each, which individuals were asked to choose between. The selection of the final set of attributes and levels for this DCE was based on a systematic review of the literature,7 focus groups with consumers and health service providers, a quantitative structured prioritisation exercise and an expert panel discussion to finalise the attributes and levels.9 The final five attributes were: screening conduct, quality and accuracy of the test results, cost to the patient, wait time to appointment for screening, and source of information about the importance of screening and the screening process ( Table 1).
The final attribute list had five attributes with three levels each, and that would result in 59,049 (310) possible choice tasks. An example choice task is given in Figure 2. Since it is not feasible to present all possible combinations (n=59,049) to all the respondents, 30 choice tasks were selected using Ngene version 1.3.0 software, in a fractional factorial design. The 30 choice tasks make up the choice set. The main aim of using a fractional factorial design was to have a manageable number of choice tasks while maximising the design’s statistical efficiency.13 Therefore, a multinomial logit model based on D-efficient fractional factorial design criteria (using the D-error value) was used to develop 30 pair-wise choice tasks using the design software Ngene. Evidence indicates that respondents can efficiently handle ten choice sets at a time.8,14 Therefore, the fractional factorial design was divided into three blocks so that a respondent would only answer ten from the 30 choice tasks in the fractional factorial design. Blocking is an accepted statistical technique in a DCE design that ensures an equal number of respondents per block.5 We used the modified Federov algorithm to develop the D-efficient design, which is known to develop designs with attribute level balance and no dominant choice tasks.15
In the absence of prior information on the coefficients of the different attributes, small positive or negative priors or zero priors (non-informative priors) were used to design the D-efficient design based on the following a priori hypotheses (Table 2).
• People have equal preference for a nurse-led, general practitioner-led, and specialist-led screening programme. Therefore, we used non-informative (zero) priors.
• People have a preference for quality and accurate screening tests.
• People have a negative preference for out-of-pocket cost and wait-time.
• People do not have a strong preference for different sources of information. Therefore, we used non-informative (zero) priors.
Using moderately informative priors for two of the attributes means the 30 choices lean towards those with larger differences in the other attributes, so more information is gathered on these attributes.
Apart from the D-error, attribute level overlap and attribute level balance were used to assess the DCE design. Attribute level overlap is when the same level is present in both choice tasks, essentially eliminating this attribute from that choice. Attribute level balance is the distribution of the attribute levels across the two choice tasks. Lower attribute level overlap and equal distribution of levels indicate a better DCE design.
The pre-test aimed to ascertain comprehension and understanding of the online DCE survey. The online survey was administered to a sample of 10 members of the general population. Empirical studies have shown that a sample size of ten respondents is sufficient for checking for readability and clarity before use in a broader population.16,17
The web-based DCE survey contained three parts. Respondents were first given information and instructions on completing the DCE and shown a sample task. They were also required to provide consent to continue the survey. Demographic data were collected (e.g., gender, age, education) to summarise the characteristics of the study participants.
The second part contained the ten DCE tasks. In addition to these ten choice tasks per respondent, a repeated choice task and a dominant choice task were also included to assess the internal reliability and consistency of responses, creating 12 DCE choice tasks presented to each participant. A choice task with an apparent dominant option was presented at the beginning of the main DCE tasks. The proportion who got this dominant option correct was considered a proxy indicator of the internal reliability and consistency of responses. The third-choice task was repeated at the end of the ten main tasks. The proportion who got the same answer to the repeated tasks was also considered a proxy indicator of the internal reliability and consistency of responses.
In the third component, respondents were asked to rate their difficulty completing DCE tasks, including their ability to understand the words used in the survey tool and ease of following the instructions. The time a respondent took to complete the survey tool was also recorded.
The pilot survey aimed to compute the priors and the best estimation coefficients associated with attributes, so that a more efficient DCE design could be developed. An online survey was administered to a representative sample of the general Australian population over 18 years of age. The data were collected in March 2022.18
Eligible respondents were sourced from the online survey panel PureProfile, an Australian online survey panel (https://www.pureprofile.com/). Pureprofile survey panels have been successfully used in population-based surveys in Australia.19,20 The respondents were drawn from participants who have subscribed to the PureProfile website for the purposes of completing surveys.
A multinomial logit model under a random utility framework was used to analyse the pilot DCE data. The random utility framework assumes that the participants chose the alternative that maximised their utility. The utility function is estimated using the five program attributes and a random error term. The analysis was conducted in NLOGIT 5 software (https://www.limdep.com/products/nlogit).
