Keywords
Reproducibility, Hackathon, Open Science, Metascience, Computational Research, Software, Community Engagement
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the Hackathons collection.
Reproducibility, Hackathon, Open Science, Metascience, Computational Research, Software, Community Engagement
Reproducibility is fundamental to science because it ensures that research results are transparent and verifiable. Computational reproducibility focuses on the ability to obtain consistent results using the original data and computational steps, essentially testing the robustness of the code and analysis. Within the framework of open science, computational reproducibility is tightly connected to, yet distinct from, the broader concept of replicability, which addresses whether a similar result can be achieved using the same methods with new data.
At a reproducibility hackathon, the goal is to use the provided data and code, usually from a published article, to determine whether the analysis described by the authors can be repeated with consistent results. Besides confirming that the computations run as intended, this often involves checking compatibility across different operating systems and software versions. The process relies heavily on full access to both data and code, making open sharing essential. For software in particular, clear documentation and adherence to established standards and ontologies are equally important pillars of reproducible work.
Such hackathons offer excellent hands-on experience, especially for early-career researchers, who can develop good research habits before rigid routines form. Building on the success of the reproducibility hackathon satellite event at the Swiss Reproducibility Conference 2024, an independent hackathon was held at UniDistance Suisse in Brig, Switzerland on June 6, 2025. The event brought together 19 participants representing a vast range of scientific disciplines and eager to strengthen reproducible research practices. In this report, we present key insights that emerged during the event.
Details of the reproduction efforts are available on ReproHack Hub (https://www.reprohack.org/event/34/), including the individual reproduction reports. Five original research papers were submitted for the hackathon, with some authors attending and engaging in reproducing work other than their own. The event emphasized a constructive and collaborative atmosphere, focusing on learning opportunities rather than criticism of the paper content. Authors who were present answered questions and provided support during the reproduction attempts.
Participants came from diverse scientific backgrounds, many were unfamiliar with the specific topics or computational methods involved. Working in groups and having direct access to the authors created a productive and supportive environment that enabled mutual learning for both participants and authors.
Four of the five submissions were at least partially reproduced ( Table 1). Participants encountered several common hurdles, including unclear or missing documentation, unspecified software dependencies, and difficulties accessing code or datasets. Differences in hardware setups also contributed to variations in results, complicating replication efforts. One difficulty was the lack of version documentation for packages within the used programs. This led to the inability to reproduce certain aspects as the functionality of packages changed over time. Further, certain individualized variables were only partially explained which made it difficult to understand their exact usage and how to manipulate them. Throughout the event, participants tackled these issues and provided valuable feedback to the original authors. Many challenges appeared solvable by improving or adding metadata and clarifying documentation, while others, such as configuring containerized environments, required more technical expertise. At the end of the day, teams shared their findings and discussed obstacles and potential solutions, fostering a deeper understanding of how reproducibility can be improved in practice.
MRS reflects subjective assessments by participants and should be interpreted as indicative rather than definitive.
| Title | MRS | Reviews |
|---|---|---|
| On reduced input-output dynamic mode decomposition1 | 2 | 1 |
| Bore me (not): boredom impairs recognition memory but not the pupil old/new effect2 | 8 | 1 |
| Closed-Form Power and Sample Size Calculations for Bayes Factors3 | 8 | 3 |
| Gender Equity Navigator (GEN)4 | 0 | 2 |
| Wastewater monitoring of SARS-CoV-2 shows high correlation with COVID-19 case numbers and allowed early detection of the first confirmed B.1.1.529 infection in Switzerland5 | 6 | 5 |
The mean reproducibility score (MRS) shown in Table 1 represents the average of all submitted reviews to the question: “How much of the paper did you manage to reproduce?”, rated on a scale of 0 to 10.
Participants shared their experiences as shown in Figure 1, expressing a mix of frustration and engagement throughout the reproduction efforts. Despite the difficulties, there was a clear interest and satisfaction in contributing to the important topic of reproducibility. Many appreciated the group setting and the exchange of perspectives across different levels of expertise.
