Keywords
Fraud Detection; Machine Learning; AI; Accounting.
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Fraud Detection; Machine Learning; AI; Accounting.
The increase in possibilities for digitized financial systems has opened up efficiencies and garnered waves for numerous organizations but offers new ways of fraud in the process.1 Available evidence suggests that enterprises across the world suffer about $5.1 trillion losses through financial fraud, and accounting fraud is a primary contributor.1 Current conventional measures that embrace auditing techniques and misconceptions in business have been inadequate for the detection of sophisticated fraudulent practices in organizations that take advantage of flexible fiscal environments. Information technology, such as artificial intelligence, machine learning, and big data analytics, has become an enabling technology for enhancing fraud detection in accounting systems.2 These technological solutions facilitate the assessment process of transactions and enable the detection of statistically aberrant or presumptively fraudulent exchanges. However, AI has the ability to continue learning from new data and enhance detection effectiveness in connection with new forms of scams. According to the work in3: Machine learning algorithms are useful in that they can handle multiple values simultaneously to determine various fraud factors that cannot be detected by conventional approaches. This study aims to develop an integrated system where three different classification algorithms (Decision Tree, Random Forest, and Neural Network) are used to reduce the rate of false positives and improve the detection of fraudulent transactions in accounting systems. Advanced technologies, including artificial intelligence, machine learning, and big data analytics, have emerged as powerful tools for revolutionizing fraud-detection capabilities within accounting systems. These technologies enable the analysis of vast transaction datasets, identification of subtle anomalies, and recognition of complex patterns that may indicate fraudulent activity. AI-powered systems can continuously learn from new data, adapt to evolving fraud techniques, and improve the detection accuracy over time. As noted in,3 machine-learning algorithms can process multivariate data points simultaneously, allowing for the identification of fraud indicators that would remain invisible to traditional detection methods. Digital transformation has fundamentally revolutionized the financial sector, driving unprecedented changes in how organizations conduct business and manage risk. This transformation encompasses the integration of cloud computing, artificial intelligence, and advanced analytics into core business processes.4 Traditional methods of fraud detection, primarily relying on auditing procedures and rule-based systems, have proven insufficient in identifying sophisticated fraudulent schemes that exploit the complexities of modern financial ecosystems.
In this study, the subject adapts and assesses an innovation that entails the use of several machine-learning models in a consolidated framework to detect fraud in accounting systems. In this context, decision trees, random forests, and neural networks were compared for transaction fraud detection, establishing an optimal approach for various scenarios. Finally, the evaluation approach also includes a deep analysis of each model, with a specific focus on accuracy, F1-score, and recall rates, as well as a confusion matrix to capture more information that may be missing in other evaluation metrics. Thus, the basis of fraud-fighting strategies is developed in this study, which is applied to the resolution of efficiency in loss reduction that increased from poor accounting practices while maintaining operational efficiency in the processes of accounting.
This paper is composed of several sections. Section Two is dedicated to related research. Section Three proposes the model and Section Four provides the dataset description. Section Five contains the results and discussion, and Section Six concludes the paper.
The new and enhanced technique of an artificial intelligence-based approach has shown higher effectiveness for fraud detection than the earlier methodologies. It is beneficial to mention that several studies have developed this direction as highly valuable for the rapidly growing field: an approach for detecting accounting fraud in financial statements was proposed by Zhang et al. (2023)5 based on deep learning. Their model combined explicit use of NLP to work with textual information and with numeric data, and the mean accuracy of the results was 91.7%. They showed that incorporating both qualitative and quantitative variables further improved the prediction power compared to models employing only financial data. Our work extends this idea further and applies a genuinely comparative approach for multiple models using a tailored algorithm assignment.
Li and Johnson (2022)6 propose a real-time fraud detection system for banking transactions using ensemble learning techniques. Their system was developed from random forest and gradient boosting regression trees to analyze transactional patterns; it obtained a detection rate of 89.3 percent with a false positive rate of 2.1 percent. The authors also focused on the fact that feature engineering is critical for addressing the problem and dealing with minor fraud hints. The proposed system extends these works by adding more complex architectures of neural networks and simultaneously providing benefits from ensemble methods.
