Keywords
evolution, plagiarism, science, academic, artificial intelligence, publishing, journal
This article is included in the Research on Research, Policy & Culture gateway.
evolution, plagiarism, science, academic, artificial intelligence, publishing, journal
Science progresses as we incrementally build on the discoveries of our predecessors, slowly expanding the human race’s knowledge. It is therefore inevitable that we, to paraphrase Isaac Newton, will stand on the shoulders of giants that preceded us in order to be able to see further and add another stone to the edifice. In doing so, we must acknowledge the existence of these giants and credit them for their labours. Giving credit where it is due, however, is a complicated matter.
Plagiarism is defined in the Merriam-Webster dictionary as the act of stealing and passing off the ideas or the words of another as one’s own without giving proper credit. Its etymological roots stem from the Greek word “plagion”, which was then incorporated into Latin as “plagiarius”, meaning kidnapper. This can take many forms, such as direct copy-pasting, paraphrasing, self-plagiarism, using a patchwork of another person’s work, data plagiarism and, finally, plagiarising another person’s idea. Plagiarism is highly discouraged in the academic world, with major sanctions being levied on those who commit it. Plagiarism is the primary method in which the academic integrity of institutions of higher education is breached. (Sozon et al. 2024).
We should first acknowledge that there are, of course, deliberately bad actors who will try to appropriate the ideas of others. This re-appropriation of ideas can sometimes be blatant, as wholesale stealing of another’s paper with only minor modifications or trying to pass off a figure as one’s own. (Bejan and Lorente 2012; Saliba and Rotzinger 2025) This is, of course, highly reprehensible and should be avoided by authors and punished by editors when it is discovered. On top of having their paper retracted, authors found guilty of plagiarism may suffer significant damage to their reputation, potentially leading to the loss of funding or even their positions. In certain instances, plagiarism involving copyright infringement can also result in legal action. It is, as Petress described it, “the plague of our profession”, underlining the proportions which it has taken. (Petress 2003) This lack of ethics inevitably leads to the slow erosion of the integrity of our academic institutions. It therefore begs the question: how can we fight these bad actors? The first line of defence is, of course, the reviewers. The hope is that the reviewer, who should be knowledgeable in their field and have a good general overview of the literature, would be able to spot suspected attempts at plagiarism and inform the editor. (Yadav and De 2013) Once the editor is involved, it is up to them to contact the potentially guilty party and to receive their attempts at rebuttal. (Yadav and De 2013) Based on this, they will decide whether or not to pursue the case, and, depending on how egregious the case of plagiarism is, they may find it appropriate to escalate the matter to the department of the offender or even a national or supranational institution. (Yadav and De 2013) This initial screening does indeed work as a gatekeeper and catches many would-be plagiarists, as evidenced by one editor claiming that 10% of the papers received get rejected due to plagiarism. (Foltýnek et al. 2019) While one might hope that this process would deter most potential plagiarists and catch those who attempt it, many problematic papers still make it through the initial screening, only to be exposed and retracted later. This is evident from the 10,000 papers retracted in 2023. If we accept estimates that plagiarism accounts for 9.8% to 17% of retractions, this would mean around 1,700 cases of plagiarism. (Amos 2014; Van Noorden 2023) Of course, this assumes that every instance is detected, which is certainly not the case.
Assuming that an article makes it through peer review only to be caught by an author who recognises that their own work has been plagiarised, what can they then do? One course of action is to directly contact the journals to expose the plagiarism, either privately by emailing the editors or publicly through letters to the editor. Examples exist of researchers noticing work that is highly similar to their own, written by authors who show more than a passing familiarity with their work, who then bring this to the attention of the public via a letter to the editor. (Kim et al. 2008; Bejan and Lorente 2012) There are other examples of researchers reinventing another’s work or ideas but using a novel, but oftentimes empty and meaningless, term to disguise the fact. (Bejan 2014) This misappropriation can be especially harmful to science, not only muddying the waters as to where a concept comes from, but also creating a false impression of substantial progress by presenting recycled concepts as genuine scientific advancement. (Bejan 2014) What’s more, these papers, once published, and de-facto accepted into the scientific corpus, can then provide the basis for the genesis of many other papers. (Bejan 2014) This can spawn a new generation of literature that is, at best, useless and, at worst, serves to mislead scientists into conducting useless research and may even surplant the actual science by sheer weight of publications. (Bejan 2014, 2018) Furthermore, this phenomenon can be amplified if the plagiarised subject matter becomes entrenched in certain academic or geographic circles, leading to an echo-chamber effect amplifying the flawed science. (Bejan 2020).
