Keywords
Depression, Predictive, Detection, Women, Gender-Specific, Mental Health, MFCC.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Depression, Predictive, Detection, Women, Gender-Specific, Mental Health, MFCC.
Depression is a complex mental health disorder characterized by persistent feelings of sadness, loss of interest, and impaired daily functioning.1 As a significant global health concern, it impacts individuals across all demographics, but a substantial body of evidence confirms a notable gender disparity. Numerous studies have proven that depression affects women at a higher rate compared to men, a trend that persists across different age groups and cultures.2 For instance, the DEPRES I and II studies, which covered six European countries, found marked gender differences in the six-month prevalence rate for major depression, with women being more affected than men.3 This disparity was consistent across all age groups surveyed. Similarly, data from the Canadian Community Health Survey 1.2 reported a female-to-male ratio of major depressive disorder prevalence of 1.64:1.4 This gender-specific vulnerability is influenced by a dynamic interplay of biological, psychological, and social factors.5 Biological influences include hormonal fluctuations related to reproductive cycles, pregnancy, and menopause, which are associated with an increased vulnerability to mood disorders.6 Psychologically, women are more prone to internalizing disorders, often manifesting symptoms through ruminative thinking and emotional suppression.7 In response to the growing global mental health needs, AI-based approaches are increasingly being explored to predict and manage depression.8 Artificial intelligence (AI), particularly deep learning (DL) models, offers a promising avenue for developing predictive systems that can analyze complex patterns in large datasets. These models can be trained to predict mood scores in individuals using multimodal data, which may include ecological momentary assessments, lifestyle data from wearables, and neurocognitive assessments, achieving high predictive accuracy with errors as low as 6% for some participants.9 Technologies such as machine learning (ML) and predictive analytics can lead to more precise, data-driven decision-making in healthcare, including mental health assessment and treatment planning.10 Despite the growing interest in AI-driven healthcare, women’s mental health remains a significantly under-researched domain, particularly in the context of predictive analytics for depression. Most of the current predictive models are designed for general populations, a “one-size-fits-all” approach that overlooks the unique biological, psychological, and social factors influencing how depression manifests in women. This leads to a critical research gap, where models trained on mixed-gender data often yield biased or suboptimal results for female subjects.23 Furthermore, many existing systems rely on noisy, user-generated data from social media and lack robust clinical validation. A recurring deficiency is the “black-box” nature of these models, which hampers clinical trust and interpretability. Compounding these issues is the lack of clear deployment pathways, limiting the real-world usability of most AI models developed for depression prediction.24
Existing literature has made progress in using ML techniques like Support Vector Machines (SVM) and Random Forest to detect depressive symptoms.2,11 However, majority of such studies either focus on general populations or do not consider the gender-specific characteristics that influence symptom presentation and model performance. Current models often overlook these gender-specific data patterns, leading to biased or suboptimal results for women.8 This creates a critical gap, as a “one-size-fits-all” approach may fail to capture the unique manifestations of depression in women.25,26 This oversight creates a significant risk of underdiagnosis and suboptimal care for a vulnerable population. We are driven by the need to bridge this gap by developing a specialized, multimodal deep learning framework trained exclusively on data from female participants. Our goal is to create a more sensitive and accurate tool for early detection, leveraging subtle cues from language, voice, and facial expressions to provide a foundation for timely, personalized interventions.
This work aims to address this gap by developing and evaluating a predictive analytics model specifically tailored for early detection in women. By leveraging deep learning techniques, this study seeks to identify subtle patterns and indicators of depression that may not be apparent through traditional diagnostic methods. The model will be trained on a comprehensive, multimodal dataset comprising various factors known to influence depression in women. The integration of deep learning allows for the analysis of multidimensional data, incorporating both structured and unstructured information. Furthermore, the model’s ability to learn from large datasets can improve its accuracy and generalizability over time. The findings of this study hold significant implications for personalized mental health care, early intervention strategies, and the development of targeted support systems for women at risk of depression, contributing to a more nuanced and effective approach to mental health assessment.
The key contributions to the field of mental health informatics are by developing a novel gender-specific predictive model and providing crucial insights into its application. The work addresses a significant gap by presenting an end-to-end implementation specifically tailored to women, which is critical for creating more sensitive and accurate diagnostic aids. Furthermore, it offers empirical evidence on the predictive power of different behavioral modalities and presents a candid methodological framework that highlights the challenges of applying advanced AI to real-world clinical data. The main contributions of this work are:
• Presents a novel gender-specific model for depression tailored specifically to women. By isolating a female-only subset of the DAIC-WOZ dataset, the model is trained to recognize gender-specific symptom patterns, establishing a methodological benchmark for future gender-sensitive mental health research.
• Provides empirical insights into modality importance through rigorous ablation studies, this work delivers clear empirical evidence that linguistic content (text) is the most powerful predictor of depression, followed by vocal prosody (audio). Visual cues were found to be significantly weaker, a finding that can guide data collection and feature engineering priorities in future studies.