Patel et al. (2022)7 focused on explainable AI in fraud detection systems in accounting processes. They argued that active and passive reasoning for a fraud type helped enhance the trust of clients and the overall usage of a system in the financial frat. A high degree of concern is on interpretability, which comes at the cost of a slightly lower accuracy of 93.5%; however, a decision tree can be interpreted by rule extraction. This work is expanded further by comparing both Decision Trees, which are very interpretable models, and Neural Networks, which have the potential to achieve better accuracy.
Rodriguez and Kim (2023)8 presented an analysis of how graph neural networks can be used to detect multiple entity and transaction fraud schemes. Their approach was to use the graph structure to represent the patterns of the financial transactions; thus, it became easy to detect fraud across the various interrelated accounts with an efficiency of 94.2%. This was an increase of 15.3% as compared to the conventional styles. The system proposed in this study aligns with this strategy by aiming at transaction-level and accommodative detectors that can be incorporated into graph-based systems.
Wang et al. (2023)9 adopted a federated learning method for fraud detection to ensure that no sensitive data were shared among themselves, yet the financial institutions would gain from the collective model training. Their system opened to a 92.8% detection rate, without subjecting any transaction information to the outside world. Although, as stated earlier, our work does not address privacy issues or design, it can be shown that the evaluated models are compatible with federated architectures.
Alharbi and Matthews (2022)10 conducted a detailed study and comparison of credit card fraud detection using ten different algorithms, such as random forest, support vector machine, and neural networks. Their research showed that the majority of ensemble learning methods are superior to individual learners, even though the highest accuracy stood at 95.7% only when using an optimal combination of the learners. The highlighted case continues by applying a comparative approach in the accounting domain, which is less similar to credit card systems in terms of transaction patterns and fraud indicators.
Chen and Davis (2023)4 put together an inventive fraud detection system that revised its model with reference to fraud analysts’ feedback. This approach minimized the false positive rate by 42% to other static models, while retaining equal detection percentage, which was 93.1%. Confounding the aforementioned facts, the researchers also pointed out that the actual deployment of fraud-detection systems requires people in the loop or working with people.
Therefore, this study introduces several benefits in contrast to these previous studies. First, these three machine-learning algorithms—Decision Trees, Random Forests, and Neural Networks—are widely used in accounting fraud detection, but they differ significantly in their structure and complexity. Random Forests is an ensemble extension of decision trees, whereas neural networks represent a completely different, often more complex, paradigm. A 99.19% accuracy rate achieved by the Neural Network model demonstrates a significant improvement over previous system. Furthermore, a detailed confusion matrix analysis is essential for understanding the effectiveness and identifying areas for enhancement in each model, ultimately helping financial institutions operationalize a superior, refined system.
The findings presented in this paper outline a comparison-based approach using multiple artificial intelligence models to detect fraud in accounting systems. It comprises the following four steps: the dataset source,11 preprocessing of the dataset, and ML phasing (training and testing), as shown in Figure 1.