The reasons for such deliberate acts of plagiarism are manifold. Characteristics related to each individual undoubtedly play a part, as older and more academically mature students tend to be less tolerant of cheating and less likely to engage in it themselves.(Landa-Blanco et al. 2020) Academic pride, however, has been shown to have a relationship with plagiarism, though academic skill has not. (Sozon et al. 2024) Social factors also play a role, with individuals being judged on their ability to produce articles in line with the current “publish or perish” academic paradigm.(Al-Adawi et al. 2016).
Further pressure can exist due to the incentive that universities have to maintain their ranking, which partially relies on citations resulting from their academic output. (Bejan et al. 2020) This in turn incentivizes individual researchers to accumulate as many citations as possible both for themselves and their institutions, with highly cited academics continuing to contribute to the citations attributed to their universities, sometimes even after their own death. (Bejan et al. 2020).
Given the stress that this can put on academics, it is little wonder that some may be tempted to violate their ethics. Systemic issues, such as the pressure on medical clinicians to publish for advancement, also contribute to the problem, as some may simply opt to purchase someone’s work instead. (Schneider 2021) This perfect storm of pride, social factors, and establishment pressure has resulted in the creation of an entire industry of so-called “paper mills” devoted to the production of academic literature that individuals can purchase and then passed off as their own.
Academics purchasing work from paper mills, other academics, or hired ghostwriters can also be seen as a form of plagiarism for hire, as one is purposefully purchasing a manuscript with the explicit aim of surreptitiously passing it off as their own. In these cases, scholars can either purchase an entire manuscript or simply a co-author position to help raise their academic standing. (Abalkina 2023) Fortunately, some clues can point to inauthentic authorship, such as an author having few papers, authors never having written about a particular field before, unlikely author combinations from different institutions, and inconsistent quality throughout the manuscript, amongst others. (Mason and Maria Sol Bernardez 2016; Abalkina 2023).
Another way that academics can claim ideas for their own is through what is called guest authorship. Though sometimes used as a mark of membership in an academic team, such as is common in some fields of physics where exceedingly large authorship lists are common, there are what are termed hyperprolific authors that seemingly publish an unlikely number of papers by these means. (Ioannidis et al. 2018) To define a true contributor to a project, the Vancouver criteria of the ICMJE are commonly used, which state that authorship should be given based on 4 criteria at a minimum. The first criterion is substantial contributions to the conception or design of the work or the acquisition, analysis, or interpretation of data for the work. The second is drafting the work or reviewing it critically for important intellectual content. The third is final approval of the version to be published, and the fourth is agreement to be accountable for all aspects of the work and ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. However, when questioned, many of these hyperprolific authors admitted to not fulfilling these criteria, though they also often said that they did not consider themselves authors of the papers and thus did not often include them on their CVs. (Ioannidis et al. 2018).
There are also, of course, other forms of plagiarism and misattribution which are less deliberate but nonetheless deleterious. As the body of knowledge grows, it becomes increasingly complex to attribute credit accurately. Every researcher has encountered a piece of information and wondered about its origin. Most have tried to trace such sources and understand firsthand how challenging it can be. This quest for the source often results in following a series of references, with the original paper often being lost to time or inaccessible behind a paywall. One must therefore face the dilemma of either quoting a source, knowing it may not be the original, or citing a reference without being able to verify that it is, in fact, the original source.
