Keywords
drug–herb–food interactions, knowledge graphs, ontology mapping, pharmacokinetics, pharmacodynamics, condition‑inclusive reasoning, interaction inference, FAIR principles
drug–herb–food interactions, knowledge graphs, ontology mapping, pharmacokinetics, pharmacodynamics, condition‑inclusive reasoning, interaction inference, FAIR principles
The use of herbal medicines, dietary supplements, and functional foods has grown sharply over the past decade,1 especially among individuals with chronic diseases who often co-administer these products with prescription drugs.2 This real-world poly-product use creates complex interaction patterns that conventional interaction checkers, typically optimized for drug–drug pairs, struggle to represent. Public tools generally provide pairwise textual summaries with limited coverage of herbs and foods and rarely incorporate health-related conditions (e.g., age, pregnancy, hepatic/renal impairment, and smoking) that materially influence PK/PD processes. Consequently, the interpretations are uniform rather than patient-context aware.
Research-oriented resources such as FIDEO and DDInter 2.0 advance structure and coverage but leave important gaps in the data. FIDEO focuses on FAIR-aligned formalization3 for food–drug interactions without mechanism-level reasoning or an end-user interface,4 while DDInter 2.0 omits drug–herb interactions using structured knowledge and does not treat health-related conditions as explicit reasoning entities.5
To address these limitations, we developed the Drug–Herb–Food Interaction Checker (DHFI-C), a mechanism-transparent, condition-integrated platform that unifies drug, herb, food, and condition domains within a single interoperable framework. DHFI-C combines an ontology-structured data model and knowledge graph with a deterministic inference engine capable of reasoning across shared enzymes, transporters, and pharmacodynamic pathways. Conditions (e.g., age, pregnancy, hepatic/renal impairment, and smoking) were modeled as first-class entities to enable context-aware interpretation. Supporting modules provide therapeutic duplication detection, combination drug decomposition, and disease-to-drug suggestions.
By integrating these capabilities within a single interoperable platform, the DHFI-C is intended to support more transparent interaction assessments in settings where polypharmacy, herbal product use, and contextual clinical factors intersect, including patient self-checking, pharmacist consultation, and exploratory research on interaction mechanisms.
DHFI-C was implemented through a staged, FAIR-aligned workflow informed by extended FAIR concepts3,6–8 that ensures transparent, reproducible construction of a condition-integrated interaction platform: (i) PRISMA-guided evidence acquisition and curation9; (ii) structured data model definition separating entities, interaction records, and mechanistic context; (iii) ontology mapping for semantic normalization; (iv) graph-native knowledge graph construction; (v) rule-guided, mechanism-based inference; and (vi) supporting functional modules for realistic assessment, including disease-to-drug suggestion, combination decomposition, and effect-duplication detection.
Searches of PubMed/MEDLINE, PubMed Central, and major open-access publishers (MDPI, Wiley, BMC) will be restricted to the period from January 2015 to December 2025. The search queries will combine terms focused on interactions and mechanisms (e.g., “drug interaction,” “herb–drug interaction,” “food–drug interaction,” “pharmacokinetics,” “pharmacodynamic interaction,” “enzyme inhibition,” and “enzyme induction”) with terms related to specific conditions, such as age, pregnancy, hepatic impairment, renal impairment, and smoking status. Boolean operators will be used to identify evidence where interaction outcomes are influenced by health-related conditions.
The initial search yielded 312 records, with an additional 28 records identified through manual screening of reference lists and targeted, open-access sources. After deduplication, screening, and removal of 74 duplicate records, 266 unique records were screened based on their titles and abstracts. Of these, 221 records were excluded because of a lack of relevance to pharmacological interactions, absence of mechanistic or condition-dependent content, non-peer-reviewed status, or inappropriate study design. The remaining 45 articles were assessed for full-text eligibility. Following the full-text review, 25 articles were excluded because they did not provide extractable interaction data, lacked PK/PD relevance, or were incompatible with the structured data extraction. The literature selection process is illustrated in Figure 1. Ultimately, 20 studies met all inclusion criteria and were included for data curation. These studies are cited collectively in References (10–29), with complete study-level metadata and extracted interaction fields provided in Extended Data 1.
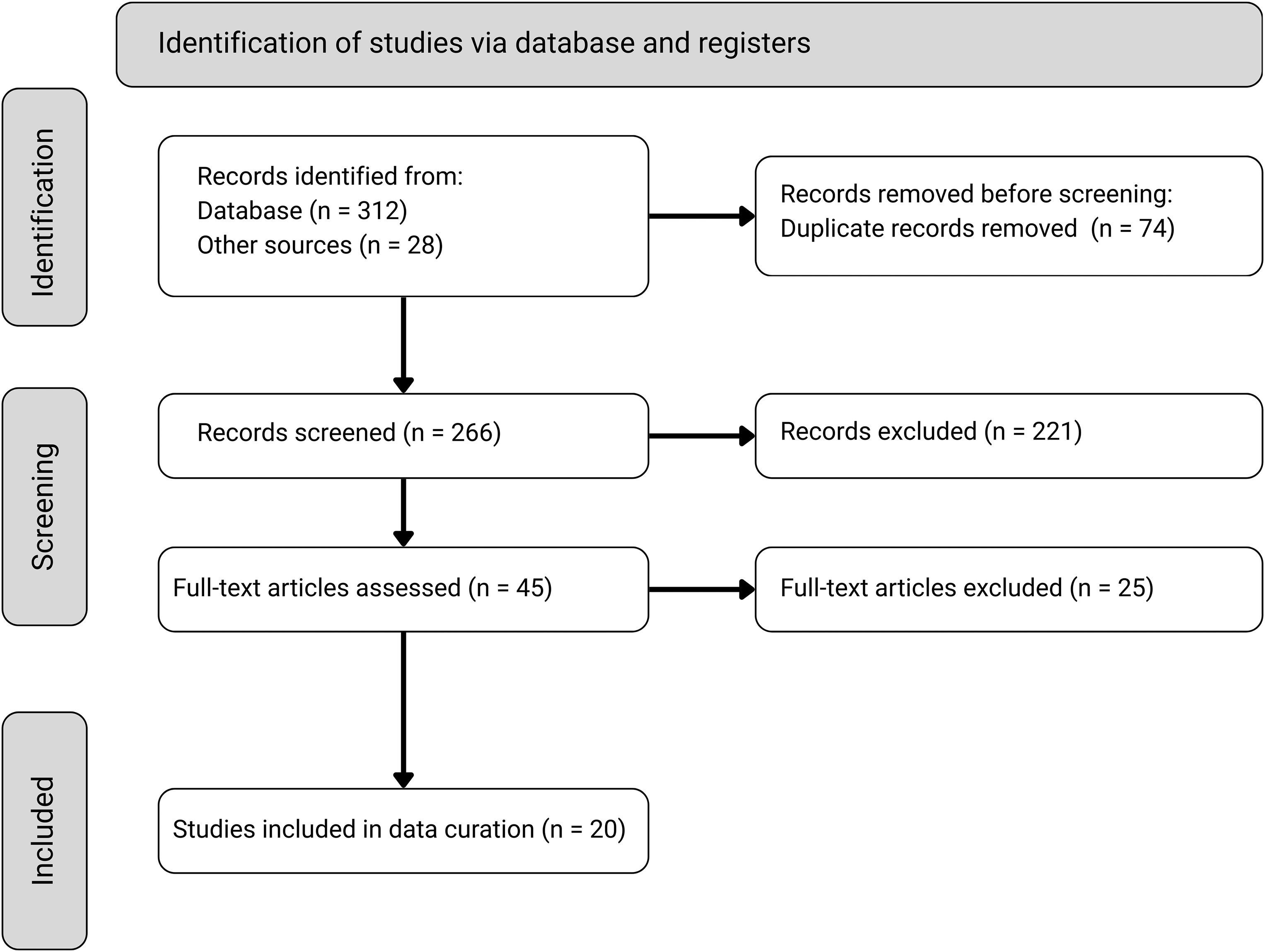
The diagram summarizes the literature identification, screening, eligibility assessment, and inclusion process used for evidence acquisition and curation. Records were identified through database searches and manual screening of reference lists and open-access sources. Following duplicate removal, titles and abstracts were screened for relevance to pharmacological interactions and mechanistic or condition-dependent evidence. Full-text articles were then assessed for eligibility, resulting in the final set of studies included for structured data curation.