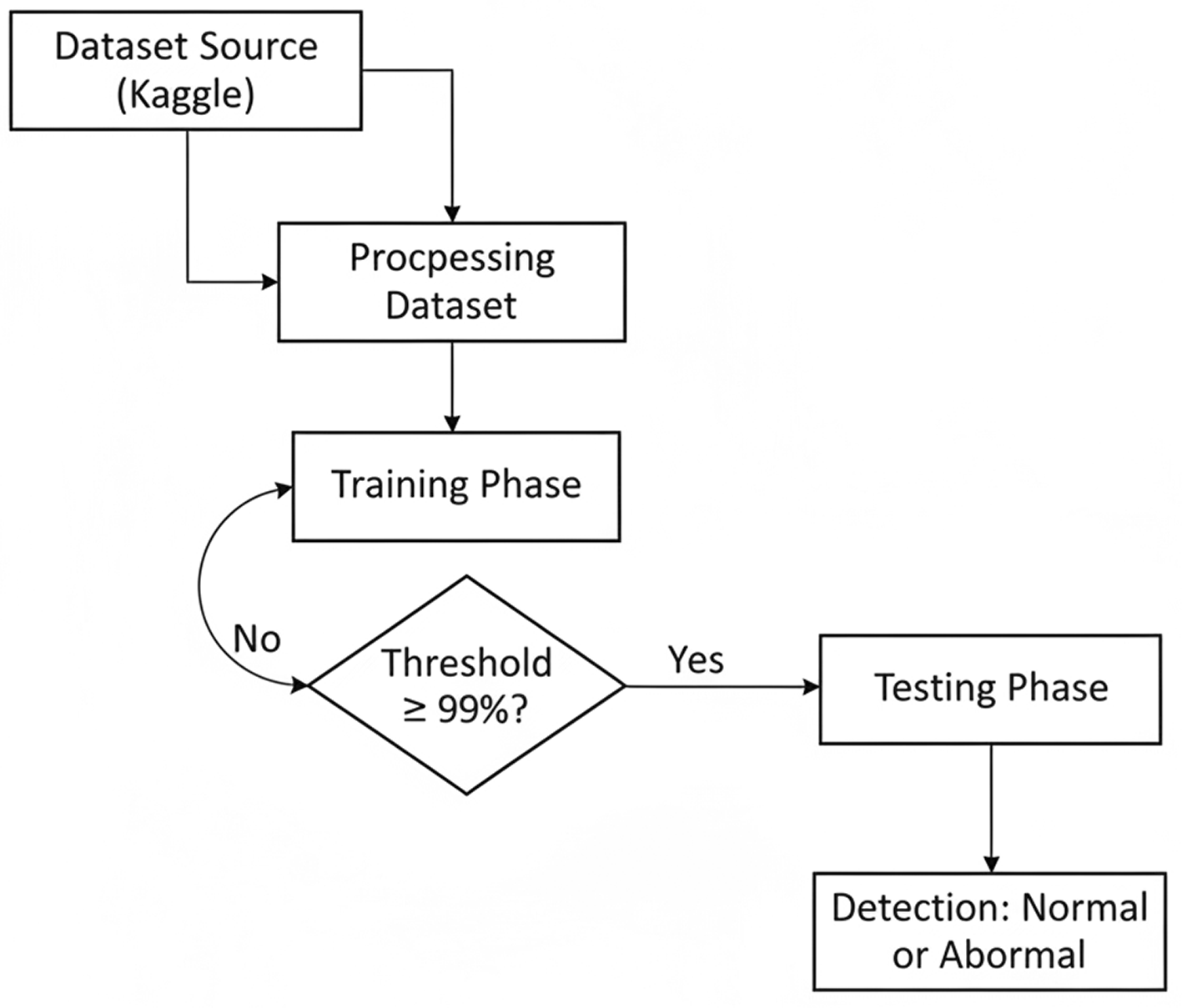
Figure 1 shows the block diagram of the proposed system. It consists of four phases: dataset source, preprocessing, training, and testing.
The following data preprocessing techniques will then be employed, depending on the nature of the financial data acquired: handling missing data, outlier treatment, and Data Balancing/over-sampling.
X is the original value.
• xmin: is the minimum of the values in the provided data.
• xmix: There is no upper limit, and the highest value is present in the dataset.
• X′: is the normalized value.
It is a component that performs preparatory work on the transaction data that needs to be analyzed, namely,
1. Pre-processing: Procedures to handle missing data, outliers, and to remove duplicates that may be contained in the dataset.
2. Preprocessing: Normalization of numerical data to make the values within a reasonable range, use of the one-hot method on categorical data, and extraction of time features extracted from transaction time stamps.
3. Data Balancing: To handle a natural tendency that involves handling a small percentage of fraudulent transactions in the total number of possible transactions, we implement a synthetic minority oversampling technique.
The evaluation component also includes the assessment of the model, which has several aspects of performance metrics.
1. Accuracy: This is the total proportion of the transactions correctly categorized out of the total ones conducted in the datasets.
