Keywords
AI Ethics, Human Rights, TCCM Framework, AI Governance, Ethical Theories
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Uttaranchal University gateway.
AI Ethics, Human Rights, TCCM Framework, AI Governance, Ethical Theories
The rapid expansion of artificial intelligence (AI) across domains such as governance, healthcare, financial services, education, public safety, and social welfare has transformed the relationship between technological innovation and the exercise of fundamental human rights (Fjeld et al., 2020). Algorithmic decision-making can interfere with autonomy, increase bias and discrimination, violate privacy and dignity, and undermine accountability mechanisms (Mpinga et al., 2022). Because these technologies become entangled in institutional practices, their impact on rights and justice calls for systematic scholarly investigation. The area of AI ethics has grown tremendously over the past ten years resulting in a plethora of normative guidelines, regulatory frameworks, and interdisciplinary analyses (Tahaei et al., 2023). For instance, a meta-analysis of more than 200 AI ethics guidelines issued worldwide identified no fewer than 17 recurring principles (Mantelero & Esposito, 2021). Nonetheless, despite the volume of discourse, the field remains characterized by conceptual diffusion, disciplinary silos, and geographic asymmetries. Indeed, normative reflection, empirical investigation, and legal rights-based analysis often proceed in parallel rather than in a truly integrative manner (Constantinides et al., 2024; Fulton et al., 2024).
One particularly salient gap lies in the intersection of AI and human rights. Although the human rights consequences of digital technologies are increasingly recognized, the systematic integration of human rights norms (such as non-discrimination, privacy, freedom of expression, due process, and participation) into AI ethics scholarship remains uneven (Constantinides et al., 2024). Empirical research suggests that much of the influential scholarship originates in the Global North, with a limited representation of voices, contexts, and constraints from the Global South (Mpinga et al., 2022). The result is a literature base that may underrepresent how AI systems operate in resource-constrained, regulatory-thin, culturally diverse environments, and thus may lack global normative applicability (Pi et al., 2025; Hernández, 2024).
From a methodological perspective, the field has also leaned heavily on normative or descriptive reviews, rather than systematic structural mapping (Sridhar, 2025). Bibliometric and science-mapping techniques provide an opportunity to visualize and quantify the architecture of scholarship by tracking publication trends, citation networks, thematic clusters, and geographic institutional contributions (Valdez et al., 2024). However, descriptive mapping alone does not suffice to advance the normative agenda: a conceptual scaffold is needed to bridge empirical mapping with theory, context, and methods to identify strategic research fronts rather than merely cataloguing activity (Stephanidis et al., 2025; Kijewski et al., 2024).
To address these gaps, this study employs a dual-level approach. First, it conducts a bibliometric science-mapping exercise covering the period from 2018 to 2025 to chart the structural contours of the literature on AI ethics and human rights, including publication volumes, citation trends, leading institutions, countries, and journals, and the evolution of thematic clusters. Second, it utilizes the TCCM (Theory–Context–Characteristics–Methodology) model as an analytical lens to organize the review of literature, and to assess and evaluate the literature (Wang & Zhang, 2025); ‘Theory’ examines how the literature on AI ethics is informed by normative and human rights theory; ‘Context’ examines the contextual, geographical, institutional and legal frameworks in which the literature was produced; ‘Characteristics’ examines the characteristics of the AI systems studied and the resultant impact on rights; whilst ‘Methodology’ examines the methodologies used to empirically/quantitatively assess those impacts (Raza et al., 2025; Ligot, 2024). Thus, by positioning the outputs from bibliometrics within this conceptual framework, this research aims to move beyond a descriptive stage to the formulation of a systematic and forward-looking research agenda (Li, 2023; John et al., 2024).
As such, the research also has a hybrid methodology and, therefore, has four research objectives:
(i) Chart the patterns of publication and citation in AI ethics and human rights from 2018 to 2025.
(ii) To identify the leading countries, institutions, authors, and journals of AI ethics and human rights.
(iii) To study the dominant and forthcoming themes in the literature by employing co-word and clustering analysis of little-used author words.
(iv) To assess the conceptual, contextual, and methodological gaps in the literature and propose a future research agenda using the TCCM framework.
By fusing bibliometric mapping with TCCM-based conceptual synthesis, this article helps our understanding in three main ways. This study provides the first empirically grounded and temporally based analysis of the development of both AI ethics and human rights as subfields of international relations that also gives researchers a bird’s-eye view of what is happening in terms of the development of the field of AI ethics and human rights (Hernández, 2024; Elia et al., 2025; Manheim et al., 2024). Second, the study contributes to the field of AI ethics and human rights by providing an analysis of how human rights issues are constructed, implemented, and geographically located in the field of AI ethics and human rights, which will contribute to ongoing normative debates regarding how human rights can be effectively protected in relation to AI (Radanliev, 2025). Third, the study provides a comprehensive and coherent framework for future research on AI ethics and human rights that is inclusive across the globe, theoretically rigorous, methodologically diverse, and sensitive to the complexity of deploying AI in multiple empirical contexts (Tabbakh et al., 2024; Jedličková, 2024; Pi et al., 2025). This study will ultimately support the transition of the field from a primarily descriptive mapping process to an integrated, rights-based, global research architecture.
A combination of a templated-bibliometric approach was used in this study to assess the thematic progression, intellectual structure, and gaps in the human rights literature on the ethics of artificial intelligence (AI) through the use of both bibliometric and templated approaches to examine the development and current state of the literature on AI and human rights (Radanliev et al., 2024; Sharma et al., 2025; Wankhade et al., 2025).
Bibliometric analysis is an analytical method that can be utilized to create visual representations of science and to analyze the frequency of publication, citation rates, and relationships among authors and researchers, providing evidence of trends within the scientific community (Mbiazi et al., 2023; Nasir et al., 2024).
In addition to the creation of a visual representation of the literature, the methodology employed in this study allows for the identification of conceptual associations between various authors, researchers, journals, and studies, along with the ability to determine clusters of related themes throughout the literature (Tettey et al., 2025; Greif et al., 2024; Nastoska et al., 2025).
Additionally, the theory–context–characteristics–methodology (TCCM) framework (Bolgouras et al., 2025) will also serve as a meta-analytic lens for assessing the current state of the literature and identifying theoretical, contextual, and methodological shortcomings in the existing literature, and subsequently provide a systematic and structured foundation for developing a future research agenda (Rees & Müller, 2022; Ibitoye et al., 2025). This dual approach of quantitative bibliometric methods paired with the qualitative synthesis of the framework provides analytical rigor and theoretical engagement (Mökander et al., 2021; Ibitoye et al., 2025).
Data for the bibliometric research were drawn from Scopus, given its multidisciplinary coverage, accuracy of metadata, and compatibility with bibliometric software. In January 2025, the search was undertaken using the Boolean string: (“Ethics of artificial intelligence” OR “AI ethics”) AND (“Data protection” OR “privacy law” OR “Digital rights” OR “Legal framework” OR “Human rights” OR “AI governance”). This provided a search string that facilitated the identification of peer-reviewed articles that specifically addressed ethical considerations arising from AI and human rights elements (Brogle et al., 2025). The search yielded initial 312 documents ranging from to 2018-2025. To achieve as accurate a result as possible, the documents identified have been peer-reviewed journal articles, conference papers, and book chapters, while discarding duplicates, editorials, and other forms of non-academic commentary. The period from 2018 to 2025 was chosen to coincide with the emergence of significant ethical and regulatory structures such as the European Union High-level Expert Group on AI and the Ethics Guidelines for Trustworthy (Hermann et al., 2023; Rees & Müller, 2022). Recommendations on the Ethics of Artificial Intelligence have had a significant impact on global academic discourse on the subject (Cihon et al., 2021).
All relevant documents were arranged in a systematic data-screening process according to the PRISMA 2020 protocol as illustrated in Figure 1 below (Lam et al., 2024; Avin et al., 2021). All retrieved documents were subjected to manual screening for relevance by two independent reviewers according to title, abstract, and keyword analysis. The inclusion criteria were as follows: (a) directly dealt with issues of the legal, ethical, or human rights implications of AI; (b) was written in English; and (c) was listed as a peer-reviewed document in Scopus. After duplication and exclusion of other non-relevant documents, the final list comprised 191 relevant documents. The metadata of the documents, including the names of the authors, titles, authors’ affiliations, sources of publication, citations, and keywords, were extracted from. CSV format.