A structured data model was developed to facilitate condition-integrated interaction modeling across the domains of drugs, herbs, food, and health-related conditions. This model distinguishes entities, interaction records, and mechanistic contexts into separate yet interconnected components, allowing for the reproducible transformation of curated evidence into the construction and inference of downstream knowledge graphs.
Entities were modeled as first-class objects across five categories: drugs, drug classes, products (herbs and foods), health-related conditions, and underlying diseases. Drugs were represented as individual active pharmaceutical entities, and drug classes were implemented as separate entities to support class-level grouping and reference. The products encompassed both herbal and food entities and were treated uniformly at the entity level. Health-related conditions, including age, pregnancy, hepatic impairment, renal impairment, and smoking status, were implemented as controlled entities using fixed semantic identifiers to ensure consistent usage across interaction records. Underlying diseases represent chronic disease contexts, such as diabetes mellitus, hyperlipidemia, hypertension, and cardiovascular diseases, and are implemented to support disease-driven input assistance.
Each entity is assigned a persistent internal identifier according to a domain-specific scheme. Drugs receive identifiers like ENT_000001, drug classes are labeled as ENT_100001, and products, including herbs and foods, are designated as ENT_200001. Conditions are represented with controlled identifiers such as ENT_COND_PREGNANCY, ENT_COND_HEPATIC_IMPAIRMENT, ENT_COND_RENAL_IMPAIRMENT, ENT_COND_ELDERLY, and ENT_COND_SMOKING, while underlying diseases are marked as ENT_ULD_000001. These identifiers offer stable internal references that are independent of external ontology identifiers, thus facilitating reproducible data transformation and system evolution.
Interaction records link subject and object entities with explicit roles and directionality. Each interaction record includes a unique interaction identifier (e.g., INT_000001), a pair type indicating the interacting domains (Drug–Drug, Herb–Drug, Food–Drug, or Condition–Drug), subject and object entity identifiers, a mechanistic interaction type descriptor, a mechanism domain label (PK or PD), and reference provenance. This structure allows the interaction interpretation to be derived from a mechanistic context rather than relying solely on predefined interaction pairs.
The mechanistic context was implemented separately from the interaction records and was organized into two primary domains. The pharmacokinetic (PK) domain captures the biological determinants of drug disposition, including phase I and II enzymes, such as UDP-glucuronosyltransferases, transporters, and metabolism-related cofactors, such as glutathione. The pharmacodynamic (PD) domain captures pharmacological effect descriptors, including effect types relevant to interaction interpretation and duplication. Mechanistic descriptors are linked to interaction records through structured attributes rather than being embedded directly as entities, enabling consistent classification and downstream reasoning.
The structured data model was implemented using normalized tabular representations to facilitate validation, version control, and reproducible transformations into a knowledge graph, as described in the following sections.
Ontology mapping followed rule-guided alignment while preserving internal identifiers as the primary reference system of the DHFI. Mapping was treated as a secondary semantic layer applied after structured data modeling to ensure that ontology alignment does not alter internal data integrity or interaction logic.
Ontology resources were selected based on predefined criteria, including domain relevance, community adoption, identifier stability, and suitability for pharmacokinetic or pharmacodynamic interpretations. Mapping was applied by entity category, and only when a suitable external ontology provided stable concept-level coverage for that category. For each entity, ontology alignment followed a consistent procedure in which curated canonical labels and synonyms from the structured data model were first used to identify exact or semantically close matches in the candidate ontologies. When an appropriate external identifier was available, the entity was linked to the ontology through an explicit mapping association. When no suitable external reference existed, the entity was retained using a persistent internal identifier and represented within the DHFI mini-ontology to preserve semantic consistency without forcing mismatched alignment. In all cases, ontology mappings were recorded as explicit associations without replacing internal identifiers, ensuring that the internal identifiers remained the primary reference system for data integrity and downstream reasoning. This strategy ensures that ontology alignment enhances semantic interoperability while maintaining reproducibility, extensibility, and independence from specific ontological versions.
Drug entities were mapped to the National Cancer Institute Thesaurus (NCIT)30 to support the standardized representation of active pharmaceutical ingredients and interoperability with established biomedical resources. Mapping was performed at the active ingredient level, independent of the formulation or brand representation.
Drug class entities were derived from curated parent concepts of individual drug entities within the NCIT hierarchy, restricted to drug- and pharmacologic substance–related categories. Parent concepts from non-drug semantic domains were excluded, and duplicate class concepts were consolidated to form a non-redundant set of drug class entities. Although drug class entities were derived from individual drug mappings, class-level ontology mappings were maintained as explicit and independent semantic references, and class properties were not automatically inferred from member drugs. This design preserves the explicit class-level semantics and prevents unintended hierarchical inference during downstream reasoning. In all cases, internal drug and drug class identifiers were the primary keys. Drugs and drug classes were mapped to NCIT identifiers stored as linked semantic references.
Product entities encompassing herbs and foods were mapped using domain-specific external ontologies. Herbal entities were aligned to NCBI Taxonomy identifiers at the species level, where applicable, enabling standardized taxonomic representation and cross-resource compatibility.31 Food entities were aligned with FoodOn concepts to support consistent food classification and interoperability.32
When suitable external identifiers were not available, such as for food preparations, mixtures, or exposure-related concepts, product entities were retained using internal identifiers within the DHFI mini-ontology. These cases were explicitly recorded to preserve semantic consistency without forcing a mismatched alignment.