Should we therefore merely acknowledge the last link in the chain as the most convenient and simple solution? This would require us to acknowledge that we often cite non-original sources, or that the original idea may have become distorted through the various citations and rewordings by different authors. We would also have to be aware of impact on careers, whereby an idea of a relatively unknown academic in an obscure journal may be cited by a better-known academic in a larger journal, resulting in only the second academic’s paper being cited due to their notoriety and the overall tendency to cite larger journals over smaller ones (Galiani et al. 2018). This problem is compounded by articles in larger journals, which tend to remain cited for more extended periods compared to the “flash in the pan” phenomenon that can occur for successful articles in smaller journals (Galiani et al. 2018).
This issue is further complicated by journals often explicitly stating that they expect article citations that are recent, or “timely”, while also having a limit on the number of cited articles. This encourages authors to cite articles that amalgamate other sources and thus fail to attribute credit to the original articles. It should be noted, however, that the American Psychological Association does not specify that this criterion be taken into account in its guidelines, indicating some heterogeneity within academic circles (Greenbaum 2021). It is, however, undeniable that over time, the number of citations a paper will receive will shrink. One study that looked at citation patterns found that the most extended lifespan that an article could reasonably expect was 20 years, with the average paper achieving peak relevance in its third year. However, this pattern varies significantly by each field (Mendoza 2021). However, this citation growth phenomenon often follows an “S-shaped” curve, growing slowly at first before rapidly increasing and then slowing down again, mimicking a pattern that is commonly found in a great number of natural phenomenon. (Bejan 2019; Bejan et al. 2020).
Furthermore, as the scientific environment becomes ever more focused on personal and journal metrics, there is an increasing incentive for both scientists and journals to focus on the publication of review articles and meta-analyses due to their increased citation potential (Bonora 2022). One can explain this as, in the current scientific paradigm, meta-analyses are the most-cited type of scientific work, with many original articles going uncited even after many years (Patsopoulos et al. 2005; Nordmann et al. 2012; Royle et al. 2013). This has led to the rise of the so-called scientific “novelist” who focuses on recounting and amalgamating the research of others instead of producing original research themselves (Bonora 2022). Novelists, whose work acts as secondary sources, end up capturing the lion’s share of citations despite often providing relatively little true advancement in the field. If we take this idea to its logical conclusion, it would mean that, based on metrics alone, scientific novelists could appear to be the leading figures in their fields, despite making negligible original contributions.
Another fundamental issue to address is when an article becomes no longer citable. The prevailing opinion seems to be that the source of knowledge no longer needs to be cited when the information becomes “common knowledge” (The Exception: Common Knowledge 2025). However, common knowledge is a murky concept to define, as it varies depending on personal, cultural, and other contextual factors. To show the difficulty in defining this threshold, we can use the ancient Greek method of pushing an argument to its extreme. To illustrate this, we can take the example of the Earth being a sphere, which we can assume is generally considered common knowledge and thus does not require citation of Pythagoras, to whom the idea is commonly attributed (although it may predate him). However, in the spirit of absurd arguments, could the fact that flat-earthers exist mean that this is not common knowledge and thus must be considered citable information? This line of argument suggests that common knowledge is not a good standard to apply, since there will always be dissenting opinions. Therefore, suggesting that something is “common knowledge” is tantamount to invalidating the opinions of others and implying that the matter is settled.
It is also worth discussing how to handle ideas that evolve over time. Science is often like the ship of Theseus in that an original idea or discovery can evolve so much as to be unrecognisable over time, or even be proven incorrect. Nevertheless, it might have served as the foundation for much greater work. One example of this could be Mendel’s discoveries in the field of biological inheritance. Although his proposals still form the basis of our understanding of genetics and are taught in high school biology classes worldwide, research has progressed and shown that the subject is infinitely more complex than initially suggested. In his case, the originator of a theory is remembered despite science having progressed far beyond the original idea. However, it can also be the case that we remember only those who have made modern contributions to ideas, whilst relegating to obscurity those who have performed the fundamental works. Such is the case of Friedrich Miescher, who first discovered DNA in 1869, but whose fundamental contributions are overshadowed by Watson and Crick’s 1953 proposal of the double helical structure.