2. F1-Score: Precision and recall are calculated as the arithmetic mean of their values, which offers medium accuracy of the model.
3. Error Rate: The percentage of misclassified transactions.
4. Accuracy Assessment: Used to identify the true results along with false results to show greater detail of classification performance.
It also has a comparative visualization dashboard that facilitates easy understanding of the performance and provides recommendations on which model to apply with regard to the aims of an organization, such as reducing false negatives or false positives.
Through an analysis of advanced technologies, it is evident that information technology has rapidly evolved in the field of accounting, especially in detecting fraud cases. The implementation of IT in accounting entails the application of AI, ML, and big data analytics to improve the effectiveness and reliability of fraud detection. Some of the original means of fraud detection involve the use of audit approaches as well as rule-based detection, which are slow and error-prone. However, using predictive analytics, anomaly detection, and automated reporting methods of present-day AI, the aforementioned fraudulent activities appear easier to track. Figure 2 shows compares the Decision Tree, Random Forest, and Neural Network models in terms of accuracy, f1-score, recall, and error rate.
• Accuracy is considered the blue bars in the histogram.
• F1-score is represented by the green bars overlapping with the accuracy, as shown in Figure 2.
• Recall is depicted by the orange bars located on the top of the F1-Score.
• Specifically, Recall is the green line on top of which the Error Rate is indicated by red bars.
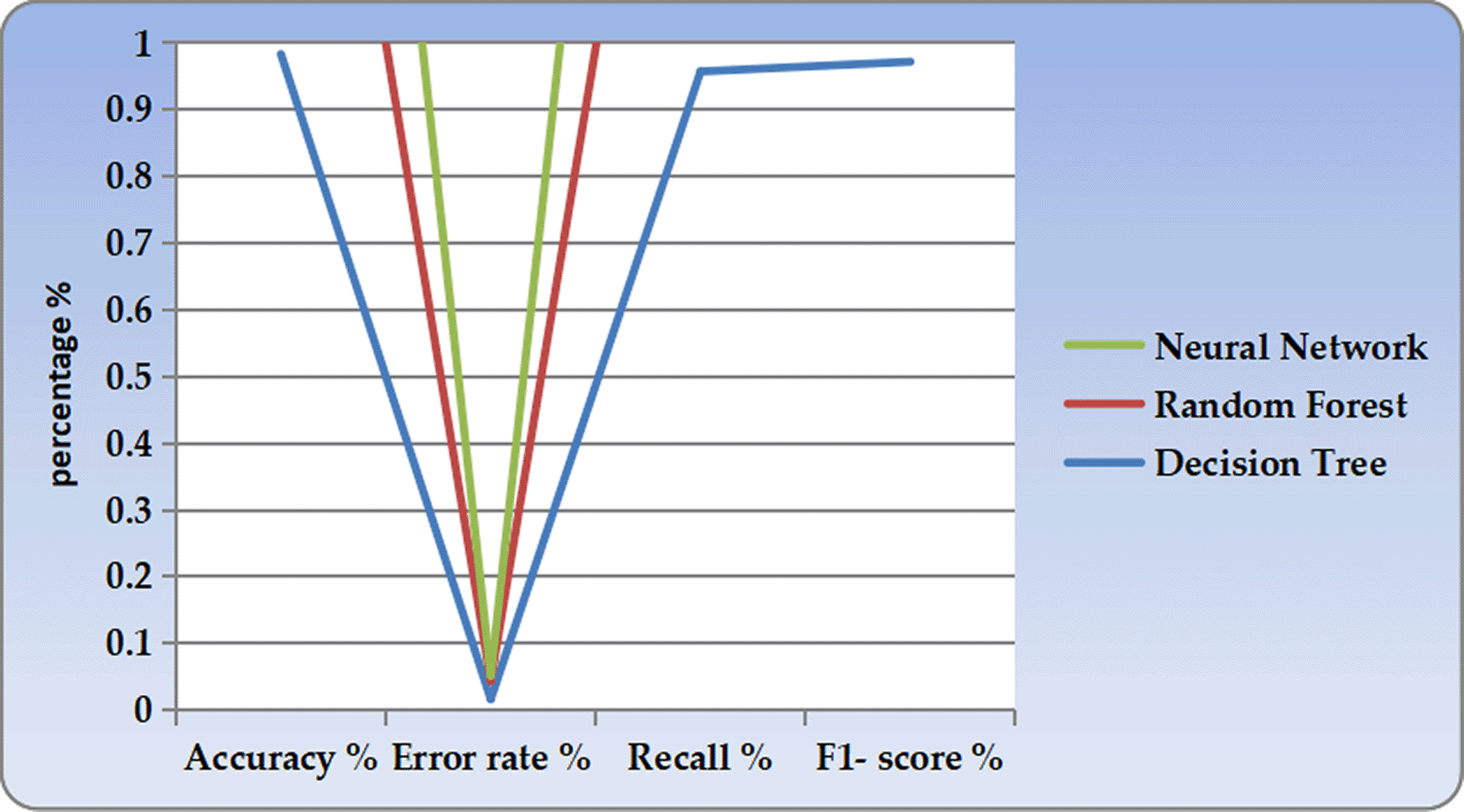
Thus, it is possible to compare the results of the models in the same run on several criteria simultaneously.