Similar to step 2, 30 choice tasks (three blocks with ten choice tasks each) were selected using Ngene software, using the multinomial logit model-based D-efficient fractional factorial design criteria. The coefficients (priors) of the pilot survey were used to improve the statistical efficiency of the final experimental DCE choice tasks design.
Sample size calculation for healthcare DCE studies is a developing field.21 A minimum required sample size for a parameter can also be calculated, once reliable priors are obtained.22,23 Assuming the prior coefficient is β1 and the standard error is SE1, the following equation would give the minimum required sample size a parameter (e.g. β1) can be estimated at 95% statistically significant level.11
Ngene software calculates this parameter (S-estimate) and this indicates the smallest sample size needed for all the parameters to be statistically significant.11 Furthermore, as in step 2, attribute level overlap and balance were also assessed.
Based on our a priori hypotheses, the priors used to design the pilot survey are listed in Table 2. Quality and accuracy of the test results, cost to the patient, and wait time were continuous variables, while the others were categorical. The best DCE design was selected based on D-error, with the lowest D-error indicating the most efficient design. The Ngene software was run for around 20 hours. A further description of the design used for the pilot study is presented in supplementary table 1.24 Of the 30 choice tasks, the quality and accuracy of the test results (5/30), cost to the patient (9/30), and wait time (9/30) had overlapping attribute levels. The three levels of the five attributes were almost equally distributed in both the choice tasks.
The main aim of the pre-test was to assess the face validity of the online survey (including the feasibility and appropriateness of the number of attributes in a choice task). The practical difficulties arising while completing the online survey were also assessed. The average time taken to complete the questionnaire was approximately 10 minutes. Based on the survey results, a few modifications were made to the wording of some instructions.
A total of 119 participants responded to the survey, and Table 3 describes the sample’s demographic characteristics. More than three-quarters of the sample were less than 55 years, and there were more males (67%). The majority were residing in metropolitan areas (71%). Only 37% had ever attended a health screening programme.
The average time taken to respond to the survey was 10 minutes (inter quartile rage 5 mins to 11 mins), which was within the expected average time according to the pre-test. The dominant and repeat tasks were correct in 95% and 90% of the responses, respectively. Eighty-one percent (81%) indicated that they did not find it difficult to understand these tasks. Every individual who participated in the survey completed it in full.
Table 4 reports estimates for the multinomial logit model. The highest utility was for a highly accurate screening test (1.03), and the lowest was for wait-time (-0.51). The coefficients for screening provided by either the GP at their regular GP clinic or by a specialist in a hospital outpatient clinic were positive indicating that respondents preferred to be screened by these providers than by a local community health clinic nurse. There was a strong preference for a highly accurate screening test, indicated by the positive utility for 85% and 95% accurate screening tests. There was a disutility when the source of information was limited familiarity and trust (-1.10).
Coefficients estimated from the pilot survey were used as priors to design the DCE choice tasks for the main DCE survey (Table 2). The Ngene software was run for around 24 hours; the S-estimate was 7.434. Results of the attribute level overlap and attribute level balance are presented in Table 3. There was a notable improvement in the attribute level overlap in the main DCE choice tasks compared to the DCE choice tasks used for the pilot survey. Of the 30 choice tasks, only cost to the patient (4/30), and wait time (4/30) had overlapping attribute levels. The three levels of the five attributes were almost equally distributed in both the choice tasks.
The main aim of this project was to design a DCE choice set that could elicit community preferences for health screening services for individuals with chronic diseases such as diabetes, cardiovascular and liver disease. The final set of attributes and levels for the DCE was based on a systematic review of the literature,7 qualitative interviews, a quantitative structured prioritisation exercise and an expert panel discussion.9 We followed a robust methodology to develop an efficient choice set that captures maximum information. The final choice set had 30 pair-wise choice tasks divided into three blocks, with minimum attribute level overlap and satisfactory attribute level balance.
Our study used the D-efficient criterion to design a fractional factorial design with 30 pair-wise choice tasks. The D-efficient criterion is probably the most common efficiency criterion in designing DCE choice tasks.25 The number of pair-wise choice tasks (rows) in the design depends on the number of parameters in the utility specification. The minimum number of pair-wise choice tasks (rows) of the DCE design equals to or greater than the number of parameters, not including constants, plus one.26 Our study had eight parameters, indicating that the minimum number of choice tasks would be nine. However, the number of choice tasks is often set to at least two or three times the minimum size to have sufficient degrees of freedom. Therefore, the use of 30 pair-wise choice tasks in the current DCE design would provide enough variation in the design matrix to estimate reliable parameter coefficients in the final DCE survey.