The rise of artificial intelligence (AI) and AI-generated or modified content adds yet another layer of complexity to the discussion of attribution. Artificial intelligence algorithms, such as large language models, use pre-existing works as training material. The resulting AI models are then utilized to answer questions or generate content in response to prompts. It is up for debate whether the output of these AI models can truly be considered original. Some have argued that, due to the AI essentially shuffling around the ideas or works of others, they can never truly create anything original (Khan 2024). If authorship is defined as requiring “the fruits of intellectual labour,” then AI can arguably be forever excluded due to lacking any tangible form of intellect (Caldwell 2023). So far, scientific publishers have taken a pragmatic approach to the issue, asking authors to declare whether they used AI to write a paper, while denying that AI can actually be considered an author.
As Professor Bejan discusses in his book, Time and Beauty – Why Time Flies and Beauty Never Dies, the waters are further muddied by the invention of terms such as “self-plagiarism” (Bejan 2022). Such terms are intrinsically illogical, as the concept of stealing an idea from oneself makes little sense. As Professor Bejan says, one owns what one creates (Bejan 2022). A distinction must still also be drawn with the act of re-publishing a work in a different language, which, if not explicitly stated to be a translation, can also be considered self-plagiarism.(Hvistendahl 2013).
As Professor Bejan also points out, there are ever-increasing financial incentives to commit plagiarism, as authors with the most citations receive the most acclaim, the most grants, and the most prestigious positions (Bejan 2022).
Yet another potential reason for underappreciation and misattribution of scientific contributions is the dominance of the English language in modern scientific literature. The fact that English is the main language is not in itself a problem, as it may, in fact, be argued that coalescing around a single language makes scientific endeavors easier. Nevertheless, this leads to articles written in other languages being overlooked, either because they are not accessible due to their potential audience not understanding the language, or because they are not included in the main databases, or simply excluded from the searches. For example, one group estimated that 36% of the current scientific literature on biodiversity conservation is not written in English, resulting in significant oversights and gaps in knowledge for those who cannot access these works (Amano et al. 2016). This could be a field in which automatic translation could increase the availability of these works, thereby expanding the dissemination of knowledge. On the other side of the equation, one should consider that anyone who is unable to publish in English will have their work underappreciated. Consequently, someone who publishes in a more commonly used language, with or without citing them, would be able to take credit for their idea (Bejan 2021). Even if an attempt is made to correctly attribute credit to the originator of an idea, if it was published in a language that few speak, their contribution will likely be forgotten or attributed to the first person to translate their idea into a more widely spoken language. This is exemplified by the misattribution of Prandtl and Dumitrescu’s idea regarding gas bubbles rising in a liquid-filled tube, first published in German in 1942, to Taylor by one of his students in 1969 in an English language journal (Bejan 2021). Although the idea had been published nearly 30 years earlier, it only became widely known once it was published in an English journal, erroneously cementing Taylor as the originator in the eyes of the broader public, who were not intimately acquainted with the history of fluid dynamics (Bejan 2021). Another notable example is the theory of the conversion of energy to heat, whose theoretical framework was set out by Robert Mayer in 1840 but attributed to James Joule, who continued and built on the work, by Peter Tait who wrote the first book on thermodynamics and wished to attribute credit to a compatriot (Bejan 2021). There are many more examples throughout history of attribution being given based on nationality or simply due to one author being forgotten because the language in which they published their work fell out of favour or was not widely used to begin with.
It is therefore both a practical and an ethical dilemma that is encountered when citing an article that itself cites another source of information. In our opinion, it is simply not feasible to always attribute the credit to the original source, for the aforementioned reasons. Nevertheless, it may be possible to somewhat alleviate the problem by creating an additional measure for article success that tracks both direct citations and the citations of articles that have cited the original source.