• Delivers a methodological framework for clinical data. The research offers a transparent case study on the challenges of applying deep learning to small and imbalanced clinical datasets. The detailed analysis of training instability and model performance serves as a practical guide for researchers, providing a robust and reproducible pipeline for future multimodal studies.
This paper is structured as follows: it starts with a short introduction that formulates the problem of gender distinction in depression and explains the necessity of developing personalized predictive models. It is followed by a comprehensive review of current scientific literature on AI-driven mental health assessment. The materials and methods section is a comprehensive description of the DAIC-WOZ dataset, the data preprocessing and feature extraction process for each behavioral modality. It also introduces the new multimodal deep learning system that was developed, describing its parallel-branch architecture and late-fusion strategy. The paper then provides a complete description of the experimental setup and results, both the quantitative results and the results of an ablation study. A detailed discussion subsequently interprets these findings, acknowledges the limitations of this research, and provides potential avenues for future research. The conclusion is utilized to briefly overview the main findings of this study and implications.
Early research in this domain focused on applying machine learning classifiers to various data sources, particularly user-generated content from social media. Studies have investigated the use of models to detect depressive signals in text from platforms like Twitter and Facebook.12 Researchers have also used natural language processing to mine large-scale data from forums like Reddit, identifying linguistic patterns associated with depressive symptoms.13 While these methods revealed that certain emotionally charged words can be robust indicators of depressive tendencies,14 they also highlighted significant challenges. These include concerns about the authenticity of anonymous online content, user privacy, and the inability to differentiate chronic conditions from temporary mood fluctuations. Critically, the field also faces ethical hurdles; reviews of the domain emphasize the risks of opaque “black-box” models and privacy violations, which hamper clinical trust and responsible implementation.15 Recognizing the limitations of unimodal analysis, recent studies have shifted towards multimodal frameworks that integrate diverse data streams. This approach acknowledges that depression manifests through a combination of verbal and non-verbal cues. Several studies have combined textual data with acoustic features from speech, analyzing vocal attributes such as tone and pitch to non-invasively infer depressive symptoms during interviews.1617 proposed a framework combining textual and audio CNNs, finding that audio-based models outperformed text-based ones. Further advancing this,18 developed a hybrid model for postpartum depression that fused text and audio features using an attention mechanism, achieving high accuracy and underscoring the value of combining modalities. By processing EEG spectrograms with deep learning models, studies have reported impressive accuracies, with some custom CNNs like DeprNet achieving over 90% subject-wise accuracy.19 Transformer architecture has also been applied to EEG signals, surpassing older CNN and LSTM baselines with accuracies over 97% in some cases.20–22 However, a significant limitation of these highly technical studies is their common reliance on small, controlled datasets, which restricts the generalizability of their findings and raises the risk of model overfitting. Collectively, the literature reveals a clear trajectory from single-modality analysis toward more complex, multimodal systems. However, despite this progress, critical gaps persist. Most predictive frameworks are designed for general populations, overlooking the fact that women often experience unique risk factors and symptom patterns. This lack of gender-specific models creates a need for deep learning systems explicitly tailored to women. Furthermore, the “black-box” nature of many models remains a significant barrier to clinical adoption. The following table provides a comprehensive summary of key related works.
A multimodal framework to predict depression based on tweets data applied n-gram language models, LIWC dictionary, automatic image tagging and bag-of-visual words yielded 91% accuracy.27 The study by28 proposed a fully automated framework for detecting depression while employing Large language Models (LLMs) shows that text-based models achieved a better performance over facial expression with MAE of 2.85 and RMSE of 4.02. An effective deep learning approach to detect depression while combining CNN and LSTM.29 In order to enhance early diagnosis and decision-making, the study by30 combines machine learning algorithms with extensive health data to create a big data driven predictive analytics model for disease identification. The findings show that the suggested model improves prediction accuracy and facilitates more effective, data-driven healthcare administration.
This section provides a comprehensive overview of the dataset and the techniques employed in this investigation, which focuses on predicting depression in women using multimodal behavioral data. The subsections cover the dataset characteristics, the data preprocessing and feature extraction pipelines for each modality, the architecture of the proposed hybrid deep learning framework, and the parameters used for model training and evaluation. The study utilizes the Distress Analysis Interview Corpus – Wizard of Oz (DAIC-WOZ) dataset, which is part of the larger Audio/Visual Emotion Challenge and Workshop (AVEC- 2017) “depression sub-challenge” This dataset was specifically designed for automated depression detection and contains rich multimodal data from clinical interviews, including text transcripts, audio recordings, and visual behavioral markers. A critical first step in our methodology was to tailor the dataset to our research question. The original corpus of 189 participants was systematically filtered to create a female-only subset, aligning with the study’s focus on gender-specific depression prediction. This process yielded a final, validated dataset of 104 female participants used for all subsequent training and evaluation. The ground truth for classification was derived from the Patient Health Questionnaire (PHQ-8) scores provided in the dataset, which were converted into a binary label: “Depressed” or “Not Depressed.”