Health-related condition entities, including age, pregnancy, hepatic impairment, renal impairment, and smoking status, were not mapped to external disease ontologies. These entities represent physiological or behavioral modifiers rather than formal disease diagnoses. Accordingly, condition entities were represented using a domain-specific controlled ontology (DHFI mini-ontology) defined by persistent internal identifiers, resolvable URIs, controlled labels, and mechanistic descriptions.
Underlying disease entities were implemented to support disease-driven input assistance and were mapped to the MONDO Disease Ontology at the disease concept level.33 Mapping was applied to support standardized disease naming and interoperability, but was not directly used as a mechanistic inference target.
Mechanistic interaction types were represented using a controlled classification scheme. Where available, the interaction types were aligned with the Drug Interaction Ontology (DINTO).34 To accommodate interaction patterns not covered by DINTO, such as physiological change–based effects and explicit no-interaction assertions, the interaction type set was extended using the DHFI mini-ontology.
Each interaction type was assigned a persistent identifier and annotated with its mechanism domain (pharmacokinetic, pharmacodynamic, or combined) and default semantic interpretation. Interaction records directly reference these identifiers, enabling consistent classification and reuse across inference use cases.
Pharmacokinetic targets were mapped at both the protein and protein family levels. Individual enzymes and transporters were aligned to UniProt identifiers,35 whereas protein family or functional domain information was aligned to Pfam accessions.36 Pharmacodynamic effect descriptors were represented using the DHFI mini-ontology owing to the absence of a mature, widely adopted external ontology suitable for interaction-level pharmacological effect representation.
All ontology mappings were stored as explicit associations linked to internal identifiers, including the mapping source, external identifier, and mapping relation. This decoupled mapping strategy allows the semantic layer to evolve independently of the core data model, supporting FAIR-aligned interoperability, controlled extensibility, and future ontology updates without disrupting the system logic.
Following structured data modeling and ontology mapping, a knowledge graph was constructed to serve as the core representation layer of the DHFI. Graph construction was implemented as a deterministic transformation process that converted normalized tabular data into a graph-native structure, preserving entity categories, interaction semantics, mechanistic context, and ontology-aligned references in an inference-ready format.
Graphs were constructed by instantiating entities as typed nodes according to their predefined categories, including drugs, drug classes, products (herbs and foods), health-related conditions, underlying diseases, pharmacokinetic targets, and pharmacodynamic effect descriptors. Each node was created using its persistent internal identifier as the primary key and annotated with entity-type metadata and, where applicable, linked external ontology references. Node typing was explicitly preserved during graph instantiation to enable domain-constrained querying and rule-guided inferences in the subsequent stages.
Interaction records were transformed into directed edges connecting the subject and object entity nodes. Directionality was preserved based on the subject–object roles defined in structured interaction records. Each interaction edge was annotated with structured attributes, including an interaction type identifier, mechanism domain (pharmacokinetic, pharmacodynamic, or combined), and reference provenance. Interaction types were represented using controlled identifiers aligned with external ontologies or the DHFI mini-ontology, ensuring consistent classification across the curated and inferred interactions.
The mechanistic context was explicitly encoded within the graph to support inferences beyond the enumerated interaction pairs. Pharmacokinetic targets, including enzymes, transporters, phase II enzymes, and metabolism-related cofactors, were instantiated as intermediate nodes and linked to relevant drug, product, or condition entities through mechanistic relationships, such as inhibition, induction, or modulation. Pharmacodynamic effects were instantiated as effect nodes and connected to entities through effect-direction relationships that represented increases, decreases, or antagonistic actions on physiological functions. These mechanistic structures were encoded independently of the specific interaction pairs to enable shared-pathway reasoning during inference.
The resulting graph-native representation supports controlled multi-hop traversal, mechanism-constrained reasoning, and explicit traceability between the interaction outputs and underlying evidence structures. By preserving entity typing, interaction semantics, mechanistic mediation, and ontology-aligned references during graph construction, the DHFI establishes a reproducible and extensible foundation for the mechanism-based inference engine described in the following section.
A Mechanism-Based Inference Engine was developed to derive interaction interpretations through explicit pharmacokinetic and pharmacodynamic mechanisms encoded within the knowledge graph, rather than relying solely on pre-enumerated interaction pairs. The engine operates deterministically on the graph-native representation described in Section 2.5 and employs rule-guided traversal to identify mechanistically plausible interactions within a given assessment context.
Inference execution starts by constructing an interaction query context, which includes a resolved set of entity nodes representing drugs, products, health-related conditions, and underlying diseases provided as input. For each entity in this query context, the engine directly retrieves curated interaction edges linked to the entity and identifies associated mechanistic nodes, such as pharmacokinetic targets and pharmacodynamic effect descriptors. This initial retrieval step ensures that curated evidence is explicitly incorporated before any inference-driven interpretation. Mechanism-based inference is conducted through constrained graph traversal, guided by mechanism domain labels and semantic interaction types. Traversal rules are applied separately to the pharmacokinetic and pharmacodynamic domains to prevent inappropriate cross-domain inferences.
In the pharmacokinetic domain, inference is triggered when two or more entities are connected to a shared pharmacokinetic target through complementary mechanistic relationships such as inhibition, induction, or substrate association. When such patterns are detected, the engine derives a structured pharmacokinetic interaction interpretation consistent with altered clearance or exposure based on predefined interaction type semantics.
Pharmacodynamic inference is performed by identifying overlapping, opposing, or reinforcing pharmacodynamic effect nodes associated with co-administered entities. Effect-direction relationships were evaluated to determine whether the combined effects corresponded to potentiation, antagonism, or additive action. This approach enables pharmacodynamic interaction interpretation even in the absence of a directly curated interaction record for a specific entity pair while preserving explicit mechanistic justification.
To maintain transparency and reproducibility, the inferred interaction outcomes were explicitly distinguished from the directly curated interaction records. Each interaction result is annotated with its derivation pathway, indicating whether it originates from curated evidence or mechanism-based inference, and is linked to specific graph paths, interaction types, and reference-associated entities. The inference engine operates as a deterministic, rule-based system over explicitly encoded graph structures and controlled interaction-type semantics, producing structured mechanistic interpretations rather than probabilistic predictions or quantitative risk scores. This design ensures reproducible interaction interpretation, clear traceability from output to underlying mechanistic evidence, and extensibility as additional interaction types, mechanistic descriptors, or condition entities are incorporated into the knowledge graph.
In addition to the core mechanism-based inference engine, the DHFI incorporates supporting functional modules implemented as modular components operating on the same structured data model and knowledge graph. These modules were developed to improve the accuracy of user input, mitigate the limitations arising from insufficient or incomplete interaction evidence in the literature, and enhance the clarity and interpretability of interaction outputs for end users.