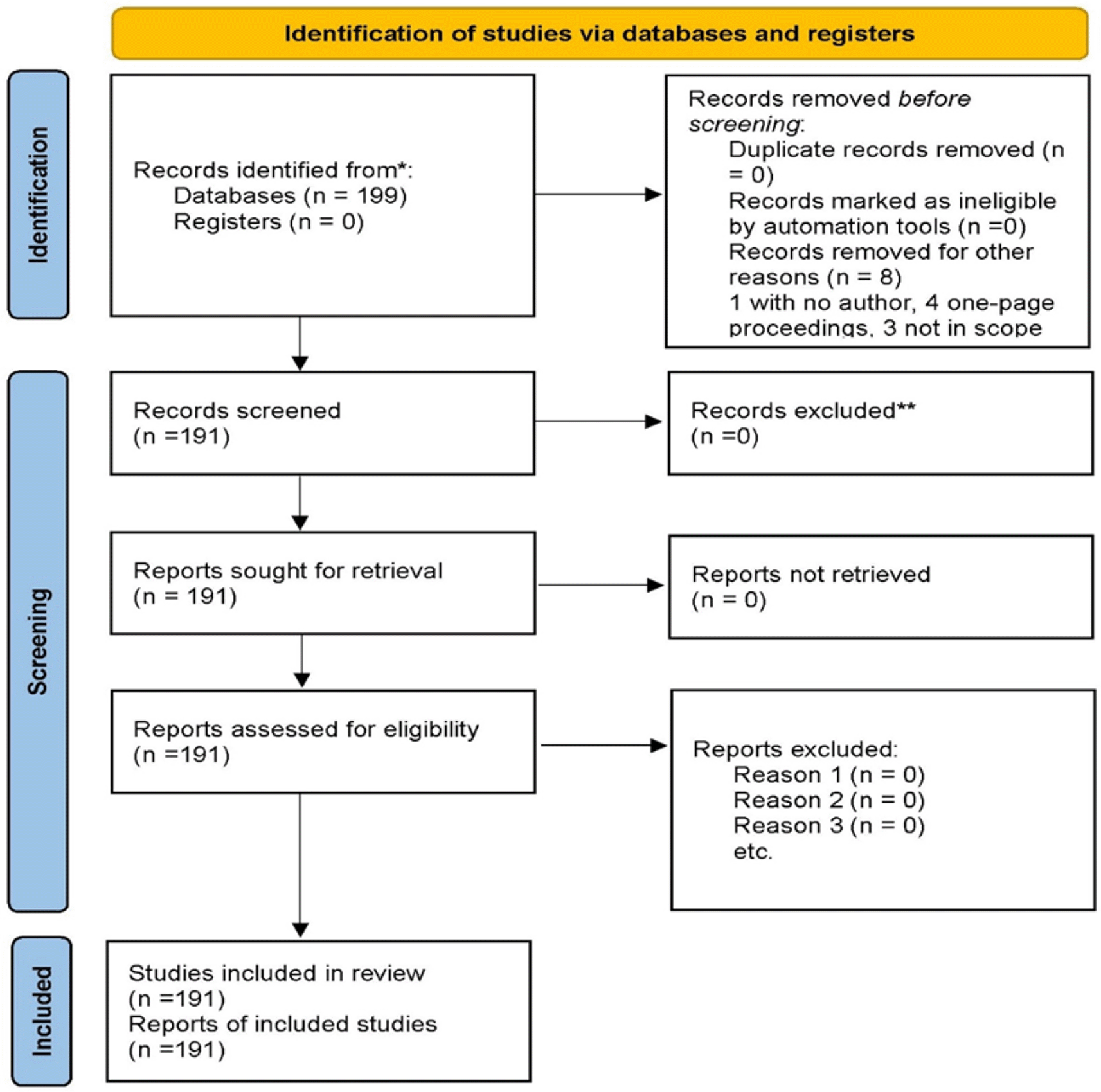
The study utilized the following combination of tools for all stages of data extraction, organization, and analysis: RStudio (Bibliometrix and Biblioshiny Packages), VOSviewer (v1.6.20.) and Microsoft Excel 2021 (Lam et al., 2024; Avin et al., 2021).
• Microsoft Excel was used at the initial stages of the procedure for cleaning of the data, table production and normalization of the metadata are concerned (Ayling & Chapman, 2021; Akula & Garibay, 2021), such as the standardization of author names and terms, keywords (the merging of, for example, “AI” and “artificial intelligence”), authors’ journal abbreviations. It has also enabled the production of basic descriptive statistics (such as frequency counts, growth rates, average citations per document) as well and the production of media for intermediate visual summaries (Ema et al., 2023; Mökander & Floridi, 2021).
• RStudio with Biblioshiny was utilized to produce quantitative bibliometric calculations of annual scientific production in terms of collaboration indices, sources of impact, Lotka’s law distribution, and the generation of keyword co-occurrence matrices (Laine et al., 2024; Ugwudike, 2021).
• VOSviewer assisted in visualizing the various bibliometric networks in co-authorship, co-citation, and co-word analyses. The scale parameters were set such that the minimum occurrence of keywords was set at five and ten citations for sources to generate good interpretive robust observations (Corrêa et al., 2023; Akula & Garibay, 2021).
The bibliometric and visualization procedures consisted of the following five analytical constructs:
1. Descriptive bibliometrics: These include the investigation of the annual growth of publications, citation patterns, and collaboration indices to generate an overview of the evolution in time of the production of academic articles (Falco et al., 2021; Raji et al., 2022).
2. Source and author impact evaluations: This, through the analyses of Bradford and Lotka, sought to document the distribution of important journals and authors with a view of producing an impression of the most effective source of publication on an impact basis source of publication (Akula & Garibay, 2021).
3. Keyword co-occurrence and thematic mapping: Through co-word analysis, thematic clusters and themes were generated that were observed in the research results. Maps of thematic evolution were generated to document how key terms such as AI governance, algorithmic accountability, and human rights have developed in the course of the periods studied (Chellappan, 2024; Oesterling et al., 2024).
4. Network Visualization: VOSviewer was employed to create co-authorship, institutional, and country-level collaboration networks (Manheim et al., 2025).
5. Cluster Validation: Thematic clusters were validated against previous bibliometric findings (Herrera-Poyatos et al., 2025; Goodman & Trehu, 2022) to ensure conceptual consistency.
Following bibliometric analysis, the TCCM framework was applied for interpretive synthesis:
• Theory (T): Identification of ethical theories (deontology, consequentialism, and virtue ethics) and legal paradigms (human rights law and constitutional principles) underpinning the literature.
• Context (C): Examination of the geographic distribution of research, particularly Global North–South asymmetry and institutional concentration.
• Characteristics (C): Evaluation of the thematic orientation of AI applications, such as fairness, accountability, transparency, privacy, and bias.
• Methodology (M): Assessment of research designs, with emphasis on the predominance of conceptual versus empirical studies.
This qualitative layer facilitated the translation of quantitative bibliometric insights into a structured research agenda that highlights gaps and future trajectories in AI ethics and human rights scholarship (Verma et al., 2025; Schiff et al., 2024).
Table 1 indicates the temporal coverage running from 2018 to 2025, containing 191 documents from 112 different outlets. This indicates that there is a moderate spread of academic output over a variety of journals or conference proceedings, meaning that the thematic area is being dealt with in a number of different outlets and is not concentrated in a few academic journals. A total of 615 writers gave an average of approximately 3.2 authors per document. This degree of collaboration is representative of the typical author co-authorship patterns found in several academic areas and indicates a balance between individual approaches to research and groups of writers working on the same research problem.
| Time period | 2018-2025 |
|---|---|
| Number of documents | 191 |
| Number of Sources | 112 |
| Annual growth rate | 80.33% |
| Authors | 615 |
| International co-authorship | 19.9% |
| References | 1580 |
| Average citations per document | 7.461 |
Figure 2 compares the figures on two indicators between the years 2018 and 2025, the number of publications generated each year, and the average number of citations received by this document in that year. From 2018 to 2019, there was no registered scientific production, which is also in accordance with the data in Table 2. The first publications cropped up in 2020, from which it can be said that there is measurable activity. The number of documents, in turn, increases annually from 2020, appreciably from 2023, and the expected maximum in 2025.
