Keywords
drug–drug interaction; pharmacovigilance; FAERS; MedDRA; disproportionality analysis; PRR; ROR; dataset
drug–drug interaction; pharmacovigilance; FAERS; MedDRA; disproportionality analysis; PRR; ROR; dataset
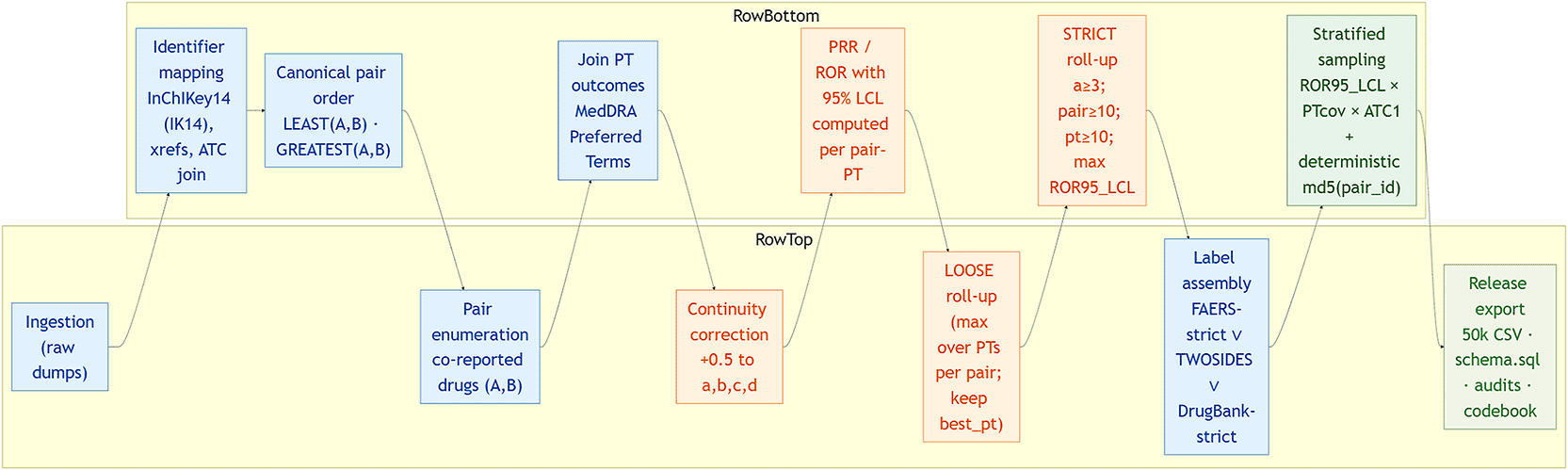
Spontaneous reporting systems such as the FDA Adverse Event Reporting System (FAERS) can surface DDI-related safety signals at scale, but their reuse in machine learning is often limited by unstable drug identifiers and opaque, non-auditable label construction.1 RxPairEvid-50 K fills these gaps with a combination of unchanging canonical drug identifiers (IK14), conservative rollups of disproportionality, and a PT-code rationale pointer per pair that associates each pair with the individual most supportive adverse outcome to be reviewed by a human as rapidly as possible. Outcomes are represented at the Preferred Term (PT) level with the use of the MedDRA terminology.4 A compact pipeline overview is shown in Figure 1, with further implementation detail in Figures 2–3.

Elements shown for TWOSIDES and DrugBank are optional layers in the authors’ internal build and are not redistributed in the public RxPairEvid-50 K release.