Disease-to-Drug Suggestion Module
The Disease-to-Drug Suggestion module was implemented as an input-support mechanism to improve the completeness and correctness of interaction assessment use cases. A limited set of underlying disease entities (initially diabetes mellitus, hyperlipidemia, hypertension, and cardiovascular diseases) was defined, and each disease entity was linked to representative drug substances curated from the WHO Model List of Essential Medicines (24th list, 2025).37 Disease–drug associations were encoded as reference-level relationships and were used solely to suggest candidate drug entities during the input construction. These associations do not participate in mechanism-based inferences or causal interpretations.
Drug Combination Handling Module
The Drug Combination Handling module was implemented to enable interaction assessment for multi-ingredient products in the absence of sufficient combination-level interaction evidence. Combination products are represented as composite entities linked to their constituent active entities through explicit composition relationships. During the assessment, composite entities were deterministically decomposed into individual active components, which were evaluated independently using the same mechanism-based inference process applied to single-ingredient entities. The decomposed components were annotated with provenance tags indicating their origin from a combination product to preserve traceability
Pharmacological Effect Duplication Detection Module
The Pharmacological Effect Duplication Detection module was implemented as a rule-based component operating on pharmacodynamic effect descriptors encoded in the knowledge graph. Pharmacodynamic effects were represented as structured effect entities linked to drugs, herbs, or products through effect–direction relationships. During the assessment, overlapping or functionally equivalent pharmacodynamic effect descriptors across co-administered entities were identified and reported as pharmacological effect duplication, with drug class information incorporated as an additional abstraction to support duplication detection.
The DHFI-C web interface is accessible via a public server endpoint (http://34.142.141.239/). The system has been tested on modern web browsers, with Google Chrome recommended for optimal performance.
The DHFI evaluation aimed to determine if the system aligns with methodological capabilities outlined in its design objectives. A capability-based evaluation framework was employed, focusing on the presence, integration, and transparency of essential functionalities related to mechanism-based reasoning, condition-inclusive interaction modeling, and multi-domain interaction integration. A use-case-based evaluation strategy was implemented to mirror complex interaction assessment tasks. Instead of assessing functions separately, a single integrated use case was developed to test the interaction-assessment workflow within a cohesive context.
The evaluation use case was predefined to include drug–drug, herb–drug, food–drug, and condition–drug interactions, encompassing pharmacokinetic and pharmacodynamic mechanisms. This use case involves multiple interacting substances, health conditions, and underlying diseases, allowing observation of condition-inclusive interaction interpretation and cross-domain integration within a unified workflow. The use case definition was established before evaluation and remained unchanged based on system outputs, ensuring methodological independence between evaluation design and observed results.
The evaluation criteria were specified as discrete capability dimensions derived from the methodological objectives of the system. These include support for mechanism-based inference beyond explicitly curated interaction pairs, explicit distinction between curated and inferred interactions, condition-level interaction interpretation using health-related condition entities, handling of multi-ingredient drug combinations, detection of pharmacological effect duplication, disease-driven input support, and provision of machine-readable ontology-aligned outputs. The capabilities were assessed qualitatively based on demonstrable system behavior and observable structured outputs. The evaluation results are reported using structured qualitative representations, including use case walkthrough descriptions, representative system outputs, and capability-oriented summary tables, providing a transparent and traceable basis for the assessment presented in the Results section.
The authors used ChatGPT (OpenAI, GPT-5) to assist with structural organization and language refinement of the manuscript to improve clarity and organization. Paperpal (version 4.11.0) was used for grammar and language checking. All scientific content, methodological decisions, data interpretation, and conclusions were independently developed, critically reviewed, and approved by the authors.
This study did not involve human participants, patient data, or identifiable personal information. The research was conducted using publicly available literature and structured datasets derived from published sources. Therefore, ethical approval from an institutional review board (IRB) and informed consent from participants were not required.
Figure 2 presents an overview of the DHFI-C system architecture, illustrating how user inputs are processed through ontology-aligned data layers and a mechanism-based inference pipeline to generate interaction-assessment outputs.
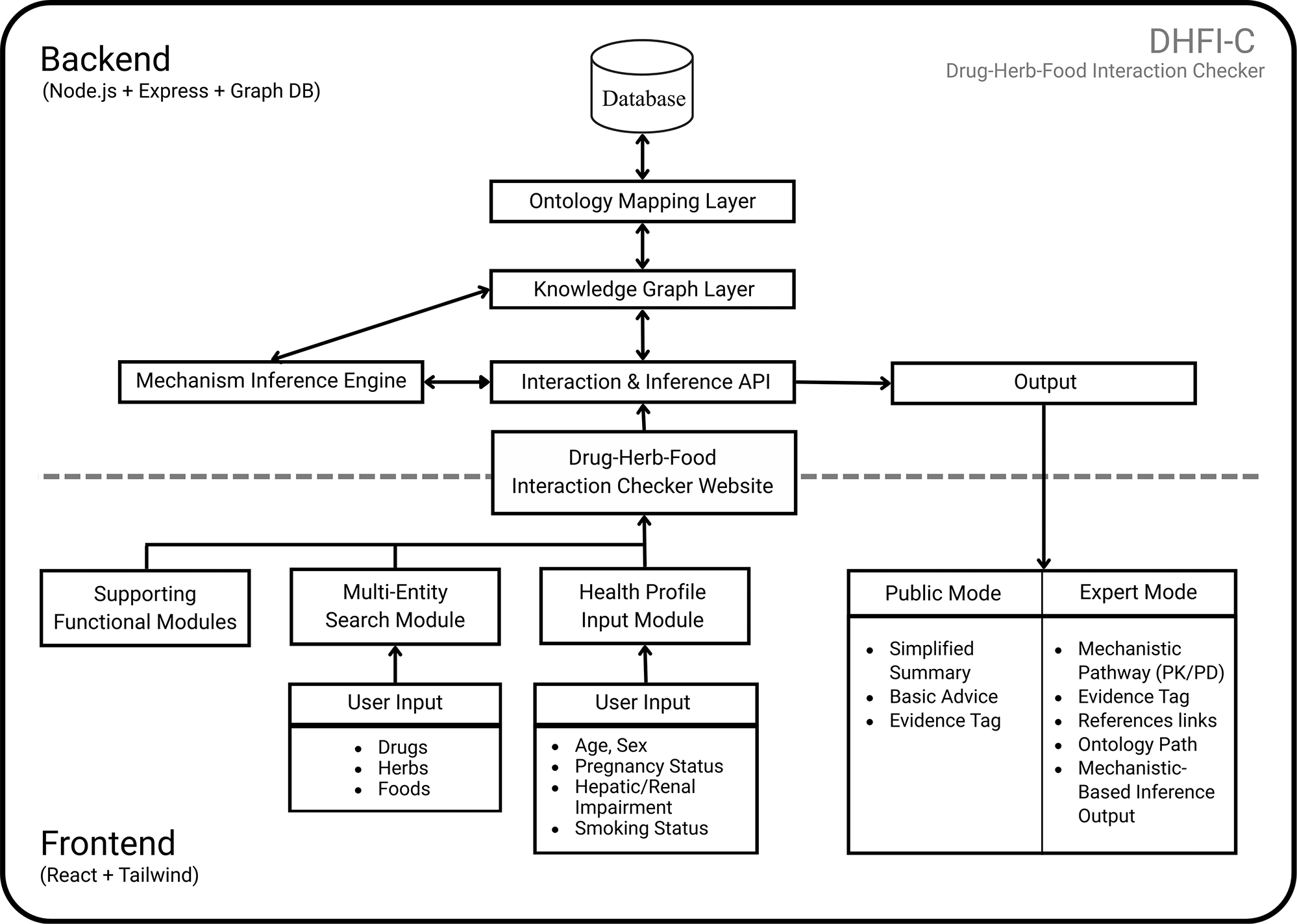
The figure illustrates the overall operational architecture of DHFI-C, comprising a backend and frontend layer. User inputs—including drugs, herbs, foods, and health-related conditions—are collected through dedicated frontend modules and processed via an Interaction and Inference API. The backend integrates an ontology mapping layer, a knowledge graph layer, and a graph database to support graph-native reasoning. A mechanism-based inference engine operates over the knowledge graph and is complemented by supporting functional modules, including disease-to-drug suggestion, drug combination handling, and pharmacological effect duplication detection. Interaction assessment outputs are delivered through two presentation modes: a public mode providing simplified summaries and basic advice, and an expert mode offering detailed mechanistic pathways, PK/PD explanations, ontology paths, evidence tags, and reference links.