Let us imagine we have a first article written by J.S. (Article 1) that is cited by R.P. (Article 2). In this case, a citation would be attributed to Article 1 as is currently the case, which we shall call L1. Then let us imagine that O.A. now cites R.P. in a third article. Article 2 would thus gain a citation, but Article 1, on which Article 2 is partially based, would not receive any recognition for its contribution. This would continue so on and so forth with each subsequent article in the chain drawing further and further away from the original source of the information in Article 1. What we would suggest is to provide an attribution to the original article. Thus, when Article 3 cites Article 2, Article 1 would also receive a “secondary citation”, which we shall call L2. If a fourth article in the chain cites Article 3, then Article 2 would receive a secondary citation (L2), Article 1 would receive a tertiary citation (L3), and so on with L4, L5 etc. ( Figure 1). In order to avoid an exponential increase of the L-index, which would be inevitable as the chain of citing articles increases, we suggest applying a weighting whereby the L-index score would be halved for each article that separates it from the source. An article that directly cites the original would therefore be worth 1 point, an article citing the second article would be worth 0.5, a third would be worth 0.25 and so on. These would be displayed as an L-number for each level of citation, as well as a total score, allowing a person to see at a glance if the article was cited many times directly and how many indirect citation it received, as well as the total score. This would therefore allow the L-index of a given article to keep increasing incrementally, thus ensuring that it continues to contribute to its legacy, whilst avoiding exponential growth of the index simply due to the lengthening of the citation chain. We have provided a basic fictional schematic example in Figure 2. We also suggest that, in order to reduce the risks of author self-citations turning into a virtuous loop which artificially boosts their L-index, that these be considered as having one degree of separation greater than is truly the case. Therefore a direct citation would be considered a second degree citation and therefore count as 0.5 points towards the total L-index score. Furthermore, an article citing the self-citing article would continue as part of the chain and thus also suffer from a penalty ( Figure 3). This would serve a similar purpose as the ability to exclude self citations in some indexes (such as the H-index) whilst maintaining the ability of the author to show that they built on their own work. Although this may seem logistically daunting, as we already track which articles cite each other, we would simply be leveraging pre-existing information.
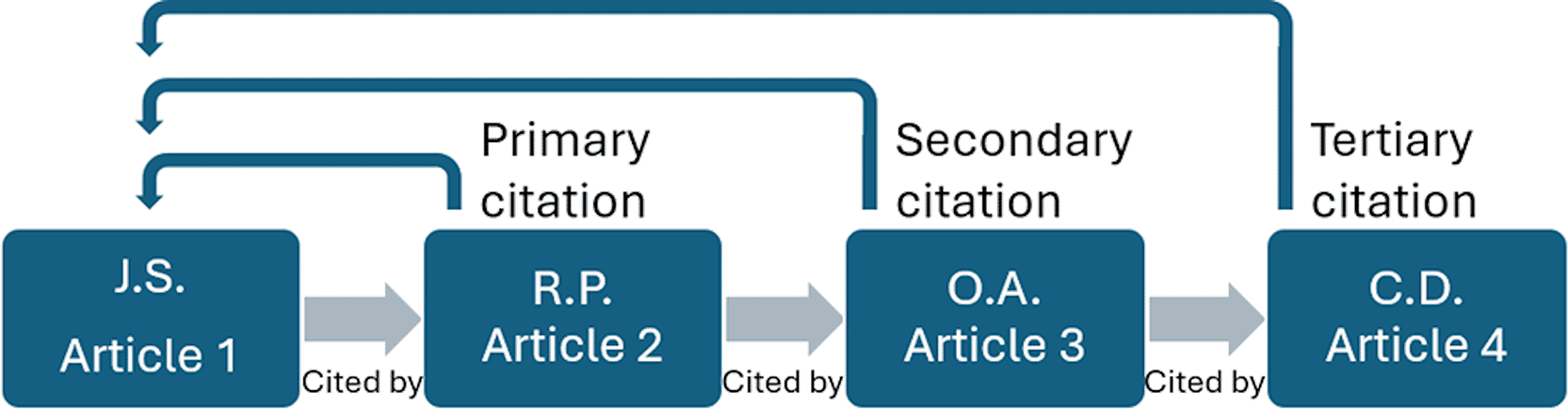
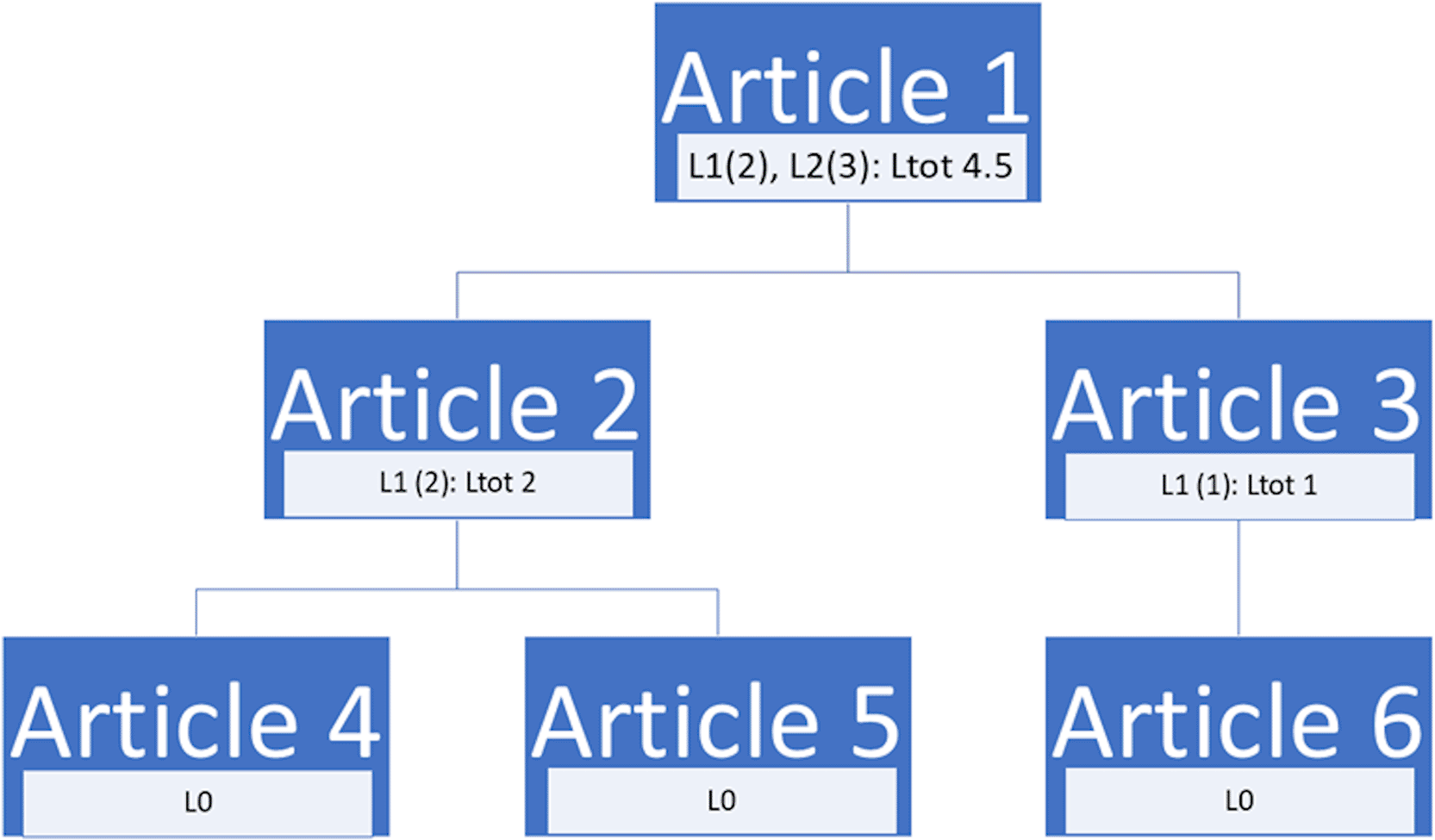
L1 represents direct citations (with a weighting of 1), L2 represents secondary citations (with a weighting of 0.5) and Ltot is the sum of citations scores which gives a total L-index score.