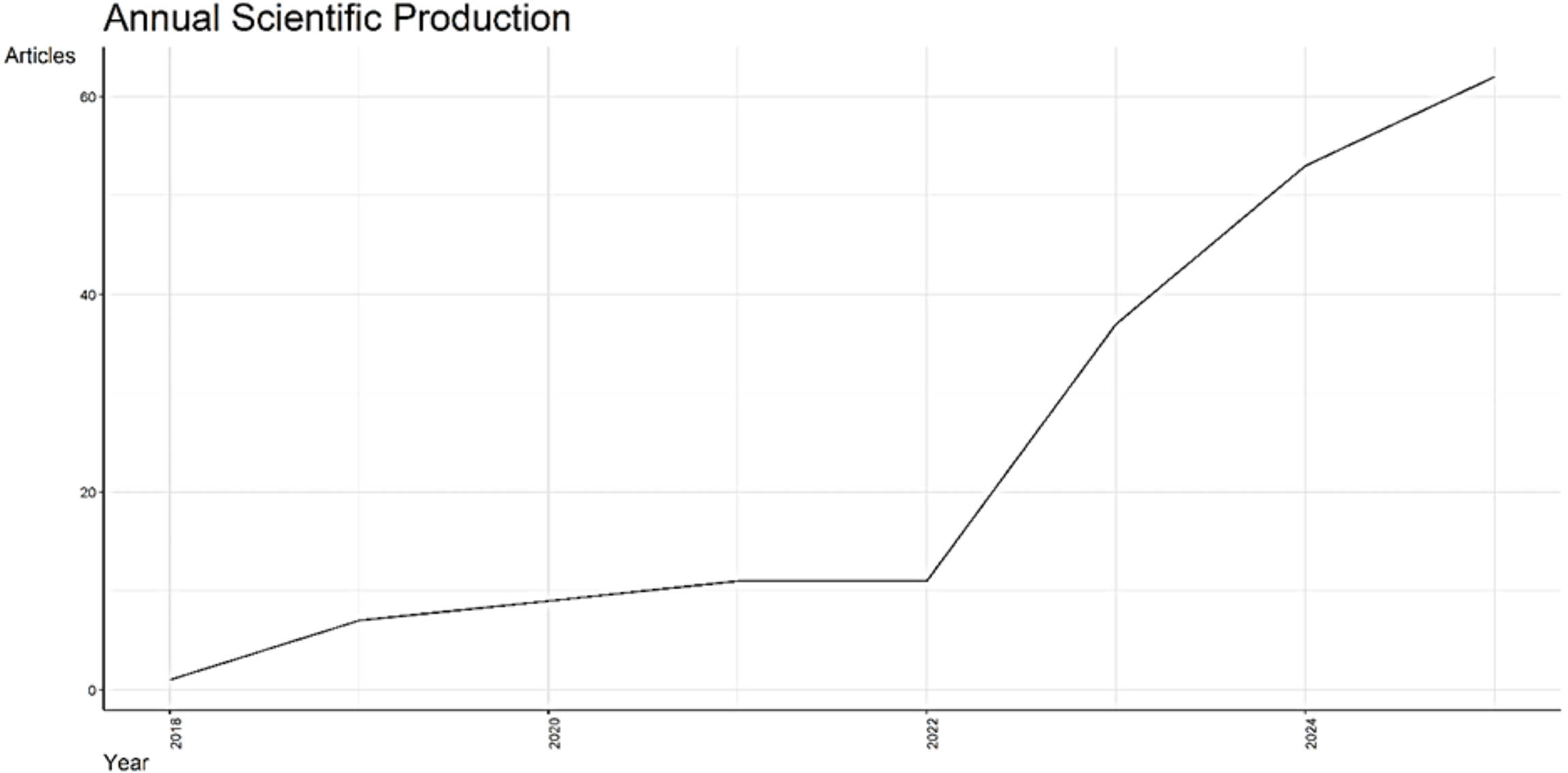
However, the average number of citations per document shows another trend. Although there is a regular increase in production volume, the average number of citations does not increase significantly. Normally the previous years (years 2020-2021) have much higher average citations that the number of documents than for their part the superior years of the 2,024-2,025. It is evident that it is very punctual because previous publications have had more time to increase the number of citations, while they are still not in circulation, those too recent for that (2024 and 2025). This inverse pattern between volume and citations highlights the time-lag effect in citation accumulation. This does not imply that recent publications are less relevant or lower in quality but simply that citation metrics are delayed indicators of impact.
Table 2 captures the growth in research activity over time, with a clear expansion in both output volume and source variety after 2021. (Source: Author)
Figure 3. highlights journals and proceedings with the highest number of publications in the dataset.
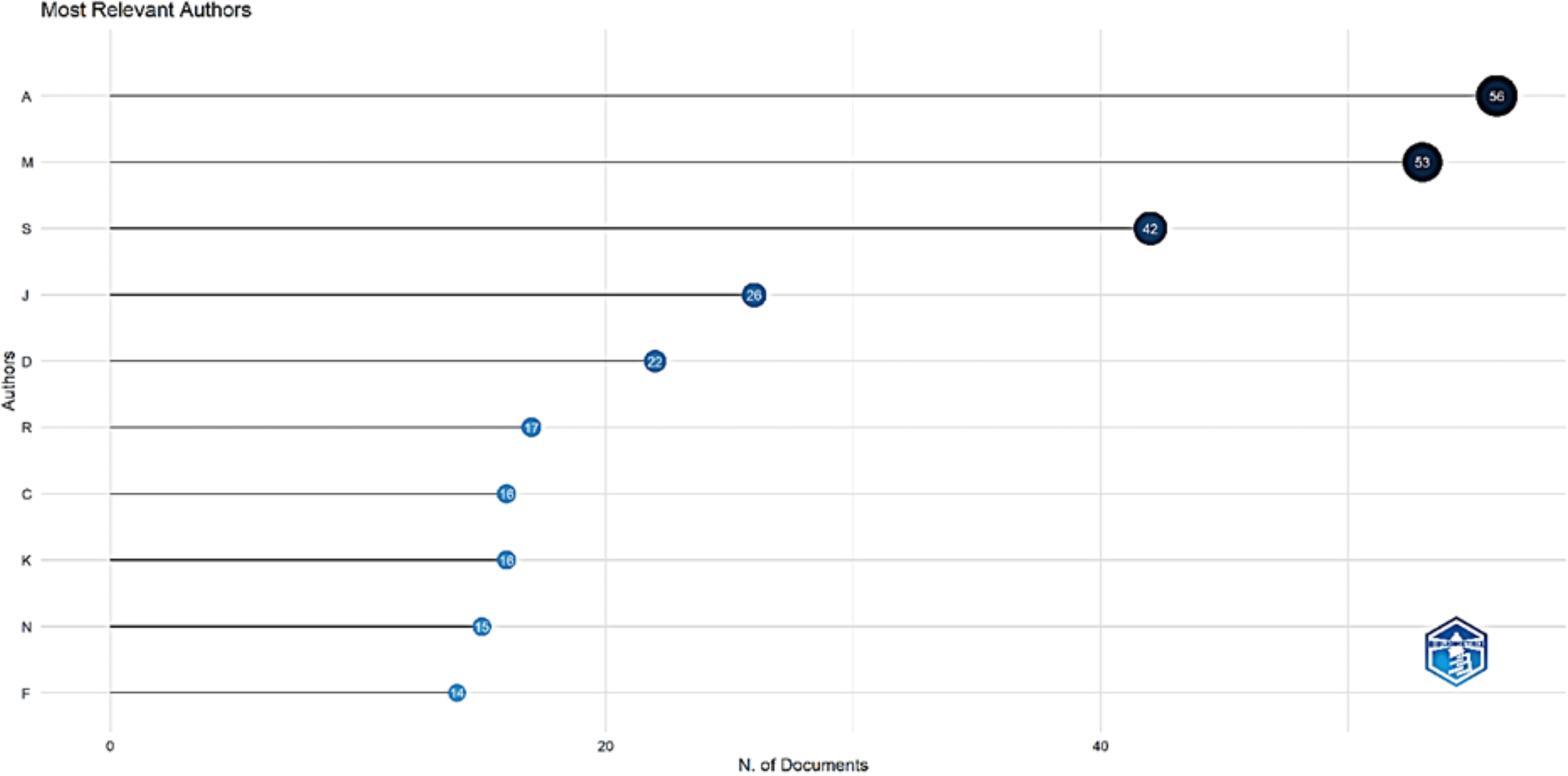
Figure 4 shows the most frequently contributing institutions based on author affiliations across the dataset. The leading affiliation is the O.P. Jindal Global University (India), which appears in five publications, making it the most active contributor. This suggests a concentrated research initiative or coordinated publishing effort from a specific department or faculty member within the university. Following this, both Universität Wien (Austria) and Tashkent State University of Law (Uzbekistan) contributed to three publications each. These two institutions show moderate but continued engagement to a lower degree. A few others, including the University of Toronto (Canada), Royal Institute of Technology (Sweden), Lovely Professional University (India), and IBM Research (USA), occurred in two documents each. This distribution suggests that the database has contributions from a number of research and academic institutions in a number of different countries, both public and private research bodies.