The system is organized into backend and frontend architectures. The backend integrates a graph database, ontology mapping layer, and knowledge graph layer, which together serve as the semantic foundation for the interaction assessment. Interaction queries are handled through a dedicated Interaction and Inference API that mediates communication between the user-facing web interface and mechanism-based inference engine. This design enables interaction reasoning to be performed directly over a graph-native representation of drugs, products (herbs and foods), health-related conditions, and mechanisms.
The mechanism-based inference engine is complemented by supporting functional modules, including disease-to-drug suggestions, drug combination handling, and pharmacological effect duplication detection. These modules contribute complementary functionalities while remaining decoupled from the core inference logic. User inputs are collected through dedicated frontend modules for multi-entity search and health profile specification, allowing users to provide substance combinations with relevant physiological or clinical contexts.
The interaction assessment results are delivered through two presentation modes: public mode, which provides simplified summaries and basic advice, and expert mode, which offers detailed mechanistic pathways, PK/PD explanations, evidence tagging, ontology paths, and reference links. This dual-mode output design allows the same inference logic to support both consumer-facing interpretation and expert-level transparency while preserving consistency across system outputs.
The scale and composition of the DHFI-C database are summarized in Tables 1 and 2.
As shown in Table 1, the database contains 24,216 drug entities representing active pharmaceutical substances and related drug components, alongside 92 product entities encompassing herbs and foods. In addition, 1,009 drug class entities were included to support the class-level grouping and reference. The mechanistic layer of the dataset comprised 21 protein targets and transporters and eight pharmacological-effect terms, which were used to support mechanism-based interaction interpretation and duplication detection. The curated interaction dataset included 1,277 interaction records, complemented by 383 target–entity associations and 39 pharmacological effect associations, forming the structural basis for graph-based inference.
Table 2 summarizes the classification of interaction records by interaction pair and mechanistic interaction types. The interaction pair coverage spans multiple domains, including 443 drug–drug interactions, 514 herb–drug interactions, 159 food–drug interactions, and 161 condition–drug interactions, reflecting the multi-domain integration capability of the system.
Mechanistic interaction types are distributed across pharmacokinetic and pharmacodynamic categories. Pharmacokinetic mechanisms were predominantly represented by enzyme activity inhibition (569 records) and transporter activity inhibition (240 records), with additional representation of enzyme activity induction (132 records), transporter activity induction (32 records), and non-absorbable complex formation (22 records). Pharmacodynamic and physiological mechanisms included physiological effect potentiation (146 records), physiological effect antagonism (17 records), physiological change effect potentiation (20 records), and physiological change effect antagonism (71 records), reflecting a range of effect-based interaction patterns captured in the dataset. A subset of 28 records was explicitly classified as having no interaction, enabling the representation of evidence-supported non-interacting pairs.
Together, these results demonstrate that the DHFI-C supports broad interaction coverage across substances, conditions, and mechanistic domains while maintaining a structured and interpretable representation suitable for mechanism-based reasoning and transparent interaction assessment.
The ontology mapping coverage across dataset domains is summarized in Table 3, reflecting the extent to which DHFI entities and interaction components were aligned with external biomedical ontologies following the controlled, rule-guided mapping strategy described in Section 2.4.
All drug entities (24,216 items) and drug class entities (1,009 items) were successfully mapped to the National Cancer Institute Thesaurus (NCIT), resulting in 100% external ontology coverage in both domains. Mapping was performed at the active ingredient and class concept levels, while preserving internal identifiers as primary references.
Product entities representing herbs and foods demonstrated partial external ontology coverage (80.4% of the total). Of the 92 product entities included in the dataset, 74 were mapped to external ontologies: herbal entities to NCBI Taxonomy at the species level and food entities to FoodOn concepts. The remaining product entities corresponded to food preparations, mixtures, or exposure-related concepts for which no suitable stable external identifiers were available and were therefore retained using DHFI mini-ontology.
Mechanistic interaction types demonstrated partial alignment with the Drug Interaction Ontology (DINTO), with nine of 12 interaction types mapped, yielding 75% coverage for this domain. These mappings support the standardized representation of common interaction mechanisms, whereas the remaining interaction types are represented using the DHFI mini-ontology to accommodate patterns not fully captured by DINTO.
Pharmacokinetic targets, including enzymes and transporters, were fully mapped to external protein reference systems, with 100% coverage achieved through alignment with UniProt identifiers and Pfam accessions at the protein and protein family levels.
Underlying disease entities used for disease-driven input assistance were fully mapped to the MONDO Disease Ontology, resulting in 100% external ontology coverage. These mappings support standardized disease naming and interoperability without direct participation in mechanistic inference.
In contrast, no pharmacological effect terms were mapped to external ontologies (0% coverage). All pharmacological effect descriptors were represented exclusively using the DHFI mini-ontology, reflecting the absence of a mature, widely adopted external ontology capable of representing interaction-level pharmacodynamic effects with sufficient semantic granularity. These effect terms were fully integrated into the knowledge graph and inference process using controlled internal identifiers, as described in Section 2.4.5.
Overall, the ontology mapping coverage varied by domain according to the availability and suitability of external reference ontologies. External mappings were applied where stable and semantically appropriate resources existed, whereas the DHFI mini-ontology was used to ensure consistent representation for domains lacking adequate external ontology support.