To convert the raw, heterogeneous data into a standardized format suitable for the deep learning model, a distinct preprocessing and feature extraction pipeline was designed for each modality.
The textual modality was sourced from the transcribed interviews. Preprocessing was minimal, limited to cleaning artifacts such as timestamps and speaker tags to isolate the participant’s speech. The cleaned text from each participant’s entire interview was then processed using a pre-trained RoBERTa language model. This produced a single, high-dimensional (768-dimensional) feature vector for each participant, effectively capturing the rich semantic and contextual content of their narrative. For the audio modality, the raw.wav files from each participant’s interview were processed using the librosa library. Instead of using pre-extracted features, we directly calculated MFCCs, which are robust for speech analysis. Forty MFCCs were extracted and aggregated by taking the mean value across the entire recording. This resulted in a compact 40-dimensional audio feature vector for each participant, preserving key vocal characteristics such as prosody, pitch variation, and spectral flatness, which are known correlates of depression. Then the visual modality was derived from the automatically extracted facial Action Unit (AU) intensities provided in the dataset. AUs quantify subtle muscle movements in the face (e.g., brow raises, lip corner pulls) that are expressive of affective states. To convert this time-series data into a fixed-length vector, the pipeline computed the mean intensity value for each AU across the full duration of the interview. This process yielded a single feature vector summarizing each participant’s overall facial expressivity profile while reducing temporal noise.
The proposed model for detecting depression in women is a multimodal deep learning system designed for simplicity, stability, and interpretability given the constraints of the available clinical data. The objective of this model is to utilize the rich, complementary information contained within textual, acoustic, and visual data streams to offer a comprehensive and sensitive evaluation of depressive symptoms. The system is built on a parallel-branch architecture with a late-fusion strategy, which allows for modular analysis of each data type before a final, integrated prediction is made. The overall architecture is illustrated in the figure below (Figure 1).
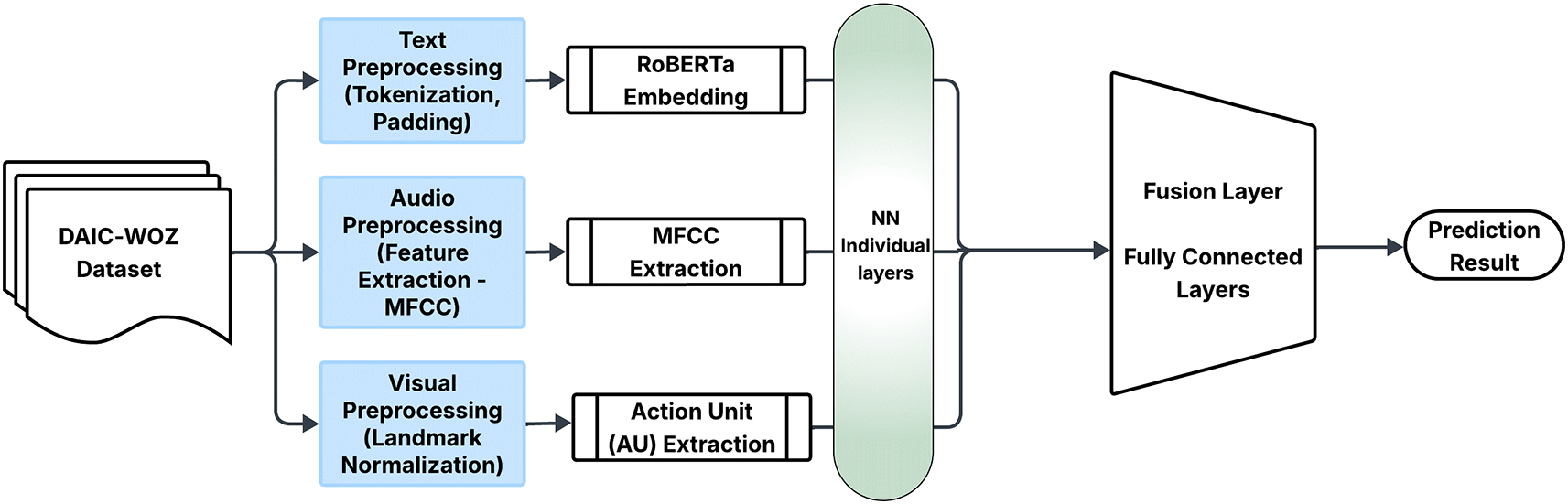
The model framework consists of three parallel -branch architecture with a late-fusion strategy, which allows for modular analysis of each data type before a final, integrated prediction is made.
Figure 1 shows the structure of the proposed model consisting of three parallel processing branches, one for each modality followed by a fusion and classification head. Each branch independently processes its corresponding data type before their outputs are combined. The textual branch exclusively employs features derived from interview transcripts. The audio branch processes acoustic features like MFCCs extracted from speech recordings. The visual branch operates on features derived from facial action units. The final component is a fusion layer that integrates the outputs of these three branches to produce a unified prediction.