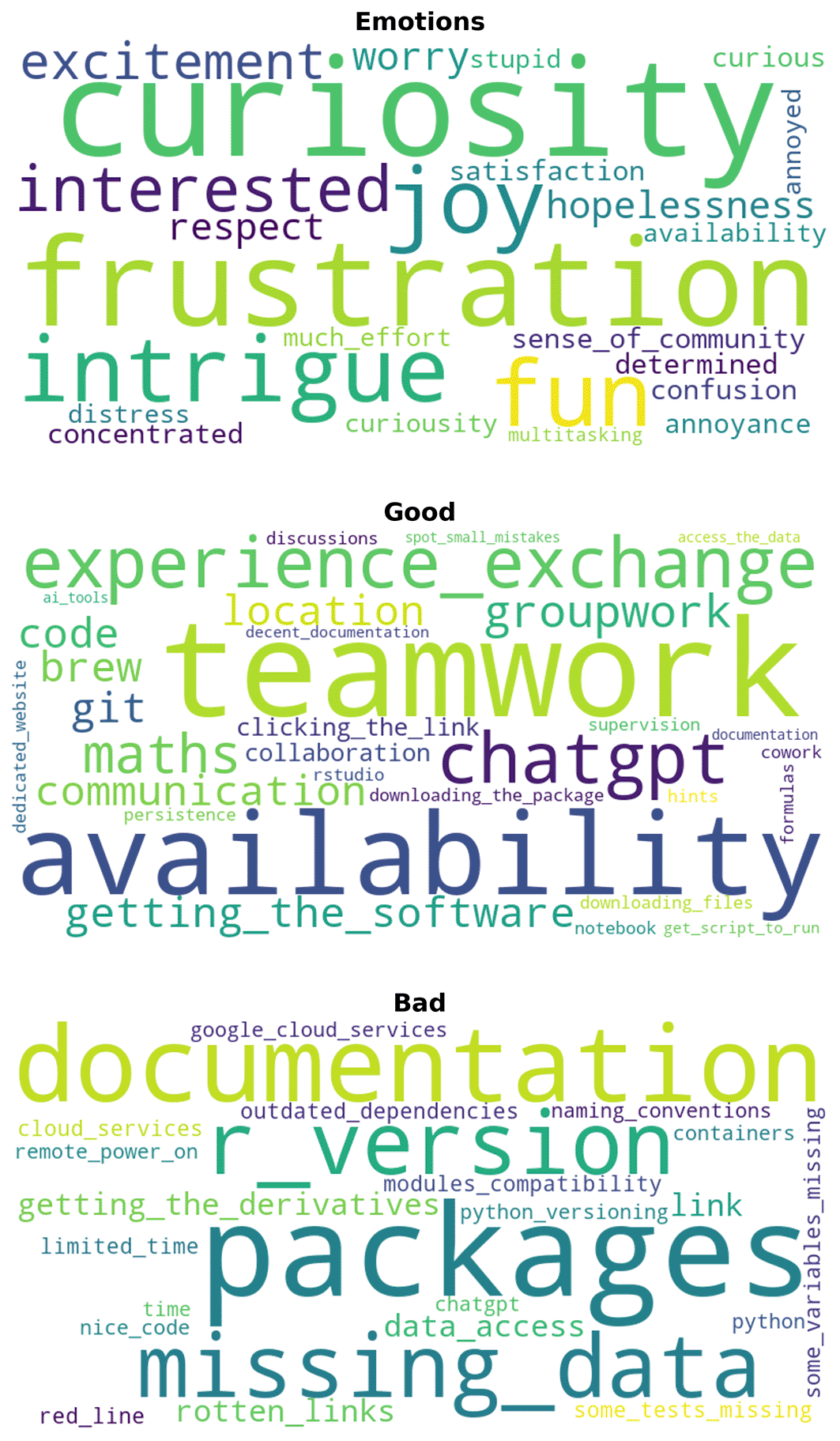
The larger a word appears the more often it was mentioned by participants. The questions were: What were your main emotions during the reproduction attempt? What worked well? What didn’t work at all?
Large language models (LLMs), such as ChatGPT, played a helpful role in creating computational environments even for those with limited technical knowledge. Outdated software and package versions proved to be significant obstacles, alongside insufficient documentation. While researchers have limited control over software stability, the responsibility for clear documentation lies with the authors. However, the lack of strong incentives often discourages investment in detailed documentation. LLMs may help ease this burden by improving clarity and readability, although their use should remain cautious and supervised. Participants later emphasized, as reflected in Figure 2, that effective documentation is one of the most critical factors for successful reproducibility.