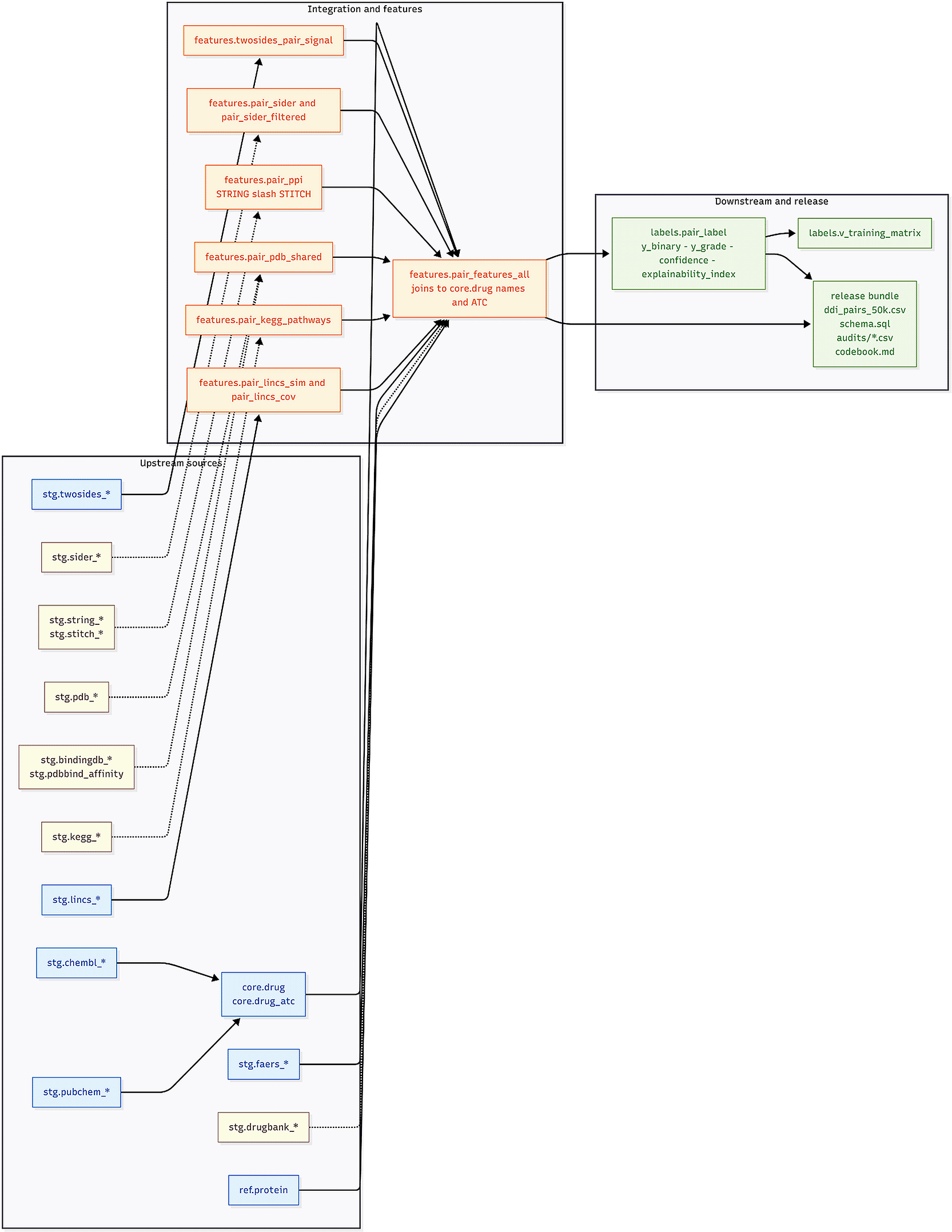
The public release packages ddi_pairs_50k.csv with schema.sql, audits, and a codebook; the other sources in the diagram are attachment points for users who use licensed data sets from their original providers.
The public release is deliberately license-clean. It redistributes only derived FAERS signal features and does not redistribute third-party resources whose terms may restrict redistribution (e.g., DrugBank, KEGG, PDBbind). The accompanying PostgreSQL schema DDL documents attachment points for readers who obtain those resources from original providers.5–12
RxPairEvid-50 K is a curated subset of a larger internal PostgreSQL database (ddi) that integrates multiple evidence layers for DDI modeling, including chemical structure (DrugBank, ChEMBL, PubChem), pathway and pharmacology (KEGG), targets and network biology (STRING, STITCH), protein–ligand bioactivity (BindingDB, PDB/PDBbind), transcriptomics (LINCS), curated adverse reactions (SIDER), and TWOSIDES signals, alongside FAERS pharmacovigilance.5–17 For public dissemination we release a compact, information-rich 50,000-pair matrix focused on FAERS-derived signal features and rationale pointers, together with provenance and audit artifacts.