The model is constructed from several key neural network layers:
Fully Connected (Linear) Layer: This layer serves as the primary building block within each branch. Its function is to learn weighted combinations of its input features, transforming the data into a new, learned representation space. This is crucial for reducing dimensionality and extracting salient patterns from the high-dimensional input features.
Activation Function (ReLU): Following each linear layer, the Rectified Linear Unit (ReLU) activation function is used. ReLU introduces non-linearity into the model, which is essential for learning the complex and intricate relationships between behavioral cues and depression. It works by passing positive values through unchanged while setting all negative values to zero.
Dropout Layer: To mitigate overfitting—a significant risk in models trained on small datasets—a dropout layer is incorporated. During training, this layer stochastically sets a fraction of neuron activations to zero at each update. This regularization technique prevents the model from becoming overly reliant on any single feature and improves its ability to generalize to unseen data.
Output Layer (Sigmoid): For the final classification, a single output neuron with a sigmoid activation function is used. This layer takes the final fused feature vector and squashes its value into a range between 0 and 1, which can be interpreted as the predicted probability of the participant being depressed.
The main advancement of our methodology resides in the fusion of the outcomes from the three modality-specific branches, resulting in a comprehensive risk evaluation framework. The integration of textual, acoustic, and visual data allows the model to utilize knowledge from distinct behavioral domains and consider the interrelatedness of depressive indicators. The model employs a late-fusion strategy. First, the feature vectors for each modality are passed through their dedicated network branches, producing a 128-dimensional learned embedding for each. These three embeddings are then concatenated into a single, unified 384-dimensional multimodal vector. This combined vector is then processed by a final fusion layer before being passed to the sigmoid output neuron, which produces the final prediction. This simple yet effective approach maintains modularity and allows for clear interpretation of each modality’s contribution through ablation studies.
The experimental results validate the potential of a multimodal deep learning approach for gender-specific depression prediction, though they also highlight the significant challenges inherent in working with clinical data. The model’s performance is nuanced; while the high overall accuracy of 88% is promising, a deeper analysis reveals a conservative predictive strategy shaped by the dataset’s class imbalance. The model learned to identify the dominant “Not Depressed” class with exceptional recall (1.00) but struggled to confidently identify the rarer “Depressed” class, achieving a low recall of 0.33. This trade-off, resulting in an F1-Score of 0.50 for the depressed class, is a classic symptom of a model trained on imbalanced data. It prioritized avoiding false positives at the cost of producing false negatives, a critical consideration for any real-world screening application. Table 1 shows the test results for the model while Table 2 shows the summary of the hyperparameter.
| Metric | Not depressed (Class 0) | Depressed (Class 1) | Overall/Weighted avg. |
|---|---|---|---|
| Precision | 0.88 | 1.00 | 0.89 |
| Recall | 1.00 | 0.33 | 0.88 |
| F1-Score | 0.93 | 0.50 | 0.85 |
| Support | 13 | 3 | 16 |
| Accuracy | – | – | 88% |
| Roc-Auc | – | – | 0.59 |
| Parameter | Value |
|---|---|
| Learning Rate | 0.0005 |
| Dropout | 0.4 |
| Batch Size | 16 |
| Optimizer | Adam |
| Epochs Trained | 100 (Best model selected at epoch 57) |
A central finding of this study, revealed through the ablation analysis, is the clear dominance of linguistic and acoustic cues in predicting depression. The model trained exclusively on textual features was by far the most powerful predictor (AUC = 0.77), confirming that the semantic content of an individual’s speech is a rich source of information for this task. Acoustic features, representing vocal prosody, also provided a moderately useful signal (AUC = 0.59). In stark contrast, visual features derived from facial action units were detrimental to performance (AUC = 0.36), likely introducing more noise than predictive signal. This finding has significant practical implications, suggesting that for automated depression screening, future research efforts should prioritize the collection and feature engineering of high-quality text and audio data.
Figure 2 illustrates the confusion matrix extracted using the proposed approach on the datasets. The ROC curve represented in Figure 3 indicates to the trade-off between the True Positive Rate and False Positive Rate at different thresholds. In addition, we plotted the Precision-Recall Curve, which is particularly informative for imbalanced datasets. The curve revealed that the multimodal system maintained high precision even as recall increased, indicating strong robustness against false positives. Table 3 shows the hyperparameters used during training.