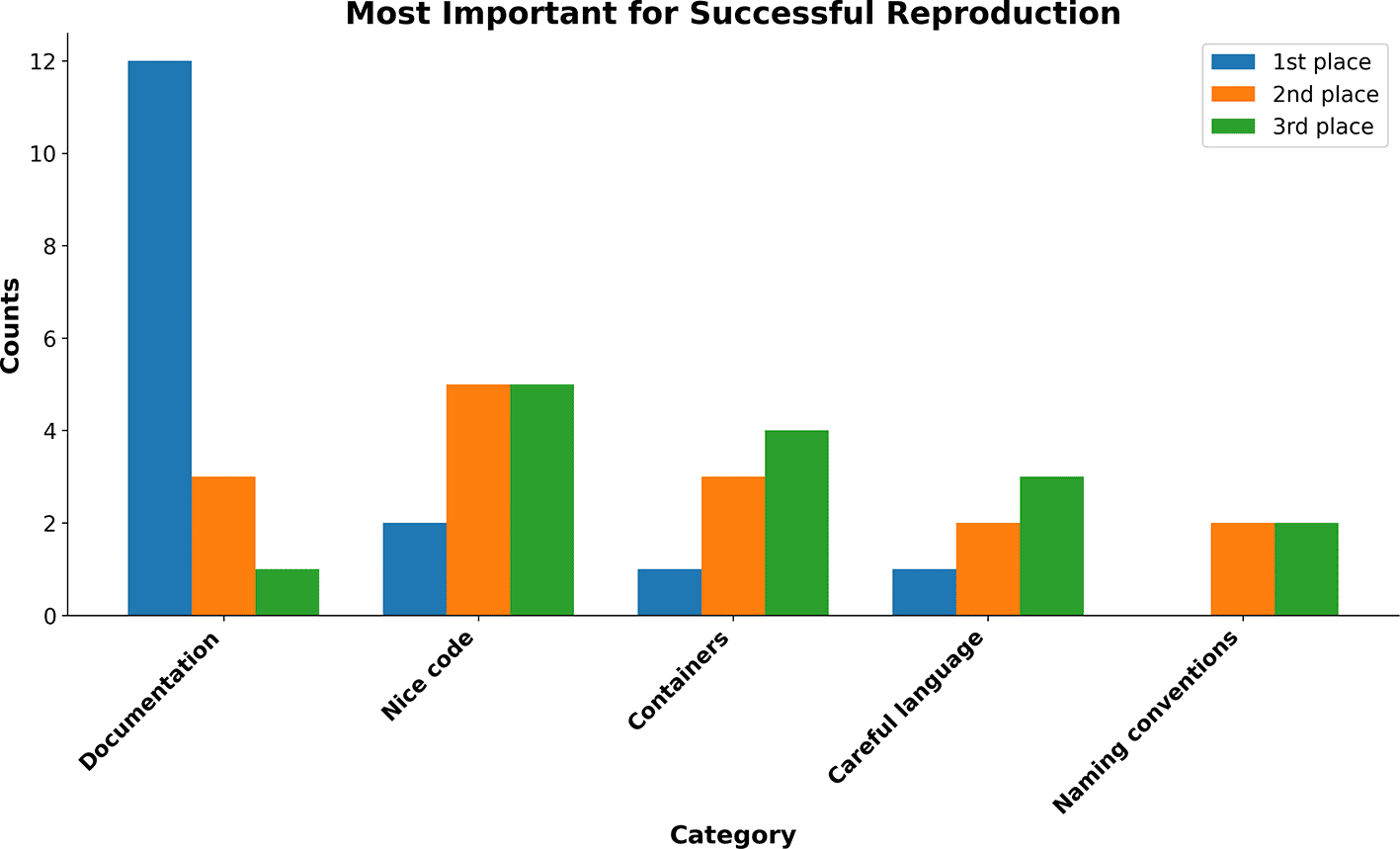
The discussions at the end of the hackathon converged on a shared understanding that computational reproducibility is less a single technical hurdle and more an ecosystem problem, shaped by documentation quality, software evolution, and community norms. While participants encountered a wide range of domain-specific challenges, the obstacles they identified were remarkably consistent across projects and disciplines.
A central theme was the importance of clear, structured documentation, which participants ranked as the single most important factor when attempting to reproduce computational work. Documentation was repeatedly described as the primary entry point into a project, enabling others to understand assumptions, variable definitions, data preprocessing steps, and expected outputs. Even well-written and logically structured code proved difficult to reuse in the absence of sufficient explanatory context. This aligns with the observation that documentation often determines whether reproduction efforts can begin at all, rather than how efficiently they proceed.
Closely related to documentation, environment capture and documentation emerged as a top priority in the participant-derived checklist, receiving the highest importance rating (mean 4.4 on a 1–5 scale, tied with data accessibility and versioning). Participants emphasized that reproducibility is strongly undermined when software dependencies, package versions, or operating system assumptions are not explicitly recorded. The rapid evolution of scientific software ecosystems means that even relatively recent code may fail to execute without careful environment specification. While researchers cannot fully control external software changes, they can mitigate their impact through explicit version pinning, environment files, and containerized setups.