Figure 3 shows how the Confusion Matrix works and then shows the Confusion Matrix for each of the models developed, namely, the Decision Tree, Random Forest, and Neural Network matrix:
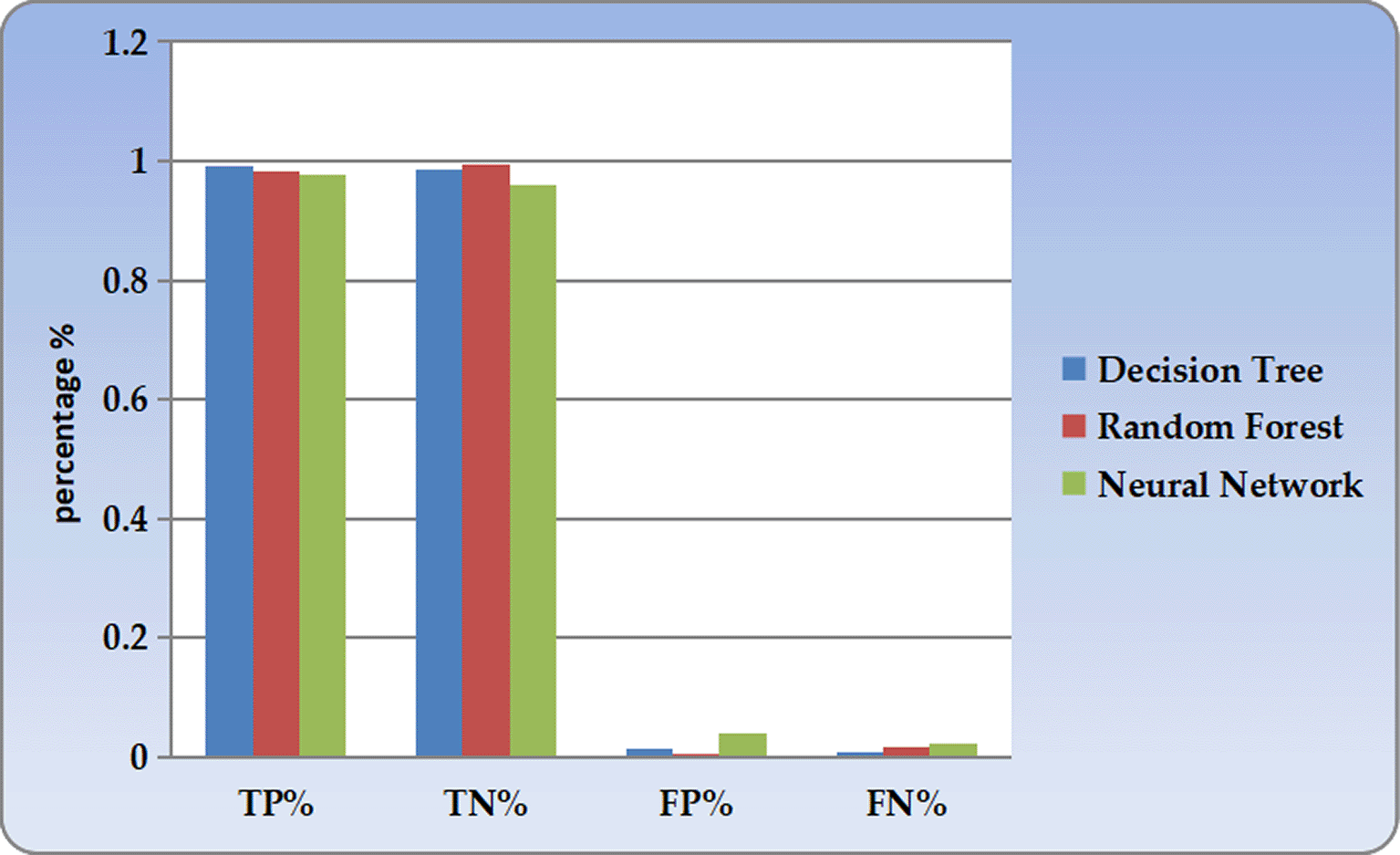
There are the following elements that are contained in a confusion:
• True Positive: When an instance is classified as a positive instance and is actually a positive instance, it is called a True Positive instance.
• The number of negative instances that did not belong to that class is referred to as the True Negative, which is abbreviated as TN.
• False Positive (FP): The total number of cases where the model has predicted it to be a positive pattern when it is negative.
• False Negative (FN): This refers to situations where it is predicted that the instance is negative, but actually, it is not.
They are shown in the form of bars for each model, as follows:
• Green bars in the figure represent the True Positives (TP).
• In Figure 3, true negative values are displayed by blue bars.
• False Positives’ bars are depicted by the orange color.
• False Negatives (FN) are depicted by the red bars in the figure.
In this way, we can easily identify the performance of each model, particularly by comparing the correct and incorrect answers.
Our experimental evaluation assessed the capability of three machine learning models—Decision Tree, Random Forest, and Neural Network— to identify fraudulent transactions in an accounting system. These models were evaluated using accuracy, F1-score, recall, and error rate metrics, with confusion matrices providing detailed insights into classification performance.