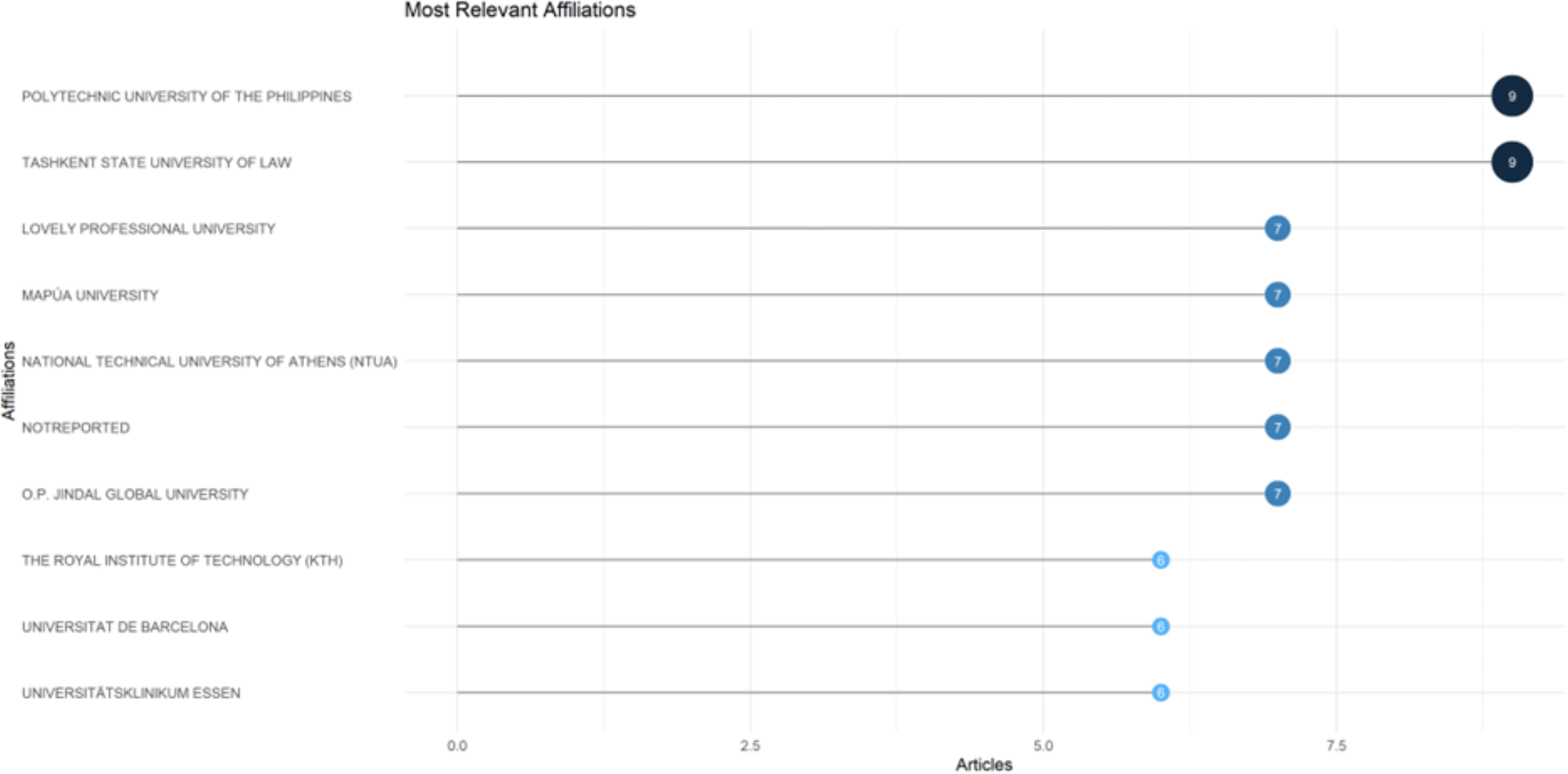
Despite the existence of some international institutions, a rather flat distribution is seen in the data after the top affiliation, with no entity except O. P. Jindal, who has issued more than three publications. This indicates that the research is not centralized to a few aggressively active academic centers but is rather diffused in its contributors. Furthermore, it is apparent that although there are international institutions, earlier data have shown that the percentage of international co-authorship is quite low (19.9%), so these affiliations are probably with independently authored papers, save for cooperative efforts.
Overall, it shows a moderately diverse institutional picture with distinct regional clusters and a small number of highly active centers. The existence of industrial research bodies such as IBM Research is clearly pleasing from the point of view of playability; however, in view of degree, their research participation made by them is of a very small order. In order to enhance cooperative strength and long-term impact, future research activities should derive benefits from building lasting institutional relationships and trans-border cooperation.
The total number of publications is illustrated in Figure 5, broken down per source for the entire period, 2018-2025. This provides a clear idea of which journals or a series of conference proceedings are employed the most throughout this dataset.
The greatest contributor is AI and Society, with six publications, making it the most frequently employed outlet. This suggests that this is the preferred medium of publication for academic authors working in this field or in this research group. It also indicates thematic concordance, as this journal focuses specifically on the social impact of technology. It would also confirm that publication outputs are concentrated in a few recurring outlets, with AI and Society being the only sources that are positively multiyear with its output. Other outlets are sporadic in nature, with most being present only once or twice. While the breadth of the outlets indicates diversity, it also indicates fragmentation.
Table 3 outlines the five most prolific journals publishing outputs on AI, software patenting, and ethics in the analyzed corpus. It typically shows journal name, number of publications, total citations, and average citations per paper.
| S.No. | Journal | No. of citations | Authors |
|---|---|---|---|
| 1 | Journal of Business Research | 124 | Brey (2022), Ryan (2022), Andreou (2022), Macnish (2022), Stahl (2022), Zicari (2022) |
| 2 | Journal of Data and Information Quality | 90 | Bertino (2020), Kundu (2020), Sura (2020) |
| 3 | Machine Learning and Knowledge Extraction | 75 | Hariri et al. (2021), Fanaei Sheikhobiasi (2021), Khosravi (2021), Zhang (2021), Al-Fuqaha (2021) |
| 4 | AI and Society | 63 | Quintarelli (2020), Biju (2020), Knight (2020), Stahl (2020), Coeckelbergh (2020), Szpak (2020) |
| 5 | Computer Law and Security Review | 53 | Rodrigues (2021), Santiago (2021), Macnish (2021), Kuner (2021), Lahlou (2021), B.C. (2021) |
In Figure 6, the United States produces the most output (55), but also leads in citations (874), indicating both a large number of articles and a large number of citations. India ranks second in output (48 publications), but has a disproportionately low number of total citations (81), indicating high output but low visibility or research impact per paper. This situation indicates that much of this input may be going to low-impact or unindexed locations. In contrast, the picture for countries such as the U.K., Australia, and Germany is very different, having much lower outputs but much higher citations per article. For instance, the U.K. has only 20 publications but has a total of 489 citations, giving an average of over 24 citations per paper, showing a much higher quality of research or wider international relevance. Saudi Arabia and China are moderately proportionate in this, having also moderate output figures and citations. Countries such as Canada, Italy, and Spain fall into the median range of both output and impact.