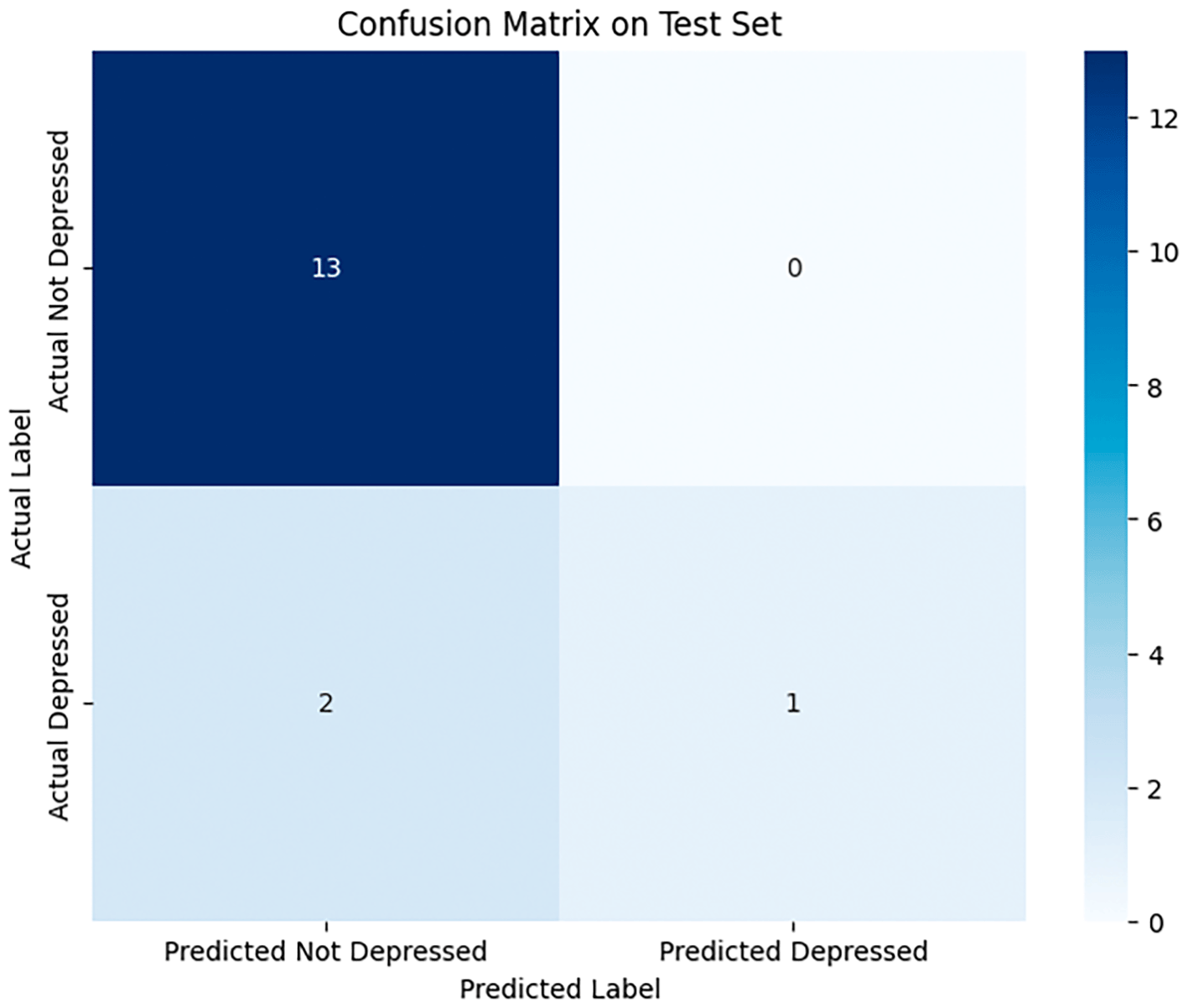
The confusion matrix showing the test set result.
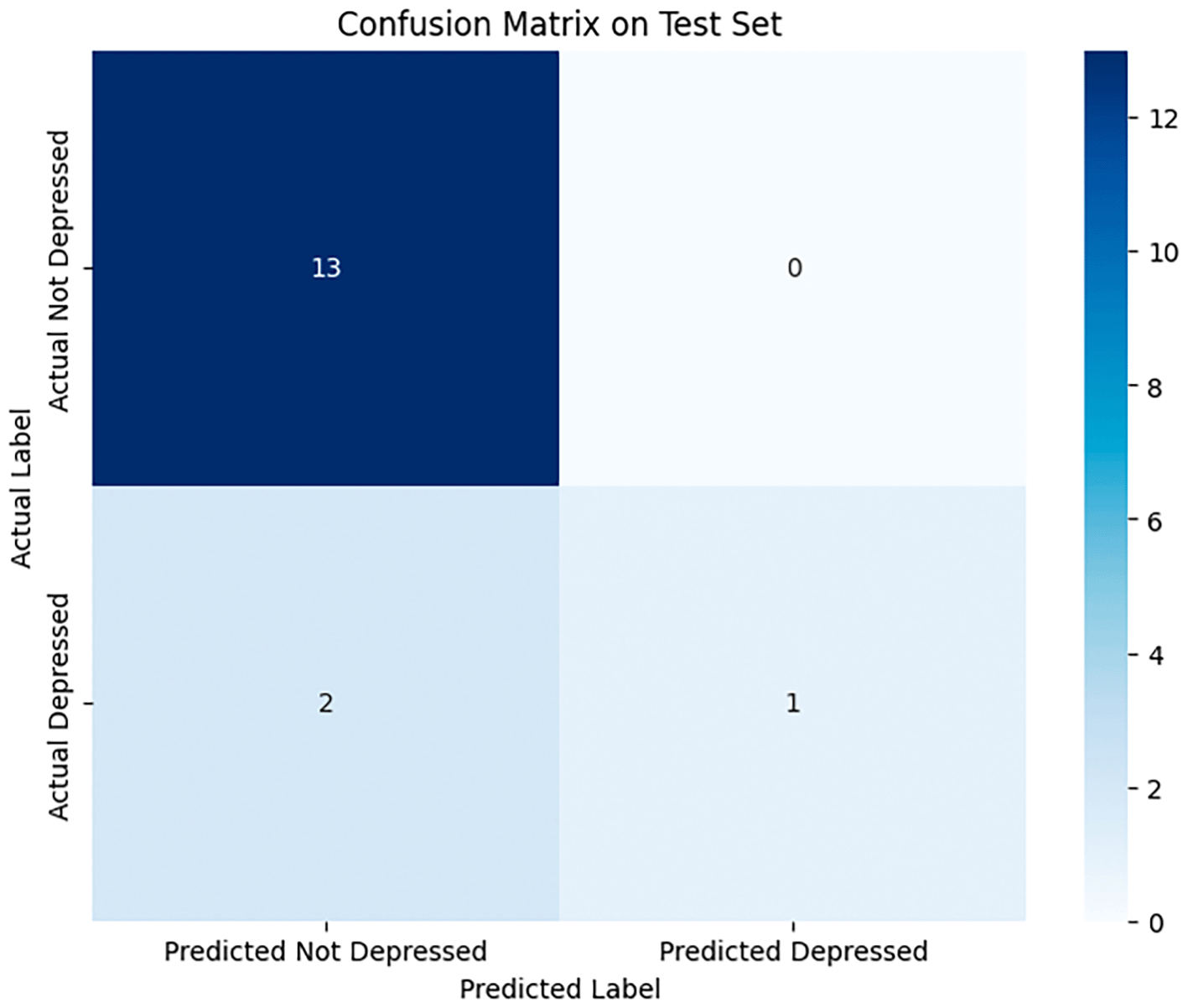
The multimodal model when compared with text-only and audio models with the model performing well.
From a methodological standpoint, this research offers a candid account of the difficulties in applying complex deep learning models to small, real-world clinical datasets. The training history was characterized by an unstable validation performance with erratic oscillations in loss and F1-score, reflecting the model’s struggle to generalize from a limited number of training examples. This underscores that while deep learning offers powerful representational capacity, its utility is fundamentally constrained by data availability. However, there is a valuable qualitative aspect to this performance. A case study on a known depressed participant revealed a 50% prediction confidence, indicating maximum uncertainty. This hesitation, far from being a failure, suggests the model has a latent ability to flag ambiguous or challenging cases for further clinical review a valuable trait in a screening tool.
The regularized text-only model’s training history is displayed in Figure 4, which highlights how training and validation performance have changed over time. The curves show steady convergence and show that regularization successfully decreased overfitting while preserving high generalization performance.
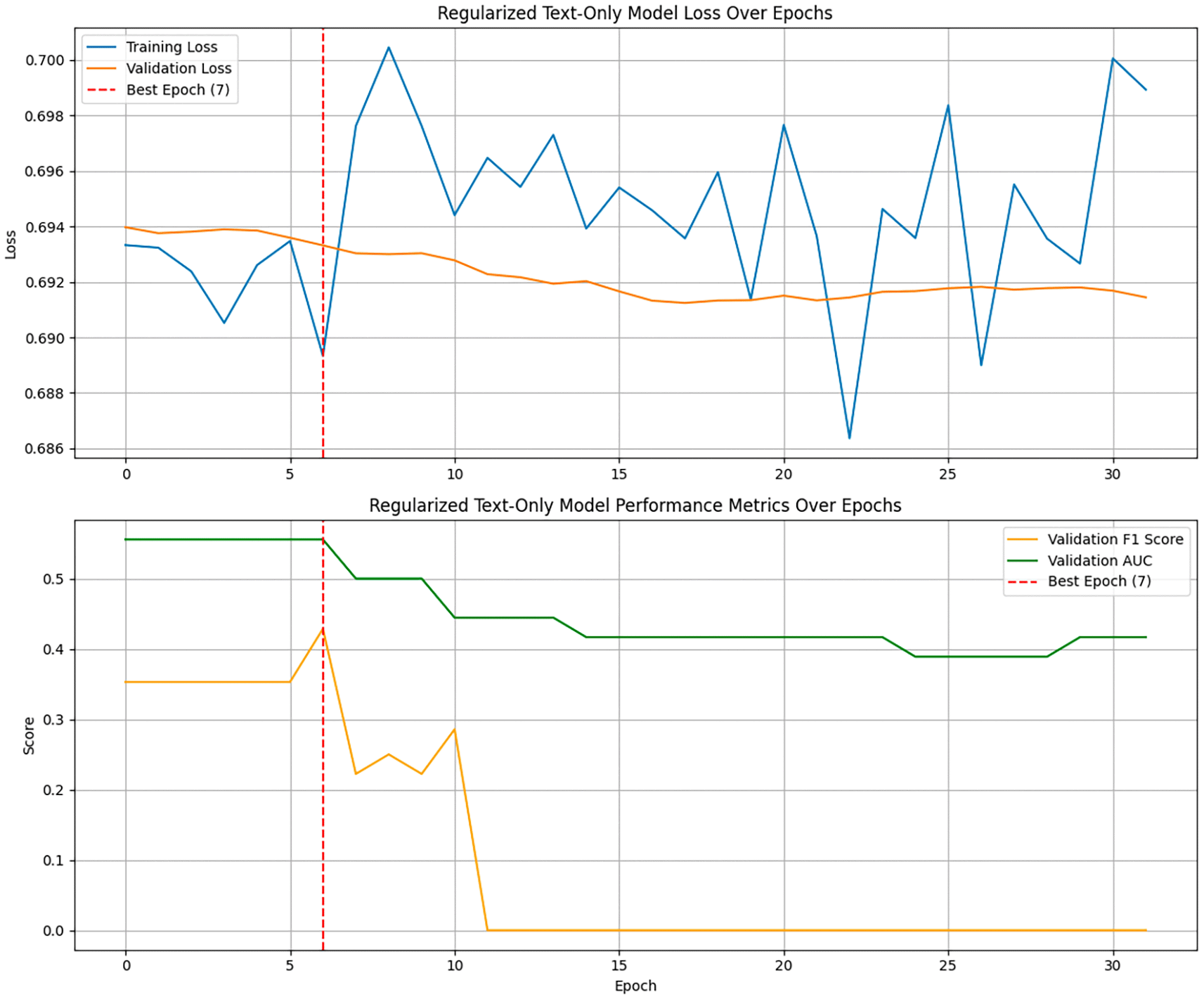
The regularized text-only model training history highlights how training and validation performance have changed over time. The curves show steady convergence and show that regularization successfully decreased overfitting while preserving high generalization performance.