Redistributed source and derived outputs:
• FAERS quarterly files (DRUG/REAC/DEMO) from 2018 onward (time window specified in provenance.md).1
Referenced as optional attachment points (not redistributed in RxPairEvid-50 K):
• MedDRA (PT text not redistributed; PT codes only).4
• DrugBank interaction knowledge and drug properties.5
• KEGG pathway annotations.6
• SIDER adverse-effect associations.11
• LINCS L1000 transcriptomic profiles.12
• ChEMBL, PubChem, BindingDB for chemistry/bioactivity crosswalks.13–15
• RxNorm/ATC for normalization/stratification where available.16
• TWOSIDES as an external signal set for ablations in the internal build.17
The verified internal build ran on PostgreSQL 14.19 (Ubuntu) with a psql 18.0 client. The exported schema report records the database layout (schemas stg, core, features, labels, ml, ref ) and provides row estimates and column types for reproducibility. This build has 11,521 canonical drugs as core.drug, 1,073,256 canonical drug pairs as features.pair_features_all and 50,340 pairs satisfying strict floors (a_raw≥3, pair≥10, PT ≥ 10) as seen in strict FAERS rollup table.
Every drug has a standardized identifier (IK14 identifier, the first 14 characters of the InChIKey) which can be used to stabilize joins across sources, and to enable decent leakage-aware evaluation splits. Pairs are represented in unordered keys (A < B) to eliminate duplication and ambiguity in ranking.
FAERS DRUG quarterly and REAC quarterly records are broken out into normalized staging tables, with powerful management of typical encoding problems. Mentions of drugs are normalised (case folding, removal of punctuations, removal of dosage/form/route tokens) and compared to IK14 with token-based dictionaries and database indexes. In the verified build, there are 322,635 distinct normalized names in the normalized FAERS name table, and the final FAERS name-to-drug mapping table has 59,507 mapped names, which gives it an auditable interface to quality checks of the mapping (e.g., frequency-ranking inspection of unmapped names).
We construct a 2 x 2 contingency table and calculate measures of disproportionality of each (drug A, drug B, PT). PRR is widely employed in signal generation of spontaneous-report data.2 ROR is as well a popular tool and application of the lower confidence bound will assist in minimizing the false positives based on the limited number of counts.3 We apply a Haldane–Anscombe (+0.5) continuity correction before computing log-scale standard errors:
It has two regimes of evidence, coverage-oriented loose regime, and a conservative strict regime. Floors on minimum counts (a raw>3, pair>10, PT > 10) are imposed by the strict regime to eliminate instability in small counts and enhance interpretability of the retained signals.
Pair-level features are produced by rolling up eligible PT rows and retaining maxima and coverage counts:
• n_faers_reports: co-report count for the pair.
• faers_prr_max_strict: maximum PRR across PTs under strict floors.
• faers_ror95_lcl_max_strict: maximum lower 95% bound of ROR across PTs under strict floors.
• faers_pt_covered_strict: number of distinct PTs meeting strict floors.
• faers_best_pt_code_strict: PT code corresponding to the maximum strict ROR95_LCL signal.
The PT-code pointer enables audit-friendly interpretation without redistributing MedDRA PT text.
RxPairEvid-50 K is deterministic stratified sample of strict FAERS rollup matrix. When there is a coarse ATC grouping; (i) ROR95 LCL bins, (ii) PT coverage bins, and (iii) a coarse ATC grouping are used to define the strata. The pairs of the stratum are ordered deterministically on the basis of md5(pair_id) and a predefined quota is sampled to obtain 50,000 rows. This enables the selection to be reproduced in rebuilds with the same strict matrix and strata definition.
The information is stored on Mendeley Data18 and is available in flat files. Table 1 contains the major fields in the primary CSV (ddi_pairs_50k.csv), and Table 2 contains the files that were added in the Mendeley record. Figure 1 gives an overview in high level of the RxPairEvid-50 K generation and release bundle, Figure 2 gives details of the steps of the FAERS processing and roll-up on a strict regime prior to sampling, and Figure 3 summarizes the internal database integration and optional attachment points of licensed resources.
Validation is more about auditability and integrity, and not about predictive performance. They have been released with the sampling strata counts, signal quantile summaries, and SHA-256 checksums so they can be checked with the benefit of both integrity verification and rapid sanity checks. Moreover, high floors and confidence-bound screening minimize the small denominator instability, and rationale pointers are used to justify manual inspection of high-signaling pairs.
Signals derived by FAERS are associative and prone to reporting bias, confounding, and stimulated reporting and should not be used as causal data of a DDI. We suggest RxPairEvid-50 K since (i) it is a benchmarking dataset to signal-based modeling (ii) it is an evidence layer used to construct labels in multi-evidence pipelines (iii) it is a transparent baseline used in ablation analysis. To evaluate leakage-aware, split on the drug level (IK14-disjoint) and then form pair splits, and use PR-AUC as a chief measurement in class imbalance.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)