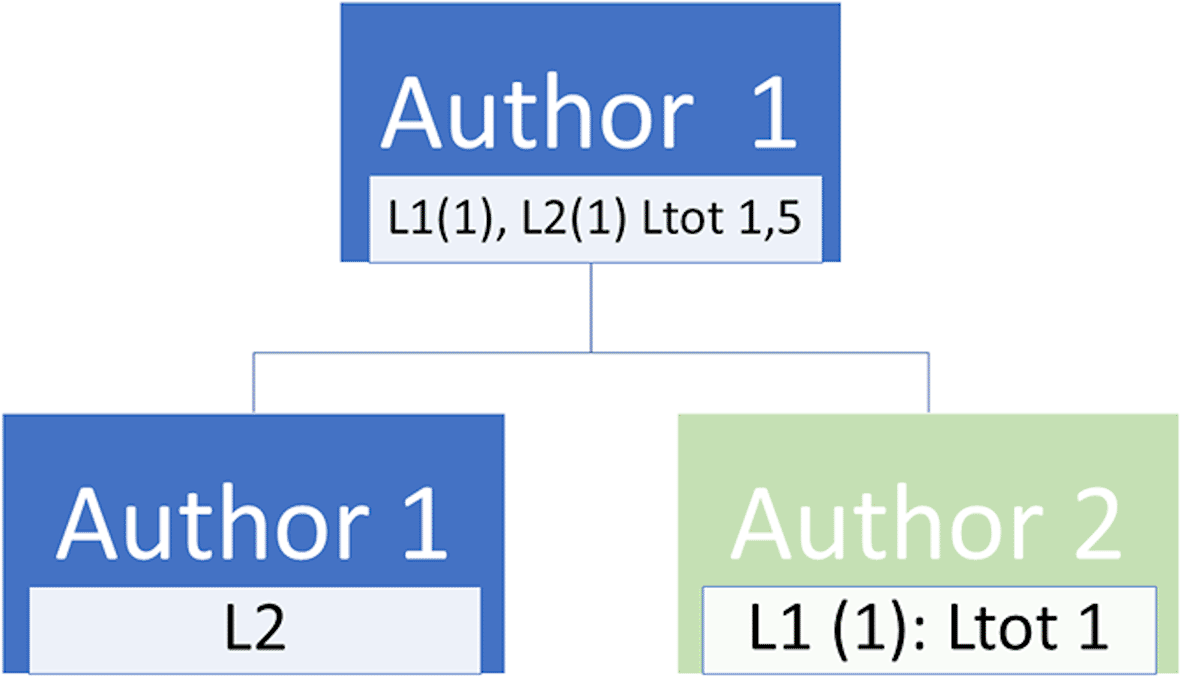
Therefore one direct citation (worth 1 point) and a direct self-citation (considered a secondary citation and thus worth 0.5 points) results in an L-index score of 1.5 for a given article.
In practice, this would create a way of measuring the impact of an article beyond its immediate lifetime and thus see how it might have been integrated into much larger articles, allowing the originators of important ideas to continue receiving credit, even if they may not be directly cited. This would show the larger impact of an article, whilst re-establishing the attribution chain of ideas, which is currently often broken as soon as a review article discussing the ideas is published. Furthermore, it would also provide a way of measuring its longevity and impact over time, allowing for a better analysis of which ideas persist and continue to be mentioned, and which fall out of favour. With this in mind, we propose calling it an L-index, with “L” standing for legacy, as the aim of this would be to capture the author’s contribution over the long term and their impact on the scientific community as a whole. Furthermore, it would allow an overview of fields as a whole and provide a structure analogous to an evolutionary tree or family tree for ideas. This would make it possible to see where ideas come from, which ideas prosper, at what point ways of thinking diverge, and finally which ideas die.
