Keywords
Smoking prevalence; ASEAN; Machine learning; Forecasting; Tobacco tax; Public health policy
This article is included in the Global Public Health gateway.
Smoking prevalence; ASEAN; Machine learning; Forecasting; Tobacco tax; Public health policy
Smoking is one of the major causes of preventable death in the ASEAN region, accounting for over 10% of all global smoking related deaths (Dai et al., 2025). Despite the World Health Organization’s (WHO) target to reduce adult smoking prevalence by 30% from 2010 to 2030, there has been limited progress across ASEAN countries (World Health Organization, 2023). The smoking trends for the ASEAN countries were clustered ( Figure 1) and forecasted aggregate smoking prevalence can also be seen ( Figure 2). Few studies have explored the impact of future policies on this goal and have used complex methods that are difficult to reproduce.
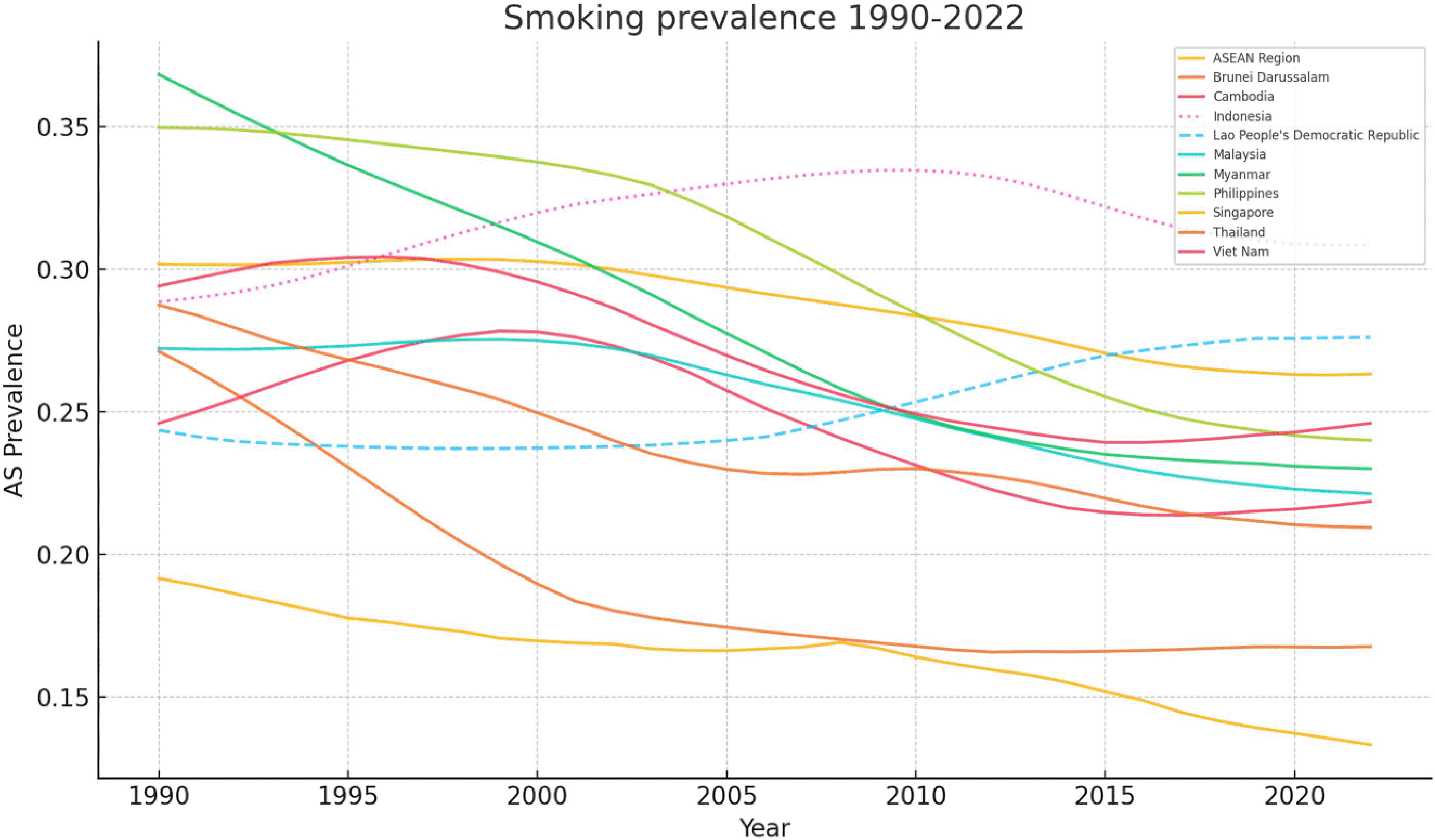
The age standardized smoking prevalence rates for all 11 ASEAN countries can be seen over the period of 1990–2022 for both sexes. Each coloured line represents a different country indicated by the key and illustrates historical trends in smoking prevalence.