The DHFI knowledge graph comprised approximately 232,630 RDF statements, including 202,540 explicitly asserted triples and 30,090 inference-derived triples, resulting in an expansion ratio of 1.15. The graph integrates drugs, herbs, foods, health-related conditions, underlying diseases, pharmacokinetic targets, transporters, pharmacodynamic effects, and drug class entities into a unified semantic structure.
Structural validation was performed using SPARQL-based integrity checks to confirm the correct node typing, domain–range consistency of relationships, and preservation of interaction directionality. Validation queries further verified the existence of valid traversal paths for pharmacokinetic mechanisms, including enzyme- and transporter-mediated interaction pathways.
Multi-step mechanistic paths, such as herbal inhibitor → shared metabolic enzyme → drug substrate, were successfully detected through controlled graph traversal, confirming that the constructed knowledge graph supports the mechanism-constrained reasoning required for downstream inference tasks.
To demonstrate the integrated capabilities of DHFI-C, a comprehensive use case was constructed to reflect a realistic and clinically complex interaction assessment task. The use case was designed to simultaneously exercise disease-driven input assistance, mechanism-based inference, condition-level interaction interpretation, and multi-domain interaction integration within a single workflow.
Use Case description
A 72-year-old male with stage 3 chronic kidney disease and chronic cardiovascular disease with atrial fibrillation was assessed using DHFI-C. The patient is prescribed metoprolol, warfarin, digoxin, lamotrigine, and a fixed-dose combination product containing ezetimibe/simvastatin.
The patient also reported chronic knee pain and was self-administering ibuprofen, while naproxen was recently prescribed by a physician. In addition, the patient self-administers Ginkgo biloba supplements, regularly consumes grapefruit and goji berry juice, and uses melatonin for sleep. The patient was an active smoker.
This regimen encompasses drug–drug, herb–drug, food–drug, condition–drug, and disease-driven input contexts involving both pharmacokinetic and pharmacodynamic mechanisms, as well as condition-dependent modifiers related to age, renal impairment, smoking status, and chronic disease.
The complete operational workflow of DHFI-C as applied to this comprehensive use case is illustrated in Figure 3A–B. The figure summarizes the end-to-end processing pipeline, including entity normalization, curated interaction retrieval, mechanism-based inference, and integrated dual-mode output presentation.
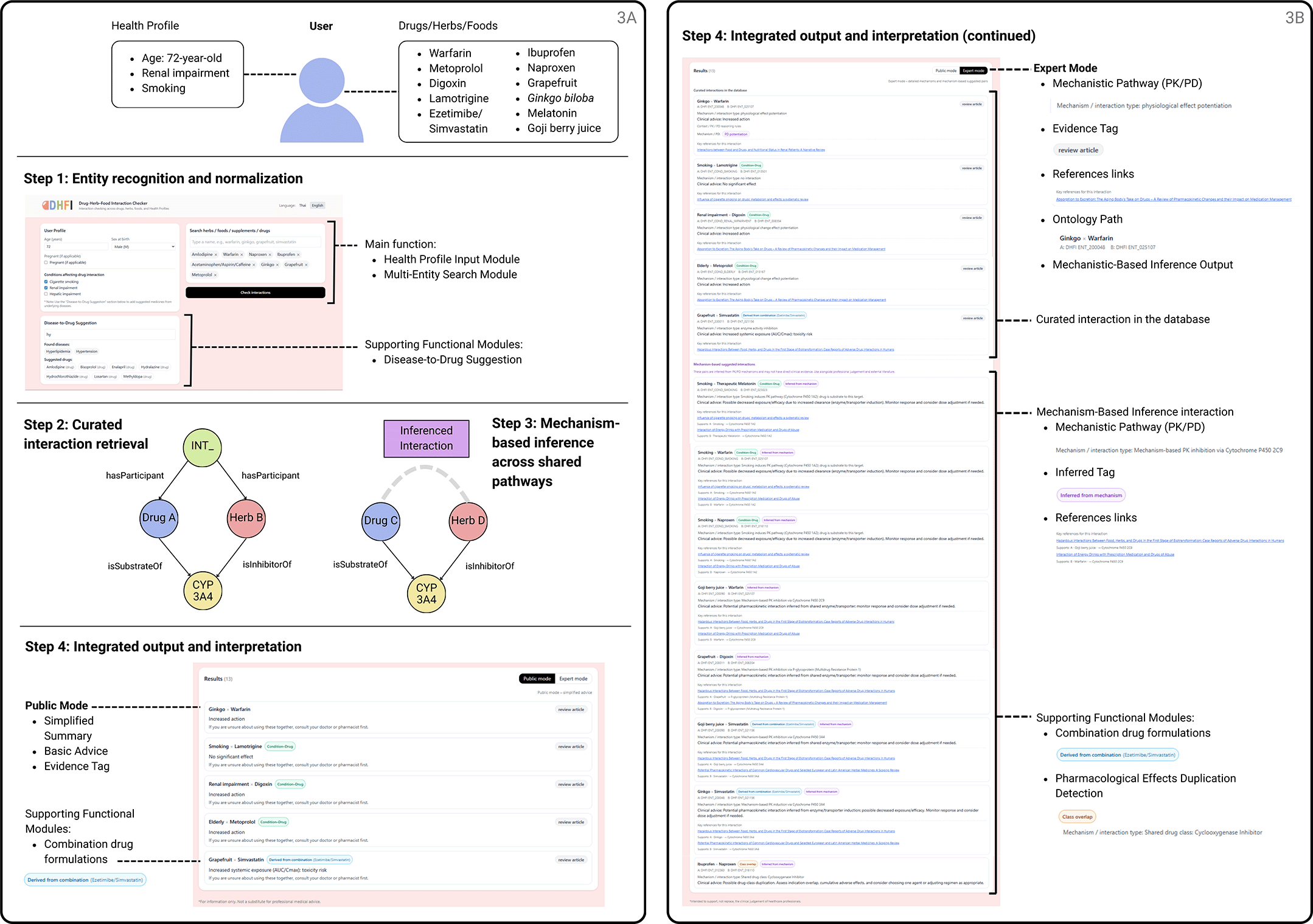
(A) Upstream interaction assessment pipeline. User inputs include health-related conditions (e.g., age, renal impairment, smoking) and substances (drugs, herbs, foods). Step 1 performs entity recognition and normalization through the health profile and multi-entity search modules, with optional disease-to-drug suggestion support. Step 2 retrieves curated interaction records stored in the knowledge graph. Step 3 performs mechanism-based inference across shared pharmacokinetic (PK) and pharmacodynamic (PD) pathways, such as enzyme- and transporter-mediated mechanisms.
(B) Integrated output and interpretation layer. Results are presented in dual modes. The public mode provides simplified summaries, basic advice, and evidence tags. The expert mode displays detailed mechanistic pathways (PK/PD), ontology paths, reference links, and explicit distinction between curated database interactions and mechanism-based inferred interactions. Supporting functional modules include combination drug handling and pharmacological effect duplication detection.