We should also consider the vulnerabilities of such an index. Just like all other indexes, people may excessively self-cite in an attempt to inflate their numbers, which may become exponentially more problematic due to the index’s chain of attribution. However, one might hope that authors would be less inclined to do so, safe in the knowledge that the chain of attribution will still show their work’s place in the field, ensuring that it will not be forgotten. Should this prove insufficient, creating an L-index that excludes self-citations, as is done for the H-index, may help reduce this problem. Nevertheless, it may remain vulnerable, as other indexes are, to citation cartels that attempt to artificially inflate paper citations by having groups of authors systematically and repeatedly cite each other’s work. (Fister et al. 2016).
Another issue may be the compounding of errors caused by misattribution as they would also be transmitted down the chain, with the wrong person being rewarded and a false legacy created. Possible solutions would be to allow peers knowledgeable in their fields to flag unlikely citation chains. However, an advantage of this methodology, which relies on individual articles’ legacy rather than an individual’s legacy, is that it would significantly reduce the need for name disambiguation, as articles typically have unique names and DOIs. This would therefore act to reduce the risk of accidental misattribution based on author names, which may cause issues for those with similar or identical names.
Other scholars have also suggested ways to better understand a work’s true contribution to the literature. Fragkiadaki et al suggested a similar system to ours with a similar chain-of-citations approach, up to the third degree of citation. (Fragkiadaki et al. 2009) In order to solve the self-citation problem, they decided to categorise them separately, which we believe results in not completely allowing a researcher to show that their own work provided an important contribution. (Fragkiadaki et al. 2009) Importantly, they only suggest looking up to 3 generations away, which could be a disadvantage to older, and sometimes seminal, papers. (Fragkiadaki et al. 2009).
Asobiaro and Ajiferuke argued that not all citations are equal and that citation counts are not robust enough to truly show a work’s influence. (Asubiaro and Ajiferuke 2022) They also suggested an index that aims to provide residual citations based on an articles semantic similarity between articles that cite each other, with some residual credit being passed on between articles with several degrees of separation. (Asubiaro and Ajiferuke 2022) However, a potential flaw of this method is that it is unclear how it would deal with articles written in different languages. (Asubiaro and Ajiferuke 2022) However, as this is not addressed in their paper it is theoretically possible that an article based on a work in a different language would fail to attribute any credit due to a semantic dissimilarity due to language and not content. (Asubiaro and Ajiferuke 2022) Though admittedly simpler, our method does not suffer from such issues.
Yang et al proposed a similar method of attributing credit based on semantic similarity. (Yang et al. 2025) Their methodology has the interesting specificity of introducing citation attribution patterns, one of which can avoid giving any credit to a paper which is cited but instead give the credit to the papers which are cited by the aforementioned paper if it is not found to have contributed but merely served a conduit for the information in the papers it cites. (Yang et al. 2025) This paper is otherwise similar to that of Asubiaro and Ajiferuke in that it gives credit according to perceived contributions based on semantics and thus potentially has similar flaws.
Ultimately, it is evident that this index, like all other indexes, would not be a panacea. However, it must be understood that, unlike other indexes, the aim of the L-index would not be to gauge an article’s popularity. Its aim would be to highlight the influence of an individual’s contribution over time and fight against the current paradigm in which review articles and meta-analyses overshadow primary sources. This would also stand out as a way of judging an individual article’s contribution to science, rather than a person’s overall contribution, as is the case with most other indexes. As such, the L-index is not meant as a replacement for current indexes but as a complementary way of assessing an individual article’s contribution to a field.
Nevertheless, we believe that such a classification system might be the best representation of the “standing on the shoulders of giants” idea, by demonstrating the lasting impact that authors can have throughout the ages.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)