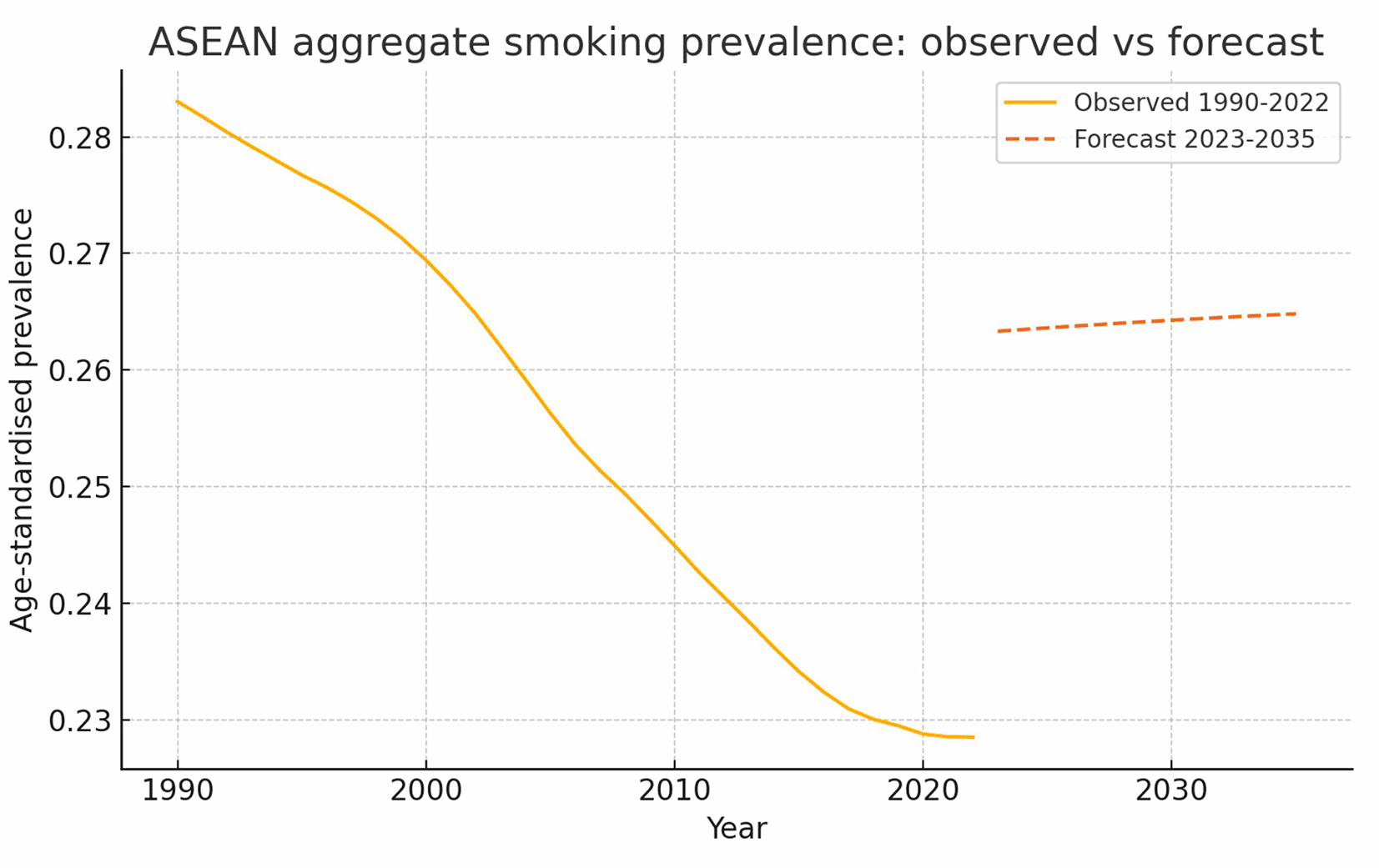
The forecasted age standardized smoking prevalence rates for both sexes were generated using the stacked LSTM model based on previous trends. The dashed lines represent the predicted average prevalence across all ASEAN countries from 2023 to 2035. The solid line illustrates the actual observed average smoking prevalence for all 11 ASEAN countries from 1990 to 2022.
Long short-term memory (LSTM) networks are types of machine learning (ML) models that have proven to be promising in forecasting public health trends and predicting future behaviours (Hochreiter and Schmidhuber, 1997). These models have performed well in predicting infectious disease outbreaks but have not been used in tobacco control.
This study aimed to build a ML tool that could be operated without additional software and could: help group ASEAN countries based on past smoking trends, produce reliable forecasts up to 2035 and thirdly simulate the impact on health of introducing new policies such as increased tobacco tax.