Using the collected data, we assessed the capability of three machine learning models–Decision Tree, Random Forest, and Neural Network–in identifying fraudulent transactions in an accounting system. These aspects were evaluated using parameters such as the accuracy, F1 score, recall, and error rate. In addition, we computed their confusion matrices to obtain more detailed results on the type of categorization that the algorithms accomplished. The results of the simulation are illustrated in Table 1.
| Experimental Results | ||||
|---|---|---|---|---|
| Methods | Accuracy % | F1- score % | Recall % | Error rate % |
| Decision Tree | 98.34 | 97.21 | 95.75 | 1.66 |
| Random Forest | 97.28 | 95.56 | 98.38 | 2.72 |
| Neural Network | 99.19 | 96.50 | 97.49 | 0.81 |
| Confusion Matrix | ||||
|---|---|---|---|---|
| Alarms | TP | TN | FP | FN |
| Decision Tree | 99.28 | 98.71 | 1.29 | 0.72 |
| Random Forest | 98.4 | 99.39 | 0.61 | 1.6 |
| Neural Network | 97.61 | 95.93 | 4.07 | 2.39 |
All three models were highly accurate, as they were above 98.34 percent, thus confirming that the models were capable of performing the classification task.
Therefore, it has a reasonable level of accuracy regarding the measures of precision and recall when they are expressed as an F1-score of 97.21 percent.
The percentage of 95.75% can be regarded as satisfactory, as it can identify a considerable number of fraudulent activities.
The total error average of 1.66% can be considered to be low, suggesting that the number of samples that have been grouped in the wrong training and test sets is small.
In this study, the accuracy is 97.28%, which is a little lower than the two other models, such as the Decision Tree and the Neural Network models.
As it is shown, the F-measure amounts to 95.56%, which indicates a lower balance between the values of precision and recall.