Step 1: Entity recognition and normalization.
Upon input, DHFI-C identified and normalized all substances, health-related conditions, and underlying diseases to standardized entity representations within the knowledge graph. Prescription drugs, herbal products, food items, smoking status, advanced age, and chronic kidney disease were resolved to their corresponding entities.
For the Disease-to-Drug Suggestion module, when “Cardiovascular disease” was entered as an underlying disease, the module returned a shortlist of representative antiarrhythmic medicines based on curated condition–drug associations, allowing digoxin—which is part of the patient’s existing regimen—to be selected without manual entry of the drug name. Combination drug formulations were decomposed into their constituent active components, enabling ezetimibe and simvastatin to be treated as independent entities while preserving traceability to the original combination product. All entities were linked to relevant drug classes, protein targets, metabolic enzymes, transporters, pharmacodynamic effect descriptors, and conditions. The system recognized the presence of a multi-domain interaction context rather than treating interactions as isolated substance pairs.
Step 2: Curated interaction retrieval.
The system retrieves curated interaction records supported by structured evidence. These included pharmacokinetic interactions between simvastatin and grapefruit mediated by CYP3A4 inhibition, and pharmacodynamic interactions between warfarin and G. biloba associated with increased bleeding risk. In addition, pharmacodynamic overlap between ibuprofen and naproxen was identified based on shared anti-inflammatory and analgesic effects.
Condition-level reasoning further contextualizes the interpretation of interactions by incorporating physiological modifiers. Advanced age was associated with altered pharmacodynamic sensitivity, resulting in potentiation of beta-blocker–related effects for metoprolol. Chronic kidney disease modifies the pharmacokinetics of digoxin by reducing clearance and increasing systemic exposure.
Smoking status was evaluated as a condition-level modifier for relevant drug entities. While smoking-related induction mechanisms were considered for multiple substrates, lamotrigine was not considered to have clinically meaningful interactions with smoking-related pathways. This outcome was explicitly represented as a no-interaction interpretation, rather than being omitted. All curated interactions were explicitly labeled and distinguished from the inferred results.
Step 3: Mechanism-based inference across shared pathways.
Beyond curated records, DHFI-C generated inferred interactions through shared mechanistic pathways encoded within the knowledge graph. Smoking status was associated with the induction of CYP1A2-related mechanisms, leading to inferred pharmacokinetic interactions affecting melatonin, which is a CYP1A2 substrate.
In addition, Goji berry juice, represented as a CYP2C9 inhibitor, enabled mechanistic inference of altered warfarin exposure through shared metabolic pathways. These inferred interactions were generated independently of pre-enumerated interaction pairs and were accompanied by transparent explanations tracing the underlying mechanistic reasoning paths within a knowledge graph.
Step 4: Integrated output and interpretation.
The final interaction output presents a consolidated view of curated interactions, inferred interactions, condition-mediated interpretations, pharmacological effect duplication alerts, and no-interaction assertions across drug–drug, herb–drug, food–drug, condition–drug, and disease-driven input domains. The consolidated interaction outputs generated for this use case are listed in Table 4.
Evidence-supported interactions and mechanism-inferred interpretations were clearly differentiated. Supported no-interaction outcomes were explicitly reported when available evidence indicated no clinically relevant interaction, whereas entity pairs for which no interaction output was generated were clearly interpreted as reflecting insufficient or unavailable evidence rather than a confirmed absence of interaction. This distinction was communicated within the output to ensure a transparent interpretation of system results. Mechanistic explanations and the decomposition of combination drug products are displayed cohesively.
This integrated presentation enabled users to understand not only which interactions were identified but also how pharmacokinetic, pharmacodynamic, physiological, disease-context, and formulation-level factors jointly shaped interaction relevance within the specific use case.
This section summarizes the system-level capabilities demonstrated by DHFI-C through a comprehensive use case evaluation. The assessment confirmed that DHFI-C supports mechanism-based interaction reasoning grounded in explicit pharmacokinetic and pharmacodynamic pathways, with clear distinction between curated evidence and mechanism-based inferred interactions. The system consistently provides transparent mechanistic explanations, enabling the traceable interpretation of interaction outcomes.
The capabilities evaluated in the use case are summarized in Table 5.
| Use-case-driven capability | Capability assessed | DHFI-C support | Evidence demonstrated in use case |
|---|---|---|---|
| Multi-domain interaction checking (drug, herb, food, condition) | Unified handling of heterogeneous interaction domains | ✓ Supported | Single integrated use case (Section 3.6) |
| PK/PD mechanism inference beyond explicit pairs | Inference via shared enzymes, transporters, and targets | ✓ Supported | CYP1A2 (smoking–melatonin), CYP2C9 (goji berry juice–warfarin) |
| Explicit distinction: curated vs inferred interactions | Separate labeling of evidence-based and inferred results | ✓ Supported | Clear differentiation in use case outputs |
| Condition-level interaction interpretation | Mechanistic modification based on physiological conditions | ✓ Supported | Age–metoprolol, Renal impairment–digoxin interpretation |
| Therapeutic duplication detection | Identification of overlapping pharmacological effects | ✓ Supported | Demonstrated via pharmacodynamic effect analysis |
| Drug combination decomposition | Decomposition of multi-ingredient products into active components | ✓ Supported | Drug inputs handled at the component level |
| Disease-to-drug suggestion support | Disease-driven input assistance for medication selection | ✓ Supported | Cardiovascular disease → digoxin inclusion |
| Consumer and professional user views | Dual-mode presentation of interaction outputs | ✓ Supported | Public vs expert-oriented explanations |
| Machine-readable/ontology-aligned output | Structured, ontology-linked interaction representation | ✓ Supported | Mechanistic paths and ontology references in output |
The characteristics of the DHFI-C dataset distinguish it from existing drug–drug and food–drug interaction resources in several important ways. A defining feature of the platform is the scale and granularity of its drug entity representation, which comprises over 24,000 drug entities derived from the National Cancer Institute Thesaurus (NCIT).30 This level of granularity reflects NCIT’s fine-grained subdivision of pharmacologic substances, including explicit representation of salt forms and stereochemical variants of drugs, as well as related pharmacologic categories such as multidrug resistance modulators, adjuvants, and radiopharmaceutical compounds. DHFI-C can accommodate interaction evidence that specifies particular drug forms, such as S-warfarin or warfarin sodium, rather than collapsing all variants into a single generic label. This design supports form-specific interaction interpretation and aligns more closely with the way pharmacokinetic and pharmacodynamic interactions are reported in the literature, thereby enabling more precise mechanism-based reasoning than that possible in systems that rely on aggregated drug representations.