Open-access datasets from the Global Burden of Disease Study 2021 were used (Dai et al., 2025) to access age-standardized smoking prevalence rates from 1990–2022 for 11 ASEAN countries (Institute for Health Metrics and Evaluation, 2024b). Alongside this, additional variables such as GDP per capita, tobacco tax levels and tobacco control scores were included if available. Smoking attributable disease burden (DALYs) were also collected from Global Burden of Disease 2021 (GBD 2021) (Institute for Health Metrics and Evaluation, 2024a).
Of the data collected, we filtered out only age-standardised, both sex prevalence rates that had no missing values and each country’s smoking history was presented as a 33-year timeline. The 11 countries were then grouped into three clusters using a time series method called Dynamic Time Warping (DTW-kM). When this was unavailable, the system defaulted to a simpler method using Euclidean distance.
We built a machine learning model (stacked LSTM network) that predicted future smoking trends based on the past six years of data. This model’s output was then compared with two current baselines: ARIMA (a traditional statistical model) and a naive model, which assumed no change. Dropout sampling was also used to estimate uncertainty, and built-in validation was used to compare forecast accuracy from 2018–2022.
Policy changes were simulated using a tool in the model such as a 15% tobacco tax rise in 2026 which was modelled to estimate its effect on smoking rates and related disease burden. DALYs were adjusted based on known elasticities (0.7% DALY reduction per 1% drop in prevalence) (Nazar et al., 2021).
The 11 ASEAN countries were categorized into three main groups based on their smoking trends:
Early Convergers – Singapore, Brunei: had already reduced smoking prevalence to below 15% by 2022.
Mid Decliners – Malaysia, Philippines, Thailand: have experienced a steady decline of 1.2 percentage points (pp) per year since 2005.
Late Stagnators – Indonesia, Myanmar, Vietnam: which still have high smoking rates of around 28% with little recent progress.
The LSTM model outperformed the ARIMA model in 9 out of 11 countries. The median absolute error from 2018 to 2022 was lower for LSTM (0.32 pp, 95% CI: 0.26–0.40) than for ARIMA (0.46 pp, 95% CI: 0.39–0.57), with a statistically significant difference (p < 0.01).
Based on current trends, the average smoking rate in the ASEAN countries will decrease modestly from 26.3% in 2022 to 24.6% by 2035 if current trends continue. Singapore is the only country projected to achieve the WHO target of less than 30% by 2030 (World Health Organization, 2023).
This lightweight machine learning tool is the first that has been developed to forecast smoking prevalence across ASEAN countries. The study creates opportunities for shared learning and policy collaboration as it groups countries based on past smoking trends. For example, Malaysia’s trajectory closely mirrors that of the Philippines and Thailand, while Indonesia’s trends resemble those of Myanmar and Vietnam.
The results show that LSTM models have higher accuracy when compared to traditional ARIMA methods which is also consistent with what has been seen in infectious disease forecasting. The LSTM model is highly practical in low-resource settings such as government health departments or public health NGOs due to it not requiring external software installations.
Based on current policies, without stronger action, most ASEAN countries will clearly not meet the WHO target of a 30% reduction in smoking prevalence by 2030. Smoking rates could be significantly reduced, and over 1 million years of life lost to smoking-related disease could be prevented with interventions such as a 15% increase in tobacco taxes.
In the future, more detailed data such as age and income could be incorporated. The model could also be expanded by exploring e-cigarette usage and vaping using advanced machine learning methods such as Temporal Fusion Transformers to improve the accuracy and applicability of the study.
We developed a simple machine learning tool that does not require installation and can predict smoking trends while assessing policy impacts across ASEAN. Based on our analysis, most countries will not achieve the WHO target unless stronger tobacco control measures are implemented. Even a modest tax increase could avoid over a million DALYs. The overall framework is also adaptable to other public health areas without external software installation.
Source code available from: https://github.com/awabahmad469/smoking-analysis
Archived source code at: https://doi.org/10.5281/zenodo.17499927
License: MIT.
This software is based on code originally published by Mahmood Ahmad (DOI: https://doi.org/10.5281/zenodo.17095791) and has been reused and extended with permission under the MIT License.
Ethical approval and consent were not required for this study as it used publicly available, deidentified datasets and there was no direct involvement from human participants.
The primary data on smoking prevalence and disease burden were obtained from the Institute for Health Metrics and Evaluation (IHME) Global Burden of Disease Study 2021, accessible at https://ghdx.healthdata.org/record/ihme-data/gbd-2021-asean-smoking-prevalence-burden-1990-2021 (accessed 30 July 2025).
Additional variables and processed datasets generated for analysis, including extrapolations to 2022 and policy simulation inputs, are publicly archived on Zenodo at https://doi.org/10.5281/zenodo.17095791, enabling full reproducibility by readers and reviewers.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)