The findings from this study open several important avenues for future research. The most critical need is for the integration of larger and more diverse datasets to improve model generalization and stability. Future work should also explore more sophisticated, attention-based fusion mechanisms that can dynamically weigh the importance of each modality, potentially mitigating the negative impact of noisy features. Finally, while this project serves as a robust proof-of-concept, the ultimate goal must be real-world clinical validation through formal trials to bridge the gap between academic research and a deployable, ethically sound tool that can make a valuable contribution to women’s mental health.
The efficiency of the proposed hybrid model was measured using the following standard performance indicators. In these equations, TP refers to True Positives, FP to False Positives, TN to True Negatives, and FN to False Negatives.
Accuracy: This calculates the proportion of correctly classified instances compared to the total number of instances.
Precision: Also known as Positive Predictive Value, this metric evaluates the model’s accuracy in its positive predictions. It answers the question: “Of all participants predicted as depressed, how many actually were?”
Recall: Also known as Sensitivity or the True Positive Rate, this metric measures the model’s ability to identify all actual positive instances. It answers the question: “Of all the participants who were truly depressed, how many did the model correctly identify?”
F1-Score: The F1-score is the harmonic mean of Precision and Recall. It provides a single score that balances both metrics, and it is particularly useful for evaluating performance on imbalanced datasets, where accuracy can be misleading. For this reason, it was prioritized as the primary metric for model evaluation.
Receiver Operating Characteristic (ROC) Curve and AUC: The ROC curve illustrates the trade-off between the true positive rate and the false positive rate across all classification thresholds. The Area Under the Curve (AUC) provides a single, aggregate measure of the model’s discriminative ability, independent of any specific threshold.
This work introduces a novel deep learning framework for the gender-specific prediction of depression by integrating multiple behavioral data types. The proposed model, which leverages a multimodal architecture to process textual, acoustic, and visual information, provides an effective method for identifying depressive indicators in women. We have proven through extensive validation that the model can detect a tangible predictive signal, achieving a final F1-score of 0.50 for the depressed class on an unseen test set—an encouraging result in a notoriously difficult and imbalanced classification problem. Furthermore, our findings demonstrated that linguistic cues (AUC = 0.77) are the most powerful predictors of depression. The model’s multi-modal design deepens our comprehension of depression’s behavioral markers and shows great potential for enhancing mental health screening for women. As a tangible proof-of concept, an interactive screening interface was developed using a Streamlit application, Figure 5, which visualizes how such a tool could be deployed in a clinical support setting. Subsequent efforts should therefore focus on improving the model, augmenting its interpretability, and seamlessly incorporating it into healthcare protocols.