In addition to its drug coverage, the DHFI-C incorporates a broad and culturally diverse set of herbal entities, including widely used medicinal herbs and components of traditional Chinese medicine. This includes commonly used herbs such as Astragalus membranaceus (Huangqi) and Cassia (Cassia fistula),10 as well as other botanicals frequently encountered in integrative and traditional medicine practices. This scope extends the drug–herb interaction space beyond that typically represented in public interaction checkers or ontology-centric repositories, which often focus on a limited subset of Western herbal products. By capturing a wider range of commonly used herbal substances,38 the dataset enhances the real-world relevance of interaction assessment, particularly in settings where patients routinely combine prescription medicines with traditional or culturally specific remedies. Together, the granularity of drug representation and the breadth of herbal coverage position DHFI-C as a dataset designed not merely for interaction lookup but for context-aware, mechanism-driven interpretation across diverse medication and product use cases.
The ontology mapping results reflect a hybrid design using external ontologies where semantically appropriate, while employing a domain-specific mini-ontology for interaction reasoning where existing resources were insufficient. Core biomedical entities were aligned with established ontologies for interoperability, while health conditions and pharmacodynamic effects were represented internally as contextual modifiers for interaction interpretation.
This hybrid approach enables the DHFI-C to balance semantic interoperability with mechanistic interpretability. By avoiding forced alignment of condition and effect concepts to disease- or molecule-centric ontologies, the system maintains transparent, mechanism-aware reasoning without semantic distortions. Simultaneously, retaining external mappings for stable biomedical entities ensures that DHFI-C remains compatible with existing knowledge ecosystems and FAIR-aligned infrastructures. This design positions the DHFI-C between ontology-centric systems focused on formal completeness and conventional interaction databases lacking semantic depth, supporting context-aware interaction assessment while remaining extensible as new ontology standards emerge.
The use case in Section 3.5 demonstrates how DHFI-C enables interaction assessments beyond standard interaction-checking platforms. The use case evaluates prescription drugs, herbs, foods, lifestyle factors, and health conditions within one workflow to identify interactions. This evaluation examines system capabilities during realistic assessments rather than relying on feature lists or dataset coverage.
Based on the qualitative capability assessment summarized in Table 6, commonly used interaction checkers, including DrugBank (https://go.drugbank.com),39 Medscape (https://reference.medscape.com/drug-interactionchecker ), Drugs.com (https://www.drugs.com/drug_interactions.html), and DDInter 2.0 (http://ddinter2.scbdd.com),5 were observed to provide partial support for multi-domain interaction checking, primarily through explicitly curated substance pairs (all accessed January 2026). However, within the evaluated use case context, these platforms did not demonstrate mechanism-based inference beyond predefined interaction records, nor did they explicitly distinguish between evidence-supported interactions and interactions inferred through mechanistic reasoning pathways.
| Use-case–driven capability | DHFI-C | DrugBank | Medscape | Drugs.com | DDInter 2.0 |
|---|---|---|---|---|---|
| Multi-domain interaction checking (drug, herb, food, condition) | ✓ | Partial | Partial | Partial | Partial |
| PK/PD mechanism inference beyond explicit pairs | ✓ | ✗ | ✗ | ✗ | ✗ |
| Explicit distinction: curated vs inferred interactions | ✓ | ✗ | ✗ | ✗ | ✗ |
| Condition-level interaction interpretation | ✓ | ✗ | ✗ | ✗ | ✗ |
| Pharmacological Effects Duplication Detection | ✓ | Partial | ✓ | ✓ | ✓ |
| Drug combination decomposition | ✓ | ✗ | ✗ | ✗ | ✗ |
| Disease-to-drug suggestion support | ✓ | ✗ | ✗ | ✗ | ✗ |
| Consumer and professional user views | ✓ | ✗ | ✗ | ✓ | ✗ |
| Machine-readable/ontology-aligned output | ✓ | ✗ | ✗ | ✗ | ✗ |
A key differentiating capability demonstrated by the DHFI-C in the use case is the condition-level interaction interpretation. While comparator systems typically present age, renal impairment, or lifestyle factors as static warnings or advisory annotations, the DHFI-C incorporates health-related conditions directly into mechanistic reasoning processes. In the demonstrated use case, age-related physiological changes and chronic kidney disease modified the interaction interpretation for metoprolol and digoxin, respectively, while smoking status enabled mechanistic inference through CYP1A2-associated pathways. Such condition-inclusive reasoning behavior was not observed in the evaluated comparator platforms in the same assessment context.
Additional capabilities exercised in the use case, including drug combination decomposition, disease-to-drug suggestion support, and pharmacological effect duplication detection, further differentiate DHFI-C from existing interaction checkers. Although therapeutic duplication alerts are supported by several platforms, the DHFI-C uniquely integrates this function within a broader mechanism-driven and context-aware interaction assessment framework. Taken together, these observations indicate that the comparative advantage of DHFI-C lies not in any single feature in isolation but in the coordinated integration of mechanistic inference, condition-inclusive reasoning, and multi-domain interaction handling within a transparent and reproducible assessment workflow.
The coverage of herb and food entities remains limited, reflecting the relative scarcity of publicly available, mechanism-resolved evidence for these product categories. Although widely used in real-world settings, many herbal and food-related interactions have been reported descriptively rather than with explicit pharmacokinetic or pharmacodynamic characterizations. As additional open-access literature and structured repositories emerge, the dataset can be systematically expanded to enhance both its completeness and mechanistic granularity.
The current Mechanism-Based Inference Engine is implemented as a deterministic, rule-based system operating over graph-encoded pharmacological knowledge. This design enables transparent and reproducible mechanistic interpretation but does not provide probabilistic risk estimation or a predictive confidence score. Future studies may explore complementary data-driven approaches, such as knowledge graph embeddings, graph neural networks, or transformer-assisted evidence extraction, provided that the interpretability and traceability of inferred interactions are preserved.
Further validation using independent real-world datasets and expert-reviewed case collections represents an additional direction for strengthening the generalizability and practical utility of the platform as the curated evidence base continues to expand.
This study aimed to address the structural and methodological limitations of existing interaction-checking systems, particularly their restricted support for multi-domain interaction assessment, condition-inclusive interpretation, and transparent mechanistic reasoning. Through the design and implementation of DHFI-C, these challenges were addressed by integrating drugs, herbs, foods, health-related conditions, and underlying diseases within a unified knowledge graph and inference framework.
The results demonstrate that DHFI-C operationalizes mechanism-based interaction reasoning across pharmacokinetic and pharmacodynamic domains, while explicitly distinguishing curated evidence from mechanism-derived interpretations. The system further supports condition-level interaction interpretation, drug combination decomposition, disease-driven input assistance, and pharmacological effect duplication detection within a single coherent assessment workflow.
By combining these capabilities within a transparent, ontology-aligned, and machine-readable architecture, the DHFI-C establishes a methodological foundation for context-aware interaction assessment that extends beyond the scope of existing public interaction-checking tools. This framework provides a basis for future expansion as additional evidence sources, interaction domains, and reasoning strategies become accessible.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)