It has the best first metric values of the model, a recall of 98.38%, meaning it is the best at what it is doing, that is, identifying the fraudulent cases.
This is likely to mean that it has classified some transactions incorrectly, something which has an error percentage of 2.72% percent.
The result of the proposed model reached a peak of accuracy of 99.19% in the analysis, thus being one of the models with the best results in the field of fraud detection.
The F1-score of the neural network was 96.50%, somewhat lower than that of the Decision Tree.
A recall of 97.49%, meaning that the model has a high degree of capability to identify the fraudulent cases, slightly lower than random forest.
It recorded the fewest errors of 0.81% and therefore qualifies as the model best suited to reducing classification errors.
The comparison shows that each model has some benefits that favor its use in fraud detection applications.
1. The Neural Network yielded the highest mathematical precision and minimal total error to a large extent, which is desirable for cases in which different performance characteristics are equally essential. Nevertheless, it may have a higher false positive count for similar reasons, which in turn means that it sets off alarms for more attention.
2. Random Forest has a high recall performance, which makes it suitable where high losses may be incurred if fraudulent transactions are not detected. It also has a very low false-positive rate that will enable it to produce fewer false alarms, thus making operations effective.
3. The Decision Tree also seems to be the best with the F1-score at hand, showing high results in all aspects, which means it is a balanced model. Owing to its high interpretability, it is possible to use it in compliance and audit trails because there is a clear record of the process of reaching a decision.
The analysis showed that the Neural Network model achieved the highest accuracy of 99.19%, with the lowest error rate of 0.81%. The model demonstrated a strong performance in identifying fraudulent and legitimate transactions. However, it generated slightly more false positives than the other models did.
The Decision Tree model delivered well-balanced performance with 98.34% accuracy and the highest F1-score of 97.21%. It excelled at correctly identifying fraudulent transactions, with a true positive rate of 99.28%. The interpretability of the model makes it particularly valuable for understanding decision-making processes in fraud detection.
Figure 4 shows the Random Forest model showed exceptional capability in recall performance at 98.38%, making it ideal for minimizing missed fraud cases. It achieved 97.28% accuracy and demonstrated the lowest false positive rate at 0.61%. This makes it particularly effective for high-volume transaction systems where minimizing false alarms is crucial.