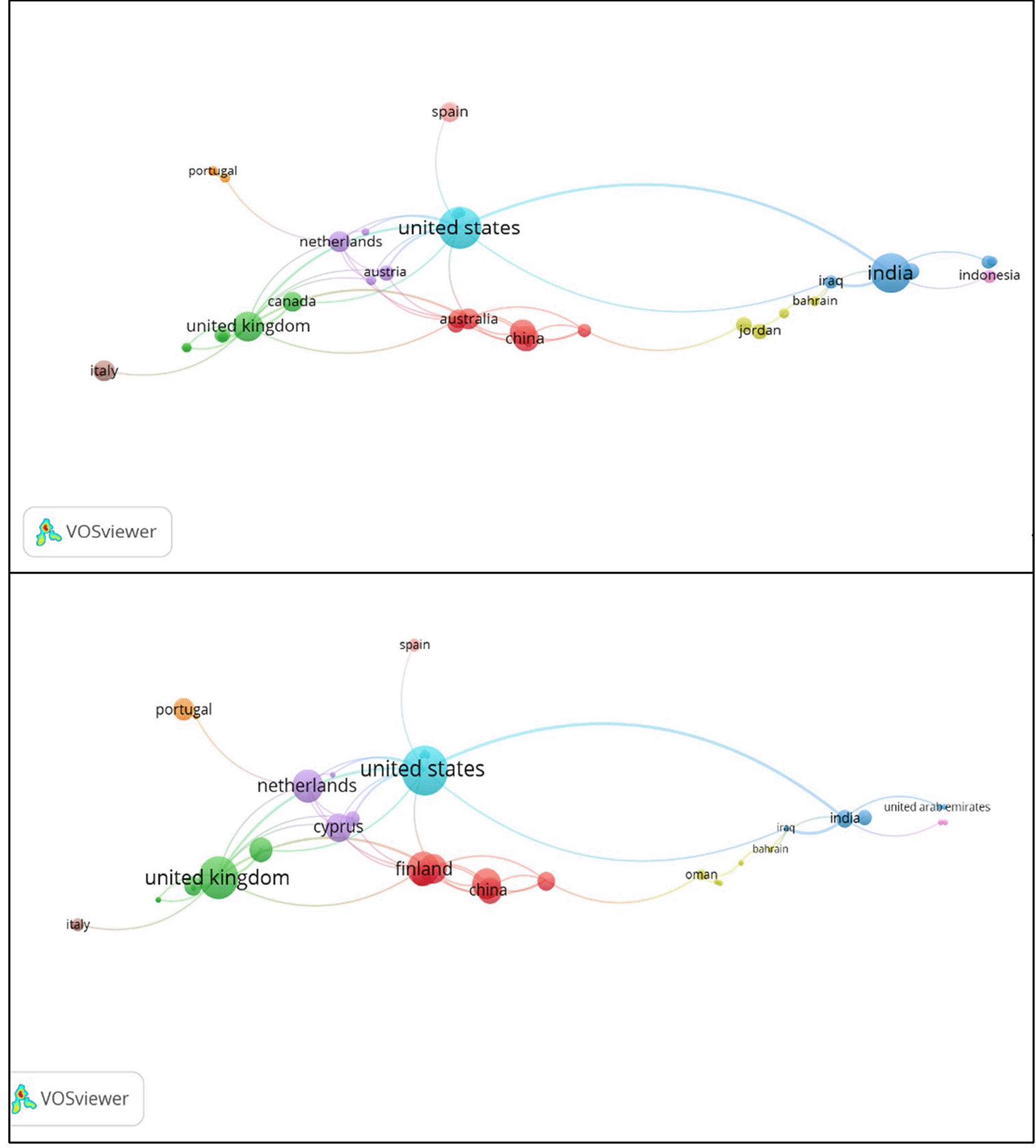
Generally, the data show a great incongruence between the number of publications and a greatly varying impact between countries. The U.S., the U.K., and Australia constitute both. In other countries, especially India and Saudi Arabia, there is a difference in citation impact; however, these countries are frequent publishers. The figures highlight the need not just to publish more, but also to publish in places that are more conducive to academic visibility and citation leverage.
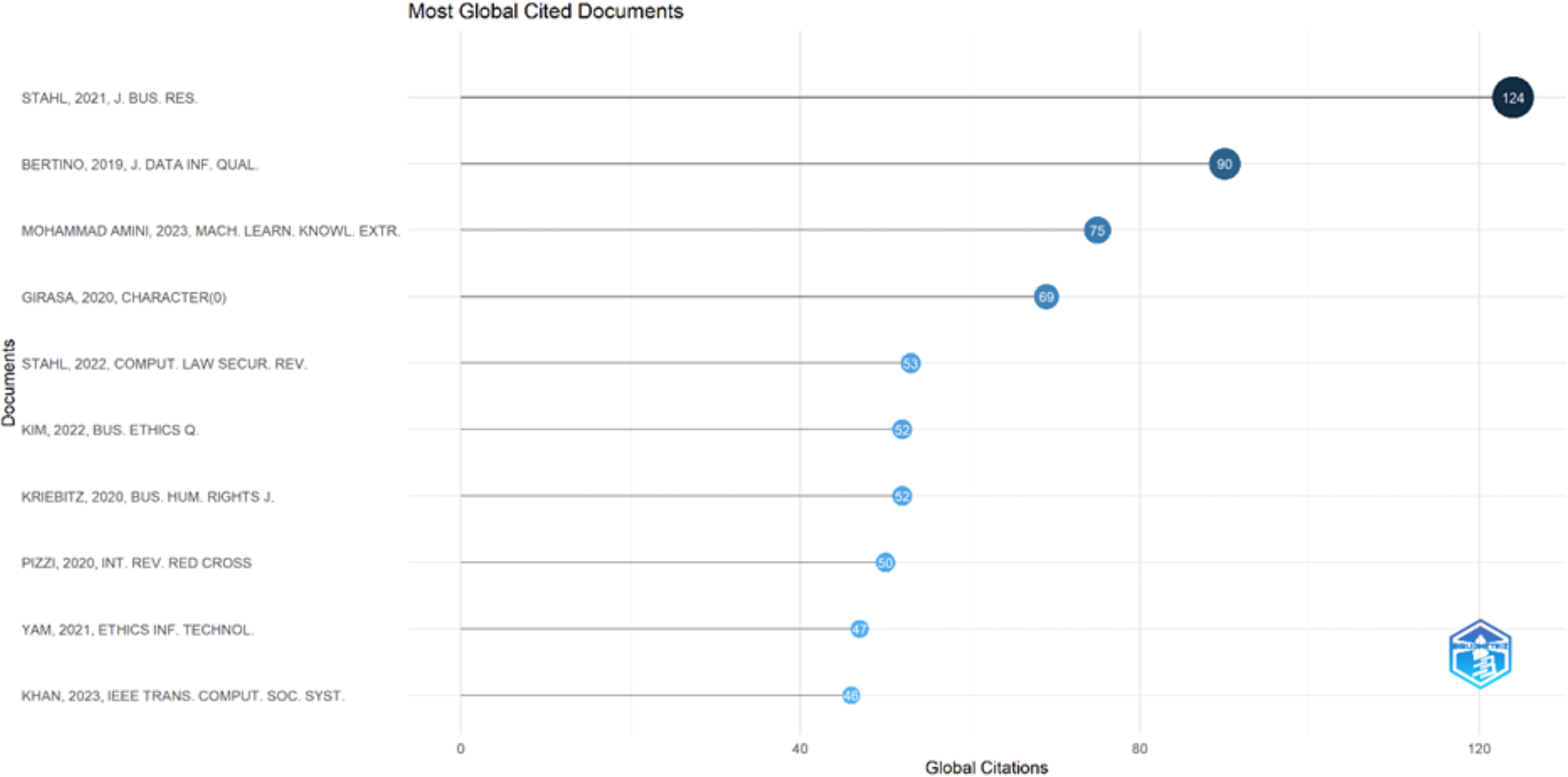
The 124 times cited document is from 2021 and concerns artificial intelligence for human flourishing. The article is characterized by, if not its unique, conceptual framing, at least a cross-disciplinary appeal. A 2019 article on blockchain and AI ethics followed (90 citations). This article has had more time to collect citations, but clearly demonstrates early engagement with basic questions of ethical concern. A high proportion of documents, those from 2020 to 2022, collect this together so that the important contributions in the data file are accounted for in a three-year window, a period in which the field saw a large increase in both interest and impactful publications engendered. Two of the 2023 articles already appear in the top 10, with 75 and 46 citations, respectively. These offer a strong record of citations early on, as they appear to be relatively recently published. This is indicative of their timeliness, rather than their relevance to current scholarly discussions. Most of the titles look at central concerns of ethics, transparency, human rights, regulation, etc., which serve to confirm that impact in this dataset models the close interrelation between socially relevant governmental areas in AI with which the social actor can be justifiably concerned. The top 10 documents model both the thematic focus and the temporal impact of papers as presented in Figure 7. The most influential was written between 2019 and 2022, with a small number of entrants representing early 2023, rising quickly. The ethical, regulatory, and human-centered perspectives on AI dominate the high-impact section of academic journal articles in connection with AI, demonstrating that future work aspiring to visibility in this sector should address ethical, regulatory, and human-centered aspects in a clear and relevant manner.