Our study used a heterogenous design, meaning each respondent responded only to a subset of the choice tasks. The choice set was divided into three blocks so that each respondent answered only ten choice tasks to reduce the burden on participants of answering all the choice tasks. Heterogeneous designs are generally considered better as they provide more information than homogenous designs.27 The number of choice tasks each respondent receives depends on the complexity of each choice task and how many the analysts believe a respondent can handle without fatigue. Mixed evidence exists as to the impact the number of choice tasks has empirically upon choice experiments. Hensher et al. suggested using 4 to 16 choice tasks28; however, few studies indicate that the number of choice tasks each respondent sees has the least influence on the error variance of choice data.29,30 Our DCE design had only five attributes, and an expert panel validated the attributes and the levels not to be mentally demanding when put into a choice set. Furthermore, based on the completion rate, the pre-test indicated that a respondent could handle ten choice tasks without any fatigue.
Efficient designs have the potential to select a subset of choice tasks from the full factorial design that yields more information, estimate smaller standard errors and increase the reliability of the parameter estimates.26 However, it is important to note that the efficiency of the design depends on the prior parameter estimates used in the model. If the priors are incorrect or close to actual behaviours, the design can become inefficient, leading to larger standard errors.31 Since no prior estimates were available in the literature, we conducted a pilot study to estimate the priors. This step has been recommended and could significantly improve the quality of the information in the final DCE survey through smart choice tasks with appropriate trade-offs across the attributes.22,32 This means that the final DCE survey designed in this study can potentially estimate reliable parameter estimates at smaller sample sizes. However, several systematic reviews which have reviewed DCE studies report that most studies either fail to report the source of the priors or use non-informative (zero) or conservative (close to zero) priors for the DCE design.7,33 This is a critical drawback as this limits the ability for critical appraisal and reproducibility of the survey. Furthermore, this leads to inefficient DCE designs that may require larger sample sizes to collect the same amount of information compared to a more efficient design.
The two DCE designs (for the pilot and the main study) developed in the study used constraints at the design stage to achieve attribute level balance, and the results indicate that the two designs achieved a satisfactory level of attribute balance. Imposing attribute balance constraints could have reduced the efficiency of the DCE design.26 However, some degree of attribute level balance in the design ensured that all parameter levels were represented. This would ensure that the parameter coefficients in the main DCE survey could be estimated well on the whole range of levels instead of having data points at only one or a few attribute levels.
We used fixed priors in the multinomial logit model to design the efficient fractional factorial design. Informative Bayesian priors have been proposed to produce more robust DCE designs against prior misspecification.34 However, this comes at a high computational cost and may not be feasible. Furthermore, it is common practice to design the DCE choice set using a fixed priors, and evidence indicates that this method works well even for estimating parameter coefficients of a panel mixed logit model.35
We followed a robust methodology to design a DCE choice set that could elicit community preferences for health screening services. The final DCE design had 30 pair-wise choice tasks and demonstrated satisfactory efficiency that will capture maximum information and best inform policy.
Ethics approval for this study was granted by the Queensland University of Technology Human Research Ethics Committee (QUT HREC), with reference number HREC/QUT/4282, on 02/08/2021. The study was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki, ensuring the protection of participants’ rights, safety, and well-being throughout the research process.
Informed consent was obtained from all participants before their involvement in the study. On the first page of the online survey, participants were required to review the participant information sheet detailing the study’s purpose, procedures, potential risks, and benefits. Participants indicated their intention to participate by clicking “Agree” or opted not to participate by clicking “Not Agree” in the online consent form. Only those who selected “Agree” were redirected to the survey tool. Due to the nature of the online recruitment method, consent was collected electronically rather than through written signatures. This approach was approved by the Queensland University of Technology Human Research Ethics Committee (reference number HREC/QUT/4282). The ethics committee deemed this method appropriate as participants were provided with sufficient information to make an informed decision and had the opportunity to review the participant information sheet in full before providing their consent.
SK, SS, AB, and DB contributed to the design of the study, coordinated the collection of data, analysed the data, and drafted the manuscript. MA, EEP, JO’B, PV, and IH contributed to the development of the data analysis plan, interpretation of the results, and review of the manuscript. All authors have read and approved the final version of the manuscript.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)