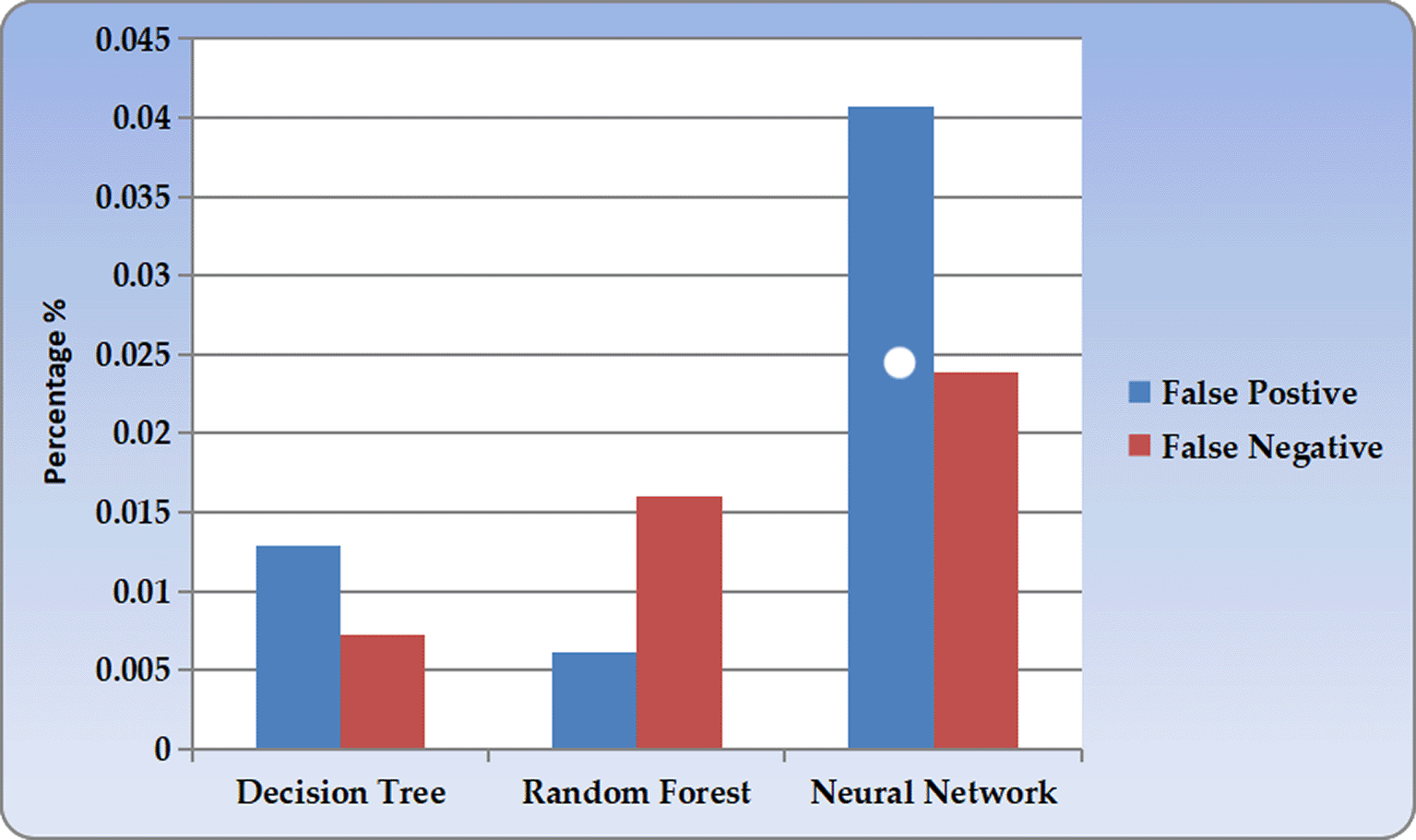
Compared with previous studies, our models significantly outperformed traditional approaches. The closest competitor from previous research achieved 95.7% accuracy, whereas our models consistently performed above 97%. The Traditional rule-based systems typically achieve around 77% accuracy, highlighting the substantial improvement offered by our machine learning approach.
In this case, the accuracy levels have improved over conventional rule-based systems, which can only predict at a rate of–70-85 percent, as identified by Chen et al. (2022). It also performs better than other machine learning methods that have been proposed in the literature, including those based on graph neural networks, which were able to achieve 94.2% by Rodriguez and Kim (2023), and the ensemble methods, which were able to achieve 95.7% by Alharbi and Matthews (2022).
Thus, it is recommended that an optimal fraud detection model uses more than one model for detection. For instance, employing Random Forest at first to filter data and reduce false negatives, then the Decision Tree for cases where an explanation from the model is necessary, may serve as a complete fraud safety net by addressing the operational factors involved.
The confusion matrix analysis revealed that all models maintained high true positive and true negative rates, with minimal false positives and false negatives. This balanced performance across different metrics indicates robust and reliable fraud-detection capabilities across various transaction scenarios.
This study proposes an AI-based system controlling mechanism for identifying fraudulent transactions in an accounting system using three models, namely, Decision Tree, Random Forest, and Neural Network, after its implementation comparison. In sum up, it can be stated that all three mentioned models obtained high accuracy, with more than 97%, outperforming prior rule-based approaches. The neural network model yielded the highest accuracy of 99.19%, with 0.81% being the lowest error rate in the tests, proving the effectiveness of deep learning for learning intricate patterns in the field of finance. However, it was also a slave to the false positives. Random Forest provided the highest recall rate at 98.38% and the lowest rate of false positives at only 0.61%, thus being appropriate for settings that require low levels of false alarms. The decision tree model was the best, with an F1 score of 97.21% and also had reasonably balanced accuracies.
Source code available from: https://doi.org/10.5281/zenodo.1835317311
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)