The leading term by a considerable distance, “AI ethics,” was found 75 times as visually presented in Figure 8 pointing to the fact that the focus of the datasets is on ethical frameworks, dilemmas and legislation pertaining to artificial intelligence technology. This is borne out by many of the most cited publications in the datasets, many of which deal with ethics, regulations, and human rights. The next most common terms were “artificial intelligence” and” ethics,” confirming the emphasis laid (in the datasets) on normative and conceptual themes. The frequent occurrence of “human rights” (20 times) and “privacy” (18 times) suggests that many publications have a legal or humanity-focus, suggesting that the technology area is focused on human accountability with respect to the method of application of technology. Terms like “AI governance,” “data protection” and “AI regulation” appeared to have roughly the same frequency of occurrence (10-14 occurrences each) suggestive that there is an increasing pre-occupation with the problem of regulation and institutional control. The mention of phrases like “responsible AI,” “generative AI” and “transparency” indicates that new sub-discussions are developing under the category of ethical discussion. Again, the occurrence of both “AI” and ‘Artificial Intelligence (AI)’ as separate headings stresses the fact that the authors have been inconsistent in their heading usage, which may slightly distort the frequency analysis. It would certainly be beneficial to reach uniformity in terms of usage in future analyses. Regarding the tree map, it appears that there is a concentrated theme being followed in more or less all AI research publications on the themes of ethics, governance, privacy, and regulation. The pre-eminence of words like “AI ethics” and “human rights” demonstrates that the players are having their drive shaped more by social legal and policy considerations than by purely technical issues. These findings can be better recognized from the fact that they are illustrated in both the most cited papers and in the source distribution across various interdisciplinary journals.
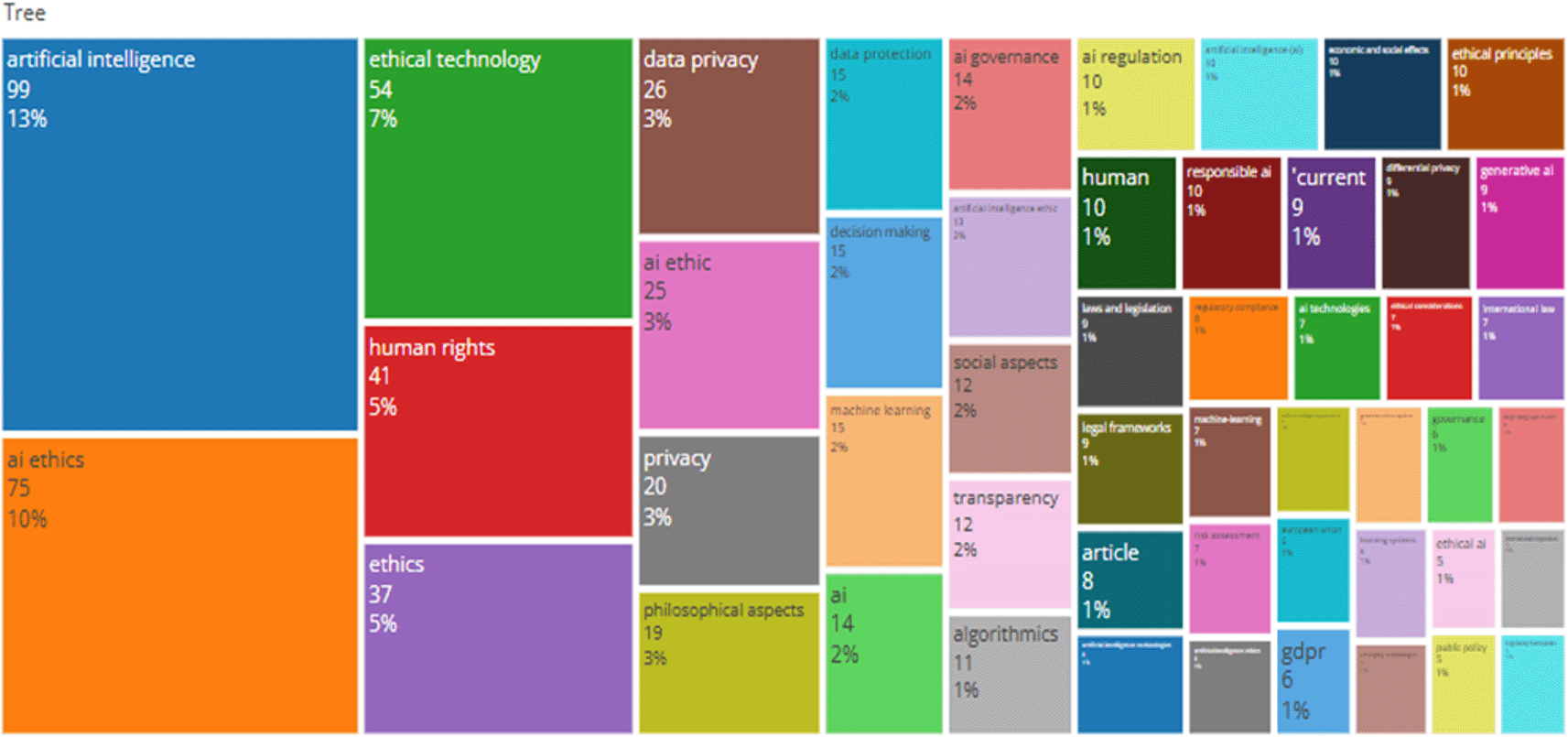
Figure 9 illustrates how often relevant keywords for authors are reflected in publications from 2018 to 2025. These data are based on the occurrence of the ten most commonly used keywords within the dataset, including words such as AI ethics, artificial intelligence, privacy, ethics, human rights, and AI governance. Relevant keywords were first used in 2018, with comments such as AI ethics, artificial intelligence, and privacy discussed separately on one occasion only. Thus, it appears that at this stage of development, ethical and privacy issues relating to AI systems were beginning to develop on a limited scale. In 2019, the frequency of the occurrence of such keywords started to increase, albeit slightly. Ethics and privacy appeared three times, indicating a growing interest in substantial ethical themes and data protection legislation. However, the use of relevant keywords is still applied to a limited number of papers.
An increase in mention is seen in the years subsequent to (2020–2023), being reflected in a considerably larger occurrence of AI ethics, human rights, AI governance, and responsible AI. This, in turn, coincides with the widespread increase in the volume of publications, which was being made and indicative of a larger and more concentrated approach to the social and legal aspects of AI. By 2023, keywords such as AI ethics, responsible AI, and generative AI appeared more frequently, indicating a more substantial approach in sub-headings, particularly those relating to more novel technology and the new applied systems of governance. It also reflects the total involvement of the worldwide debate on the regulation of AI and ethics in the field, which developed rapidly during this time.
It may be concluded from the data that although there were sporadic mentions of important keywords during the first years (2018–2019), a much more considerable and widespread allusion of relevant ethical keywords appeared to be taken only in the years 2020 and subsequently to 2025. Accordingly, this would indicate that there is a growing inquiry to be subjoined not merely in the development of AI systems, but also the more serious consideration of such to their ethical aspects, the regulation under which they will place on their creation, or the laws affected by such and their effect on society.