Data accessibility and versioning were rated equally important (mean 4.4), reflecting the practical reality that reproduction efforts cannot proceed if datasets are unavailable, poorly documented, or ambiguously versioned. Participants noted that even when data were technically accessible, missing metadata, unclear preprocessing steps, or undocumented transformations created substantial barriers. Persistent identifiers for datasets and clear links between data versions and specific analyses were repeatedly highlighted as good practice.
Other checklist components (code structure, sharing, and execution (mean 3.9), result provenance and reporting (mean 3.8), and randomness control and determinism (mean 3.3)) were seen as important but secondary. This ordering suggests a pragmatic perspective: reproducibility first depends on being able to run an analysis at all, before finer-grained concerns such as numerical determinism or formal provenance tracking become relevant. Participants also ranked “nice code” and “containers” highly when asked about the most important aspects of reproduction, reinforcing the idea that readability, modularity, and standardized execution environments meaningfully lower the barrier for third-party reuse.
Importantly, these discussions underscored that reproducibility should be approached as a process designed from the outset, rather than a retrospective fix. Participants agreed that early planning – such as deciding where code and data will be hosted, how versions will be tracked, and how results will be reported – has a disproportionately large impact on downstream reproducibility. Rather than debating optimal tools, participants advocated for clear, well-documented choices that can be understood and reused by others. Support structures, including research software engineers and data stewards, were identified as key enablers, particularly for researchers without formal training in software development.
Finally, the role of institutional and journal-level policies was discussed. Mandatory data and code sharing requirements were widely acknowledged as having already improved reproducibility standards, although participants noted that compliance alone does not guarantee usability. In this context, lightweight tools, such as checklists, example repositories, and shared templates, were seen as promising mechanisms to translate policy requirements into meaningful practice.
The SwissRN Computational Reproducibility Hackathon demonstrated that hands-on reproduction efforts can generate not only valuable feedback for individual projects, but also transferable insights into the structural conditions that enable or hinder computational reproducibility. Building on these experiences, a central ambition emerging from this initiative is to move beyond isolated events toward the development of widely accessible, community-driven best practices for computational reproducibility, and to embed these practices sustainably into research training.
Repeated hackathons conducted across different regions, institutions, and scientific domains, without being fixed to a specific topic, provide a particularly powerful mechanism for identifying generalizable reproducibility principles. By deliberately exposing a wide variety of computational workflows to reproduction attempts, such events allow recurring challenges and effective solutions to surface independently of discipline-specific conventions. At the same time, they naturally reveal topical or methodological special cases, which can be documented as extensions rather than exceptions to a shared core of best practices.
A key next step is therefore to distill the insights gained from multiple hackathons into a concise, practical best-practice guide for computational reproducibility, grounded in empirical experience rather than abstract recommendations. Participant feedback from this and future events can directly inform the structure of such guidance, prioritizing aspects that have the greatest downstream impact, such as documentation quality, environment capture, and data accessibility, while offering pragmatic advice on code organization, provenance tracking, and randomness control. Making this guidance openly available in modular, reusable formats (e.g., checklists, templates, example repositories) will be essential to ensure broad adoption.
Beyond documentation, there is a clear opportunity and responsibility to translate these best practices into effective educational offerings, particularly at the undergraduate level and across disciplines. Teaching computational reproducibility early, before ad-hoc habits become entrenched, has the potential to raise baseline standards across entire research communities. Rather than treating reproducibility as an advanced or optional topic, it should be integrated into core curricula wherever computational methods are used.
To scale such efforts sustainably, we see strong alignment with established training frameworks such as The Carpentries,6,7 emphasizing reusable lesson materials, instructor training, and a “teach the teachers” model. Casting reproducibility content into this framework would allow best practices to be disseminated efficiently, adapted locally, and maintained collaboratively. In this context, close collaboration with the SwissRN Working Group for Training represents a natural and important next step, ensuring that methodological insights from hackathons are translated into pedagogically sound, high-quality training resources.
Ultimately, reproducibility hackathons should be understood as catalysts within a larger ecosystem; linking empirical assessment, community knowledge generation, and education. By systematically connecting hackathon-derived insights with open best-practice guidance and scalable training initiatives, SwissRN can contribute to a durable improvement in computational reproducibility across disciplines and career stages.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)