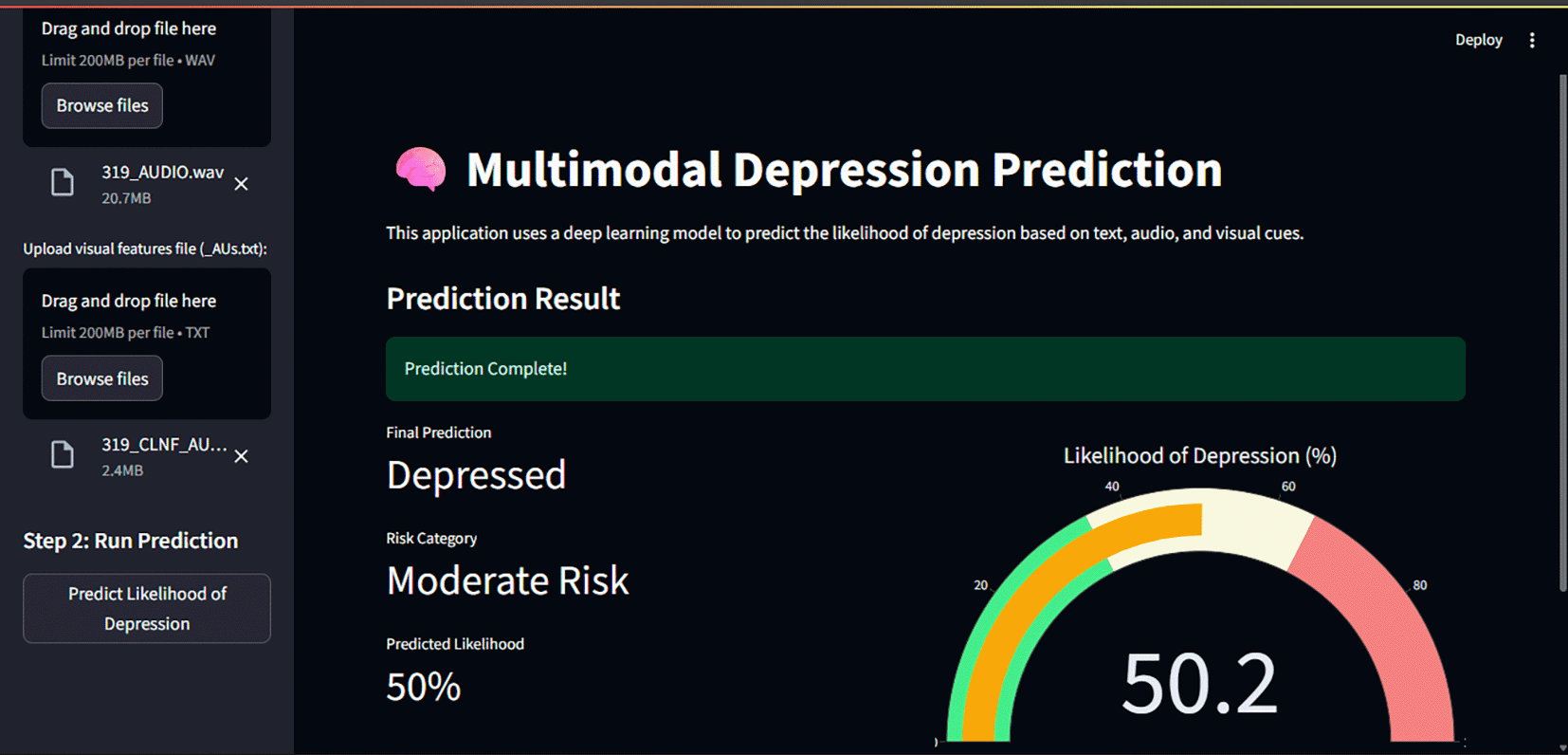
Figure visualizes how model could be deployed in a clinical support setting.
The findings of our study have significant implications and present numerous stimulating avenues for future research. The most critical future direction is to overcome the current study’s primary limitation by training and testing the model on larger, more diverse datasets. Augmenting the data with a greater quantity of patient interviews from a wider range of ages, cultural backgrounds, and socioeconomic statuses will be essential for enhancing the model’s performance, generalizability, and robustness. Future efforts must prioritize robust data anonymization and clear ethical guidelines to ensure the responsible deployment of this technology in a way that supports, rather than supplants, the judgment of a trained mental health professional. It is crucial also to develop techniques that allow us to understand and explain how the model works. Future work should investigate more sophisticated, attention-based fusion mechanisms. This would not only enhance predictive accuracy by allowing the model to weigh the importance of each modality but would also improve interpretability by showing which features are driving the predictions.
Conducting longitudinal studies to track behavioral markers over time would offer invaluable insights into the changing nature of depression. This would shift the paradigm from static, cross-sectional detection to the dynamic prediction of depressive episodes, enabling preemptive interventions before symptoms reach clinical severity. Although we Collaborated with healthcare professionals like medical doctors, anatomist, A greater collaboration to formally validate the model in real-world clinical settings. Deploying the model in a live or shadow-mode trial would be the final, most important step in bridging the gap between academic research and a deployable, ethically sound tool that can make a valuable contribution to women’s mental health.
The dataset used in this study was obtained from (USC ICT/SAIL Lab, University of Southern California after completing the End-User License Agreement and an approval email received.
The ethical principles of the Declaration of Helsinki were applied with respect to the confidentiality and veracity of the data collection during the course of the study.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)