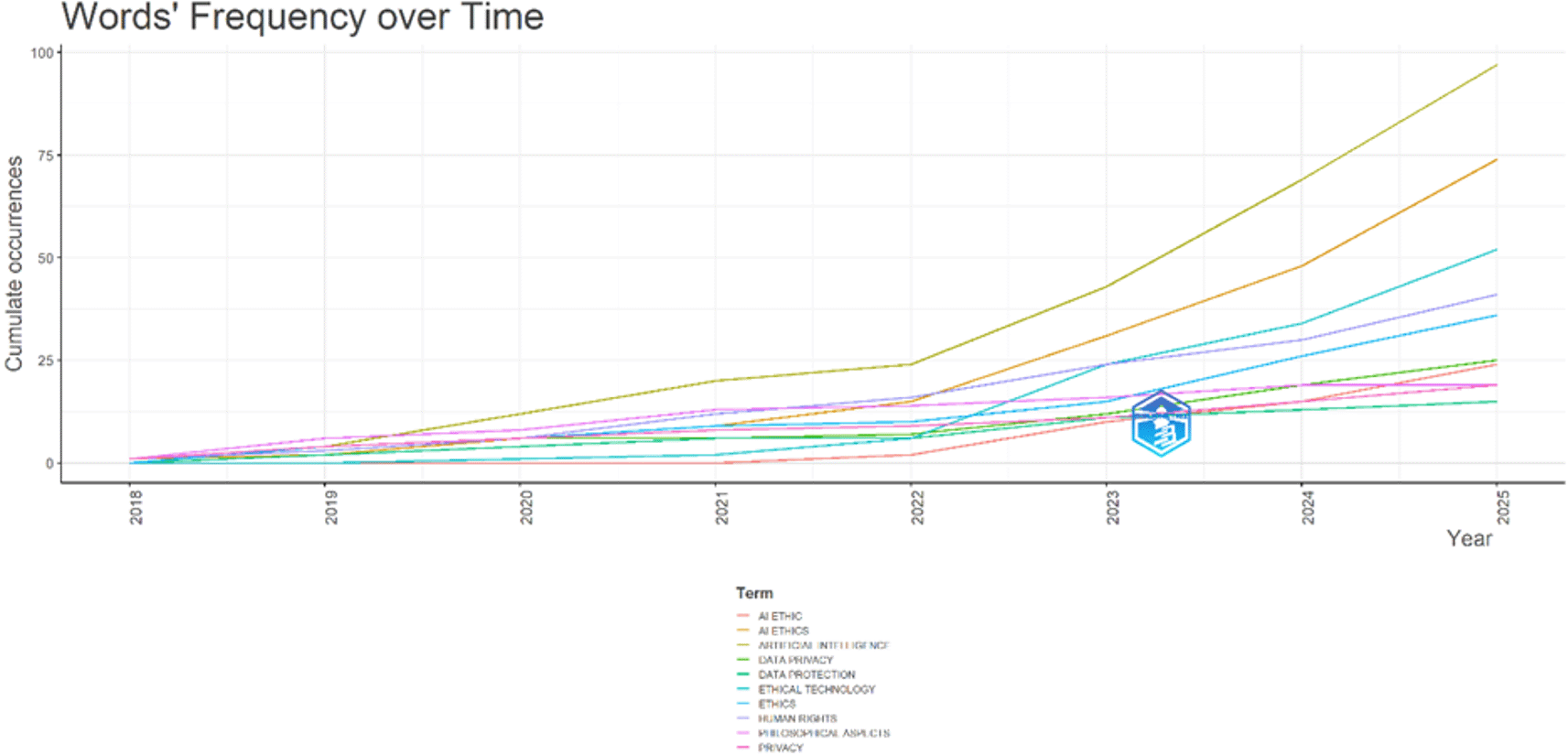
Figure 10 provides a combined view of the evolution of the core research themes over time and their relative conceptual relationships within the dataset. The first part, the topic trends diagram, shows the temporal emergence and frequency of usage of the selected key terms from 2019 to 2025. Lines correspond to each thematic term and the size of the dot corresponds to the frequency of usage of the term in each given year. These terms, including artificial intelligence, AI ethics, and ethical technology, show consistent and high-frequency use from approximately 2022 until 2025. This indicates consistent and growing attention to these topics in the recent literature. The terms previously appearing, such as privacy, human rights, and data protection, began to appear prominently around 2020 but remain regularly important topics. These keywords suggest important legal and ethical themes that created the foundation for early work in the field. By contrast, terms such as legal frameworks, international law, and AI technology have emerged recently, primarily after 2023. This indicates a widening of the research from general ethical considerations to more specific discussions concerning regulations, implementation, and international policy structures. Topics such as general data protection regulations (GDPR) and philosophical aspects were discussed actively in earlier years, but do not show up in the same consistency or growth of usage, which suggests that they may tend to indicate foundational discussions that have since become subsumed under more specific topics. The second part of the figure illustrates the keyword co-occurrence network. This network shows how often these terms appear concurrently within the same documents, providing an idea of the thematic structure of a research field. The center of the network focuses on artificial intelligence, which connects heavily to terms such as ethics, data privacy, machine learning, and AI ethics. These strong connections provide evidence that AI is the superordinate term from which most research themes emanate. A very dense cluster adjoining the terms ethics, privacy, transparency, and philosophical aspects indicates that there is a frequent co-occurrence of ethical and conceptual themes, producing a core discourse around AI and normative considerations. A different area of connectedness produces a cluster of co-occurring terms such as AI ethics, ethical technology, AI regulation, legal frameworks, and international law. This cluster shows a clear but developing focus on governance, compliance, and legal considerations, indicating a fledging area of discussion in the field of structured regulatory questions. More peripheral terms, such as public policy, emerging technologies, and generative AI, are indicated, but remain marginal in the network, to an extent, indicating either newer areas of research or less closely integrated sub-fields. The appearance of large language models and generative AI in the same cluster as ethics and privacy clearly suggests that these emergent technologies are quickly becoming socially arranged within the existing ethical discourses. It also suggests a maturing into the field of research that has evolved from general consensus with regard to ethical matters to a much more detailed engagement with governance, law, and societal implications. The ethical discourse remains core, but this is now in conjunction with, and in some instances driven by, the regulatory, legal, and political questions that AI development poses. The patterns shown indicate that these topics are not isolated, but are increasingly interrelated, forming a densely interconnected and evolving thematic structure.
Figure 11 illustrates the triadic relationship among journals, keywords, and countries, allowing a geographic and outlet distribution of the concentration of specific research themes of interest. The data reveal the frequency of each of the dominant keyword-couplet/country pairs to be indicated in the journal publications of interest, suggesting research thematic output and geographic regional areas of study. The largest cluster appeared in the International Journal of Medical Informatics, Saudi Arabia, for which the following keywords, being unique but related in theme, were found most frequently in usage (22 times each): ethical considerations, artificial intelligence (AI), resource allocation, mass gatherings (MGs), health care, and data security. The high frequency of this clustering of keywords would suggest a directed, perhaps institutional research project addressing itself in large part to the ethical and specified logistical aspects of health data and AI use for health technologies applied to large mass gathering events, such as Hajj. The correlation of the many high-frequency keywords in use centered around one journal country pair indicates a directed and closely allied thematic output from one national context. Another remarkable cluster appears from the Conference on Human Factors and Computing Systems, whereby the United States is related to such words as AI ethics, responsible AI, and human-centered AI, each being 10 times. This suggests a large concentration of research directing itself from institutions in the United States to human - AI interactions and the ethical design of systems in usage, being allied under trending directions for U.S. institutions to be moving, such as in ethical, responsible innovation, or participatory design. Figure 11 also indicates that the themes involved in the research work do not discriminate against either national or journal series reaches. Instead, keyword clusters were of recognizable discriminatory context, both in national and journal names, suggesting both institutional priorities and regional predominance. For example, Saudi Arabian publications are heavily inclined toward subjects surrounding AI in health care and public infrastructure, while the U.S. has subjects assigned to it with a tendency toward ethics and human-centered design. In contrast, Australia and Austria show more distinctive subject areas of a conditionally sociotechnical or contextual nature. Taken together, the field appears to be globally populated but also regionally spawned, with research themes conditioned by national priorities and disciplinary stress.
Figure 12 illustrates the network that visualizes conceptual relationships between AI ethics and software patenting research, where large nodes denote the most frequently used terms, edges signify the strength of co-occurrence strength, while the clusters correspond to the larger thematic area’s ethical governance, privacy and accountability, and patentability and legal methods, indicating how the deliberation of AI ethics and intellectual property matures into interconnected subfields.

Table 4 shows the results of the thematic cluster analysis of research on AI ethics and human rights. Five clusters were identified as the major clusters of analysis in the wider research area. These clusters were assigned according to the keywords used and themes identified in academic literature (Waltersdorfer et al., 2024).
Future Research Agenda Based on the TCCM Framework
Future research agendas for the field of AI ethics and human rights can be organized using the TCCM framework, which assumes the following key dimensions: Theory, Context, Characteristics and Methodology. The results of this bibliometric analysis indicate several specific gaps across each of the four dimensions, which need to be addressed in future studies to advance both academic knowledge and practical deployment in this domain.
The Figure 13 below summarizes the TCCM framework to categorize the research gaps and future directions.
Theory Development (T)
From a theoretical perspective, the literature reviewed is largely descriptive and policy-oriented with limited interaction with formal ethical and legal theory. Although terms such as ethics, artificial intelligence ethics, and human rights appear frequently in author keywords or co-occurrence networks, the documents examined rarely subscribe to systematic models of ethical theory such as deontology, consequentialism, or international law on human rights (Cihon et al., 2021; Corrêa et al., 2023). This lack of theoretical depth limits the generalizability of the findings and weakens the normative underpinnings in the field. Future research must remedy this situation by explicitly including ethical models and legal theorizing in the analysis. For example, research could drive the application of rights theories to the specific harms created by artificial intelligence in different settings or investigate how the ethical impact of artificial intelligence technologies is mediated by institutional contexts using sociotechnical systems theory.
Context (C)
In terms of context, publication and citation data reveal considerable imbalance. The large body of highly cited work seems to reside in the USA, UK, and Australia, while a significant number of publications with low citation impact are produced in countries such as India, Saudi Arabia, and a number of global southern regions. This finding suggests a geographical concentration of influence and visibility. Future research must expand the dimensions of the inquiry by including those areas where influence is under-represented, in particular those areas confronted by specific challenges in the area of artificial intelligence legislation, such as low regulatory capacity or autocratic political systems. Comparative cross-country studies examining how different legal systems understand the ethical principles governing the use of AI would add most insights (Faveri et al., 2025; Goodman & Trehu, 2022). In addition, non-English publications and region-specific datasets must be considered by researchers to prevent linguistic and epistemic bias.
Characteristics (C)
In the dimension of characteristics, the dataset shows that and invoke vague themes like AI ethics, privacy, or human rights, but does not distinguish between the various types of AI systems or the various uses to which they are put. Statistics provided on such things as words and their trends and the co-occurrence of words show that modern themes such as AI governance, generative AI, and automated decision-making are just beginning to reveal themselves. There is considerable demand for future research to focus on the risks related to specific domains and the specific characteristics of systems (Hariri et al., 2021; Mpinga et al., 2022). For instance, ethical problems related to facial recognition in public surveillance through AI are radically different from those posed in connection with AI-assisted hiring or medical triage systems. The implications of technologies on specific rights, such as privacy, the right against discrimination, and the right to due process, should be studied by researchers in relation to various sectors, such as law enforcement, education, and the healthcare sector.
Methodologies (M)
Finally, the methodology employed in most studies is predominantly conceptual or literature based. Papers that conduct empirical investigations are rare, and audits of the evaluated systems should be almost non-existent. There is a dearth of evidence as to how human beings are affected by AI systems or how they are governed in practice. To this end, the way forward should entail empirical research, such as stakeholder interviews, surveys, case studies, and algorithm audits. It would be particularly useful to employ a mixed-method approach that couples traditional legal analysis with an analysis of systems so that the gap between normative statements or claims and the visible effect can be closed. Encouraging interdisciplinary cooperation between legal scholars and political scientists involved with AI, scientists, and social scientists is vital in the pursuit of robust methodologies needed to understand the ethical and operational issues surrounding AI systems (Rodrigues, 2021). The TCCM framework elucidates that the question of how to take the AI ethics and human rights question forward is not simply a question of discussion.
Through a bibliometric analysis of peer-reviewed publications for the respective period of 2018–2025, this study systematically maps the academic field of AI ethics by presenting the key trends in publications, citation impact and thematic development of this area of research. Through this mechanism, the paper will map a thorough overview of the development that AI ethics research has gone through, from its inception and subsequent concerns regarding algorithmic accountability, data privacy, and governance of AI. A key contribution of this study is the application of the TCCM framework (,) which highlights how the research gaps that remain have been structured and how precisely an agenda for future research has been made available to scholars engaged in the field (Raji et al., 2022). The study also highlights important theoretical issues such as the lack of formal integration of ethical models and legal frameworks within AI ethics research. It highlights the geographical disparity of research being conducted in this area, particularly concerning the lack of representation of perspectives from the Global South and the need for regionally focused research in this field. Furthermore, the study highlights the lack of research concerning the specific ethical issues emerging from different AI technologies and applications, such as facial recognition technology, generative AI, and automated decision making. Finally, the study encourages the use of empirical research methodologies, such as algorithmic audits and stakeholder interviews, to complement the normative and conceptual work that has been done in this area. Ultimately, this paper serves to provide both a diagnostic view of the current status of AI ethics and human rights research, as well as a strategic overview of work to be conducted in the future. Through an examination of the theoretical, geographical, and methodological gaps in the field, it provides a platform for work that is more rigorous, inclusive, and practical in light of the protection and promotion of human rights in an age of rapidly evolving technologies.
Despite a thorough review of the published literature on artificial intelligence ethics and human rights, this study has several limitations that must be considered. First, the data used in this study were obtained only from the Scopus database. Although Scopus is well-known for its wide discipline coverage and accepted indexing, it is not exhaustive. Second, the search string used to locate the relevant documents ((“Artificial intelligence ethics” OR “AI ethics”) AND (“data protection” OR “privacy law” OR digital rights OR legal framework OR human rights OR tech governance)) was intended to be non-random and be able to target specific thematic interconnectedness. However, this Boolean search string may have unintentionally excluded literature that discusses themes using different terminology, geographical articulations, or implicit framing, without the language of the relevant keywords. This deficiency is inherent in all bibliometric studies, which depends on the choice of keywords, and may lead to the possibility of under-indication from certain theoretical or geographical perspectives. Fourthly, the quantitative bibliometrics approaches striven for in this study, which enable the investigation of publication trends, significant authors, significant keywords etc, do not assess the qualitative depth or normative quality of the arguments propounded in each article. The highly quoted literature may indicate popularity or transmutability, rather than theoretical or empirical justification. Similarly, keyword co-occurrence and source indicators may not indicate the presence of contradiction, comparative theoretical coherence, or methodological rigor. Fifth, although library software, such as VOS viewer, Biblioshiny, and Excel, were effectively employed to map and visualize the dataset, they relied on the metadata provided by Scopus, which may be inconsistent in the use of author names, institutional affiliations, and keyword tagging. Despite data cleaning efforts, certain residual errors such as duplicate authors or incomplete data on institutions may persist and affect clustering or trend analyses. Finally, the timeframe examined (2018–2025) contains the projected records for later publications. Forward-looking inclusion is a method of understanding emerging trends.
This paper demonstrates that there has been a rapid increase in the literature on AI ethics, whereby most of the contributions are from high-income countries such as the USA, the UK, and Australia. Thematic focus has gradually shifted from general ethical concerns to more specific ones, such as AI governance, algorithmic accountability, and data privacy, and more recently to issues relating to generative AI. In contrast, there are still gaps in both the theory and methodology of the literature. The literature is still mainly conceptual and lacks serious engagement with more structured ethical or legal theories such as deontology and human rights law. The geographical distribution of the literature is heavily weighted in the Global North, whereas the Global South, while providing an increasing number of publications, is hampered by a lack of visibility and citation impact. Furthermore, the literature is still mainly on general thematic categories, such as AI ethics and privacy, with little exploration of specific AI technologies and their specific ethical consequences. In addressing these gaps, the paper a future research agenda based on the TCCM framework (Theory–Context–Characteristics–Methodology). In conclusion, this study highlights the need for a theoretical shift in favor of more formal ethical models and legal frameworks. In regard to context, it is essential, it is intended in future publications to include those from underrepresented regions, together with non-English language ones, to provide a more complete global perspective.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)